
虽然编译原理还没有开始学习,但是
libco中用到的hook技术已然用到了其中的一些知识.于是发奋拿起了<<深入理解计算机系统>>看了一下链接的篇章.在此处做一个简单的总结!!!
下面这张图,相信很多人已经很熟悉很熟悉了!!!
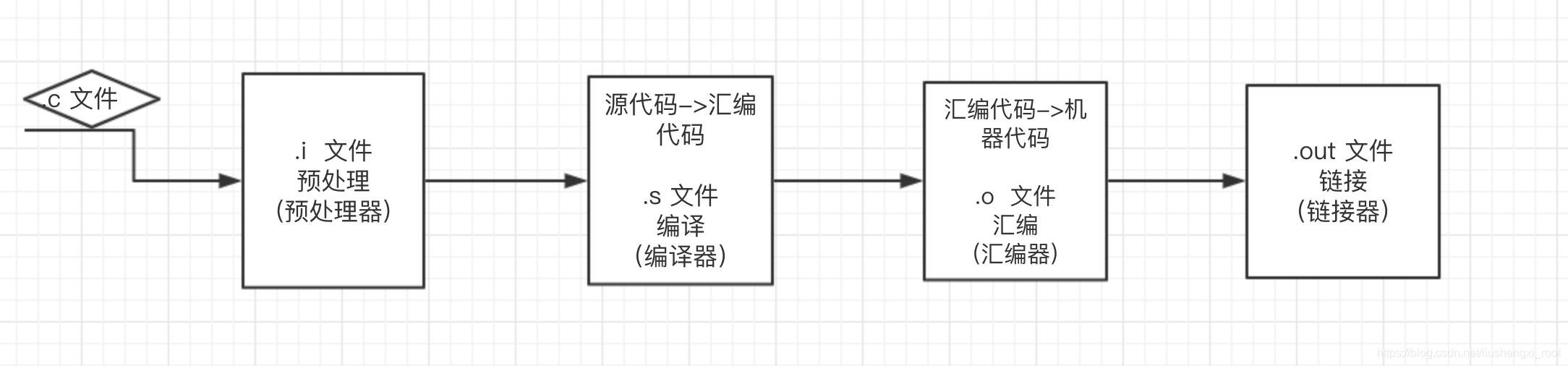
其中最后一个过程,链接可以
- 执行于编译时,也就是在源代码被翻译成机器代码时;
- 也可以执行于加载时,也就是在程序被加载器加载到存储器并执行时;
- 甚至可以执行于运行时,由应用程序来执行。
所以说链接以上的顺序并不是绝对固定的!!!
更加详细的内容见:https://www.cnblogs.com/mickole/articles/3659112.html
接下来的内容主要还是围绕链接的一些比较深入的细节。
从传统静态链接到加载时的共享库的动态链接,以及到运行时的共享库的动态链接。
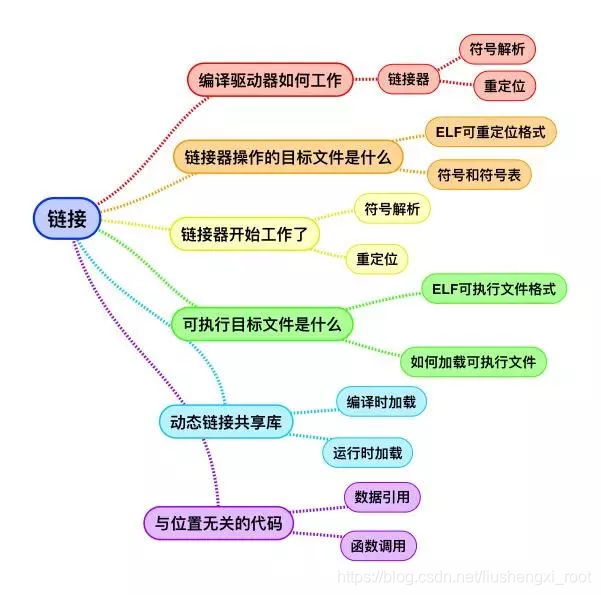
编译器驱动程序(其实就是上面的那一套流程)
用到的两个程序代码:
swap.c
/* $begin swap */
/* swap.c */
extern int buf[];
int *bufp0 = &buf[0];
int *bufp1;
void swap()
{
int temp;
bufp1 = &buf[1];
temp = *bufp0;
*bufp0 = *bufp1;
*bufp1 = temp;
}
/* $end swap */

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
main.c
/* $begin main */
/* main.c */
void swap();
int buf[2] = {1, 2};
int main()
{
swap();
return 0;
}
/* $end main */
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
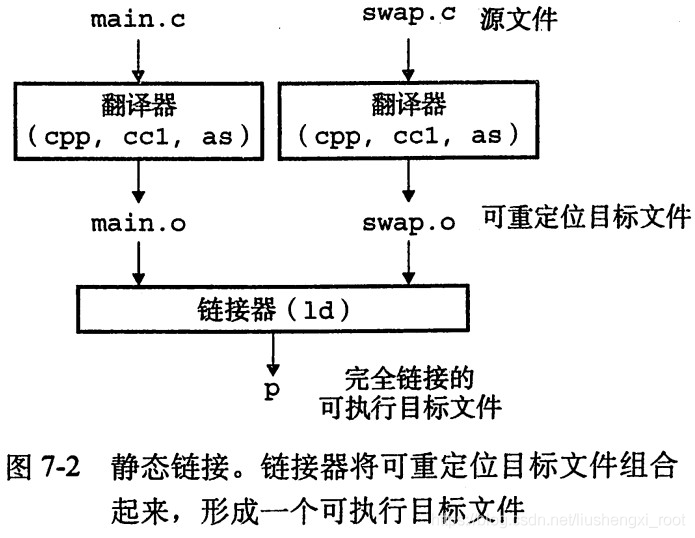
由预处理器(cpp)将main.c翻译成中间文件:main.i,接下来是编译器(cc1)将main.i翻译成汇编文件main.s。然后是汇编器(as)将main.s翻译成一个可重定位的目标文件main.o。最后由链接器(ld)将main.o和swap.o以及一些系统目标文件组合起来,创建可执行目标文件p
之后,shell调用系统中加载器的函数,由它将可执行文件 p 中的代码和数据复制到内存,然后将控制转移到这个程序的开头。
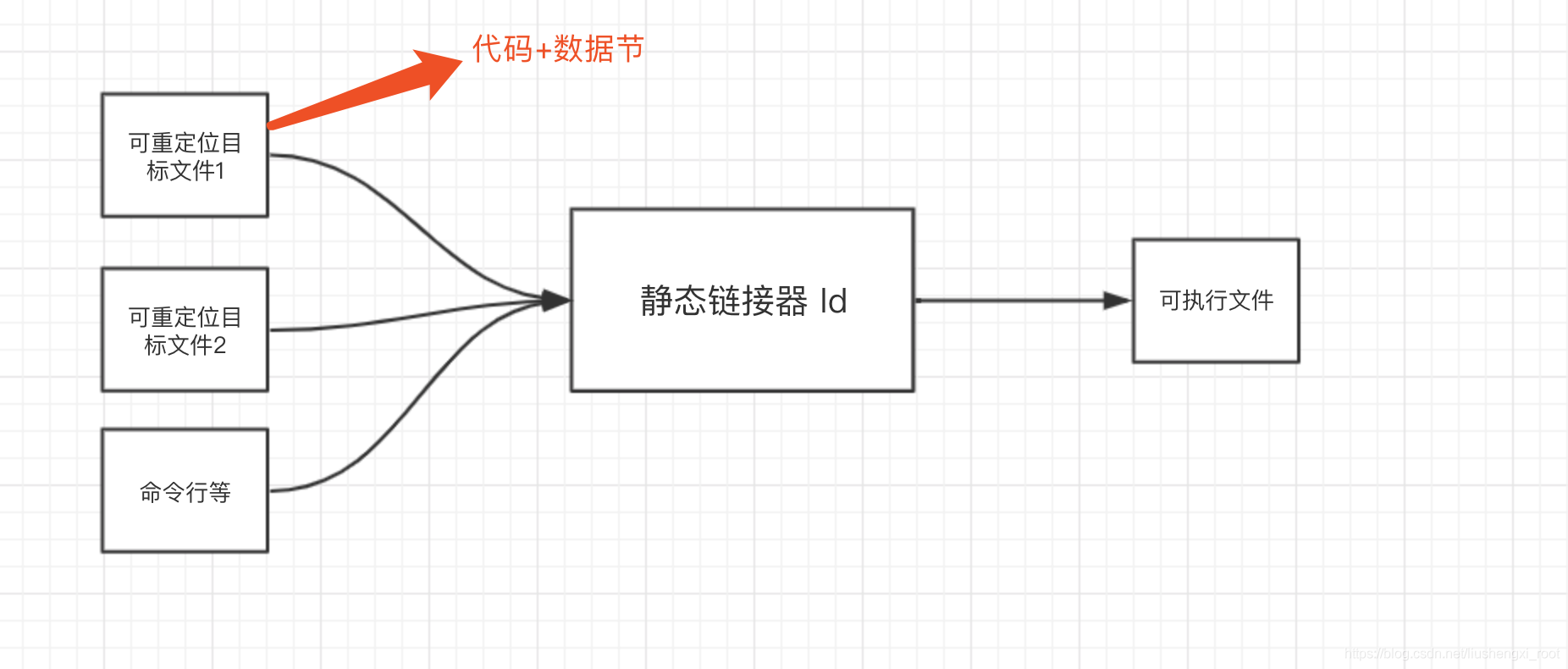
静态链接器
静态链接器就是以一组可重定位目标文件和命令行(这个其实就是前面的编译器和汇编器传过来的引导链接器和加载器的数据结构)为输入,以一个完整的可执行文件为输出
- 可重定位目标文件:由
各种不同的代码和数据节组成,每一节都是一个连续的字节序列,指令在一节,初始化的全局变量在一节,未初始化的变量在另外一节.
链接器必须完成两个主要任务:
为了构造可执行文件,链接器必须完成以下的两件事:
-
① 符号解析(symbol resolution)。 目标文件定义和引用符号,每个符号对应于一个函数、一个全局变量或一个静态变量(即C语言中任何以static属性声明的变量)。
符号解析的目的是将每个符号引用正好和一个符号定义关联起来。 -
② 重定位(relocation)。 编译器和汇编器生成从地址0开始的代码和数据节。链接器通过把每个符号定义与一个内存位置关联起来,从而重定位这些节,然后修改所有对这些符号的引用,使得它们指向这个内存位置。链接器使用汇编器产生的重定位条目(relocation entry) 的详细指令,不加甄别地执行这样的重定位。
一些前提知识
目标文件究竟是什么?有什么样的特殊格式吗?
所谓的目标文件大概有三种不同的形式:
- 可重定位目标文件;(前面已讲)
- 可执行目标文件
- 共享目标文件(一种特殊的可重定位目标文件,在加载或者运行时被动的加载进内存被链接)
我们接下来讨论的目标文件是基于Unix系统的ELF格式(Exxcutable and Linkable Format),这同Windows系统上的PE(Portable Executable)文件格式在基本概念上其实是相似的:
可重定位目标文件
- 一个典型的 ELF 可重定位目标文件的格式:
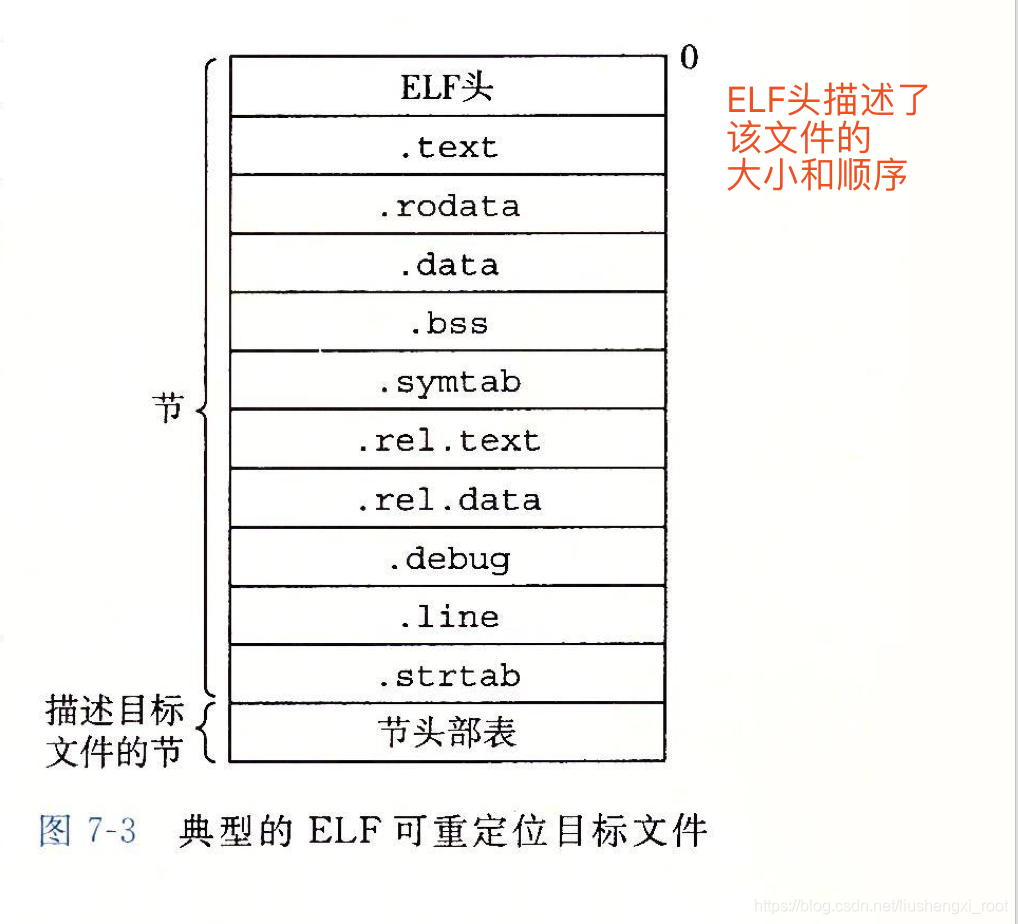
ELF头剩下的部分:包含帮助链接器语法分析和解释目标文件的信息。其中包括ELF头的大小、目标文件的类型(如可重定位、可执行或者共享的)、机器类型(如x86- 64)、节头部表(section header table) 的文件偏移,以及节头部表中条目的大小和数量。不同节的位置和大小是由节头部表描述的,其中目标文件中每个节都有一个固定大小的条目(entry)。夹在ELF头和节头部表之间的都是节。一个典型的ELF可重定位目标文件包含下面几个节:
解释:
.text:已编译程序的机器码;.rodata:只读数据(read-only-data);
.data:已初始化的全局/静态C变量;.bss:未初始化的全局/静态C变量;未初始化变量不占据任何实际的磁盘空间,运行时分配。
.symtab:一个符号表(存放程序中定义和引用的函数和全局变量的信息);
.rel.text:代码重定位条目, 一个.text节中位置的列表,需要修改的位置;
.rel.data: 被模块引用或定义的任何全局变量的重定位信息;
.debug:一个调试符号表; .line:原始C源程序中的行号和.text机器指令的映射;
.strtab: 一个字符串表
看完是不是感觉和进程的地址空间有点类似呐!!!
符号和符号表
每个可重定位目标模块m都有一个符号表,它包含m定义和引用的符号的信息。在链接器的上下文中,有三种不同的符号:
由模块m定义并能被其他模块引用的全局符号。(不带static的C函数以及全局变量)由其他模块定义并被模块m引用的全局符号。这些符号称为外部符号(外部定义的不带static的C函数以及全局变量)只被模块 m 定义和引用的局部符号。它们对应于带static属性的C函数/变量和全局变量。这些符号在模块m中任何位置都可见,但是不能被其他模块引用。(带 static的C函数/变量以及全局变量)
注意:本地程序(未带有static的局部)变量在符号表中不出现,直接放在栈中管理.
如果是带有static符号的就会在.data 和.bss中为每个定义分配空间,并在.symtab中创建一个唯一名字的本地符号。比如:

中有两个static定义的x变量,其会在.data中分配空间,并在.symtab中创建两个符号,x.1表示f函数的定义和x.2表示函数g的定义。(注:使用static可以保护你自己的变量和函数)
符号表的结构(简略总结)

我们给出main.o符号表中的最后三个条目:(开始的都是使用的本地符号)
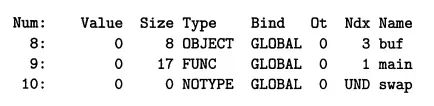
我们看到num8处的全局变量buf定义条目,位于.data(Ndx=3)开始字节偏移为0(value为0)处的8个字节目标(size)。随后是全局符号main的定义,其位于.text(Nex=1)处,偏移字节为0处(value)的17个字节函数。最后一个是swap的引用,所以是Und。(这个应该有点问题,去看一下书中的解释吧!Ndx== 1 .text 节,Ndx == 3, .data 节)
1.符号解析
符号解析任务简单的说,就是**链接器在这一个阶段的主要任务就是把代码中的每个符号引用和输入的可重定位文件的符号表中确定的一个符号定义联系起来**.对于本地符号,这个任务相对来说是简单的。复杂的就是全局符号,编译器(cc1)遇到不是在当前模块中定义的符号时,会假设该符号的定义在其他模块中,生成一个链接器符号交给链接器处理。如果链接器ld在所有的模块中都找不到定义的话就会抛出异常。
这里最容易产生的错误就是当多个模块定义同一个符号的时候,我们的链接器到底怎么做。
以C++中的函数重载为例,我们会按照实际的需要重载许多相同名字的函数,链接器(ld)使用一种叫做重整的方法(mangling)将相同函数名不同参数的函数编码为对链接器来说唯一的名字.举例如下:
class Test
{
public:
void print1()
{ }
void print1(int a)
{ }
void print1(string a)
{ }
};
他们各自对应的名字可能就是3Test_print_int_a,3Test_print_string_a
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
那么链接器如何解析多重定义的全局符号?
链接器的输入是一组可重定位目标模块,有些是局部的(只对自己模块可见),有些是全局的(对所有模块可见),那么如果多个模块定义了相同的全局符号,该怎么办呐?
Linux 是这样做的:
Linux 在编译时,编译器向汇编器输出每个全局符号,要么是强,要么是弱.汇编器把这个信息放到符号表中.强弱符号定义的基本规则是:
- 强:函数+已初始化的全局变量
- 弱:未初始化的全局变量
使用如下规则:
规则1:不允许多个同名的强符号;
规则2:如果有一个强符号和多个弱符号同名,那么选择强符号;
规则3:如果有多个弱符号同名,那么在这些弱符号中任意选择一个;
- 1
- 2
- 3
- 4
- 5
举例:
//main.cpp
#include - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
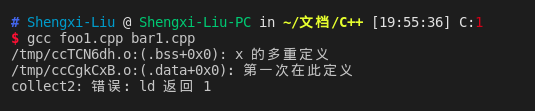
可见上面说的规则已经不适用于当下的编译器了.不过,无所谓,我们先知道大致上有这么回事即可.以后遇到了再深入探究一下!!!
具体解析会有三个集合,然后balabalabalabala的,太细节,有时间再看书搞一搞吧!
2.重定位
一旦完成了符号解析,就把代码中的每个符号引用(就是说你这个函数中使用的某个符号来自于哪里)和符号的定义(即声明)关联起来了.此时,链接器就知道了输入的模块中的代码和数据节的确切大小.然后就可以愉快的开始重定位了.主要就是:合并输入模块,并为每个符号分配运行时的地址。一般有两步:
-
重定位节和符号定义:在这一步中,
链接器将所有模块中的相同类型的节合并为同一类型的新的聚合节。然后,链接器将运行时的内存地址赋给新的聚合节,赋给输入模块定义的每个节,以及赋给输入模块定义的每个符号。完成时,每条指令和全局变量都就有唯一的运行时内存地址了。 -
重定位节和符号引用:修改代码节和数据节中对于每个符号的引用,使得他们指向正确的运行时地址(依赖于可重定位目标模块中称为重定位条目的数据结构)
可执行目标文件格式(一个典型的ELF可执行文件)
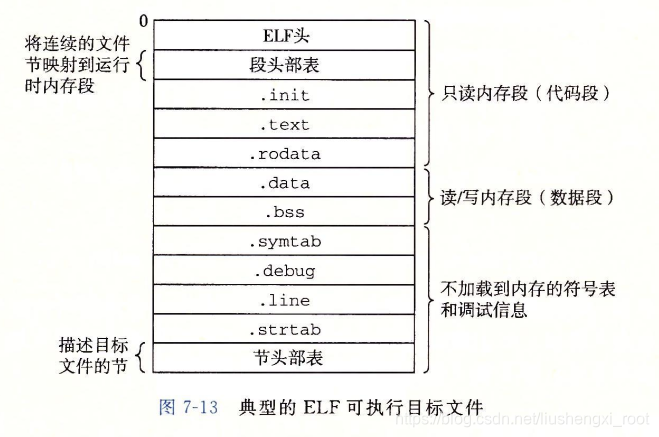
说明:
- ELF头部:描述文件总体格式,标注出程序入口点;.init:定义了初始化函数;
- 段头部表:可执行文件是一个个连续的片,段头部表中描述了这种映射关系;

可见有两个段,代码段和数据段。
代码段:同下
数据段:第3行和第4行告诉我们第二个段(数据段)有读/写访问权限,开始于内存地址0x600df8处,总的内存大小为0x230 字节,并用从目标文件中偏移0xdf8 处开始的.data节中的0x228个字节初始化。该段中剩下的8个字节对应于运行时将被初始化为0的.bss数据。
对于任何段s,链接器必须选择一个起始地址vaddr,使得
vaddr mod align = off mod align
这里,off 是目标文件中段的第一个节的偏移量,align 是程序头部中指定的对齐(21= 0x200000)。例如,图7-14中的数据段中
vaddr mod align = 0x600df8 mod 0x200000 = 0xdf8以及
off mod align = 0xdf8 mod 0x200000 = 0xdf8
- 1
- 2
- 3
这个对齐要求是一种优化,使得当程序执行时,目标文件中的段能够很有效率地传送到内存中。原因有点儿微妙,在于虚拟内存的组织方式,它被组织成- -些很大的、连续的、大小为2的幂的字节片
如何加载可执行目标文件
从./a.out 开始:
- Exec镞函数 -> 调用驻留在内存中称为加载器的OS代码来运行 a.out
- 加载器将可执行文件中的代码和数据从磁盘复制到内存中(加载)
- 跳转到程序的第一条指令或者入口点来运行程序
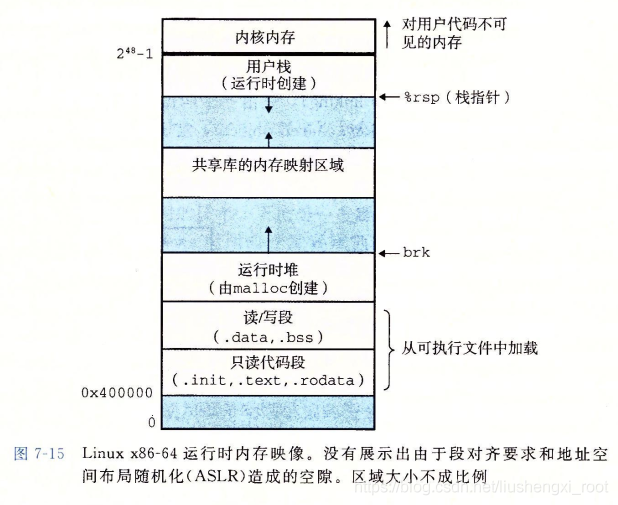
-
加载后运行的每个Unix程序都有一个镜像,如上图所示。
-
什么是加载?说白了就是将程序拷贝到存储器并运行的过程。这里是由execev函数来调用加载器(驻留在存储器中)完成的,我们要执行p文件的时候,就是使用./p来,加载器就把p的数据和代码拷贝从磁盘拷贝到了存储器中,并通过跳转到ELF头部中的程序入口点开始程序p的执行。
-
怎样加载?当加载器运行时,就先创建一个存储器映像(上图所示),在ELF可执行文件头部表的指示下,加载器将可执行文件的片复制到代码段和数据段,然后跳转到程序入口点_start(在系统目标文件ctrl.o中定义,对所有的C程序都一样,其实就是系统启动函数__libc_start_main,该函数定义在libc.so中,它初始化执行环境,调用用户层的main函数,处理main函数的返回值等)开始执行
加载器总结:
-
Linux系统中的每个程序都运行在一个进程上下文中,有自己的虚拟地址空间。当shell 运行一个程序时,父shell进程生成一个子进程,它是父进程的一个复制。(运行镜像的一种复制)
-
子进程通过execve系统调用启动加载器。加载器删除子进程现有的虚拟内存段,并创建一组新的代码、数据、堆和栈段。新的栈和堆段被初始化为零。
-
通过将虛拟地址空间中的页映射到可执行文件的页大小的片(chunk),新的代码和数据段被初始化为可执行文件的内容。
-
最后,加载器跳转到_ start地址, 它最终会调用应用程序的main函数。
-
除了一些头部信息,在加载过程中没有任何从磁盘到内存的数据复制。直到CPU引用一个被映射的虚拟页时才会进行复制,此时,操作系统利用它的页面调度机制自动将页面从磁盘传送到内存。
库打桩机制
Linux链接器所提供的技术,允许用户截获对共享库函数的调用,并执行自己的代码(当然是在普通权限下,管理员权限通常是禁止使用该技术的)。
使用打桩机制,可以追踪某个特殊库函数的调用次数、验证并追踪其输入输出,甚至把它替换成一个完全不同的实现。
三种方式:
- 编译时打桩(宏定义)
//主要是这,具体看书
#ifndef COMPILE_TIME
#define malloc(size) mymalloc(size)
#define free(ptr) myfree(ptr)
- 1
- 2
- 3
- 链接时打桩(相当于简单的替换)
Linux静态链接器支持用–wrap f标志进行链接时打桩。这个标志告诉链接器,把对符号f的引用解析成__wrap_f(前缀是两个下划线),还要对符号__real_f的引用解析成f。
- 运行时打桩
编译时打桩需要访问程序的源代码,连接时打桩需要能够访问程序的可重定位的对象文件。不过运行时打桩仅需要访问可执行目标文件即可,它的基本原理是基于动态链接器的LD_PRELOAD环境变量的。
如果LD_PRELOAD环境变量被设置为一个共享库路径的列表(以空格或分号分隔),那么当你加载和执行一个程序,需要解析未定义的引用时,动态链接器会先搜做LD_PRELOAD中给定的库,然后才搜索任何其他的库。有了这个机制,当你加载和执行任意可执行文件时,可以对任何共享库中任意函数打桩,包括libc.so中的malloc和free。
// mymalloc.c
#ifdef RUNTIME
#define _GNU_SOURCE
#include - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
参考:
https://www.jianshu.com/p/7f27c0316355
评论记录:
回复评论: