
AnyAttack: Targeted Adversarial Attacks on Vision-Language Models Toward Any Images

本文 “AnyAttack: Targeted Adversarial Attacks on Vision-Language Models Toward Any Images” 提出了针对视觉语言模型(VLMs)的目标性对抗攻击框架 AnyAttack,该框架利用自监督学习在无标签监督下生成对抗图像,揭示了 VLMs 存在的安全风险,强调了开发防御机制的紧迫性。
速览总结
- 首次将 “预训练-微调” 范式大规模应用到目标性对抗攻击;
- 预训练阶段在大规模数据集上训练解码器来生成对抗噪声,后续可以在下游数据集上进行微调,微调时可以根据不同的任务设置不同的微调任务;
- 预训练阶段提出了K增强操作,把数据集复制K组进行打乱,以增强泛化能力;
摘要-Abstract
Due to their multimodal capabilities, Vision-Language Models (VLMs) have found numerous impactful applications in real-world scenarios. However, recent studies have revealed that VLMs are vulnerable to image-based adversarial attacks, particularly targeted adversarial images that manipulate the model to generate harmful content specified by the adversary. Current attack methods rely on predefined target labels to create targeted adversarial attacks, which limits their scalability and applicability for largescale robustness evaluations. In this paper, we propose AnyAttack, a self-supervised framework that generates targeted adversarial images for VLMs without label supervision, allowing any image to serve as a target for the attack. Our framework employs the “pre-training and fine-tuning” paradigm, with the adversarial noise generator pre-trained on the large-scale LAION-400M dataset. This large-scale pre-training endows our method with powerful transferability across a wide range of VLMs. Extensive experiments on five mainstream open-source VLMs (CLIP, BLIP, BLIP2, InstructBLIP, and MiniGPT-4) across three multimodal tasks (image-text retrieval, multimodal classification, and image captioning) demonstrate the effectiveness of our attack. Additionally, we successfully transfer AnyAttack to multiple commercial VLMs, including Google Gemini, Claude Sonnet, Microsoft Copilot and OpenAI GPT. These results reveal an unprecedented risk to VLMs, highlighting the need for effective countermeasures.
由于视觉语言模型(VLMs)具有多模态能力,它们在现实场景中有着众多具有影响力的应用。然而,最近的研究表明,视觉语言模型容易受到基于图像的对抗攻击,特别是那些旨在操控模型生成攻击者指定的有害内容的目标性对抗图像。目前的攻击方法依赖于预定义的目标标签来构建目标性对抗攻击,这限制了它们在大规模稳健性评估中的可扩展性和适用性。在本文中,我们提出了AnyAttack,这是一种自监督框架,无需标签监督即可为视觉语言模型生成定向对抗图像,使得任何图像都能作为攻击目标。我们的框架采用 “预训练和微调” 范式,其中对抗噪声生成器在大规模LAION-400M数据集上进行预训练。这种大规模预训练赋予了我们的方法强大的跨多种视觉语言模型的迁移能力。在五个主流开源视觉语言模型(CLIP、BLIP、BLIP2、InstructBLIP和MiniGPT-4)上进行的涵盖三个多模态任务(图像文本检索、多模态分类和图像字幕生成)的大量实验,证明了我们攻击方法的有效性。此外,我们成功地将AnyAttack应用于多个商业视觉语言模型,包括谷歌的Gemini、Claude Sonnet、微软的Copilot和OpenAI的GPT。这些结果揭示了视觉语言模型面临的前所未有的风险,凸显了采取应对措施的必要性。
引言-Introduction
这部分内容主要介绍了视觉语言模型(VLMs)的现状、面临的威胁、现有攻击方法的局限性,引出了本文提出的AnyAttack框架,具体内容如下:
- VLMs的发展与隐患:VLMs在多任务中表现卓越,这得益于训练数据规模和模型大小。然而,因其高度依赖视觉输入,易受到基于图像的对抗攻击。其中,目标性对抗攻击尤为危险,能操控模型输出攻击者预设的有害内容,影响内容审核系统,对VLMs在现实场景中的可靠性和安全性构成严重威胁。
- 现有攻击方法的局限:现有针对VLMs的定向攻击方法依赖目标标签进行监督,限制了训练过程的可扩展性。例如,在ImageNet上训练的生成器难以对VLMs产生有效的对抗噪声。
- AnyAttack框架的提出:为解决上述问题,本文提出了AnyAttack,这是一种自监督框架。它以原始图像自身为监督,允许任何图像作为目标性对抗攻击的目标。该框架在大规模LAION-400M数据集上预训练生成器,使其学习到全面的噪声模式,并可在下游数据集上微调以适应不同任务。这是首次将“预训练和微调”范式大规模应用于目标性对抗攻击。
- 研究贡献总结:提出AnyAttack自监督框架,利用原始图像作为监督,让任意图像都能成为攻击目标;首次采用“预训练和微调”范式进行目标性对抗攻击;通过实验证明了AnyAttack在五个主流开源VLMs(包括CLIP, BLIP, BLIP2, InstructBLIP, and MiniGPT-4)和三个多模态任务上的有效性,并成功将攻击迁移到四个商业VLMs(包括Google Gemini, Claude Sonnet, Microsoft Copilot 和 OpenAI GPT)。
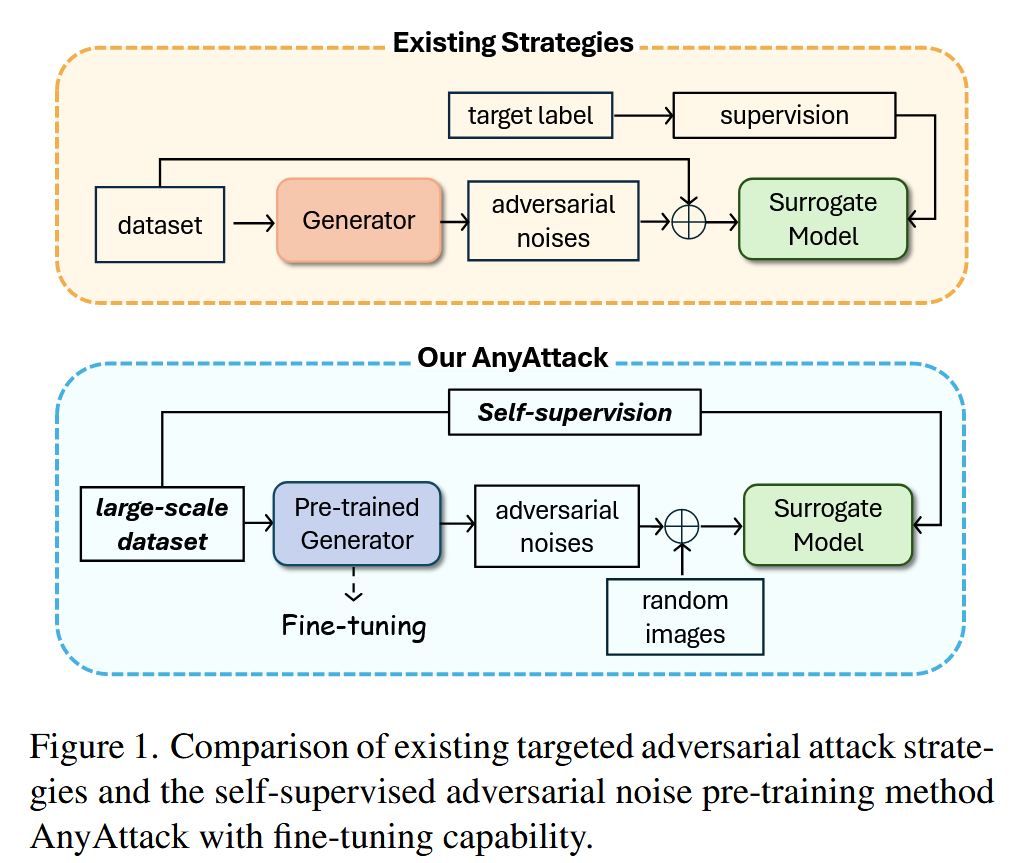
图1. 现有目标性对抗攻击策略与具有微调能力的自监督对抗噪声预训练方法AnyAttack的对比。
相关工作-Related Work
这部分内容主要回顾了与本文研究相关的工作,包括针对视觉模型的目标性对抗攻击、对VLMs的越狱攻击以及对VLMs的对抗攻击,具体内容如下:
- Targeted Adversarial Attacks(目标性对抗攻击):许多研究致力于提高针对视觉模型的目标性对抗攻击的有效性和迁移性。通过输入增强技术(如图像平移、裁剪、混合和调整大小)增加对抗输入的多样性,进而提升跨模型的迁移性;探索对抗微调与模型增强技术,通过混合干净样本和对抗样本重新训练代理模型,增强其攻击能力;利用自适应学习率和梯度裁剪等优化技术,稳定对抗训练中的更新过程,提高对抗攻击的整体性能。
- Jailbreak Attacks on VLMs(对VLMs的越狱攻击):VLMs借助大规模多模态数据集预训练取得发展,主要分为基于大语言模型构建多模态功能和平衡文本与视觉模态两类。针对VLMs的研究发现了越狱攻击和对抗攻击等威胁。多模态越狱攻击利用VLMs的跨模态交互漏洞影响大语言模型,通过操纵文本、图像或两者输入,诱导模型产生有害但非预定义的响应;而基于图像的对抗攻击主要针对VLMs的图像编码器,目的是通过精确的视觉操纵诱导模型产生攻击者指定的预定义响应 。
- Adversarial Attacks on VLMs(对VLMs的对抗攻击):相比视觉模型,对VLMs的对抗研究相对较少,且大多集中于非目标性攻击。如Co-Attack率先对多个VLMs进行白盒非目标性攻击,后续有更多方法致力于提升黑盒非目标性攻击的迁移性。CrossPrompt Attack基于大语言模型的提示探索对抗迁移性的新设置,AttackVLM通过结合文本输入和文本到图像模型生成引导图像来创建目标性对抗图像,与本文方法目标相似,但本文方法是自监督且不依赖文本引导的。
提出的攻击-Proposed Work
预备知识-Preliminaries
这部分内容主要介绍了目标性对抗攻击的相关预备知识,包括威胁模型和问题的数学表述,为后续介绍AnyAttack方法做铺垫,具体内容如下:
- 威胁模型:本文聚焦于基于迁移的黑盒攻击场景。在这种场景下,攻击者利用完全可访问的预训练代理模型 f s f_{s} fs 生成对抗图像 x ′ x' x′. 对于目标VLM f t f_{t} ft,攻击者既不了解其架构和参数,也无法利用其输出重建对抗图像。攻击者的目标是使目标VLM f t f_{t} ft 将对抗图像 x ′ x' x′ 与目标文本描述 y t y_{t} yt 错误匹配。
- 问题表述:设 f s f_{s} fs 为预训练的代理模型, D = ( x , y ) D={(x, y)} D=(x,y) 表示图像数据集,其中 x x x 是原始图像, y y y 是对应的标签(描述)。攻击者的任务是构建一个对抗样本 x ′ = x + δ x'=x+\delta x′=x+δ,使目标模型 f t f_{t} ft 将其误判为预定义的目标标签 y t y_{t} yt。在VLMs的背景下,这要求 x ′ x' x′ 与 y t y_{t} yt 构成有效的图像 - 文本对。通常,生成目标性对抗图像的过程是利用代理模型 f s f_{s} fs 找到合适的扰动 δ \delta δ.
AnyAttack
框架概述-Framework Overview
这部分内容介绍了AnyAttack的整体架构,它通过两个关键阶段来实现对视觉语言模型的目标性对抗攻击,具体内容如下:
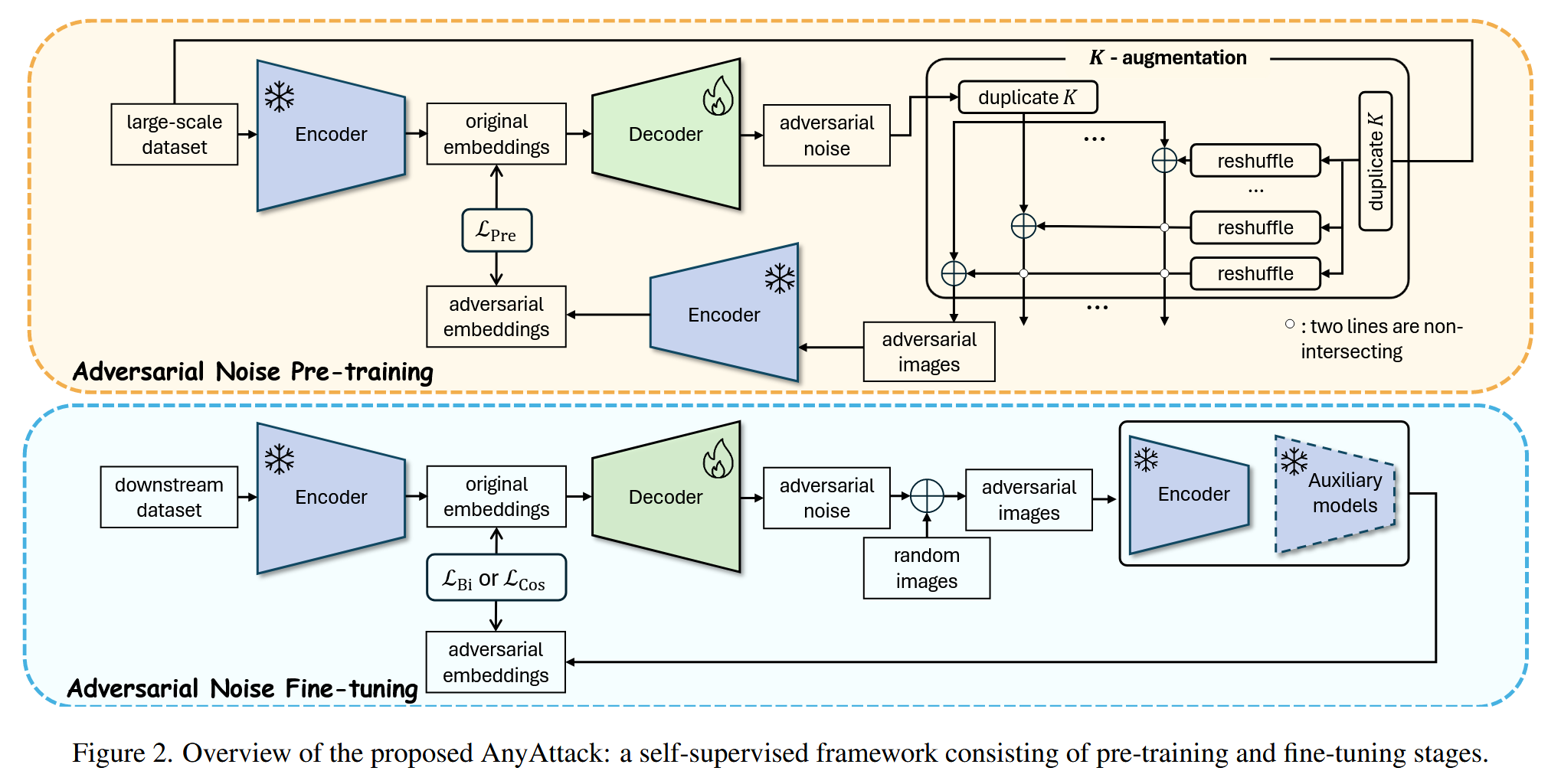
图2. 所提出的AnyAttack框架概述:这是一个由预训练和微调阶段组成的自监督框架。
- 自监督对抗噪声预训练:利用大规模数据集 D p D_{p} Dp 训练解码器 F F F 以生成对抗噪声 δ \delta δ ,将冻结的编码器 E E E 作为代理模型。在训练时,用冻结的图像编码器 E E E 提取一批图像 x x x 的嵌入,将这些归一化嵌入 z z z 输入解码器 F F F,生成与图像 x x x 对应的对抗噪声 δ \delta δ. 为增强模型泛化能力和计算效率,引入 K K K - 增强策略,在每个小批量内对原始图像进行 K K K 次打乱,形成多个不同版本,将对抗噪声添加到这些打乱后的随机图像上得到对抗图像。在这个过程中,定义对抗噪声预训练损失 L P r e L_{Pre} LPre,通过最大化正样本对(每个小批量中对抗嵌入和原始嵌入的第 i i i 个元素)之间的余弦相似度,最小化负样本对(所有其他元素组合)之间的相似度来更新解码器 F F F.
- 自监督对抗噪声微调:将预训练的解码器 F F F 适配到特定的下游数据集 D f D_{f} Df. 从外部数据集 D e D_{e} De 中选取无关的随机图像 x r x_{r} xr ,将其与生成的噪声 δ \delta δ 相加得到对抗图像。根据不同的下游任务,采用不同的微调目标。对于图像 - 文本检索任务,使用双向对比损失 L B i L_{Bi} LBi ,它对相似样本的区分有更严格要求,确保从对抗嵌入 z ( a d v ) z^{(adv)} z(adv) 到原始嵌入 z z z 以及从 z z z 到 z ( a d v ) z^{(adv)} z(adv) 的双向检索性能都较为稳健;对于图像字幕、多模态分类等一般的视觉 - 语言任务,使用余弦相似度 L C o s L_{Cos} LCos,使得对抗嵌入 z ( a d v ) z^{(adv)} z(adv) 与原始嵌入 z z z 相匹配,从而使模型更好地适应特定领域和多模态任务。
自监督对抗噪声预训练-Self-supervised Adversarial Noise Pre-training
这部分主要介绍了AnyAttack框架中的自监督对抗噪声预训练过程,通过在大规模数据集上训练解码器生成对抗噪声,具体内容如下:
- 训练目标:在无目标标签或目标图像监督的情况下,在大规模数据集上训练生成器,使其能处理各种输入图像作为潜在攻击目标。目标函数为 m i n L ( f s ( δ + x r ) , f s ( x ) ) , s . t . x r ≠ x min \ \mathcal{L}\left(f_{s}\left(\delta+x_{r}\right), f_{s}(x)\right),\ s.t.\ \ x_{r} \neq x min L(fs(δ+xr),fs(x)), s.t. xr=x,其中 x r x_{r} xr 是与 x x x 无关的随机图像,对抗噪声 δ \delta δ 旨在使 x r + δ x_{r}+\delta xr+δ 在代理模型的嵌入空间中与原始图像 x x x 对齐。
- 模型与数据处理:从大规模训练数据集 D p D_{p} Dp 中取一批 n n n 张图像 x ∈ R n × H × W × 3 x \in \mathbb{R}^{n ×H ×W ×3} x∈Rn×H×W×3,使用冻结的CLIP ViT-B/32图像编码器作为编码器 E E E,得到对应原始图像的归一化嵌入 E ( x ) = z ∈ R n × d E(x)=z \in \mathbb{R}^{n ×d} E(x)=z∈Rn×d( d = 512 d = 512 d=512)。初始化解码器 F F F,将嵌入 z z z 映射为对应原始图像 x x x 的对抗噪声 D ( z ) = δ ∈ R n × H × W × 3 D(z)=\delta \in \mathbb{R}^{n ×H ×W ×3} D(z)=δ∈Rn×H×W×3,期望生成的噪声 δ \delta δ 添加到随机图像 x r x_{r} xr 后,能被编码器 E E E 解释为原始图像 x x x,即 E ( x r + δ ) = E ( x ) E(x_{r}+\delta)=E(x) E(xr+δ)=E(x).
- K - 增强策略:为增加每个批次内随机图像的数量,提出K - 增强策略。将对抗噪声 δ \delta δ 和原始图像 x x x 都复制 K K K 次,形成 K K K 个小批量。每个小批量中对抗噪声顺序不变,原始图像顺序打乱得到打乱图像,将打乱图像与对应对抗噪声相加得到对抗图像。这些对抗图像输入解码器 F F F 产生对抗嵌入 z ( a d v ) z^{(adv)} z(adv),用于后续与原始嵌入 z z z 的计算。
- 预训练损失:引入对抗噪声预训练损失 L P r e L_{Pre } LPre,通过最大化每个小批量中对抗嵌入和原始嵌入的第 i i i 个元素(正样本对)的余弦相似度,最小化其他元素组合(负样本对)的相似度来实现。每个小批量中有 n n n 个正样本对和 n ( n − 1 ) n(n - 1) n(n−1) 个负样本对,累积梯度以更新 F F F. L P r e L_{Pre } LPre 公式为 L P r e = − 1 n ∑ i = 1 n l o g e x p ( z i ⋅ z i ( a d v ) / τ ( t ) ) ∑ j = 1 n e x p ( z i ⋅ z j ( a d v ) / τ ( t ) ) \mathcal{L}_{Pre }=-\frac{1}{n} \sum_{i=1}^{n} log \frac{exp \left(z_{i} \cdot z_{i}^{(a d v)} / \tau(t)\right)}{\sum_{j=1}^{n} exp \left(z_{i} \cdot z_{j}^{(a d v)} / \tau(t)\right)} LPre=−n1∑i=1nlog∑j=1nexp(zi⋅zj(adv)/τ(t))exp(zi⋅zi(adv)/τ(t)),其中 τ ( t ) \tau(t) τ(t) 是训练步长 t t t 时的温度参数,初始设为较大值 τ 0 \tau_{0} τ0,随训练逐步减小到 τ f i n a l \tau_{final } τfinal,计算公式为 τ ( t ) = τ 0 ( τ f i n a l τ 0 ) t T = τ 0 e x p ( − λ t ) \tau(t)=\tau_{0}\left(\frac{\tau_{final }}{\tau_{0}}\right)^{\frac{t}{T}}=\tau_{0} exp (-\lambda t) τ(t)=τ0(τ0τfinal)Tt=τ0exp(−λt).
自监督对抗噪声微调-Self-supervised Adversarial Noise Fine-tuning
这部分内容主要介绍了AnyAttack框架中的自监督对抗噪声微调阶段,包括对预训练解码器的调整和不同任务下的微调目标设定,具体如下:
- 微调目的:利用特定任务的目标函数,在下游视觉语言数据集上对预训练的解码器 F F F 进行优化,使模型能够更好地适应特定领域和多模态任务。
- 微调过程:从下游数据集 D f D_f Df 中获取一批图像 x x x,保持编码器 E E E 冻结,将其输出的嵌入 z z z 输入解码器 F F F 生成噪声 δ \delta δ. 由于 D f D_f Df 规模小于预训练数据集 D p D_p Dp,从外部数据集 D e D_e De 中随机选择图像作为随机图像 x r x_r xr,与生成的噪声 δ \delta δ相加得到对抗图像。同时,引入辅助模型与编码器E形成集成代理,以提高对抗图像的迁移性。
- 微调目标
- 图像 - 文本检索任务:采用双向对比损失 L B i L_{Bi} LBi,该任务对相似样本的区分要求更严格,需要在从对抗嵌入 z ( a d v ) z^{(adv)} z(adv) 到原始嵌入 z z z 以及从 z z z 到 z ( a d v ) z^{(adv)} z(adv) 的双向检索中都具备强大性能。 L B i L_{Bi} LBi 的计算公式为 L B i = 1 2 n ∑ i = 1 n ( − l o g e x p ( z i ⋅ z i ( a d v ) / τ ) ∑ j = 1 n e x p ( z i ⋅ z j ( a d v ) / τ ) − l o g e x p ( z i ( a d v ) ⋅ z i / τ ) ∑ j = 1 n e x p ( z i ( a d v ) ⋅ z j / τ ) ) \mathcal{L}_{Bi}=\frac{1}{2n} \sum_{i=1}^{n}(-log \frac{exp \left(z_{i} \cdot z_{i}^{(adv)} / \tau\right)}{\sum_{j=1}^{n} exp \left(z_{i} \cdot z_{j}^{(adv)} / \tau\right)}-log \frac{exp \left(z_{i}^{(adv)} \cdot z_{i} / \tau\right)}{\sum_{j=1}^{n} exp \left(z_{i}^{(adv)} \cdot z_{j} / \tau\right)}) LBi=2n1∑i=1n(−log∑j=1nexp(zi⋅zj(adv)/τ)exp(zi⋅zi(adv)/τ)−log∑j=1nexp(zi(adv)⋅zj/τ)exp(zi(adv)⋅zi/τ)).
- 一般任务:对于图像字幕、多模态分类等一般视觉语言应用,使用余弦相似度 L C o s L_{Cos} LCos,要求对抗嵌入 z i ( a d v ) z_{i}^{(adv)} zi(adv) 与原始嵌入 z i z_{i} zi 相匹配,通过该目标使模型在这些任务中表现更优。
实验-Experiments
实验设置-Experimental Setup
这部分内容主要介绍了实验的设置,包括基线方法、数据集、模型、任务、评估指标以及实现细节,具体如下:
- 基线方法:选用了当前最先进的针对VLMs的定向对抗攻击方法AttackVLM,其包含基于不同攻击目标的AttackVLM-ii和AttackVLM-it两种变体,且与本文方法一样使用CLIP ViT-B/32图像编码器作为代理模型。还纳入了为视觉分类模型设计的SU和SASD-WS两种定向对抗攻击方法,并将其原始的交叉熵损失修改为余弦损失和均方误差(MSE)损失以适配视觉语言任务,分别记为SU-Cos/SASD-WS-Cos和SU-MSE/SASD-WS-MSE。本文提出的方法则根据不同的微调设置,记为AnyAttack-Cos、AnyAttack-Bi、AnyAttack-Cos w/ Aux和AnyAttack-Bi w/ Aux。
- 数据集、模型和任务:使用MSCOCO、Flickr30K和SNLI-VE数据集进行实验。目标模型涵盖CLIP、BLIP、BLIP2、InstructBLIP和MiniGPT-4等多种VLMs。聚焦的下游任务包括图像文本检索、多模态分类和图像字幕生成,每个任务选取1000张图像。同时,按照相关方法,使用ImageNet-1K验证集中的1000张图像作为干净(随机)图像来生成对抗示例。
- 评估指标:主要使用攻击成功率(ASR)评估目标性对抗攻击的性能。不过,在不同任务中ASR的计算方式稍有差异,例如在图像文本检索任务中,ASR是对抗图像与对应真实文本描述之间的召回率;在多模态分类任务中,ASR指正确分类“对抗图像和真实描述”对的准确率。
- 实现细节:研究受 ℓ ∞ \ell_{\infty} ℓ∞ 范数约束的扰动,确保 ∥ δ ∥ ∞ ≤ 165 \|\delta\|_{\infty} \leq 165 ∥δ∥∞≤165. 在LAION-400M数据集上对解码器进行520,000步的预训练,使用3个NVIDIA A100 80GB GPU,每个GPU的批量大小为600。优化器采用AdamW,初始学习率为 1 × 1 0 − 4 1 ×10^{-4} 1×10−4,并使用余弦退火调整学习率。在下游数据集上,使用相同的优化器、初始学习率和余弦退火调度对解码器进行20轮微调。部署了两个辅助模型,分别是在ImageNet-1K上从头训练的ViT-B/16和ViT-L/14 EVA模型。设置因子 K K K 为5,在预训练阶段,初始温度 τ 0 \tau_{0} τ0 设为1,最终温度 τ f i n a l \tau_{final} τfinal 设为0.07,总步数 T T T 设为10,000。更多细节在附录中给出。
在图文检索任务上的评估-Evaluation on Image-Text Retrieval
这部分主要在图像文本检索任务上对比评估了AnyAttack与基线方法的性能,通过分析MSCOCO和Flickr30K数据集上的实验结果,验证了AnyAttack的有效性,具体内容如下:
-
实验对比:在图像文本检索任务中,将AnyAttack方法与多个基线方法进行对比,在MSCOCO数据集上开展实验,结果在表1中呈现,Flickr30K数据集的详细结果在附录中给出。
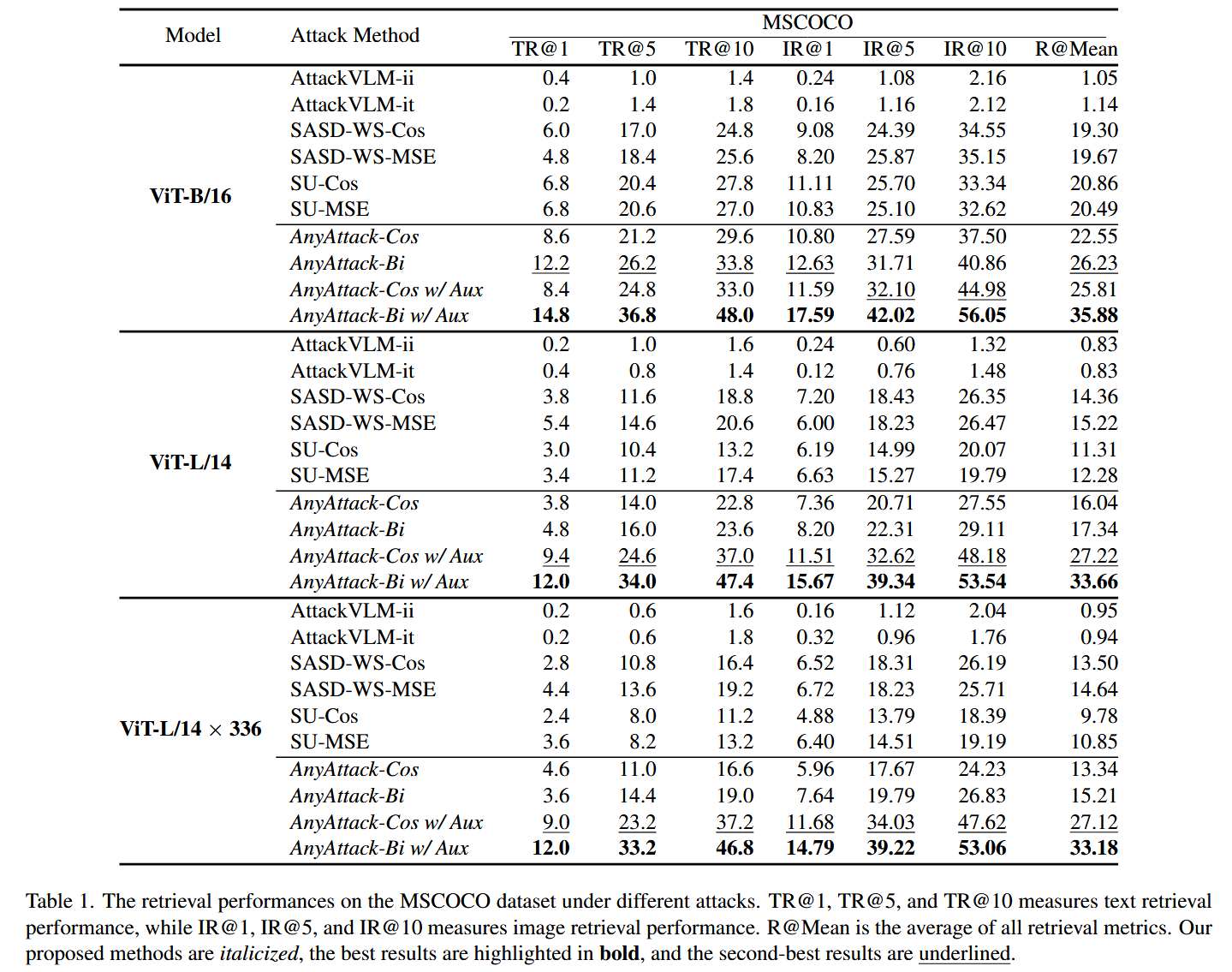
表1. 在不同攻击下,MSCOCO数据集上的检索性能。TR@1、TR@5和TR@10衡量文本检索性能,而IR@1、IR@5和IR@10衡量图像检索性能。R@Mean是所有检索指标的平均值。我们提出的方法用斜体表示,最佳结果用粗体突出显示,第二好的结果用下划线标出。 -
结果分析
- AnyAttack - Bi w/ Auxiliary的优势:该变体在不同模型上均取得了显著优于所有基线的成绩。在ViT - B/16、ViT - B/32和ViT - L/14模型上,其性能分别比表现最佳的基线高出15.02%、18.44%和18.54% ,突出了AnyAttack方法的有效性。
- 辅助模块的作用:对比有无辅助模块的AnyAttack方法发现,辅助模块显著提升了性能。在ViT - B/16、ViT - B/32和ViT - L/14模型上,带辅助模块的AnyAttack相较于不带辅助模块的版本,性能分别提升了6.455%、13.75%和15.875% ,表明辅助模块在增强攻击转移性方面效果显著。
- 双向损失的优势:双向对比损失 L B i L_{Bi} LBi 在检索任务中优势明显,使用 L B i L_{Bi} LBi 的AnyAttack - Bi始终比使用余弦相似度损失 L C o s L_{Cos} LCos 的AnyAttack - Cos表现更优,说明双向对比损失在改善图像和文本嵌入对齐方面更有效。
在多模态分类任务上评估-Evaluation on Multimodal Classification
这部分内容在多模态分类任务上对AnyAttack和基线方法的性能进行了对比评估,验证了AnyAttack在该任务上的有效性,具体如下:
- 对比实验:在多模态分类任务上,将AnyAttack攻击方法与基线方法进行性能比较,实验选用SNLI-VE数据集。
- 结果分析:实验结果显示,AnyAttack-Cos w/ Auxiliary方法在多模态分类任务中表现最佳,其性能超过最强基线SASD-WS-MSE达20.0%。这一结果充分证明了AnyAttack在多模态分类任务方面具有显著的攻击效果,突出了该方法在此类任务中的有效性和优势。
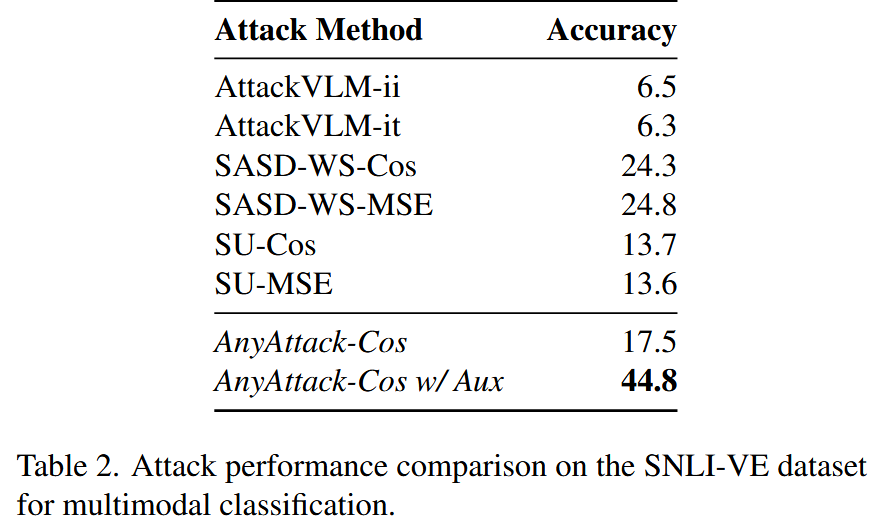
表2. 在SNLI-VE数据集上针对多模态分类的攻击性能对比。
在图像描述任务上评估-Evaluation on Image Captioning
这部分主要在图像描述任务上评估了AnyAttack的性能,通过与基线方法对比,展现了AnyAttack在此任务上的优势,具体内容如下:
- 评估任务与数据集:利用MSCOCO数据集,在图像描述任务上对AnyAttack的攻击性能进行评估。在此任务中,视觉语言模型以对抗图像作为输入,生成文本描述,然后将这些描述与真实的图像字幕进行对比,使用标准指标来评估生成描述的质量。
- 评估模型与指标:对InstructBLIP、BLIP2、BLIP和MiniGPT-4这四个视觉语言模型进行测试,评估指标包括SPICE、BLEU-1、BLEU-4、METEOR、ROUGE-L和CIDEr等。
- 结果与分析:实验结果表明,在所有评估指标上,本文提出的AnyAttack-Cos w/ Auxiliary攻击方法在各个视觉语言模型上均展现出优于基线攻击方法的性能,证明了该方法在图像字幕生成任务中的有效性和优越性。
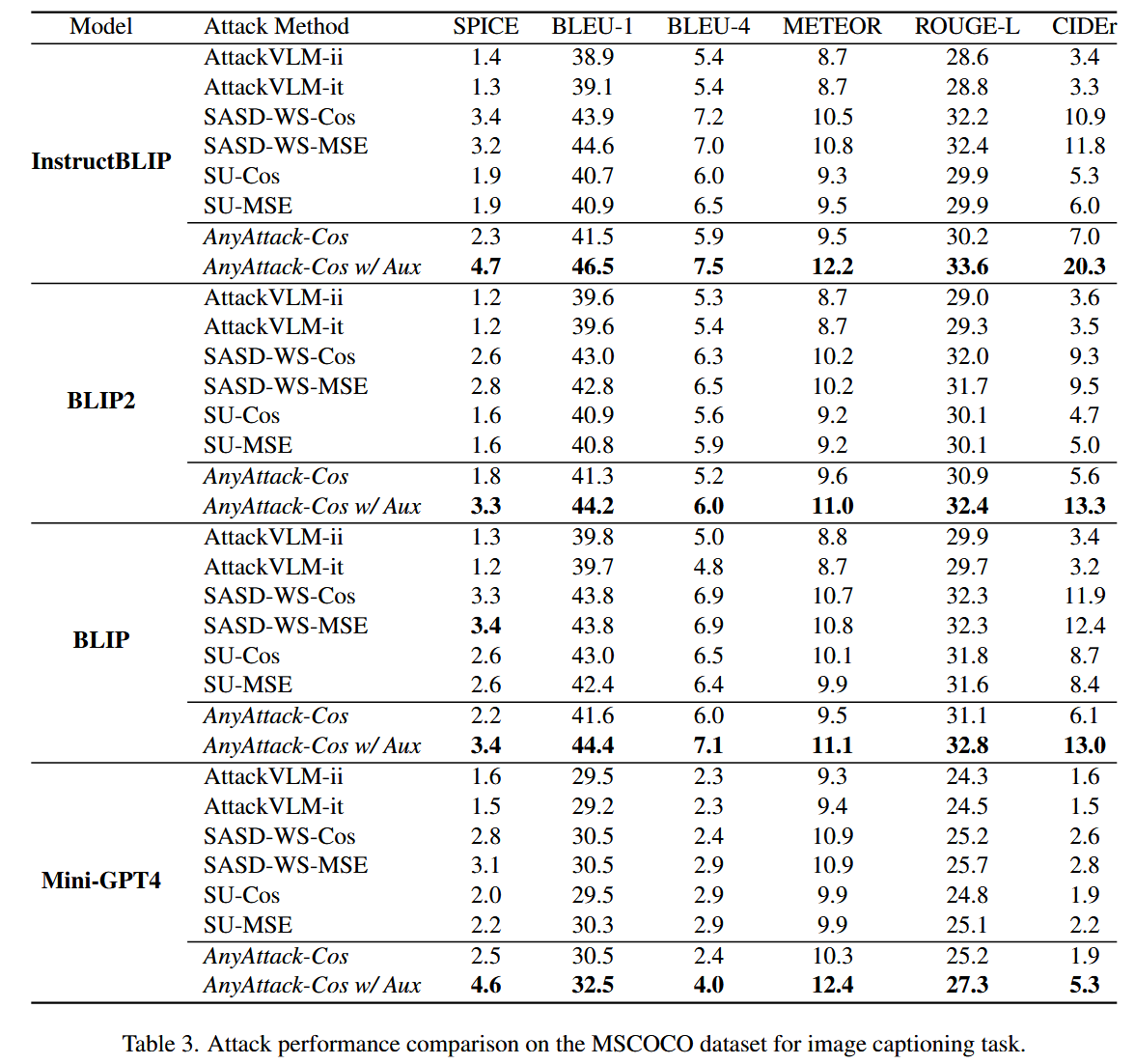
表3. 在MSCOCO数据集上针对图像字幕生成任务的攻击性能对比。
迁移到商业VLMs-Transfer to Commercial VLMs
这部分主要研究了AnyAttack生成的对抗图像对商业视觉语言模型(VLMs)的迁移性,通过定量和定性分析,验证了其在商业模型上的攻击效果,具体如下:
- 研究目的:评估由AnyAttack方法生成的对抗图像对商业VLMs(如Google Gemini、Claude Sonnet、OpenAI GPT和Microsoft Copilot )的迁移性。
- 定量分析:从MSCOCO数据集选取100张图像作为目标图像,对比AnyAttack与基线方法。使用“Evaluate the relationship between the given image and text”提示及相应选项,统计商业VLMs将响应标记为“relevant”的百分比。结果显示,AnyAttack在所有评估的商业VLMs上均优于基线方法,实现了显著的性能提升。
- 定性分析:将对抗图像上传到商业VLMs的公开网络界面进行定性验证。文中图3展示了代表性示例,图像中红色突出显示的部分对应目标图像,直观地展示了AnyAttack对商业VLMs的攻击效果,进一步证明了该方法的有效性。
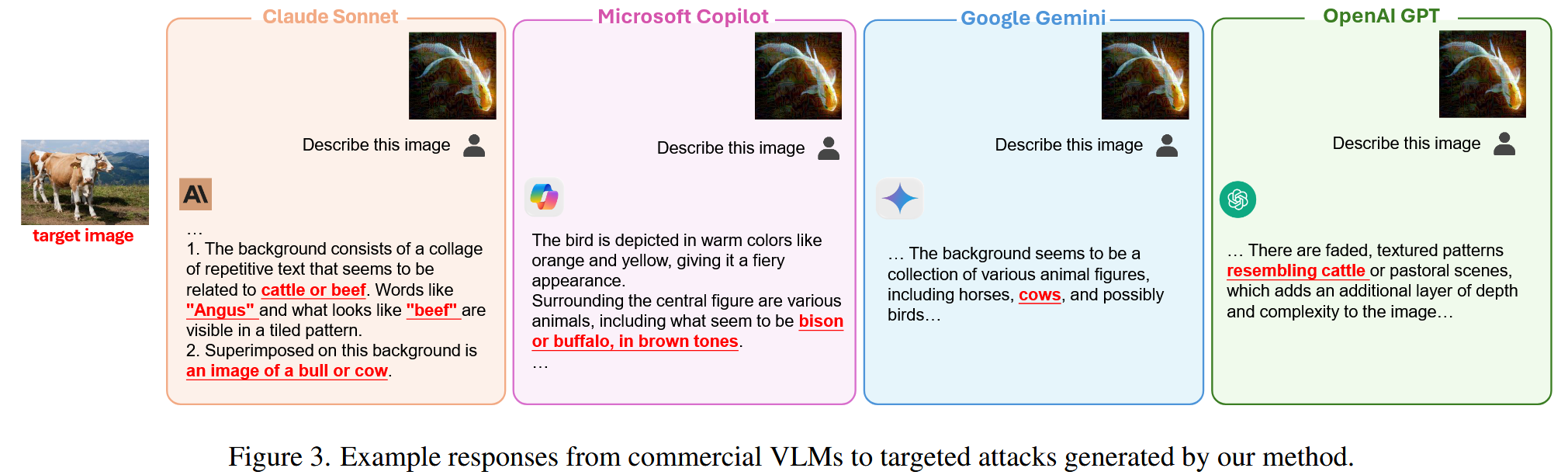
图3. 商业视觉语言模型对我们的方法所生成的定向攻击的示例响应。
深入分析-Further Analysis
这部分主要从消融研究和效率分析两方面,对AnyAttack方法进行了更深入探究,为理解其性能和优势提供了依据,具体内容如下:
- 消融研究:在MSCOCO数据集的图像文本检索任务上,对AnyAttack的三个关键组件进行消融研究,分析其对攻击性能的影响。
- 训练方式:对比预训练、微调以及从头开始训练三种方式,发现微调预训练模型的性能最高,从头开始训练的效果明显较差,这表明预训练对于模型适应任务至关重要。
- 辅助模型:研究有无辅助模型的情况,结果显示包含辅助模型能持续提升性能,突出了辅助模型在增强模型转移性方面的重要作用。
- 微调目标:比较余弦相似度损失
L
C
o
s
L_{Cos}
LCos 和双向对比损失
L
B
i
L_{Bi}
LBi,发现
L
B
i
L_{Bi}
LBi 始终优于
L
C
o
s
L_{Cos}
LCos,说明
L
B
i
L_{Bi}
LBi 在改善图像和文本嵌入对齐上更有效。
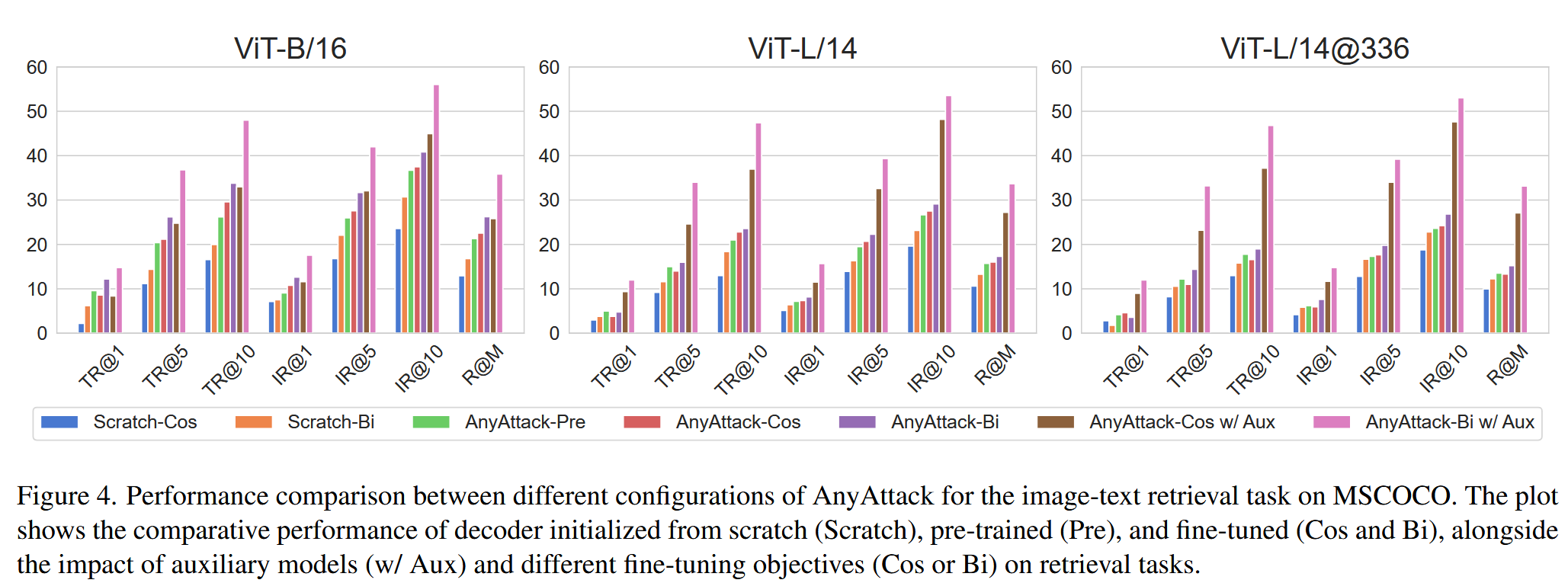
图4. 在MSCOCO数据集上,针对图像文本检索任务的AnyAttack不同配置的性能对比。该图展示了从头初始化(Scratch)、预训练(Pre)和微调(Cos和Bi)的解码器的性能,以及辅助模型(w/ Aux)和不同微调目标(Cos或Bi)对任务的影响。
- 效率分析:将AnyAttack与SU、SASD和AttackVLM的效率进行对比。在单个NVIDIA A100 80GB GPU上,以批量大小250生成1000个对抗图像,结果表明AnyAttack在计算速度和内存效率上均显著优于基线方法。
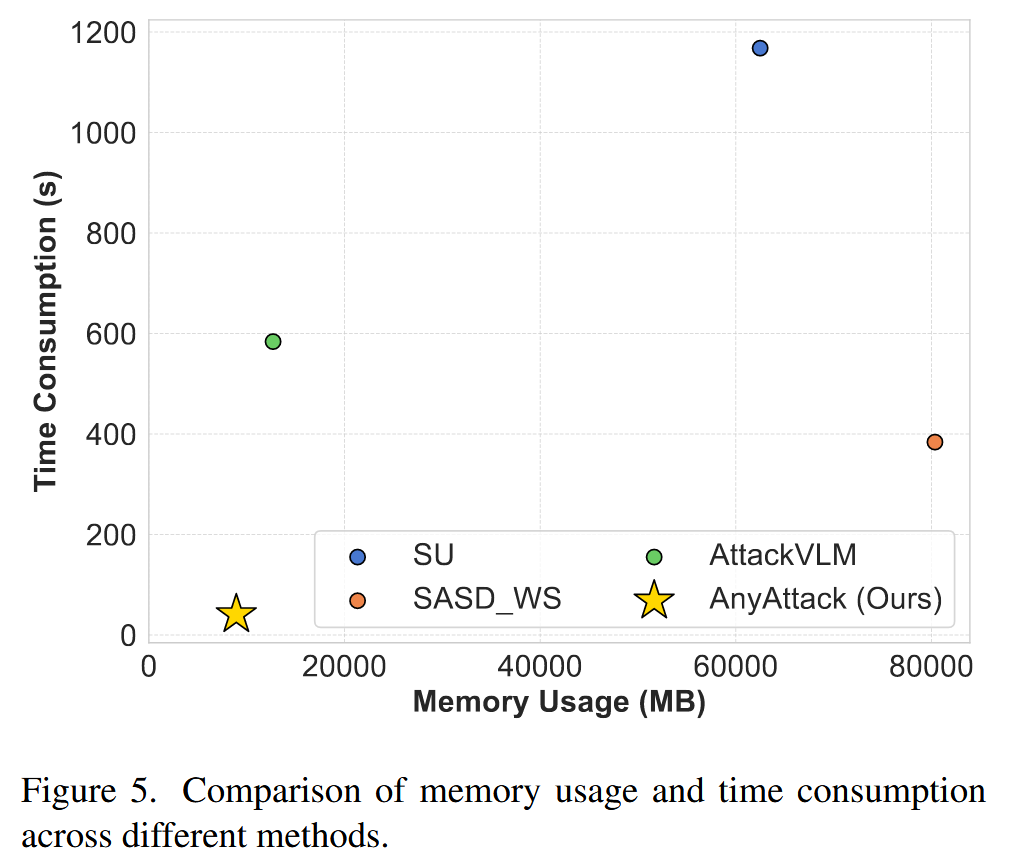
图5. 不同方法的内存使用和时间消耗对比。
结论-Conclusion
这部分内容总结了文章的核心研究成果,阐述了方法的优势、局限性以及未来的研究方向,具体如下:
- 研究成果总结:提出了一种名为AnyAttack的自监督框架,用于对视觉语言模型(VLMs)进行定向对抗攻击。该框架包含自监督对抗噪声预训练和自监督对抗噪声微调两个阶段,能有效提升对VLMs的攻击性能。
- 方法优势阐述:在多个视觉语言任务(如图像文本检索、多模态分类、图像字幕生成)和不同的VLMs(如CLIP、BLIP、BLIP2、InstructBLIP、MiniGPT-4等)上进行实验,结果表明AnyAttack在攻击成功率(ASR)等指标上显著优于当前最先进的基线方法。同时,在计算速度和内存效率方面,AnyAttack也比基线方法更具优势。
- 研究局限性:尽管AnyAttack表现出色,但也存在局限性,即它需要对每个目标模型进行微调,这在处理大量模型时可能会带来一定的计算负担和时间成本。
- 未来研究方向:未来计划探索如何将AnyAttack扩展到其他模态(如音频、视频),以进一步增强其在多模态领域的应用能力。同时,也会研究如何减少微调的计算成本,提升方法的效率和实用性。
评论记录:
回复评论: