
目录
一、环境变量
1、补充:命令行参数
main函数其实是有三个参数的,分别是argc和argv[]和env[]!argv其实就是一个指针数组,argc表示argv数组元素的个数。
- // code.c
- #include
-
- // main函数有参数吗?
- int main(int argc, char *argv[])
- {
- for(int i = 0; i < argc; i++)
- printf("argv[%d]:%s\n", i, argv[i]);
- return 0;
- }
- // 运行结果
- $ ./code a b c
- argv[0]:./code
- argv[1]:a
- argv[2]:b
- argv[3]:c

main函数的命令行参数就是通过不同的选项实现不同的子功能的方法(指令选项的原理)。我们来模拟一下:
- #include
- #include
-
- int main(int argc, char *argv[])
- {
- if(argc != 2)
- {
- printf("Usage: %s[-a|-b|-c]\n", argv[0]);
- return 1;
- }
- const char *arg = argv[1];
-
- if(strcmp(arg, "-a") == 0)
- printf("这是功能1\n");
- else if(strcmp(arg, "-b")==0)
- printf("这是功能2\n");
- else if(strcmp(arg, "-c")==0)
- printf("这是功能3\n");
- else
- printf("Usage: %s[-a|-b|-c]\n", argv[0]);
-
- return 0;
- }
- $ make
- gcc -o code code.c -std=c99
- $ ./code
- Usage: ./code[-a|-b|-c]
- $ ./code -a
- 这是功能1
- $ ./code -b
- 这是功能2
- $ ./code -c
- 这是功能3
结论:进程拥有一张argv表,用来支持实现选项功能。
2、环境变量基本概念
• 环境变量(environment variables)一般是指在操作系统中用来指定操作系统运行环境的一些参数
• 如:我们在编写C/C++代码的时候,在链接的时候,从来不知道我们的所链接的动态静态库在哪里,但是照样可以链接成功,生成可执行程序,原因就是有相关环境变量帮助编译器进行查找。
• 环境变量通常具有某些特殊用途,还有在系统当中通常具有全局特性。
3、查看常见环境变量
echo $环境变量名称,打印出来的路径由【:】分隔开
- zyt@iZ2vcf9wvlgcetfeub9f11Z:~/linux-journey-log/code_25_3_31$ echo $PATH
- /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin
(1)PATH
PATH:指定命令的搜索路径
为什么一些指令可以不带路径执行?而我们的二进制程序却要带路径?
· 因为这些命令的二进制文件位于 PATH 包含的目录中,Shell 会自动在 PATH 中搜索它们,所以无需输入完整路径。例如:ls → /bin/ls
· 自定义程序通常不在 PATH 包含的目录中,例如:程序 my_program,放在 /home/user/projects/ 下,但 PATH 不包含这个目录,所以 Shell 找不到它。
如何让自定义程序像系统命令一样直接运行?
方法1:临时添加到
PATH(仅当前终端有效)
方法2:永久添加到
PATH(修改 Shell 配置文件)在
~/.bashrc或~/.bash_profile中添加:export PATH="$PATH:/home/user/projects"然后重新加载配置:
source ~/.bashrc方法3:将程序复制到系统
PATH目录(需要管理员权限)sudo cp my_program /usr/local/bin/ # 现在可以直接运行 my_program
(2)HOME
HOME:指定用户的主工作目录(用户登录到Linux系统中时,默认的目录)
① 用root用户和普通用户同时执行【echo $HOME】对比实验结果:HOME由系统自动设置,指向当前用户的家目录。root 可以访问所有目录(包括 /home/用户名),但普通用户无法访问 /root(权限不足时会报错)。
- root@iZ2vcf9wvlgcetfeub9f11Z:~# echo $HOME
- /root
- root@iZ2vcf9wvlgcetfeub9f11Z:~# su zyt
- zyt@iZ2vcf9wvlgcetfeub9f11Z:/root$ echo $HOME
- /home/zyt
② ~与HOME关系:~ 和 $HOME 环境变量都代表当前用户的家目录,但它们的使用方式和上下文有所不同。~ 是 Shell 提供的快捷方式,在命令解析阶段被替换。$HOME 是一个环境变量,存储家目录的实际路径。下面实验:两种写法等效。
- zyt@iZ2vcf9wvlgcetfeub9f11Z:~$ cd ~ # 切换到当前用户的家目录(~ 被替换为 $HOME 的值)
- zyt@iZ2vcf9wvlgcetfeub9f11Z:~$ pwd # 打印当前工作目录(此时是家目录)
- /home/zyt
- zyt@iZ2vcf9wvlgcetfeub9f11Z:~$ cd "$HOME" # 明确使用环境变量
- zyt@iZ2vcf9wvlgcetfeub9f11Z:~$ pwd
- /home/zyt
(3)PWD
PWD:用于存储当前工作目录(Current Working Directory)的绝对路径。
(4)HISTSIZE
HISTSIZE:用于控制 命令历史记录(history) 中保存的最大命令数量。
- zyt@iZ2vcf9wvlgcetfeub9f11Z:~$ echo $HISTSIZE
- 1000
(5)SHELL
SHELL:当前Shell,他的值通常是/bin/bash
4、思考
如何理解环境变量(存储的角度)?
bash内部形成一个环境变量表(指针数组),每个指针指向一个形如
KEY=value的字符串!当我们在命令行输入字符串,会被bash拿到,构建出命令行参数表并解析指令,在表中找到对应功能,然后再环境变量表中找到PATH,再由bash根据【PATH的每一个路径+程序名】,在系统当中查找该命令是否存在?如果存在就创建子进程,并通过execve()执行该程序,同时将环境变量表传递给子进程。如果不存在就返回command not found。=》bash进程上下文里有两张表。
如果Linux系统有10个用户登录,那么就存在10个bash,每个bash都有两张表。
环境变量最开始是从哪里来的?
系统的相关配置文件中来【~/.bashrc】【~/.bash_profile】
5、环境变量相关的命令
1. echo: 显示某个环境变量值
2. export: 设置一个新的环境变量
3. env: 显示所有环境变量
4. unset: 清除环境变量
5. set: 显示本地定义的shell变量和环境变量
6、环境变量组织方式
每个程序都会收到一张环境表,环境表是一个字符指针数组,每一个指针指向一个以‘\0’结尾的环境字符串。
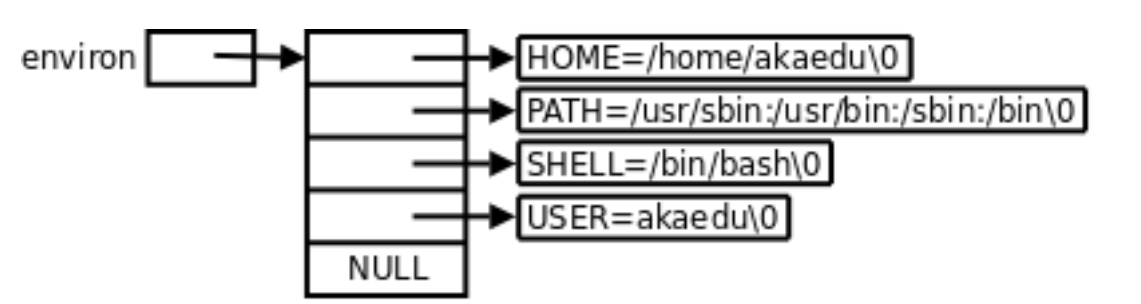
7、获取环境变量
(1)通过main函数命令行的第三个参数。(代码获取)
- #include
- #include
-
- int main(int argc, char *argv[], char *env[])
- {
- (void)argc;
- (void)argv;
-
- for(int i = 0; env[i]; i++)
- {
- printf("env[%d]-> %s\n", i, env[i]);
- }
- return 0;
- }
结果: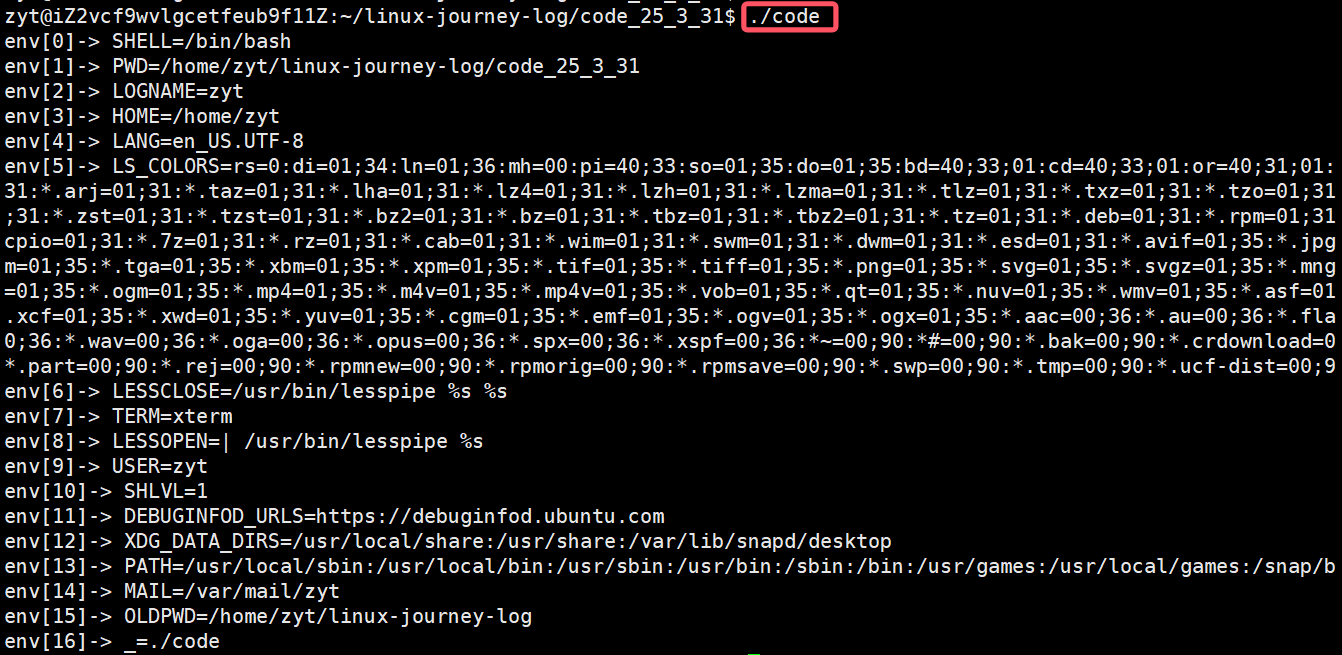
补充实验:环境变量表是可以被子进程继承的,所以说环境变量在系统中具有全局特性。
当我们调用export添加新进程MYENV1,MYENV2,MYENV3后执行程序【./code】(bash的子进程)也会显示出MYENV1,MYENV2,MYENV3。
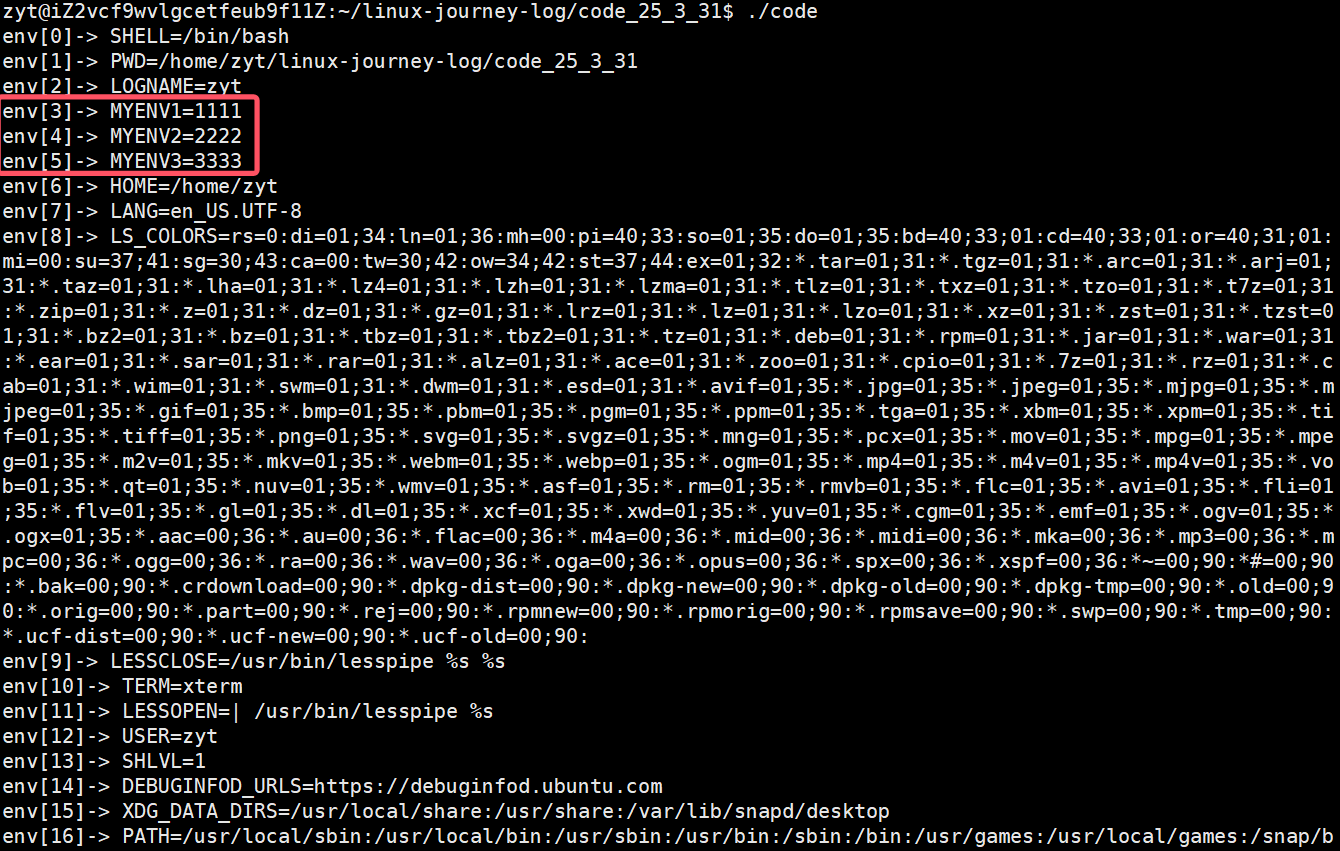
(2)通过第三方变量environ
environ 是一个全局变量(extern char **environ),它直接指向进程的环境变量表。environ没有被包含在任何头文件里,所以使用时要用extern声明。
- #include
- #include
-
- extern char **environ; // 声明环境变量表指针
- #include
- #include
- #include
- #include
-
- extern char **environ; // 定义在C标准库里,此处只是声明
-
- int main(int argc, char *argv[])
- {
- (void)argc;
- (void)argv;
-
- for(int i = 0; environ[i]; i++)
- {
- printf("environ[%d]-> %s\n", i, environ[i]);
- }
- return 0;
- }
(3)getenv()/setenv()函数
① getenv():根据变量名查找环境变量,返回对应的值,如果变量不存在,返回 NULL。
- #include
- char *getenv(const char *name);
底层实现:
内部通过访问 environ 全局变量(char **environ)搜索环境变量。
不涉及系统调用,直接读取进程内存中的环境变量表。
- #include
- #include
- #include
- int main(int argc, char *argv[], char *env[])
- {
- (void)argc;
- (void)argv;
- (void)env;
-
- char *value = getenv("PATH");
- if(value == NULL) return 1;
-
- printf("PATH->%s\n", value);
- return 0;
- }
结果:
- zyt@iZ2vcf9wvlgcetfeub9f11Z:~/linux-journey-log/code_25_3_31$ ./code
- PATH->/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin
② setenv():设置环境变量
参数:name:变量名;value:变量值;
overwrite:非零时覆盖已有变量,零时保留原值(不修改)。
返回值
成功返回 0,失败返回 -1(如内存不足)。
- #include
- int setenv(const char *name, const char *value, int overwrite);
底层实现:
在堆(heap)中分配新内存,构建 name=value 字符串。
更新 environ 全局变量(可能重新分配内存)。
不直接调用系统调用,但修改的环境变量会传递给子进程(通过 fork() + exec())
- if (setenv("MY_VAR", "hello", 1) == 0) {
- printf("MY_VAR set to: %s\n", getenv("MY_VAR"));
- }
③ 应用:设计一个唯我使用的程序
前面我们得出了结论:环境变量表是可以被子进程继承的。那可以通过子进程的环境变量表对用户进行身份识别。
- #include
- #include
- #include
- int main(int argc, char *argv[], char *env[])
- {
- (void)argc;
- (void)argv;
- (void)env;
-
- char *name = getenv("USER");
- if(name == NULL) return 0;
- if(strcmp(name, "zyt")==0)
- {
- printf("这是程序的正常逻辑!USER: %s\n", name);
- }
- else
- {
- printf("Only zyt!\n");
- }
- return 0;
- }

8、理解环境变量的特性
(1)环境变量具有全局特性,可以被子进程继承下去。
(2)bash会记录两套变量:环境变量和本地变量(用set命令查看)
但是本地变量不会被子进程继承,只能在shell内部被使用。
- zyt@iZ2vcf9wvlgcetfeub9f11Z:~/linux-journey-log/code_25_3_31$ i=10 # 本地变量
- zyt@iZ2vcf9wvlgcetfeub9f11Z:~/linux-journey-log/code_25_3_31$ echo $i
- 10
(3)环境变量是在bash进程的上下文里,那我们执行export命令不就是子进程给父进程添加环境变量了?这不就违反了进程具有独立性的原则?
调用export命令是内键命令,执行时不需要创建子进程,是bash直接调用或者系统调用完成的!
二、进程地址空间(虚拟地址空间)
1、C程序的存储空间布局(回顾)
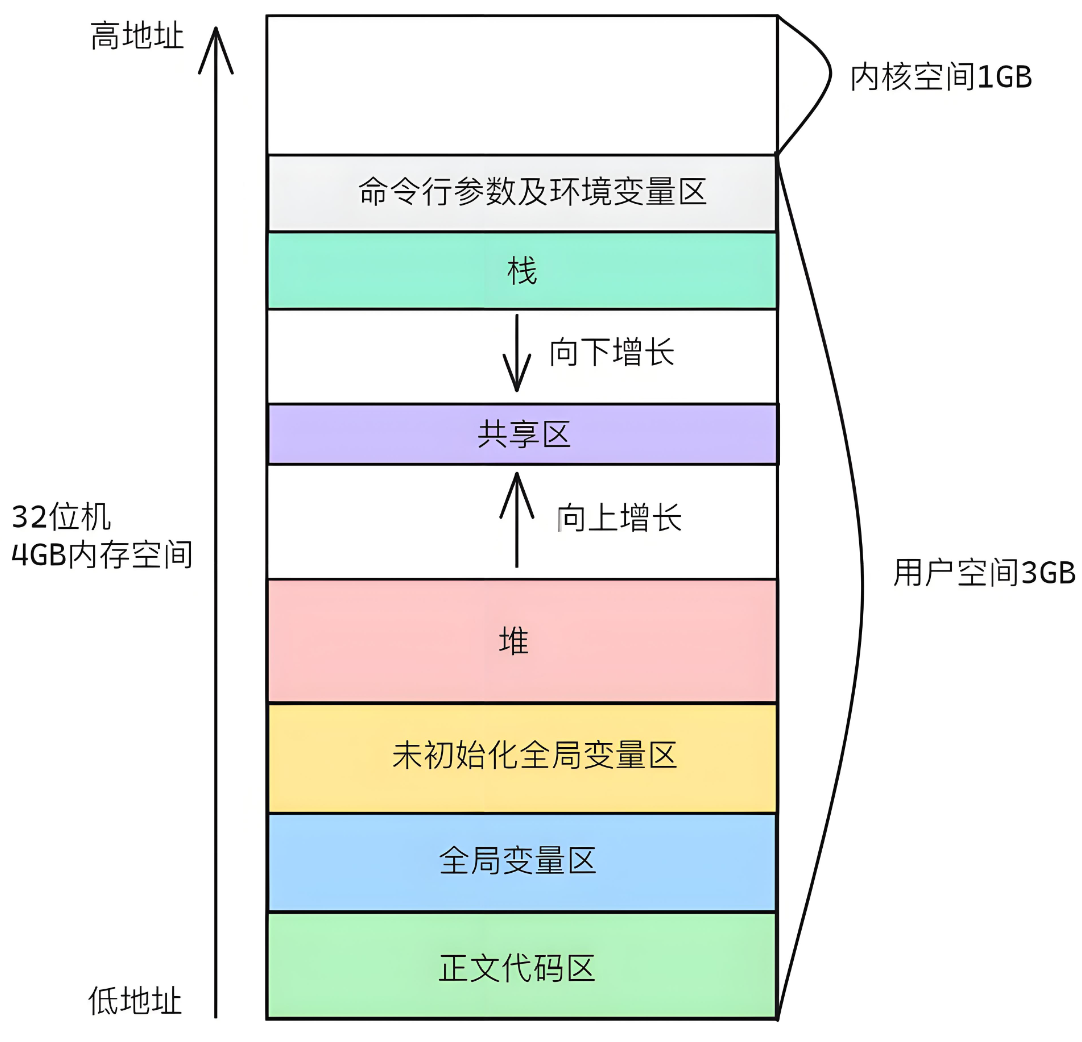
● 正文段。这是由CPU执行的机器指令部分。通常,正文段是可共享的,所以即使是频繁执行的程序(如文本编辑器、C编译器和shel 等)在存储器中也只需有一个副本,另外,正文段常常是只读的,以防止程序由于意外而修改其指令。
● 初始化数据段。通常将此段称为数据段,它包含了程序中需明确地赋初值的变量。例如,C程序中任何函数之外的声明: int maxcount =99; 使此变量以其初值存放在初始化数据段中。
● 未初始化数据段。通常将此段称为bss段,这一名称来源于早期汇编程序一个操作符,意思是“由符号开始的块”(blockstartedbysymbol),在程序开始执行之前,内核将此段中的数据初始化为0或空指针。函数外的声明: long sum[1000]; 使此变量存放在非初始化数据段中。
● 栈。自动变量以及每次函数调用时所需保存的信息都存放在此段中。每次函数调用时,其返回地址以及调用者的环境信息(如某些机器寄存器的值)都存放在栈中。然后,最近被调用的函数在栈上为其自动和临时变量分配存储空间。通过以这种方式使用栈,C递归函数可以工作。递归函数每次调用自身时,就用一个新的栈帧,因此一次函数调用实例中的变量集不会影响另一次函数调用实例中的变量。
● 堆。通常在堆中进行动态存储分配。由于历史上形成的惯例,堆位于未初始化数据段和栈之间。
来段代码感受一下:
- #include
- #include
- #include
-
- int g_unval;
- int g_val = 100;
-
- int main(int argc, char *argv[], char *env[])
- {
- const char *str = "helloworld";
- printf("code addr: %p\n", main);
- printf("init global addr: %p\n", &g_val);
- printf("uninit global addr: %p\n", &g_unval);
-
- static int test = 10;
- char *heap_mem = (char*)malloc(10);
- char *heap_mem1 = (char*)malloc(10);
- char *heap_mem2 = (char*)malloc(10);
- char *heap_mem3 = (char*)malloc(10);
- printf("heap addr: %p\n", heap_mem); //heap_mem(0), &heap_mem(1)
- printf("heap addr: %p\n", heap_mem1); //heap_mem(0), &heap_mem(1)
- printf("heap addr: %p\n", heap_mem2); //heap_mem(0), &heap_mem(1)
- printf("heap addr: %p\n", heap_mem3); //heap_mem(0), &heap_mem(1)
-
- printf("test static addr: %p\n", &test); //heap_mem(0), &heap_mem(1)
- printf("stack addr: %p\n", &heap_mem); //heap_mem(0), &heap_mem(1)
- printf("stack addr: %p\n", &heap_mem1); //heap_mem(0), &heap_mem(1)
- printf("stack addr: %p\n", &heap_mem2); //heap_mem(0), &heap_mem(1)
- printf("stack addr: %p\n", &heap_mem3); //heap_mem(0), &heap_mem(1)
-
- printf("read only string addr: %p\n", str);
- for(int i = 0 ;i < argc; i++)
- {
- printf("argv[%d]: %p\n", i, argv[i]);
- }
- for(int i = 0; env[i]; i++)
- {
- printf("env[%d]: %p\n", i, env[i]);
- }
-
- return 0;
- }
结果如下:
- code addr: 0x5fc4bf384189
- init global addr: 0x5fc4bf387010
- uninit global addr: 0x5fc4bf38701c
- heap addr: 0x5fc4c000f6b0
- heap addr: 0x5fc4c000f6d0
- heap addr: 0x5fc4c000f6f0
- heap addr: 0x5fc4c000f710
- test static addr: 0x5fc4bf387014
- stack addr: 0x7ffc632ee5b0
- stack addr: 0x7ffc632ee5b8
- stack addr: 0x7ffc632ee5c0
- stack addr: 0x7ffc632ee5c8
- read only string addr: 0x5fc4bf385004
- argv[0]: 0x7ffc632ef6d0
- env[0]: 0x7ffc632ef6d7
- env[1]: 0x7ffc632ef6e7
- env[2]: 0x7ffc632ef713
- env[3]: 0x7ffc632ef71f
- env[4]: 0x7ffc632ef72b
- env[5]: 0x7ffc632ef737
- env[6]: 0x7ffc632ef743
- env[7]: 0x7ffc632ef752
- env[8]: 0x7ffc632ef763
- env[9]: 0x7ffc632efe7c
- env[10]: 0x7ffc632efe9e
- env[11]: 0x7ffc632efea9
- env[12]: 0x7ffc632efec9
- env[13]: 0x7ffc632efed2
- env[14]: 0x7ffc632efeda
- env[15]: 0x7ffc632eff09
- env[16]: 0x7ffc632eff4a
- env[17]: 0x7ffc632effb2
- env[18]: 0x7ffc632effc5
- env[19]: 0x7ffc632effe8
2、虚拟地址
C程序的存储空间布局是指进程的虚拟地址空间,而非物理内存。实验如下:
- #include
- #include
- #include
-
- int g_val = 100;
-
- int main()
- {
- pid_t id = fork();
- if(id == 0)
- {
- while(1)
- {
- printf("子:g_val: %d, &g_val: %p, pid: %d, ppid: %d\n", g_val, &g_val, getpid(), getppid());
- sleep(1);
- g_val++;
- }
- }
- else
- {
- while(1)
- {
- printf("父:g_val: %d, &g_val: %p, pid: %d, ppid: %d\n", g_val, &g_val, getpid(), getppid());
- sleep(1);
- }
- }
-
- return 0;
- }
- zyt@iZ2vcf9wvlgcetfeub9f11Z:~/linux-journey-log/code_25_4_1$ ./code
- 父:g_val: 100, &g_val: 0x5e35ce24c010, pid: 358641, ppid: 344183
- 子:g_val: 100, &g_val: 0x5e35ce24c010, pid: 358642, ppid: 358641
- 父:g_val: 100, &g_val: 0x5e35ce24c010, pid: 358641, ppid: 344183
- 子:g_val: 101, &g_val: 0x5e35ce24c010, pid: 358642, ppid: 358641
- 父:g_val: 100, &g_val: 0x5e35ce24c010, pid: 358641, ppid: 344183
我们发现,父子进程输出地址是一致的,但是变量内容不一样。所以可以断定这里的地址一定不是物理内存地址!所以我们以前学c语言用的指针指向的也不是内存地址,而是虚拟地址!
物理地址用户一律看不到,由OS统一管理,OS必须负责将虚拟地址转换成物理地址。
3、进程地址空间
一个进程一个虚拟地址空间!32位机器下有2^32个地址(也就是4GB,其中[0,3]是用户空间,[3,4]是内核空间),64位机器下有2^64个地址。
(1)页表 (Page Table)
一个进程一套页表!页表是用来做虚拟地址和物理地址的映射的,由CPU生成虚拟地址。
分页机制:
内存被划分为固定大小的页(Page)(通常4KB,x86/x86_64)
虚拟页号+ 页内偏移 → 物理页帧号 + 相同偏移。
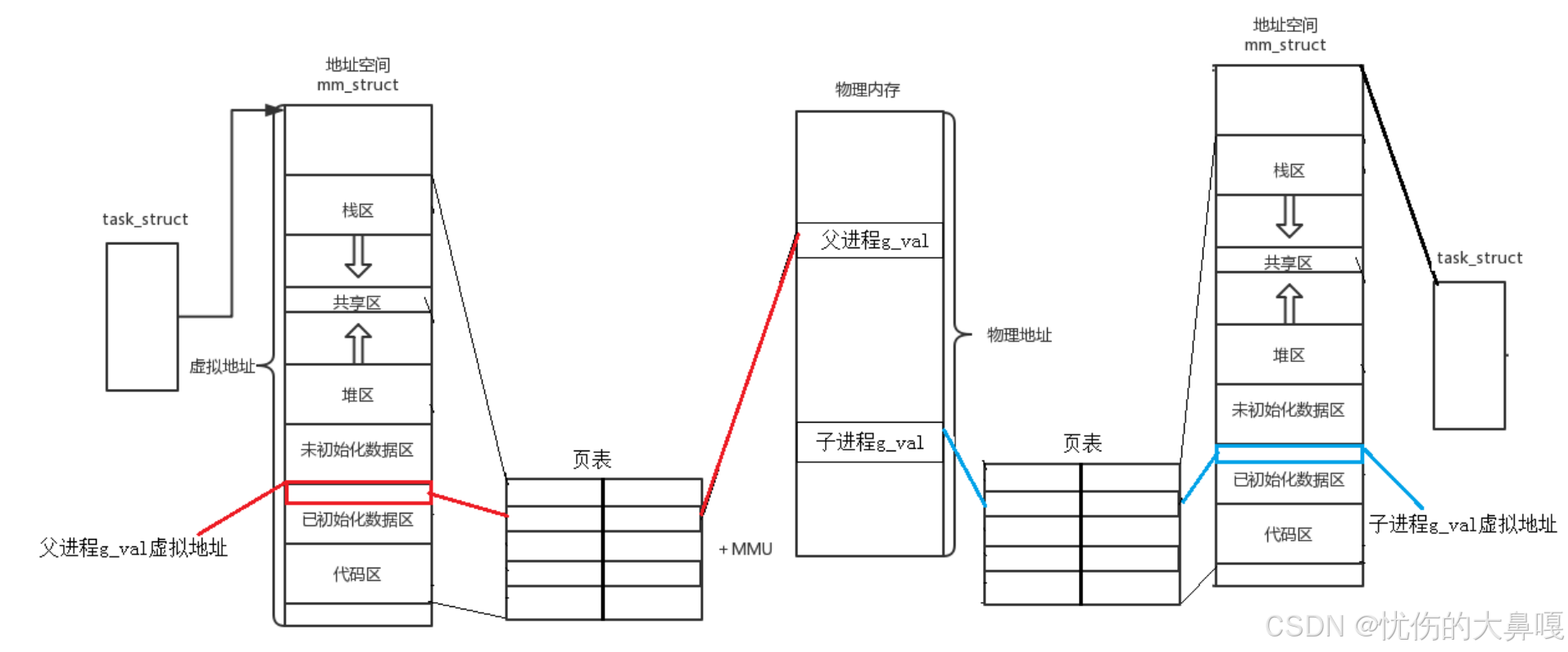
这也解释了之前程序的现象:同一个变量,地址相同,其实就是虚拟地址相同(子进程继承了父进程的虚拟地址),内容不同其实是被映射到了不同的物理地址(操作系统内部做了写实拷贝,把目标变量复制申请新的内存,并修改页表的映射关系)。
(2)虚拟内存管理
① 举个例子:理解虚拟地址空间
场景:假设你的手机同时运行:① 微信(聊天)② 抖音(刷视频)③ 支付宝(付款)
虚拟地址空间的作用:每个App独享自己的"虚拟内存"
● 微信认为自己有 4GB 内存(实际可能只分配了 500MB 物理内存)
● 抖音也认为自己有 4GB 内存
● 支付宝同样认为自己有 4GB 内存这里的手机就是操作系统,三个App就是三个进程, 每个App认为自己独享的4GB内存就是虚拟地址空间。
总结:虚拟地址空间让每个App活在"楚门的世界"里——它们以为自己独占整个内存,而操作系统在幕后默默管理真实的物理资源,既保证安全隔离,又实现高效共享。
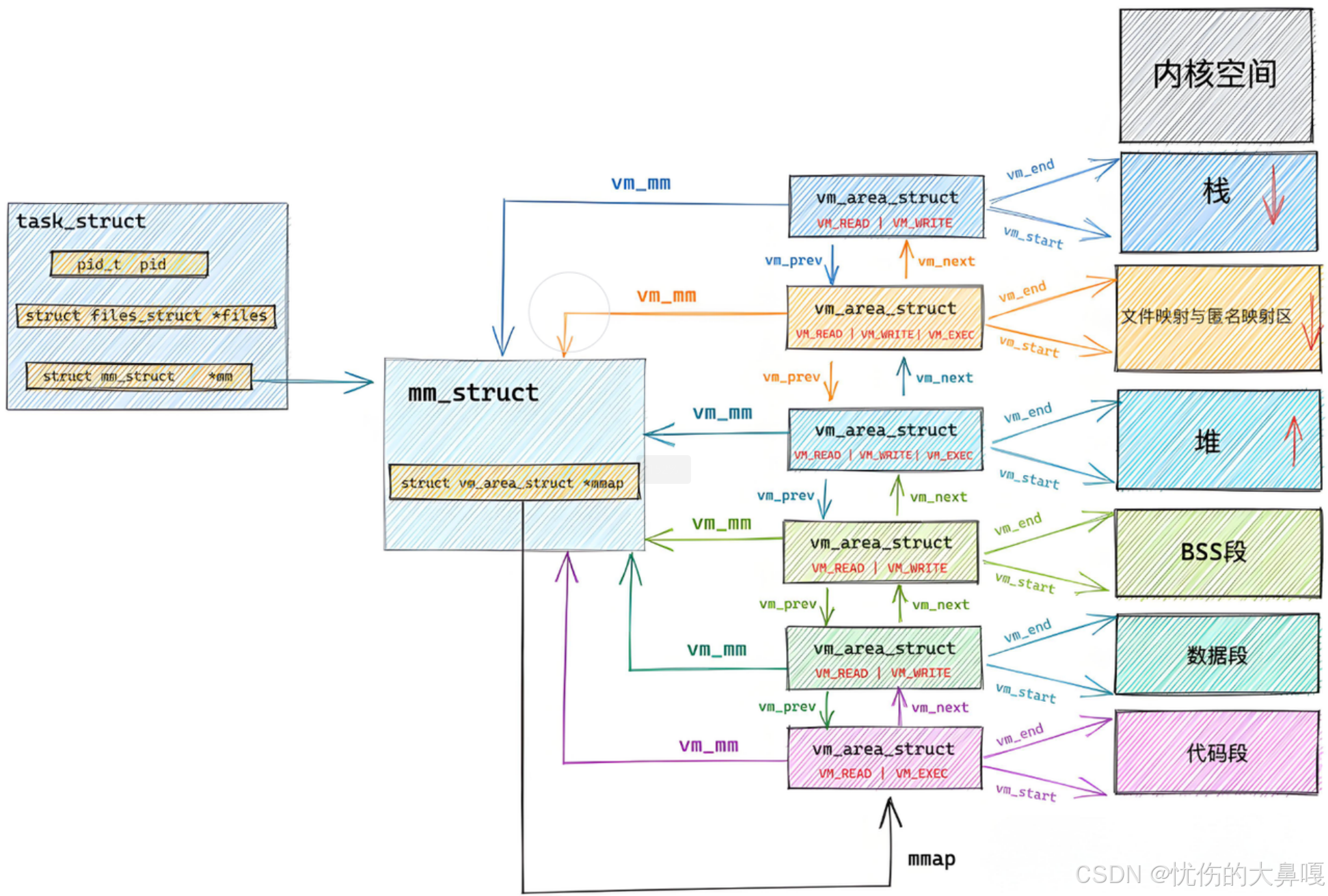
② mm_struct结构体(存储进程地址空间信息)
描述Linux下进程的地址空间的所有信息的结构体是mm_struct(内存描述符)。每个进程只有一个mm_struct结构,在每一个进程的task_struct结果中,有一个指向该进程的结构。
- struct task_struct {
- /*...*/
-
- /*
- * 指向进程的内存描述符 (mm_struct)
- * - 对普通用户进程:指向它的虚拟地址空间(用户空间部分)
- * - 对内核线程:NULL(因为内核线程没有用户空间)
- */
- struct mm_struct *mm;
-
- /*
- * 活跃的内存描述符
- * - 对普通用户进程:与 mm 相同
- * - 对内核线程:借用前一个用户进程的 mm_struct
- * (用于内核页表管理,避免频繁切换)
- */
- struct mm_struct *active_mm;
-
- /*...*/
- };
可以说,mm_struct结构是对整个用户空间的描述。每一个进程都会有自己独立的mm_struct,这样每一个进程都会有自己独立的地址空间才能互不干扰。先来看看由task_struct,进程的地址空间的分布情况:
定位mm_struct文件所在位置和task_struct所在路径是一样的,不过他们所在文件是不一样的,mm_struct所在文件是mm_types.h。
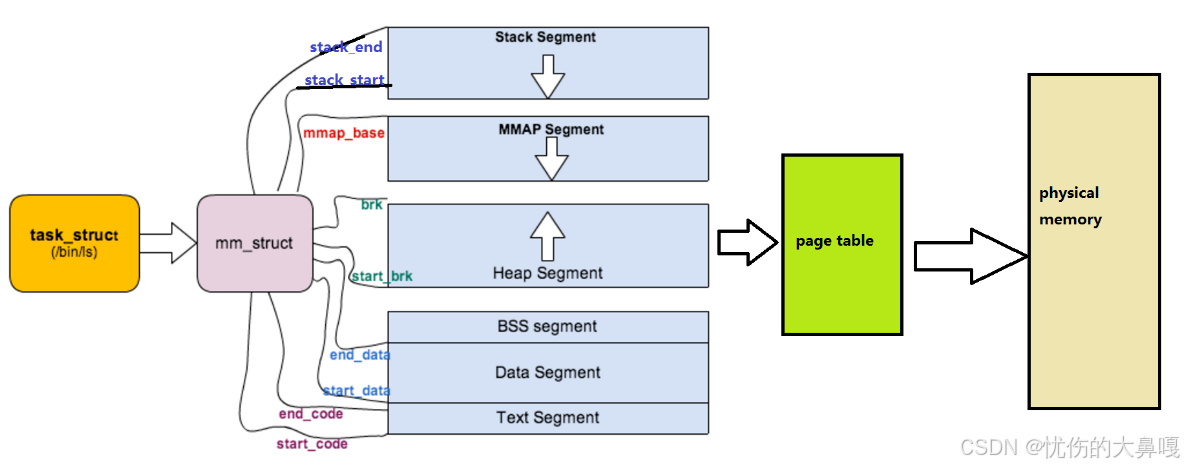
- struct mm_struct {
- /* 内存区域管理 */
- struct vm_area_struct *mmap; /* 线性链表方式存储的VMA列表头 */
- struct rb_root mm_rb; /* 红黑树方式组织的VMA结构(优化查找)*/
-
- /* 地址空间尺寸 */
- unsigned long task_size; /* 用户态虚拟地址空间大小(如32位系统为3GB) */
-
- /* 关键内存段边界 */
- unsigned long start_code; /* 代码段起始地址 */
- unsigned long end_code; /* 代码段结束地址 */
- unsigned long start_data; /* 数据段起始地址 */
- unsigned long end_data; /* 数据段结束地址 */
-
- /* 动态内存区域 */
- unsigned long start_brk; /* 堆区起始地址 */
- unsigned long brk; /* 堆区当前break位置(通过brk()调整)*/
- unsigned long start_stack; /* 栈区起始地址 */
-
- /* 进程参数与环境变量 */
- unsigned long arg_start; /* 命令行参数起始地址 */
- unsigned long arg_end; /* 命令行参数结束地址 */
- unsigned long env_start; /* 环境变量起始地址 */
- unsigned long env_end; /* 环境变量结束地址 */
-
- /*...其他字段省略...*/
- };
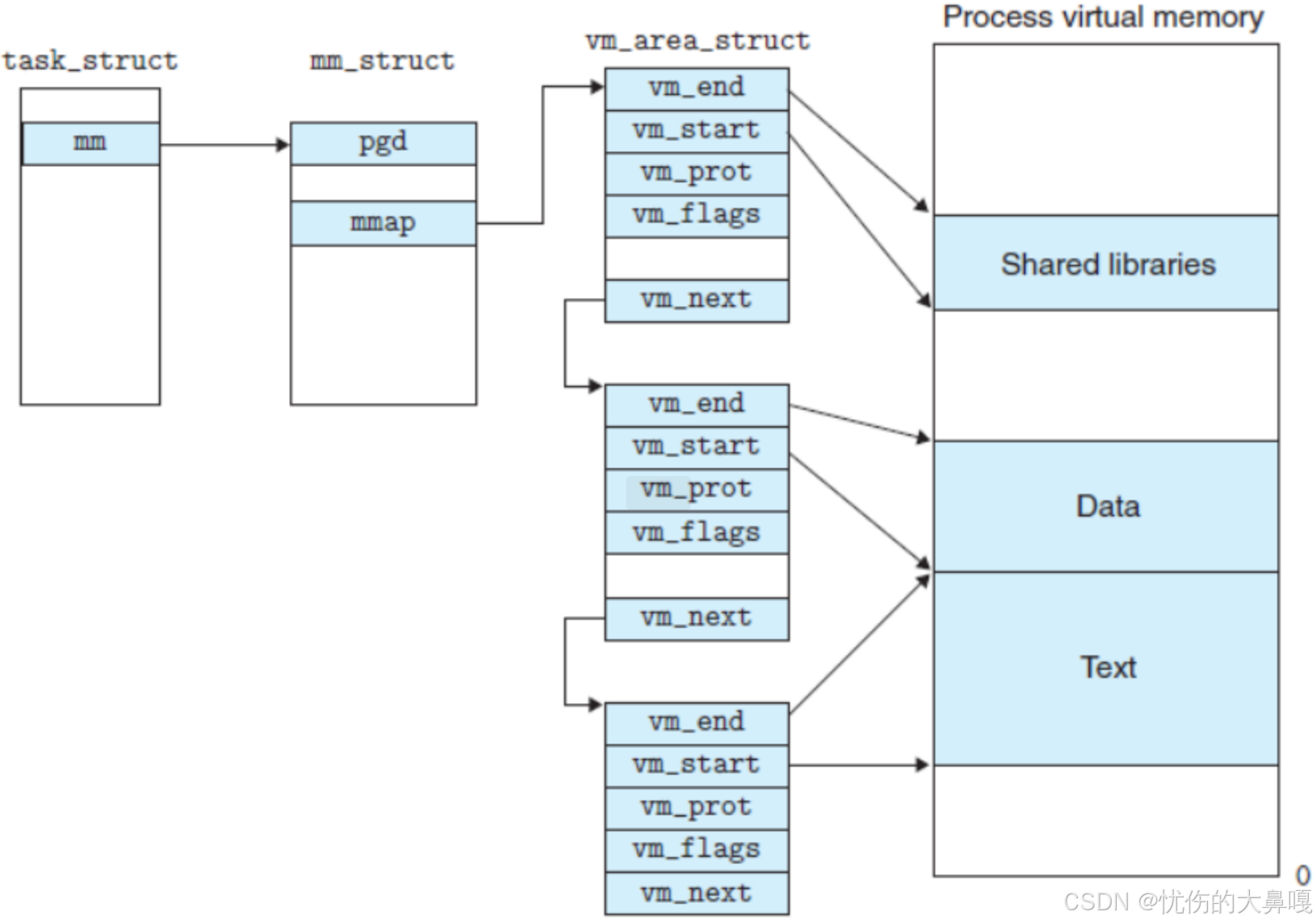
③ 管理虚拟内存vm_area_struct
在 Linux 内核中,每个进程的虚拟地址空间通过 mm_struct 结构体进行管理,其中的虚拟内存区域(VMA)使用 vm_area_struct 结构体来表示。为了高效管理这些 VMA,Linux 采用了两种组织方式:
● 当进程的虚拟内存区域较少时,内核使用单链表进行管理,通过 mm_struct 中的 mmap 指针指向这个链表。这种方式的优点是实现简单,适合 VMA 数量较少的情况(通常少于 32 个),但查找效率为 O(n)。
● 当进程的虚拟内存区域较多时,内核转而使用红黑树进行管理,通过 mm_struct 中的 mm_rb 指针指向这棵红黑树。红黑树是一种自平衡的二叉搜索树,能够将查找、插入和删除操作的时间复杂度都优化到 O(log n),非常适合管理大量的 VMA(如浏览器等复杂应用可能包含数百个 VMA)。
④ 区域划分:
每个 vm_area_struct 结构体都描述了一个连续的虚拟内存区域,包含该区域的起始地址(vm_start)、结束地址(vm_end)、访问权限(vm_flags)等关键信息。这些 VMA 可能代表不同的内存段,如代码段、数据段、堆、栈、内存映射文件等。
- struct vm_area_struct {
- /* 基础地址信息 */
- unsigned long vm_start; // 虚拟内存区域起始地址
- unsigned long vm_end; // 虚拟内存区域结束地址
-
- /* 链表结构(用于少量VMA管理) */
- struct vm_area_struct *vm_next; // 下一个VMA(单链表正向指针)
- struct vm_area_struct *vm_prev; // 上一个VMA(单链表反向指针)
-
- /* 红黑树结构(用于大量VMA管理) */
- struct rb_node vm_rb; // 红黑树节点
- unsigned long rb_subtree_gap; // 子树最大间隙
-
- /* 所属内存描述符 */
- struct mm_struct *vm_mm; // 关联的mm_struct
-
- /* 内存保护与标志 */
- pgprot_t vm_page_prot; // 页保护权限(读/写/执行)
- unsigned long vm_flags; // 标志位(VM_READ|VM_WRITE|VM_SHARED等)
-
- /* 共享内存相关 */
- struct {
- struct rb_node rb;
- unsigned long rb_subtree_last;
- } shared; // 用于共享VMA的红黑树
-
- /* 匿名映射管理 */
- struct list_head anon_vma_chain; // 匿名VMA链
- struct anon_vma *anon_vma; // 匿名页反向映射
-
- /* 操作函数集 */
- const struct vm_operations_struct *vm_ops; // VMA操作函数(缺页处理、销毁等)
-
- /* 文件映射信息 */
- unsigned long vm_pgoff; // 文件映射偏移量(以页为单位)
- struct file *vm_file; // 关联的文件指针(如果是文件映射)
- void *vm_private_data; // 驱动私有数据
-
- /* 高级功能 */
- atomic_long_t swap_readahead_info; // 交换预读信息
- #ifndef CONFIG_MMU
- struct vm_region *vm_region; // NOMMU架构专用映射区域
- #endif
- #ifdef CONFIG_NUMA
- struct mempolicy *vm_policy; // NUMA内存策略
- #endif
- struct vm_userfaultfd_ctx vm_userfaultfd_ctx; // 用户态缺页处理上下文
-
- } __randomize_layout; // 内核随机化布局(安全加固)
(3)代码加载到内存的完整流程
1、内核为进程创建虚拟地址空间(mm_struct),当程序启动时,内核会为它创建一个mm_struct,初始化虚拟内存区域的划分。初始值来自可执行文件的ELF头部信息(如.text段的虚拟地址0x400000、.data段的地址等)。内核解析ELF文件后,将这些信息填充到mm_struct中。
2、在虚拟地址空间中申请空间,内核根据ELF文件的要求,在进程的虚拟地址空间中预留出代码段、数据段、BSS段等区域。此时仅是虚拟地址的分配,尚未分配物理内存。
3、加载代码到物理内存,内核从磁盘读取可执行文件的代码段和数据段,申请物理页帧。对于BSS段(未初始化数据),内核直接分配清零的物理页。
4、 建立页表映射(虚拟→物理),虚拟地址 <-> 物理地址 -> 页表进行映射!代码段:只读(RX权限),数据段:可读写(RW权限)。
5、物理地址→虚拟地址的转换(执行阶段),当CPU执行程序时,指令中的虚拟地址(如call 0x400000)会被MMU(硬件)通过页表转换为物理地址,从而实际访问内存中的代码或数据。
4、为什么要有虚拟地址空间?
(1)内存隔离与保护
地址空间和页表是OS创建并维护的!是不是也就意味着,凡是想使用地址空间和页表进行映射,也一定要在OS的监管之下来进行访问!!也顺便,包括各个进程以及内核的相关有效数据!保护了物理内存中的所有的合法数据。
-
隔离性:每个进程拥有独立的虚拟地址空间,彼此无法直接访问对方的内存区域,防止恶意或错误的程序干扰其他进程或操作系统内核。
-
权限控制:通过页表(Page Table)设置内存区域的读写执行权限(如代码段只读、数据段可写),避免非法操作(例如修改代码段会导致段错误,权限拦截了)。
(2)进程管理模块和内存管理模块解耦合
因为有地址空间的存在和页表的映射的存在,我们的物理内存中可以对未来的数据进行任意位置的加载!物理内存的分配和进程的管理就可以做到没有关系。进程管理模块和内存管理模块就完成了解耦合。
(3)从“无序”变“有序”
因为页表的映射的存在,程序在物理内存中理论上就可以任意位置加载。它可以将地址空间上的虚拟地址和物理地址进行映射,在进程视角所有的内存分布都可以是有序的。
(4)简化内存管理
因为有地址空间的存在,所以我们在C、C++语言上new、malloc空间的时候,其实是在地址空间上申请的,物理内存可以甚至一个字节都不给你。而当你真正进行对物理地址空间访问的时候,才执行内存的相关管理算法,帮你申请内存,构建页表映射关系(延迟分配),这是由操作系统自动完成,用户包括进程完全0感知!!
-
统一视图:程序员无需关心物理内存的实际分布,只需在连续的虚拟地址空间中编写程序,由操作系统和硬件(MMU)自动处理物理内存的分配与映射。
-
动态扩展:堆(Heap)和栈(Stack)可以按需动态增长,物理内存的分配延迟到实际使用时(如缺页异常触发物理页分配)。
评论记录:
回复评论: