
目标
通过vsCode用python访问deepseek。
环境准备
没有环境的,vscode环境准备请参考之前的文章,另外需安装ollama:
【菜鸟飞】用vsCode搭建python运行环境-CSDN博客
AI入门1:AI模型管家婆ollama的安装和使用-CSDN博客
选读文章:
【菜鸟飞】Conda安装部署与vscode的结合使用-CSDN博客
开始实操
1、获得访问DeepSeek R1的Token
咱们测试学习,就找个免费的,硅基流动被邀请用户送token,量大够用,官方的声明:
硅基流动官网:注册即送 2000 万 Tokens:受邀好友作为新用户完成 SiliconCloud 账号注册,立刻获得 2000万 Tokens。
通过以下地址注册:硅基流动统一登录 (带了我的邀请码,接受邀请注册,才能获赠免费tocken)
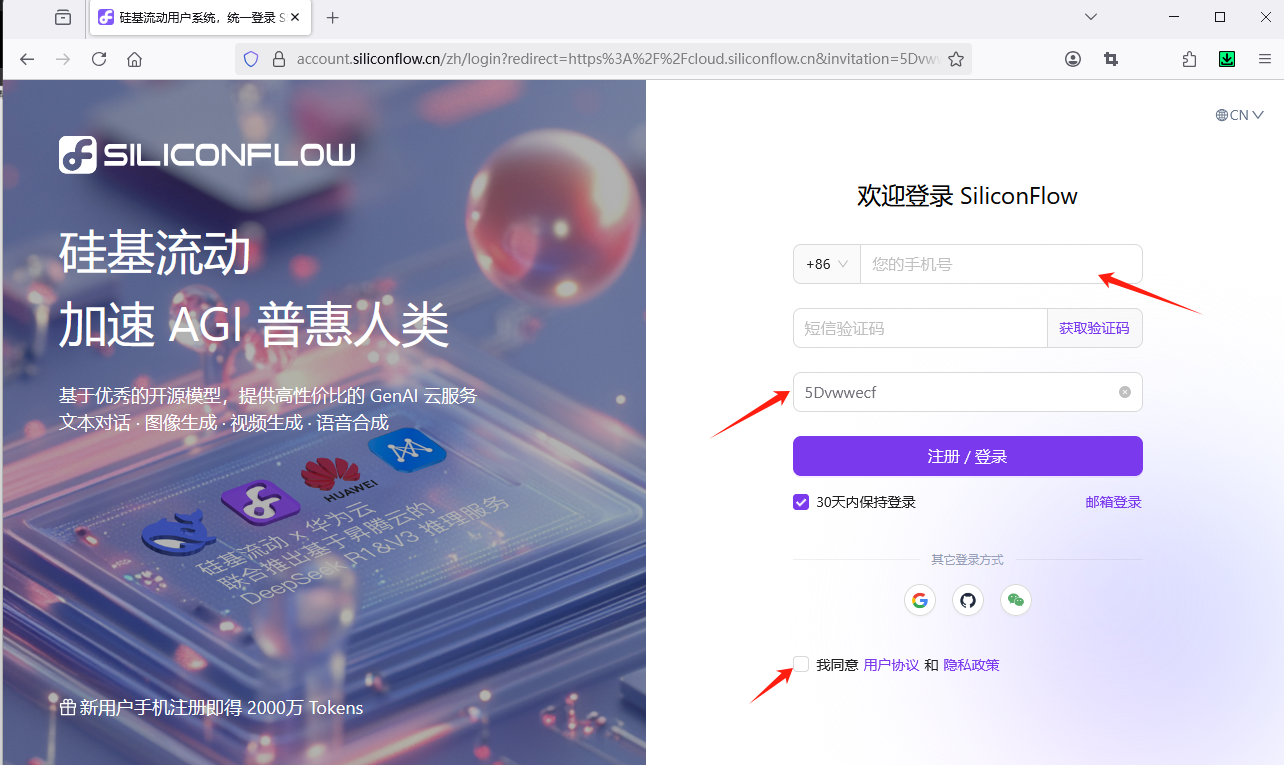
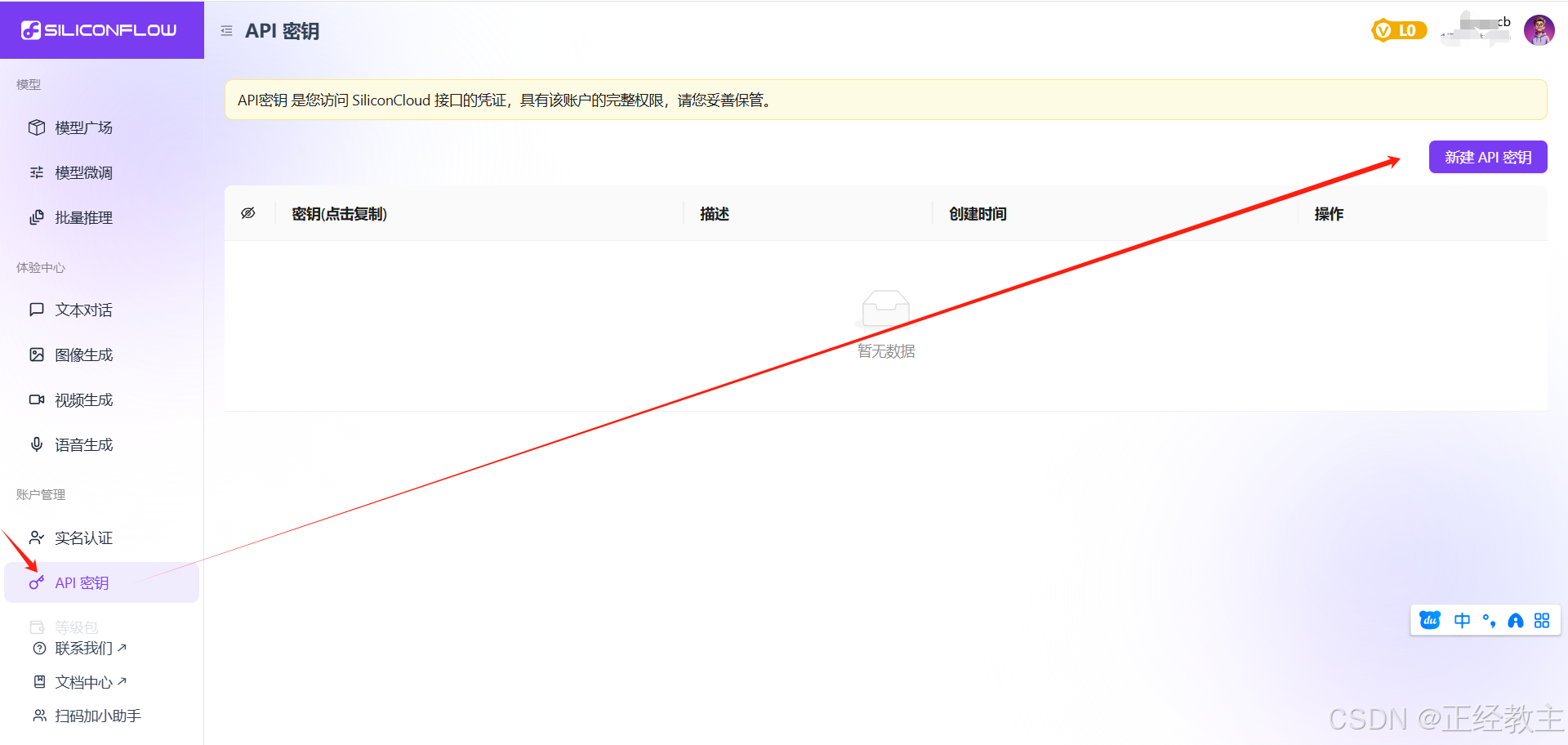
自动填写了邀请码,手机验证注册,然后,创建密钥:
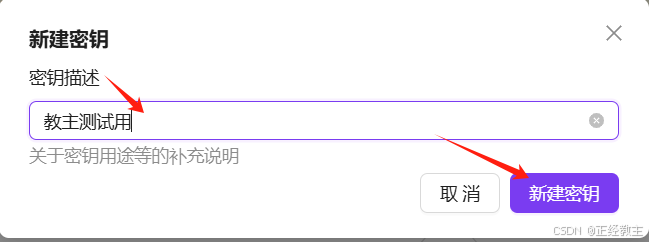
弹出对话框,输入描述信息,主要是给自己看,备注干嘛用的:
然后,系统创建一条密钥:
 密钥是加密显示的,鼠标划上去,显示复制提示:
密钥是加密显示的,鼠标划上去,显示复制提示:

在密钥上左键点击一下,提示“已复制”,可以粘贴到文本文件等地方,以便后面程序使用:

2、vscode设置
官方文档参考:
硅基流动有文档中心,通过下面界面进入,或者直接访问链接,可以看到相关帮助文档,https://docs.siliconflow.cn/cn/userguide/introduction
参考一下官方文档: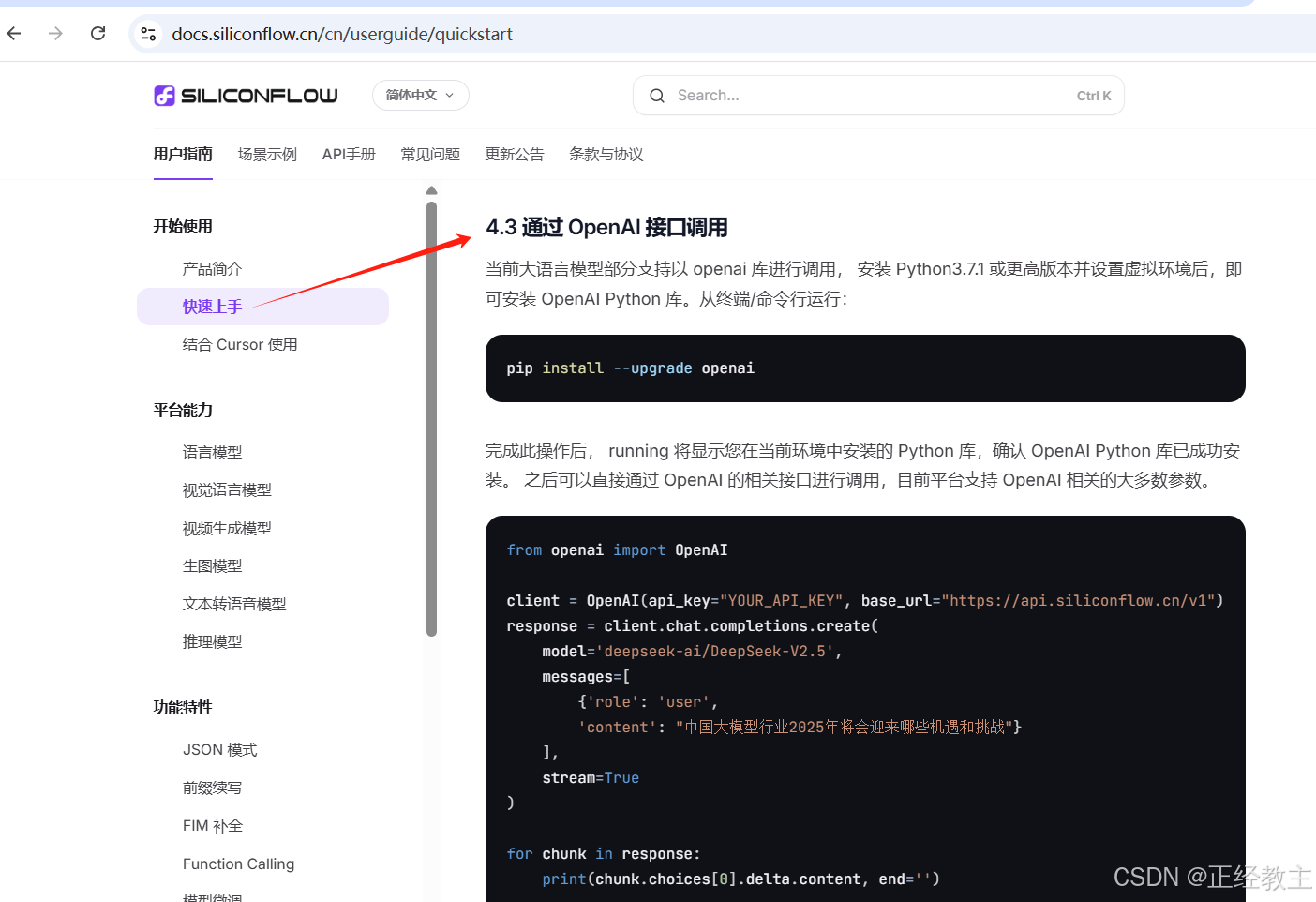
设置vscode运行环境
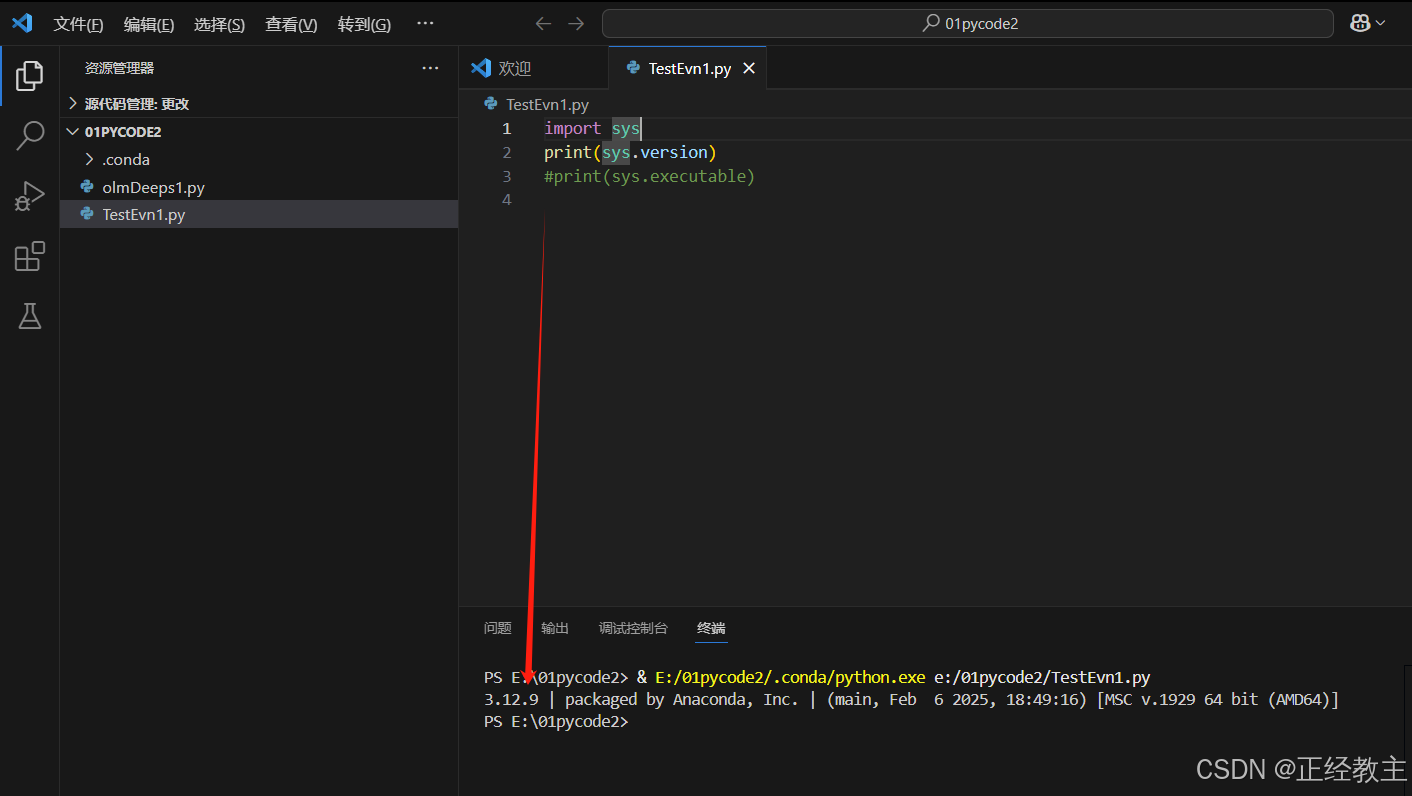
参考前面vs搭建文档,创建一个python12的运行环境,并测试运行正常:
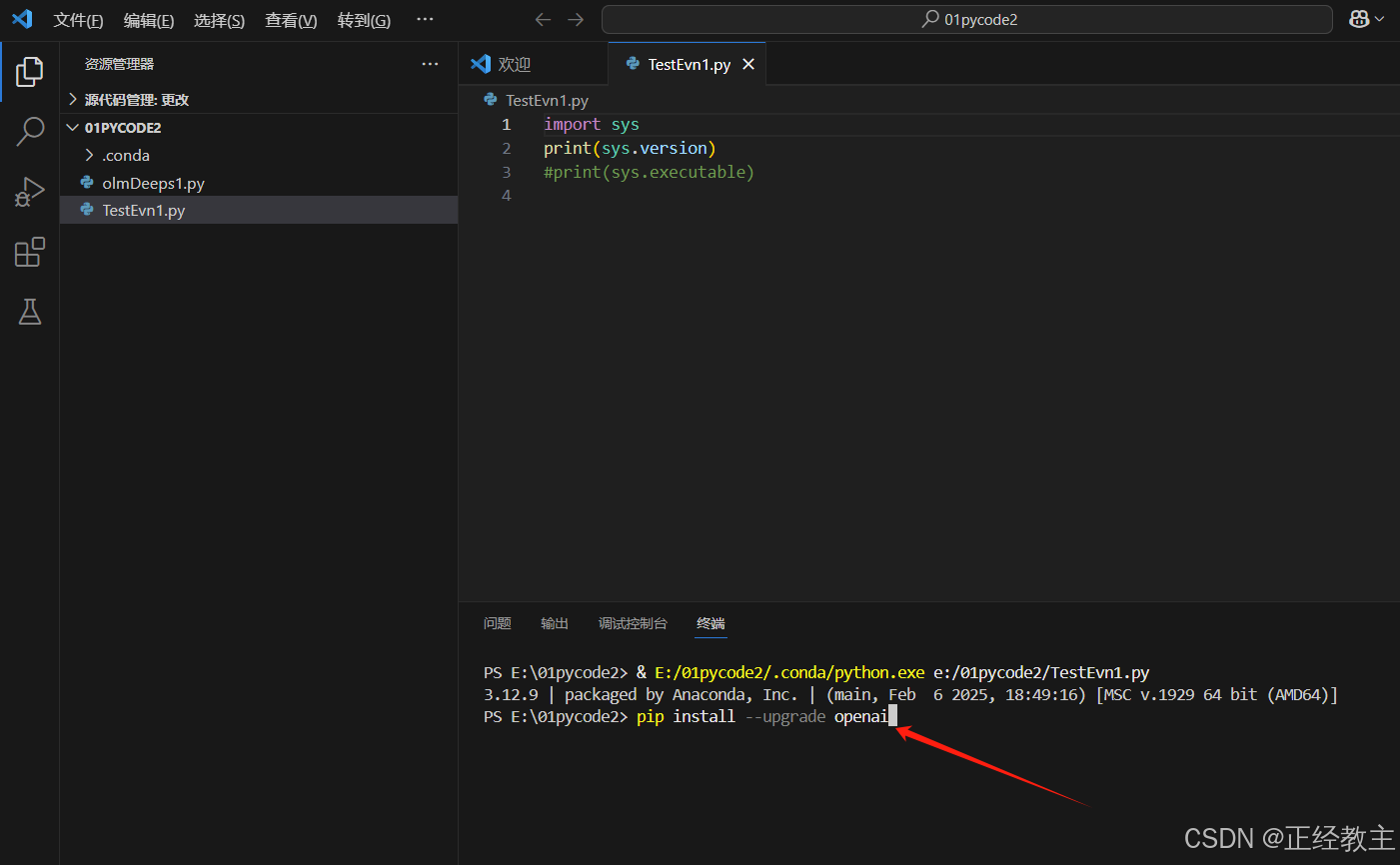
 用pip方式安装 OpenAI Python 库,命令为:
用pip方式安装 OpenAI Python 库,命令为:
pip install --upgrade openai执行界面如下:
执行过程中出错:
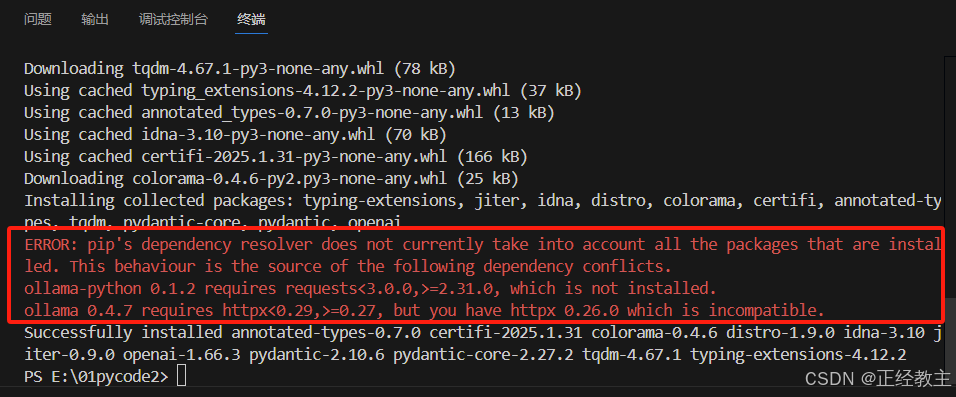 升级ollama:启动ollama后,在任务栏会有ollama图标,点击右键会有关闭升级的菜单,点击后,ollama进入升级程序执行界面:
升级ollama:启动ollama后,在任务栏会有ollama图标,点击右键会有关闭升级的菜单,点击后,ollama进入升级程序执行界面:
然后再次执行命令:pip install --upgrade openai ,这次就没有报错了。
3、执行测试代码
然后,创建已py文件,考入下面代码:
- from openai import OpenAI
-
- client = OpenAI(api_key="YOUR_API_KEY", base_url="https://api.siliconflow.cn/v1")
- response = client.chat.completions.create(
- model='deepseek-ai/DeepSeek-V2.5',
- messages=[
- {'role': 'user',
- 'content': "中国大模型行业2025年将会迎来哪些机遇和挑战"}
- ],
- stream=True
- )
-
- for chunk in response:
- print(chunk.choices[0].delta.content, end='')
把上面YOUR_API_KE,换成刚才在硅基流动注册的密钥,点击执行,就会返还模型的反馈信息了,界面如下:
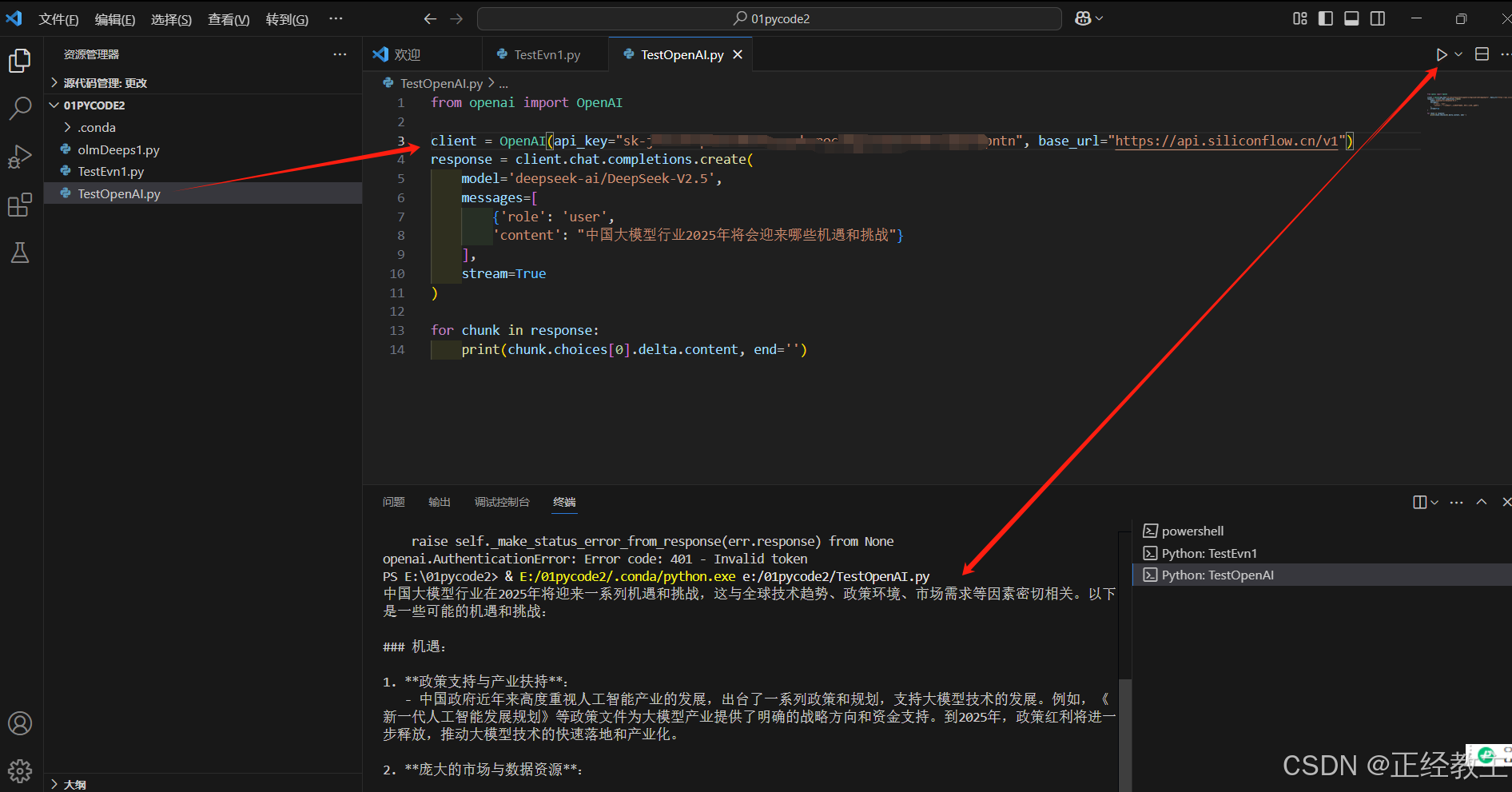
初步测试成功,换成自己想要的模型。
4、deepseek-r1模型调用
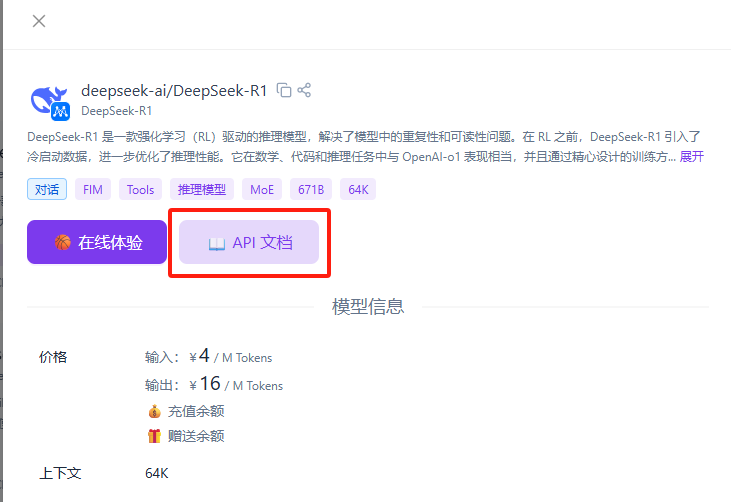
在模型广场看到很多模型,查找自己需要的模型:
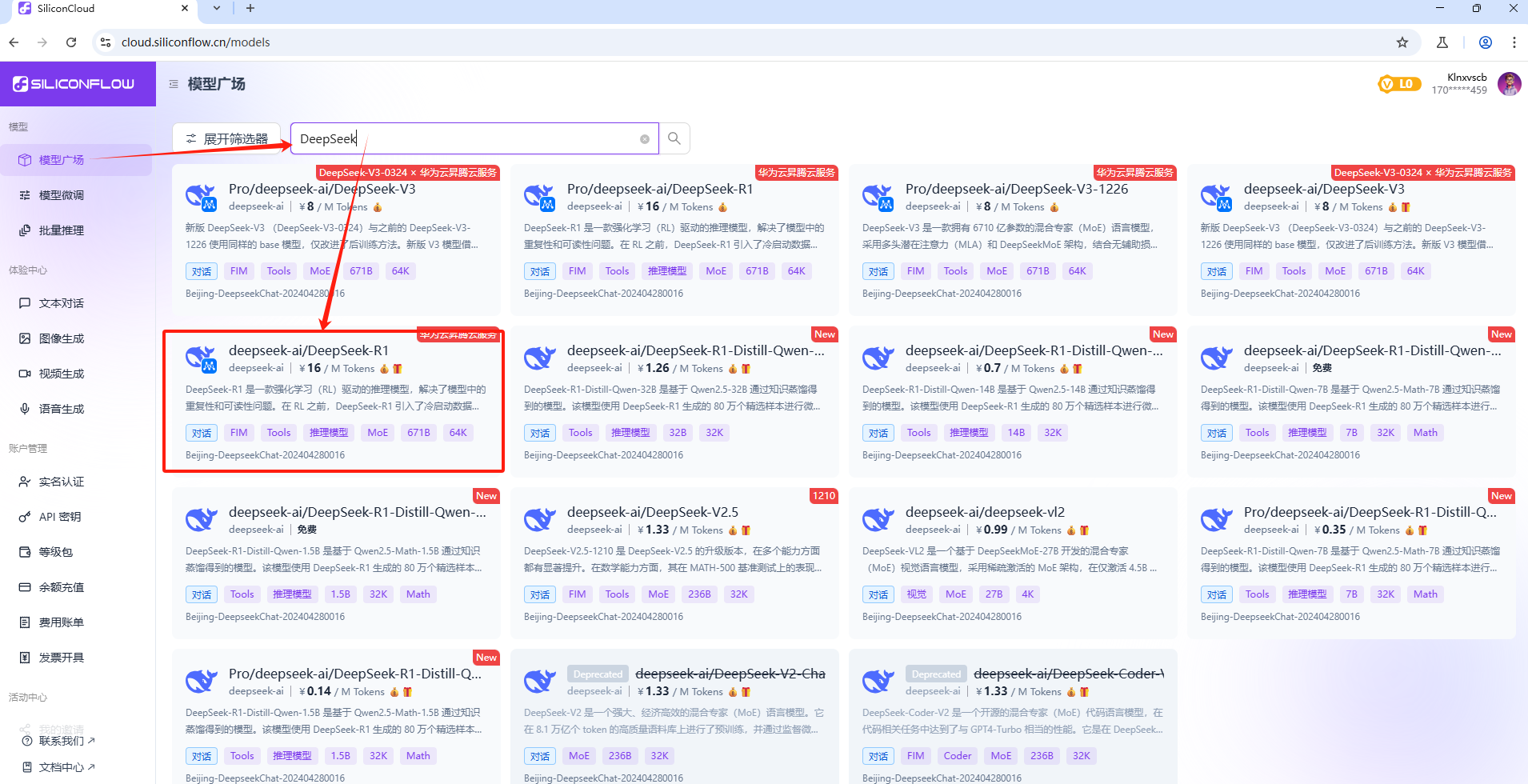
注意,模型广场提供了两种版本,一种是标准版,如deepseek-ai/DeepSeek-R1,另一种是Pro版,如Pro/deepseek-ai/DeepSeek-R1,Pro版本是优化过的高效版,不支持免费Tocken调用,所以不要选,打开标准版,点击标题旁边的拷贝图标,复制其地址,如图:
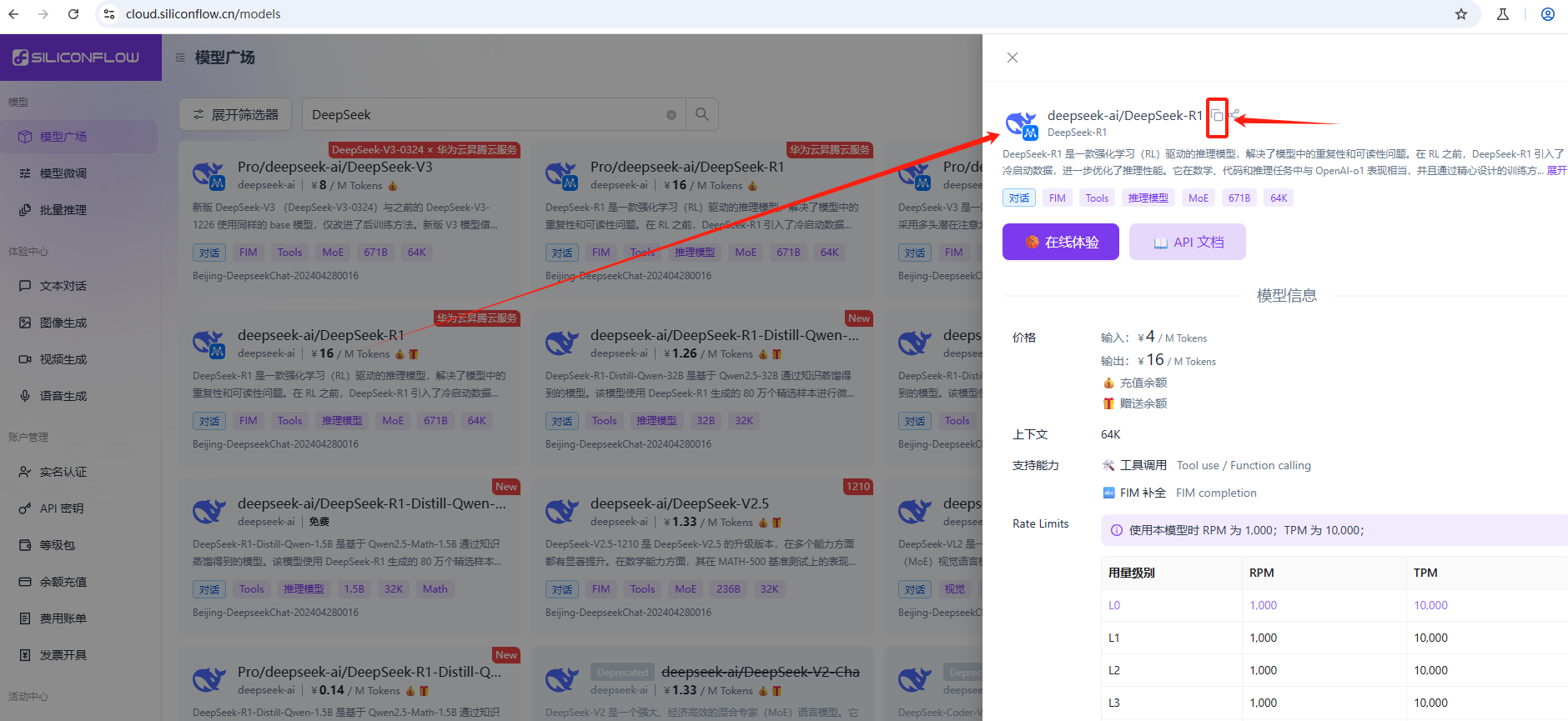
在代码里,更换model为模型地址“deepseek-ai/DeepSeek-R1”,【提示:每个模型里有有API文档的链接,如上图,为后面扩展自己的逻辑方便很多,必须点赞一下】修改为:
model='deepseek-ai/DeepSeek-R1'
修改界面及执行如下:
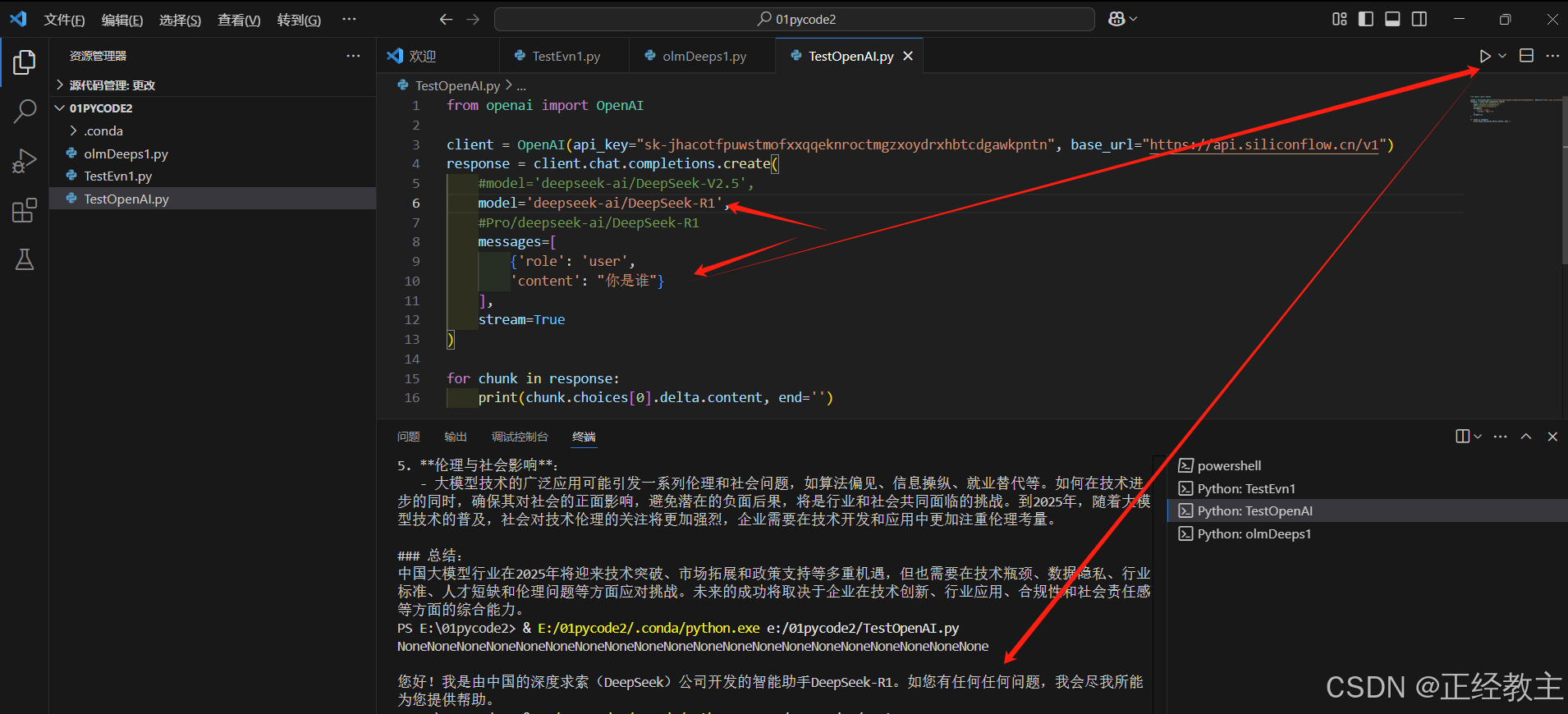
其模型调用类似,进一步可以构建自己的业务逻辑了。
第二种访问方式
打开模型的API文档,可以看到不同语言的调用方式:
python的调用方式,给出了requests的调用方式,下面还有返回代码的各种格式及解释:
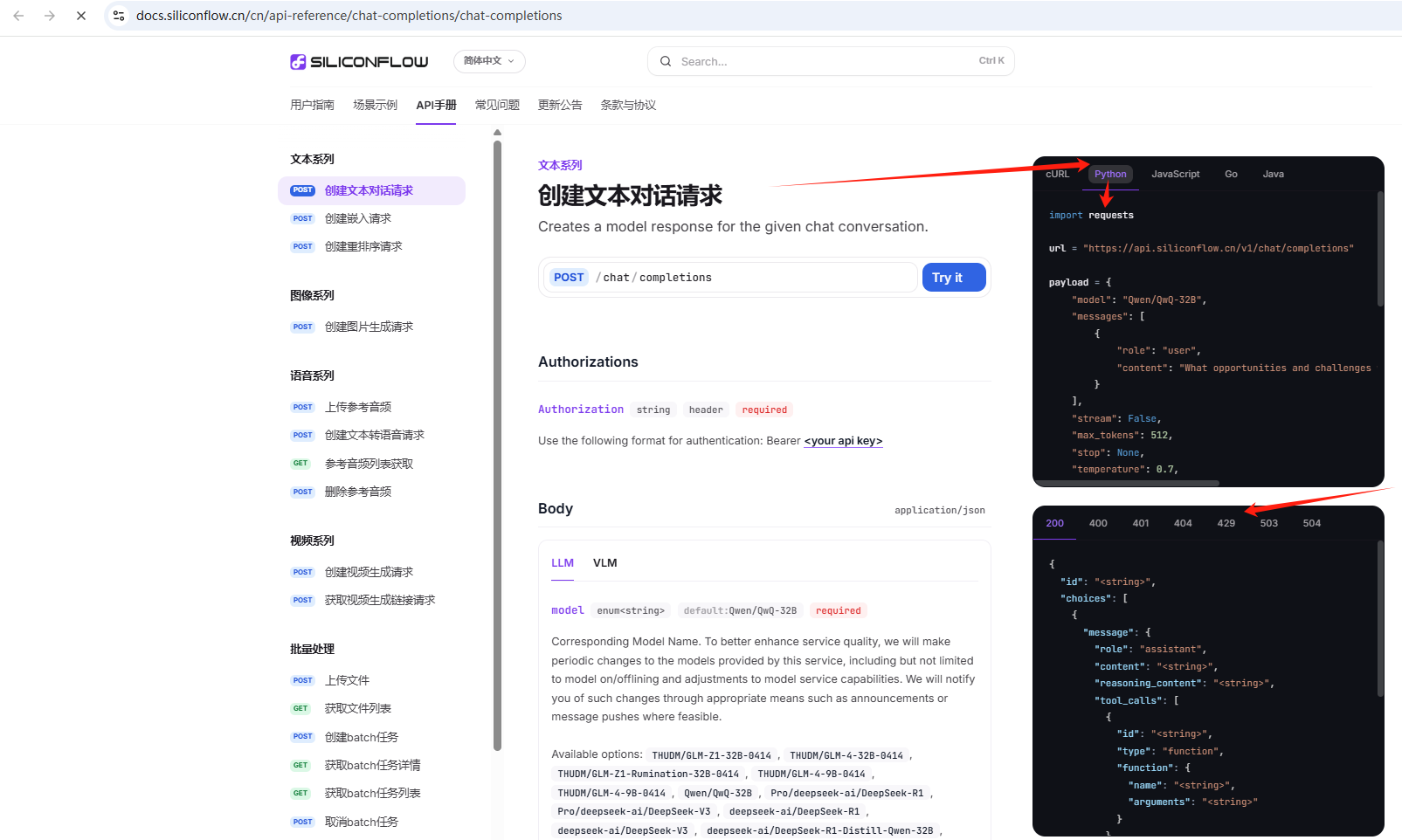 示例代码:
示例代码:
- import requests
-
- url = "https://api.siliconflow.cn/v1/chat/completions"
-
- payload = {
- "model": "Qwen/QwQ-32B",
- "messages": [
- {
- "role": "user",
- "content": "What opportunities and challenges will the Chinese large model industry face in 2025?"
- }
- ],
- "stream": False,
- "max_tokens": 512,
- "stop": None,
- "temperature": 0.7,
- "top_p": 0.7,
- "top_k": 50,
- "frequency_penalty": 0.5,
- "n": 1,
- "response_format": {"type": "text"},
- "tools": [
- {
- "type": "function",
- "function": {
- "description": "
" , - "name": "
" , - "parameters": {},
- "strict": False
- }
- }
- ]
- }
- headers = {
- "Authorization": "Bearer
" , - "Content-Type": "application/json"
- }
-
- response = requests.request("POST", url, json=payload, headers=headers)
-
- print(response.text)

修改其中这句代码,把自己的api-key替换上就可以了:
"Authorization": "Bearer " ,备注:查看剩余tocken
200wtocken,貌似相对于是系统里的14元,在余额充值里查看:
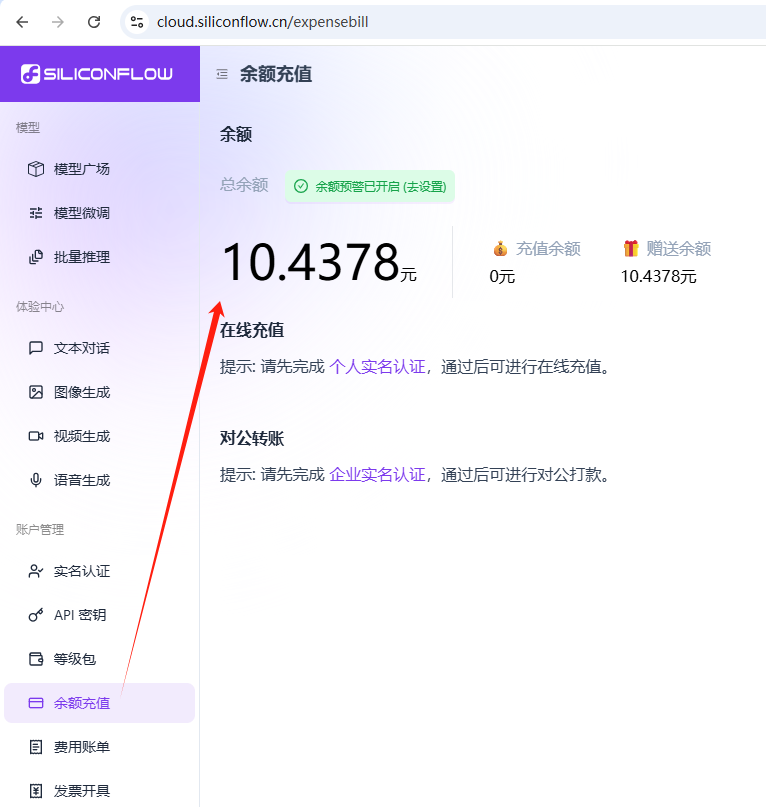
还有费用账单可以查看明细:
我用这个来做佛经译文的内容总结,输出markdown格式,一共200来个文件,r1和v3分别生成一份,预计会用5,6块钱的样子,如果你只是像我这样批量使用的话,应该能用很久。
附赠:文档内容总结代码
如果大家需要文档内容总结,可以参考我下面的代码:
- import os
- from openai import OpenAI
-
- # 更新 API 客户端配置
- client = OpenAI(
- api_key="你自己key",
- #os.getenv("SILICONFLOW_API_KEY"), # 使用新的 API Key 环境变量
- base_url="https://api.siliconflow.cn/v1" # 使用新的 API 地址
- )
-
- # 定义文件夹路径
- #输入目录,和输出目录
- input_folder = r'D:\01成长探索\001佛法_禅修法要\阿含经译文\mkinpt\完成'
- output_folder = r'D:\01成长探索\001佛法_禅修法要\阿含经译文\mkoutpt'
-
- # 确保输出文件夹存在
- os.makedirs(output_folder, exist_ok=True)
-
- # 遍历文件夹中的每个文件
- for filename in os.listdir(input_folder):
- if filename.endswith('.txt'): # 假设文件是txt格式,可以根据需要修改
- file_path = os.path.join(input_folder, filename)
- print(f'-----------: {filename}')
- # 读取文件内容
- with open(file_path, 'r', encoding='utf-8') as file:
- content = file.read()
-
- # 使用大模型进行分析和总结
- completion = client.chat.completions.create(
- model="deepseek-ai/DeepSeek-R1", # 更新模型名称 pro/deepseek-ai/DeepSeek-V3需要付费 deepseek-ai/DeepSeek-V3可以用
- messages=[
- #{'role': 'user', 'content': f'请仔细阅读并全面总结以下内容,结果以markdown格式输出,输出的内容后续用于生成思维导图,请兼顾这一点,首行不要输出```markdown,各项要有能生成导图分支的符合标识:\n{content}'}
- {'role': 'user', 'content': f'请仔细阅读以下内容,并全面总结,结果以markdown格式输出:\n{content}'}
- ]
- )
-
- # 通过content字段获取最终答案
- summary = completion.choices[0].message.content
-
- # 将总结结果保存为Markdown文件
- output_file_path = os.path.join(output_folder, f'{os.path.splitext(filename)[0]}_逻辑分析.md')
- with open(output_file_path, 'w', encoding='utf-8') as output_file:
- output_file.write(summary)
评论记录:
回复评论: