
Langchain系列文章目录
01-玩转LangChain:从模型调用到Prompt模板与输出解析的完整指南
02-玩转 LangChain Memory 模块:四种记忆类型详解及应用场景全覆盖
03-全面掌握 LangChain:从核心链条构建到动态任务分配的实战指南
04-玩转 LangChain:从文档加载到高效问答系统构建的全程实战
05-玩转 LangChain:深度评估问答系统的三种高效方法(示例生成、手动评估与LLM辅助评估)
06-从 0 到 1 掌握 LangChain Agents:自定义工具 + LLM 打造智能工作流!
文章目录
前言
近年来,大语言模型(LLM, Large Language Model)已成为人工智能领域的核心技术,背后的生成式预训练模型(GPT, Generative Pre-trained Transformer)更是推动了自然语言处理(NLP)的快速发展。从GPT-1到GPT-4,这一系列模型持续突破技术边界,本文将详细介绍GPT的演进历程及其核心原理。
一、大语言模型进化树
语言模型的发展是人工智能技术进步的缩影,其背后依赖于 Transformer 架构的不断创新。从2018年 Transformer 模型的提出到2023年支持多模态任务的 GPT-4 问世,大语言模型在架构、训练规模和应用领域上取得了显著进展。通过“语言模型进化树”图可以清晰地看到,语言模型的发展路径主要分为三大分支:Encoder-only、Encoder-Decoder 和 Decoder-only。
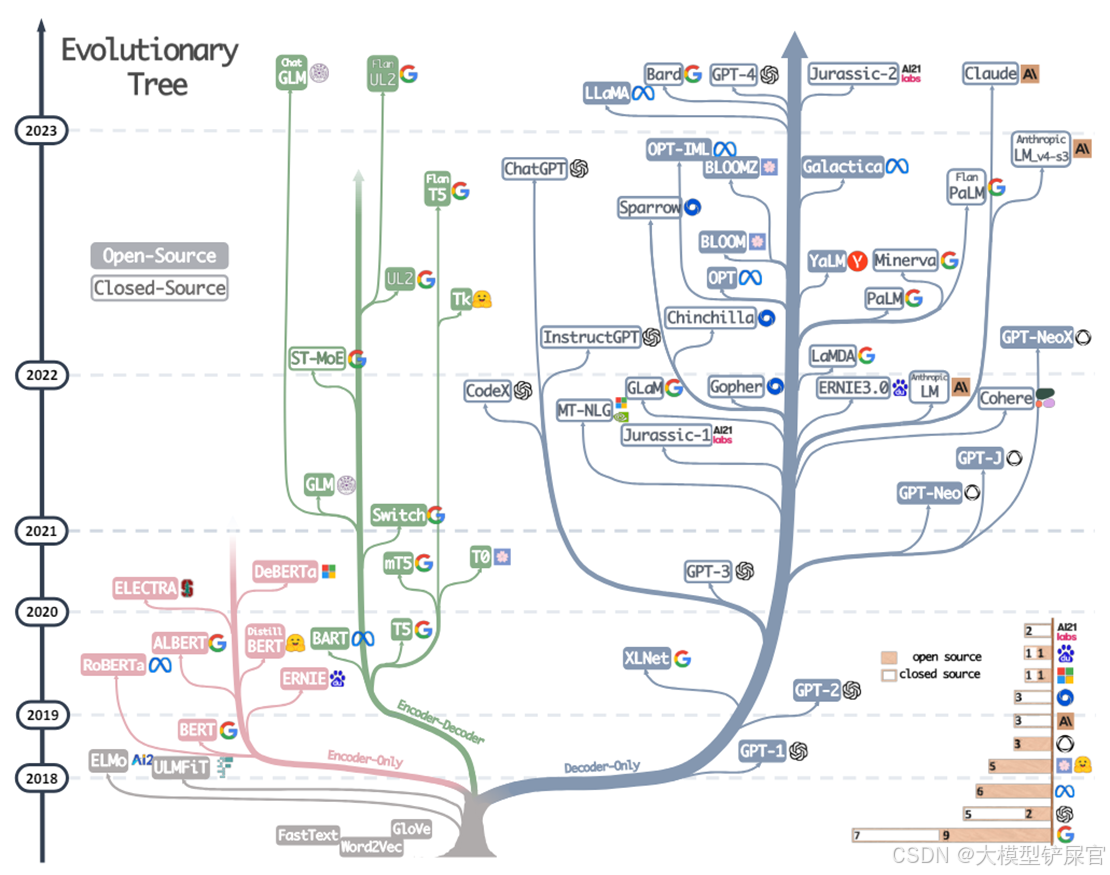
1.1 Encoder-only 模型
Encoder-only 模型主要用于理解文本内容,适合完成需要深度语言理解的任务,比如文本分类、问答、情感分析或实体识别。它们类似于“语言解读者”,通过多次分析输入文本,提取隐藏在字里行间的深层含义。
代表模型:
BERT(2019):双向理解语言的开创者,大幅提升了文本理解的效果。
RoBERTa 和 ALBERT:在BERT的基础上优化了训练方法和效率。
ELECTRA 和 DeBERTa:进一步提高了语言理解任务的性能。
特点:
全面理解上下文:通过“双向编码”,既能从左往右看,也能从右往左看,确保对句子含义的完整理解。
局限性:由于它缺少生成模块,只能用于分析和理解,不能生成新的文本内容,比如写文章或聊天。
1.2 Encoder-Decoder 模型
Encoder-Decoder 模型是一种既能理解语言又能生成语言的通用型架构。它的工作方式可以比作“翻译官”:先完全读懂输入内容(编码器负责),然后根据理解生成输出内容(解码器负责)。这类模型特别适合翻译、总结、对话生成等任务。
代表模型:
T5(2020):开创了“文本到文本”统一格式的学习方法,让所有任务都能通过类似翻译的方式完成。
BART 和 mT5:对T5进行了优化,并支持多语言处理。
FLAN-T5:通过大规模任务训练进一步提升了生成能力。
特点:
双向理解+单向生成:编码器负责理解完整输入,解码器则专注于从左到右生成输出。
多任务适应性强:可以灵活应对翻译、摘要生成、对话生成等复杂任务。
实用性:适合同时处理需要理解和生成能力的任务,比如总结文章或写邮件。
1.3 Decoder-only 模型
Decoder-only模型是语言生成任务的核心。它们的专长是“边看边写”,也就是说,它们通过分析输入的上下文,逐字逐句地生成内容。它更像是“语言的创作者”,擅长写作、创意生成、对话和自动化写作等任务。
代表模型:
GPT-1(2018):第一次提出“生成式预训练”的概念,开启了语言生成新时代。
GPT-2(2019):提出了Zero-shot学习,无需额外标注数据也能完成任务。
GPT-3(2020):支持Few-shot学习,通过少量样本即可适应多种任务。
ChatGPT(2022):结合人类反馈优化生成质量,提升对话能力。
GPT-4&#x
评论记录:
回复评论: