
戳蓝字“CSDN云计算”关注我们哦!

作者:阿里云智能事业群高级开发工程师 萧元
转自:阿里系统软件技术
Kubernetes作为一个分布式容器编排调度引擎,资源调度是它的最重要的功能。在 Kubernetes集群中,调度器作为一个独立模块运行。本文将介绍 Kubernetes 调度器的实现原理,工作流程, 以及未来发展。
Kubernetes 调度工作方式
Kubernetes 中的调度器,是作为单独组件运行,一般运行在 Master 中,和 Master 数量保持一致。通过 Raft 协议选出一个实例作为 Leader 工作,其他实例 Backup。 当 Master 故障,其他实例之间继续通过 Raft 协议选出新的 Master 工作。
其工作模式如下:
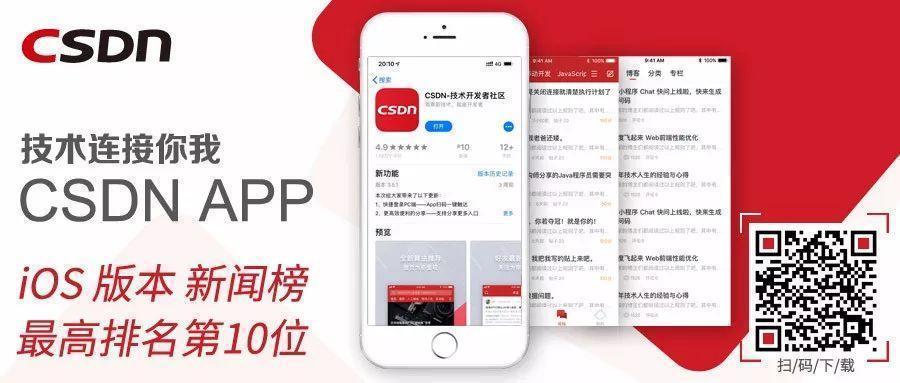
调度器内部维护一个调度的 pods 队列 podQueue, 并监听 APIServer;
当我们创建 Pod 时,首先通过 APIServer 往 ETCD 写入 Pod 元数据;
调度器通过 Informer 监听 Pods 状态,当有新增 Pod 时,将 Pod 加入到 podQueue 中;
调度器中的主进程,会不断的从 podQueue 取出的 Pod,并将 Pod 进入调度分配节点环节;
调度环节分为两个步奏, Filter 过滤满足条件的节点 、 Prioritize 根据 Pod 配置,例如资源使用率,亲和性等指标,给这些节点打分,最终选出分数最高的节点;
分配节点成功, 调用 apiServer 的 binding pod 接口, 将
pod.Spec.NodeName设置为所分配的那个节点;节点上的 kubelet 同样监听 ApiServer,如果发现有新的 pod 被调度到所在节点,在节点上拉起对应的容器
假如调度器尝试调度 Pod 不成功,如果开启了优先级和抢占功能,会尝试做一次抢占,将节点中优先级较低的 pod 删掉,并将待调度的 pod 调度到节点上。 如果未开启,或者抢占失败,会记录日志,并将 pod 加入 podQueue 队尾。
实现细节
kube-scheduling 是一个独立运行的组件,主要工作内容在 Run 函数 。 这里面主要做几件事情:
初始化一个 Scheduler 实例
sched,传入各种 Informer,为关心的资源变化建立监听并注册 handler,例如维护 podQuene;注册 events 组件,设置日志;
注册 http/https 监听,提供健康检查和 metrics 请求;
运行主要的调度内容入口
sched.run()。 如果设置--leader-elect=true,代表启动多个实例,通过Raft选主,实例只有当被选为master后运行主要工作函数sched.run。
调度核心内容在 sched.run() 函数,它会启动一个 go routine 不断运行sched.scheduleOne, 每次运行代表一个调度周期。
func (sched *Scheduler) Run() {
if !sched.config.WaitForCacheSync() {
return
}
go wait.Until(sched.scheduleOne, 0, sched.config.StopEverything)
}
我们看下 sched.scheduleOne 主要做什么:
func (sched *Scheduler) scheduleOne() {
pod := sched.config.NextPod()
.... // do some pre check
scheduleResult, err := sched.schedule(pod)
if err != nil {
if fitError, ok := err.(*core.FitError); ok {
if !util.PodPriorityEnabled() || sched.config.DisablePreemption {
..... // do some log
} else {
sched.preempt(pod, fitError)
}
}
}
...
// Assume volumes first before assuming the pod.
allBound, err := sched.assumeVolumes(assumedPod, scheduleResult.SuggestedHost)
...
fo func() {
// Bind volumes first before Pod
if !allBound {
err := sched.bindVolumes(assumedPod)
if err != nil {
klog.Errorf("error binding volumes: %v", err)
metrics.PodScheduleErrors.Inc()
return
}
}
err := sched.bind(assumedPod, &v1.Binding{
ObjectMeta: metav1.ObjectMeta{Namespace: assumedPod.Namespace, Name: assumedPod.Name, UID: assumedPod.UID},
Target: v1.ObjectReference{
Kind: "Node",
Name: scheduleResult.SuggestedHost,
},
})
}
}
在sched.scheduleOne 中,主要会做几件事情:
通过
sched.config.NextPod(), 从 podQuene 中取出 pod;运行
sched.schedule,尝试进行一次调度;假如调度失败,如果开启了抢占功能,会调用
sched.preempt尝试进行抢占,驱逐一些 pod,为被调度的 pod 预留空间,在下一次调度中生效;如果调度成功,执行 bind 接口。在执行 bind 之前会为 pod volume 中声明的的 PVC 做 provision。
sched.schedule 是主要的 pod 调度逻辑:
func (g *genericScheduler) Schedule(pod *v1.Pod, nodeLister algorithm.NodeLister) (result ScheduleResult, err error) {
// Get node list
nodes, err := nodeLister.List()
// Filter
filteredNodes, failedPredicateMap, err := g.findNodesThatFit(pod, nodes)
if err != nil {
return result, err
}
// Priority
priorityList, err := PrioritizeNodes(pod, g.cachedNodeInfoMap, metaPrioritiesInterface, g.prioritizers, filteredNodes, g.extenders)
if err != nil {
return result, err
}
// SelectHost
host, err := g.selectHost(priorityList)
return ScheduleResult{
SuggestedHost: host,
EvaluatedNodes: len(filteredNodes) + len(failedPredicateMap),
FeasibleNodes: len(filteredNodes),
}, err
}
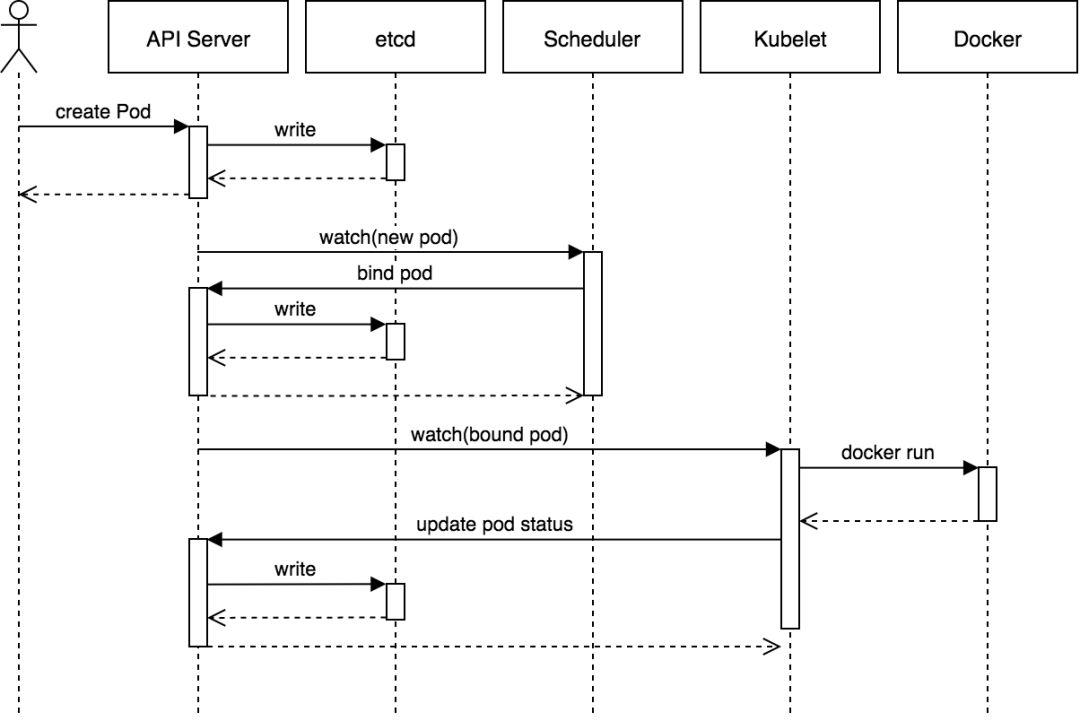
调度主要分为三个步奏:
Filters: 过滤条件不满足的节点;
PrioritizeNodes: 在条件满足的节点中做 Scoring,获取一个最终打分列表 priorityList;
selectHost: 在 priorityList 中选取分数最高的一组节点,从中根据 round-robin 方式选取一个节点。
接下来我们继续拆解, 分别看下这三个步奏会怎么做
Filters
Filters 相对比较容易,调度器默认注册了一系列的 predicates 方法, 调度过程为并发调用每个节点的 predicates 方法。最终得到一个 node list,包含符合条件的节点对象。
func (g *genericScheduler) findNodesThatFit(pod *v1.Pod, nodes []*v1.Node) ([]*v1.Node, FailedPredicateMap, error) {
if len(g.predicates) == 0 {
filtered = nodes
} else {
allNodes := int32(g.cache.NodeTree().NumNodes())
numNodesToFind := g.numFeasibleNodesToFind(allNodes)
checkNode := func(i int) {
nodeName := g.cache.NodeTree().Next()
// 此处会调用这个节点的所有predicates 方法
fits, failedPredicates, err := podFitsOnNode(
pod,
meta,
g.cachedNodeInfoMap[nodeName],
g.predicates,
g.schedulingQueue,
g.alwaysCheckAllPredicates,
)
if fits {
length := atomic.AddInt32(&filteredLen, 1)
if length > numNodesToFind {
// 如果当前符合条件的节点数已经足够,会停止计算。
cancel()
atomic.AddInt32(&filteredLen, -1)
} else {
filtered[length-1] = g.cachedNodeInfoMap[nodeName].Node()
}
}
}
// 并发调用checkNode 方法
workqueue.ParallelizeUntil(ctx, 16, int(allNodes), checkNode)
filtered = filtered[:filteredLen]
}
return filtered, failedPredicateMap, nil
}
值得注意的是, 1.13 中引入了 FeasibleNodes 机制,为了提高大规模集群的调度性能。允许我们通过 bad-percentage-of-nodes-to-score 参数, 设置 filter 的计算比例(默认 50%), 当节点数大于 100 个, 在 filters的过程,只要满足条件的节点数超过这个比例,就会停止 filter 过程,而不是计算全部节点。
举个例子,当节点数为 1000, 我们设置的计算比例为 30%,那么调度器认为 filter 过程只需要找到满足条件的 300 个节点,filter 过程中当满足条件的节点数达到 300 个,filter 过程结束。 这样 filter 不用计算全部的节点,同样也会降低 Prioritize 的计算数量。 但是带来的影响是 pod 有可能没有被调度到最合适的节点。
Prioritize
Prioritize 的目的是帮助 pod,为每个符合条件的节点打分,帮助 pod 找到最合适的节点。同样调度器默认注册了一系列 Prioritize 方法。这是 Prioritize 对象的数据结构:
// PriorityConfig is a config used for a priority function.
type PriorityConfig struct {
Name string
Map PriorityMapFunction
Reduce PriorityReduceFunction
// TODO: Remove it after migrating all functions to
// Map-Reduce pattern.
Function PriorityFunction
Weight int
}
每个 PriorityConfig 代表一个评分的指标,会考虑服务的均衡性,节点的资源分配等因素。 一个 PriorityConfig 的主要 Scoring 过程分为 Map 和 Reduce:
Map 过程计算每个节点的分数值
Reduce 过程会将当前 PriorityConfig 的所有节点的打分结果再做一次处理。
所有 PriorityConfig 计算完毕后,将每个 PriorityConfig 的数值乘以对应的权重,并按照节点再做一次聚合。
workqueue.ParallelizeUntil(context.TODO(), 16, len(nodes), func(index int) {
nodeInfo := nodeNameToInfo[nodes[index].Name]
for i := range priorityConfigs {
var err error
results[i][index], err = priorityConfigs[i].Map(pod, meta, nodeInfo)
}
})
for i := range priorityConfigs {
wg.Add(1)
go func(index int) {
defer wg.Done()
if err := priorityConfigs[index].Reduce(pod, meta, nodeNameToInfo, results[index]);
}(i)
}
wg.Wait()
// Summarize all scores.
result := make(schedulerapi.HostPriorityList, 0, len(nodes))
for i := range nodes {
result = append(result, schedulerapi.HostPriority{Host: nodes[i].Name, Score: 0})
for j := range priorityConfigs {
result[i].Score += results[j][i].Score * priorityConfigs[j].Weight
}
}
此外 Filter 和 Prioritize 都支持 extener scheduler 的调用,本文不做过多阐述。
现状
目前 Kubernetes 调度器的调度方式是 Pod-by-Pod,也是当前调度器不足的地方。主要瓶颈如下:
Kubernetes 目前调度的方式,每个 pod 会对所有节点都计算一遍,当集群规模非常大,节点数很多时,pod 的调度时间会非常慢。 这也是 percentage-of-nodes-to-score 尝试要解决的问题;
pod-by-pod 的调度方式不适合一些机器学习场景。 Kubernetes 早期设计主要为在线任务服务,在一些离线任务场景,比如分布式机器学习中,我们需要一种新的算法 gang scheduler,pod 也许对调度的即时性要求没有那么高,但是提交任务后,只有当一个批量计算任务的所有 workers 都运行起来时,才会开始计算任务。 pod-by-pod 方式在这个场景下,当资源不足时非常容易引起资源死锁;
当前调度器的扩展性不是十分好,特定场景的调度流程都需要通过硬编码实现在主流程中,比如我们看到的 bindVolume 部分, 同样也导致 Gang Scheduler 无法在当前调度器框架下通过原生方式实现。
Kubernetes 调度期的发展
社区调度器的发展,也是为了解决这些问题:
调度器 V2 框架,增强了扩展性,也为在原生调度器中实现 Gang schedule 做准备;
Kube-batch: 一种 Gang schedule 的实现 https://github.com/kubernetes-sigs/kube-batch;
poseidon: Firmament 一种基于网络图调度算法的调度器,poseidon 是将 Firmament 接入 Kubernetes 调度器的实现 https://github.com/kubernetes-sigs/poseidon。
参考文献
[1]https://medium.com/jorgeacetozi/kubernetes-master-components-etcd-api-server-controller-manager-and-scheduler-3a0179fc8186
[2]https://jvns.ca/blog/2017/07/27/how-does-the-kubernetes-scheduler-work/

福利
扫描添加小编微信,备注“姓名+公司职位”,加入【云计算学习交流群】,和志同道合的朋友们共同打卡学习!

推荐阅读:
大数据背后的无奈与焦虑:“128元连衣裙”划分矮穷挫与白富美?
315 后,等待失业的程序员
再不编程就老了!05 后比特币专家准备赚个 134,000,000 元!
Pig变飞机?AI为什么这么蠢 | Adversarial Attack
互联网没有春天
麦克阿瑟奖得主Dawn Song:区块链能保密和保护隐私?图样图森破!
 喜欢就点击“好看”吧
喜欢就点击“好看”吧
JDK的SPI机制的缺点
⽂件中的所有类都会被加载且被实例化。这样也就导致获取某个实现类的方式不够灵活,只能通过 Iterator 形式获取,不能根据某个参数来获取对应的实现类。如果不想用某些实现类,或者某些类实例化很耗时,它也被载入并实例化了,没有办法指定某⼀个类来加载和实例化,这就造成了浪费。
此时dubbo的SPI可以解决
dubbo的SPI机制
dubbo⾃⼰实现了⼀套SPI机制来解决Java的SPI机制存在的问题。
dubbo中则采用了类似kv对的样式,在具体使用的时候则通过相关想法即可获取,而且获取的文件路径也不一致
ExtensionLoader 类文件
java 代码解读复制代码private static final String SERVICES_DIRECTORY = "META-INF/services/";
private static final String DUBBO_DIRECTORY = "META-INF/dubbo/";
private static final String DUBBO_INTERNAL_DIRECTORY = DUBBO_DIRECTORY + "internal/";
如上述代码片段可知,dubbo是支持从META-INF/dubbo/,META-INF/dubbo/internal/以及META-INF/services/三个文件夹的路径去获取spi配置
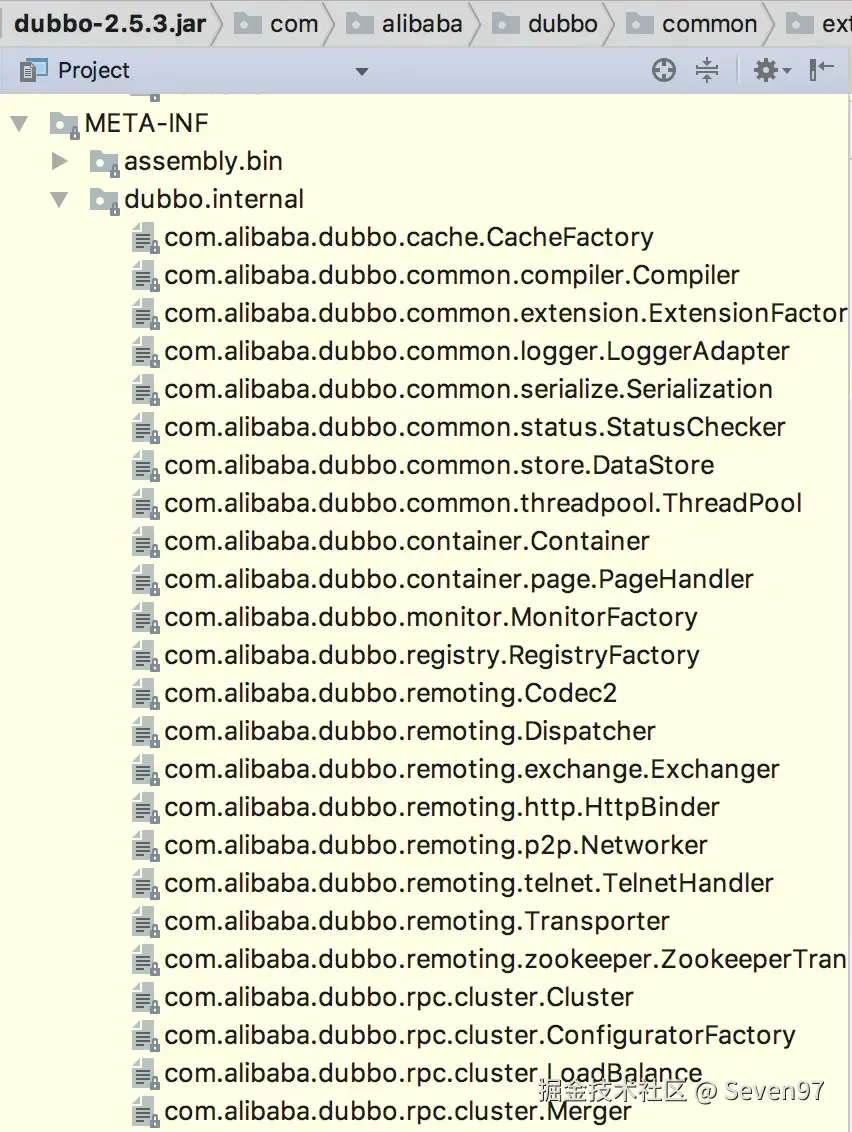
例如com.alibaba.dubbo.rpc.Protocol 文件内容
java代码解读复制代码registry=com.alibaba.dubbo.registry.integration.RegistryProtocol filter=com.alibaba.dubbo.rpc.protocol.ProtocolFilterWrapper listener=com.alibaba.dubbo.rpc.protocol.ProtocolListenerWrapper mock=com.alibaba.dubbo.rpc.support.MockProtocol injvm=com.alibaba.dubbo.rpc.protocol.injvm.InjvmProtocol dubbo=com.alibaba.dubbo.rpc.protocol.dubbo.DubboProtocol rmi=com.alibaba.dubbo.rpc.protocol.rmi.RmiProtocol hessian=com.alibaba.dubbo.rpc.protocol.hessian.HessianProtocol com.alibaba.dubbo.rpc.protocol.http.HttpProtocol com.alibaba.dubbo.rpc.protocol.webservice.WebServiceProtocol thrift=com.alibaba.dubbo.rpc.protocol.thrift.ThriftProtocol memcached=memcom.alibaba.dubbo.rpc.protocol.memcached.MemcachedProtocol redis=com.alibaba.dubbo.rpc.protocol.redis.RedisProtocol
不过观察上述文件会发现,HttpProtocol是没有对应的k值,那就是说无法通过kv对获取到其协议实现类。后面通过源码可以发现,如果没有对应的name的时候,dubbo会通过findAnnotationName方法获取一个可用的name
Dubbo SPI 使用 & 源码学习
通过获取协议的代码来分析下具体的操作过程
Protocol 获取
Protocol protocol = ExtensionLoader.getExtensionLoader(Protocol.class).getAdaptiveExtension();
java 代码解读复制代码public static ExtensionLoader getExtensionLoader(Class type) {
// 静态方法,意味着可以直接通过类调用
if (type == null)
throw new IllegalArgumentException("Extension type == null");
if(!type.isInterface()) {
throw new IllegalArgumentException("Extension type(" + type + ") is not interface!");
}
if(!withExtensionAnnotation(type)) {
throw new IllegalArgumentException("Extension type(" + type +
") is not extension, because WITHOUT @" + SPI.class.getSimpleName() + " Annotation!");
}
ExtensionLoader loader = (ExtensionLoader) EXTENSION_LOADERS.get(type);
// 从map中获取该类型的ExtensionLoader数据
if (loader == null) {
EXTENSION_LOADERS.putIfAbsent(type, new ExtensionLoader(type));
// 如果没有则,创建一个新的ExtensionLoader对象,并且以该类型存储
loader = (ExtensionLoader) EXTENSION_LOADERS.get(type);
// 再从map中获取
// 这里这样做的原因就是为了防止并发的问题,而且map本是也是个ConcurrentHashMap
}
return loader;
}
java 代码解读复制代码private ExtensionLoader(Class type) {
this.type = type;
objectFactory = (type == ExtensionFactory.class ? null : ExtensionLoader.getExtensionLoader(ExtensionFactory.class).getAdaptiveExtension());
}
// 传入的type是Protocol.class,所以需要获取ExtensionFactory.class最合适的实现类
java 代码解读复制代码public T getAdaptiveExtension() {
Object instance = cachedAdaptiveInstance.get();
if (instance == null) {
if(createAdaptiveInstanceError == null) {
synchronized (cachedAdaptiveInstance) {
instance = cachedAdaptiveInstance.get();
if (instance == null) {
try {
instance = createAdaptiveExtension();
// 创建对象,也是需要关注的函数
cachedAdaptiveInstance.set(instance);
} catch (Throwable t) {
createAdaptiveInstanceError = t;
throw new IllegalStateException("fail to create adaptive instance: " + t.toString(), t);
}
}
}
}
else {
throw new IllegalStateException("fail to create adaptive instance: " + createAdaptiveInstanceError.toString(), createAdaptiveInstanceError);
}
}
return (T) instance;
}
java 代码解读复制代码private T createAdaptiveExtension() {
try {
return injectExtension((T) getAdaptiveExtensionClass().newInstance());
// (T) getAdaptiveExtensionClass().newInstance() 创建一个具体的实例对象
// getAdaptiveExtensionClass() 生成相关的class
// injectExtension 往该对象中注入数据
} catch (Exception e) {
throw new IllegalStateException("Can not create adaptive extenstion " + type + ", cause: " + e.getMessage(), e);
}
}
java 代码解读复制代码private Class getAdaptiveExtensionClass() {
getExtensionClasses();
// 通过加载SPI配置,获取到需要的所有的实现类存储到map中
// 通过可能会去修改cachedAdaptiveClass数据,具体原因在spi配置文件解析中分析
if (cachedAdaptiveClass != null) {
return cachedAdaptiveClass;
}
return cachedAdaptiveClass = createAdaptiveExtensionClass();
}
java 代码解读复制代码private Class createAdaptiveExtensionClass() {
String code = createAdaptiveExtensionClassCode();
// 动态生成需要的代码内容字符串
ClassLoader classLoader = findClassLoader();
com.alibaba.dubbo.common.compiler.Compiler compiler = ExtensionLoader.getExtensionLoader(com.alibaba.dubbo.common.compiler.Compiler.class).getAdaptiveExtension();
return compiler.compile(code, classLoader);
// 编译,生成相应的类
}
如下代码Protocol$Adpative 整个的类就是通过createAdaptiveExtensionClassCode()方法生成的一个大字符串
java 代码解读复制代码public class Protocol$Adpative implements com.alibaba.dubbo.rpc.Protocol {
public void destroy() {throw new UnsupportedOperationException("method public abstract void com.alibaba.dubbo.rpc.Protocol.destroy() of interface com.alibaba.dubbo.rpc.Protocol is not adaptive method!");
}
public int getDefaultPort() {throw new UnsupportedOperationException("method public abstract int com.alibaba.dubbo.rpc.Protocol.getDefaultPort() of interface com.alibaba.dubbo.rpc.Protocol is not adaptive method!");
}
public com.alibaba.dubbo.rpc.Exporter export(com.alibaba.dubbo.rpc.Invoker arg0) throws com.alibaba.dubbo.rpc.RpcException {
// 暴露远程服务,传入的参数是invoke对象
if (arg0 == null) throw new IllegalArgumentException("com.alibaba.dubbo.rpc.Invoker argument == null");
if (arg0.getUrl() == null) throw new IllegalArgumentException("com.alibaba.dubbo.rpc.Invoker argument getUrl() == null");
com.alibaba.dubbo.common.URL url = arg0.getUrl();
String extName = ( url.getProtocol() == null ? "dubbo" : url.getProtocol() );
// 如果没有具体协议,则使用dubbo协议
if(extName == null) throw new IllegalStateException("Fail to get extension(com.alibaba.dubbo.rpc.Protocol) name from url(" + url.toString() + ") use keys([protocol])");
com.alibaba.dubbo.rpc.Protocol extension = (com.alibaba.dubbo.rpc.Protocol)ExtensionLoader.getExtensionLoader(com.alibaba.dubbo.rpc.Protocol.class).getExtension(extName);
return extension.export(arg0);
}
public com.alibaba.dubbo.rpc.Invoker refer(java.lang.Class arg0, com.alibaba.dubbo.common.URL arg1) throws com.alibaba.dubbo.rpc.RpcException {
// 引用远程对象,生成相对应的远程invoke对象
if (arg1 == null) throw new IllegalArgumentException("url == null");
com.alibaba.dubbo.common.URL url = arg1;
String extName = ( url.getProtocol() == null ? "dubbo" : url.getProtocol() );
if(extName == null) throw new IllegalStateException("Fail to get extension(com.alibaba.dubbo.rpc.Protocol) name from url(" + url.toString() + ") use keys([protocol])");
com.alibaba.dubbo.rpc.Protocol extension = (com.alibaba.dubbo.rpc.Protocol)ExtensionLoader.getExtensionLoader(com.alibaba.dubbo.rpc.Protocol.class).getExtension(extName);
return extension.refer(arg0, arg1);
}
}
到现在可以认为是最上面的获取protocol的方法Protocol protocol = ExtensionLoader.getExtensionLoader(Protocol.class).getAdaptiveExtension() 返回了一个代码拼接而成然后编译操作的实现类Protocol$Adpative
可是得到具体的实现呢?在com.alibaba.dubbo.rpc.Protocol extension = (com.alibaba.dubbo.rpc.Protocol)ExtensionLoader.getExtensionLoader(com.alibaba.dubbo.rpc.Protocol.class).getExtension(extName)这个代码中,当然这个是有在具体的暴露服务或者引用远程服务才被调用执行的。
java 代码解读复制代码public T getExtension(String name) {
if (name == null || name.length() == 0)
throw new IllegalArgumentException("Extension name == null");
if ("true".equals(name)) {
return getDefaultExtension();
}
Holder
if (holder == null) {
cachedInstances.putIfAbsent(name, new Holder
holder = cachedInstances.get(name);
}
// 无论是否真有数据,在cachedInstances存储的是一个具体的Holder对象
Object instance = holder.get();
if (instance == null) {
synchronized (holder) {
instance = holder.get();
if (instance == null) {
instance = createExtension(name);
// 创建对象
holder.set(instance);
}
}
}
return (T) instance;
}
java 代码解读复制代码private T createExtension(String name) {
Class clazz = getExtensionClasses().get(name);
// 获取具体的实现类的类
if (clazz == null) {
throw findException(name);
}
try {
T instance = (T) EXTENSION_INSTANCES.get(clazz);
if (instance == null) {
EXTENSION_INSTANCES.putIfAbsent(clazz, (T) clazz.newInstance());
// clazz.newInstance 才是真正创建对象的操作
instance = (T) EXTENSION_INSTANCES.get(clazz);
}
injectExtension(instance);
// 往实例中反射注入参数
Set> wrapperClasses = cachedWrapperClasses;
if (wrapperClasses != null && wrapperClasses.size() > 0) {
for (Class wrapperClass : wrapperClasses) {
instance = injectExtension((T) wrapperClass.getConstructor(type).newInstance(instance));
}
}
return instance;
} catch (Throwable t) {
throw new IllegalStateException("Extension instance(name: " + name + ", class: " +
type + ") could not be instantiated: " + t.getMessage(), t);
}
}
到这一步就可以认为是dubbo的spi加载整个的过程完成了,整个链路有些长,需要好好的梳理一下
SPI配置文件解析
上文说到getExtensionClasses完成对spi文件的解析
java 代码解读复制代码private Map> loadExtensionClasses() {
final SPI defaultAnnotation = type.getAnnotation(SPI.class);
// 查看该类是否存在SPI注解信息
if(defaultAnnotation != null) {
String value = defaultAnnotation.value();
if(value != null && (value = value.trim()).length() > 0) {
String[] names = NAME_SEPARATOR.split(value);
if(names.length > 1) {
throw new IllegalStateException("more than 1 default extension name on extension " + type.getName()
+ ": " + Arrays.toString(names));
}
if(names.length == 1) cachedDefaultName = names[0];
// 设置默认的名称,如果注解的值经过切割,发现超过1个的数据,则同样会认为错误
}
}
Map> extensionClasses = new HashMap>();
loadFile(extensionClasses, DUBBO_INTERNAL_DIRECTORY);
// 加载文件
loadFile(extensionClasses, DUBBO_DIRECTORY);
loadFile(extensionClasses, SERVICES_DIRECTORY);
return extensionClasses;
}
private void loadFile(Map> extensionClasses, String dir) {
String fileName = dir + type.getName();
// type.getName就是类名称,和java的类似
try {
Enumeration urls;
ClassLoader classLoader = findClassLoader();
if (classLoader != null) {
urls = classLoader.getResources(fileName);
} else {
urls = ClassLoader.getSystemResources(fileName);
}
if (urls != null) {
while (urls.hasMoreElements()) {
java.net.URL url = urls.nextElement();
try {
BufferedReader reader = new BufferedReader(new InputStreamReader(url.openStream(), "utf-8"));
try {
String line = null;
while ((line = reader.readLine()) != null) {
final int ci = line.indexOf('#');
if (ci >= 0) line = line.substring(0, ci);
line = line.trim();
if (line.length() > 0) {
try {
String name = null;
int i = line.indexOf('=');
// 对k=v这样的格式进行分割操作,分别获取
if (i > 0) {
name = line.substring(0, i).trim();
line = line.substring(i + 1).trim();
}
if (line.length() > 0) {
Class clazz = Class.forName(line, true, classLoader);
if (! type.isAssignableFrom(clazz)) {
throw new IllegalStateException("Error when load extension class(interface: " +
type + ", class line: " + clazz.getName() + "), class "
+ clazz.getName() + "is not subtype of interface.");
}
if (clazz.isAnnotationPresent(Adaptive.class)) {
// 如果获取的类包含了Adaptive注解
if(cachedAdaptiveClass == null) {
cachedAdaptiveClass = clazz;
} else if (! cachedAdaptiveClass.equals(clazz)) {
// 已经存在了该数据,现在又出现了,则抛出异常
throw new IllegalStateException("More than 1 adaptive class found: "
+ cachedAdaptiveClass.getClass().getName()
+ ", " + clazz.getClass().getName());
}
} else { // 不包含Adaptive注解信息
try {
clazz.getConstructor(type);
// 查看构造函数是否包含了type的类型参数
// 如果不存在,则抛出NoSuchMethodException异常
Set> wrappers = cachedWrapperClasses;
if (wrappers == null) {
cachedWrapperClasses = new ConcurrentHashSet>();
wrappers = cachedWrapperClasses;
}
wrappers.add(clazz);
// 往wrappers中添加该类
} catch (NoSuchMethodException e) {
clazz.getConstructor();
if (name == null || name.length() == 0) {
// 没用名字的那种,也就是不存在k=v这种样式
// 例如上面的HttpProtocol
name = findAnnotationName(clazz);
// 查看该类是否存在注解
if (name == null || name.length() == 0) {
if (clazz.getSimpleName().length() > type.getSimpleName().length()
&& clazz.getSimpleName().endsWith(type.getSimpleName())) {
name = clazz.getSimpleName().substring(0, clazz.getSimpleName().length() - type.getSimpleName().length()).toLowerCase();
} else {
throw new IllegalStateException("No such extension name for the class " + clazz.getName() + " in the config " + url);
}
}
}
String[] names = NAME_SEPARATOR.split(name);
// 可能存在多个,切割开
if (names != null && names.length > 0) {
Activate activate = clazz.getAnnotation(Activate.class);
if (activate != null) {
// 如果类存在Activate的注解信息
cachedActivates.put(names[0], activate);
}
for (String n : names) {
if (! cachedNames.containsKey(clazz)) {
cachedNames.put(clazz, n);
}
Class c = extensionClasses.get(n);
if (c == null) {
extensionClasses.put(n, clazz);
// 往容器中填充该键值对信息,k和v
} else if (c != clazz) {
// 存在多个同名扩展类,则抛出异常信息
throw new IllegalStateException("Duplicate extension " + type.getName() + " name " + n + " on " + c.getName() + " and " + clazz.getName());
}
}
}
}
}
}
} catch (Throwable t) {
IllegalStateException e = new IllegalStateException("Failed to load extension class(interface: " + type + ", class line: " + line + ") in " + url + ", cause: " + t.getMessage(), t);
exceptions.put(line, e);
}
}
} // end of while read lines
} finally {
reader.close();
}
} catch (Throwable t) {
logger.error("Exception when load extension class(interface: " +
type + ", class file: " + url + ") in " + url, t);
}
} // end of while urls
}
} catch (Throwable t) {
logger.error("Exception when load extension class(interface: " +
type + ", description file: " + fileName + ").", t);
}
}
这样完成了对spi配置文件的整个的扫描过程了
评论记录:
回复评论: