
 点击上方↑↑↑蓝字关注我们~
点击上方↑↑↑蓝字关注我们~

「2019 Python开发者日」7折优惠最后2天,请扫码咨询 ↑↑↑
译者 | Major
出品 | AI科技大本营(ID:rgznai100)
TensorFlow已经发展成为事实上的ML(机器学习)平台,在业界和研究领域都很流行。对TensorFlow的需求和支持促成了一系列围绕培训和服务ML模型的OSS库、工具和框架。TensorFlow Serving是一个构建在分布式生产环境中、主要为ML模型提供推理服务的项目。
Mux在其基础设施的几个部分中使用TensorFlow Serving,我们之前已经讨论过使用TensorFlow来实现按标题编码(per-title-encoding)功能。今天,我们将重点关注通过优化预测服务器和客户端来改善延迟的技术。模型预测通常是“在线”操作(在关键的应用请求路径上),因此我们的主要优化目标是以尽可能低的延迟处理大量的请求。
首先,让我们简要介绍一下TensorFlow Serving。
什么是TensorFlow Serving?
TensorFlow Serving提供了灵活的服务器架构,旨在部署和服务ML模型。一旦模型经过训练并可以用于预测,TensorFlow Serving需要将模型导出到可服务类(Servable)兼容格式。
Servable是包装TensorFlow对象的中心抽象。例如,模型可以表示为一个或多个Servable。因此,Servable是客户端用于执行计算(如推理)的底层对象。Servable的大小很重要,由于较小的模型使用更少的内存、更少的存储,因此将有更快的加载时间(加载时间更短)。Servable要求模型以SavedModel格式加载,并使用PerdictAPI提供服务。
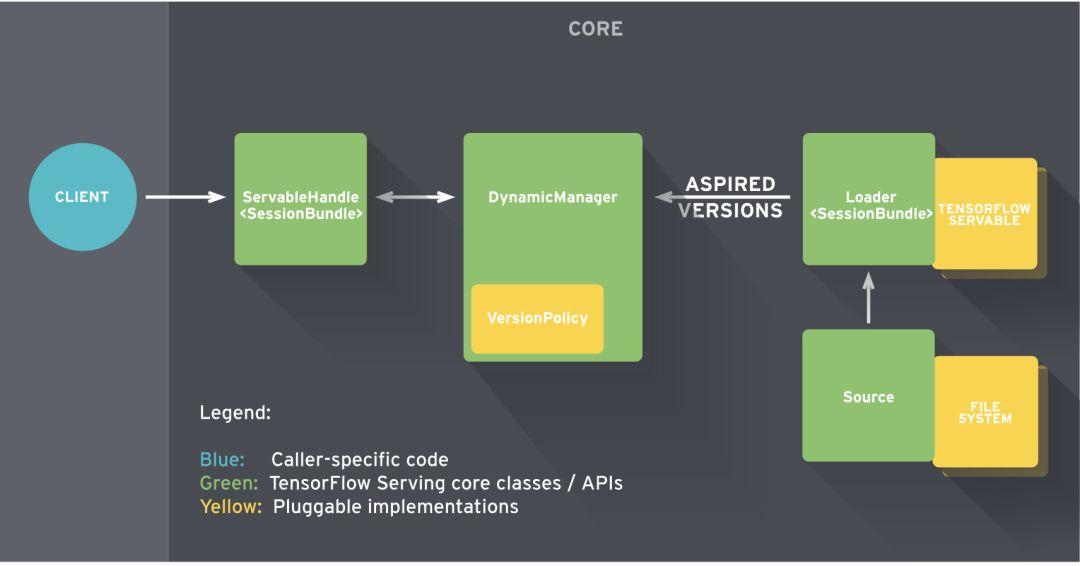
TensorFlow Serving将核心服务组件组合在一起,构建一个GRPC/HTTP服务器。该服务器可以服务多个ML模型(或多个版本),并提供监测组件和可配置的体系结构。
Tensorflow Serving and Docker
让我们使用标准的TensorFlow Serving获得基线预测性能延迟指标(未使用CPU优化)。
首先,从TensorFlow Docker hub提取最新的服务映像文件:
docker pull tensorflow/serving:latest
在这篇文章中,所有的容器都运行在一个4核、15 GB、Ubuntu 16.04主机上。
将TensorFlow模型导出到SavedModel格式
使用TensorFlow训练模型时,可以将输出保存为可变检查点(磁盘上的文件)。推理可以通过恢复模型检查点或在其转换的静态图(二进制)上直接运行。
为了使用TensorFlow服务这些模型,必须静态图导出到SavedModel格式。TensorFlow文档可查询以SavedModel格式导出预训练模型的示例。
TensorFlow还提供了一系列官方和研究模型作为实验、研究或生产的入门资料。
例如,我们将使用深残余网络(ResNet)模型,可用于对ImageNet的1000个类的数据集进行分类。下载预训练 ResNet-50 v2模型,特别是 channels_last (NHWC)卷积SavedModel,这对于CPU来说通常更好。
在以下结构中复制RestNet模型目录:
models/
1/
saved_model.pb
variables/
variables.data-00000-of-00001
variables.index
TensorFlow Serving按数字排序的目录结构管理模型版本。在本例中,目录1/对应于模型版本1,其中包含模型体系结构。saved_model.pb以及模型权重(变量)的快照。
加载和服务SavedModel
下面的命令在docker容器中启动一个TensorFlow模型服务器。为了加载SavedModel,需要将模型的主机目录mount到预期的容器目录中。
docker run -d -p 9000:8500 \
-v $(pwd)/models:/models/resnet -e MODEL_NAME=resnet \
-t tensorflow/serving:latest
检查容器日志,确定ModelServer正在运行并可以在GRPC和HTTP端点上为resnet模型提供服务:
I tensorflow_serving/core/loader_harness.cc:86] Successfully loaded servable version {name: resnet version: 1}
I tensorflow_serving/model_servers/server.cc:286] Running gRPC ModelServer at 0.0.0.0:8500 ...
I tensorflow_serving/model_servers/server.cc:302] Exporting HTTP/REST API at:localhost:8501 ...
预测客户端
TensorFlow将API服务模式定义为协议缓冲器(protobuf)。预测API的gRPC客户端用例会被打包为tensorflow_serving.apis Python包。考虑到实用功能,我们还需要tensorflow Python包。
让我们安装倚赖项(dependencies)创建一个简单的客户端:
virtualenv .env && source .env/bin/activate && \
pip install numpy grpcio opencv-python tensorflow tensorflow-serving-api
ResNet-50 v2模型要求浮点Tensor输入应采用Channel_last(NHWC)格式的数据结构。因此,输入图像是使用OpenCV-python读取的,它以32位浮点数据类型加载到numpy数组(高度x宽度x通道)中。下面的脚本创建预测客户端存根,并将JPEG图像数据加载到numpy数组中,然后转换为TensorProto以发出GRPC预测请求:
#!/usr/bin/env python
from __future__ import print_function
import argparse
import numpy as np
import time
tt = time.time()
import cv2
import tensorflow as tf
from grpc.beta import implementations
from tensorflow_serving.apis import predict_pb2
from tensorflow_serving.apis import prediction_service_pb2
parser = argparse.ArgumentParser(description='incetion grpc client flags.')
parser.add_argument('--host', default='0.0.0.0', help='inception serving host')
parser.add_argument('--port', default='9000', help='inception serving port')
parser.add_argument('--image', default='', help='path to JPEG image file')
FLAGS = parser.parse_args()
def main():
# create prediction service client stub
channel = implementations.insecure_channel(FLAGS.host, int(FLAGS.port))
stub = prediction_service_pb2.beta_create_PredictionService_stub(channel)
# create request
request = predict_pb2.PredictRequest()
request.model_spec.name = 'resnet'
request.model_spec.signature_name = 'serving_default'
# read image into numpy array
img = cv2.imread(FLAGS.image).astype(np.float32)
# convert to tensor proto and make request
# shape is in NHWC (num_samples x height x width x channels) format
tensor = tf.contrib.util.make_tensor_proto(img, shape=[1]+list(img.shape))
request.inputs['input'].CopyFrom(tensor)
resp = stub.Predict(request, 30.0)
print('total time: {}s'.format(time.time() - tt))
if __name__ == '__main__':
main()
使用JPEG图像作为输入,运行客户端的输出如下所示:
python tf_serving_client.py --image=images/pupper.jpg
total time: 2.56152906418s
输出Tensor的预测结果为一个整数值和各特征的概率。
outputs {
key: "classes"
value {
dtype: DT_INT64
tensor_shape {
dim {
size: 1
}
}
int64_val: 238
}
}
outputs {
key: "probabilities"
...
对于单个请求,这种预测延迟是不可接受的。然而,这并非完全出乎意料;默认的TensorFlow二进制程序的目标是支持最广泛的硬件以覆盖绝大多数用例。您可能已经从标准的TensorFlow容器日志中注意到:
I external/org_tensorflow/tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
这表明TensorFlow二进制程序运行在不兼容的CPU平台上,而该平台没有为其进行优化。
构建CPU优化服务二进制代码
根据 TensorFlow文献资料,建议从源代码编译TensorFlow,并采用运行二进制文件的主机平台的CPU提供的所有优化。TensorFlow给出了Build选项标志,以便为特定于平台的CPU指令集构建二进制代码:
指令集 | 标志 |
AVX | -Copt=-mavx |
AVX 2 | -Copt=-mavx 2 |
FMA | --copt=-mfma |
SSE 4.1 | -Copt=-msse4.1 |
SSE 4.2 | -Copt=-msse4.2 |
全部由处理器支持 | --copt=-march=native |
克隆TensorFlow固定到特定版本。在这种情况下,我们将使用1.13(发表此文时的最新版本):
USER=$1
TAG=$2
TF_SERVING_VERSION_GIT_BRANCH="r1.13"
git clone --branch="$TF_SERVING_VERSION_GIT_BRANCH" https://github.com/tensorflow/serving
TensorFlow Serving映像使用Bazel作为Build工具。针对特定处理器CPU指令集的生成目标可以用如下方式指定:
TF_SERVING_BUILD_OPTIONS="--copt=-mavx --copt=-mavx2 --copt=-mfma --copt=-msse4.1 --copt=-msse4.2"
如果内存有限制,则使用--local_resources=2048,.5,1.0标志。参考TensorFlow与Docker联合服务和Bazel docs的文献作为这些构建标志上的资源。
使用开发图像建立serving image作为服务基类:
USER=$1
TAG=$2
TF_SERVING_VERSION_GIT_BRANCH="r1.13"
git clone --branch="${TF_SERVING_VERSION_GIT_BRANCH}" https://github.com/tensorflow/serving
TF_SERVING_BUILD_OPTIONS="--copt=-mavx --copt=-mavx2 --copt=-mfma --copt=-msse4.1 --copt=-msse4.2"
cd serving && \
docker build --pull -t $USER/tensorflow-serving-devel:$TAG \
--build-arg TF_SERVING_VERSION_GIT_BRANCH="${TF_SERVING_VERSION_GIT_BRANCH}" \
--build-arg TF_SERVING_BUILD_OPTIONS="${TF_SERVING_BUILD_OPTIONS}" \
-f tensorflow_serving/tools/docker/Dockerfile.devel .
cd serving && \
docker build -t $USER/tensorflow-serving:$TAG \
--build-arg TF_SERVING_BUILD_IMAGE=$USER/tensorflow-serving-devel:$TAG \
-f tensorflow_serving/tools/docker/Dockerfile .
ModelServer可以用TensorFlow专用标志配置以启用会话并行性。以下选项配置两个线程池并行执行:
intra_op_parallelism_threads
控制用于单个操作并行执行的最大线程数。
用于具有固有非倚赖子操作的并行执行。
inter_op_parallelism_threads
控制独立的不同操作并行执行的最大线程数。
对TensorFlow Graph的操作彼此独立,因此可以在不同的线程上运行。
这两个选项的默认值设置为0。这意味着,系统选择一个适当的数字,这通常需要每个CPU核心有一个线程可用。但是,对于多核CPU并行性,我们可以手动控制。
接下来,按照与之前类似的方式启动服务容器,这一次使用从源代码编译的docker映像,并使用TensorFlow特定的CPU优化标志:
docker run -d -p 9000:8500 \
-v $(pwd)/models:/models/resnet -e MODEL_NAME=resnet \
-t $USER/tensorflow-serving:$TAG \
--tensorflow_intra_op_parallelism=4 \
--tensorflow_inter_op_parallelism=4
容器日志应该不显示CPU guard告警。在不更改任何代码的情况下,运行相同的预测请求会使预测延迟降低约35.8%:
python tf_serving_client.py --image=images/pupper.jpg
total time: 1.64234706879s
提高预测客户端的速度
我们能做得更好吗?服务器端已经为其CPU平台进行了优化,但超过1s的预测延迟似乎仍然太高。
问题是,加载tensorflow_serving和tensorflow库确实会导致这个问题。每次调用tf.contrib.util.make_tensor_proto同时也增加了不必要的延迟开销。
“等等”,你可能在想。“难道我不需要TensorFlow Python包向TensorFlow Server提出预测请求吗?”
答案很简单:确实如此,实际上不需要tensorflow或tensorflow_serving包发出预测请求。
如前所述,TensorFlow预测API被定义为Protobufs。因此,可以通过生成必要的tensorflow和tensorflow_serving protobuf python 存根(stubs)。这就避免了对客户机本身整个(巨大)TensorFlow库的调用。
首先,舍弃tensorflow和tensorflow_serving依赖项,添加grpcio-tools包。
pip uninstall tensorflow tensorflow-serving-api && \
pip install grpcio-tools==1.0.0
复制tensorflow/tensorflow和tensorflow/serving存储库,并将以下Protobuf文件复制到客户端项目中:
tensorflow/serving/
tensorflow_serving/apis/model.proto
tensorflow_serving/apis/predict.proto
tensorflow_serving/apis/prediction_service.proto
tensorflow/tensorflow/
tensorflow/core/framework/resource_handle.proto
tensorflow/core/framework/tensor_shape.proto
tensorflow/core/framework/tensor.proto
tensorflow/core/framework/types.proto
将上述原型文件复制到protos/目录并保存原始路径:
protos/
tensorflow_serving/
apis/
*.proto
tensorflow/
core/
framework/
*.proto
为了简单起见,prediction_service.proto(预测服务)可以简化为只实现Predict RPC。这避免了引入服务中定义的其他RPC的嵌套依赖关系。这里是简化后的prediction_service.proto.
使用grpcio.tools.protoc:
PROTOC_OUT=protos/
PROTOS=$(find . | grep "\.proto$")
for p in $PROTOS; do
python -m grpc.tools.protoc -I . --python_out=$PROTOC_OUT --grpc_python_out=$PROTOC_OUT $p
done
现在可以删除整个tensorflow_serving模块:
from tensorflow_serving.apis import predict_pb2
from tensorflow_serving.apis import prediction_service_pb2
中生成的Probufs替换为protos/tensorflow_serving/apis:
from protos.tensorflow_serving.apis import predict_pb2
from protos.tensorflow_serving.apis import prediction_service_pb2
为了使用帮助函数make_tensor_proto,导入了TensorFlow库,也就是用于包装python/numpy对象成为TensorProto对象。
因此,我们可以替换以下依赖项和代码片段:
import tensorflow as tf
...
tensor = tf.contrib.util.make_tensor_proto(features)
request.inputs['inputs'].CopyFrom(tensor)
导入Protobuf,构建TensorProto对象:
from protos.tensorflow.core.framework import tensor_pb2
from protos.tensorflow.core.framework import tensor_shape_pb2
from protos.tensorflow.core.framework import types_pb2
...
tensor_shape = [1]+list(img.shape)
dims = [tensor_shape_pb2.TensorShapeProto.Dim(size=dim) for dim in tensor_shape]
tensor_shape = tensor_shape_pb2.TensorShapeProto(dim=dims)
tensor = tensor_pb2.TensorProto(
dtype=types_pb2.DT_FLOAT,
tensor_shape=tensor_shape,
float_val=list(img.reshape(-1)))
request.inputs['inputs'].CopyFrom(tensor)
完整的python脚本请访问这里。运行更新后的初始客户端,该客户端向优化的TensorFlow发出预测请求:
python tf_inception_grpc_client.py --image=images/pupper.jpg
total time: 0.58314920859s
下图显示了针对标准、优化的TensorFlow和客户端10次运行的预测请求的延迟:
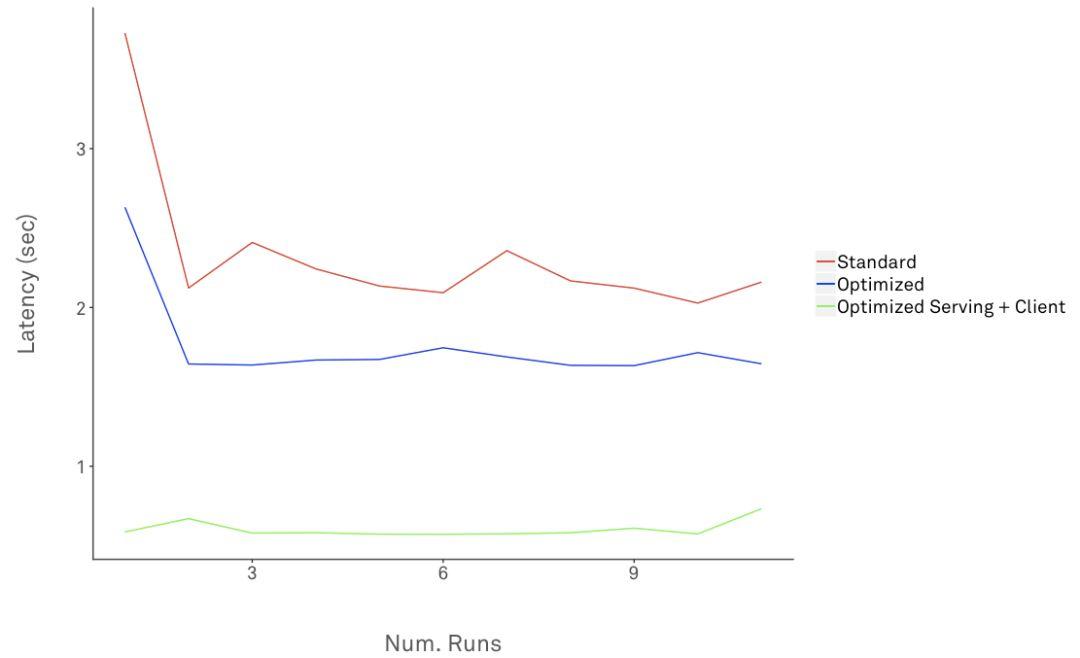
显然,从标准TensorFlow到优化版的平均延迟下降了约70.4%。
优化预测吞吐量
TensorFlow Serving也可以配置为高吞吐量处理。对吞吐量的优化通常用于“脱机”批处理,在这些批处理中,不需要有严格的延迟阀值。
(1) 服务器端批处理
服务器端批处理由TensorFlow Serving支持开箱即用。.
延迟和吞吐量之间的权衡取决于所支持的批处理参数。TensorFlow批处理最有效地利用硬件加速器承诺(保证)的高吞吐量。
若要启用批处理,请设置--enable_batching和--batching_parameters_file标志。可以将批处理参数设置为SessionBundleConfig。对于只使用CPU的系统,请考虑设置num_batch_threads可以使用的核心数量。批处理配置方法可访问这里,使用支持GPU的系统。
当服务器端的批处理请求全部到达时,推理请求在内部合并为单个大请求(Tensor),并在合并请求上运行一个TensorFlow会话。在单个会话上运行批量请求,可以真正利用CPU/GPU并行性。
批处理过程中需要考虑的Tensorflow Serving Batching进程:
在客户端使用异步请求,以在服务器端进行批处理
在CPU/GPU上加入模型图组件,加速批处理
在同一服务器服务多个模型时,对预测请求进行交织处理
对于“脱机”大容量推理处理,强烈推荐批处理。
(2) 客户端批处理
客户端的批处理是将多个输入组合在一起,以发出单个请求。
由于ResNet模型要求以NHWC格式输入(第一个维度是输入的数量),所以我们可以将多个输入图像聚合到一个RPC请求中:
...
batch = []
for jpeg in os.listdir(FLAGS.images_path):
path = os.path.join(FLAGS.images_path, jpeg)
img = cv2.imread(path).astype(np.float32)
batch.append(img)
...
batch_np = np.array(batch).astype(np.float32)
dims = [tensor_shape_pb2.TensorShapeProto.Dim(size=dim) for dim in batch_np.shape]
t_shape = tensor_shape_pb2.TensorShapeProto(dim=dims)
tensor = tensor_pb2.TensorProto(
dtype=types_pb2.DT_FLOAT,
tensor_shape=t_shape,
float_val=list(batched_np.reshape(-1)))
request.inputs['inputs'].CopyFrom(tensor)
对N个图像的批处理,响应(相应)的输出Tensor对于请求批处理中相同数量的输入具有预测结果,在这种情况下,N=2(以下是N=2的情况):
outputs {
key: "classes"
value {
dtype: DT_INT64
tensor_shape {
dim {
size: 2
}
}
int64_val: 238
int64_val: 121
}
}
...
硬件加速
关于GPU:
对于训练,GPU可以更直观地利用并行化,因为构建深层神经网络需要大量的计算才能得到最优解。
然而,推理的情况并不总是如此。很多时候,当图形执行步骤放置在GPU设备上时,CNN的推理就会加快。然而,挑选能够优化性价比的硬件,需要进行严格的测试、深入的技术和成本分析。硬件加速并行化对于“脱机”推理批处理(海量卷)更有价值。
在引入GPU处理之前,要考虑业务需求,并对收益(严格延迟、高吞吐量)进行彻底的成本(货币、操作、技术)分析。
原文链接:
https://mux.com/blog/tuning-performance-of-tensorflow-serving-pipeline/
(本文为 AI科技大本营编译文章,转载请微信联系 1092722531)
◆
精彩推荐
◆
「2019 Python开发者日」7折票限时开售!这一次我们依然“只讲技术,拒绝空谈”10余位一线Python技术专家共同打造一场硬核技术大会。更有深度培训实操环节,为开发者们带来更多深度实战机会。
目前演讲嘉宾议题已确认,扫描海报二维码,即刻抢购7折优惠票价!更多详细信息请咨询13581782348(微信同号)。

推荐阅读:

你也可以点击阅读原文,查看大会详情。
评论记录:
回复评论: