
第一:了解什么是YOLOv5算法
这里说很详细,你自己看就可以了。写论文你绝对用得上,但既然称之为Yolov5,也有很多非常不错的地方值得我们学习。不过因为Yolov5的网络结构和Yolov3、Yolov4相比,不好可视化。
1.Yolov5四种网络结构
Yolov5官方代码中,给出的目标检测网络中一共有4个版本,分别是Yolov5s、Yolov5m、Yolov5l、Yolov5x四个模型。学习一个新的算法,最好在脑海中对算法网络的整体架构有一个清晰的理解。但比较尴尬的是,Yolov5代码中给出的网络文件是yaml格式,和原本Yolov3、Yolov4中的cfg不同。因此无法用netron工具直接可视化的查看网络结构,造成有的同学不知道如何去学习这样的网络。
比如下载了Yolov5的四个pt格式的权重模型:

- Yolov5网络结构图
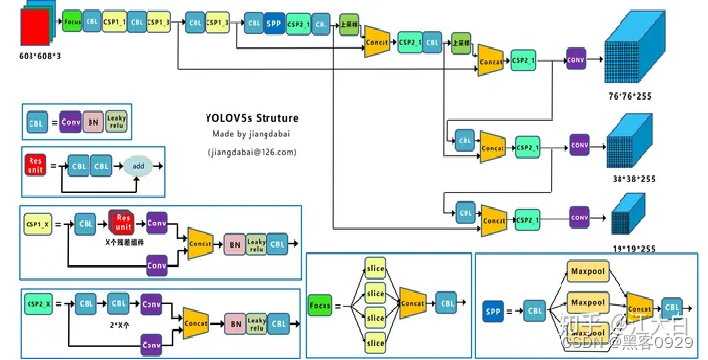
2.Yolov5核心基础内容
Yolov5的结构和Yolov4很相似,但也有一些不同,大白还是按照从整体到细节的方式,对每个板块进行讲解。
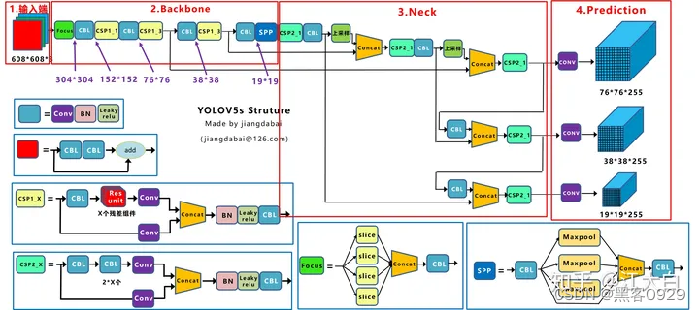
上图即Yolov5的网络结构图,可以看出,还是分为输入端、Backbone、Neck、Prediction四个部分。
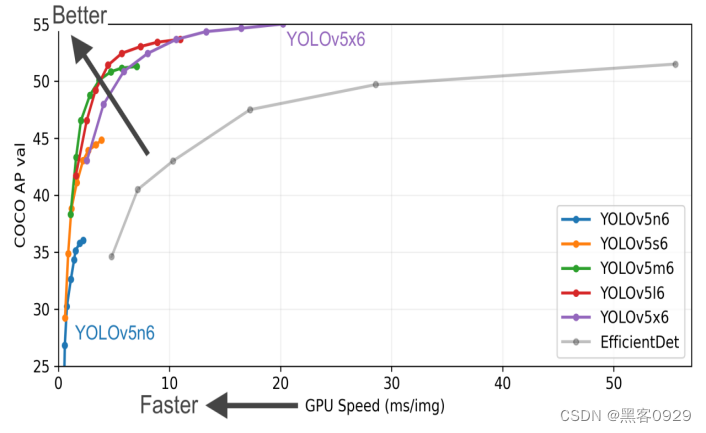
上面是Yolov5作者的算法性能测试图:
1、Yolov5的项目结构
看这篇博客:你会学会很多,写论问也用得上。(博主连接如下)
YOLOv5源码逐行超详细注释与解读(1)——项目目录结构解析-CSDN博客


2、YOLO总体架构图
-
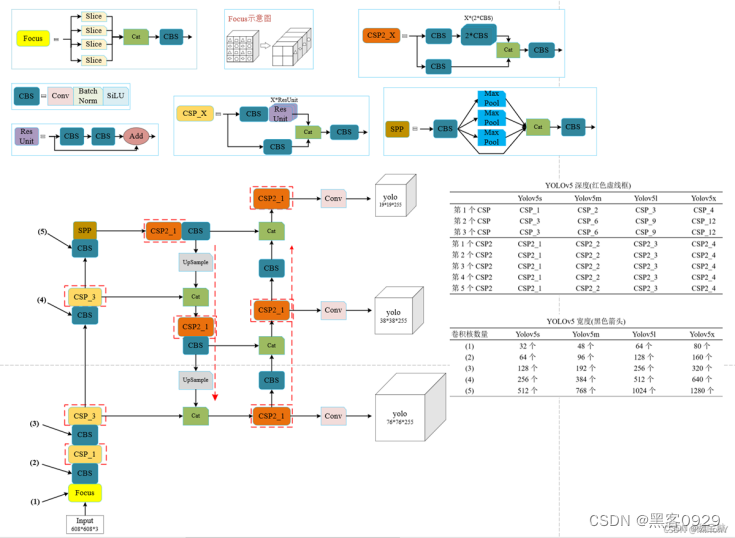 3、训练自己的自定义数据集YOLOv5。
3、训练自己的自定义数据集YOLOv5。
- # coding:utf-8
- # ----------------------------------------------------------------------------
- # Pytorch multi-GPU YOLOV5 based UMT
-
- from __future__ import absolute_import
- from __future__ import division
- from __future__ import print_function
-
-
- import argparse
- import logging
- import math
- import os
- import random
- import sys
- import time
- import warnings
- import yaml
- import numpy as np
- from copy import deepcopy
- from pathlib import Path
- from threading import Thread
- from tqdm import tqdm
-
- import torch.distributed as dist
- import torch.nn as nn
- import torch.nn.functional as F
- import torch.optim as optim
- import torch.optim.lr_scheduler as lr_scheduler
- import torch.utils.data
-
- from torch.cuda import amp
- from torch.nn.parallel import DistributedDataParallel as DDP
- from torch.utils.tensorboard import SummaryWriter
-
- FILE = Path(__file__).absolute()
- sys.path.append(FILE.parents[0].as_posix()) # add yolov5/ to path
-
- import ssda_yolov5_test as test # for end-of-epoch mAP
- from models.experimental import attempt_load
- from models.yolo import Model
-
- from utils.autoanchor import check_anchors
- from utils.datasets import create_dataloader
- from utils.datasets_single import create_dataloader_single
- from utils.google_utils import attempt_download
- from utils.loss import ComputeLoss
-
- from utils.torch_utils import ModelEMA, WeightEMA, select_device, intersect_dicts, torch_distributed_zero_first, de_parallel
- from utils.wandb_logging.wandb_utils import WandbLogger, check_wandb_resume
- from utils.plots import plot_images, plot_labels, plot_results, plot_evolution
- from utils.metrics import fitness
-
- from utils.general import labels_to_class_weights, increment_path, labels_to_image_weights, init_seeds, \
- strip_optimizer, get_latest_run, check_dataset, check_file, check_git_status, check_img_size, \
- check_requirements, print_mutation, set_logging, one_cycle, colorstr, \
- non_max_suppression, check_dataset_umt, xyxy2xywhn
-
-
- logger = logging.getLogger(__name__)
- LOCAL_RANK = int(os.getenv('LOCAL_RANK', -1)) # https://pytorch.org/docs/stable/elastic/run.html
- RANK = int(os.getenv('RANK', -1))
- WORLD_SIZE = int(os.getenv('WORLD_SIZE', 1))
-
- # hyp means path/to/hyp.yaml or hyp dictionary
- def train(hyp, opt, device):
-
- save_dir, epochs, batch_size, weights, single_cls, evolve, data, cfg, resume, notest, nosave, workers, = \
- opt.save_dir, opt.epochs, opt.batch_size, opt.weights, opt.single_cls, opt.evolve, opt.data, opt.cfg, \
- opt.resume, opt.notest, opt.nosave, opt.workers
-
- teacher_alpha, conf_thres, iou_thres, max_gt_boxes, lambda_weight, student_weight, teacher_weight = \
- opt.teacher_alpha, opt.conf_thres, opt.iou_thres, opt.max_gt_boxes, opt.lambda_weight, \
- opt.student_weight, opt.teacher_weight
-
- all_shift = opt.consistency_loss
-
- # Directories
- save_dir = Path(save_dir)
- wdir = save_dir / 'weights'
- wdir.mkdir(parents=True, exist_ok=True) # make dir
- last_student, last_teacher = wdir / 'last_student.pt', wdir / 'last_teacher.pt'
- best_student, best_teacher = wdir / 'best_student.pt', wdir / 'best_teacher.pt'
- results_file = save_dir / 'results.txt'
-
- # Hyperparameters
- if isinstance(hyp, str):
- with open(hyp) as f: # default path data/hyps/hyp.scratch.yaml
- hyp = yaml.safe_load(f) # load hyps dict
- logger.info(colorstr('hyperparameters: ') + ', '.join(f'{k}={v}' for k, v in hyp.items()))
-
- # Save run settings
- with open(save_dir / 'hyp.yaml', 'w') as f:
- yaml.safe_dump(hyp, f, sort_keys=False)
- with open(save_dir / 'opt.yaml', 'w') as f:
- yaml.safe_dump(vars(opt), f, sort_keys=False)
-
- # Configure
- plots = not evolve # create plots
- cuda = device.type != 'cpu'
- init_seeds(1 + RANK)
- with open(data) as f:
- data_dict = yaml.safe_load(f) # data dict
-
- # Loggers
- loggers = {'wandb': None, 'tb': None} # loggers dict
- if RANK in [-1, 0]:
- # TensorBoard
- if not evolve:
- prefix = colorstr('tensorboard: ')
- logger.info(f"{prefix}Start with 'tensorboard --logdir {opt.project}', view at http://localhost:6006/")
- loggers['tb'] = SummaryWriter(str(save_dir))
-
- # W&B
- opt.hyp = hyp # add hyperparameters
- run_id = torch.load(weights).get('wandb_id') if weights.endswith('.pt') and os.path.isfile(weights) else None
- run_id = run_id if opt.resume else None # start fresh run if transfer learning
- wandb_logger = WandbLogger(opt, save_dir.stem, run_id, data_dict)
- loggers['wandb'] = wandb_logger.wandb
- if loggers['wandb']:
- data_dict = wandb_logger.data_dict
- weights, epochs, hyp = opt.weights, opt.epochs, opt.hyp # may update weights, epochs if resuming
-
- nc = 1 if single_cls else int(data_dict['nc']) # number of classes
- names = ['item'] if single_cls and len(data_dict['names']) != 1 else data_dict['names'] # class names
- assert len(names) == nc, '%g names found for nc=%g dataset in %s' % (len(names), nc, data) # check
- is_coco = data.endswith('coco.yaml') and nc == 80 # COCO dataset
-
- # Model
- pretrained = weights.endswith('.pt')
- # torch.cuda.empty_cache()
- # strip_optimizer(weights) # strip optimizers, this will apparently reduce the model size
- if pretrained:
- with torch_distributed_zero_first(RANK):
- weights = attempt_download(weights) # download if not found locally
- ckpt = torch.load(weights, map_location=device) # load checkpoint
- # model_student
- model_student = Model(cfg or ckpt['model'].yaml, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
- # model_teacher
- model_teacher = Model(cfg or ckpt['model'].yaml, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
- exclude = ['anchor'] if (cfg or hyp.get('anchors')) and not resume else [] # exclude keys
- state_dict = ckpt['model'].float().state_dict() # to FP32
- state_dict = intersect_dicts(state_dict, model_student.state_dict(), exclude=exclude) # intersect
- model_student.load_state_dict(state_dict, strict=False) # load
- # model_teacher.load_state_dict(state_dict, strict=False) # load
- model_teacher.load_state_dict(state_dict.copy(), strict=False) # load
- logger.info('Transferred %g/%g items from %s' % (len(state_dict), len(model_student.state_dict()), weights)) # report
- else:
- model_student = Model(cfg, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
- model_teacher = Model(cfg, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
-
-
- # Update models weights [only by this way, we can resume the old training normally...][ref models.experimental.attempt_load()]
- if student_weight != "None" and teacher_weight != "None": # update model_student and model_teacher
- torch.cuda.empty_cache()
- ckpt_student = torch.load(student_weight, map_location=device) # load checkpoint
- state_dict_student = ckpt_student['ema' if ckpt_student.get('ema') else 'model'].float().half().state_dict() # to FP32
- model_student.load_state_dict(state_dict_student, strict=False) # load
- del ckpt_student, state_dict_student
-
- ckpt_teacher = torch.load(teacher_weight, map_location=device) # load checkpoint
- state_dict_teacher = ckpt_teacher['ema' if ckpt_teacher.get('ema') else 'model'].float().half().state_dict() # to FP32
- model_teacher.load_state_dict(state_dict_teacher, strict=False) # load
- del ckpt_teacher, state_dict_teacher
-
-
-
-
- # Dataset
- with torch_distributed_zero_first(RANK):
- # check_dataset(data_dict) # check, need to be re-write or command out
- check_dataset_umt(data_dict) # check, need to be re-write or command out
- train_path_source_real = data_dict['train_source_real'] # training source dataset w labels
- train_path_source_fake = data_dict['train_source_fake'] # training target-like dataset w labels
- train_path_target_real = data_dict['train_target_real'] # training target dataset w/o labels
- train_path_target_fake = data_dict['train_target_fake'] # training source-like dataset w/o labels
- test_path_target_real = data_dict['test_target_real'] # test on target dataset w labels, should not use testset to train
- # test_path_target_real = data_dict['train_target_real'] # test on target dataset w labels, remember val in 'test_target_real'
-
-
- # Freeze
- freeze_student = [] # parameter names to freeze (full or partial)
- for k, v in model_student.named_parameters():
- v.requires_grad = True # train all layers
- if any(x in k for x in freeze_student):
- print('freezing %s' % k)
- v.requires_grad = False
- freeze_teacher = [] # parameter names to freeze (full or partial)
- for k, v in model_teacher.named_parameters():
- v.requires_grad = True # train all layers
- if any(x in k for x in freeze_teacher):
- print('freezing %s' % k)
- v.requires_grad = False
-
- # Optimizer
- nbs = 64 # nominal batch size
- accumulate = max(round(nbs / batch_size), 1) # accumulate loss before optimizing
- hyp['weight_decay'] *= batch_size * accumulate / nbs # scale weight_decay
- logger.info(f"Scaled weight_decay = {hyp['weight_decay']}")
-
- pg0, pg1, pg2 = [], [], [] # optimizer parameter groups
- for k, v in model_student.named_modules():
- if hasattr(v, 'bias') and isinstance(v.bias, nn.Parameter):
- pg2.append(v.bias) # biases
- if isinstance(v, nn.BatchNorm2d):
- pg0.append(v.weight) # no decay
- elif hasattr(v, 'weight') and isinstance(v.weight, nn.Parameter):
- pg1.append(v.weight) # apply decay
-
- if opt.adam:
- student_optimizer = optim.Adam(pg0, lr=hyp['lr0'], betas=(hyp['momentum'], 0.999)) # adjust beta1 to momentum
- else:
- student_optimizer = optim.SGD(pg0, lr=hyp['lr0'], momentum=hyp['momentum'], nesterov=True)
-
- student_optimizer.add_param_group({'params': pg1, 'weight_decay': hyp['weight_decay']}) # add pg1 with weight_decay
- student_optimizer.add_param_group({'params': pg2}) # add pg2 (biases)
- logger.info('Optimizer groups: %g .bias, %g conv.weight, %g other' % (len(pg2), len(pg1), len(pg0)))
- del pg0, pg1, pg2
-
- # UMT algorithm
- student_detection_params = []
- for key, value in model_student.named_parameters():
- if value.requires_grad:
- student_detection_params += [value]
- teacher_detection_params = []
- for key, value in model_teacher.named_parameters():
- if value.requires_grad:
- teacher_detection_params += [value]
- value.requires_grad = False
- teacher_optimizer = WeightEMA(teacher_detection_params, student_detection_params, alpha=teacher_alpha)
-
-
- # For debugging
- # for k, v in model_student.named_parameters():
- # print(k, v.requires_grad)
- # for k, v in model_teacher.named_parameters():
- # print(k, v.requires_grad)
-
-
- # Scheduler https://arxiv.org/pdf/1812.01187.pdf
- # https://pytorch.org/docs/stable/_modules/torch/optim/lr_scheduler.html#OneCycleLR
- if opt.linear_lr:
- lf = lambda x: (1 - x / (epochs - 1)) * (1.0 - hyp['lrf']) + hyp['lrf'] # linear
- else:
- lf = one_cycle(1, hyp['lrf'], epochs) # cosine 1->hyp['lrf']
- scheduler = lr_scheduler.LambdaLR(student_optimizer, lr_lambda=lf)
- # plot_lr_scheduler(

评论记录:
回复评论: