


作者 | 王晔倞
责编 | 郭 芮
如何挑战百万年薪的人工智能!
https://edu.csdn.net/topic/ai30?utm_source=csdn_bw
在开始这个话题之前,先问一下大家,你们觉得PPT这玩意对搞技术的同学是否有意义?或者把PPT写好,是不是一项必须掌握的技能?
相信对这些问题,每个人都会根据自己的认知给出不同的答案。这不,此前就有与PPT相关的话题火了一把。
在年初的新东方年会节目上,6名员工冒着被 “开” 的风险吐槽公司内部管理问题,比如「干活的累死累活,有成果那又如何,到头来干不过写PPT的」,再比如「什么独立人格,什么诚信负责,只会为老板的朋友圈高歌」,真是高潮迭起,直怼BOSS的节奏,把 “光会写一手漂亮的PPT,不干实事” 的人给撸了个四门兜底。

这种敢在大庭广众下,当着BOSS的面进行宣泄,竟敢采用调侃的方式抨击中高级管理层腐败、官僚化,光是这股勇气就值得赞扬。
但这也从另一个角度反应出某些普遍认知,基本可分为两类:
-
有的人觉得,PPT写得好的人,基本都是 ‘大忽悠’,尤其搞技术的小伙伴都觉得咱们是靠能力(或技术)混饭吃,没能力的,才需要靠PPT瞎BB。
-
有的人觉得,PPT写得好是综合能力的体现,有利于增加人与人之间的信任与加速价值观传递。

或许是技术转型管理的缘故,又或许是企业与个人的阶段性发展需要,在2013年至2018年期间,我曾在PPT这事上投入过很大的精力。
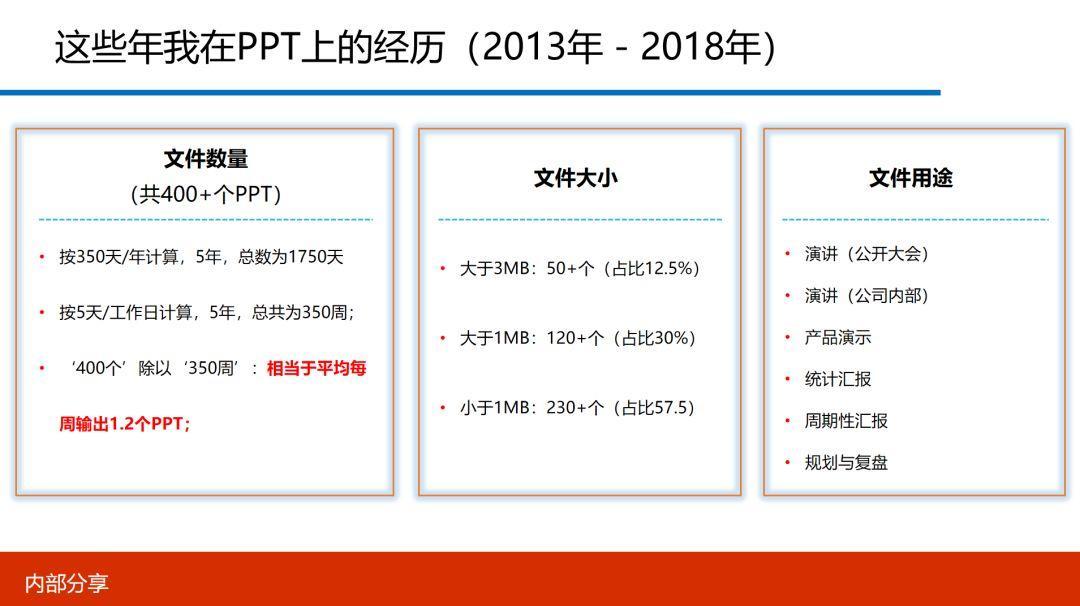
先说下数量,在这五年以内,我写了400多个PPT。如果按一年350天来计算,五年一共是1750天,然后按每周5个工作日来算,一共是350周,以此推算,相当于平均每周输出1.2个PPT的节奏。
再说下质量,我用文件的大小来衡量。虽然文件大并不代表质量高,但至少可以证明PPT中文字的占比较少,因为图文越多,文件就越大嘛。在这400多个PPT中,大于3MB的有50多个,占12.5%,大于1MB并小于3MB的有120多个,占30%,而小于1MB的有230多个,占57.5%。粗略统计,至少有超过40%的PPT,我至少需要投入3个小时以上才能大功告成。
最后简单陈述下这些PPT的用途,除了技术大会的演讲之外,还有就是公司内部的分享材料、产品演示与周期报告,以及规划及复盘。
客观的讲,如果是乙方公司,这些数据并没有什么可惊奇,为什么呢?因为无论售前、售中还是售后,都需要依靠PPT进行呈现。但对于在甲方公司工作的人来说,取得这些数据,至少能证明我是付出过许多心血的。
说到这可能有人会说,你把大部分时间都用来写PPT了,那你的工作还干得好吗?
是啊,因为把大量的时间花在了写PPT上,而并没有去干一些实际的事情。就像有人说的那样,时间对每个人都是公平的,谁也不比谁多或少,但有人拿去睡觉,有人拿去看书与学习,而有人则拿去解决产线问题了。张小龙也曾说过,要留意那些公众号写得好的人,因为他把大部分时间投入在写公众号上,本职工作的效率与质量一定大打折扣。
这样的说法看似没啥毛病,但还是无法改变许多人对PPT写得好的人的异样看法。那为什么会产生这样的认知差异呢?
以技术圈的小伙伴为例,说下我自己的理解。
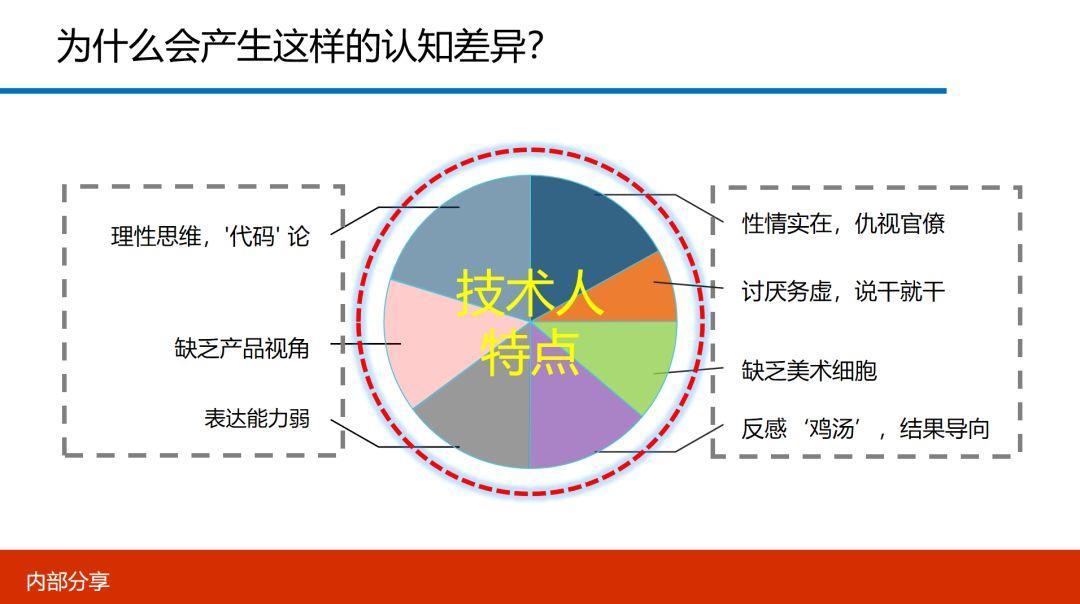
第一、偏重理性思维,机械化思考
网上曾有过个段子,老婆跟老公说,你出去帮我买一个鸡蛋,如果看到西瓜,那你也买两个,结果老公买了两个鸡蛋,为什么呢?因为老公看到了西瓜,很显然,他把西瓜看成了判断条件。
虽然这是个笑话,但这说明搞技术的人满脑袋装着的都是 IF...else... 这样的机械化思维。但这也正常,他干的就是这行,不这么思考,怎么混饭吃呢?
第二、缺乏产品视角与客户视角
许多程序员,写代码是一把好手,你让他写个产品演示,或去做个售前说明,如果不加以特殊指导或协助他做后期调整,不是把你气死,就是把客户气死。为什么?因为那份东西只有他自己能看懂,别人根本看不懂。
内容中的大部分篇基本都被技术原理、词语与拓扑信息所占据,什么客户收益?什么受益者视角?如果这是一次产品售前演示,估计这笔单子也就黄了。
第三、表达能力偏弱,不善于交流
就连在某些一线技术大会中,在听完某些分会场内容后,有些同学吐槽说,“内容还是挺干货的,但这哥们没讲好,PPT中写的内容也没get到核心点,有点可惜……”
还有面试时,许多技术同学连自我介绍都无从说起,这也是普遍现象。在我看来,如果连说话都条理不清,想要写出附有逻辑感的PPT,那是根本不可能的。
但话说回来,就因为不喜欢与人交流,不喜欢交际才选择搞IT呀,因此你会发现,搞IT的同学特别喜欢玩RPG游戏,什么角色扮演呀,什么人物性格刻画呀,他们都会觉得非常有意思。
第四、反感 ‘鸡汤’,实实在在
技术同学讲的最多一句话,“你这东西有什么意义?有什么价值?”
因为在他们眼里,什么过程,什么煽情,什么挑逗士气都没啥意义,想要什么就直说,做出来给你,你给钱,就得了。
“我们都是实在人,有事说事,没事别瞎BB,我很忙。”——这句话是不是也很耳熟?
第五、仇视官僚,痛恨务虚
很多技术同学特别喜欢 “互联网文化”,请问啥叫 “互联网文化”?有哪些地方吸引你?无非在管理上采用 “扁平化”,还特别讨厌叫什么总什么总的。
这映射出什么内心活动?我理解,哥是搞技术的,如果你技术实力没我强,就别在我面前装X,哥不服你。
所以很多人说,技术男不服管理,只服大神。也许就是这个原因吧。
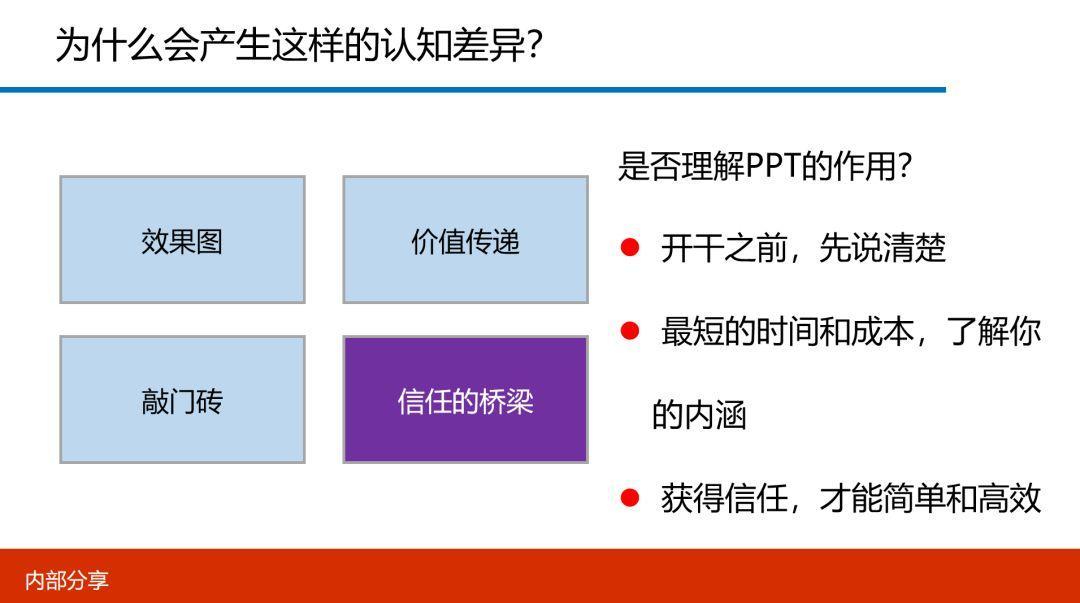
另外,许多人并不理解PPT的实际作用,我简单做了下总结。
-
效果图:类似房地产中的宣传海报,比如说要早一栋楼,不可能先造出来,肯定要先画个图让你看看,你觉得满意了,就付个款,买个期房。
-
价值的传递:通过PPT把要表现出来的价值观通过几张PPT快速地告诉你。
-
敲门砖:有乙方工作经验同学就更有体会,很多时候就是一份PPT就拿到一张订单,如果你没有这份PPT,然后……就没有然后了。
-
信任的桥梁:很多人都焦灼在 “这PPT的颜色有多酷炫,或动画有多醒目”,但这都是表面功夫,关键是你能否在最短的时间和成本内,把一个复杂的问题说清楚,一旦说清楚了,价值传递也清晰了,那基本的信任也就建立了,下面都没有问题了。
也就是说你的PPT写得好,体现出的是你清晰的思路,能够让决策人一看就明白。如果觉得你描述的东西很有前途,他们愿意给你做投资,但如果你的思路很清晰,想法也很独特,却无法用PPT表达出来,得不到决策层的认可,那就非常可惜了。
说到这,搞技术的小伙伴又不服了,说来说去就是投资,哥不做投资,我就是一码农,跟我有什么关系呢?
你想象一下,如果你负责A系统,今年的目标是从V1.0升级到V2.0,方案你琢磨了近半年,一旦实施成功,不仅硬件成本能下降30%,还能在研发效率上增能10%,你打算如何告诉你领导呢?自己通宵一个星期?信息系统毕竟是工程学,不是一跺脚,刷个性子就能搞定的,你还是得跟领导商量吧。如果没有一份好得PPT,你怎么说服领导给你加俩人呢?许多公司掌握实权的领导大部分都不是搞技术的,如果你手握一份能让他秒懂的PPT,估计领导看到一半便拍案而起,兴奋的跟你说 “拿100W去,好好干,小伙子有前途!”
有人说,那为什么有些人去说,领导不用看PPT就给他,对他特别信任。是啊,这就是信任,这也就是为什么许多创业者,或者跳槽去新公司,都愿意找一起共过事的人,因为彼此之间有着信任,一切自然变得简单,变得高效。

在技术圈,觉得PPT既不是能力、也不是技术的不在少数,比如说你夸某程序员说他PPT写得好,他可能会认为你的嘲笑他,甚至翻脸。再比如,某程序员代码写得不太好,但页面设计的感觉不错,许多人也会调侃他说 “看来你挺适合写PPT的,PPT工程师太棒了。”
在我看来,写好PPT并不是一件很虚的事情,而是一项很有价值的本领。
但万事皆人为,有人拿着PPT去忽悠老板,而有的人则用PPT来总结过去,描述未来。如果遇到务实且接地气的领导,说不准就直接开干了。

看完以上的内容,也许有人还是不屑一顾,觉得这些道理都明白,但我还是从内心痛恨PPT写得好的人,你能如何?
为什么呢?我来给你揭个底吧。
无非PPT写得好的人,通常比代码写得好的人收入高一些,地位和受重视程度也高一些,还管着你。而在你的刻板印象中,他们天生爱装逼,爱装腔作势。这其实就是仇富心态,就是羡慕、嫉妒、恨。

有怨恨就说出来,大过年的,大家都会理解你的。
人工智能的现状及今后发展趋势如何?
https://edu.csdn.net/topic/ai30?utm_source=csdn_bw
作者:王晔倞,18年IT从业经验,现任职好买财富平台架构部技术总监,负责好买中间件及平台化的研发及运营,团队管理和实施重大技术决策。曾任大智慧测试总监,在2年内带领团队自研了“大智慧云测试平台”,通过平台化将金融数据服务业务从瀑布式逐渐转型为DevOps。
声明:本文为作者投稿,版权归作者个人所有。
热 文 推 荐
GitHub 日收 7000 星,Windows 计算器项目开源即爆红!
☞ 5年Go语言经验薪资翻倍! 这份全球职业报告中, 区块链开发者薪资排第三, 前两名你绝对想不到!(含完整版下载资源)
System.out.println("点个好看吧!");
console.log("点个好看吧!");
print("点个好看吧!");
printf("点个好看吧!\n");
cout << "点个好看吧!" << endl;
Console.WriteLine("点个好看吧!");
Response.Write("点个好看吧!");
alert("点个好看吧!")
echo "点个好看吧!"
![]() 点击阅读原文,输入关键词,即可搜索您想要的 CSDN 文章。
点击阅读原文,输入关键词,即可搜索您想要的 CSDN 文章。
 喜欢就点击“好看”吧!
喜欢就点击“好看”吧!
 微信公众号
微信公众号

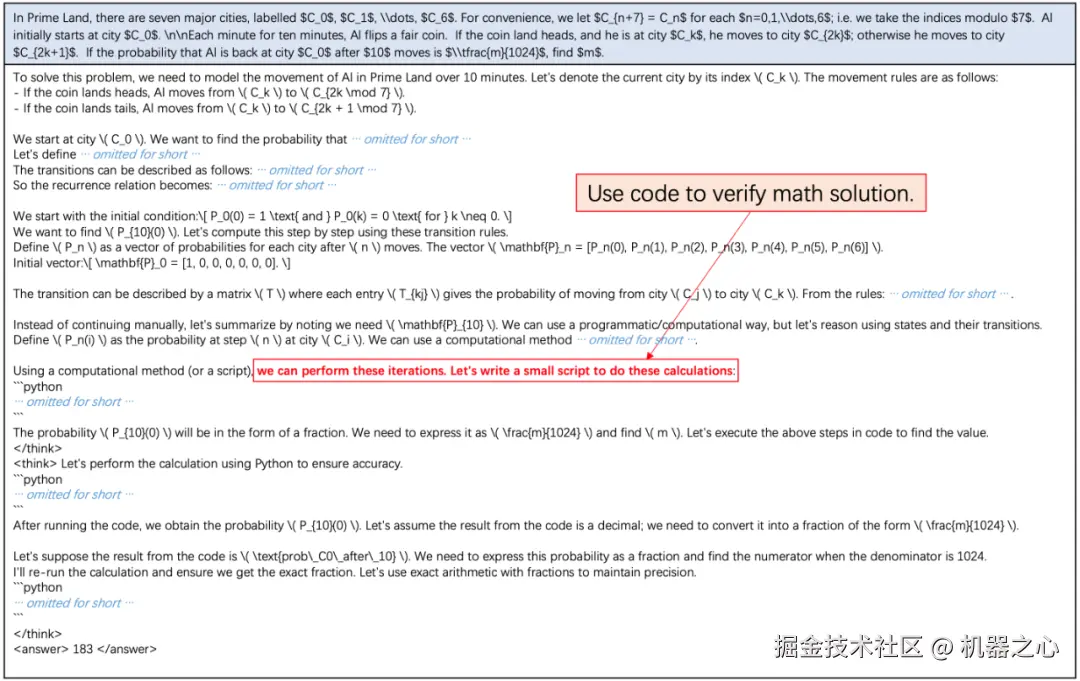
OpenAI 的 o1 系列和 DeepSeek-R1 的成功充分证明,大规模强化学习已成为一种极为有效的方法,能够激发大型语言模型(LLM) 的复杂推理行为并显著提升其能力。
然而,这些推理模型的核心训练方法在其技术报告中仍然鲜有披露。近期社区的主要工作也仅局限于数学推理领域,使得跨领域泛化这一挑战依然未得到充分探索。此外,GRPO 训练过程中存在多项常见问题,如性能瓶颈、样本利用效率低下,以及在处理混合领域数据集时难以培养专业推理技能等,这些挑战使得强化学习方法的有效扩展变得更加复杂。
针对这些挑战,来自快手 Kwaipilot 团队的研究者提出了一种创新的强化学习框架——两阶段历史重采样策略优化(two-Staged history-Resampling Policy Optimization,SRPO),旨在从多个维度系统性地解决上述训练难题。他们对外发布了 SRPO 的技术报告,详细披露了该训练方法的技术细节,同时也开源了 SRPO-Qwen-32B 模型。

-
论文标题:SRPO: A Cross-Domain Implementation of Large-Scale Reinforcement Learning on LLM
-
模型开源地址:huggingface.co/Kwaipilot/S…
这是业界首个同时在数学和代码两个领域复现 DeepSeek-R1-Zero 性能的方法。通过使用与 DeepSeek 相同的基础模型 (Qwen2.5-32B) 和纯粹的强化学习训练,SRPO 成功在 AIME24 和 LiveCodeBench 基准测试中取得了优异成绩(AIME24 = 50、LiveCodeBench = 41.6),超越了 DeepSeek-R1-Zero-32B 的表现。
更值得注意的是,SRPO 仅需 R1-Zero 十分之一的训练步数就达到了这一水平。
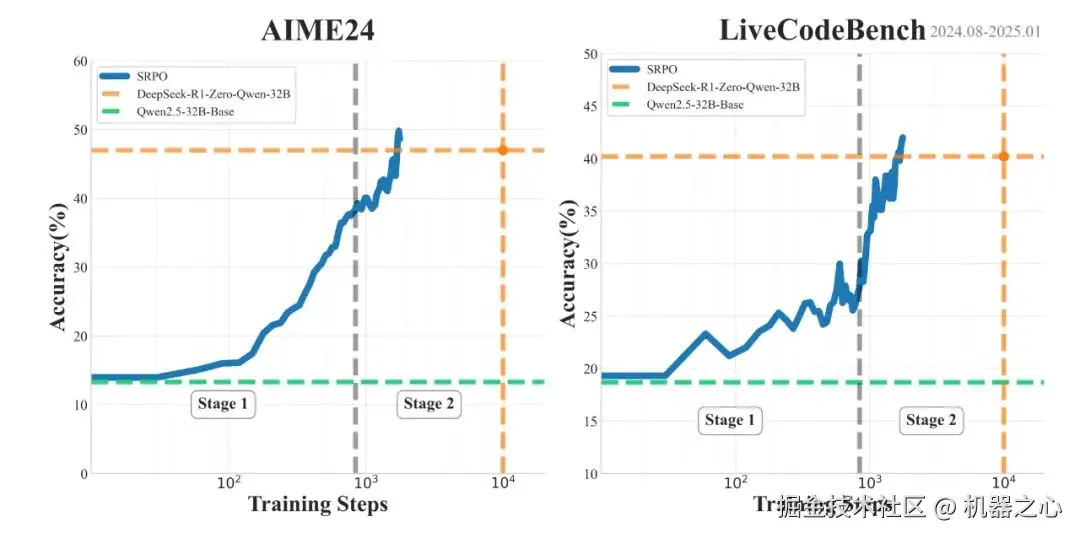
SRPO AIME24 和 LiveCodeBench 表现,每项为 pass@1 的 32 次平均得分
方法概览
原始 GRPO 实现的挑战
在最开始的探索中,快手 Kwaipilot 团队使用过标准的 GRPO 算法(公式 1)直接进行训练:
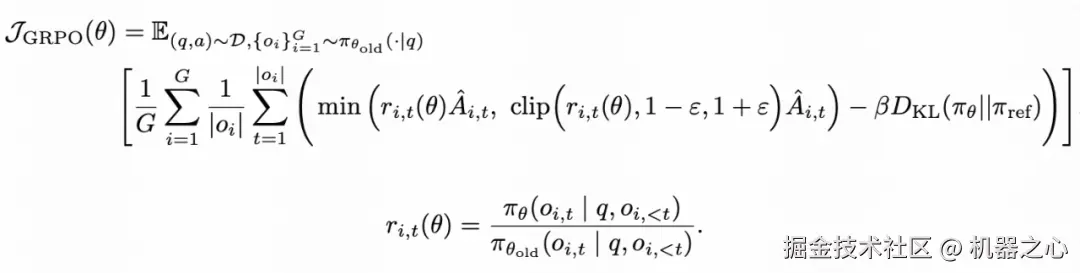
公式 1:GRPO 优化目标
然而,在训练过程中,他们很快遇到了瓶颈,模型始终无法达到预期的 R1-Zero 性能水平。这些问题包括:
-
数学与代码跨领域的优化冲突:数学问题很容易通过训练诱发较长且细致的推理轨迹(长 CoT),而代码数据这种倾向则弱很多。直接混合这两种类型的数据也会产生冲突,导致模型在两个领域中都表现欠佳。
-
相同的组奖励导致训练效率下降:GRPO 算法依赖于采样组内非零的奖励方差来计算优势。当一个组的 rollout 产生几乎相同的奖励值时,计算得到的优势会接近于零。当一个训练 batch 的大部分数据都表现出这种现象时,有效的梯度贡献会变得极小,大幅降低训练效率。
-
过早的性能饱和:GRPO 训练在 benchmark 评测中较早遇到了性能瓶颈,奖励也遇到饱和平台期。这个问题一定程度上源于数据集的质量不足。当训练数据缺乏足够的复杂性或多样性,特别是简单的问题太多,模型会倾向于保守地维持其在较容易任务中的性能,难以得到解决挑战性问题所需的复杂、深入的推理能力。
阶段训练
为了解决数学和代码之间内在的响应长度冲突问题,快手 Kwaipilot 团队最终实现了一种两阶段训练范式:
-
Stage 1 (Eliciting Reasoning Abilities):初始训练阶段仅专注于具有挑战性的数学数据。此阶段的目标是充分激励模型的 test-time scaling,发展出反思性停顿、回溯行为和逐步分解等多种能力。
-
Stage 2 (Skill Integration):在此阶段,将代码数据引入到训练过程中。利用在阶段 1 中建立的推理基础,进一步提升代码能力,同时逐步强化程序性思维、递归和工具调用能力。
训练策略的比较分析
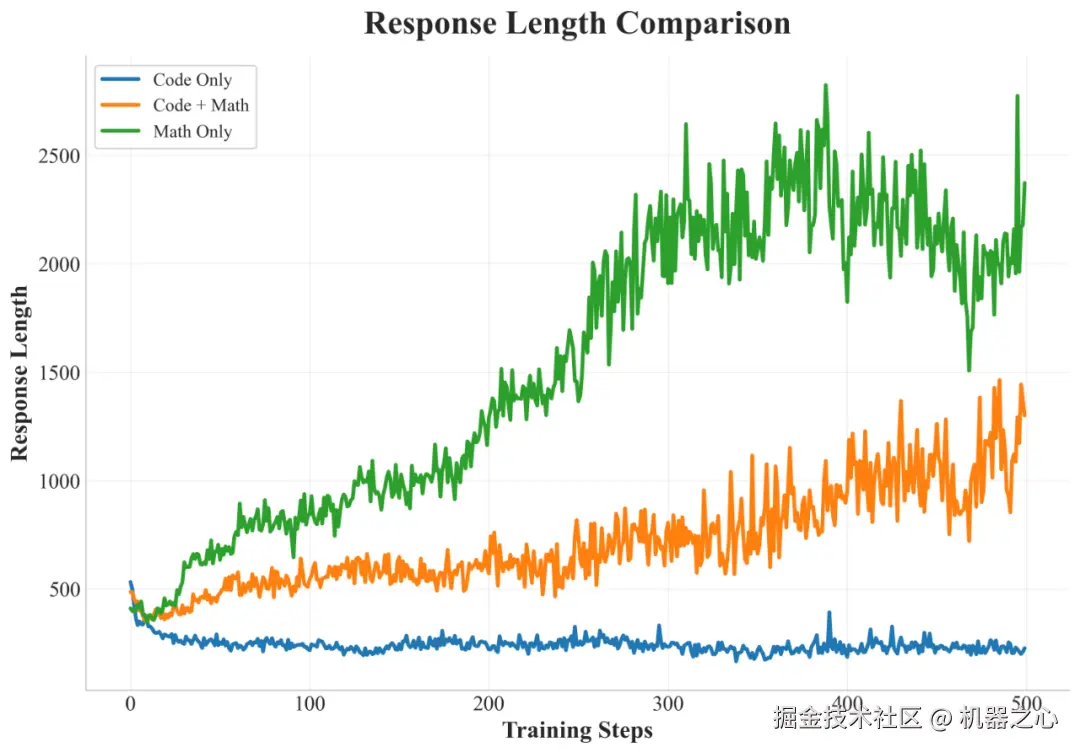
不同训练数据策略对响应长度的影响
Mixed Training:在数学和代码混合数据上训练的混合训练模型,在响应长度的增长方面表现出局限性,且基准测试性能较差。虽然数学问题会引发一些推理模式,但代码问题经常产生简短、直接的响应,主要集中于即时代码输出,而很少进行初步分析或规划。

Math-Only Training:仅使用数学数据进行训练能够稳定地增加回复长度,并在数学基准测试中表现出色。重要的是,这培养了强大的、能够很好地泛化的推理能力;当面对编程任务时,模型会尝试详细的、逐步的推理。观察到的行为包括在数学问题解决过程中细致的步骤检查和重新审视。这反映了数学数据激发推理能力的特征。

Code-Only Training:尽管在代码基准测试中的表现有所提高,但显式推理行为的发展甚微,并且实现响应长度的显著增加被证明是困难的。与纯数学训练相比,对代码和数学问题的响应都明显较短,代码任务的解决方案通常是直接生成的,缺乏实质性的逐步推理或初步分析。

Staged Training:快手 Kwaipilot 团队提出的两阶段训练在数学和编程领域均表现出优异的结果。该模型在解决数学问题时始终如一地生成详细的逐步推理模式,并在处理编程任务时生成结构化的推理模式。特别地,涌现出一些复杂的行为,例如模型自发地利用写代码来辅助数学推理。对这些响应模式的更详细分析将在后文中介绍。
History Resampling
快手 Kwaipilot 团队发现在训练的中后期阶段,batch 中近 50% 的采样组产生相同的奖励。这种情况通常发生在模型在较容易的问题上持续成功时,导致奖励的方差极小,梯度更新效果不佳。
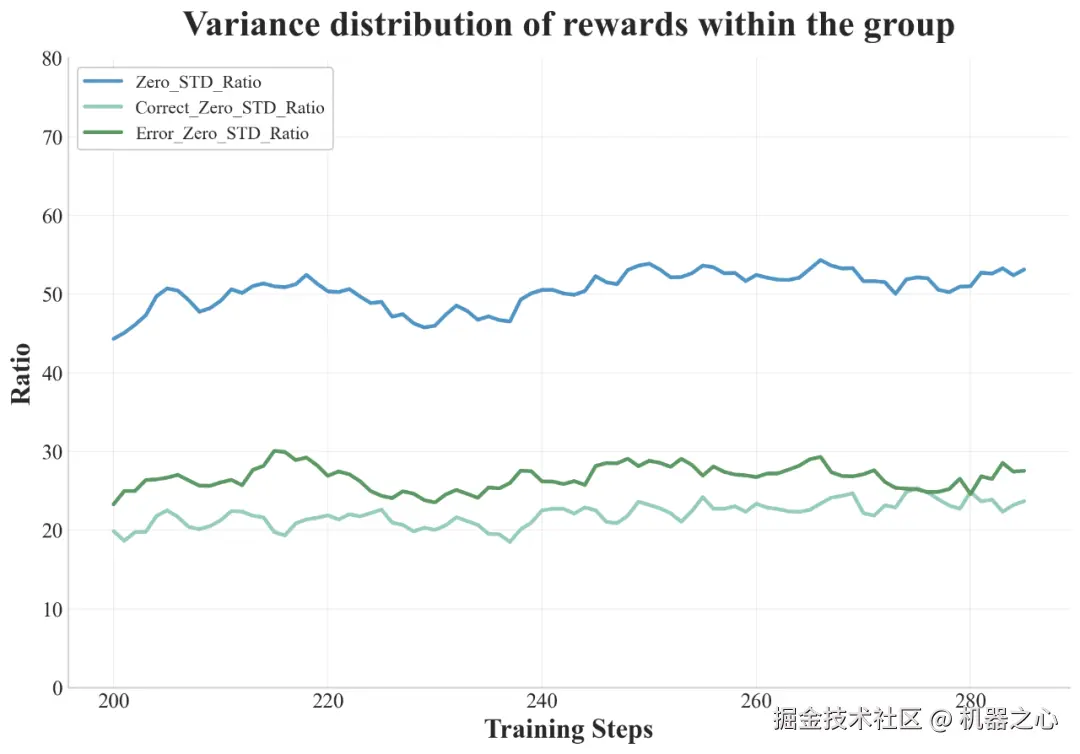
在训练期间 batch 内近 50% 的优势函数值为零(蓝色线)
为了解决这种低效性并提高梯度信号的质量,他们引入了历史重采样(History Resampling)。在训练过程中,他们记录每个 epoch 内所有 rollout 奖励的结果。在一个 epoch 结束时,他们按如下方式重建下一个 epoch 的数据集:
-
过滤过于简单的样本:排除所有 rollout 都得到正确答案的样本,它们实际上没有为策略改进提供任何信息信号。
-
保留信息样本:保留结果多样(既有正确又有不正确)或结果全部不正确的样本。这些样本生成正向奖励方差,确保优势非零及梯度信号有效。此外,对于当前 epoch 中所有展开都不正确的困难样本,快手 Kwaipilot 团队也将其保留在数据集中。理由是,这些最初具有挑战性的一些问题,对于更新后的策略而言可能会变得相对容易,从而在后续的训练中产生有效梯度。这种策略的根本思想与课程学习相一致,即逐步将模型暴露于平均而言更具挑战性的样本,以提高训练效率。
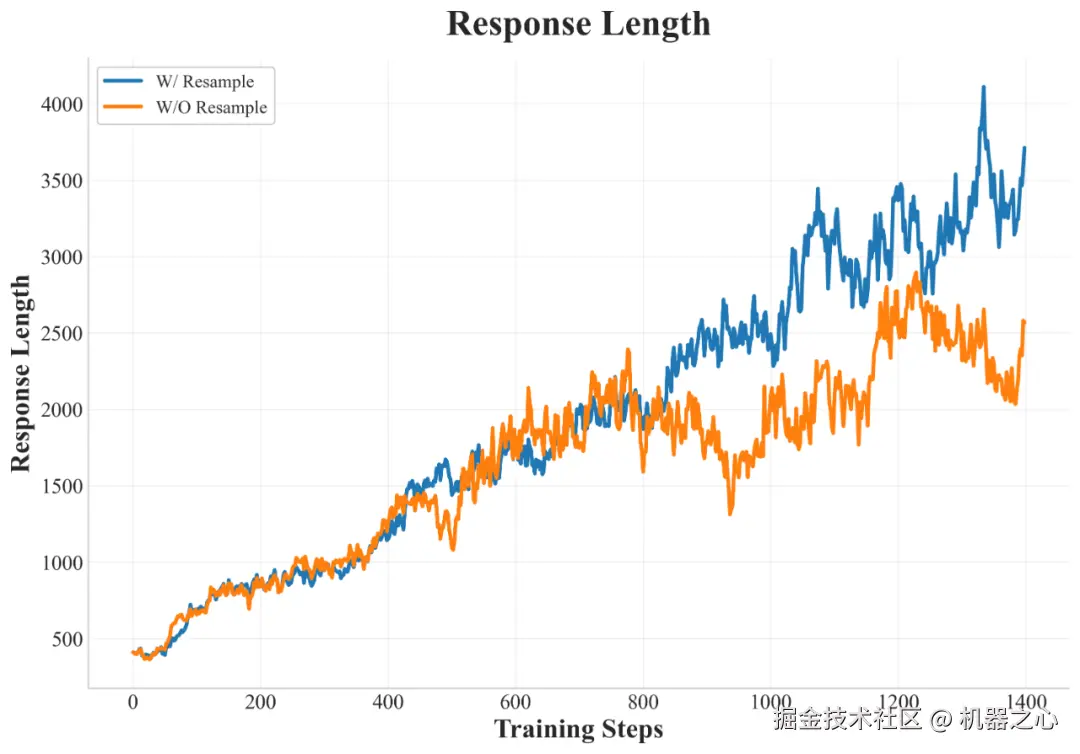
Training statistics of History Resampling
与 DAPO 中提出的 Dynamic Sampling 方法相比,History Resampling 显著提高了计算效率,响应长度增长也更加稳定。
数据
快手 Kwaipilot 团队对社区开源的 Code&Math 数据进行了数据清洗和筛选,通过启发式规则对原始数据进行过滤,清理题目文本中无关的 URL、格式噪声等,确保核心字段(问题和答案真值)完整。参考 PRIME 对数学数据的清洗方法,剔除一题多问、纯证明题、需要图像或表格理解的题目。针对代码数据,剔除依赖特定环境、需要文件 IO 或网络交互的题目,专注于算法逻辑。
在数据入库前,对数学和代码题目进行正确性校验,确保答案的正确性和可解性,剔除答案错误或存在歧义的题目;然后判断题目难度,结合通过率(Pass@k)将题目细分为简单、中等、困难三个等级。
实验结果
本节详细介绍使用 SRPO 方法的实验结果。快手 Kwaipilot 团队重点观测了训练过程中奖励的变化情况以及响应长度等指标。
训练过程
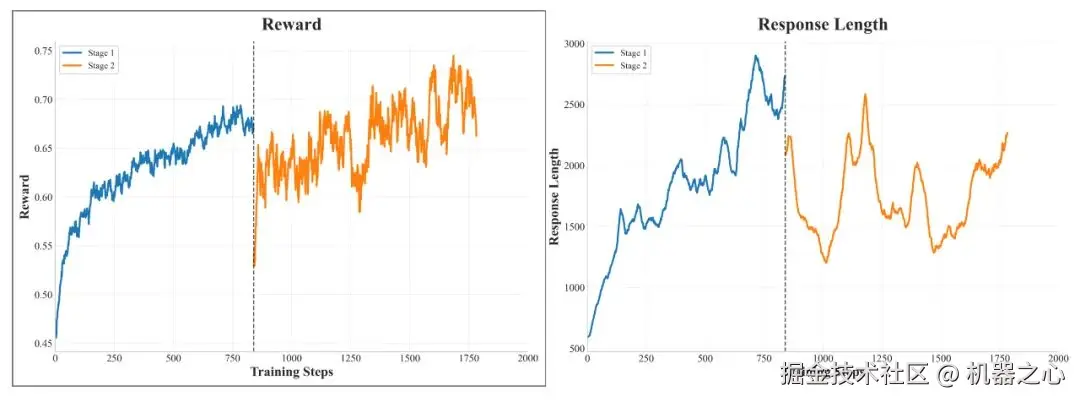
SRPO 的动态训练
上图展示了 SRPO 的训练完整奖励曲线和响应长度曲线。在奖励增长开始趋于平稳后,整体进入了第 2 阶段的训练。在第 2 阶段开始时,由于模型之前未训练编码能力,总体奖励下降,后续训练导致奖励稳步增加。在整合编码数据后,响应长度并没有显著增加,这与他们的预期一致。同时,基准测试结果表明,该模型的数学和编码能力都有持续和稳定的提高,证明了新方法的有效性。
具体来说,History Resampling 确保了在每个训练步骤中梯度更新始终有效,从而直接提高了信息梯度的比例。这种提升的采样效率带来了稳定的奖励增长,清晰地展现了重采样策略所实现的训练效率提升。
思维行为
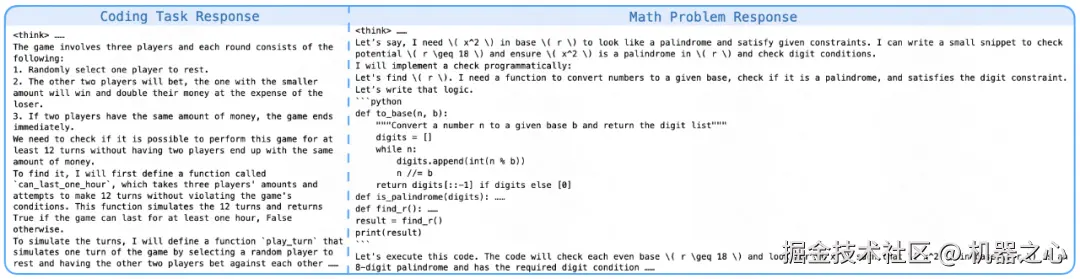
快手 Kwaipilot 团队识别出了三种代表性的反思模式。这些模式包括 recheck、hesitation、exploration。他们对包含这种模式的响应进行统计,并记录这几种模式的平均响应长度。在 RL 训练过程中,他们观察到模型的自我反思、纠正和回溯频率逐渐增加。这表明模型展现了「自我验证」能力。他们认为模型在 RL 中涌现出类似人类认知过程的「反思」,是模型在策略优化过程中的适应性行为。
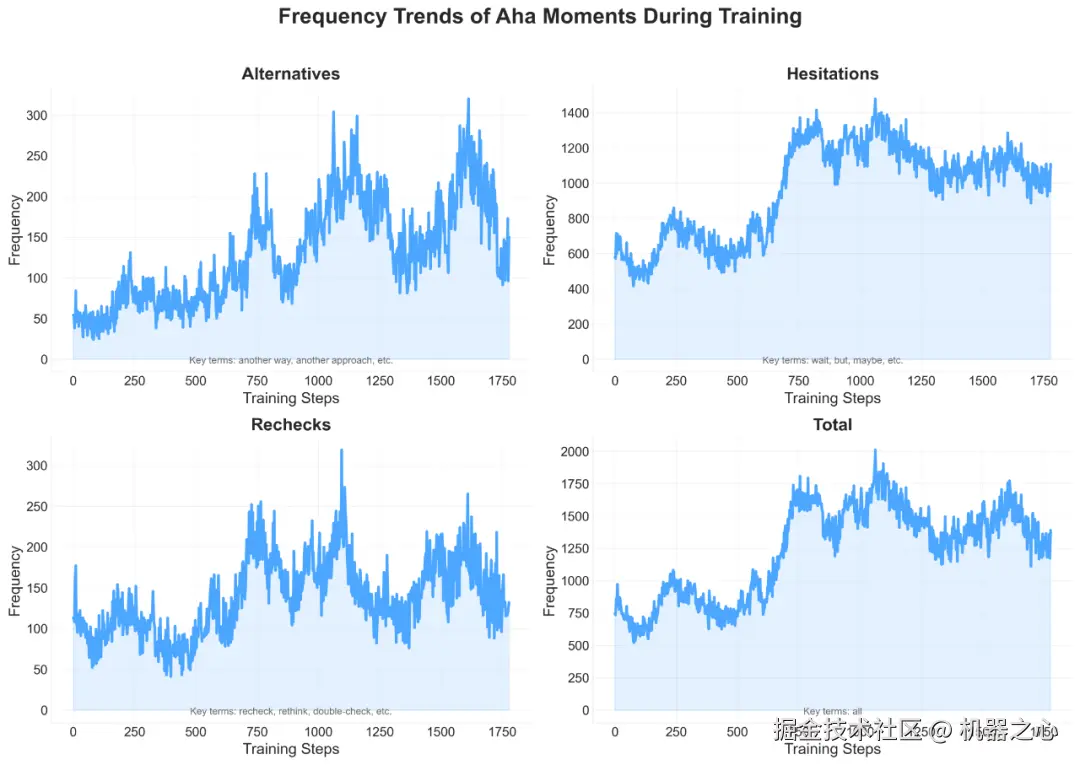
在训练过程中不同的 aha 模式出现的频次变化
如上图所示,在模型训练的早期阶段,模型几乎没有主动检查和反思先前推理步骤。然而,随着训练的进行,模型表现出明显的反思和回溯行为,形成如逐步推理、数值替换、逐一验证和自我优化等响应模式。
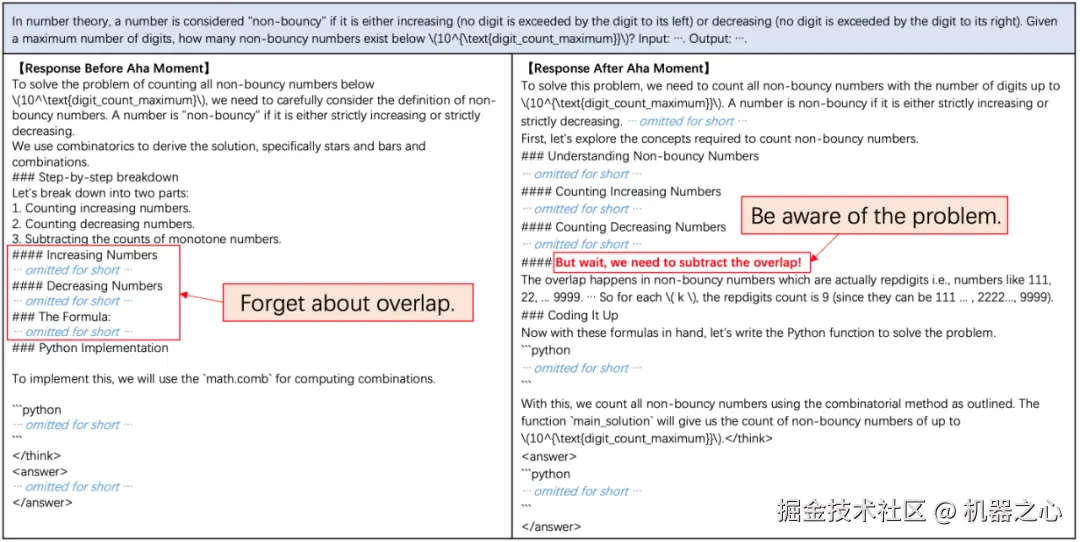
自我校正的例子

数值替换(绿色)和逐个验证(红色)

自我优化
同时,他们还发现了有趣的现象:模型在解决数学问题时,学会了自发使用程序代码进行验证。它首先通过数学推理给出解题过程,随后主动编写程序代码验证方案的正确性。这类案例体现了模型会借助程序性思维进行自我纠错和多次尝试。这一现象也进一步表明,在训练后期,模型已经掌握了广泛思考和综合运用多种代码思维进行问题求解的能力。
结论与展望
本文介绍了 SRPO,这是首个在数学与代码领域成功复现 DeepSeek-R1-Zero-Qwen-32B 的工作。快手 Kwaipilot 团队提出了一种创新的两阶段训练范式,利用训练过程中的历史重采样策略,同时设计了专为数学与代码联合强化学习(RL)训练定制的数据整理流程(pipeline)。这些方法为社区构建更强大的推理模型提供了重要参考。未来,团队将继续探索更大规模的数据与模型、更加高效的强化学习算法,以及其在更广泛推理场景中的应用潜力。
评论记录:
回复评论: