

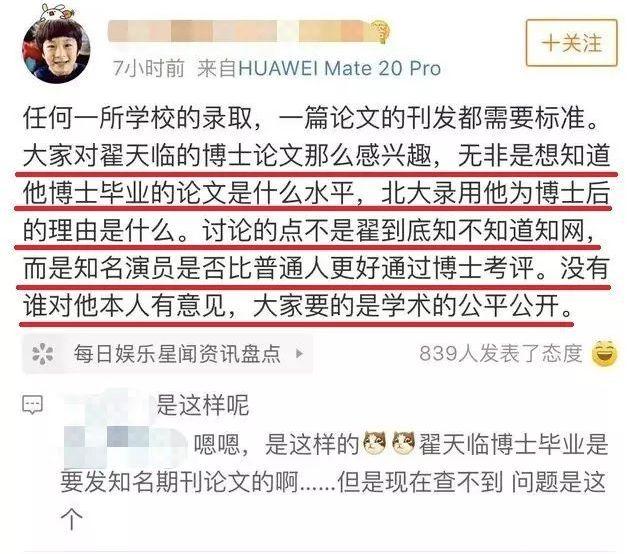
这段时间,翟天临的博士门事件闹的沸沸扬扬。一句「知网是什么」引出了强大的蝴蝶效应。

在网·柯南·友们的努力下,不仅其学术经历被扒了个底儿掉,还接着引出了北电院长的种种「大新闻」,难怪人们谈起翟博士都纷纷由衷感慨:引爆自己,照亮黑暗。

这还没完,不光学术不端被攻击,接二连三的「人品」问题也被爆出,什么在日本对影迷黑脸、仗着有演技对工作人员态度恶劣、不听导师教诲太嘚瑟等等。大有墙倒众人推的感觉。
不过随着个人的道歉,这件事终归快要告一段落,营长不想去对这件事的孰是孰非发表评论。但《人民日报》的观点却让营长深感赞同:博士不是一个轻飘飘的荣誉称号。博士称号的背后是对学科进行深入探索后的贡献,也是个人学术成就的体现,分量很重。
正如一个高票留言所说:
随着国内高校对区块链的重视,一些学校也开设了博士研究方向。这不禁激起了营长的好奇,国内研究区块链的到底是些什么人?在国内要拿到区块链方向的博士学位有哪些条件?毕业后的规划又有哪些?
带着这些问题,营长最近采访了,大连理工大学软件工程专业区块链方向的在读博士齐风子,请他谈谈国内区块链博士的现状,并且从自己的角度分享一个典型区块链博士的生活。
谁是区块链博士?
齐风子(以下简称「小齐」),大连理工大学软件工程向博士一年级,也是该校区块链实验室唯一一个在读的博士,硕博的专业都是软件工程。
这两天,他刚刚放完寒假,从山东老家回到大连。
早先,他们的实验室是跟IBM的Watson实验室一起做智慧城市方面的研究的,小齐跟着导师负责数据分析。不过随着IBM业务全面转型区块链后,小齐的实验室也跟着转到了区块链方向,从研二开始小齐就全面负责整个课题组的事务。现在实验室除了小齐之外,研究区块链的还有12个硕士和若干本科生。
从2017起,区块链技术越来越火,但整个行业也比较混乱。在转型区块链方向之后,想要在混乱中找到有价值的研究方向并不容易。想来想去,小齐他们确定了一个核心原则:不炒币。
虽然没有找到好的研究方向,但他们并没有闲着,而是先参加了一些区块链方面的活动和比赛,“看看他们在干什么”。
“我们当时参加了很多比赛,从2017年到2018年,我们参加过IBM组织的高校区块链黑客松(三等奖)、教育部组织的高校区块链大赛(二等奖)、IBM-ICBC金融科技创新大赛(特等奖)等等赛事。”小齐介绍道。
有了这些积累,实验室先后发了几篇论文,用小齐的话说:都是工程性的论文,理论创新价值不够高端。直到去年下半年,实验室从工信部那边拿来一个课题——链上数据分析,才算是定下了大方向。一直做到春节前,但“还没拿出实际成果来”。
小齐准备返校后再去好好地攻坚。
博士不是你想读,想读就能读
在区块链方向想要取得博士学位并非易事,首先,很多人存在一个误区,就是当我们说起「区块链博士」时,指的是「区块链专业的博士」,但事实并非如此。就目前大多数高校而言,区块链还并不是一个专业。以大连理工为例,小齐读的实际上是软件工程专业的博士,只是研究方向为区块链。
如此一来,毕业的条件也就跟软件工程专业其他研究方向的条件一样。在大连理工,软件工程博士的学制为4~6年,毕业生水平一般为为5篇论文,其中至少3篇Sci -II区以上的论文。
“往年毕业的博士,一般都是三篇二区期刊一篇英文会议,再加一篇中文核心,或者两个顶刊,再随便配几个中文核心。”小齐补充道。
小齐给自己的博士生涯计划是5年毕业:前3年集齐论文,第4年出国交换,并且开始接触一些优秀的企业和项目;第5年考虑就业。但小齐也坦言:“想前3年就集齐论文还是有难度。”
说起当初为什么选择区块链这个方向,小齐认为,读区块链这个方向的优势很明显,例如以下几点。
第一,就业有底。区块链比较热门,小齐的很多其他计算机领域的博士同学对于毕业后的就业压力很大。而区块链方向的博士则不会有这方面的压力,这对读博期间的心态有很重要的影响。
第二,学术突破空间大,区块链目前的研究成果较少,很多方向都是一片空白,学术突破有很大的空间。相较而言,传统计算机网络、数据库等研究方向的博士,想要在前人的基础上再去突破,难度就很大。而区块链领域只要能做出一些东西来,都是很大的突破。
第三,门槛低,区块链作为一门交叉学科,很多研究生都是从金融和软件工程两个专业过来的,门槛不算高。不需要花很长时间入门。区块链更倾向于工程实践,不像纯密码学等领域那么抽象。
但劣势也很明显,比如:对于博士来说,区块链方面的专刊会议比较少。“毕竟我们首先要考虑毕业,我们写完论文后,发现能投的期刊或者会议都很新。想攒分数不好攒。”
除此之外,区块链不像其他学科有很全面的参考资料,想要入门,没有比较要的培养路径。而且有资历的导师资源也较少,经常遇到问题发现导师也并不能指导我们,因为导师也跟我们一样在摸索。
区块链高校哪家强?
由于区块链领域的人才需求一直比较旺盛,国内有数十家高校已经开设了区块链课程或研究方向。一些高校也发表了以区块链为主题的毕业论文。但仅仅一两门概述性的课程或几篇学位论文还远远不足以支撑起一个系统全面的人才培养体系。国内高校出现系统性的区块链人才培养机制仍尚需时日。
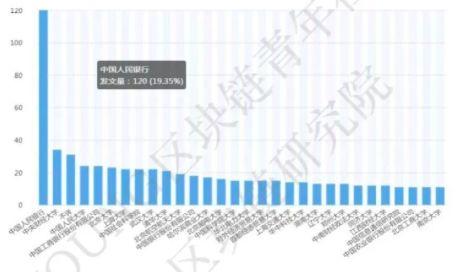
在小齐主笔的《中国高校区块链发展研究报告》中,区块链科研成果主要集中于金融单位,其中中国人民银行排名第一,发文量达120篇,超过紧随其后的是央财、人大、工商、北大之和
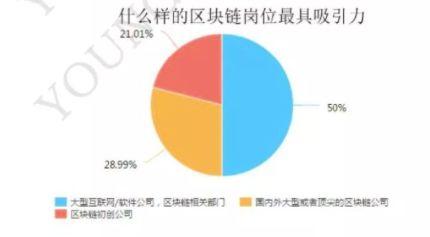
高校研究者有超过半数表示,收到大型互联网公司区块链部门的Offer,他们更愿意前往就职
作为区块链博士之一,小齐对国内高校区块链现状如数家珍,他先告诉了我一个学界的共识:南浙大,北北航。
|
|


接着,就国内主要高校的区块链现状侃侃而谈。
“华北比较厉害的是北航,北航有好几个实验室,起步比较早,投入比较大。计算机学院、软件学院等都有独立的区块链实验室。而且他们高层次的学者,比如院士很多,而且在密码学方面的积累也比较多。优势很大。”
“北京地区,清华和北大联合成立了一个新数字经济研究院,清华的速度比较快,成立的几个研究中心发展都很迅速。除了北清之外,北理工也比较厉害。情况跟我们基本一样,也是跟IBM的关系很密切,不过他们比我们的校外资源多,联盟链发展的也比较快。而且北理工实验室的负责人祝烈煌老师是CCF区块链委员会的秘书长。”
“山东的两个大学——山东大学和山东师范大学,原本就是实力较强的密码学实验室,有很多密码学的研究成果。借助于已有成果,他们在区块链的密码学问题中做出了很多建设性的成果。”
在谈到为啥没选择名校就读的原因时,小齐表示:虽然名校光环很重要,但博士由于学制时间长,要求高,更重要的还是定方向。
当时选择了区块链这个方向就没打算学别的。而区块链方向的高校就那么几个。清北和北航要求较高,所以就留在大连理工继续跟着自己的导师了。
区块链博士的一天
虽然读博已经一年,但小齐仍然直言自己的生活“比较简单”。早上8点钟起床,9点之前到实验室,一直到晚上10点。一天的生活基本上就是看论文查资料。要是有了灵感,就会去写写代码,或者跑一跑实验。

大连理工大学区块链实验室,小齐为第二排左四
看论文更像是一个从一个点带出一条线的过程,通过查找看不懂的东西,带出更多需要学习的地方。有时候,想出一个新想法,小齐会去跟导师汇报,通过反复争论,由导师决定这个想法有没有价值,有价值就写篇论文,没有价值就继续重复看论文的步骤。
经过努力,目前小齐的实验室已经确定了三个大致的研究方向,即:
共识算法优化,对联盟链里的共识算法进行研究,以几种现在常见的共识算法作为参考,如PoW、PoS、DPoS等,提出了几个优化后的共识算法,当前正在进行论文投稿来;
场景应用模型,针对不同场景,研究区块链在这方面的应用,目前包括版权保护、医疗、智能制造,去年还申请了很多专利;
链上数据分析,与工信部合作,仍在探索中。
说起这一年来读博的经历,小齐认为最觉得满意的地方就是有了更高的行业参与度。在研究生时期,感觉自己就是个搬砖的,这个砖是用来盖楼还是垒墙,自己并不知道。都是导师告诉你干啥就干啥。
而读博之后情况转变了,自己很清楚自己在做什么,导师的想法是什么,我做的东西是否有用,能用在哪个领域,以及目前学界和工业界他们分别在想什么问题。
“对整体有把握,是我比较大的一个收获。因为将来就业要考虑这些问题,衡量行业的发展。”小齐总结道。
— END —
EOS工作原理 | EOS开发环境 | 智能合约 | DAPP开发

推荐阅读:
点击“阅读原文”,打开 APP 获取更多干货哟!
Kubelet 介绍
Kubelet 是 Kubernetes 集群中的一个核心组件,它在每个节点上运行并负责维护容器的生命周期。这包括创建和删除容器、监控容器的健康状况以及向 Kubernetes 控制平面报告容器的状态。此外,Kubelet 还负责将容器日志上传到配置的日志服务器,并提供容器运行时的度量信息。对 Kubelet 的性能进行深入了解和监控是确保 Kubernetes 集群稳定性和效率的关键。
Kubelet 监控主要有以下几个方面的维度:
| 监控维度 | 描述 | 重要性 |
|---|---|---|
| 节点状态监控 | 监控节点的健康状况,包括 Ready、NotReady 状态 | 高 |
| 容器状态监控 | 监控容器的运行状态,如 Running、Paused、Terminated 等 | 高 |
| 系统资源监控 | 监控 CPU、内存、磁盘等资源的使用情况 | 高 |
| 网络监控 | 监控 Pod 和节点的网络性能和连接状态 | 中 |
| 事件和日志监控 | 监控 Kubernetes 集群中的事件和日志,帮助理解应用程序和资源的状态 | 高 |
| 追踪监控 | 跟踪请求在系统各服务和组件中的流程 | 中 |
| Pod 调度和运行 | 监控 Pod 的调度效率和运行时性能 | 高 |
| Kubelet API 性能 | 监控 Kubelet API 的响应时间和错误率 | 中 |
| 镜像拉取和存储 | 监控容器镜像的拉取效率和存储使用情况 | 中 |
Kubelet 组件的核心指标接口,除了本身的 /metrics 以外,还包括 cAdvisor 相关的指标接口 /metrics/cadvisor。以下为接口的简要说明。
/metrics
/metrics 接口提供了 kubelet 自身以及节点级别的监控指标。这些指标可以帮助管理员监控节点资源使用情况,优化资源分配,并快速定位性能瓶颈。以下是一些关键的指标类型:
- CPU 指标:包括 cpu_usage_total(总 CPU 使用量)和 cpu_usage_percent(CPU 使用率)等。
- 内存指标:包括 memory_usage_total(总内存使用量)和 memory_usage_percent(内存使用率)等。
- 存储指标:包括 disk_io_total(总磁盘 I/O)和 disk_io_rate(磁盘 I/O 速率)等。
- 网络指标:包括网络流量和带宽使用情况等。
这些指标对于监控节点资源使用和性能分析至关重要。
/metrics/cadvisor
/metrics/cadvisor 接口是由集成在 kubelet 中的 cAdvisor 提供的,用于监控容器资源使用情况。cAdvisor(Container Advisor)是 Google 开源的一个工具,它可以在各种容器环境中运行,包括 Docker、rkt 等。以下是 cAdvisor 的一些关键特性和指标:
- 容器级别的监控:cAdvisor 提供了容器级别的资源使用数据,包括 CPU、内存、磁盘 I/O 等。
- 实时数据:cAdvisor 定期从容器中收集信息,并暴露在 HTTP 接口上供用户查询。
观测云
观测云是一款专为 IT 工程师打造的全链路可观测产品,它集成了基础设施监控、应用程序性能监控和日志管理,为整个技术栈提供实时可观察性。这款产品能够帮助工程师全面了解端到端的用户体验追踪,了解应用内函数的每一次调用,以及全面监控云时代的基础设施。此外,观测云还具备快速发现系统安全风险的能力,为数字化时代提供安全保障。
部署 DataKit
DataKit 是一个开源的、跨平台的数据收集和监控工具,由观测云开发并维护。它旨在帮助用户收集、处理和分析各种数据源,如日志、指标和事件,以便进行有效的监控和故障排查。DataKit 支持多种数据输入和输出格式,可以轻松集成到现有的监控系统中。
登录观测云控制台,在「集成」 - 「DataKit」选择对应安装方式,当前采用 Linux 主机部署 DataKit。
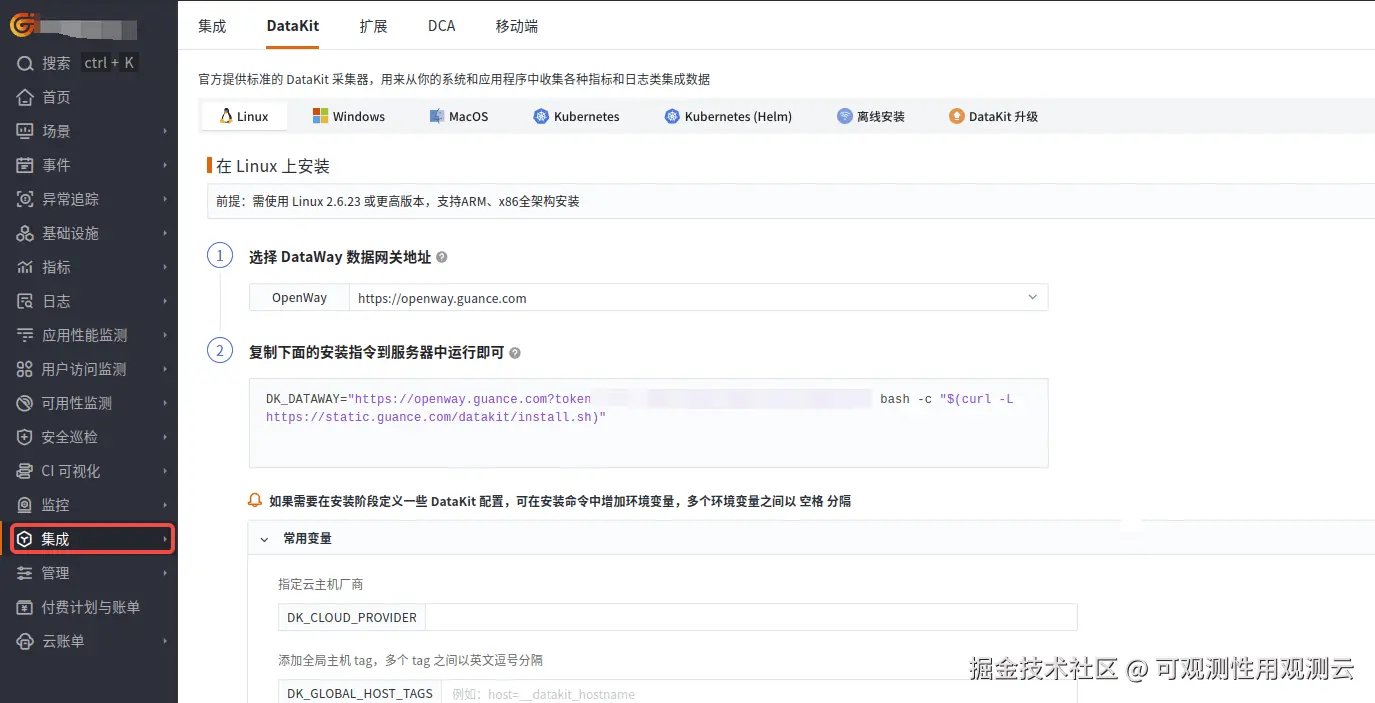
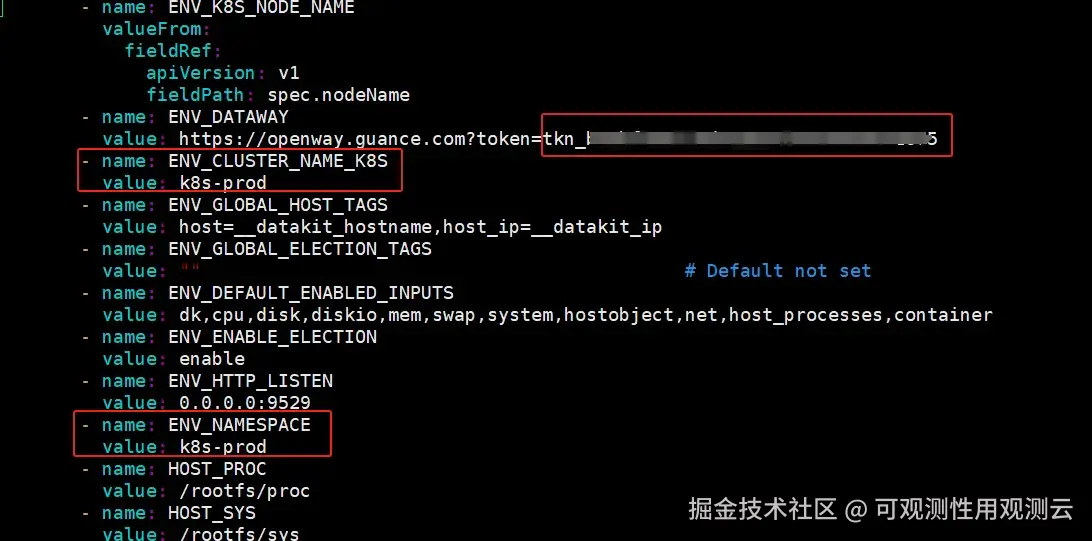
编辑 datakit.yaml ,把 token 粘贴到 ENV_DATAWAY 环境变量值中“token=”后面,设置环境变量 ENV_CLUSTER_NAME_K8S 的值并增加环境变量 ENV_NAMESPACE,这两个环境变量的值一般和集群名称对应,一个工作空间集群名称要唯一。
yaml 代码解读复制代码 - name: ENV_NAMESPACE
value: xxxx
把 datakit.yaml 上传到可以连接到 Kubernetes 集群的主机上,执行如下命令。
arduino代码解读复制代码kubectl apply -f datakit.yaml kubectl get pod -n datakit
采集器配置
KubernetesPrometheus 是 DataKit 的一个采集器,它根据自定义配置实现自动发现 Prometheus 服务并进行采集,极大简化了采集 Kubernetes 集群中 Kubelet 指标的复杂度。
通过在 DataKit 的 Comfigmap 中添加 kubernetesprometheus.conf 采集器,对 Kubelet 中 /metrics 以及 /metrics/cadvisor 指标接口进行采集。
ini 代码解读复制代码apiVersion: v1
kind: ConfigMap
metadata:
name: datakit-conf
namespace: datakit
data:
kubelet.conf: |-
[inputs.kubernetesprometheus]
[[inputs.kubernetesprometheus.instances]]
role = "node"
selector = "kubernetes.io/os=linux"
scrape = "true"
scheme = "https"
port = "__kubernetes_node_kubelet_endpoint_port"
path = "/metrics"
params = ""
interval = "15s"
[inputs.kubernetesprometheus.instances.custom]
measurement = "kubelet"
job_as_measurement = true
[inputs.kubernetesprometheus.instances.custom.tags]
instance = "__kubernetes_mate_instance"
cluster_name_k8s = "default"
job = "kubelet"
[inputs.kubernetesprometheus.instances.auth]
bearer_token_file = "/var/run/secrets/kubernetes.io/serviceaccount/token"
[inputs.kubernetesprometheus.instances.auth.tls_config]
insecure_skip_verify = true
cert = "/var/run/secrets/kubernetes.io/serviceaccount/ca.crt"
[[inputs.kubernetesprometheus.instances]]
role = "node"
selector = "kubernetes.io/os=linux"
scrape = "true"
scheme = "https"
port = "__kubernetes_node_kubelet_endpoint_port"
path = "/metrics/cadvisor"
params = ""
interval = "15s"
[inputs.kubernetesprometheus.instances.custom]
measurement = "cadvisor"
job_as_measurement = true
[inputs.kubernetesprometheus.instances.custom.tags]
instance = "__kubernetes_mate_instance"
cluster_name_k8s = "default"
job = "kubelet"
node = "__kubernetes_node_name"
label_alpha_eksctl_io_nodegroup_name = "__kubernetes_node_label_alpha.eksctl.io/nodegroup-name"
[inputs.kubernetesprometheus.instances.auth]
bearer_token_file = "/var/run/secrets/kubernetes.io/serviceaccount/token"
[inputs.kubernetesprometheus.instances.auth.tls_config]
insecure_skip_verify = true
cert = "/var/run/secrets/kubernetes.io/serviceaccount/ca.crt"
再把 kubelet.conf 挂载到 DataKit 的 /usr/local/datakit/conf.d/kubernetesprometheus/kubelet.conf 下面,最后重新部署 DataKit。
yaml 代码解读复制代码 - mountPath: /usr/local/datakit/conf.d/kubernetesprometheus/kubelet.conf
name: datakit-conf
subPath: kubelet.conf
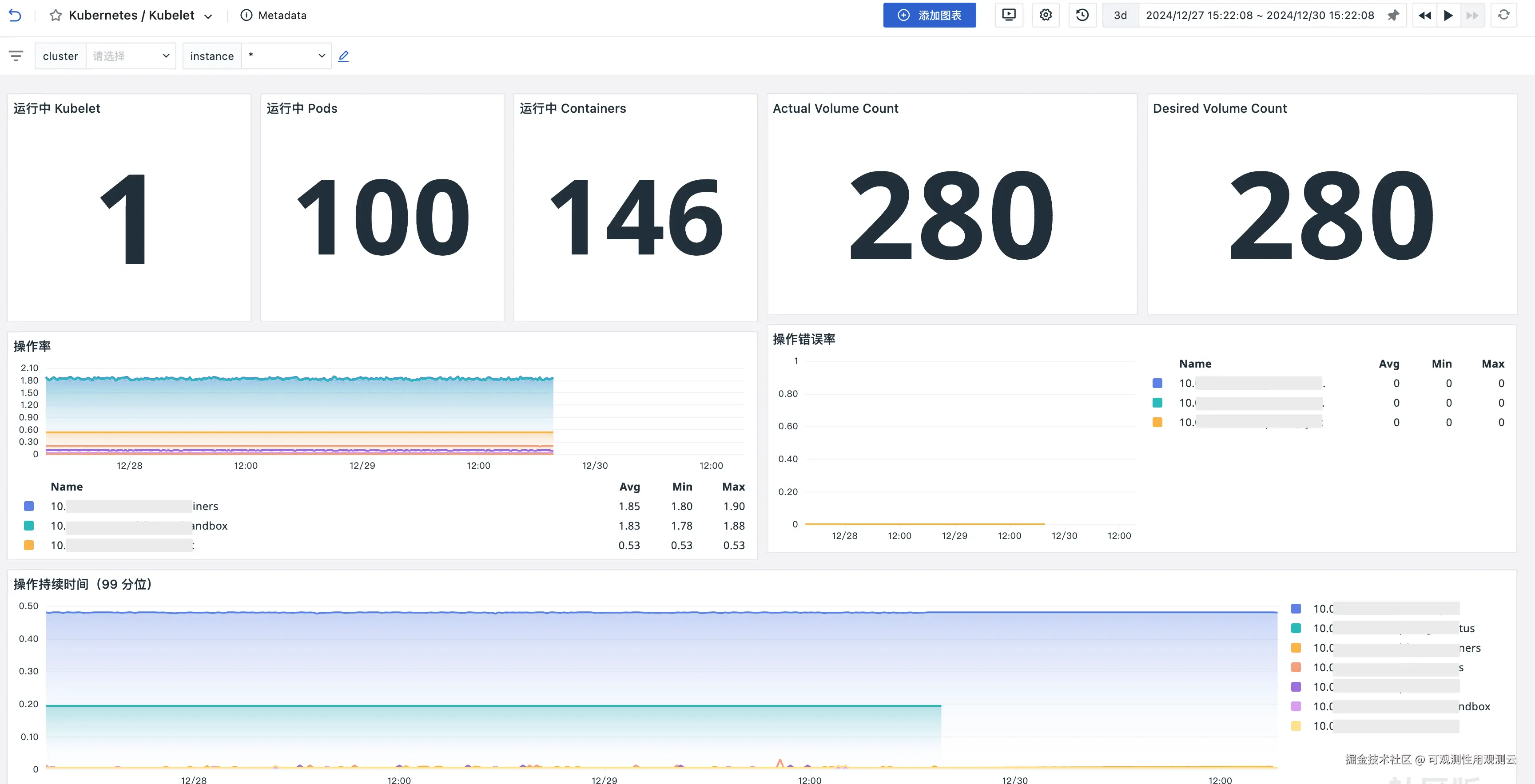
关键指标
| Metrics | 描述 | 单位 |
|---|---|---|
kubelet_node_name | Kubelet 所在的节点 | count |
kubelet_running_pods | 当前节点正在运行的 Pod 数量 | count |
kubelet_running_containers | 当前节点上正在运行的容器数量 | count |
volume_manager_total_volumes | 当前节点上管理的卷总数 | count |
volume_manager_total_volumes | Kubelet 执行的容器运行时操作总数 | count |
kubelet_runtime_operations_total | Kubelet 执行的容器运行时操作失败的次数 | count |
kubelet_runtime_operations_errors_total | Kubelet 执行的容器运行时操作的持续时间分布 | s |
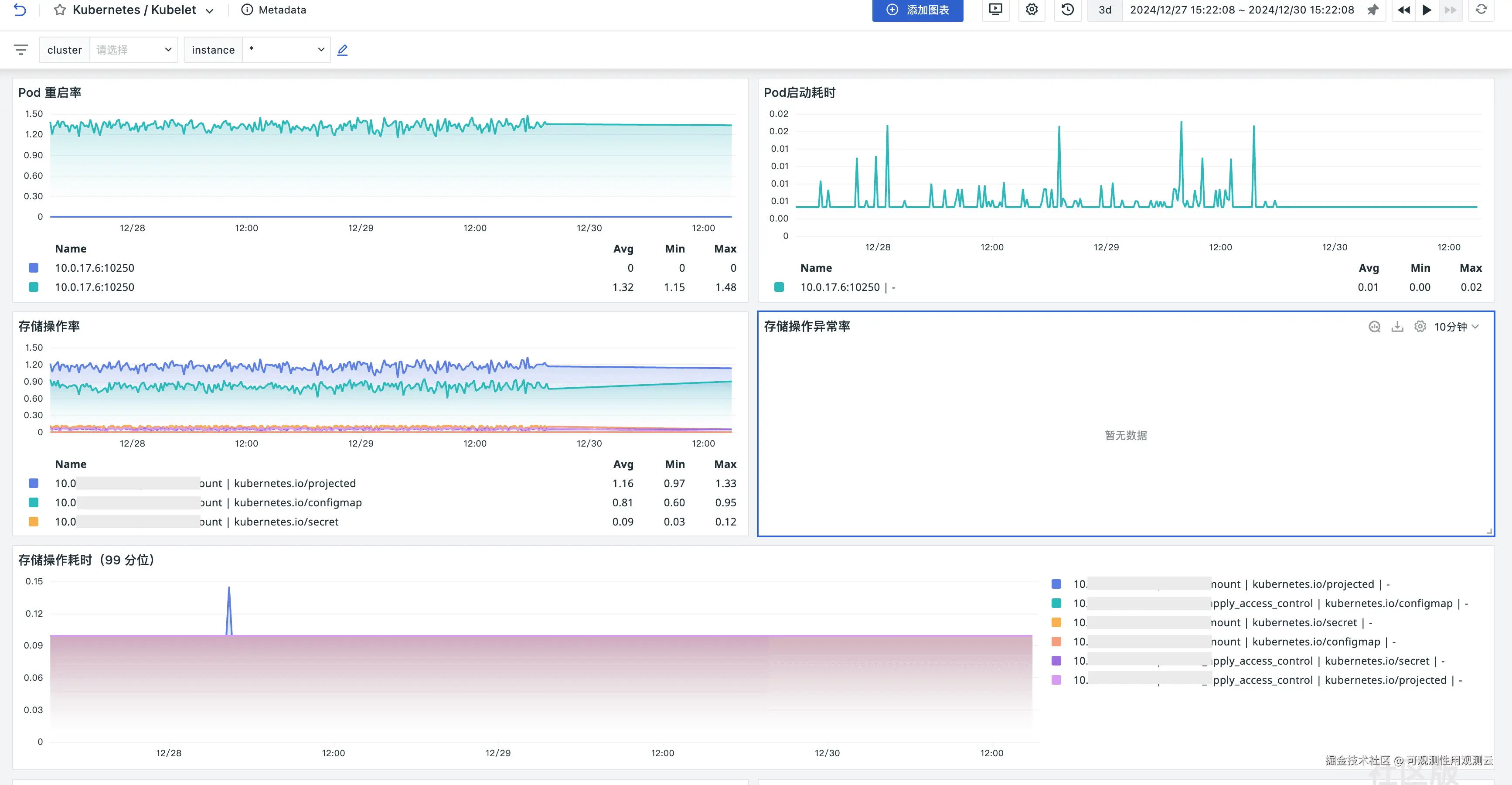
kubelet_runtime_operations_duration_seconds_bucket | Kubelet 启动 Pod 的总次数 | count |
kubelet_pod_start_duration_seconds_count | Kubelet 启动 Pod 的持续时间分布 | s |
kubelet_pod_start_duration_seconds_bucket | 存储操作的总次数 | count |
storage_operation_duration_seconds_count | 存储操作失败的总次数 | count |
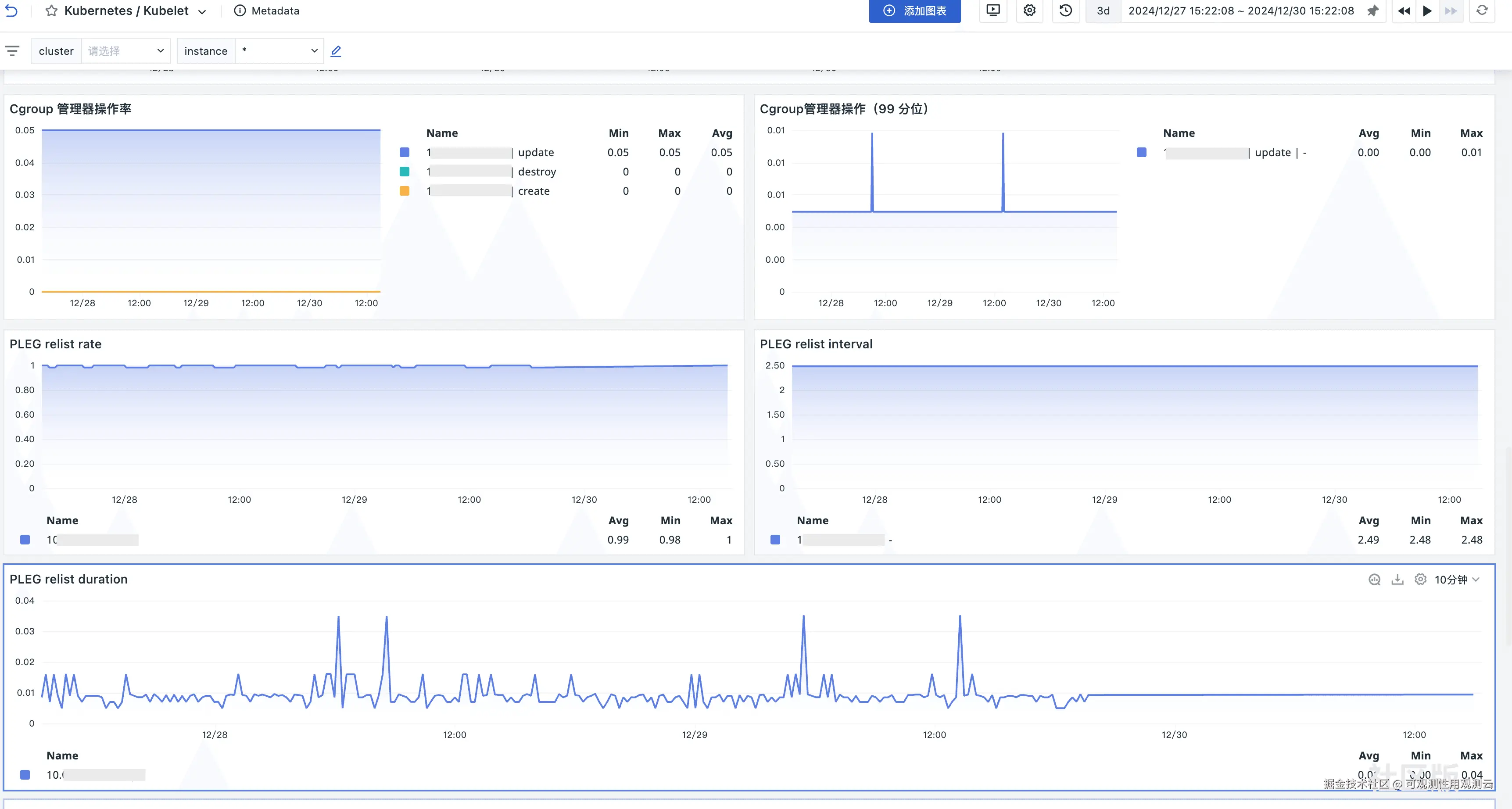
storage_operation_errors_total | Kubelet 管理 cgroup 的操作总次数 | count |
kubelet_cgroup_manager_duration_seconds_count | Kubelet 管理 cgroup 的操作持续时间分布 | s |
kubelet_cgroup_manager_duration_seconds_bucket | Kubelet 的 Pod 生命周期事件生成器(PLEG)重新列出操作的总次数 | count |
kubelet_pleg_relist_duration_seconds_count | Kubelet 向 Kubernetes API Server 发送的 REST 请求总数 | count |
rest_client_requests_total | Kubelet 向 Kubernetes API Server 发送的 REST 请求的持续时间分布 | count |
rest_client_request_duration_seconds_bucket | Kubelet 进程占用的物理内存大小 | byte |
process_resident_memory_bytes | Kubelet 进程占用的 CPU 时间总和 | s |
process_cpu_seconds_total | Kubelet 进程占用的 CPU 时间总和 | s |
go_goroutines | Kubelet 进程中活跃的 Go 协程数量 | count |
场景视图
监控器(告警)
Kubelet 内存告警
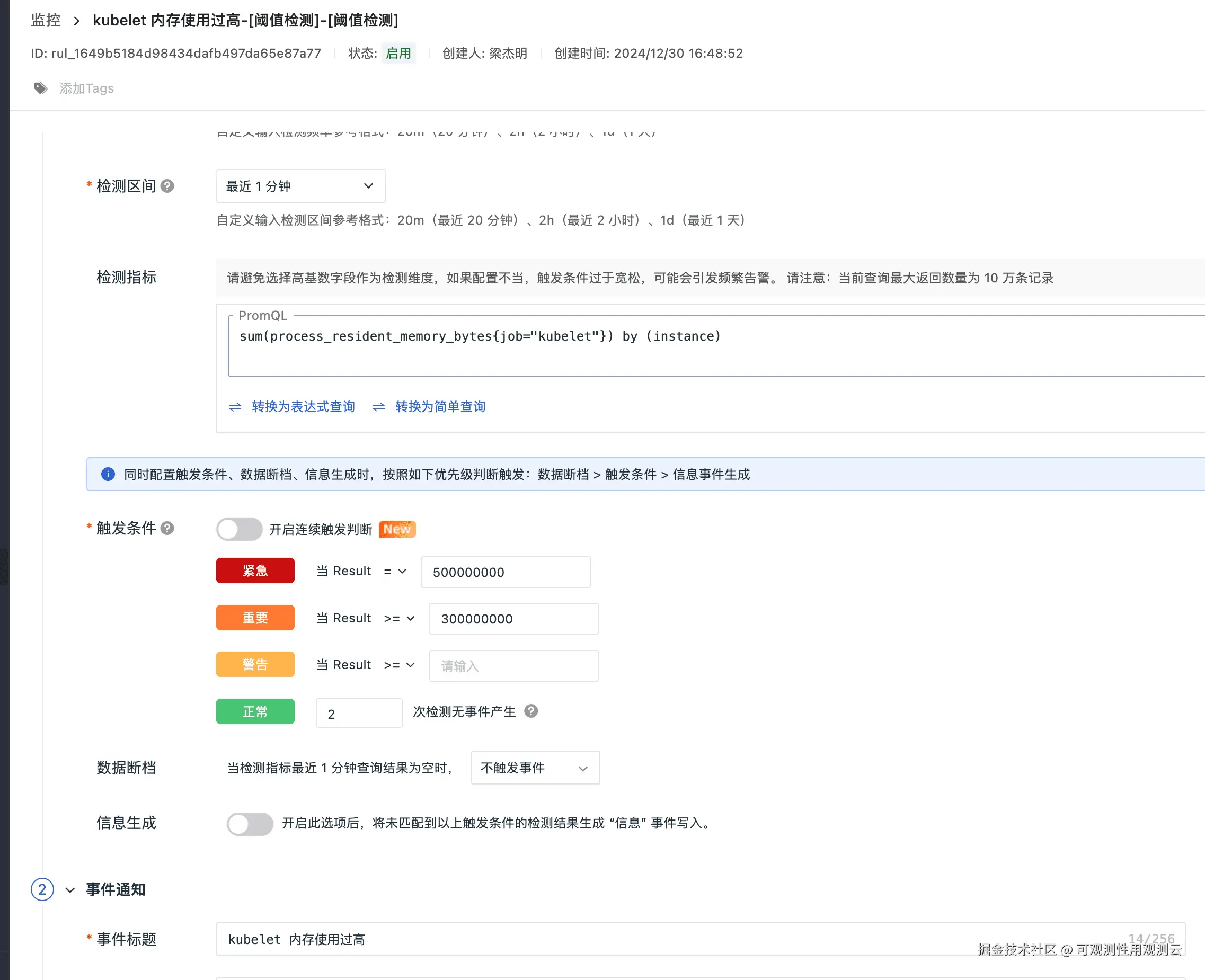
Kubelet CPU告警
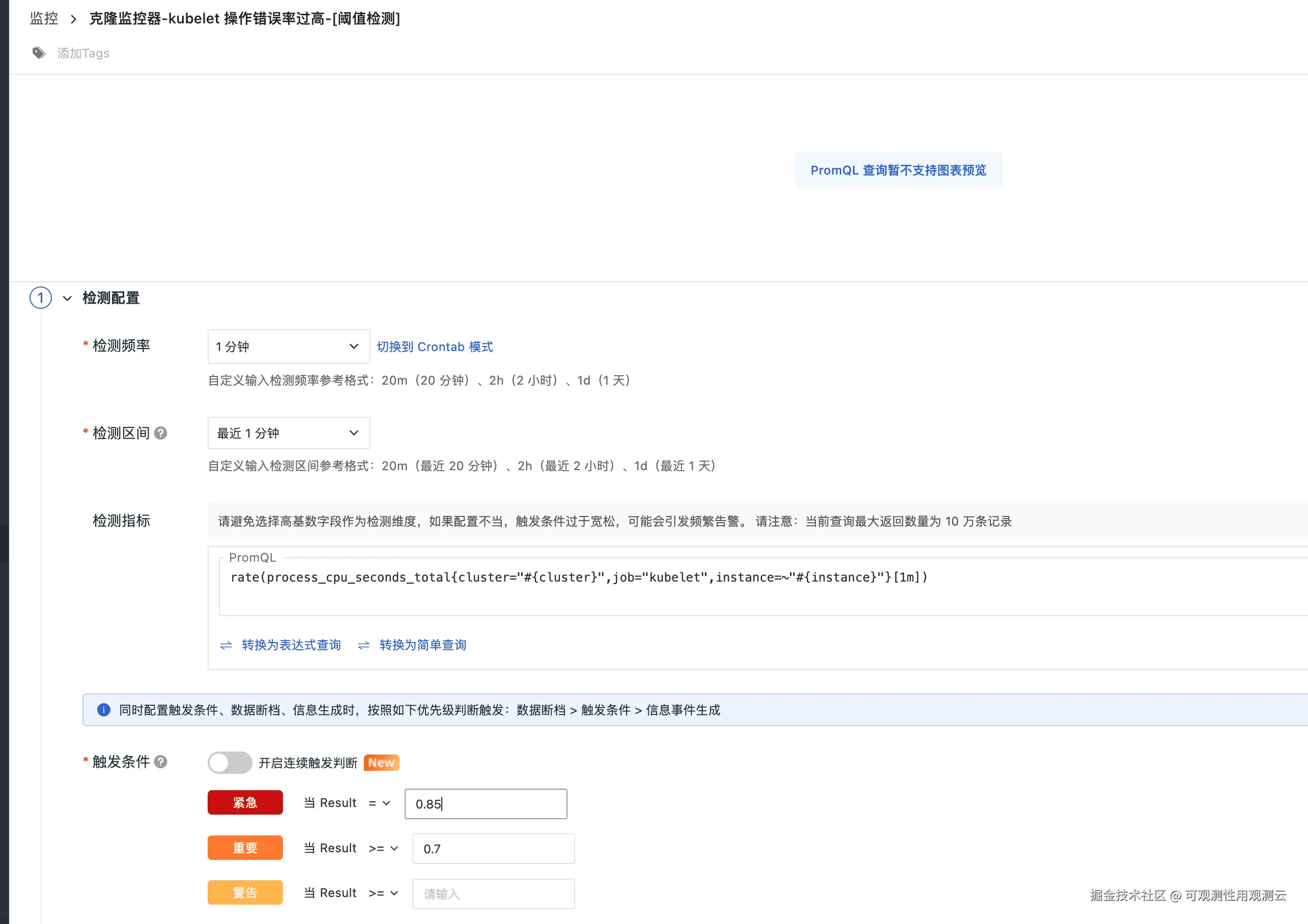
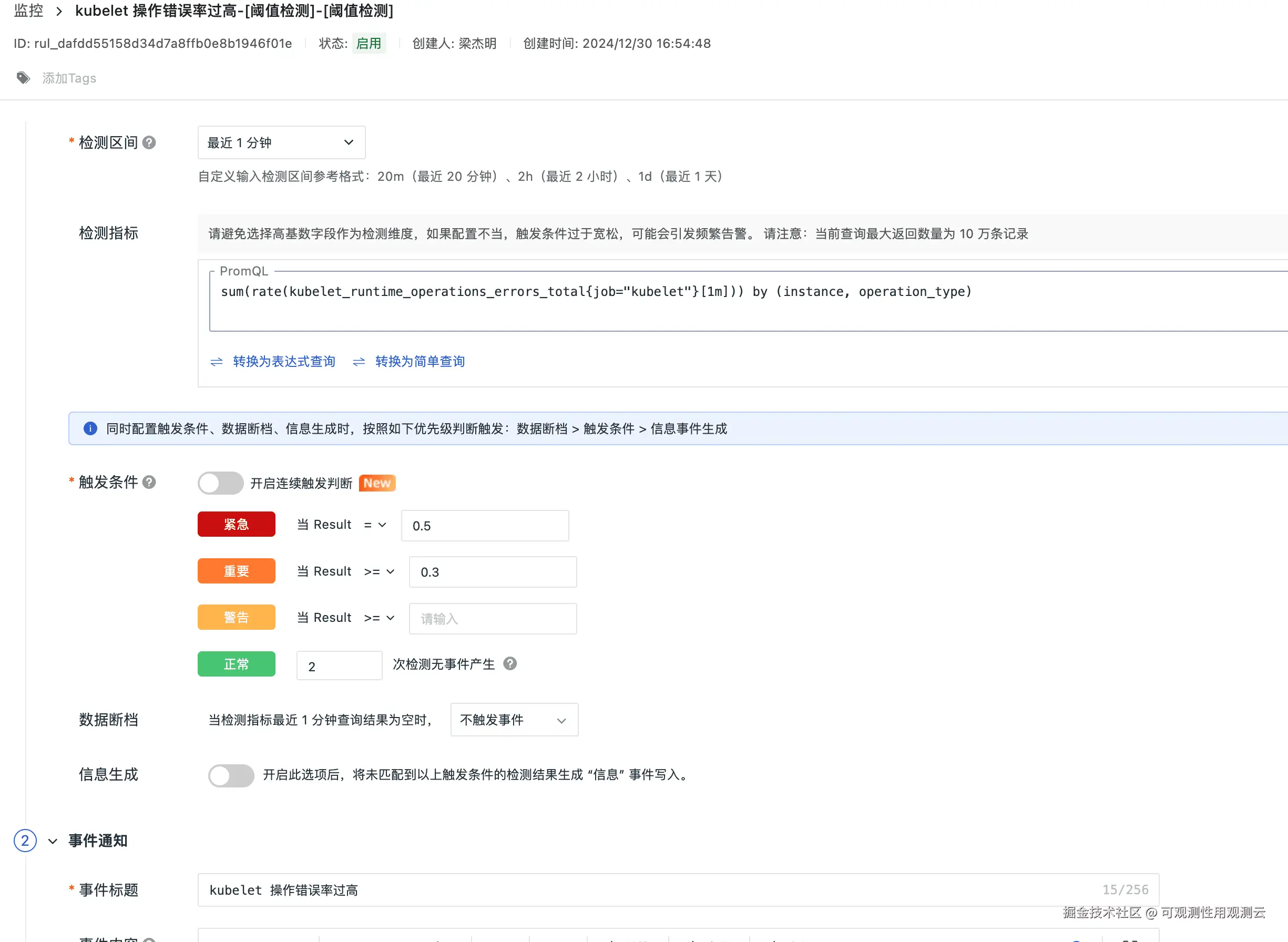
Kubelet 操作错误率过高告警
总结
Kubelet 是 Kubernetes 集群中负责维护容器生命周期的核心组件,其性能监控对于保障集群稳定性和效率至关重要。借助观测云,用户不仅能实时掌握 Kubelet 的运行状态,还能通过场景视图直观呈现监控数据,并设置监控器实现告警功能,从而有效管理 Kubelet 性能,提升 Kubernetes 集群的整体可靠性与性能。
评论记录:
回复评论: