
戳蓝字“CSDN云计算”关注我们哦!

本文转载自公众号:中桥调研咨询
向数字化转型已经深入人心,在数字经济下,IT架构正在向以数字为核心转变,云计算的普及和多元化趋势驱动了人工智能和物联网的快速发展,而两者的融合(AIoT)将为彼此打开新的应用天地。5G所带来的影响不容小觑,超融合和NVMe SSD市场将持续升温。中桥综合对中国企业IT管理者千余人次的调研,以及对超过百名IT决策者的深访,认为以下热点在2019年值得关注。
1
IT架构转向以数据为核心随着向数字化转型的深入,整个IT正在从传统的以物理设备为核心的数据中心架构,向以数据为核心的IT架构转型。在传统经济下,用户更关心数据中心的可靠性和稳定性以及降低IT成本,但传统IT架构应用部署周期长,运维管理复杂,响应速度慢。互联网、大数据、云计算、物联网和人工智能的相继兴起,不断催生以数据为驱动力的新经济快速发展,互联网原生应用和云原生应用大量涌现,应用多元化成为常态,但这些应用由于开发和上线都是“短平快”方式,往往在可靠性和安全性方面薄弱。因此,如何构建以数据为核心的跨核心、多云和边缘的IT架构,通过数据实现业务价值,已经成为企业向数字化转型和实现业务模式创新突破的关键。
2
云计算向下一代发展
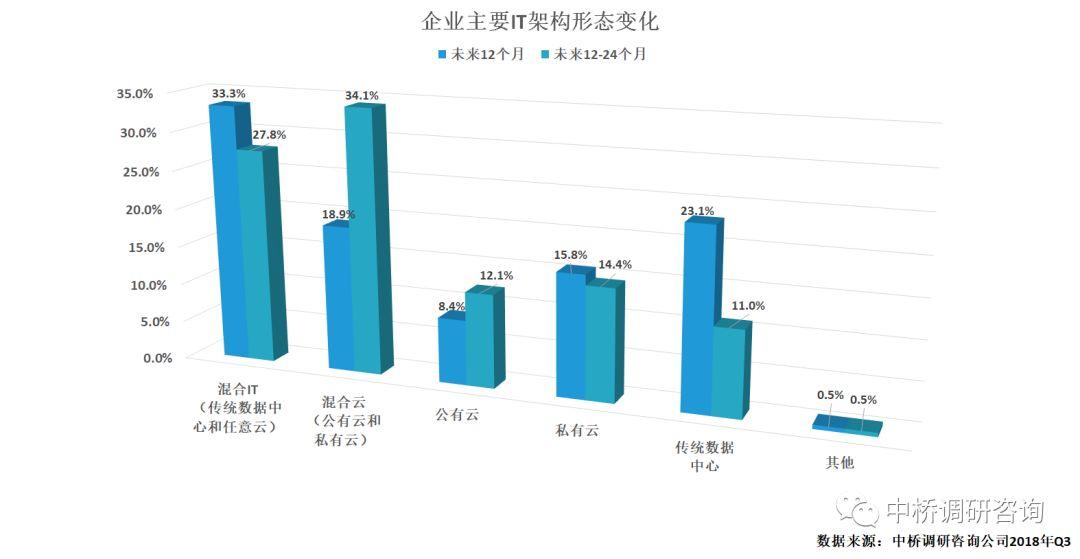
向数字化转型推动了云计算的持续演进。在云计算兴起的初期阶段,公有云和私有云泾渭分明,非此即彼,但随着云计算的不断发展,以及用户需求的变化,公有云或私有云已经不是用户的惟一选择,它们之间的边界将越来越模糊。一方面,公有云服务商已经开始涉足私有云,另一方面,私有云提供商也与更多的公有云服务商合作。因此,未来混合云和多云将成为趋势,用户甚至不需要知道到底用的是什么形式的云,而是关注云所带来的业务价值,云层之上不同云之间的数据共享、透明管理甚至工作负载动态迁移将成为其中的焦点问题,考量云计算更多的是跨核心、跨多云、跨边缘计算的能力。另外,随着云的深入发展,云计算从中小微企业逐渐向中大型企业普及,更多的企业级用户将云作为IT架构的一部分,并且多云和混合云将是大多数企业级用户的选择,中桥调研数据也表明,未来混合云将呈现出快速增长趋势(下图)。与此同时,云计算已经逐渐演进成为支撑人工智能和物联网应用发展的有力平台。
3
如何将人工智能技术转化为业务价值面临挑战
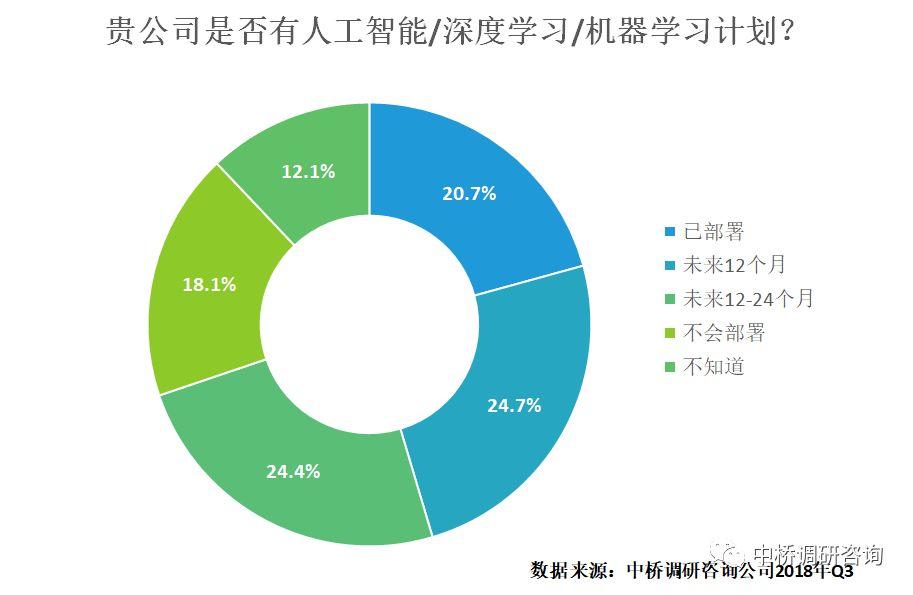
近两年来,云计算和大数据的快速发展激发了对人工智能(AI)和机器学习技术研发的热潮,无论是交通、电力、生命科学,还是健康、教育、制造业,许多企业和机构都将应用AI列为未来业务的重点。中桥调研数据显示,在受访企业中,有超过49%的企业在未来两年将会部署AI/深度学习/机器学习(下图),期望通过AI将数据转化为业务价值。不过,尽管AI目前技术上发展很快,但从技术研发到实际应用,并将数据和资源转化为业务价值还面临着诸多挑战,同时,对IT架构跨云、核心和边缘计算的能力要求也越来越高。在应用层面,应用开发者亟需通过API接口提升AI应用开发的速度,尽快将数据和资源转化为业务能力;在建模层面,由于目前我国AI人才尤其是数据科学家匮乏,亟需通过AI平台和建模工具来简化建模过程,实现数据的抓取、标签等,加快AI应用的普及。因此,从AI技术研发到实现应用的业务创新和突破,还有不小的距离,构建业务应用的API接口和行业AI平台是AI应用普及的关键环节。
4
AIoT拓展人工智能的应用领域
人工智能(AI)通过对大量数据的分析和深度学习,从中得到预测性的推断;而物联网(IoT)则是通过大量互联设备或装置,完成对数据的采集。因此,AI和IoT的结合——AIoT将通过IoT进行数据采集,并依靠AI对数据进行分析、辨识,发现异常、预测未来。可以预测,AIoT未来的发展将影响到各行各业,使AI在应用层面具有更多的可能性,产生更多的创新应用,并将在交通、安防、环保等行业率先应用。AI将最大化IoT数据带来的价值,而IoT又能为AI提供所需的数据流。中桥调研数据表明,未来两年中国企业用户的IT重点将逐渐转移到AI和IoT,AIoT将成为新一代的“黄金组合”,实现从数据采集到智能分析的一站式解决方案,真正将“人与人”、“物与物”、“人与物”之间相连接的价值发挥至最大。尤其随着5G的落地,将大大提升IoT前端的计算能力和数据传输能力,进一步促进AI和IoT的融合。
5
物联网加快云到边缘计算的迁移
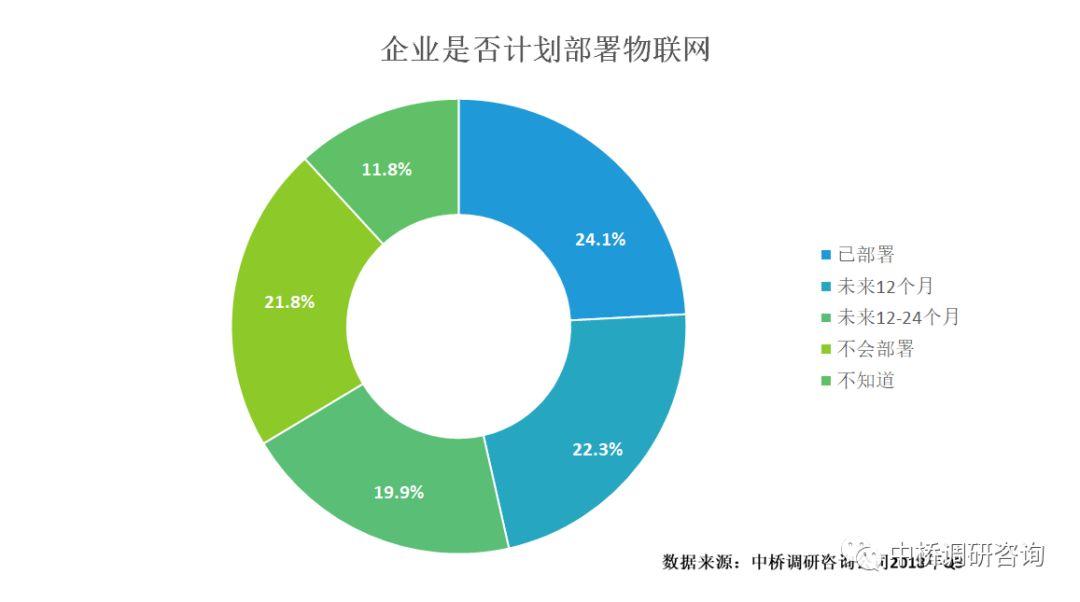
物联网从IoT(Internet of Things)到IoE(Internet of Everything),再到IIoT(Industrial IoT),正在经历一个持续演进的发展过程。物联网被认为是继计算机、互联网、智能手机之后世界信息产业发展的下一个风口。未来,物联网和以物联网为依托的新技术变革,将会为中国的经济发展和业务创新带来更多的机遇,中桥调研数据也表明,在受访企业中,有超过40%的企业在未来两年将部署物联网(下图),以期通过物联网加速企业创新变革和转型升级。同时,物联网的发展加速了工作负载从云到边缘计算的迁移,使更多的应用从云上下来,更靠近“数据源”,从而实现数据收集、处理和分析的低延迟,降低数据传输的压力,提高效率,并将带动边缘计算的大发展。因此,物联网将推动边缘计算的发展,同时将使超融合技术更加火热。
6
超融合技术持续演进
传统经济向数字经济的转型促使超融合(HCI)技术出现和发展,并不断推进超融合从HCI 1.0向HCI 2.0和HCI 3.0的持续演进。超融合技术出现之初的HCI 1.0,通过整合服务器、存储和网络资源,缩短IT部署周期,并简化IT管理,实现了架构和应用的对接,但异构HCI也形成了新的应用孤岛;随着IT向以数据为核心转型,为适应同时满足传统IT应用和云原生新应用的需求,超融合开始向HCI 2.0演进,实现工作负载双向迁移,同时通过压缩、去重、容灾等进行数据管理,满足混合云和多云的需求;未来,由于人工智能和物联网的兴起,使跨云、核心和边缘实现工作负载的动态多向迁移成为IT新的需求,并满足以数据为核心实现数据自动化的管理、保护、容灾、访问权限等个性化的QoS,由此将推动超融合进一步向HCI 3.0演进。
7
5G对NFV和AI的影响巨大
更低延迟、更高带宽、更大容量的5G即将到来,它将对很多行业产生巨大的影响,尤其是通信行业,当3G、4G呈现出管道化趋势时,5G将带来通信行业的重新“洗牌”和布局。作为5G的关键技术之一,NFV(网络功能虚拟化)市场将随着5G的到来而获得更大的发展机遇,5G将带来网络流量的急速增长,而现有网络的灵活性难以应对未来整个电信运营商、企业网络、云端、OTT等需求,网络虚拟化进程必将加速,迫切需要NFV技术。同时,5G将为人工智能(AI)和物联网(IoT)的发展助力,一方面将带动智能医疗、智能家居、智能电网、智能交通、智能农业和智能制造的快速推进,另一方面,5G将使万物互联(IoE)成为现实。
8
全闪存和NVMe SSD将持续增长
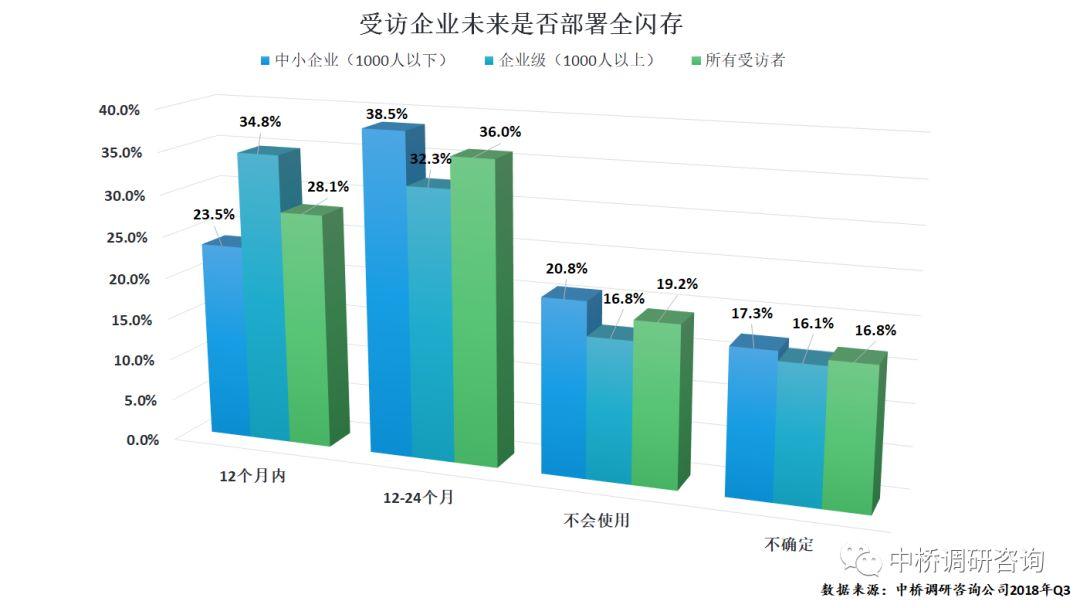
在企业级IT应用中,闪存特别是全闪存所带来的好处已经广为人知,并被越来越多的企业和机构所接受。中桥调研数据显示,对于全闪存的选择,在受访企业中,只有36%的企业目前没有具体的计划,而64%的企业在未来两年都将相继部署全闪存(下图)。同时,SATA/SAS SSD将逐年减少,而取而代之的将是性能大幅提升、功耗降低的NVMe SSD。由于近年来NVMe技术逐渐成熟,软硬件生态系统建设日益完善,未来将呈现持续增长态势。尤其是物联网和人工智能的快速崛起,拓展了NVMe的应用领域,加上来自互联网公司和运营商的大型数据中心的应用需求,这些都将进一步拉动NVMe市场的增长。不过,NVMe SSD的价格因素仍将是其发展的一大障碍。

福利
扫描添加小编微信,备注“姓名+公司职位”,加入【云计算学习交流群】,和志同道合的朋友们共同打卡学习!


推荐阅读:
K8S安全军规101:对CNCF最佳实践的扩充
50个最有价值的数据可视化图表(推荐收藏)
微服务、Kubernetes和无服务器之后,即将发生的……
月入5万,程序员夫人们过上"贵妇"生活了吗?
为什么说稳定币才是诺奖得主哈耶克想要的非国家货币?
“扔瓶子”有套路?日本高中生开发机器人,手残党们有救了
那些简历造假拿 Offer 的程序员,后来都怎么样了?
 喜欢就点击“好看”吧
喜欢就点击“好看”吧
引言
在金融、电信等高并发场景下,GaussDB作为国产分布式数据库的核心组件,其Schema设计直接影响数据治理效率、查询性能和资源利用率。本文基于GaussDB 特性,深入解析Database与Schema的协同设计方法,通过5大行业场景的实战案例,揭示分布式环境下Schema设计的黄金法则,并结合智能索引、资源隔离等高级特性,构建企业级数据架构的完整解决方案。
一、GaussDB架构与Schema核心机制
1.1 分布式架构下的Schema组织
sql 代码解读复制代码-- 查看数据库全局视图
SELECT db_name,
schema_name,
table_count,
data_size
FROM information_schema.schemata
WHERE db_name = 'finance_db';
- 三级组织架构:Database → Schema → Object的层级关系
- 多租户支持:通过Schema实现客户数据物理隔离(每个 tenant 对应独立 Schema)
- 资源分组机制:RESOURCE GROUP控制CPU/内存配额(示例:CREATE RESOURCE GROUP rsg_financial WITH (CPU=40%, MEMORY=60GB);)
1.2 Schema的分布式特性

二、Schema设计核心原则
2.1 业务驱动的设计范式
css 代码解读复制代码graph TD
A[业务模型] --> B(实体关系图)
B --> C{是否需要独立Schema?}
C -->|是| D[创建主题Schema]
C -->|否| E[复用公共Schema]
D --> F[定义资源配额]
E --> G[设置权限边界]
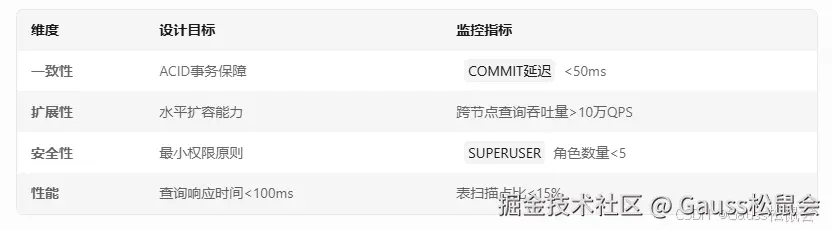
2.2 关键设计指标
三、行业场景实战设计
3.1 金融核心交易系统
sql 代码解读复制代码-- 创建交易Schema并配置资源组
CREATE SCHEMA transactions
RESOURCE GROUP rsg_trading
QUOTA 100GB
WITH (
VERSIONING = ON,
TABLESPACE = ts_trading
);
-- 交易流水表设计
CREATE TABLE orders (
order_id BIGINT PRIMARY KEY,
user_id INT REFERENCES users(user_id),
amount NUMERIC(12,2),
status CHAR(20) CHECK (status IN ('PENDING','SUCCESS','FAILED')),
CREATE_TIME TIMESTAMP DEFAULT CURRENT_TIMESTAMP
) PARTITION BY RANGE (CREATE_TIME) (
PARTITION p202310 VALUES LESS THAN ('2023-11-01'),
PARTITION p202311 VALUES LESS THAN ('2023-12-01')
);
设计要点:
- 按时间分区实现历史数据自动归档
- 使用RESOURCE GROUP限制交易高峰期资源占用
- 启用版本控制防止数据误删
3.2 电商商品目录
sql 代码解读复制代码-- 创建多级分类Schema
CREATE SCHEMA products
WITH (SEARCH_PATH = TO_ARRAY('public', 'products'));
-- 商品表设计
CREATE TABLE items (
sku VARCHAR(30) PRIMARY KEY,
name VARCHAR(255),
category_id INT REFERENCES categories(category_id),
price NUMERIC(10,2),
stock INT CHECK (stock >= 0)
)
WITH (
ORIENTATION = COLUMNSTORE,
COMPRESSION = 'lz4'
);
-- 创建全文索引加速搜索
CREATE INDEX idx_product_search
ON items(name, description)
USING FULLTEXT
LANGUAGE 'zh';
性能优化:
- 列式存储+压缩降低I/O负载
- 全文索引支持模糊搜索(MATCH (name) AGAINST ('智能手机 2023'))
- 预关联类别数据提升查询效率
3.3 物联网设备监控
sql 代码解读复制代码-- 时序数据Schema设计
CREATE SCHEMA iot
WITH (TIMESTAMPwithoutTIMEZONE = true);
-- 设备状态表
CREATE TABLE device_status (
device_id VARCHAR(50),
sensor_type VARCHAR(20),
value NUMERIC(10,2),
timestamp TIMESTAMP DEFAULT CURRENT_TIMESTAMP
) PARTITION BY RANGE (timestamp) (
PARTITION p202310 VALUES LESS THAN ('2023-11-01'),
PARTITION p202311 VALUES LESS THAN ('2023-12-01')
);
-- 创建时间窗口索引
CREATE INDEX idx_iot_time
ON device_status(device_id, timestamp)
USING BRIN;
架构优势:
- 时间分区支持亿级数据存储
- BRIN索引加速时间范围查询
- 自动化冷热数据分离策略
四、高级设计技巧
4.1 智能索引与图计算融合
sql 代码解读复制代码-- 创建物化视图加速关联查询
CREATE MATERIALIZED VIEW mv_user_orders AS
SELECT u.user_id,
COUNT(o.order_id) AS order_count,
SUM(o.amount) AS total_spent
FROM users u
JOIN orders o ON u.user_id = o.user_id
GROUP BY u.user_id;
-- 启用物化视图自动更新
ALTER MATERIALIZED VIEW mv_user_orders SET (REFRESH = 'ON COMMIT');
4.2 多Schema协同查询优化
sql 代码解读复制代码-- 创建跨Schema连接视图
CREATE VIEW cross_schema_report AS
SELECT
s.order_id,
c.customer_name,
i.product_name,
o.status
FROM sales.orders o
JOIN marketing.customers c ON o.customer_id = c.customer_id
JOIN iot.device_status i ON o.order_id = i.device_id;
-- 配置连接路由策略
SET search_path TO sales, marketing, iot;
4.3 自动化运维设计
sql 代码解读复制代码-- 创建Schema健康检查任务
DO $$
DECLARE
schema_name TEXT;
BEGIN
FOR schema_name IN SELECT nspname FROM pg_catalog.pg_namespace
WHERE nspname NOT IN ('pg_catalog', 'information_schema')
AND pg_size_pretty(pg_total_relation_size(n.oid)) > 50GB
LOOP
EXECUTE format(
'ALTER SCHEMA %I SET (QUOTA = 80GB);',
schema_name
);
END LOOP;
END
$$ LANGUAGE plpgsql;
五、监控与维护体系
5.1 关键监控指标
vbnet 代码解读复制代码-- 查询Schema资源使用热力图
SELECT
nspname AS schema_name,
pg_size_pretty(total_size) AS total_size,
COUNT(*) AS object_count,
active_connections AS concurrent_users
FROM pg_catalog.pg_namespace
LEFT JOIN pg_stat_activity ON pg_namespace.oid = pg_stat_activity.relnamespace
GROUP BY nspname
ORDER BY total_size DESC;
5.2 碎片化治理策略
sql 代码解读复制代码-- 执行索引碎片整理
ALTER INDEX idx_user_email REBUILD;
-- 自动清理过期Schema
DO $$
DECLARE
r RECORD;
BEGIN
FOR r IN SELECT nspname FROM pg_catalog.pg_namespace
WHERE nspname LIKE 'temp_%' AND NOT EXISTS (
SELECT 1 FROM pg_catalog.pg_class
WHERE relnamespace = pg_namespace.oid
)
LOOP
EXECUTE format('DROP SCHEMA %I CASCADE', r.nspname);
END LOOP;
END
$$ LANGUAGE plpgsql;
六、安全与合规设计
6.1 数据加密与审计
sql 代码解读复制代码-- 创建加密表空间
CREATE TABLESPACE enc_ts
DATAFILE '/opt/gaussdb/data/enc_ts01.dbf'
SIZE 10GB ENCRYPTED WITH (AES-256, KEY 'secure_key');
-- 启用审计 trails
CREATE AUDIT POLICY db_audit
FOR DATABASE finance_db
AUDITING EVENTS (SELECT, INSERT, UPDATE, DELETE)
WHERE user_role NOT IN (' auditor', ' readonly_user');
6.2 权限最小化实践
sql 代码解读复制代码-- 创建只读视图实现数据隔离
CREATE VIEW financial_report AS
SELECT
department,
SUM(amount) AS total_revenue
FROM transactions
WHERE EXTRACT(YEAR FROM create_time) = 2023
GROUP BY department;
-- 授予受限权限
GRANT SELECT ON financial_report TO hr_team;
REVOKE ALL PRIVILEGES FROM hr_team ON transactions;
七、未来演进方向
7.1 云原生架构升级
yaml 代码解读复制代码# Kubernetes部署配置示例
apiVersion: database.gaussdb.com/v1alpha1
kind: GaussDBCluster
metadata:
name: gaussdb-cluster
spec:
nodes:
cn:
count: 3
instanceType: "cn-small"
dn:
count: 6
instanceType: "dn-medium"
storage:
size: 100GB
autoExpand: true
7.2 智能自治特性
sql 代码解读复制代码-- 启用AI驱动的索引推荐
ALTER SYSTEM SET auto_index = ON;
-- 查看优化建议
SELECT * FROM system.auto_index_suggestions
WHERE table_name = 'orders'
ORDER BY confidence DESC;
结语
在GaussDB中,优秀的Schema设计是构建高性能、可扩展、安全可靠的数据库系统的基石。
作者:hhh1218
评论记录:
回复评论: