


作者 | channingbreeze
责编 | 胡巍巍

小史是一个应届生,虽然学的是电子专业,但是自己业余时间看了很多互联网与编程方面的书,一心想进BAT互联网公司。

今天小史去了一家在线英语培训公司面试了。简单的自我介绍后,面试官给了小史一个问题。


面试现场

题目:我有500w个单词,你帮忙设计一个数据结构来进行存储,存好之后,我有两个需求。
1、来了一个新的单词,需要判断是否在这500w个单词中
2、来了一个单词前缀,给出500w个单词中有多少个单词是该前缀
小史这次没有不假思索就给出回答,他学会了深沉。


小史回忆起吕老师之前教他的Bitmap算法。

小史心想:Bitmap可以判断一个数是否在40亿个int32数中,其核心是每一个数映射成一个位,同时申请的bit位数覆盖了整个int32的值域。
小史在纸上算了半天,终于开口了。



小史:好的,我用Bitmap来做第一问。我把每一个字符串映射成一个位。比如,a是第1位,b是第2位,z是第26位,aa是第27位,ab是第28位,以此类推。英文一共26个字母,我算了一下,6个字符长度的单词总共有26的6次方个,需要占26的6次方个位,大概300M。
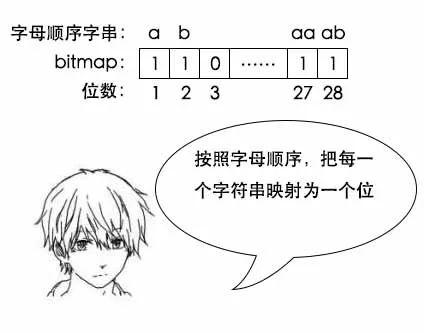








小史:建立数据结构的时候,排序需要花掉nlg(n),排序时字符串比较花掉m,时间一共mnlg(n)。查找的话用二分,就是mlg(n)了,空间是mn。


一分钟过去了。





请教大神
回到学校,小史把面试情况和吕老师说了一下。



吕老师:你想想,a到z这26个字母中,可能只有a和i两个是单词,其他都不是,所以你的Bitmap大量空间都被浪费了。这种情况你搞个Hashset没准还更省一点。




树形结构解难题







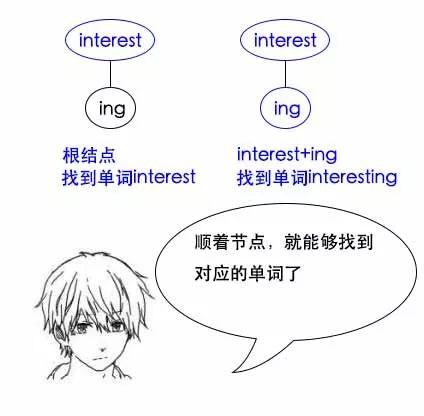
小史:哦,这确实是节省了空间,如果要找单词interest,那么就找根节点了,如果是找单词interesting,那么就从根节点往下走,再把沿路的字母们都拼起来就行了。



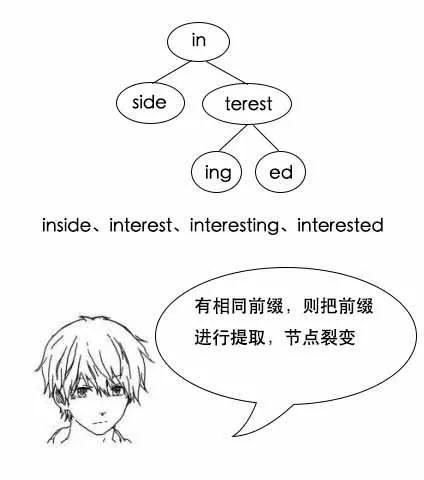

(注:这里说的in不是单词,指的是in不是500w单词中的单词。)
吕老师还没说完,小史就打断了他。

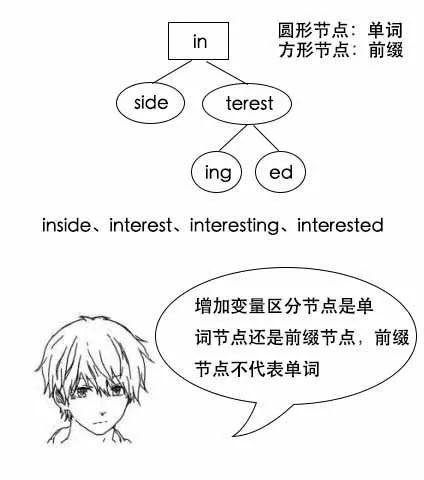


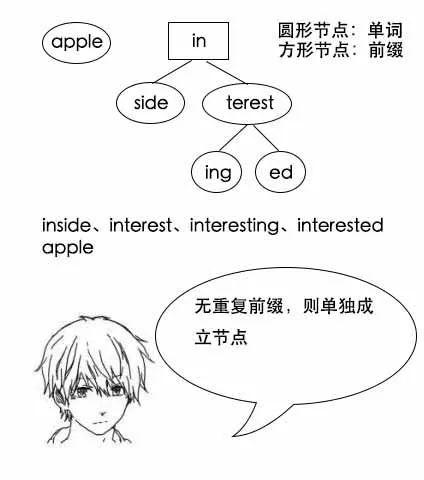

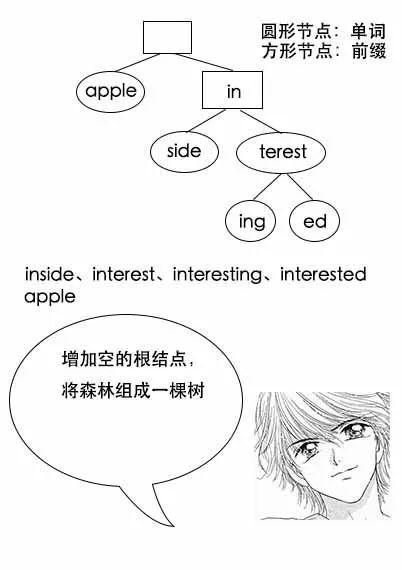

找单词interest:
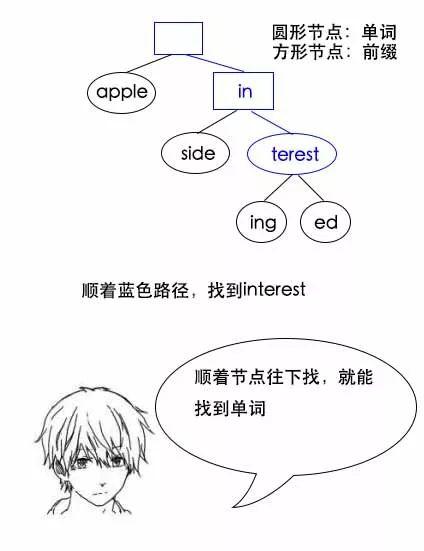
找前缀为inter的所有单词:
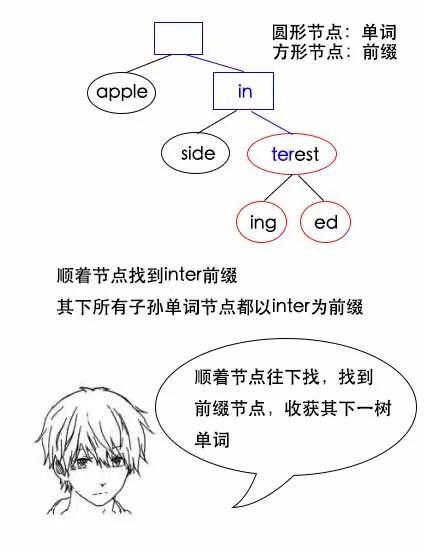
遍历以前缀节点为根结点的一棵树,就能统计出前缀为inter的所有单词有多少个。

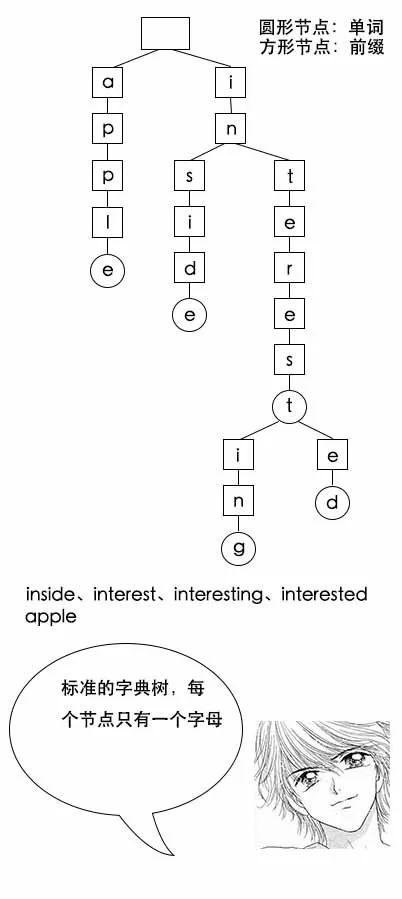
字典树










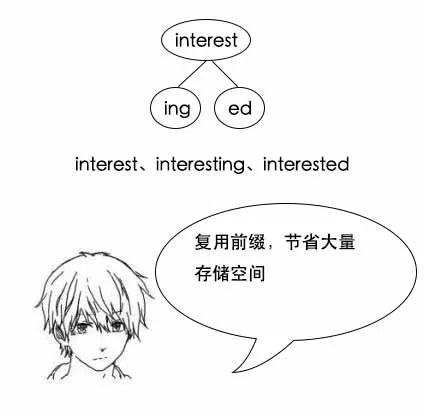
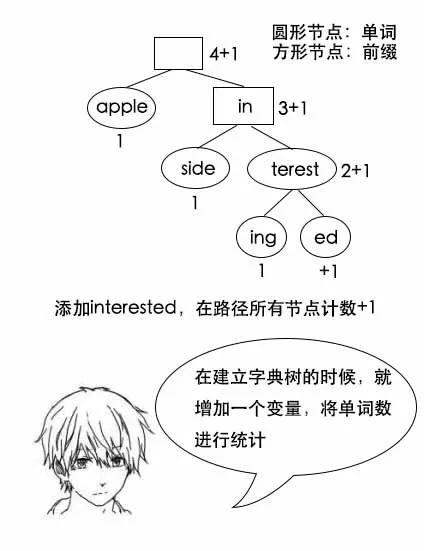
小史:节点中增加一个变量用于计数,在添加节点的时候,就把相应的计数+1。


理解了算法之后,小史的代码写起来也是非常快,不一会儿就写好了:
DictionaryTree.java:
import java.util.HashMap;import java.util.Map;/** * @author xiaoshi on 2018/10/5. */public class DictionaryTree { // 字典树的节点 private class Node { // 是否是单词 private boolean isWord; // 单词计数 private int count; // 字串 private String str; // 子节点 private Map childs; // 父节点 private Node parent; public Node() { childs = new HashMap(); } public Node(boolean isWord, int count, String str) { this(); this.isWord = isWord; this.count = count; this.str = str; } public void addChild(String key, Node node) { childs.put(key, node); node.parent = this; } public void removeChild(String key) { childs.remove(key); } public String toString() { return "str : " + str + ", isWord : " + isWord + ", count : " + count; } } // 字典树根节点 private Node root; DictionaryTree() { // 初始化root root = new Node(); } // 添加字串 private void addStr(String word, Node node) { // 计数 node.count++; String str = node.str; if(null != str) { // 寻找公共前缀 String commonPrefix = ""; for(int i=0; i i && word.charAt(i) == str.charAt(i)) { commonPrefix += word.charAt(i); } else { break; } } // 找到公共前缀 if(commonPrefix.length() > 0) { if (commonPrefix.length() == str.length() && commonPrefix.length() == word.length()) { // 与之前的词重复 } else if(commonPrefix.length() == str.length() && commonPrefix.length() < word.length()) { // 剩余的串 String wordLeft = word.substring(commonPrefix.length()); // 剩余的串去子节点中继续找 searchChild(wordLeft, node); } else if(commonPrefix.length() < str.length()) { // 节点裂变 Node splitNode = new Node(true, node.count, commonPrefix); // 处理裂变节点的父关系 splitNode.parent = node.parent; splitNode.parent.addChild(commonPrefix, splitNode); node.parent.removeChild(node.str); node.count--; // 节点裂变后的剩余字串 String strLeft = str.substring(commonPrefix.length()); node.str = strLeft; splitNode.addChild(strLeft, node); // 单词裂变后的剩余字串 if(commonPrefix.length() < word.length()) { splitNode.isWord = false; String wordLeft = word.substring(commonPrefix.length()); Node leftNode = new Node(true, 1, wordLeft); splitNode.addChild(wordLeft, leftNode); } } } else { // 没有共同前缀,直接添加节点 Node newNode = new Node(true, 1, word); node.addChild(word, newNode); } } else { // 根结点 if(node.childs.size() > 0) { searchChild(word, node); } else { Node newNode = new Node(true, 1, word); node.addChild(word, newNode); } } } // 在子节点中添加字串 public void searchChild(String wordLeft, Node node) { boolean isFind = false; if(node.childs.size() > 0) { // 遍历孩子 for(String childKey : node.childs.keySet()) { Node childNode = node.childs.get(childKey); // 首字母相同,则在该子节点继续添加字串 if(wordLeft.charAt(0) == childNode.str.charAt(0)) { isFind = true; addStr(wordLeft, childNode); break; } } } // 没有首字母相同的孩子,则将其变为子节点 if(!isFind) { Node newNode = new Node(true, 1, wordLeft); node.addChild(wordLeft, newNode); } } // 添加单词 public void add(String word) { addStr(word, root); } // 在节点中查找字串 private boolean findStr(String word, Node node) { boolean isMatch = true; String wordLeft = word; String str = node.str; if(null != str) { // 字串与单词不匹配 if(word.indexOf(str) != 0) { isMatch = false; } else { // 匹配,则计算剩余单词 wordLeft = word.substring(str.length()); } } // 如果匹配 if(isMatch) { // 如果还有剩余单词长度 if(wordLeft.length() > 0) { // 遍历孩子继续找 for(String key : node.childs.keySet()) { Node childNode = node.childs.get(key); boolean isChildFind = findStr(wordLeft, childNode); if(isChildFind) { return true; } } return false; } else { // 没有剩余单词长度,说明已经匹配完毕,直接返回节点是否为单词 return node.isWord; } } return false; } // 查找单词 public boolean find(String word) { return findStr(word, root); } // 统计子节点字串单词数 private int countChildStr(String prefix, Node node) { // 遍历孩子 for(String key : node.childs.keySet()) { Node childNode = node.childs.get(key); // 匹配子节点 int childCount = countStr(prefix, childNode); if(childCount != 0) { return childCount; } } return 0; } // 统计字串单词数 private int countStr(String prefix, Node node) { String str = node.str; // 非根结点 if(null != str) { // 前缀与字串不匹配 if(prefix.indexOf(str) != 0 && str.indexOf(prefix) != 0) { return 0; // 前缀匹配字串,且前缀较短 } else if(str.indexOf(prefix) == 0) { // 找到目标节点,返回单词数 return node.count; // 前缀匹配字串,且字串较短 } else if(prefix.indexOf(str) == 0) { // 剩余字串继续匹配子节点 String prefixLeft = prefix.substring(str.length()); if(prefixLeft.length() > 0) { return countChildStr(prefixLeft, node); } } } else { // 根结点,直接找其子孙 return countChildStr(prefix, node); } return 0; } // 统计前缀单词数 public int count(String prefix) { // 处理特殊情况 if(null == prefix || prefix.trim().isEmpty()) { return root.count; } // 从根结点往下匹配 return countStr(prefix, root); } // 打印节点 private void printNode(Node node, int layer) { // 层级递进 for(int i=0; i (友情提示:本文所有代码均可左右滑动))
Main.java:
/**
* @author xiaoshi on 2018/10/5.
*/
public class Main {
public static void main(String[] args) {
DictionaryTree dt = new DictionaryTree();
dt.add("interest");
dt.add("interesting");
dt.add("interested");
dt.add("inside");
dt.add("insert");
dt.add("apple");
dt.add("inter");
dt.add("interesting");
dt.print();
boolean isFind = dt.find("inside");
System.out.println("find inside : " + isFind);
int count = dt.count("inter");
System.out.println("count prefix inter : " + count);
}
}
运行结果:
str : null, isWord : false, count : 8 str : apple, isWord : true, count : 1 str : in, isWord : false, count : 7 str : ter, isWord : true, count : 5 str : est, isWord : true, count : 4 str : ing, isWord : true, count : 2 str : ed, isWord : true, count : 1 str : s, isWord : false, count : 2 str : ert, isWord : true, count : 1 str : ide, isWord : true, count : 1find inside : truecount prefix inter : 5
字典树的应用


小史:我想想啊,大量字符串的统计和查找应该就可以用字典树吧?字符串前缀的匹配也可以用,像咱们搜索常见的AutoComplete控件是不是就可以用?




作者简介:channingbreeze,国内某互联网公司全栈开发。
声明:本文为作者投稿,版权归对方所有。作者独立观点,不代表 CSDN 立场。
推荐阅读:

 微信公众号
微信公众号

评论记录:
回复评论: