


作者 | 倪升武
责编 | 胡巍巍
现在基本上所有网站都支持搜索功能,现在搜索的工具有很多,比如Solr、Elasticsearch,它们都是基于 Lucene 实现的,各有各的使用场景。Lucene 比较灵活,中小型项目中使用的比较多,我个人也比较喜欢用。

效果展示
我前段时间做了一个网站,搜索功能用的就是 Lucene 技术,效果还可以,支持中文高亮显示,支持标题和摘要同时检索,若能检索出,均高亮展示等功能,可以看下效果。
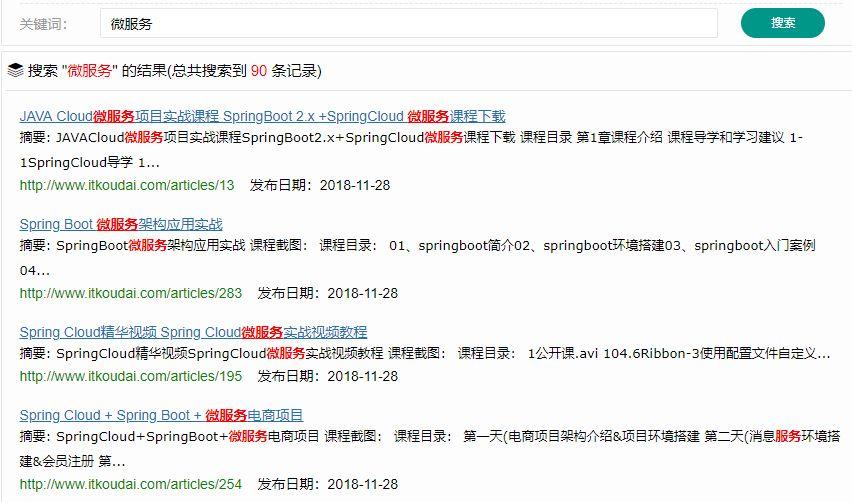
点击查看更清晰
可以看出,搜索 “微服务” 之后,可以将相关的资源全部检索出来,不管是标题包含还是摘要包含都可以检索出来。
这是比较精确的匹配,还有非精确的匹配也支持,比如我搜索 “Java项目实战”,看看结果如何。
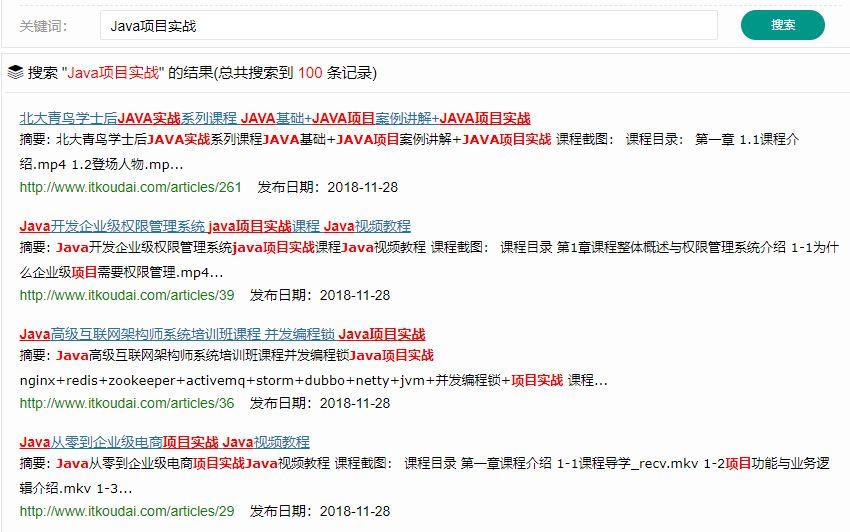
点击查看更清晰
可以看出,如果不能完全精确匹配,Lucene 也可以做模糊匹配,将最接近搜索的内容给检索出来,展示在页面上。
我个人还是比较喜欢使用 Lucene 的,关于 Lucene 全文检索的原理我就不浪费篇幅介绍了,谷歌百度有一大堆原理。这篇文章主要来分享下如何使用 Lucene 做到这个功能。

依赖导入
使用 Lucene 有几个核心的依赖需要导入到项目中,上面展示的这个效果涉及到中文的分词,所以中文分词依赖也需要导入。
<dependency>
<groupId>org.apache.lucenegroupId>
<artifactId>lucene-coreartifactId>
<version>5.3.1version>
dependency>
<dependency>
<groupId>org.apache.lucenegroupId>
<artifactId>lucene-queryparserartifactId>
<version>5.3.1version>
dependency>
<dependency>
<groupId>org.apache.lucenegroupId>
<artifactId>lucene-highlighterartifactId>
<version>5.3.1version>
dependency>
<dependency>
<groupId>org.apache.lucenegroupId>
<artifactId>lucene-analyzers-smartcnartifactId>
<version>5.3.1version>
dependency>

建立分词索引
使用 Lucene 首先要建立索引,然后再查询。如何建立索引呢?为了更好的说明问题,我在这写一个 demo:直接对字符串内容建立索引。
因为在实际项目中,绝大部分情况是获取到一些文本字符串(比如从表中查询出来的结果),然后对该文本字符串建立索引。
索引建立的过程,先要获取 IndexWriter 对象,然后将相关的内容生成索引,索引的 Key 可以自己根据项目中的情况来自定义,value 是自己处理过的文本,或者从数据库中查询出来的文本。生成的时候,我们需要使用中文分词器。代码如下:
public class ChineseIndexer {
/**
* 存放索引的位置
*/
private Directory dir;
//准备一下用来测试的数据
//用来标识文档
private Integer ids[] = {1, 2, 3};
private String citys[] = {"上海", "南京", "青岛"};
private String descs[] = {
"上海是个繁华的城市。",
"南京是一个文化的城市南京,简称宁,是江苏省会,地处中国东部地区,
长江下游,濒江近海。全市下辖11个区,总面积6597平方公里,2013年建
成区面积752.83平方公里,常住人口818.78万,其中城镇人口659.1万人。
[1-4] “江南佳丽地,金陵帝王州”,南京拥有着6000多年文明史、近2600
年建城史和近500年的建都史,是中国四大古都之一,有“六朝古都”、
“十朝都会”之称,是中华文明的重要发祥地,历史上曾数次庇佑华夏之正
朔,长期是中国南方的政治、经济、文化中心,拥有厚重的文化底蕴和丰富
的历史遗存。[5-7] 南京是国家重要的科教中心,自古以来就是一座崇文重
教的城市,有“天下文枢”、“东南第一学”的美誉。截至2013年,南京有
高等院校75所,其中211高校8所,仅次于北京上海;国家重点实验室25所、
国家重点学科169个、两院院士83人,均居中国第三。[8-10] 。",
"青岛是一个美丽的城市。"
};
/**
* 生成索引
* @param indexDir
* @throws Exception
*/
public void index(String indexDir) throws Exception {
dir = FSDirectory.open(Paths.get(indexDir));
// 先调用 getWriter 获取IndexWriter对象
IndexWriter writer = getWriter();
for(int i = 0; i < ids.length; i++) {
Document doc = new Document();
// 把上面的数据都生成索引,分别用id、city和desc来标识
doc.add(new IntField("id", ids[i], Field.Store.YES));
doc.add(new StringField("city", citys[i], Field.Store.YES));
doc.add(new TextField("desc", descs[i], Field.Store.YES));
//添加文档
writer.addDocument(doc);
}
//close了才真正写到文档中
writer.close();
}
/**
* 获取IndexWriter实例
* @return
* @throws Exception
*/
private IndexWriter getWriter() throws Exception {
//使用中文分词器
SmartChineseAnalyzer analyzer = new SmartChineseAnalyzer();
//将中文分词器配到写索引的配置中
IndexWriterConfig config = new IndexWriterConfig(analyzer);
//实例化写索引对象
IndexWriter writer = new IndexWriter(dir, config);
return writer;
}
public static void main(String[] args) throws Exception {
new ChineseIndexer().index("D:\\lucene2");
}
}
这里我们用 ID、city、desc 分别代表 ID、城市名称和城市描述,用他们作为关键字来建立索引,后面我们获取内容的时候,主要来获取城市描述。
南京的描述我故意写的长一点,因为下文检索的时候,根据不同的关键字会检索到不同部分的信息,有个权重的概念在里面。
然后执行一下 main 方法,将索引保存到 D:\lucene2\ 中。

中文分词查询
中文分词查询效果是:将查询出来的关键字标红加粗。它的原理很简单:需要计算出一个得分片段,这是什么意思呢?
比如上面那个文本中我搜索 “南京文化” 跟搜索 “南京文明”,应该会返回不同的结果,这个结果是根据计算出的得分片段来确定的。
这么说,大家可能不太明白,我举个更加通俗的例子,比如有一段文本:“你好,我的名字叫倪升武,科大讯飞软件开发工程师……江湖人都叫我武哥,我一直觉得,人与人之间讲的是真诚,而不是套路。……”。
如果我搜 “倪升武”,可能会给我返回结果:“我的名字叫倪升武,科大讯飞软件开发工程师”;
如果我搜 “武哥”,可能会给我返回结果:“江湖人都叫我武哥,我一直觉得”。这就是根据搜索关键字来计算一段文本不同地方的得分,将最符合的部分搜出来。
明白了原理,我们看一下代码,我把详细的步骤写在注释中了,避免大篇幅阐述。
public class ChineseSearch {
private static final Logger logger = LoggerFactory.getLogger(ChineseSearch.class);
public static List<String> search(String indexDir, String q) throws Exception {
//获取要查询的路径,也就是索引所在的位置
Directory dir = FSDirectory.open(Paths.get(indexDir));
IndexReader reader = DirectoryReader.open(dir);
IndexSearcher searcher = new IndexSearcher(reader);
//使用中文分词器
SmartChineseAnalyzer analyzer = new SmartChineseAnalyzer();
//由中文分词器初始化查询解析器
QueryParser parser = new QueryParser("desc", analyzer);
//通过解析要查询的String,获取查询对象
Query query = parser.parse(q);
//记录索引开始时间
long startTime = System.currentTimeMillis();
//开始查询,查询前10条数据,将记录保存在docs中
TopDocs docs = searcher.search(query, 10);
//记录索引结束时间
long endTime = System.currentTimeMillis();
logger.info("匹配{}共耗时{}毫秒", q, (endTime - startTime));
logger.info("查询到{}条记录", docs.totalHits);
//如果不指定参数的话,默认是加粗,即
SimpleHTMLFormatter simpleHTMLFormatter = new SimpleHTMLFormatter("
//根据查询对象计算得分,会初始化一个查询结果最高的得分
QueryScorer scorer = new QueryScorer(query);
//根据这个得分计算出一个片段
Fragmenter fragmenter = new SimpleSpanFragmenter(scorer);
//将这个片段中的关键字用上面初始化好的高亮格式高亮
Highlighter highlighter = new Highlighter(simpleHTMLFormatter, scorer);
//设置一下要显示的片段
highlighter.setTextFragmenter(fragmenter);
//取出每条查询结果
List<String> list = new ArrayList<>();
for(ScoreDoc scoreDoc : docs.scoreDocs) {
//scoreDoc.doc相当于docID,根据这个docID来获取文档
Document doc = searcher.doc(scoreDoc.doc);
logger.info("city:{}", doc.get("city"));
logger.info("desc:{}", doc.get("desc"));
String desc = doc.get("desc");
//显示高亮
if(desc != null) {
TokenStream tokenStream = analyzer.tokenStream("desc", new StringReader(desc));
String summary = highlighter.getBestFragment(tokenStream, desc);
logger.info("高亮后的desc:{}", summary);
list.add(summary);
}
}
reader.close();
return list;
}
}

功能测试
到这里,最核心的功能都实现好了,我们可以自己写个小接口来调用下,看看效果。
("/lucene")
public class IndexController {
("/test")
public String test(Model model) {
// 索引所在的目录
String indexDir = "D:\\lucene2";
// 要查询的字符
String q = "南京文化";
try {
List<String> list = ChineseSearch.search(indexDir, q);
model.addAttribute("list", list);
} catch (Exception e) {
e.printStackTrace();
}
return "result";
}
}
在 result.html 页面做一个简单的展示操作:
<html lang="en" xmlns:th="http://www.thymeleaf.org">
<head>
<meta charset="UTF-8">
<title>Titletitle>
head>
<body>
<div th:each="desc : ${list}">
<div th:utext="${desc}">div>
div>
body>
html>
上面我们搜索的是 “南京文化”,来看下检索出来的结果是什么。

再将搜索关键字改成 “南京文明”,看下命中的效果如何?

可以看出,不同的关键词,它会计算一个得分片段,也就是说不同的关键字会命中同一段文本中不同位置的内容,然后将关键字根据我们自己设定的形式高亮显示。
从结果中可以看出,Lucene 也可以很智能地将关键字拆分命中,这在实际项目中会很好用。
作者简介:倪升武,CSDN 博客专家,CSDN达人课作者。硕士毕业于同济大学,曾先后就职于 eBay、爱奇艺、华为。目前在科大讯飞从事Java领域的软件开发,他的世界不仅只有Coding。
声明:本文为作者投稿,版权归其个人所有。
推荐阅读:

 微信公众号
微信公众号

评论记录:
回复评论: