
书名:Vue.js设计与实现
作者:霍春阳(HcySunYang)
Vue.js 3.0 的扩展能力非常强,我们可以编写自定义的渲染器,甚至可以编写编译器插件来自定义模板语法。
通过阅读 ECMAScript 规范,基于 Proxy 实现一个完善的响应系统;通过阅读 WHATWG 规范,实现一个类 HTML 语法的模板解析器,并在此基础上实现一个支持插件架构的模板编译器。
第一篇 框架设计概览
第 1 章 权衡的艺术
1.1 命令式和声明式
jQuery 就是典型的命令式框架,命令式框架关注过程。
js 代码解读复制代码$('#app') // 获取 div
.text('hello world') // 设置文本内容
.on('click', () => { alert('ok') })
声明式框架关注结果。
html 代码解读复制代码<div @click="() => alert('ok')">hello worlddiv>
Vue.js 帮我们封装了过程。因此,我们能够猜到 Vue.js 的内部实现一定是命令式的,而暴露给用户的却更加声明式。
1.2 性能与可维护性的权衡
声明式代码的性能不优于命令式代码的性能。
声明式代码的更新性能消耗 = 找出差异的性能消耗 + 直接修改的性能消耗,
在采用声明式提升可维护性的同时,性能就会有一定的损失,而框架设计者要做的就是:在保持可维护性的同时让性能损失最小化。
1.3 虚拟 DOM 的性能到底如何
虚拟 DOM,就是为了最小化找出差异这一步的性能消耗而出现的。
采用虚拟 DOM 的更新技术的性能理论上不可能比原生 JavaScript 操作 DOM 更高。这里我们强调了理论上三个字,因为这很关键,为什么呢?因为在大部分情况下,我们很难写出绝对优化的命令式代码。
innerHTML 比较特殊。使用 innerHTML 操作页面和虚拟 DOM 相比性能如何?innerHTML 和 document.createElement 等 DOM 操作方法有何差异?
innerHTML 为了渲染出页面,首先要把字符串解析成 DOM 树,这是一个 DOM 层面的计算。我们知道,涉及DOM 的运算要远比 JavaScript 层面的计算性能差。
纯 JavaScript 层面的操作要比 DOM 操作快得多,它们不在一个数量级上。基于这个背景,我们可以用一个公式来表达通过 innerHTML 创建页面的性能:HTML 字符串拼接的计算量 + innerHTML 的 DOM 计算量。
虚拟 DOM 创建页面的过程分为两步:第一步是创建 JavaScript 对象,这个对象可以理解为真实 DOM 的描述;第二步是递归地遍历虚拟 DOM 树并创建真实 DOM。我们同样可以用一个公式来表达:创建 JavaScript 对象的计算量 + 创建真实 DOM 的计算量。

图 1-2 innerHTML 和虚拟 DOM 在创建页面时的性能
可以看到,无论是纯 JavaScript 层面的计算,还是 DOM 层面的计算,其实两者差距不大。这里我们从宏观的角度只看数量级上的差异。
接下来我们看看它们在更新页面时的性能。
使用 innerHTML 更新页面的过程是重新构建 HTML 字符串,再重新设置 DOM 元素的 innerHTML 属性,而重新设置 innerHTML 属性就等价于销毁所有旧的 DOM 元素,再全量创建新的 DOM 元素。
再来看虚拟 DOM 是如何更新页面的。它需要重新创建 JavaScript 对象(虚拟 DOM 树),然后比较新旧虚拟 DOM,找到变化的元素并更新它。

图 1-3 虚拟 DOM 和 innerHTML 在更新页面时的性能
可以发现,在更新页面时,虚拟 DOM 在 JavaScript 层面的运算要比创建页面时多出一个 Diff 的性能消耗,然而它毕竟也是 JavaScript 层面的运算,所以不会产生数量级的差异。再观察 DOM 层面的运算,可以发现虚拟 DOM 在更新页面时只会更新必要的元素,但 innerHTML 需要全量更新。这时虚拟 DOM 的优势就体现出来了。
对于虚拟 DOM 来说,无论页面多大,都只会更新变化的内容,而对于 innerHTML 来说,页面越大,就意味着更新时的性能消耗越大。

图 1-4 虚拟 DOM 和 innerHTML 在更新页面时的性能(加上性能因素)
基于此,我们可以粗略地总结一下 innerHTML、虚拟 DOM 以及原生 JavaScript(指 createElement 等方法)在更新页面时的性能,如图 1-5 所示。

图 1-5 innerHTML、虚拟 DOM 以及原生 JavaScript 在更新页面时的性能
至此,我们有必要思考一下:有没有办法做到,既声明式地描述 UI,又具备原生 JavaScript 的性能呢?
1.4 运行时和编译时
当设计一个框架的时候,我们有三种选择:纯运行时的、运行时 + 编译时的或纯编译时的。
假设我们设计了一个框架,它提供一个 Render 函数,用户可以为该函数提供一个树型结构的数据对象,然后 Render 函数会根据该对象递归地将数据渲染成 DOM 元素。
js 代码解读复制代码function Render(obj, root) {
const el = document.createElement(obj.tag)
if (typeof obj.children === 'string') {
const text = document.createTextNode(obj.children)
el.appendChild(text)
} else if (obj.children) {
// 数组,递归调用 Render,使用 el 作为 root 参数
obj.children.forEach(child => Render(child, el))
}
// 将元素添加到 root
root.appendChild(el)
}
const obj = {
tag: 'div',
children: [{ tag: 'span', children: 'hello world' }]
}
// 渲染到 body 下
Render(obj, document.body)
这就是一个纯运行时的框架。
能不能引入编译的手段,把 HTML 标签编译成树型结构的数据对象。
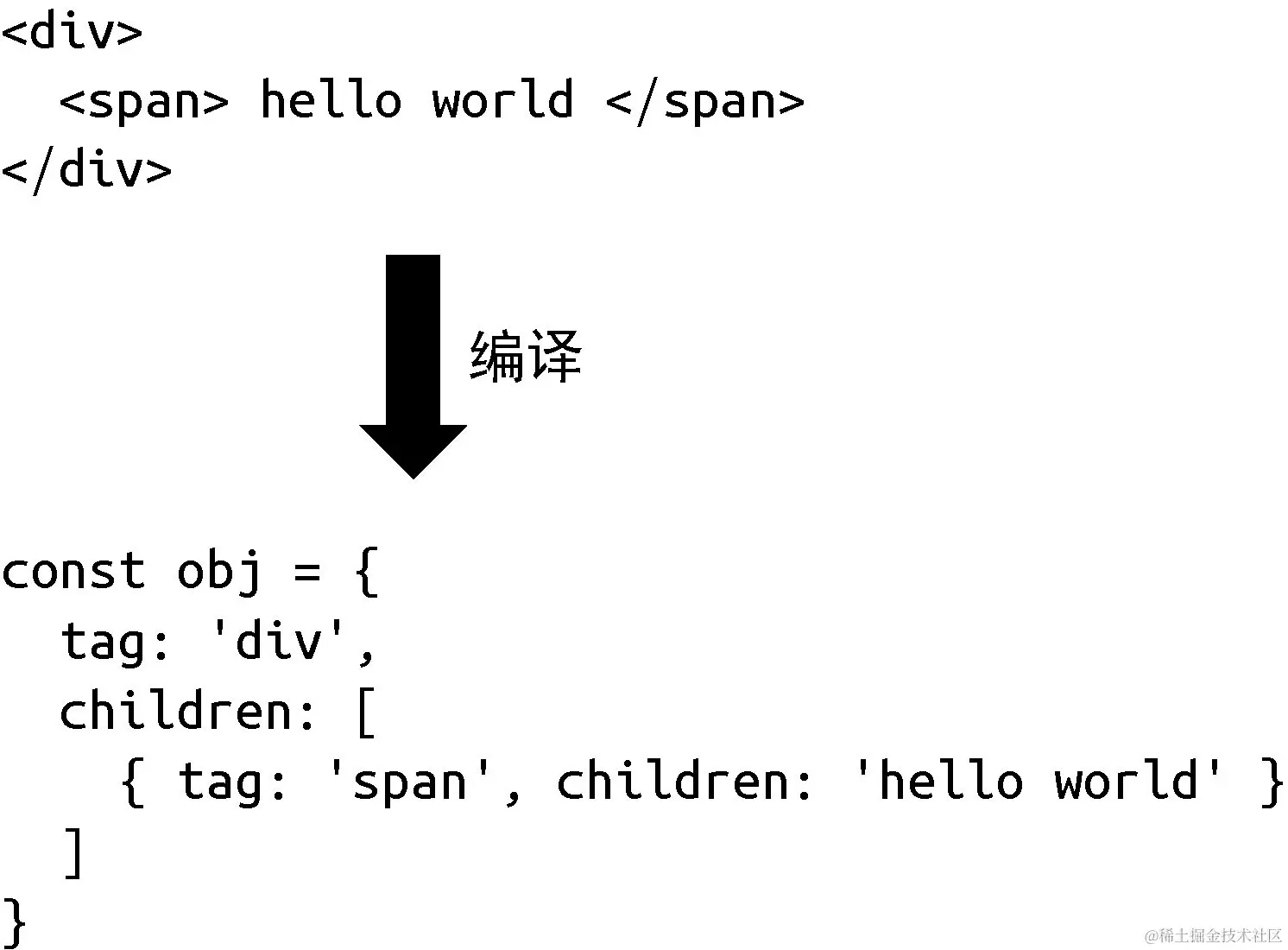
图 1-6 把 HTML 标签编译成树型结构的数据对象
编写一个叫作 Compiler 的程序,它的作用就是把 HTML 字符串编译成树型结构的数据对象。
那么用户该怎么用呢?其实这也是我们要思考的问题,最简单的方式就是让用户分别调用 Compiler 函数和 Render 函数:
js 代码解读复制代码const html = `
hello world
`
// 调用 Compiler 编译得到树型结构的数据对象
const obj = Compiler(html)
// 再调用 Render 进行渲染
Render(obj, document.body)
这时我们的框架就变成了一个运行时 + 编译时的框架。它既支持运行时,用户可以直接提供数据对象从而无须编译;又支持编译时,用户可以提供 HTML 字符串,我们将其编译为数据对象后再交给运行时处理。准确地说,上面的代码其实是运行时编译,意思是代码运行的时候才开始编译,而这会产生一定的性能开销,因此我们也可以在构建的时候就执行 Compiler 程序将用户提供的内容编译好,等到运行时就无须编译了,这对性能是非常友好的。
不过,聪明的你一定意识到了另外一个问题:既然编译器可以把 HTML 字符串编译成数据对象,那么能不能直接编译成命令式代码呢?

图 1-7 将 HTML 字符串编译为命令式代码的过程
这样我们只需要一个 Compiler 函数就可以了,连 Render 都不需要了。其实这就变成了一个纯编译时的框架。
一个框架既可以是纯运行时的,也可以是纯编译时的,还可以是既支持运行时又支持编译时的。那么,它们都有哪些优缺点呢?
首先是纯运行时的框架。由于它没有编译的过程,因此我们没办法分析用户提供的内容,但是如果加入编译步骤,可能就大不一样了,我们可以分析用户提供的内容,看看哪些内容未来可能会改变,哪些内容永远不会改变,这样我们就可以在编译的时候提取这些信息,然后将其传递给 Render 函数,Render 函数得到这些信息之后,就可以做进一步的优化了。然而,假如我们设计的框架是纯编译时的,那么它也可以分析用户提供的内容。由于不需要任何运行时,而是直接编译成可执行的 JavaScript 代码,因此性能可能会更好,但是这种做法有损灵活性,即用户提供的内容必须编译后才能用。实际上,在这三个方向上业内都有探索,其中 Svelte 就是纯编译时的框架,但是它的真实性能可能达不到理论高度。Vue.js 3 仍然保持了运行时 + 编译时的架构,在保持灵活性的基础上能够尽可能地去优化。等到后面讲解 Vue.js 3 的编译优化相关内容时,你会看到 Vue.js 3 在保留运行时的情况下,其性能甚至不输纯编译时的框架。
1.5 总结
在本章中,我们先讨论了命令式和声明式这两种范式的差异,其中命令式更加关注过程,而声明式更加关注结果。命令式在理论上可以做到极致优化,但是用户要承受巨大的心智负担;而声明式能够有效减轻用户的心智负担,但是性能上有一定的牺牲,框架设计者要想办法尽量使性能损耗最小化。
接着,我们讨论了虚拟 DOM 的性能,并给出了一个公式:声明式的更新性能消耗 = 找出差异的性能消耗 + 直接修改的性能消耗。虚拟 DOM 的意义就在于使找出差异的性能消耗最小化。我们发现,用原生 JavaScript 操作 DOM 的方法(如 document.createElement)、虚拟 DOM 和 innerHTML 三者操作页面的性能,不可以简单地下定论,这与页面大小、变更部分的大小都有关系,除此之外,与创建页面还是更新页面也有关系,选择哪种更新策略,需要我们结合心智负担、可维护性等因素综合考虑。一番权衡之后,我们发现虚拟 DOM 是个还不错的选择。
最后,我们介绍了运行时和编译时的相关知识,了解纯运行时、纯编译时以及两者都支持的框架各有什么特点,并总结出 Vue.js 3 是一个编译时 + 运行时的框架,它在保持灵活性的基础上,还能够通过编译手段分析用户提供的内容,从而进一步提升更新性能。
第 2 章 框架设计的核心要素
我们的框架应该给用户提供哪些构建产物?产物的模块格式如何?当用户没有以预期的方式使用框架时,是否应该打印合适的警告信息从而提供更好的开发体验,让用户快速定位问题?开发版本的构建和生产版本的构建有何区别?热更新(hot module replacement,HMR)需要框架层面的支持,我们是否也应该考虑?另外,当你的框架提供了多个功能,而用户只需要其中几个功能时,用户能否选择关闭其他功能从而减少最终资源的打包体积?
2.1 提升用户的开发体验
那么有没有办法在打印 count 的时候让输出的信息更友好呢?当然可以,浏览器允许我们编写自定义的 formatter,从而自定义输出形式。在 Vue.js 3 的源码中,你可以搜索到名为 initCustomFormatter 的函数,该函数就是用来在开发环境下初始化自定义 formatter 的。以 Chrome 为例,我们可以打开 DevTools 的设置,然后勾选“Console”→“Enable custom formatters”选项,如图 2-3 所示。
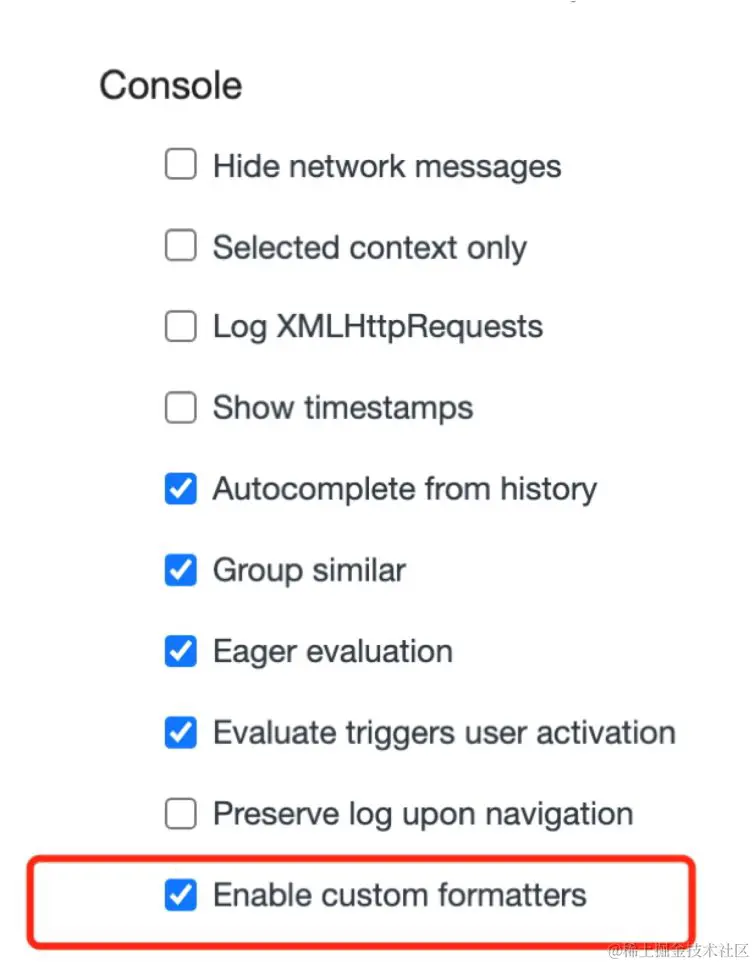
图 2-3 勾选“Console”→“Enable custom formatters” 选项
2.2 控制框架代码的体积
js 代码解读复制代码if (__DEV__ && !res) {
warn(
`Failed to mount app: mount target selector "${container}" returned null.`
)
}
Vue.js 使用 rollup.js 对项目进行构建,这里的 __DEV__ 常量实际上是通过 rollup.js 的插件配置来预定义的,其功能类似于 webpack 中的 DefinePlugin 插件。
当 Vue.js 用于构建生产环境的资源时,会把 __DEV__ 常量设置为 false。
js 代码解读复制代码if (false && !res) {
warn(
`Failed to mount app: mount target selector "${container}" returned null.`
)
}
这时我们发现这段分支代码永远都不会执行,因为判断条件始终为假,这段永远不会执行的代码称为 dead code,它不会出现在最终产物中,在构建资源的时候就会被移除。
在开发环境中为用户提供友好的警告信息的同时,不会增加生产环境代码的体积。
2.3 框架要做到良好的 Tree-Shaking
Tree-Shaking 指的就是消除那些永远不会被执行的代码,也就是排除 dead code,现在无论是 rollup.js 还是 webpack,都支持 Tree-Shaking。
想要实现 Tree-Shaking,必须满足一个条件,即模块必须是 ESM(ES Module),因为 Tree-Shaking 依赖 ESM 的静态结构。
- ESM: export + import
- CommonJS: module.exports + require
ES Module 是静态引入,编译时引入;CommonJS 是动态引入,运行时引入。
ES Module 特点:
- 只能作为模块顶层的语句出现
- import 的模块名只能是字符串常量
- import binding 是 immutable 的
ES Module 采用的是静态分析,从字面量对代码进行分析。静态分析程序流,判断哪些模块和变量未被使用或者引用,进而删除对应代码。import 的模块名只能是字符串常量,ES Module 依赖关系是确定的,和运行时的状态无关,因此可以进行可靠的静态分析,判断哪些模块最终没有被引用,这就是 Tree-Shaking 的基础。
CommonJS 是动态分析,必须执行到才知道引用什么模块。
Dead Code,也叫死码,无用代码,它的范畴主要包含了以下:
- 代码不会被执行,不可到达
- 代码执行的结果不会被用到
- 代码只会影响死变量(只写不读)
在传统的静态编程语言编译器中,编译器可以判断出某些代码根本不影响输出,我们可以借助编译器将 Dead Code 从 AST(抽象语法树)中删除。但 JavaScript 是动态语言,编译器不能帮助我们完成死码消除,我们需要自己实现 Dead code elimination。而我们说的 Tree-Shaking,就是 Dead code elimination 的一种实现,它借助于 ECMAScript 6 的模块机制原理,更多关注的是对无用模块的消除,消除那些引用了但并没有被使用的模块。
Tree Shaking概念和原理以及es6 module和commonjs的区别
Webpack 4 和 Webpack 5 中 Tree Shaking 的区别
Webpack 4:
1、Tree Shaking 只支持ES模块的使用,不支持 require 这种动态引入模块的方式。
2、只分析浅层的模块导出与引入关系,进行 dead-code 的去除。
Webpack 5 :
1、Webpack 5 中增加了对一些 CommonJS 风格模块代码的静态分析功功能。
支持 exports.xxx、this.exports.xxx、module.exports.xxx 语法的导出分析。
支持 object.defineProperty(exports, "xxxx", ...) 语法的导出分析。
支持 require('xxxx').xxx 语法的导入分析。
2、支持对嵌套引入模块的依赖分析优化,还增加了分析模块中导出项与导入项的依赖关系的功能。
通过 optimization.innerGraph(生产环境下默认开启)选项,Webpack 5 可以分析特定类型导出项中对导入项的依赖关系,从而找到更多未被使用的导入模块并加以移除
Webpack 曾经不进行对 CommonJs 导出和 require() 调用时的导出使用分析。
Webpack 5 增加了对一些 CommonJs 构造的支持,允许消除未使用的 CommonJs 导出,并从 require() 调用中跟踪引用的导出名称。
当检测到不可分析的代码时,webpack 会放弃,并且完全不跟踪这些模块的导出信息(出于性能考虑)。
ESM 动态导入
ES2020 引入了 import() 函数
import(), a syntax to asynchronously import Modules with a dynamic specifier.
js 代码解读复制代码document.getElementById("button")
.addEventListener("click", async () => {
const { app } = await import(`./app.${type}.js`);
app();
});
所以 import() 是不支持 Tree Shaking 的。
我们以 rollup.js 为例看看 Tree-Shaking 如何工作,其目录结构如下:
lua 代码解读复制代码├── demo
│ └── package.json
│ └── input.js
│ └── utils.js
下面是 input.js 和 utils.js 文件的内容:
js 代码解读复制代码// input.js
import { foo } from './utils.js'
foo()
// utils.js
export function foo(obj) {
obj && obj.foo
}
export function bar(obj) {
obj && obj.bar
}
注意,我们并没有导入 bar 函数。
npx rollup input.js -f esm -o bundle.js
js 代码解读复制代码// bundle.js
function foo(obj) {
obj && obj.foo
}
foo()
由于我们并没有使用 bar 函数,因此它作为 dead code 被删除了。但是仔细观察会发现,foo 函数的执行也没有什么意义,仅仅是读取了对象的值,所以它的执行似乎没什么必要。既然把这段代码删了也不会对我们的应用程序产生影响,那么为什么 rollup.js 不把这段代码也作为 dead code 移除呢?
这就涉及 Tree-Shaking 中的第二个关键点——副作用。如果一个函数调用会产生副作用,那么就不能将其移除。
因为静态地分析 JavaScript 代码很困难,所以像 rollup.js 这类工具都会提供一个机制,让我们能明确地告诉 rollup.js:“放心吧,这段代码不会产生副作用,你可以移除它。
2.4 框架应该输出怎样的构建产物
首先我们希望用户可以直接在 HTML 页面中使用