
前言
双十一大促或者春运抢票这样的流量高峰期,是最考验系统稳定性的时候,在这样的高并发场景下,下游访问偶尔响应时间变得很长时,可能给我们的服务带来怎样的影响呢?
当请求下游迟迟不能返回结果时,我们服务与下游服务之间的连接就无法释放,而且正在等待请求返回的协程也会被读请求给阻塞住。一旦响应时间变长的请求数量变多,极有可能使我们服务的机器资源被耗尽,最终使得我们的服务崩溃。
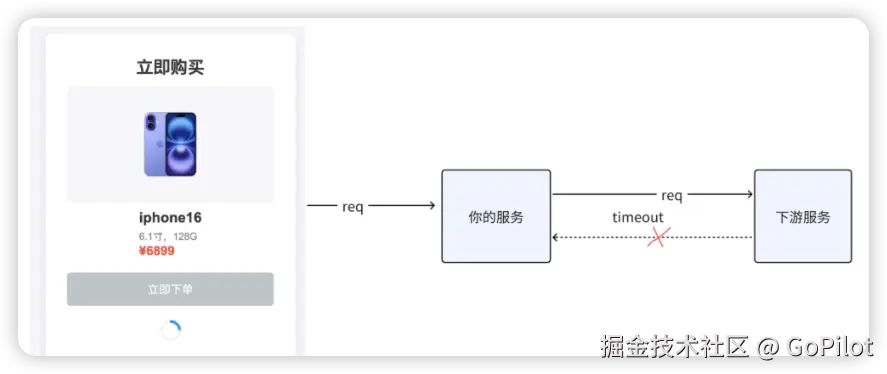
那么,面对请求下游偶现超时,进而可能导致我们服务崩溃的这种情况,我们又该采取什么样的措施来应对呢?
超时机制
很容易想到的一个方案就是采取超时主动快速失败的策略。若下游在一定时间内没有返回,则我们的服务就主动释放请求下游占用的连接和协程,避免因无限等待下游,导致系统的资源被耗尽⽽宕机。
超时时间设置多少合适?
谈到超时,其中很重要的一点是超时时间的设置。如果超时时间设置过短,就像下面的图一样,假设下游服务访问数据库就要 50ms,而你将调用下游的超时时间设置为 40ms,就会导致调用下游大量超时失败。
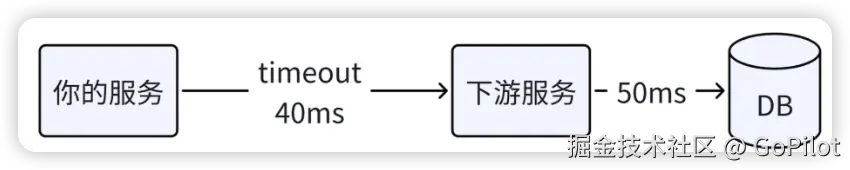
但超时时间也不能设置过长,过长达不到快速失败、释放资源的目的。比如就像下面的图一样,上游调用你的服务设置超时时间是 30ms,而你调用下游服务的超时时间设置为 40ms,实际上,⼀旦下游发生延时抖动,上游服务 30ms 就超时返回了,你对下游的调⽤在 30ms 之后返回毫无意义。

为了避免调用下游大量超时失败,我们可以基于调用下游服务的 p99 延时(99% 的请求都在这个时间内返回),外加一定的冗余时间作为超时时间。而且为了尽量避免无意义的等待,这个超时时间应该小于上游调用我们服务设置的超时时间。

超时快速失败的方案的确可以尽量防止我们被下游拖垮,但是假如我们调用下游的请求是一个重要请求,比如说在下单前的校验请求,超时失败会直接导致用户下不了单,造成公司收入上的损失。对于这种重要请求超时,我们就要特别对待了,需要采取一些重试机制。
重试机制
实际上,由于网络抖动或者下游服务单台机器的问题,线上请求偶尔出现超时是非常正常的。
为了提升我们服务整体的可用性,在确保下游服务接口调用幂等的情况下,你可以采取超时重试的策略。在超时失败时,向下游服务的另外一台机器发起请求,在很多时候,重试请求都能够成功收到下游响应。
然而,重试不是无限的重试,对于每个请求,我们都需要限制超时重试的次数。
- 一方面是避免因重试次数过多,增加下游系统的负载,导致超时现象更加严重。
- 另一方面是为了节约机器资源,在我们的上游服务调用超时返回之后,我们对下游的重试请求会占用连接和协程资源,并且毫无意义。例如,上游调你的服务超时时间是 30ms,在 30ms 之后它就返回了,你在 30ms 之后对下游的重试属于无效重试。

重试次数设置多少合适?
实践中,一般设置成 2-3 次,而且这个重试次数,需要小于上游超时时间除以我们调下游的超时时间得到的次数,避免无效重试。
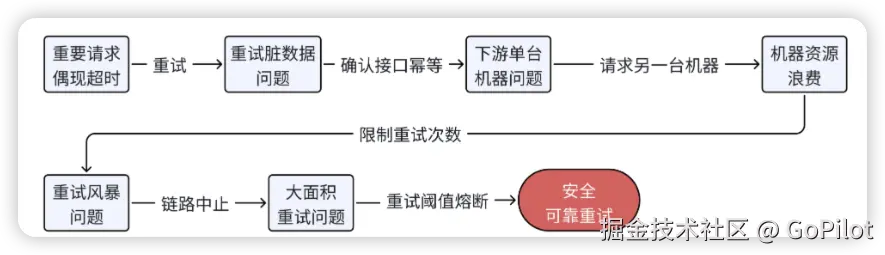
然而,如果所处的是高并发场景,在此情形下,还必须警惕一种情况,那就是当下游出现较多超时时,我们的服务若频繁进行大量重试,是极有可能把下游服务给压垮的。
现在很多系统采用的都是微服务架构,除了我们自身服务会有重试操作外,当对下游服务的调用一直失败时,位于我们上游链路的服务说不定也会展开重试操作,这样一来,便很可能引发重试风暴问题,进而使得下游服务的故障程度进一步加剧。
例如,假设我们的服务在调用下游服务时会重试 3 次,而上游的服务 B 因为调用失败又会重试 3 次,再往上的服务 A 由于超时失败同样也会重试 3 次。这样一来,虽然用户发出的仅仅是一个请求,实际上我们的下游服务累计会被调用多达 27 次。

重试链路中止 + 熔断
为了避免大面积重试把下游服务打垮,可以采用链路中止策略,对于上游链路过来的重试请求,不再对下游进行超时重试,避免重试风暴问题。而且,对下游的重试调用,你可以设置重试阈值熔断,当在一个时间窗口内,重试请求达到正常请求的一定比例,就不再进行重试。这样就避免因层层重试导致下游服务过载或雪崩。
具体策略可以有:
- 通过请求上下文控制链路重试最大次数:每个请求都会经过多个服务,在请求链路中 增加一个重试次数的标识,这样每个服务都可以判断 整个请求链路已经被重试了多少次,如果超过设定的阈值,就 不再进行重试,直接返回错误。例如在 HTTP header或 gRPC metadata 里增加
X-Retry-Count字段,每个服务接收请求时,检查该字段的值,超过阈值则拒绝重试,转发请求时增加X-Retry-Count的值。 - 请求幂等判断(防重放设计):如果每个重试请求都重新执行一次操作(如创建订单),可能会导致 重复操作,因此需要判重,可以在请求中携带唯一
Request-ID(Trace ID) ,下游服务存储已处理的Request-ID,如果接收到相同请求,直接返回缓存结果,而不是重新执行,确保即使发生重试,也不会多次执行相同的业务逻辑。 - 引入指数退避+随机抖动策略:如果必须进行重试,最好不要立即重试,减少瞬时高并发请求,导致请求拥堵。
- 熔断器(Circuit Breaker):微服务架构通常使用熔断器 来避免对故障服务持续发送请求。典型的熔断器实现包括:当失败次数达到阈值时,短时间内直接拒绝请求,一段时间后尝试半开(Half-Open),如果服务恢复,则恢复调用。go服务可以参考这个包:
github.com/alibaba/sentinel-golang/core/circuitbreaker或者github.com/sony/gobreaker - API 网关 / Service Mesh 限制重试:在 API 网关(如 Kong、Nginx、Envoy)中配置最大重试次数,超过后直接失败;在Service Mesh(如 Istio、Linkerd)可以限制每个请求的最大重试次数。
总结
在高并发场景,当下游访问偶现响应时间很长时,我们究竟应当采取哪些措施,才能够尽可能地确保我们所提供的服务始终保持稳定且可用呢?
- 首先,我们需要对下游调用设置合理的超时时间,避免因长时间等待下游返回,我们服务的机器资源不能释放而耗尽;
- 其次,如果对下游的调用是重要的请求类型,比如说涉及到关键业务流程的校验等环节,在保证下游调用是幂等的情况下,我们需要进行超时重试,尽量提升我们服务整体的可用性;
- 接着,我们需要采用链路中止策略,避免重试风暴给下游造成较大压力;
- 最后,我们需要设置重试阈值熔断,控制重试比例,避免大面积超时重试直接把下游打崩。
一句话小结:给线上服务配置超时时间,对于重要的下游调用可以加上重试策略,确保你的服务更加稳定可用。
参考
《go服务开发高手课》
评论记录:
回复评论: