
MCP的大火,让MCP服务器开发也变得热门,上一篇文章: 手搓MCP客户端&服务端:从零到实战极速了解MCP是什么?
手搓了一个极其简单的小场景的MCP实战案例,详细的安装环境及操作步骤已经讲过了,本文不在重复讲,今天带领大家手搓一个稍微带点复杂度的案例:百度热榜新闻采集MCP服务器并接入cline。
一、MCP的最少必要知识
一)MCP是什么?
MCP(Model Context Protocol,模型上下文协议) ,2024年11月底,由 Anthropic 推出的一种开放标准,旨在统一大型语言模型(LLM)与外部数据源和工具之间的通信协议。
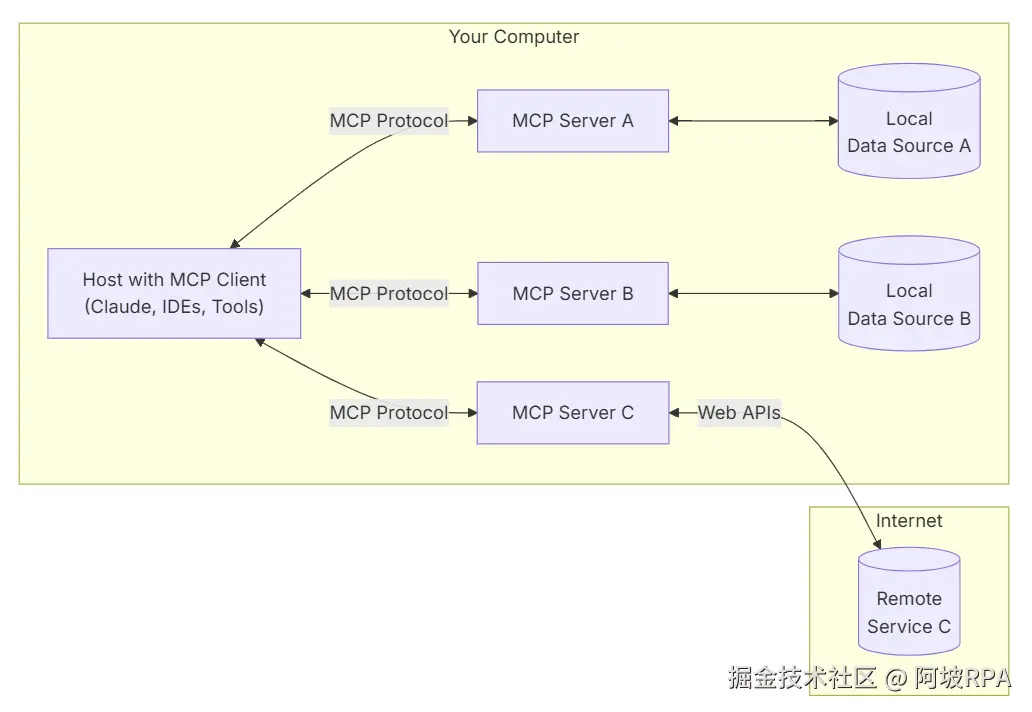
二)它解决了什么问题?
MCP 的主要意义在于解决当前 AI 模型因数据孤岛限制而无法充分发挥潜力的难题,MCP 使得 AI 应用能够安全地访问和操作本地及远程数据,为 AI 应用提供了连接万物的接口。
二、开发一个百度热搜榜采集
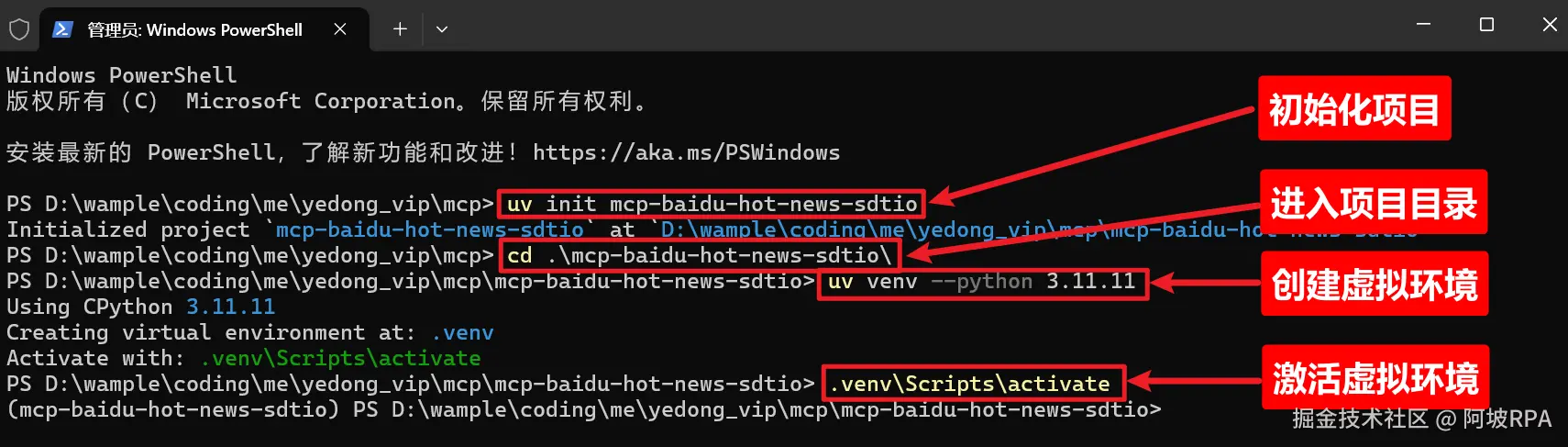
一)初始化项目环境
shell 代码解读复制代码# 初始化项目
uv init mcp-baidu-hot-news-sdtio
# 进入目录
cd .\mcp-baidu-hot-news-sdtio\
# 安装python 3.11.11 的pyton环境
uv venv --python 3.11.11
# 激活(进入)虚拟环境
.venv\Scripts\activate
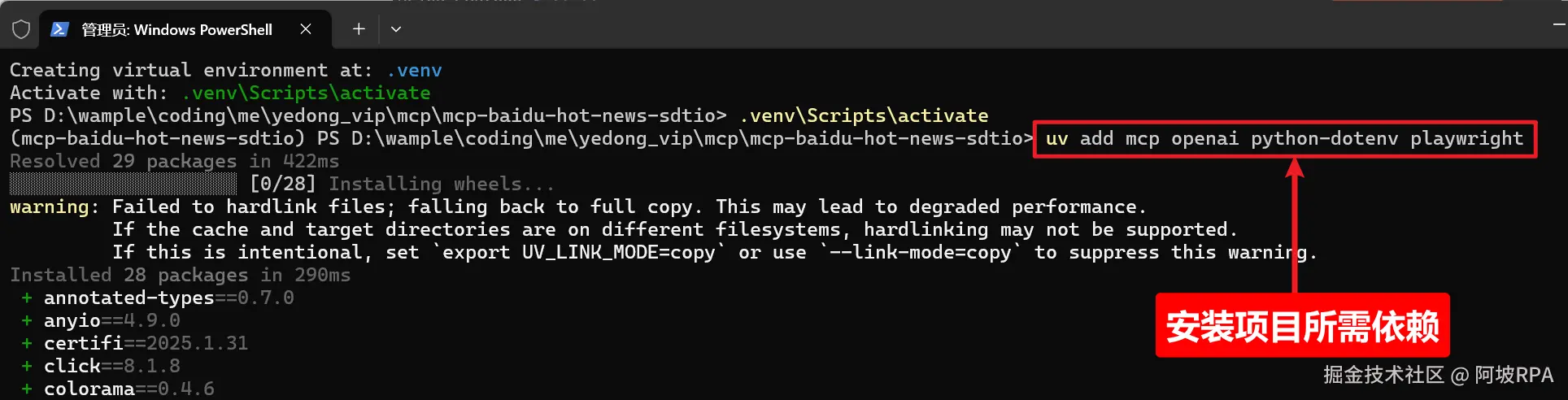
二)安装项目所需依赖
使用uv安装项目所需依赖,所有依赖就只安装到当前项目下,便于打包和分发项目
shell 代码解读复制代码# 在虚拟环境中安装依赖
uv add mcp openai python-dotenv playwright
三)编写MCP客户端
上一篇文章: 手搓MCP客户端&服务端:从零到实战极速了解MCP是什么?
已经带大家做过一个MCP客户端,这里基本的MCP客户端基本上一篇的保持一致;
1、创建env文件
ini 代码解读复制代码BASE_URL=https://api.deepseek.com
MODEL=deepseek-chat
API_KEY="你的API_KEY"
2、MCP客户端
在项目根目录下,创建一个 client.py 文件
客户端就做了一下几个事情:
- 启动并初始化 MCP 客户端
- 连接到 MCP 服务器
- 列出 MCP 服务器上的工具
- 与用户进行交互式对话
python 代码解读复制代码import asyncio
import os
from openai import OpenAI
from dotenv import load_dotenv
from contextlib import AsyncExitStack
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
import json
# 加载 .env 文件
load_dotenv()
class MCPClient:
def __init__(self):
"""初始化 MCP 客户端"""
self.exit_stack = AsyncExitStack()
self.openai_api_key = os.getenv("API_KEY") # 读取 OpenAI API Key
self.base_url = os.getenv("BASE_URL") # 读取 BASE URL
self.model = os.getenv("MODEL") # 读取 model
if not self.openai_api_key:
raise ValueError("未找到 API KEY. 请在.env文件中配置API_KEY")
self.client = OpenAI(api_key=self.openai_api_key,
base_url=self.base_url)
async def process_query(self, query: str) -> str:
"""
调用大模型处理用户输入
"""
messages = [{"role": "user", "content": query}]
response = await self.session.list_tools()
print('服务端工具列表', response.tools)
available_tools = [{
"type": "function",
"function": {
"name": tool.name,
"description": tool.description,
"input_schema": tool.inputSchema
}
} for tool in response.tools]
response = self.client.chat.completions.create(model=self.model,
messages=messages,
tools=available_tools)
print('大模型返回', response)
# 处理返回的内容
content = response.choices[0]
print('大模型返回内容', content)
if content.finish_reason == "tool_calls":
# 如何发现要使用工具,就执行工具
tool_call = content.message.tool_calls[0]
tool_name = tool_call.function.name
tool_args = json.loads(tool_call.function.arguments)
# 执行工具
result = await self.session.call_tool(tool_name, tool_args)
print(f"\n\n[Calling tool {tool_name} with args {tool_args}]\n\n")
# 将模型返回的原始消息和工具执行的结果都添加到messages中
messages.append(content.message.model_dump())
messages.append({
"role": "tool",
"content": result.content[0].text,
"tool_call_id": tool_call.id,
})
# 将上面的结果再返回给大模型生产最终的结果
response = self.client.chat.completions.create(
model=self.model,
messages=messages,
)
return response.choices[0].message.content
return content.message.content
async def chat_loop(self):
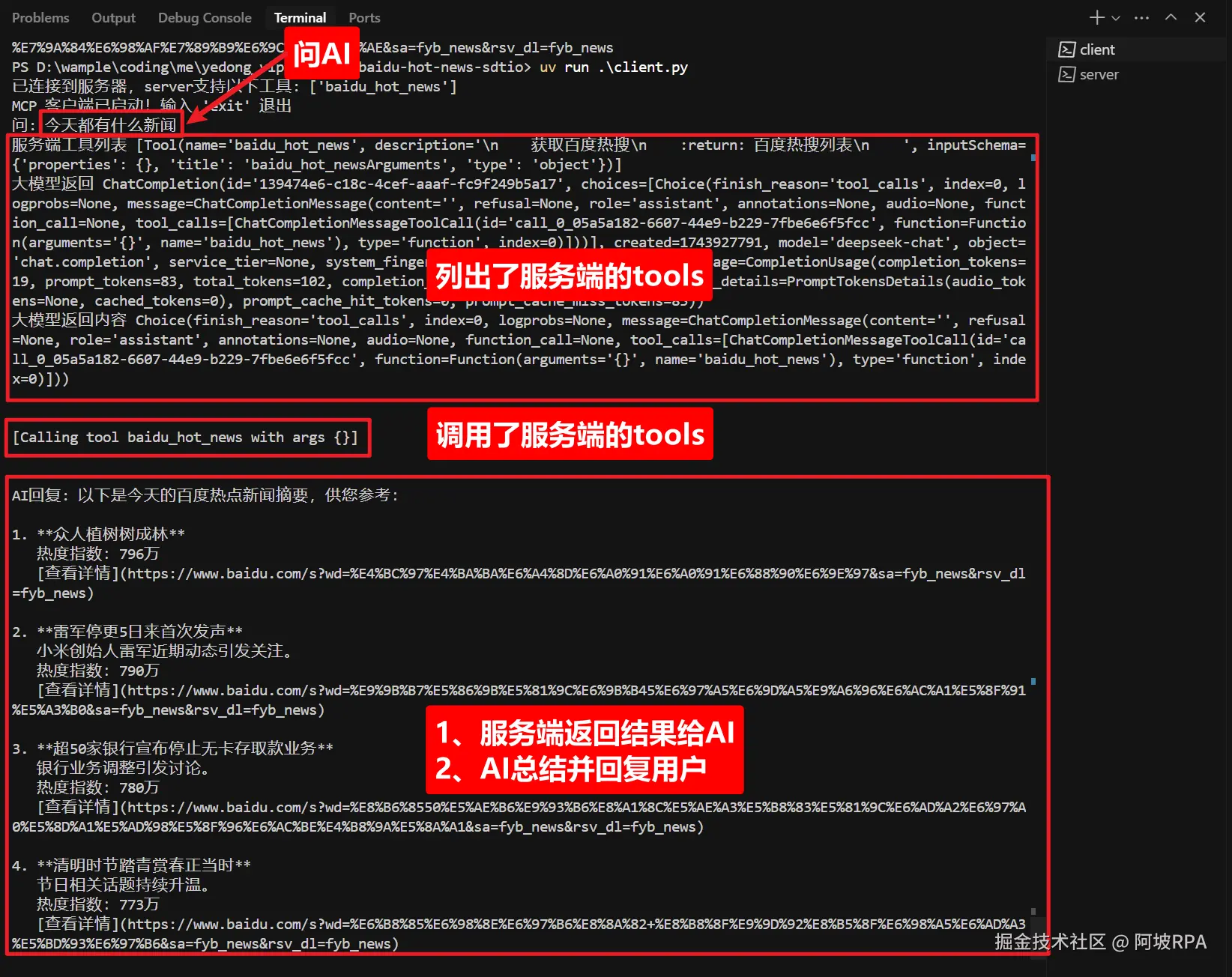
"""运行交互式聊天循环"""
print("MCP 客户端已启动!输入 'exit' 退出")
while True:
try:
query = input("问: ").strip()
if query.lower() == 'exit':
break
response = await self.process_query(query)
print(f"AI回复: {response}")
except Exception as e:
print(f"发生错误: {str(e)}")
async def clean(self):
"""清理资源"""
await self.exit_stack.aclose()
async def connect_to_server(self, server_script_path: str):
"""
连接到 MCP 服务器
"""
is_python = server_script_path.endswith('.py')
is_js = server_script_path.endswith('.js')
if not (is_python or is_js):
raise ValueError("不支持的文件类型")
command = "python" if is_python else "node"
server_params = StdioServerParameters(command=command,
args=[server_script_path],
env=None)
# 启动 MCP 服务器并建立通信
stdio_transport = await self.exit_stack.enter_async_context(
stdio_client(server_params))
self.stdio, self.write = stdio_transport
self.session = await self.exit_stack.enter_async_context(
ClientSession(self.stdio, self.write))
await self.session.initialize()
async def list_tools(self):
"""列出所有工具"""
# 列出 MCP 服务器上的工具
response = await self.session.list_tools()
tools = response.tools
print("已连接到服务器,server支持以下工具:", [tool.name for tool in tools])
async def main():
# 启动并初始化 MCP 客户端
client = MCPClient()
try:
# 连接到 MCP 服务器
await client.connect_to_server('server.py')
# 列出 MCP 服务器上的工具
await client.list_tools()
# 运行交互式聊天循环,处理用户对话
await client.chat_loop()
finally:
# 清理资源
await client.clean()
if __name__ == "__main__":
asyncio.run(main())
四)创建MCP服务端
1、采集百度热榜
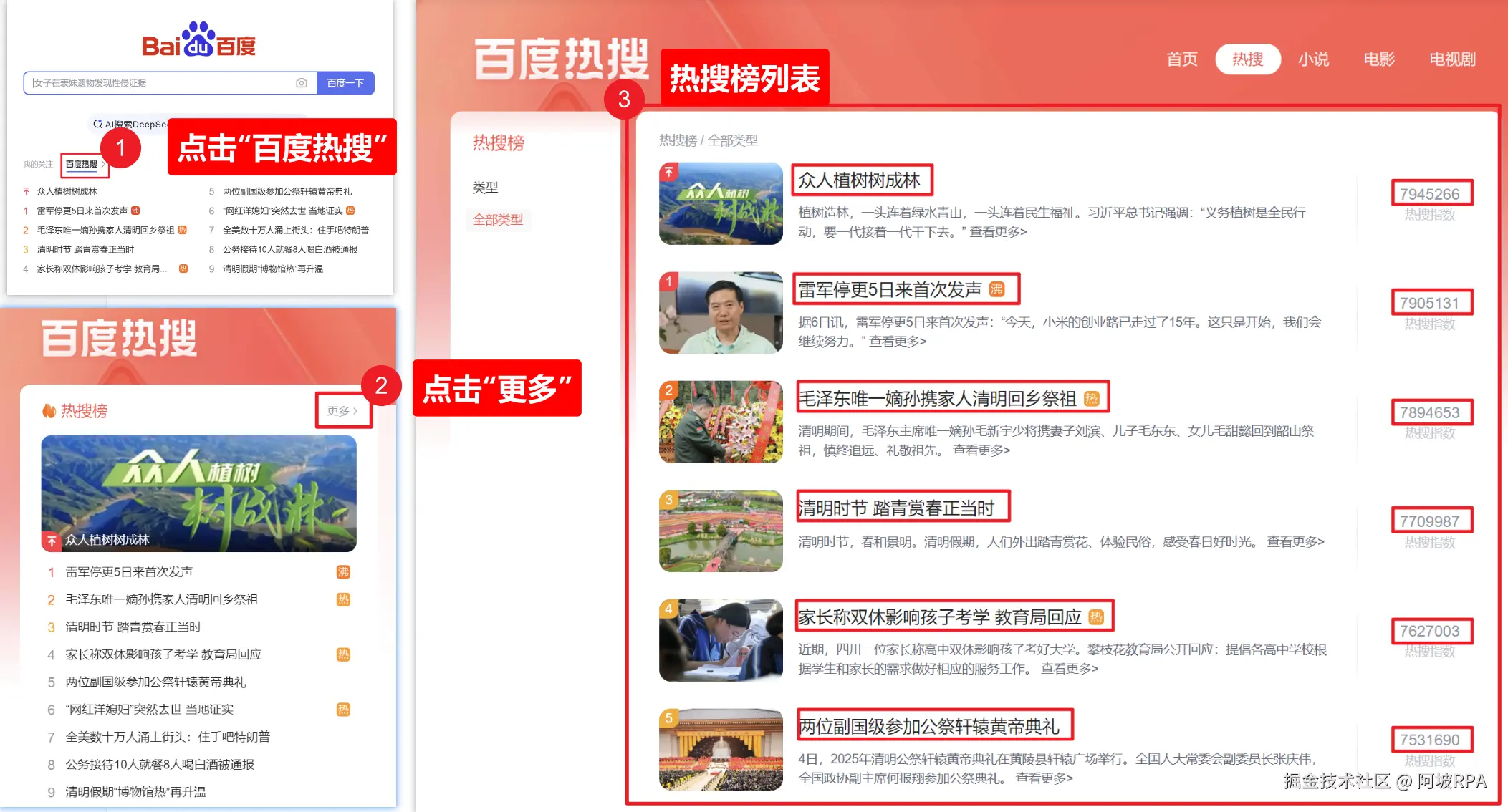
1)百度热榜页面
我们采集的元素只有三个:标题,热搜指数,链接
2)采集热榜脚本
采集数据的工具:playwright
采集方法:无头模式采集(不打开浏览器)
创建热榜采集脚本 : baidu_hot_news.py
python 代码解读复制代码from playwright.async_api import async_playwright
import time
import json
import logging
import os
import asyncio
# 确保日志目录存在
log_dir = "logs"
if not os.path.exists(log_dir):
os.makedirs(log_dir)
# 创建一个专门的日志处理器
file_handler = logging.FileHandler(os.path.join(log_dir, 'baidu_hot_news.log'),
encoding='utf-8')
file_handler.setFormatter(
logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s'))
logger = logging.getLogger(__name__)
logger.setLevel(logging.DEBUG)
logger.addHandler(file_handler)
class BaiduHotNews:
def __init__(self):
logger.info("初始化 BaiduHotNews 实例")
self.browser = None
self.context = None
self.page = None
self.playwright = None
# 同步上下文管理器
def __enter__(self):
return self
def __exit__(self, exc_type, exc_val, exc_tb):
if self.browser:
self.browser.close()
if self.playwright:
self.playwright.stop()
# 异步上下文管理器
async def __aenter__(self):
return self
async def __aexit__(self, exc_type, exc_val, exc_tb):
if self.browser:
await self.browser.close()
if self.playwright:
await self.playwright.stop()
async def init_browser(self):
"""初始化浏览器"""
try:
logger.info("开始初始化浏览器...")
self.playwright = await async_playwright().start()
logger.info("Playwright 启动成功")
self.browser = await self.playwright.chromium.launch(
headless=True,
args=[
'--disable-gpu', '--disable-dev-shm-usage', '--no-sandbox',
'--disable-setuid-sandbox'
])
logger.info("浏览器启动成功")
self.context = await self.browser.new_context(
viewport={
'width': 1920,
'height': 1080
},
user_agent=
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36')
self.page = await self.context.new_page()
logger.info("页面创建成功")
except Exception as e:
logger.error(f"浏览器初始化失败: {str(e)}", exc_info=True)
raise
async def scrape(self):
"""抓取百度热搜原始数据
Returns:
list: 包含热搜信息的列表,格式为 [{"title": str, "link": str, "hot_index": int}]
"""
try:
await self.init_browser()
# 访问百度热搜页面
await self.page.goto('https://top.baidu.com/board?tab=realtime')
# 等待页面加载完成
await self.page.wait_for_load_state('networkidle')
await self.page.wait_for_selector(
'xpath=//div[contains(@class, "category-wrap_")]')
await asyncio.sleep(2)
# 获取热搜列表
hot_items = await self.page.query_selector_all(
'xpath=//div[contains(@class, "category-wrap_")]')
hot_news_list = []
for item in hot_items:
try:
# 获取标题
title_element = await item.query_selector(
'xpath=.//div[contains(@class, "c-single-text-ellipsis")]'
)
if not title_element:
continue
title = await title_element.inner_text()
title = title.strip()
# 获取热搜指数并转换为整数
index_element = await item.query_selector(
'xpath=.//div[contains(@class, "hot-index_")]')
hot_index = 0 # 默认值
if index_element:
try:
# 移除非数字字符并转换为整数
hot_index_str = await index_element.inner_text()
hot_index = int(''.join(
filter(str.isdigit, hot_index_str.strip())))
except ValueError:
hot_index = 0
# 获取链接
link_element = await item.query_selector(
'xpath=.//a[contains(@class, "title_")]')
link = await link_element.get_attribute(
'href') if link_element else ""
if title: # 只添加有标题的条目
hot_news_list.append({
'title': title,
'link': link,
'hot_index': hot_index
})
logger.info(f"成功解析: {title}")
except Exception as e:
logger.error(f"解析条目出错: {str(e)}")
continue
return hot_news_list
except Exception as e:
logger.error(f"抓取过程出错: {str(e)}")
return []
finally:
if self.browser:
await self.browser.close()
async def get_hot_news(self):
"""获取百度热搜
Returns:
str: JSON字符串,包含百度热搜列表和错误信息
"""
try:
results = await self.scrape()
if not results:
return json.dumps({
"error": "未获取到热搜数据",
"data": []
},
ensure_ascii=False)
return json.dumps({
"error": None,
"data": results
},
ensure_ascii=False)
except Exception as e:
return json.dumps({
"error": f"获取热搜失败: {str(e)}",
"data": []
},
ensure_ascii=False)
if __name__ == '__main__':
# 使用示例
async def main():
async with BaiduHotNews() as scraper:
result = await scraper.get_hot_news()
data = json.loads(result)
if data["error"]:
print(f"错误: {data['error']}")
else:
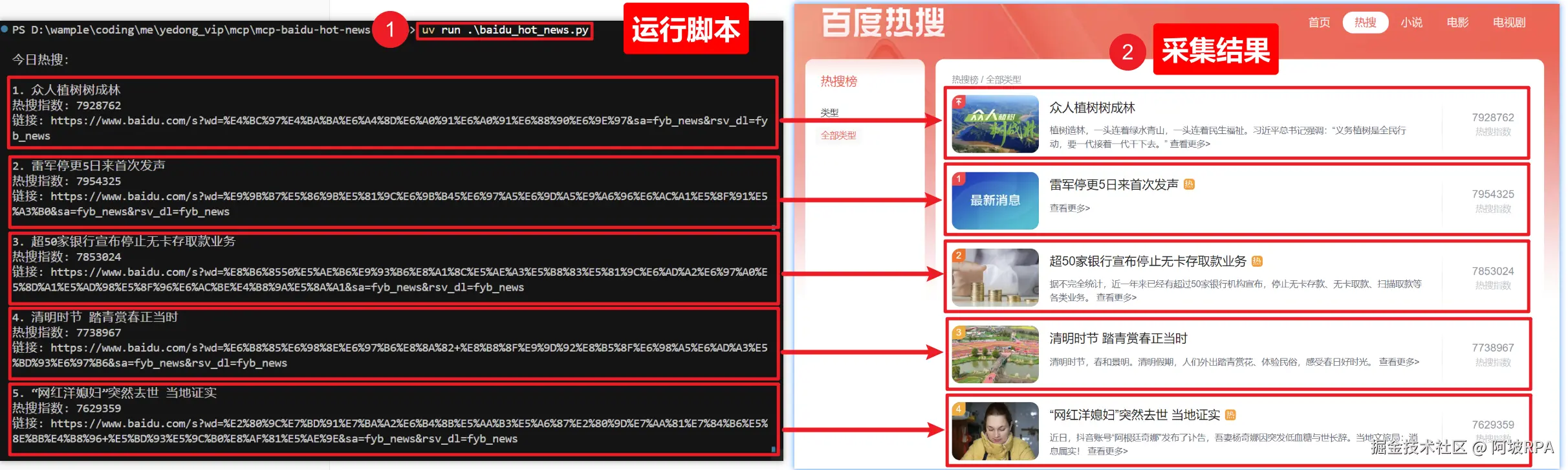
print("\n今日热搜:")
for idx, item in enumerate(data["data"], 1):
print(f"\n{idx}. {item['title']}")
print(f"热搜指数: {item['hot_index']}")
print(f"链接: {item['link']}")
asyncio.run(main())
3)测试采集脚本
运行以下命令:
代码解读复制代码python .\baidu_hot_news.py
2、编写MCP客户端
1)服务端脚本
客户端核心逻辑如下:
- 运行
baidu_hot_news.py的采集逻辑 - 将获取的结果并序列化返回给客户端
创建 server.py 文件:
python 代码解读复制代码import logging
import json
import os
from mcp.server.fastmcp import FastMCP
from baidu_hot_news import BaiduHotNews
# 确保日志目录存在
log_dir = "logs"
if not os.path.exists(log_dir):
os.makedirs(log_dir)
# 配置日志 - 只输出到文件
logging.basicConfig(
level=logging.DEBUG, # 使用 DEBUG 级别以获取更多信息
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler(os.path.join(log_dir, 'mcp_server.log'),
encoding='utf-8'),
])
logger = logging.getLogger(__name__)
# 初始化FastMCP服务器
mcp = FastMCP("baidu_hot_news")
@mcp.tool()
async def baidu_hot_news() -> str:
"""
获取百度热搜
:return: 百度热搜列表
"""
logger.info("开始执行百度热搜抓取...")
try:
scraper = BaiduHotNews()
async with scraper:
result = await scraper.get_hot_news()
logger.info(f"获取到原始结果: {result[:100]}...")
data = json.loads(result)
logger.info(f"解析JSON成功,数据条数: {len(data.get('data', []))}")
return data
except Exception as e:
error_msg = f"执行出错: {str(e)}"
logger.error(error_msg, exc_info=True)
return {"error": error_msg, "data": []}
if __name__ == "__main__":
# 以标准 I/O 方式运行 MCP 服务器
mcp.run(transport="stdio")
2)运行MCP服务
运行如下命令:
python代码解读复制代码uv run .\server.py

五)MCP客户端&服务端联调
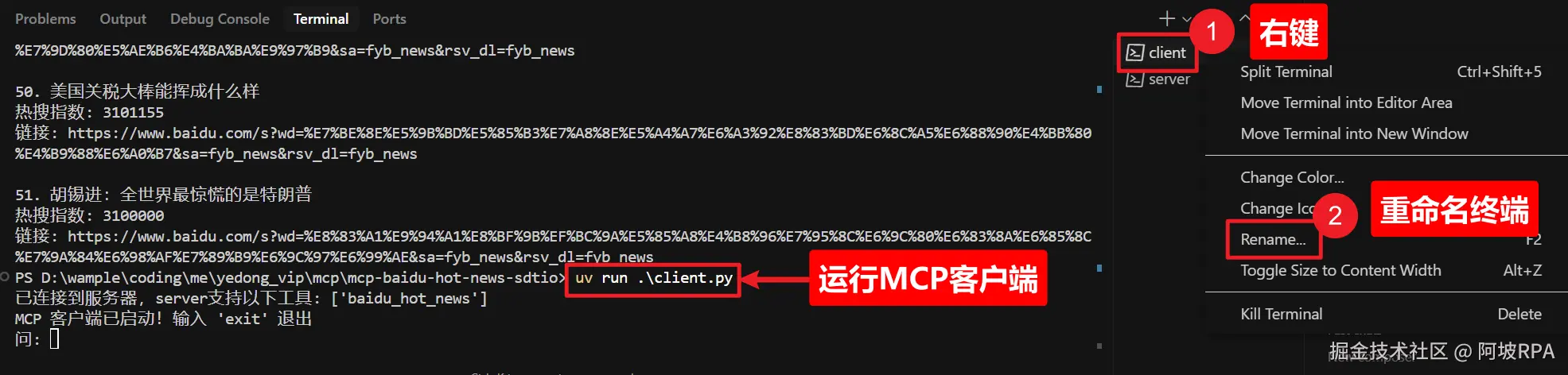
1、运行客户端
从上一步的服务端终端切换到client终端,并重命名,如下图:
2、测试
三、将MCP服务器添加到Cline客户端
一)前置条件
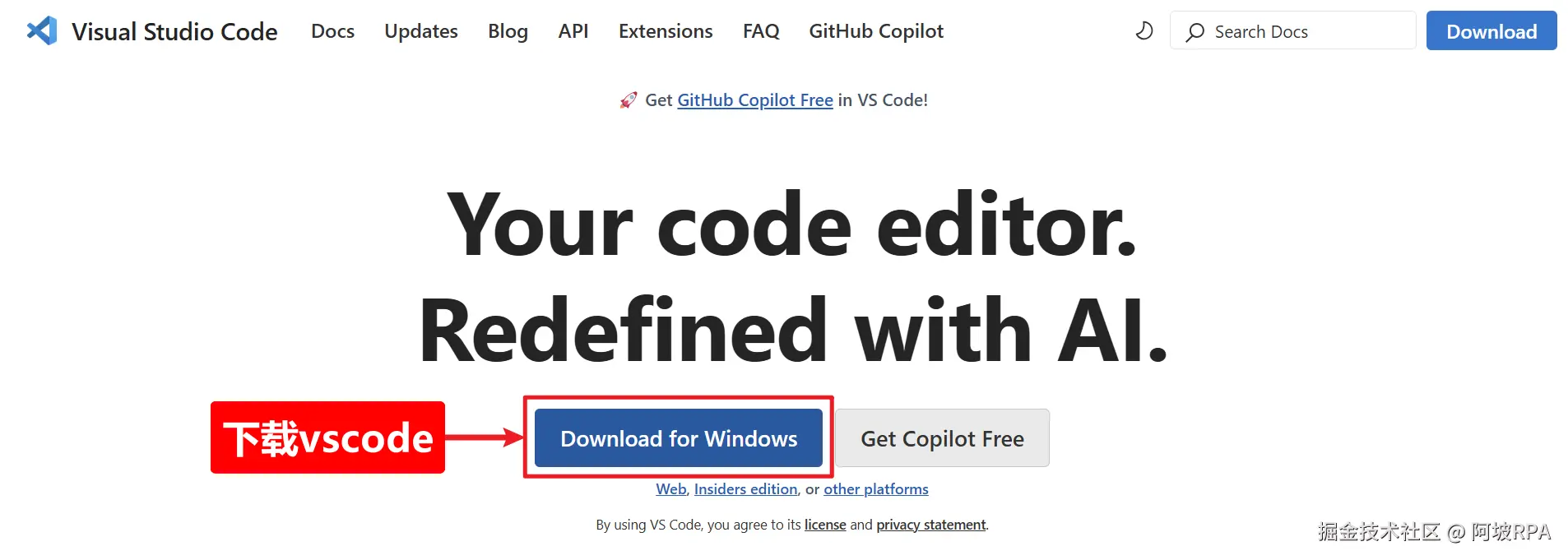
1、下载并安装vscode
cline是vscode的一个插件,所以安装cline之前需要先安装vscode,这个就不在赘言了,没有安装的去官网下载安装即可:
vscode官网:code.visualstudio.com/
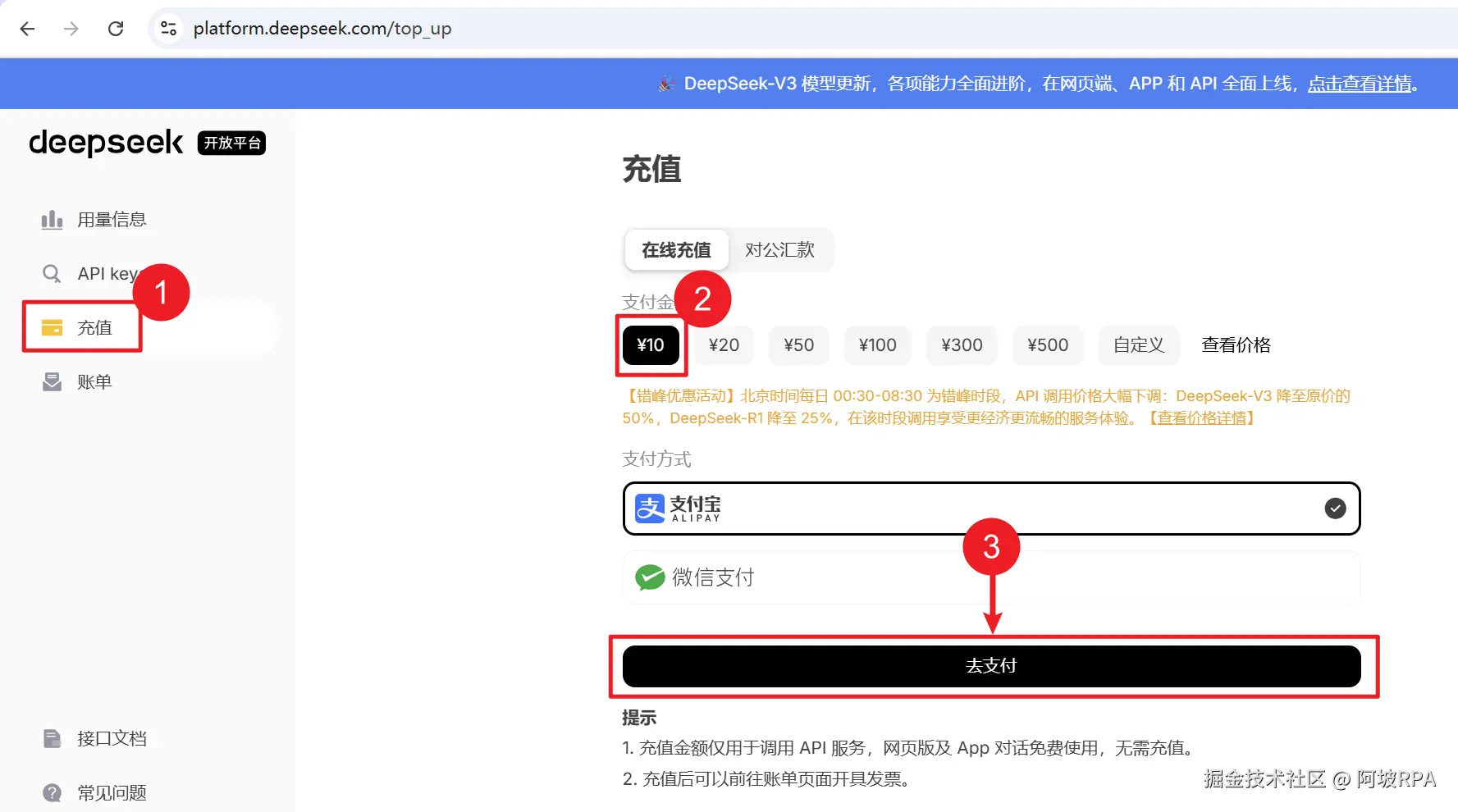
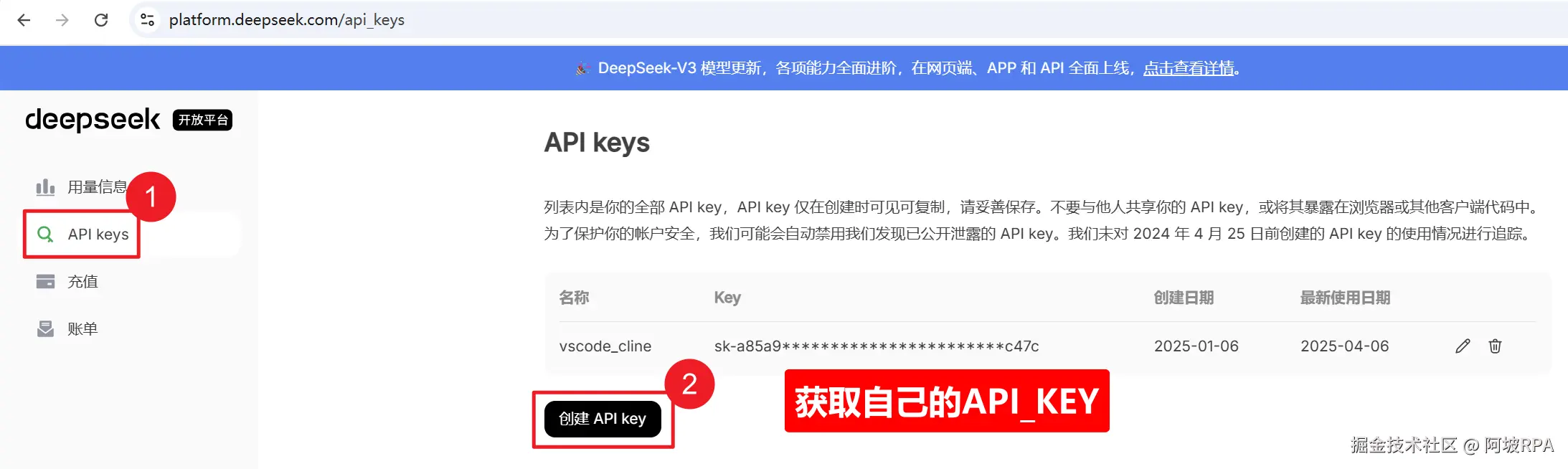
2、获取deepseek的api key
deepseek的api key 需要付费,不过价格是白菜价,10块钱都够你用一阵子了
充值地址:platform.deepseek.com/top_up
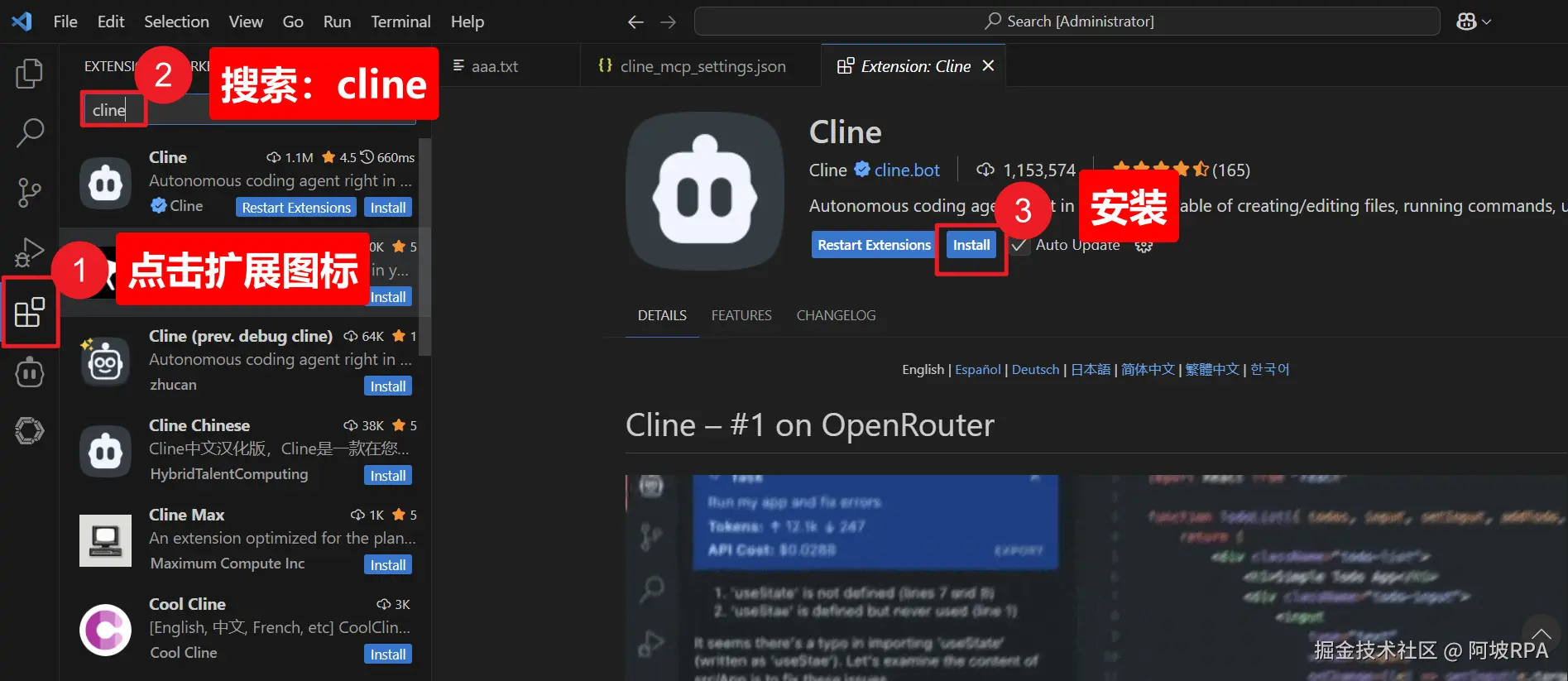
二)安装cline
1、搜索安装
2、进入cline
三)配置deepseek
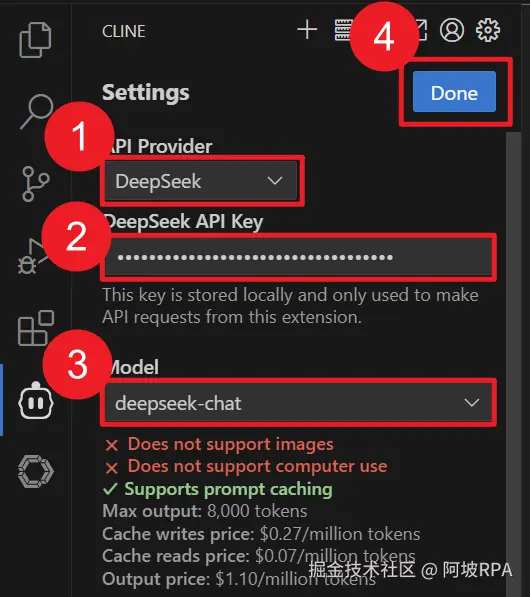
将自己的的deepseek的API_KEY配置进来,如下图:
四)配置MCP服务器
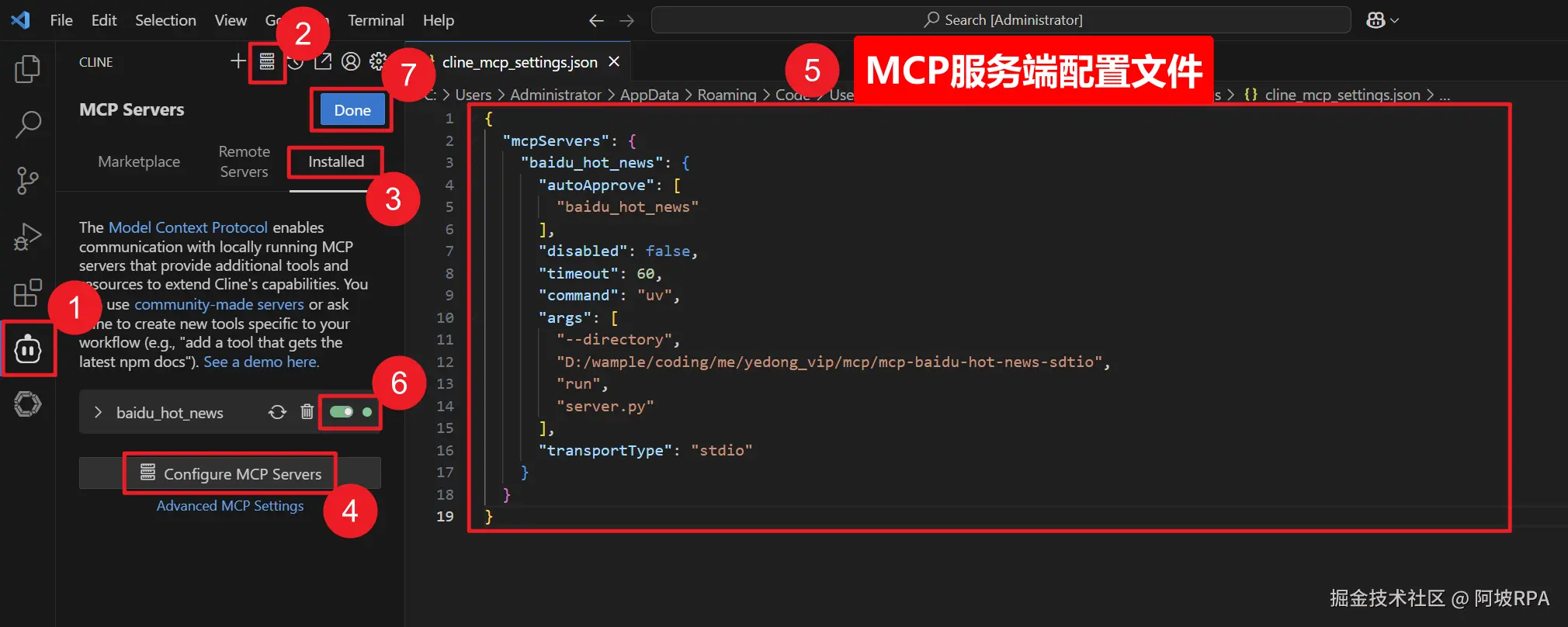
① 点击进入cline
② 添加MCP服务器
③ 选择 installed
④ 点击配置MCP服务器
⑤ 填写PC服务器配置
json 代码解读复制代码{
"mcpServers": {
"baidu_hot_news": {
"autoApprove": [
"baidu_hot_news"
],
"disabled": false,
"timeout": 60,
"command": "uv",
"args": [
"--directory",
"D:/wample/coding/me/yedong_vip/mcp/mcp-baidu-hot-news-sdtio",
"run",
"server.py"
],
"transportType": "stdio"
}
}
}
⑥ 千万别忘记点击打开服务器按钮
⑦ 点击确定,mcp服务器配置完成
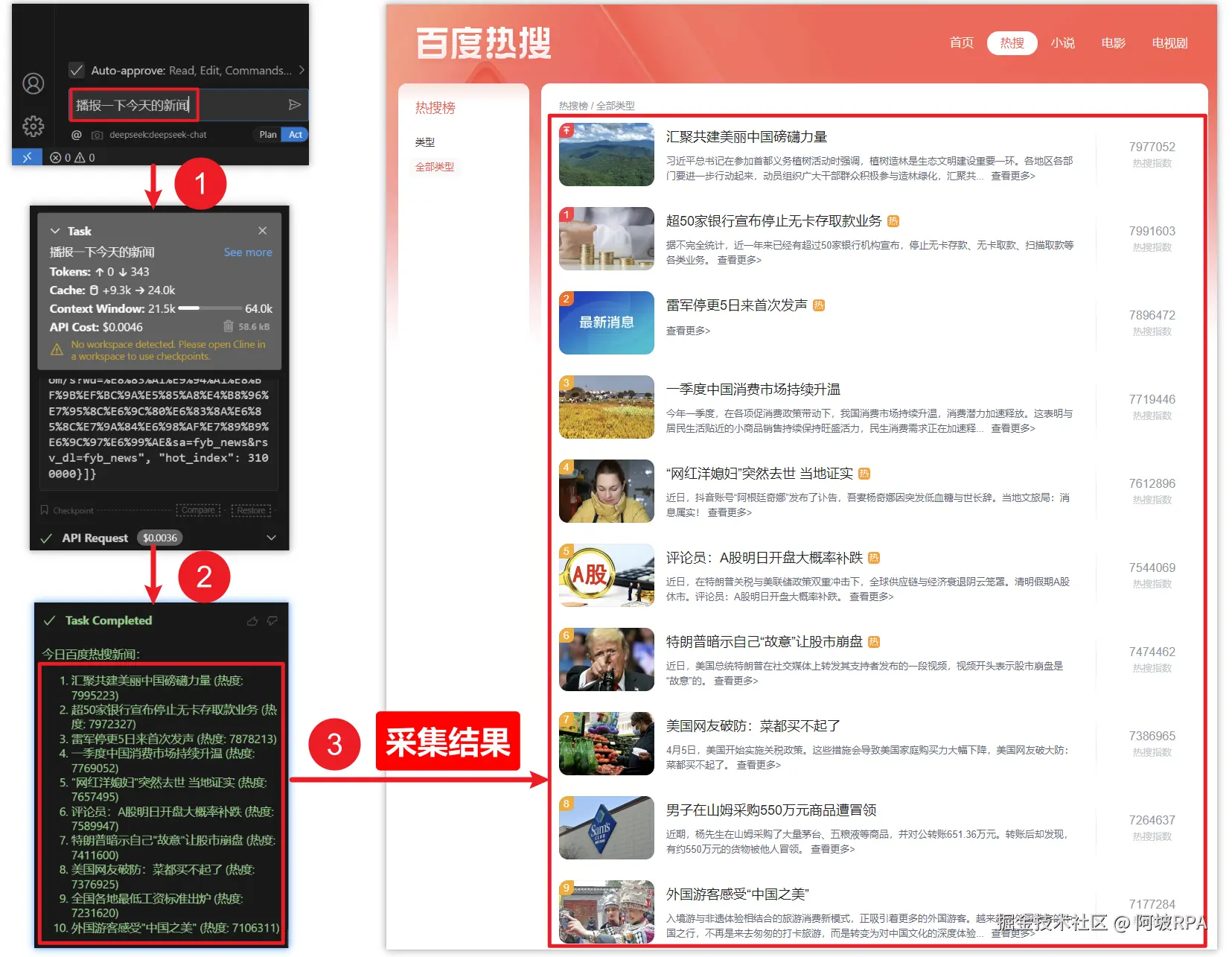
五)测试
四、MCP能否替代传统RPA?
一)核心区别
-
RPA:是一种规则驱动的自动化工具,通过 UI 交互或 API 执行重复性任务。它按预设脚本运行,没有推理能力,输出是固定的,适合固定流程、重复性高的任务
-
MCP:是基于 MCP 协议的服务器,为 AI(如 LLM)提供动态数据、执行能力和推理模板。它服务于 AI 的灵活需求,支持动态响应和智能交互,适合需要 AI 智能处理和动态响应的场景。
二)功能对比
- RPA:
-
功能:模拟人工操作(如点击、填写表单),调用 API 或脚本执行任务,处理结构化数据。
-
特点:固定流程,无需理解任务,输出直接可用。
-
适用场景:任务固定、重复性高的场景,如数据抓取、简单任务执行。
-
- MCP:
- 功能:提供动态数据(Resources)、执行任务(Tools)、推理模板(Prompts)。
- 特点:动态响应,服务于 AI 的灵活需求,输出需 AI 处理。
- 适用场景:需要 AI 智能处理和动态响应的场景,如情感分析、实时数据抓取。
三)MCP 与 RPA 的互补性
- MCP 能替代的部分:
-
简单数据抓取:RPA 可以抓取网页数据并存为文件,类似 MCP 的基本功能。
-
固定任务:RPA 按脚本批量处理任务,类似 MCP 的某些工具功能。
-
- MCP 无法替代的部分:
- 智能交互性:MCP 支持 AI 动态推理,而 RPA 没有推理能力,只能按脚本运行。
- 协议标准化:MCP 使用统一的 MCP 协议,与 AI 生态无缝协作,而 RPA 没有标准协议,需要额外接口。
- 动态性与灵活性:MCP 支持实时抓取和动态调整,而 RPA 流程固定,需求变更需要重写脚本。
MCP 无法完全替代 RPA,但两者可以结合使用,例如 MCP 提供动态数据和推理支持,RPA 执行固定任务,共同实现更复杂的自动化流程。

评论记录:
回复评论: