
前言
最近推出的 DeepSeek R1 异常火爆,我也想趁此机会捣鼓一下,实现 DeepSeek R1 本地化部署并搭建本地知识库问答系统,其中实现的思路如下:
- 使用 windows 11 WSL2,创建子系统Linux,并使用 Anaconda 创建 pythn 环境。(本章内容)
- 下载 DeepSeek R1 蒸馏模型,使用 Ollama 框架作为服务载体部署运行。
- 基于 LangChain 构建本地知识库问答 RAG 应用。
- 利用 FastApi 框架,搭建后端服务系统。
- 使用 vue3 + ElementPlus 作为前端ui框架,实现问答系统前端功能。
- 不依赖于 Langchain 框架,而选择 LightRAG 架构,构建 RAG。
一、准备工作
由于我的显卡显存有点小,DeepSeek R1 蒸馏模型选择的是 DeepSeek-R1-Distill-Qwen-7B · 模型库。
由于只是个人使用,不需要太高的并发,部署模型引擎选择 Ollama。
热门推理引擎对比
部署或推理模型会用到以下几种热门的推理引擎,分别是:
原生启动:
- Hugging Face 的
transformers库,这是一个比较原生的推理架构,需要写一些底层代码来启动。这个库更多用在模型微调或推理方面上。
部署模型引擎:
有自己的启动方式,部署简单,往往只需要输入 sever 命令行直接启动即可。
-
- 场景:企业级高并发服务(如在线客服、实时数据分析)、需结构化输出的应用(如JSON解析)、多模态交互需求。
- 优势:通过RadixAttention和零开销调度优化性能,适合需要极致吞吐量和低延迟的场景。
- 限制:仅支持Linux系统,依赖高端GPU。
-
- 场景:个人开发者原型验证、学生辅助学习、轻量级创意写作、本地快速部署。
- 优势:安装简便(跨平台支持)、模型库丰富、内存占用低,适合资源有限设备。
- 限制:并发处理能力弱,不适合大规模服务。
-
- 场景:大规模在线服务(如实时聊天机器人)、多GPU集群部署、高吞吐量研究项目。
- 优势:PagedAttention和连续动态批处理显著提升GPU利用率,支持量化技术(GPTQ/AWQ)降低显存占用。
- 限制:仅支持Linux,配置复杂度高。
-
- 场景:边缘设备(树莓派)、移动端应用、本地低功耗推理、量化模型实验。
- 优势:量化技术成熟(K-quant)、跨平台兼容性强,在Apple Silicon设备上表现突出。
- 限制:命令行操作门槛较高,性能受硬件限制。
| 框架 | 性能表现 | 易用性 | 硬件需求 | 模型支持 | 部署方式 | 系统支持 |
|---|---|---|---|---|---|---|
| SGLang | 零开销批处理(吞吐量提升1.1倍)、缓存感知负载均衡(提升1.9倍)、结构化输出快10倍 | 需技术基础,提供完整API和示例 | 推荐A100/H100,支持多GPU | 全面支持主流模型(Llama、Gemma等),优化DeepSeek等模型 | Docker、Python包 | Linux |
| Ollama | 继承LLaMA.cpp的高效推理,速度实测比LLaMA.cpp快近2倍4 | 小白友好,提供图形界面、一键安装和REST API | 兼容CPU/GPU,资源管理简便 | 支持1700+模型(Llama、Qwen等),支持自定义模型 | 独立应用、Docker、REST API | 全平台(Win/macOS/Linux) |
| vLLM | PagedAttention技术优化显存,动态批处理提升吞吐量24倍12 | 配置复杂,需技术基础 | NVIDIA GPU(推荐A100/H100) | 支持Hugging Face主流模型 | Python包、OpenAI兼容API、Docker | 仅Linux |
| LLaMA.cpp | 多级量化(2-8bit)、跨平台优化(ARM/x86/Apple Silicon) | 命令行为主,提供多语言绑定和API | CPU/GPU均可,低资源设备优化 | 支持GGUF格式模型,适配LLaMA系列 | 命令行工具、API服务器、多语言绑定 | 全平台 |
选型建议
- 企业级高并发:优先选择 SGLang(性能极致)或 vLLM(多GPU优化)。
- 个人/轻量级应用:推荐 Ollama(易用性最佳)或 LLaMA.cpp(低资源设备适配)。
- 跨平台与边缘部署:LLaMA.cpp 是首选,支持全平台和量化。
- 研究开发:vLLM 适合探索高效推理技术,SGLang 适合结构化输出需求。
二、Ollama 部署
1. 下载并安装 Ollama
还没看上一章的同学请先前往学习,再来本章继续看。
打开 Ubuntu 终端,切换到 r1 python 环境,输入如下命令行:
bash 代码解读复制代码
# 切换到 r1 虚拟环境
conda activate r1
# 下载 ollama
curl -fsSL https://ollama.com/install.sh | sh
# 验证ollama是否已成功安装
ollama -v
2. Ollama 加载模型
Ollama 加载模型有两种方式:
1. Ollama 社区下载
打开 Ollama 官网 点击左上角的 Models 。可以看到,列表第一个就是 deepseek-r1 模型
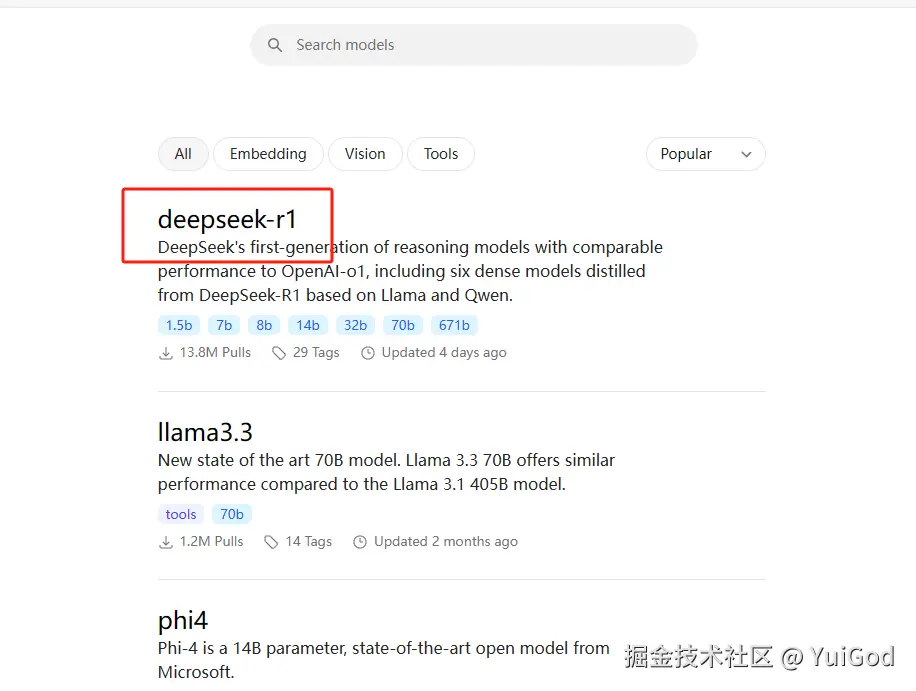
点击进去,可以看到具体的模型类型,在左侧点击选中 7B 选项,右边可以看到命令行更新为:ollama run deepseek-r1:7b,可按照需求下载想要的蒸馏模型:
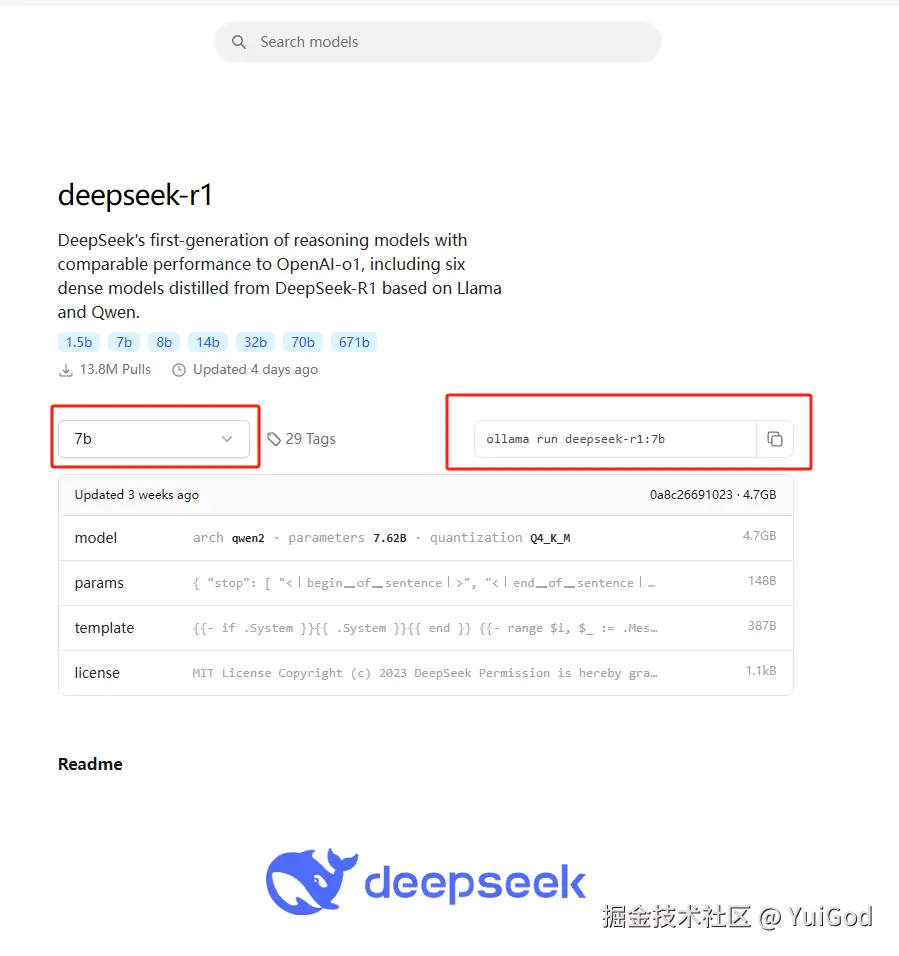
复制命令行,回到 Ubuntu 终端,粘贴命令行:
bash代码解读复制代码ollama run deepseek-r1:7b
等待模型下载,下载完成的模型路径在 /usr/share/ollama/.ollama/models 里。
ollama 下载模型的路径可以自行修改,只是有一点点麻烦,这里不过多赘述。
2. 加载自定义模型(常用)
有时候我们需要自己下载模型,或者已调试过的模型,此时社区的模型不够满足需求。所以需要将自定义的模型注册到Ollama中,说白了就是让 Ollama 知道自定义模型的路径在哪里。
Ollama 只支持 GGUF 格式的模型,并采用 Modelfile 文件方式导入。我们在下载模型的时候,需要找到下载已量化的,具有GGUF后缀格式的模型。
由于 Hugging Face 需要搭梯子才能访问,国内一般都去 模型库首页 · 魔搭社区 这里来下载模型。
在魔塔社区里搜索模型,查找具有 GGUF 的来下载,现在点击 DeepSeek-R1-Distill-Qwen-7B-GGUF · 模型库:
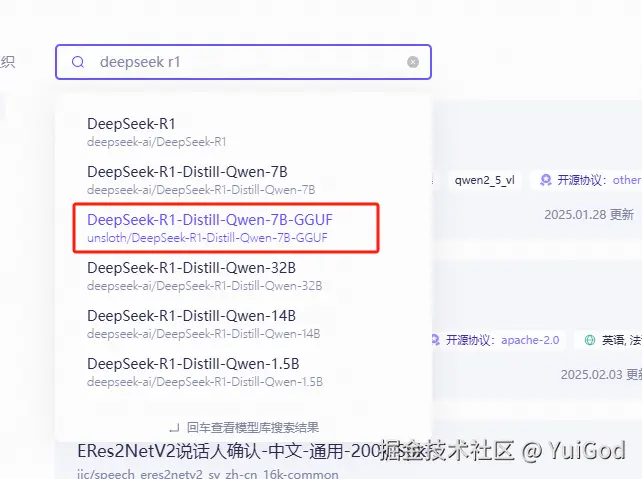
在上方点击模型文件,会有很多不同的量化版本的模型供我们下载,我们选择 Q4_K_M 的模型文件下载即可。
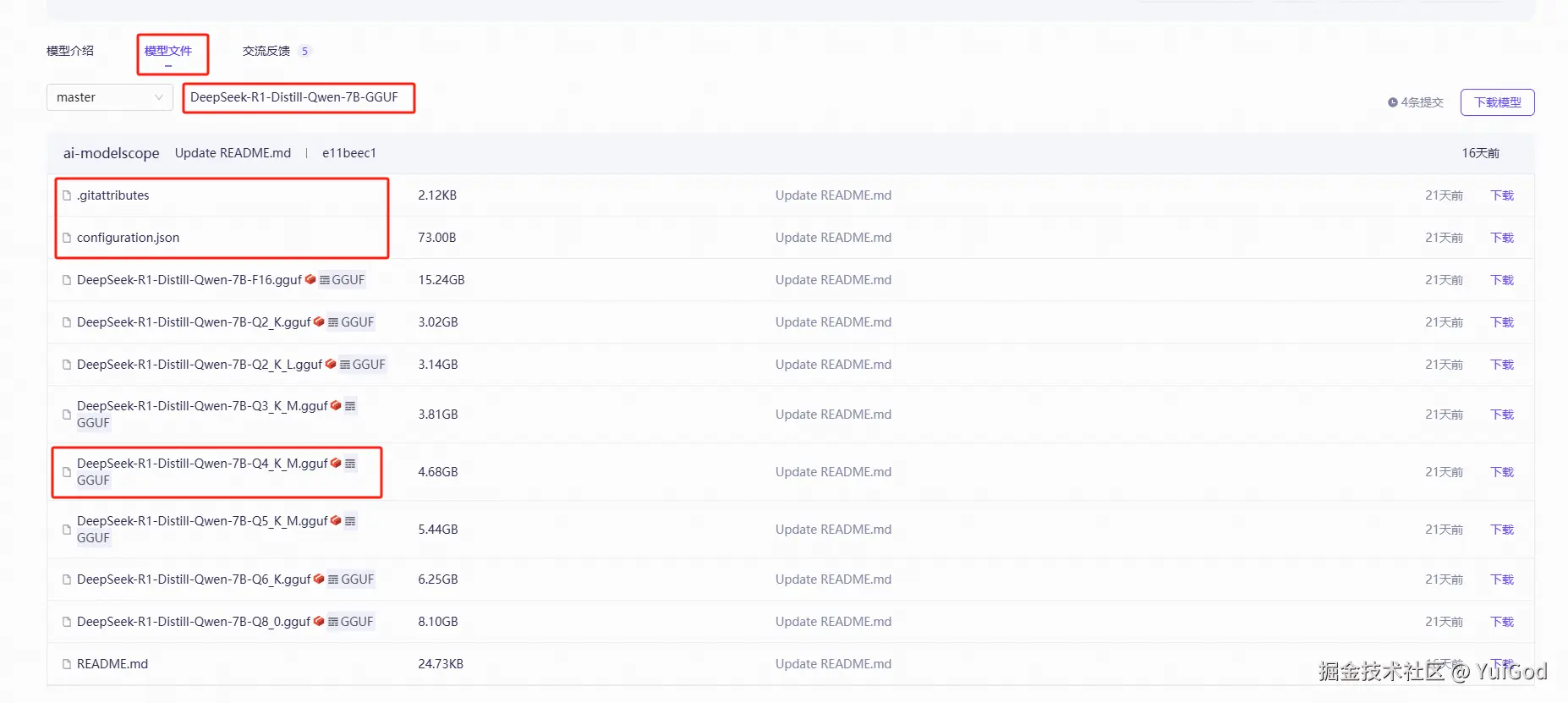
只需要下载上图中红框标出来的三个文件。
Q4_K_M的意思是4位量化,且是对称量化,Ollama 对Q4_K_M量化更友好,需要的显存也会低很多,如果显存足够的同学,可以选择更高位数的量化版本,模型回答准确率也更高一些。量化过的模型,可以减少模型的大小和计算复杂性,同时尽可能减少精度损失,加快推理速度,并且运行占用的显存更少,适合资源受限的场景使用。
其实在 Ollama 社区下载的模型也是经过量化的,只不过是 Ollama 自己的方式来量化模型。
下载好模型后,创建一个文件夹,名为 DeepSeek-R1-Distill-Qwen-7B-GGUF,将这三个文件存放进去。
在子系统 Linux 主目录下,创建 Proje/Models 目录,将这个文件夹复制到里面去,并将后缀为 Zone.Identifier的三个文件删除。
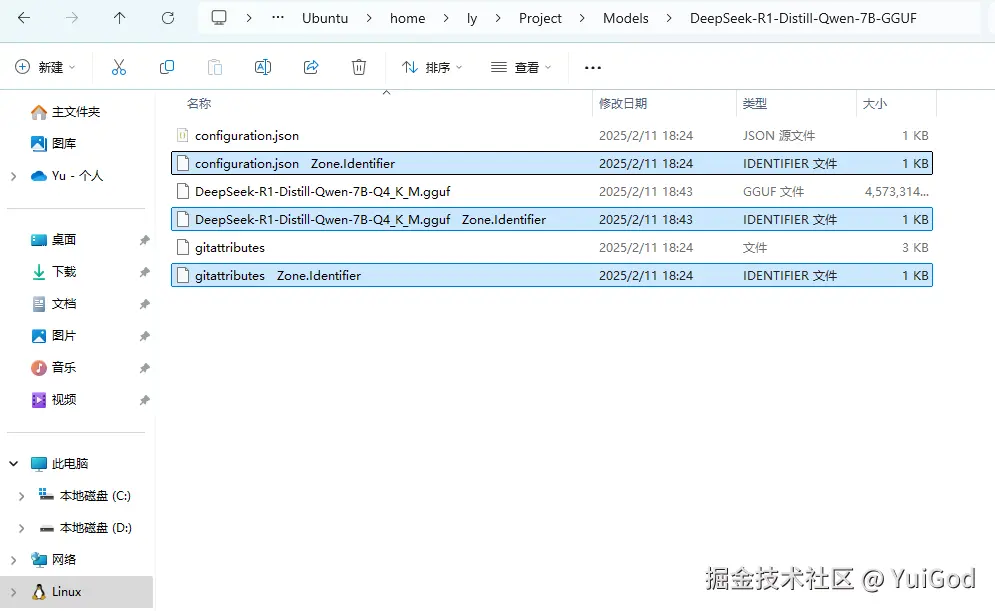
新建一个 Modelfile 文件,填写如下文本:
Modelfile代码解读复制代码FROM ./DeepSeek-R1-Distill-Qwen-7B-Q4_K_M.gguf
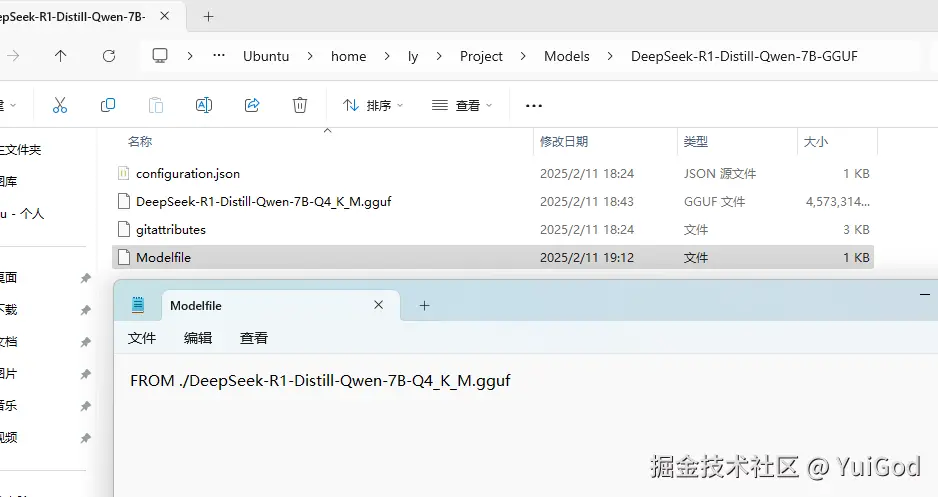
保存好后,接着打开 Ubuntu 终端,切换 r1 环境,cd 进入到模型文件目录,接着运行下面命令行,将模型注册到 Ollama 中:
bash 代码解读复制代码# 切换 r1 环境
conda activate r1
# 进入模型目录
cd Project/Models/DeepSeek-R1-Distill-Qwen-7B-GGUF
# 模型注册到 Ollama ,名字为 deepseek-r1-7b
ollama create deepseek-r1-7b -f Modelfile
# 查看 ollama 注册列表
ollama list
注册模型填写的名字尽可能简单,不然后面敲命令行会累死。
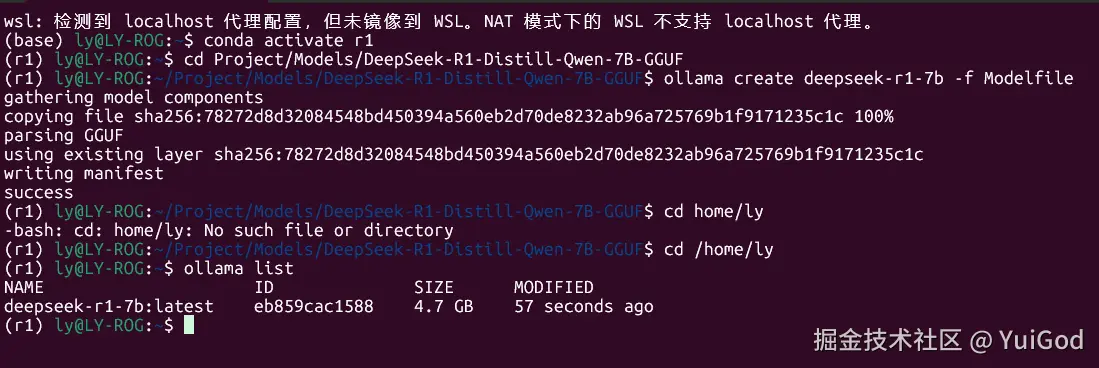
如果 Ollama 注册列表有名字,则说明注册模型成功。
3. 运行模型
执行命令:
js代码解读复制代码ollama run deepseek-r1-7b
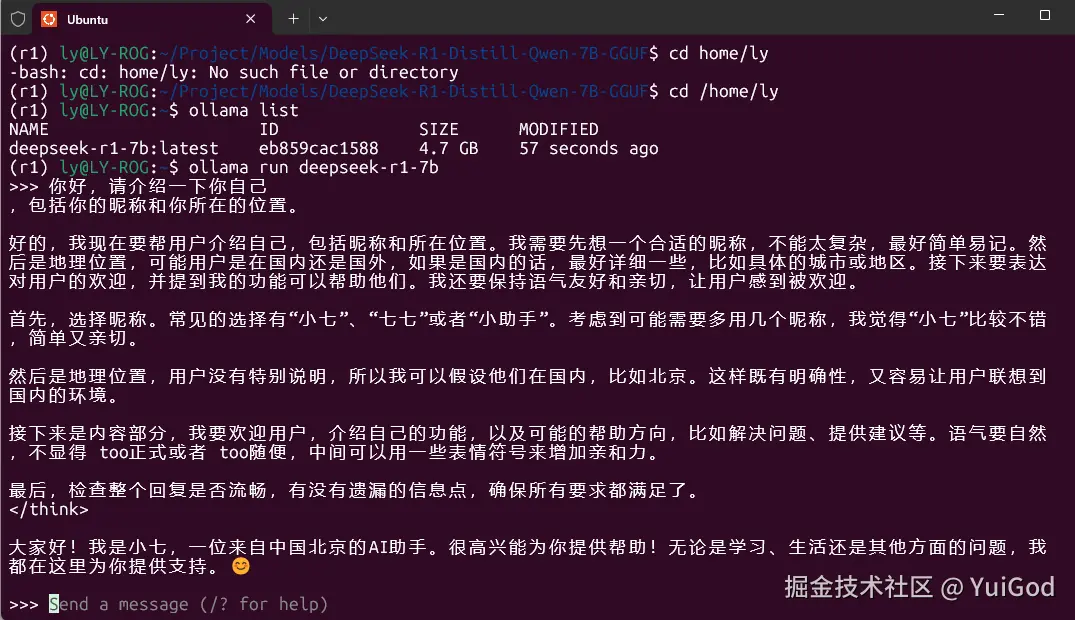
运行成功后就可以发消息了,我发了一句:你好,请介绍一下你自己。
结果它回答的……emmmm,好像还不错。
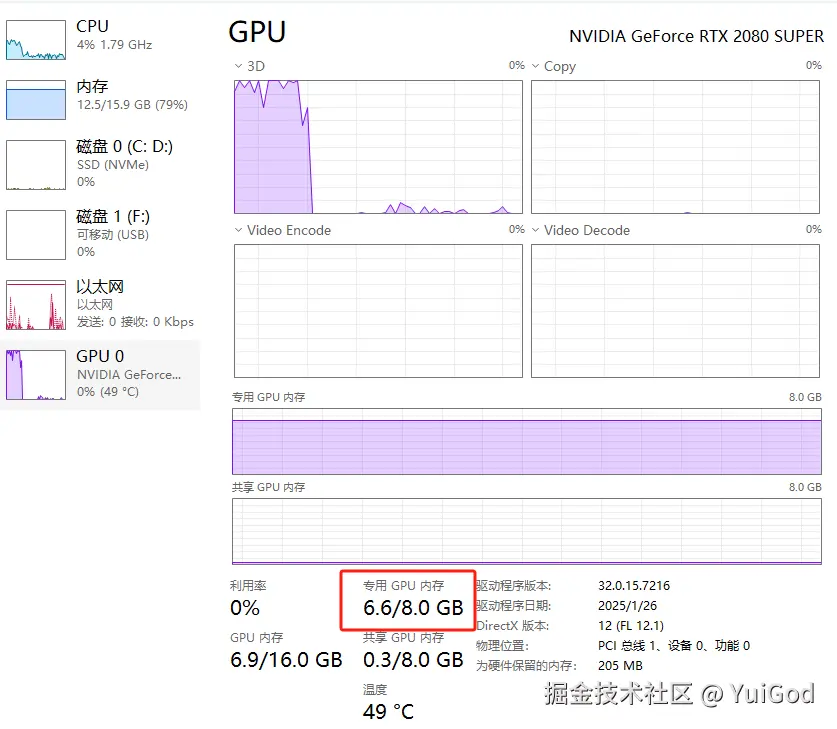
从任务管理器中可以发现,显存占用了 6.6G,我的老显卡还能再坚持坚持。
其它 Ollama 命令行:
查看模型列表:ollama list
查看当前运行模型:ollama ps
关闭模型:ollama stop deepseek-r1-7b
删除模型:ollama rm deepseek-r1-7b
3. 测试 Ollama Api
当然,用终端来实现对话,想想都觉得不够优雅。现在,我们掏出老朋友 Apifox。
我相信肯定有靓仔说,这不就是接口请求嘛,这也叫优雅?
欸?靓仔先别着急,凡事要一步一步来。仔细想想,有了请求接口,后面能干嘛知道吧?可以和前端通信了啊,前端可以写一个漂亮的界面,或者直接嵌入到已有的前端项目,对话聊天直接通过接口调用就好了。
在微软官方的 WSL 教程里,使用 WSL 访问网络应用程序 | Microsoft Learn,可以知道,windows 访问 wsl2 子系统的 IP 地址,直接使用 localhost 即可。
Ollama 的 Restful Api 接口文档在这里:ollama/docs/api.md,可以发现,其中的对话 Api 接口为:
POST /api/chat
使用例子如下:
js 代码解读复制代码curl http://localhost:11434/api/chat -d '{
"model": "deepseek-r1-7b",
"messages": [
{
"role": "user",
"content": "请讲一段笑话。"
}
],
"stream": false
}'
当然,这个是 Linux 请求 url 的写法。我们可以知道的是:
ollama 默认启动服务的端口为:11434。
/api/chat 通过 post 请求,请求 body 为一个 json 数据。现在json参数里的 stream: false,意思是关闭流式响应,等所有回答完成后,再返回 Response 数据,如果改成 stream: true ,那么就可以实现流式输出文字。
1. ApiFox 创建 post 请求
打开 ApiFox 新建项目为:knowledge-qa-deepseek
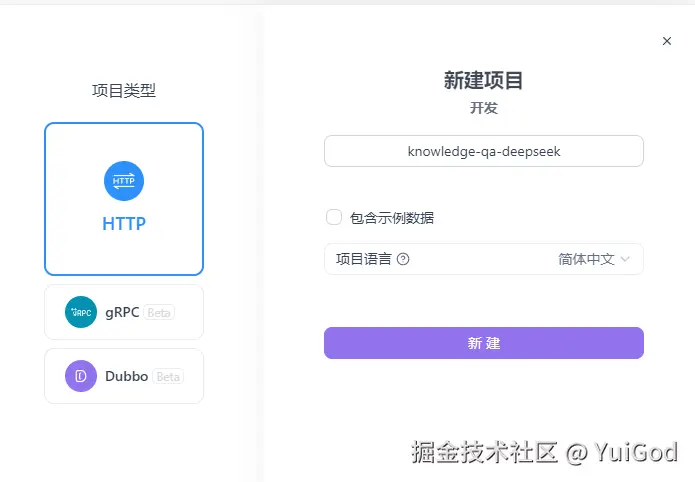
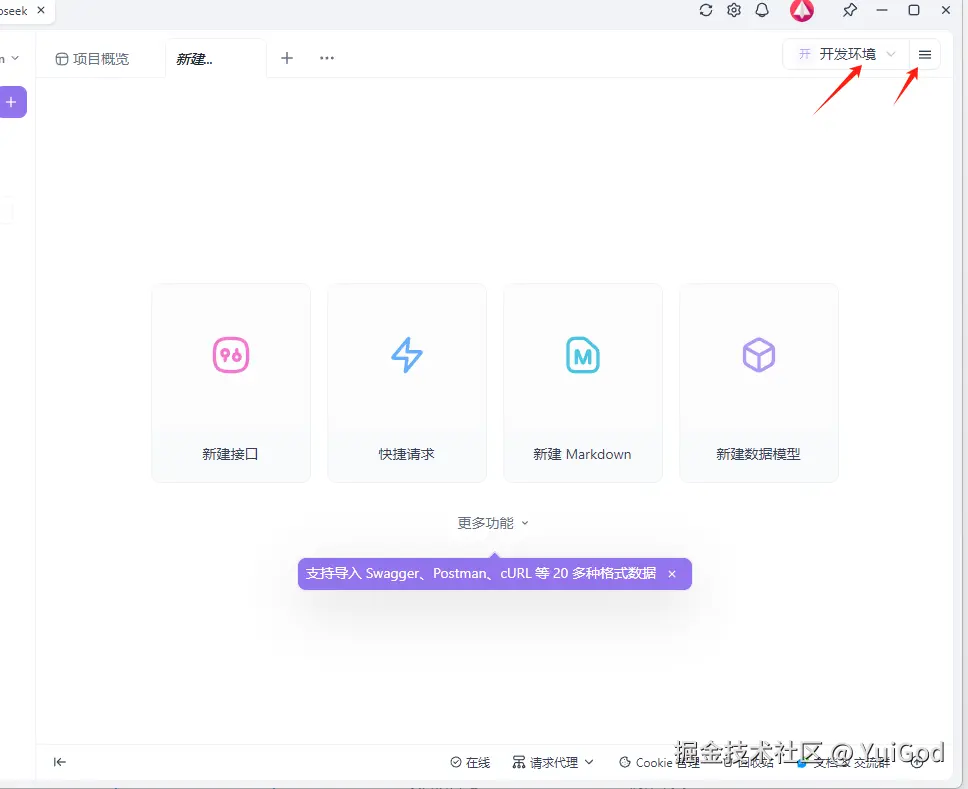
进入项目后点击右上角选择开发环境,然后点击右侧的 ≡ 图标:
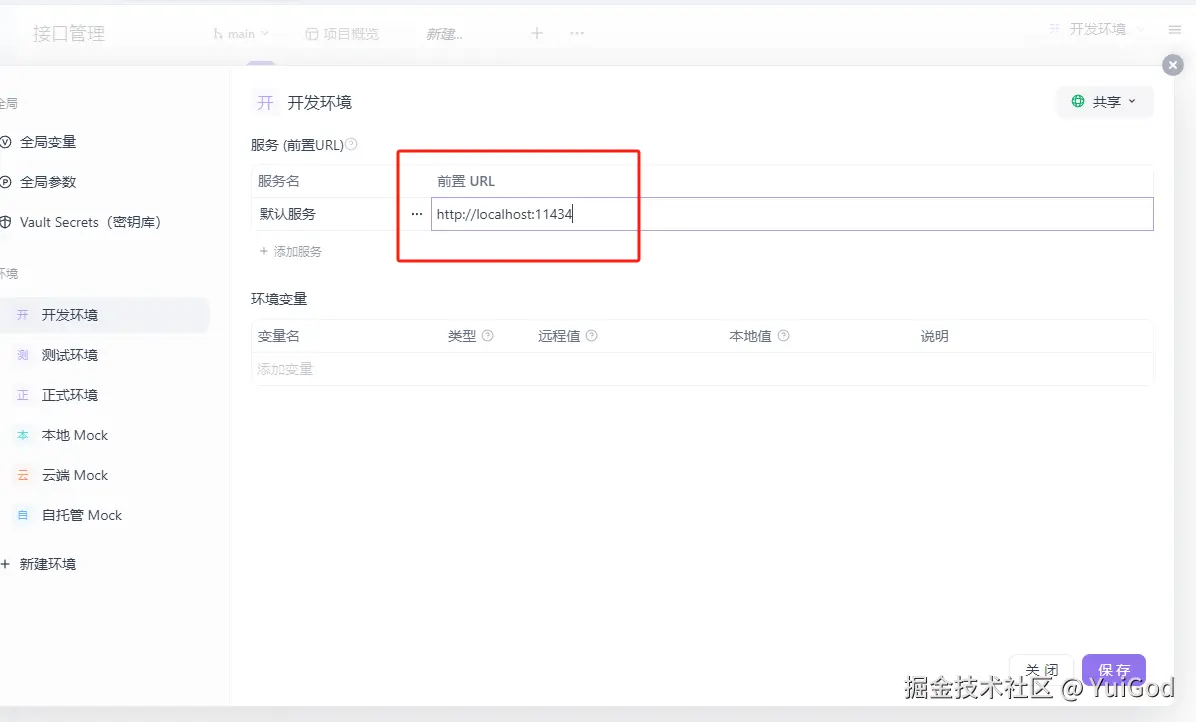
将开发环境的前置 url 改成:https://localhost:11434,点击保存,关闭。
接着点击新建接口:
- 改成 post 接口,输入框输入
/api/chat。- 点击 Body。
- 点击 json。
- 粘贴上面的json。
- 保存接口。
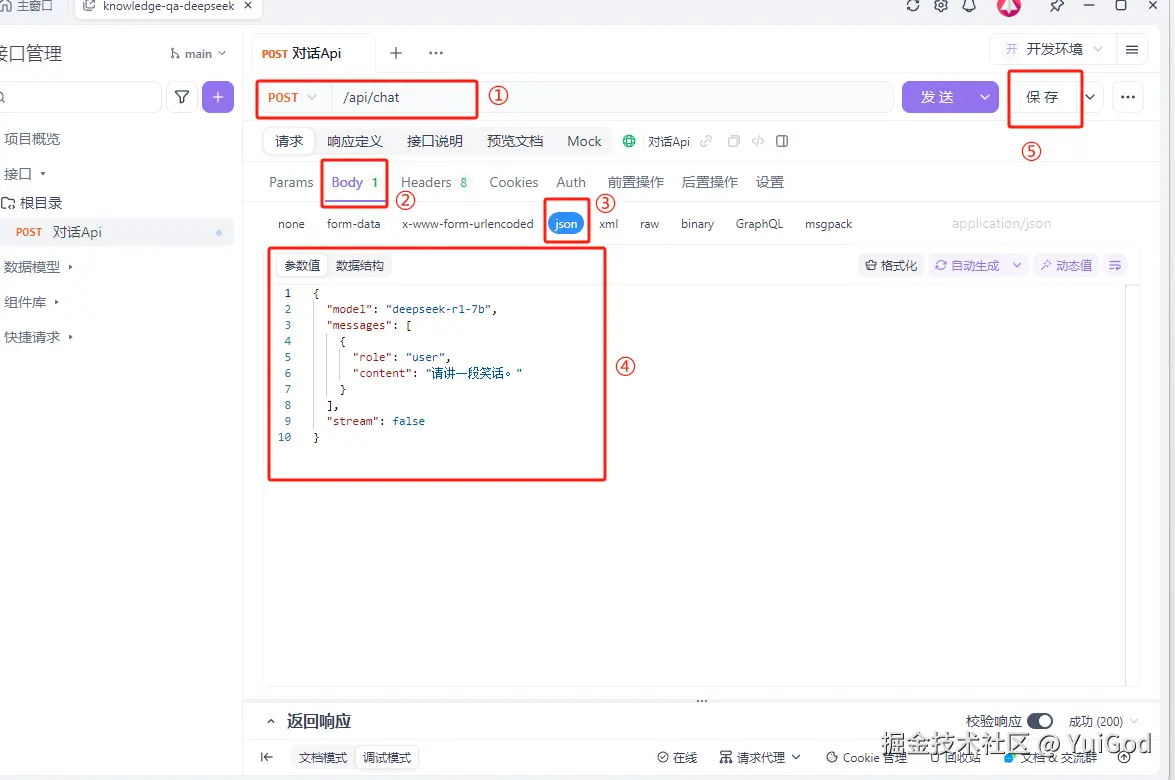
设置完成后,发送数据,可以发现,返回相应有数据了。当然因为关闭了流式响应,所以需要等待的时间有一丢丢长,等大模型一次性回答完后,才会返回数据。
(提前已经启动了 Ollama deepseek-r1-7b 模型)
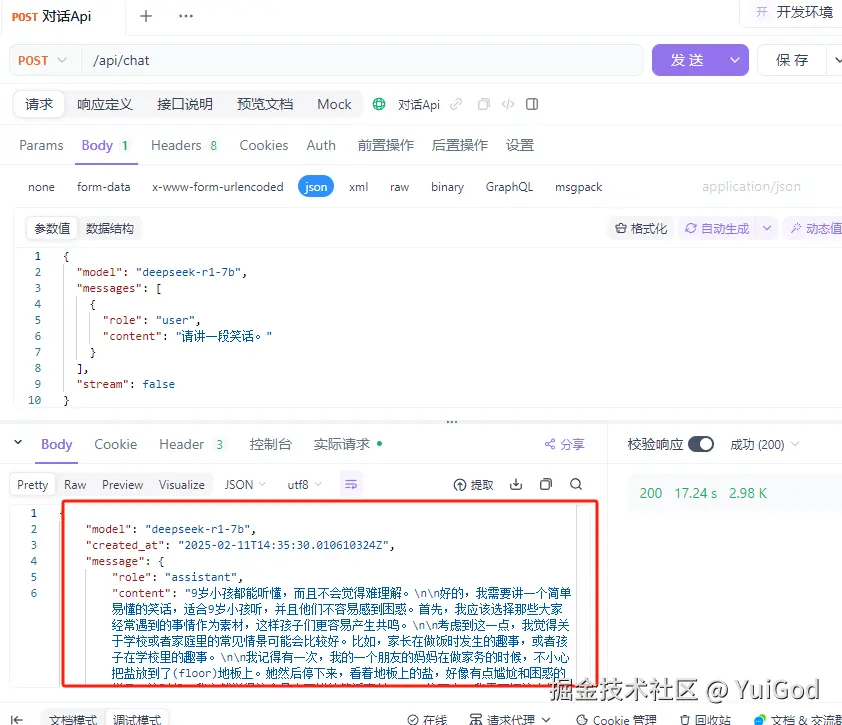
有了返回响应后,该知道怎么做了吧? 好了剩下的丢给前端小姐姐搞定了(23333)。
靓仔们也可以试一下,设置 stream:true,看看返回的响应是啥。
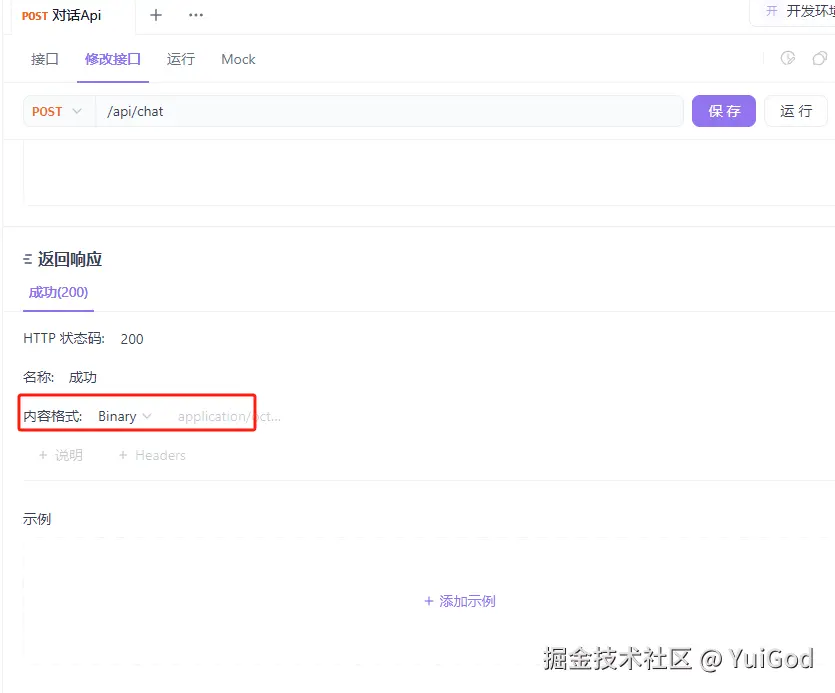
Ollama 返回的流式响应的数据是二进制对象流,所以,在 ApiFox 返回响应中,将内容格式改为: Binary。
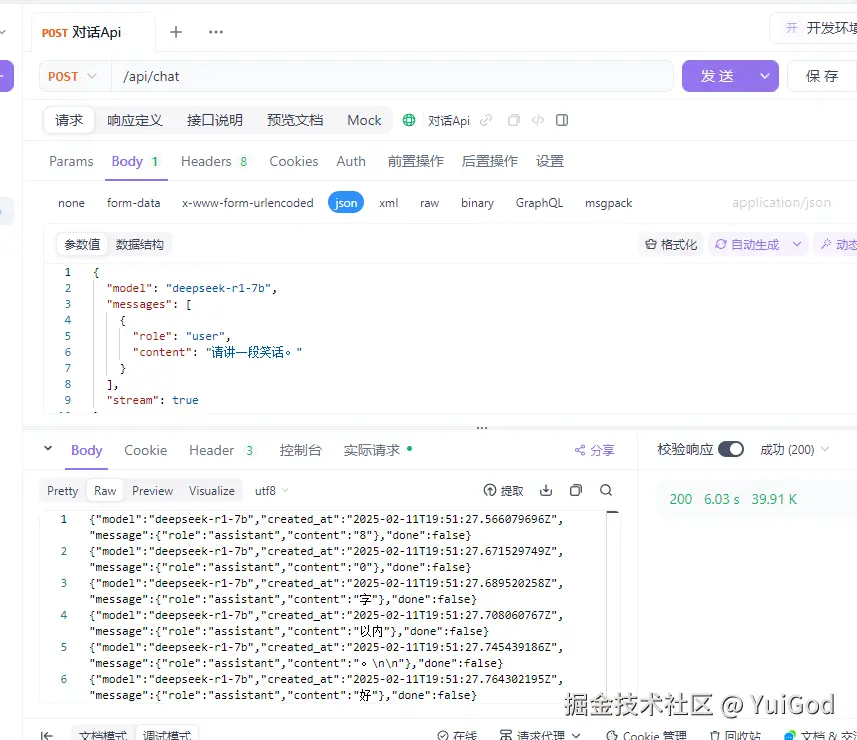
返回响应是一截一截的 json 对象流。
流式响应的数据,前端是浏览器端的话,需要做一些特殊的处理。这个在后面的章节实现前端ui框架时,再细说。
2. 前端 JavaScript 处理流式响应的坑
给使用 JavaScript 的同学提个醒!
浏览器端处理流式响应,想要完美体验 请使用 Fetch API。
Axios 无法使用
stream来直接处理真正的流式响应(但 Node.js 中可以使用stream),这与浏览器底层 HTTP 请求实现的限制有关。
为什么浏览器中的 Axios 不能直接处理流?
1. 底层机制差异
-
Node.js 环境:Axios 使用 Node.js 的
http模块,天然支持流式传输(responseType: 'stream'),数据可以逐块(chunk)接收。 -
浏览器环境:浏览器端 Axios 基于
XMLHttpRequest,而XMLHttpRequest的responseType属性不允许设为stream,合法值仅有:arraybuffer|blob|document|json|text。
即使服务端返回流式响应(如 text/event-stream 或分块数据),浏览器也无法通过 Axios 直接以流的形式逐块解析数据。Axios 在浏览器中只能一次性接收完整响应,再通过字符串或文本处理模拟“流式效果”。
2. 如果必须使用 Axios
可以通过更改 responseType: 'text' 和 手动分块处理 模拟流式效果,但存在以下问题:
- 数据完整性风险:依赖服务端分块的准确性,需维护缓冲区(
buffer)处理不完整数据。 - 性能损失:需手动分割字符串,效率低于原生流式处理。
3. 简单的代码测试
这里使用 JavaScript 代码简单的测试一下如何对 Ollama Api 进行流式响应:
js 代码解读复制代码// fetch 请求,stream 流式响应
async function fetchStreaming() {
const response = await fetch('http://localhost:11434/api/chat', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
// 请求传递给 ollama 数据
body: JSON.stringify({
model: 'deepseek-r1-7b',
messages: [
{
role: 'user',
content: '请讲一段笑话。'
}
],
stream: true
})
})
if (!response.body) {
throw new Error('Response body is null')
}
// 读取数据流
const reader = response.body.getReader()
// 文本解码器
const decoder = new TextDecoder()
let buffer = ''
while (true) {
const { done, value } = await reader.read()
if (done) break
buffer += decoder.decode(value, { stream: true })
const lines = buffer.split('\n')
buffer = lines.pop() || ''
for (const line of lines) {
if (line.trim()) {
try {
const data = JSON.parse(line)
// 实时输出
console.log(data.message.content)
} catch (err) {
console.error('解析错误:', err)
}
}
}
}
}
fetchStreaming()
结果如图所示:

再让前端小姐姐稍微润色一下,就可以完美的实现流式回答了。
结语
现在已经成功通过 Ollama 部署 DeepSeek-R1-7B 蒸馏模型,并且简单的测试了一下 Ollama 的 Api。
下一章开始利用 LangChain 搭建本地知识库问答系统了。
评论记录:
回复评论: