
一、网际寻址原理
前一篇网络接口层管理介绍了数据链路层可以靠MAC地址在同一个数据链路局域网内寻址。拿以太网为例,在一个数据链路中主机常与以太网交换机(可以看作是有多个端口的网桥)相连,它们根据数据链路层中每个帧的目标MAC地址,决定从哪个网桥接口发送数据,选择发送接口的依据就是交换机的地址转发表(Forwarding Table,可根据交换机自学算法自动生成)。
当网络设备地址总数并不是很多的情况下,有了唯一地址(比如MAC地址)就可以定位相互通信的主体。然而,当地址总数越来越多时,如何高效地从中找出通信的目标地址将成为一个重要的问题。为此人们发现地址除了具有唯一性还需要具有层次性。MAC地址虽然具有唯一性,但没有层次性,也即当网络设备增加到一定程度,需要将网络分成多个数据链路时,MAC地址无法跨链路寻址,是真正负责最终通信的地址。要实现跨局域网的网际寻址,就要靠具有层次性的网络IP地址实现了。
1.1 网络地址IPv4
网络IP地址是怎样实现分层的呢?IP地址由网络号和主机号两部分组成,即使通信主体的IP地址不同,若主机号不同,网络号相同,说明它们处于同一个网段。网络号相同的主机在组织结构、提供商类型和地域分布上都比较集中,为IP寻址带来了极大的方便。下面先看下IP地址的分类:
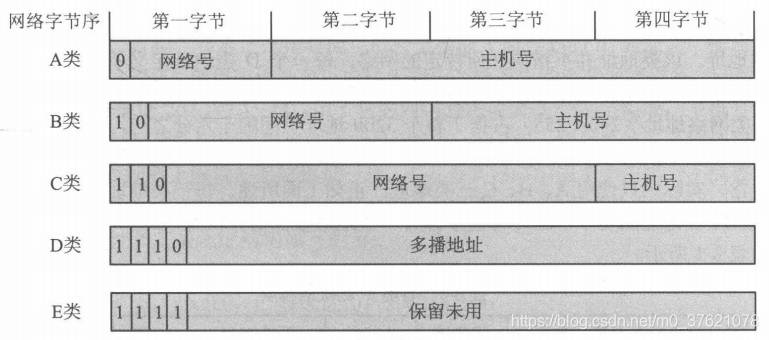
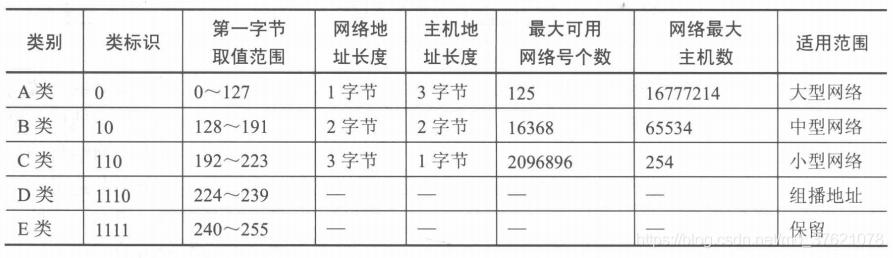
网络IP地址是一个32bit整数地址,只有具有有效IP地址的主机才能跨越数据链路实现网际寻址。目前的IP地址多采用分类编址,把所有IP地址划分为A/B/C/D/E五类,前三类由网络号和主机号组成,D类都是组播地址,E类保留未用,各类IP地址特点如下表示:
MAC地址中除了单播地址还有多播和广播地址,在IP地址中也有一些特殊的网络地址。列举几个如下:
- 网络地址:主机号全部取0;
- 直接广播地址:主机号全部取1;
- 受限广播地址:IP地址32位全部为1,将广播限制在最小范围内,若采用标准IP编址则跟直接广播地址一致,若采用子网编址则广播被限制在本子网内,属于E类地址;
- 多播地址:即上面介绍的D类地址;
- 本网络上的特定主机:网络号全部取0;
- 本网络本主机:IP地址32位全部为0;
- 环回地址:127.x.x.x,通常使用127.0.0.1;
前面介绍的特殊地址不能被分配给任何主机使用,下面还有一些专用地址(也叫私有地址)可以被分配给多个主机使用,当然这些主机应该处于互相独立的专用网内,例如以太网局域网:

随着互联网的覆盖范围逐渐增大,网络地址会越来越不足以应对需求,直接使用A/B/C类地址显得浪费资源,为了根据需求更精细的使用IP地址,又增加了“子网掩码”的识别码将A/B/C类网络地址细分为更多的子网。子网掩码也是一个32位的整数地址,它对应IP地址网络标识部分的位全部为“1”,对于IP地址主机标识的部分全部为“0”,由此一个IP地址可以不再受限于自己的类别,而是可以用这样的子网掩码自由地定位自己的网络标识长度。举例图示如下:

1.2 网际寻址与路由协议
前面谈到MAC地址只能在本数据链路内寻址,不能跨局域网寻址,这里介绍的网络IP地址可以实现跨局域网实现网际寻址。MAC寻址靠交换机的地址转发表(记录MAC地址与发送接口的表),IP寻址则靠路由控制表(Routing Table)。路由控制表中记录着网络地址与下一步应该发送至路由器的地址,在发送IP数据包时,根据IP包首部中的目标IP地址从路由控制表中找到与该地址具有相同网络地址的记录,根据该记录将IP数据包转发给相应的下一个路由器,如果路由控制表中存在多条相同的网络地址记录,则根据最长匹配原则选择相同位数最多网络地址的下一个路由器作为转发目标。
路由控制表的生成有静态和动态两种方式,静态路由控制表需要手工配置且不自动刷新,动态路由控制表可以根据路由协议自动生成并自动刷新,所以一般使用动态路由表。由于网络地址的分层特性,可以将内部的多个子网掩码合并,对外呈现出同一个网络地址,通过这种路由信息的聚合有效减少了路由表的项数。但路由控制表也很难包含所有的网络及子网信息,一般都会配置一个默认路由(默认网关),当在路由控制表中查不到匹配项时,就把默认路由作为该IP数据包的转发目标。
动态路由控制表是靠路由协议交换路由信息生成的,那么路由协议是如何生成路由控制表的呢?前面介绍网络号相同的主机在组织结构、提供商类型和地域分布上都比较集中,实际上制定路由策略时对一个企业或组织内部的网络授权给该企业或组织内部自行决定,这样可以根据自己的需求构建合适的网络也能对外屏蔽企业内部的网络细节,以此为准在一个或多个网络群体中采用的小型网络单位叫做自治系统(AS: Autonomous System),自治系统内部动态路由采用的是域内路由协议(IGP: Interior Gateway Protocol),自治系统之间的路由控制则采用域间路由协议(EGP: Exterior Gateway Protocol)。下面给出一个关系图示:
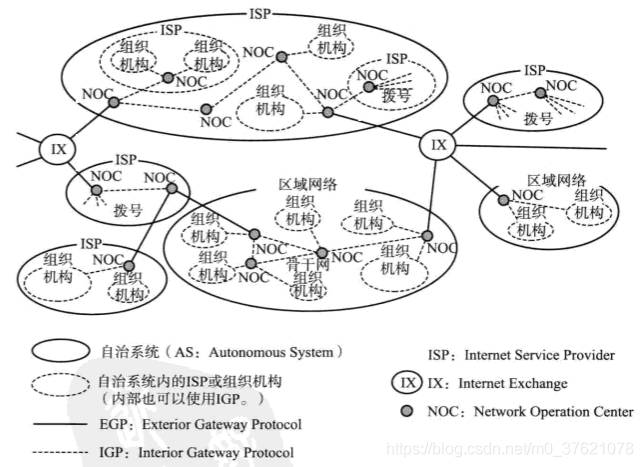
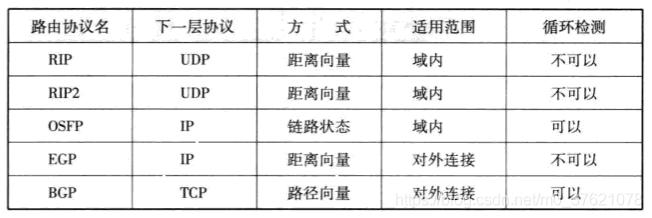
路由协议被分为EGP和IGP两个层次:EGP主要在区域网络之间进行路由选择,常用的路由协议是BGP(Border Gateway Protocol);IGP主要在区域网络内部进行路由选择,常用的路由协议有RIP(Routing Information Protocol)、RIP2、OSPF(Open Shortest Path First)等,主要路由协议的特点如下表示:
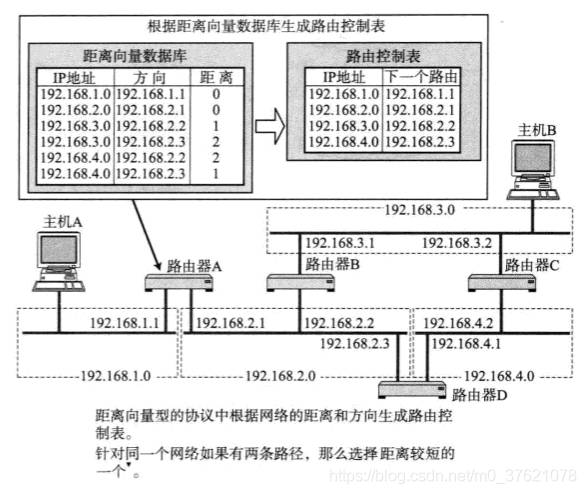
距离向量算法是根据距离和方向决定目标网络或目标主机位置的,路由器之间可以互换目标网络的方向及其距离信息,并以此为基础制作路由控制表。其中RIP/RIP2就是使用距离向量算法实现的协议,这里的距离单位是“跳数“(所经过的路由器个数),通过定期全网广播,每经过一个路由器距离增加1,根据距离向量生成距离向量表,再抽出较小距离的路由生成路由控制表,大概图示如下:
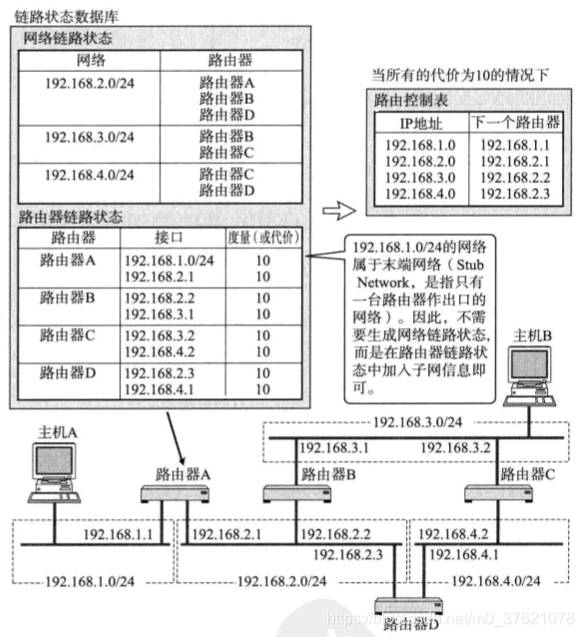
链路状态算法是路由器在了解网络整体连接状态的基础上生成路由控制表的一种方法,在该方法中每个路由器必须保持同样的信息才能进行正确的路由选择。OSPF就是一种链路状态型路由协议,路由器之间交换链路状态生成网络拓扑信息,然后根据这个拓扑信息生成路由控制表。RIP/RIP2路由协议中要求途中所经过的路由器个数越少越好,OSPF路由协议则可以给每条链路赋予一个权重(每种链路的网络带宽不同),并始终选择一个总权重最小的路径作为最终路由。这里使用了图论中的最短路径算法,RIP/RIP2使用了无权最短路径算法,OSPF使用了有权最短路径算法(参考Dijkstra算法),算法原理这里就不展开介绍了。给出OSPF路由协议的工作原理图示如下:
BGP边界网关协议所使用的路径向量算法跟距离向量算法类似,不过RIP/RIP2是以所经过的路由器个数作为距离代价,BGP则把所要经过的AS自治系统的个数作为距离代价。BGP路由协议一般选择所经过AS数最少的路径,但需要遵循各个AS之间签约的细节进行更细颗粒度的路由选择。
1.3 网络地址IPv6
IPv6是为了从根本上解决IPv4地址耗尽的问题而被标准化的网际协议,IPv4的地址长度为4个8位字节即32比特,而IPv6的地址长度为8个16位字节即128比特,地址空间是IPv4的2^96倍,足以为人们所能想象到的所有主机和路由器分配地址了。IPv6位数是IPv4的四倍,如果还用IPv4的十进制表示方法显得太长,所以IPv6采用16位字节为一组,且中间出现连续的0时可以将这些0省略一次,IPv6的表示方法如下:

IPv6地址也分单播地址与多播地址,但没有广播地址,主要是考虑到广播降低了网络性能,IPv6使用多播地址来替代IPv4中必须使用广播的情况。IPv6的全局单播地址格式如下:
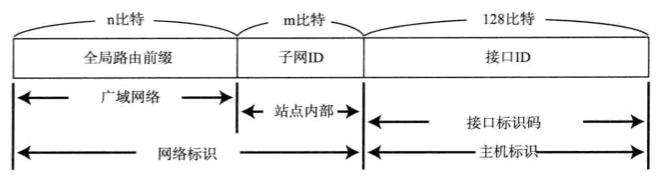
现在IPv6的网络中常使用的格式为:广域网络ID n = 48,子网ID m = 16,主机接口ID 128-n-m = 64。多播地址第一字节全1,可简略表示为FF00::/8。除了单播与多播地址外,跟IPv4类似,也有一些私有地址,在不与互联网直接接入的局域网内部,可以使用唯一本地地址,在不跨路由器的同一链路上可以使用链路本地单播地址。这些地址结构如下表示:
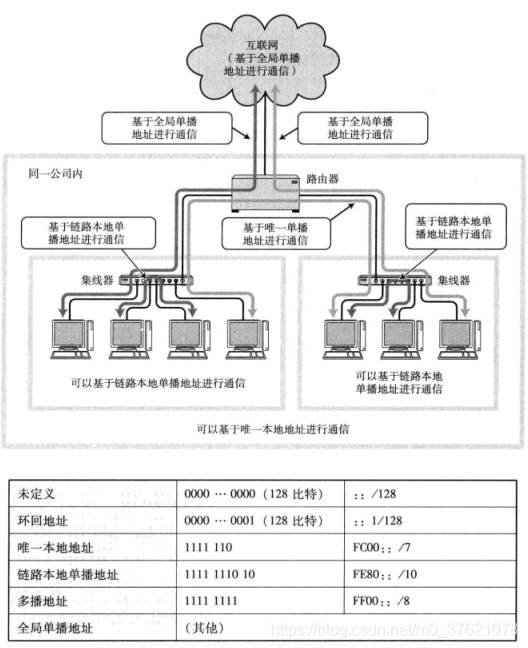
在IPv6的环境下,可以同时将这些IP地址(上表列举的多种类型IP地址)同时配置在同一个NIC上,按需灵活使用。
1.4 网络地址转换与IP隧道
前面介绍的IP地址除了全局地址还有私有地址,私有地址只能在局域网内使用,不能直接接入互联网,这主要是为了缓解IPv4地址短缺问题出现的局域网私有地址复用方案。那么,局域网内被分配私有IP地址的主机如何访问互联网呢?这就需要路由器通过NAT(Network Address Translation)功能来实现了,一个支持NAT功能的路由器至少要有一个内部地址和一个外部地址,内部地址也即私有地址是用于与局域网内的用户通信的,外部地址也即全局地址是用于与外部互联网通信的。当局域网内主机访问外部互联网时,NAT将用户的内部IP地址转换为一个外部公共IP地址;反之,数据从外部返回时,NAT将目的地址替换为用户的内部IP地址,实现多个私有地址共有一个全局地址访问互联网的功能。NAT工作过程如下图示:
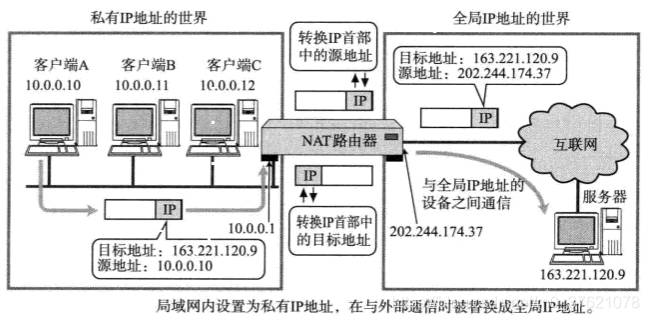
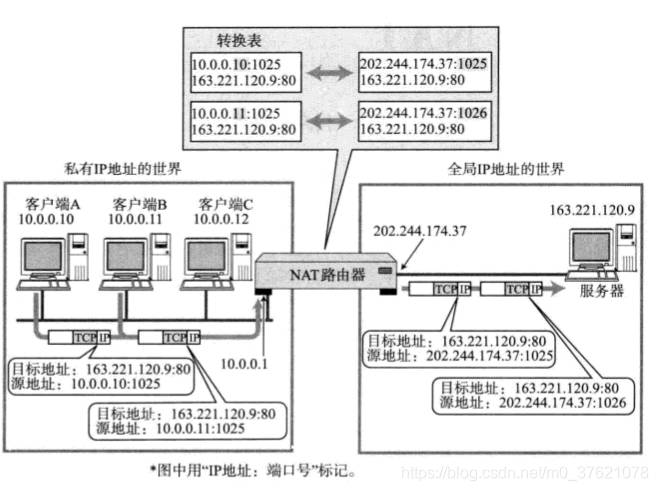
在NAT路由器内部会自动生成一张地址转换表,用于记录私有地址与全局地址的映射关系。当局域网内的多台主机同时都要与外部进行通信时,仅仅转换IP地址已经不够用了,需要将传输层TCP/UDP的端口号一起转换,这种转换方式称为NAPT(Network Address Port Translation),转换过程如下图示:
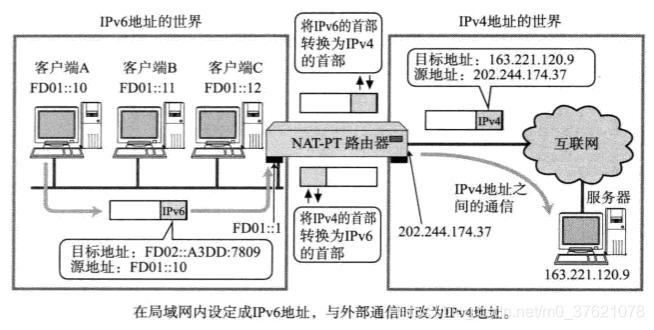
现在IPv6使用率还比较低,IPv4到IPv6的切换需要一个循序渐进的过程,因此很长一段时间内免不了IPv4与IPv6共存的情况,IPv4与IPv6混合组网也需要能互相通信。借鉴前面介绍的全局地址与私有地址的转换方案,IPv4与IPv6能否实现相互转换呢?为了解决这个问题,出现了NAT-PT(Network Address Translator - Protocol Translator)技术,能实现IPv6与IPv4网络地址的相互转换,转换过程如下图示:
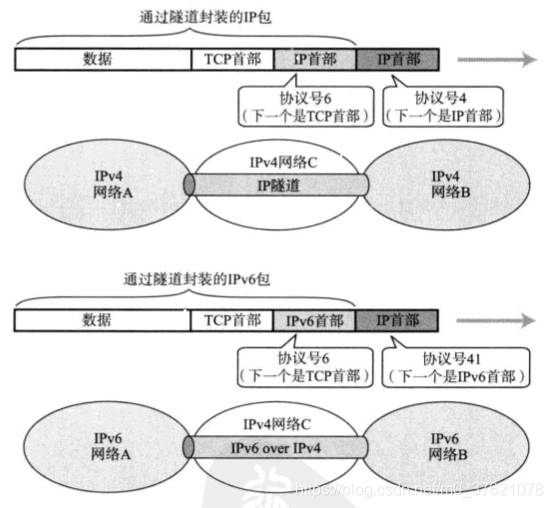
NAT网络地址转换都依赖于自己生成的转换表,存在一些限制或开销较大等缺点,比如两个互相通信的主机都处于IPv6网络,这两个IPv6网络无法直接进行通信,需要通过中间的IPv4网络相互通信,如果在两个IPv6间建立一个IP隧道,显然比两端都进行NAT地址转换更加简单高效。IP隧道怎么建立呢?通常情况下一个数据包只有一个IP首部,要进入中间网络时为了符合待穿越网络的IP地址要求,需要在原IP首部前再追加一个IP首部,待离开该网络时再删除临时追加的IP首部,从而完成数据包穿越中间网络的目的,这个利用临时追加、过后删除IP首部的技术称为IP隧道,穿越过程如下图示:
二、ARP协议
2.1 ARP协议简介
前面分别介绍了IP地址进行网际寻址,MAC地址进行链路内寻址,需要两者配合一起完成主机寻址的任务。数据包从一个主机发送到另一个主机时,目标IP地址一直不变,作为查询路由控制表进行路由转发的依据,但实际转发还是需要在链路层根据MAC地址选择相应的转发接口,所以目标MAC地址一直指向下一个网络接口,整个寻址过程如下:
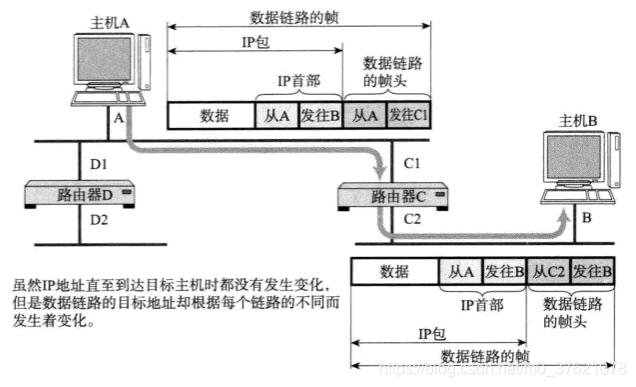
前面介绍路由控制表的下一个路由地址是一个IP地址,但实际是通过把数据帧的目标MAC地址设置为下一个路由接口的MAC地址实现转发的,这就要知道每个IP地址对应的MAC地址。
ARP(Address Resolution Protocol)就是一种解决IP地址与MAC地址映射问题的协议,以目标IP地址为线索,用来定位下一个应该接收数据包的网络设备对应的MAC地址。为了实现IP地址与MAC地址的转换,ARP协议引入了ARP缓存表的概念,ARP缓存表中记录了一条条
从上图看ARP缓存表也分静态与动态,静态主要是多播与广播地址,实际寻址时常靠ARP协议自动生成并动态刷新维护。ARP缓存表的建立跟ARP数据包密切相关,在以太网中,ARP数据包与IP数据包是两个相互独立的部分,它们都封装在以太网帧中发送。ARP数据包有两种:一是ARP请求包,它是通过以太网广播的方式发送的,用于向具有某个IP地址的主机发送请求,希望该主机返回其MAC地址;二是ARP应答包,收到ARP请求的主机会比对该数据包中的IP地址与自己的IP地址是否相符,若是,则该主机向源主机返回一个ARP应答包,向源主机报告自己的MAC地址,源主机通过提取ARP应答包中的相关字段来更新ARP缓存表。
RARP(Reverse Address Resolution Protocol)是将ARP反过来,从MAC地址定位IP地址的一种协议。平时我们使用电脑设置IP地址常通过DHCP(Dynamic Host Configuration Protocol)自动分配获取IP地址,但对于受限的嵌入式设备,在无法通过DHCP动态获取到IP地址的情况下,可以假设一台RARP服务器,并在这个服务器上注册设备的MAC地址及其IP地址。当设备接入网络插电启动时,通过向该服务器发送RARP请求包向RARP服务器请求IP地址,该设备通过来自RARP服务器的应答包设置自己的IP地址。
2.2 ARP缓存表描述
ARP协议的核心在于ARP缓存表的建立、更新与查询,ARP缓存表由缓存表项(entry)组成,每个表项记录一组IP地址与MAC地址的绑定信息,为了便于管理,还包含了与数据包发送控制、缓存表项管理相关的状态、控制信息等。LwIP中描述缓存表项的数据结构与图示如下:
// rt-thread\components\net\lwip-1.4.1\src\netif\etharp.c
struct etharp_entry {
#if ARP_QUEUEING
/** Pointer to queue of pending outgoing packets on this ARP entry. */
struct etharp_q_entry *q;
#else /* ARP_QUEUEING */
/** Pointer to a single pending outgoing packet on this ARP entry. */
struct pbuf *q;
#endif /* ARP_QUEUEING */
ip_addr_t ipaddr;
struct netif *netif;
struct eth_addr ethaddr;
u8_t state;
u8_t ctime;
};
struct etharp_q_entry {
struct etharp_q_entry *next;
struct pbuf *p;
};
enum etharp_state {
ETHARP_STATE_EMPTY = 0,
ETHARP_STATE_PENDING,
ETHARP_STATE_STABLE,
ETHARP_STATE_STABLE_REREQUESTING
#if ETHARP_SUPPORT_STATIC_ENTRIES
,ETHARP_STATE_STATIC
#endif /* ETHARP_SUPPORT_STATIC_ENTRIES */
};
static struct etharp_entry arp_table[ARP_TABLE_SIZE];

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
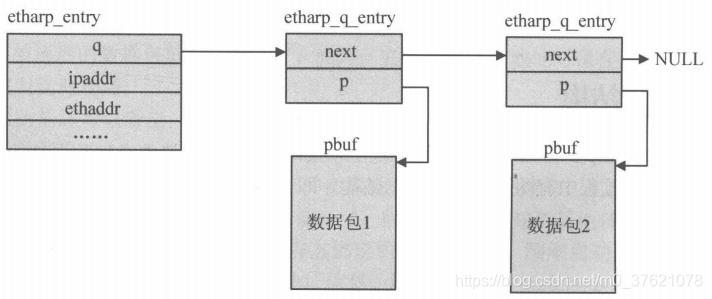
ARP缓存表是以数组方式定义的,每个缓存表项etharp_entry除了保存IP地址与MAC地址外,还保存因暂时查不到表项而不知道目的MAC地址的数据包,在接收到目标主机的ARP应答前,可能有不止一个数据包待发送,这里可以使用数据包缓冲队列etharp_q_entry(实际上是一个单向链表)来描述这些数据包。
缓存表项还包含了描述该entry状态的成员state,使用枚举类型etharp_state进行管理,初始化时ARP缓存表项的状态都为ETHARP_STATE_EMPTY;若该表项只记录了IP地址还未记录对于的MAC地址则其状态为ETHARP_STATE_PENDING;若该表项记录了一对完整的IP地址与MAC地址则其状态为ETHARP_STATE_STABLE;由于ARP缓存表项需要定期更新,原本处于stable状态的表项处于更新过程中,还未接收到ARP应答包完成更新时的状态为ETHARP_STATE_STABLE_REREQUESTING。
为了保持缓存表中各个表项的有效性,ARP模块必须设置一定的超时检查机制,每个处于非ETHARP_STATE_EMPTY状态的表现都有生存时间,用ctime成员描述该缓存表项entry定时器的超时时间,若该表项的生存时间超时系统将会删除该表项。最后一个字段是前面网络接口层介绍过的netif结构体指针,在发送数据包时起着至关重要的作用。
2.3 ARP数据包描述
前面介绍ARP缓存表的生成是靠ARP请求与应答数据包实现的,下面介绍下ARP数据包的组织结构,由于ARP数据包是被封装在以太网帧中发送的,所以下图也列出了以太网帧首部(前篇网络接口层介绍过):
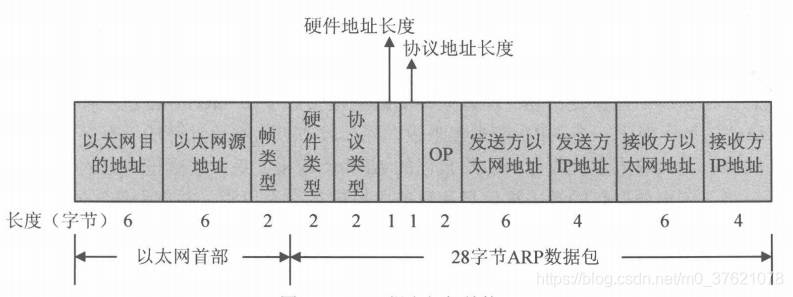
以太网首部这里就不再介绍了,ARP数据包中硬件类型字段表示发送方想要知道的硬件接口类型,对于以太网MAC地址该类型值为1;协议类型字段表示要映射的协议地址类型,若要映射为IP地址该类型值为0x0800(与以太网帧首部的帧类型字段使用相同的一组值)。硬件地址长度字段对于以太网MAC地址该长度值为6,协议地址字段对于ARP协议表示IP地址的长度,由于ARP协议只适用于IPv4,不能用于IPv6(IPv6使用ICMPv6中的邻居探索消息替代ARP协议的功能),所以该协议长度值为4。
操作字段OP指出ARP数据包的类型,它们可以是ARP请求(值为1)、ARP应答(值为2)、RARP请求(值为3)、RARP应答(值为4)。剩余的四个字段比较好理解就不解释了,ARP数据包的描述如下:
// rt-thread\components\net\lwip-1.4.1\src\include\netif\etharp.h
#ifndef ETHARP_HWADDR_LEN
#define ETHARP_HWADDR_LEN 6
#endif
PACK_STRUCT_BEGIN
struct eth_addr {
PACK_STRUCT_FIELD(u8_t addr[ETHARP_HWADDR_LEN]);
} PACK_STRUCT_STRUCT;
PACK_STRUCT_END
PACK_STRUCT_BEGIN
/** Ethernet header */
struct eth_hdr {
PACK_STRUCT_FIELD(struct eth_addr dest);
PACK_STRUCT_FIELD(struct eth_addr src);
PACK_STRUCT_FIELD(u16_t type);
} PACK_STRUCT_STRUCT;
PACK_STRUCT_END
PACK_STRUCT_BEGIN
/** the ARP message, see RFC 826 ("Packet format") */
struct etharp_hdr {
PACK_STRUCT_FIELD(u16_t hwtype);
PACK_STRUCT_FIELD(u16_t proto);
PACK_STRUCT_FIELD(u8_t hwlen);
PACK_STRUCT_FIELD(u8_t protolen);
PACK_STRUCT_FIELD(u16_t opcode);
PACK_STRUCT_FIELD(struct eth_addr shwaddr);
PACK_STRUCT_FIELD(struct ip_addr2 sipaddr);
PACK_STRUCT_FIELD(struct eth_addr dhwaddr);
PACK_STRUCT_FIELD(struct ip_addr2 dipaddr);
} PACK_STRUCT_STRUCT;
PACK_STRUCT_END
#define SIZEOF_ETH_HDR 14
#define SIZEOF_ETHARP_HDR 28
#define SIZEOF_ETHARP_PACKET (SIZEOF_ETH_HDR + SIZEOF_ETHARP_HDR)
/** 5 seconds period */
#define ARP_TMR_INTERVAL 5000
#define ETHTYPE_ARP 0x0806U
#define ETHTYPE_IP 0x0800U
/** ARP message types (opcodes) */
#define ARP_REQUEST 1
#define ARP_REPLY 2
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
上面定义的数据结构都使用了宏PACK_STRUCT_FIELD来禁止编译器的字节自动对齐,因为我们需要使用结构体中的字段去直接操作数据包中的数据,而数据包中的数据都是以字节方式对齐的,若编译器改变了对齐方式会造成严重问题,所以网络数据包中常使用该宏来禁止编译器字节字对齐。
2.4 ARP层数据处理函数
ARP缓存表的操作主要是缓存表的建立、查询与更新,缓存表项的建立或更新需要ARP请求/应答数据包的发送与接收,下面先给出ARP层数据处理的总流程图示:
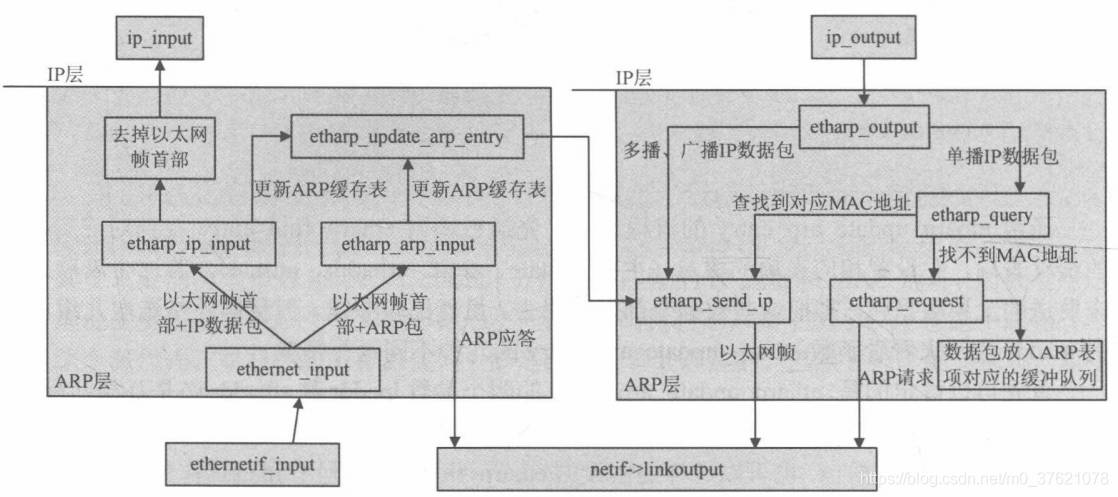
由上面的流程图可以看出,ARP表项查询通过函数etharp_query完成,如果查询不到某表项则通过etharp_request发送ARP请求包,待通过etharp_arp_intput接收到ARP应答包后,将获得的缓存表项信息通过etharp_update_arp_entry更新到缓存表中。相关的操作函数与功能描述如下:
| 操作函数 | 功能描述 |
|---|---|
| err_t etharp_output(struct netif *netif, struct pbuf *q, ip_addr_t *ipaddr) | 发送一个IP数据包到目的IP地址处,根据IP 地址类型调用相应的处理函数递交数据包; |
| err_t etharp_query(struct netif *netif, ip_addr_t *ipaddr, struct pbuf *q) | 根据单播IP地址查询ARP缓存表获得对应的 MAC地址,如果查得MAC地址则将该数据包 发送出去,否则发送一个ARP请求包; |
| err_t etharp_request(struct netif *netif, ip_addr_t *ipaddr) | 构建一个ARP请求包并以MAC广播发送出去; |
| static s8_t etharp_find_entry(ip_addr_t *ipaddr, u8_t flags) | 根据IP地址查询匹配的ARP表项或建立一个 新的表项; |
| static err_t etharp_send_ip(struct netif *netif, struct pbuf *p, struct eth_addr *src, struct eth_addr *dst) | 填写以太网帧首部,调用网卡注册的数据包 发送函数; |
| err_t ethernet_input(struct pbuf *p, struct netif *netif) | 校验接收到的数据包,并根据帧类型调用相应 的处理函数递交数据包; |
| static void etharp_arp_input(struct netif *netif, struct eth_addr *ethaddr, struct pbuf *p) | 处理ARP数据包,更新ARP缓存表,对ARP 请求包进行应答; |
| static void etharp_ip_input(struct netif *netif, struct pbuf *p) | 使用接收到的源IP与源MAC更新ARP缓存表项; |
| static err_t etharp_update_arp_entry( struct netif *netif, ip_addr_t *ipaddr, struct eth_addr *ethaddr, u8_t flags) | 更新ARP缓存表项,如果一个表项从pending 状态变为stable状态,将其后的缓冲数据包发 送出去; |
| static void etharp_free_entry(int i) | 释放指定的ARP缓存表项; |
| void etharp_tmr(void) | 定期删除生存时间超时的缓存表项; |
| err_t etharp_add_static_entry(ip_addr_t *ipaddr, struct eth_addr *ethaddr) | 添加一个新的静态ARP缓存表项; |
| err_t etharp_remove_static_entry(ip_addr_t *ipaddr) | 移除一个静态ARP缓存表项; |
| void etharp_cleanup_netif(struct netif *netif) | 清除指定网卡接口上的所有ARP缓存表项; |
2.5 ARP攻击
这里大家可能会发现ARP协议有一个很大的漏洞,如果网络中的所有用户都规规矩矩,按照上述流程使用ARP协议就不会存在任何问题。但当某些主机收到一个ARP请求后(ARP请求是以广播方式发送的,局域网内所有用户都能收到),它不管请求包中的IP地址与本地地址是否相符,都会产生一个ARP应答包,告诉请求的用户本主机的MAC地址就是你请求的目的IP匹配的MAC地址,由于发送ARP请求的源主机不具备任何容错、认证功能,它会直接把ARP应答数据加入到自己的ARP缓存表项中。源主机在以后都会将具有该目的IP地址的数据包发送到这个伪装主机上,这些伪装主机能轻松实现数据的窃取,这就是ARP攻击的基本原理。
ARP攻击通过伪装IP地址和MAC地址实现ARP欺骗,能够在网络中产生大量的ARP通信量使网络阻塞,攻击者只要持续不断地发出伪造的ARP响应包,就能更改目标主机ARP缓存表项。ARP木马病毒只需感染一台主机,就可能导致整个局域网都无法上网,严重的甚至可能带来整个网络的瘫痪。
怎么防御ARP攻击呢?最有效也是最笨的方法就是采用静态ARP缓存表,即在程序初始化时将可信任的IP和MAC地址对固定写入到ARP缓存表中,但这种方法违背了ARP动态地址解析的原则,使用上受到很大的限制。
IPv6不再使用ARP协议,转而使用ICMPv6中的邻居探索消息替代ARP协议的功能,但在应对IP与MAC伪装攻击方面并没有明显改进。在IPv4中是ARP欺骗,到了IPv6中换为了NA(Neighbor Advertisement)欺骗,攻击原理类似,使用时仍需要注意防御可能的欺骗攻击。
三、IP协议
IP协议在发包之前并不需要建立与对端目标地址之间的连接,上层如果遇到需要发送给IP层的数据,该数据会立即被压缩成IP包发送出去,所以IP层是面向无连接的,只提供尽力服务(Best Effort,为了把数据包发送到目标地址,尽最大努力),自身并不做最终收到与否的验证。IP数据包在途中可能会发生丢包、错位以及数据量翻倍等问题,为了提供通信的可靠性,上层传输层中的TCP协议提供了面向连接的可靠通信服务,IP层只需要专注完成自身的寻址送达任务即可。
3.1 IP分片与路径MTU发现
前面介绍了数据包的寻址转发原理,但数据包在从一个主机送达另一个主机的过程中,需要经过很多数据链路,不同数据链路的最大传输单元MTU(Maximum Transmission Unit)不尽相同,如果要想在数据链路上正确传输,就不能超过其MTU的限制。鉴于IP层属于数据链路上一层,它必须不受限于不同数据链路的MTU大小,所以IP层提供了针对不同数据链路对IP报文进行分割与重组的能力,以便能将数据报分割为不超过相应MTU的大小进行有效传输。下面列出各种数据链路及其MTU大小供参考:
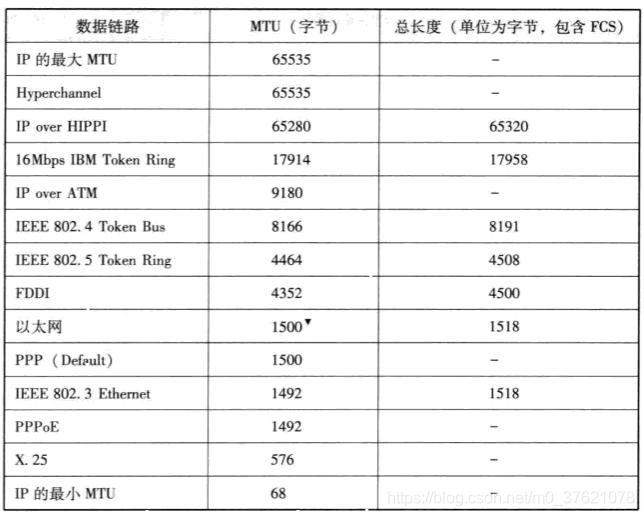
如果IP数据包经过路由器转发到另一个MTU更小的数据链路上,需要路由器对数据包再分片才能继续转发,所以IPv4首部包含了便于IP分片重组的字段,但会增大路由器的处理负荷并降低网络的利用率。随着人们对网络安全和传输速度要求的提高,路由器需要处理的任务也越来越多,可以避免让路由器承担IP数据包分片任务吗?为此产生了一种新技术”路径MTU发现“(Path MTU Discovery),也即发现从发送端主机到接收端主机之间不需要分片时最大MTU的大小(路径中存在的所有数据链路中最小的MTU)。路径MTU发现过程如下图示:
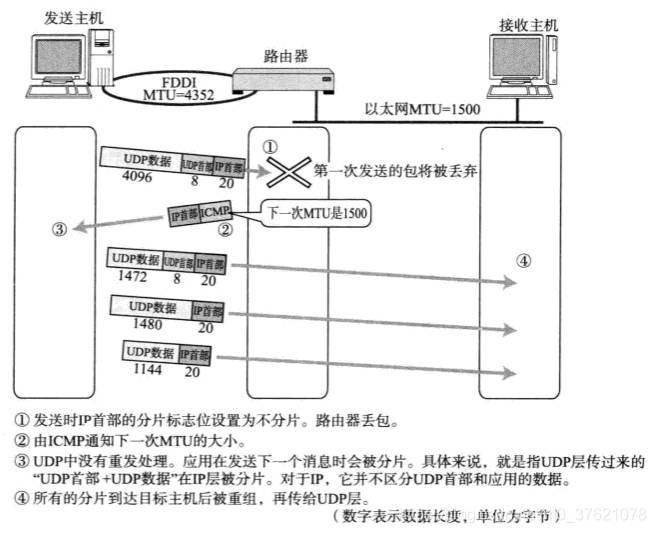
上图以UDP数据包的发送为例说明路径MTU发现过程,换成TCP数据包情况类似。使用路径MTU发现功能后,IP数据包只需要在源主机必要时分片,到达目的主机后再重组为完整IP数据包,经过中间路由器时只需要转发,不需要再进行分片处理,提高了转发速率和网络利用率。
在IPv6首部直接取消了跟数据包分片与重组的字段,所以IPv6中的”路径MTU发现“功能是必不可少的,IPv6的分片处理也只能在发送端主机上进行,路由器不参与分片。不过IPv6中最小MTU为1280字节(IPv4中最小MTU为68字节),在资源受限的嵌入式系统中不需要进行”路径MTU发现“,直接在发送IP包时以1280字节分片发出。
3.2 IPv4数据报描述
通过IP进行通信时,需要在数据前加入IP首部信息,正如通过数据链路通信时需要链路帧首部信息一样。IP首部中包含了用于IP协议进行发包控制时所有的必要信息,了解IP首部结构能对IP所提供的功能有一个详细的把握。IPv4数据报的格式如下图示:
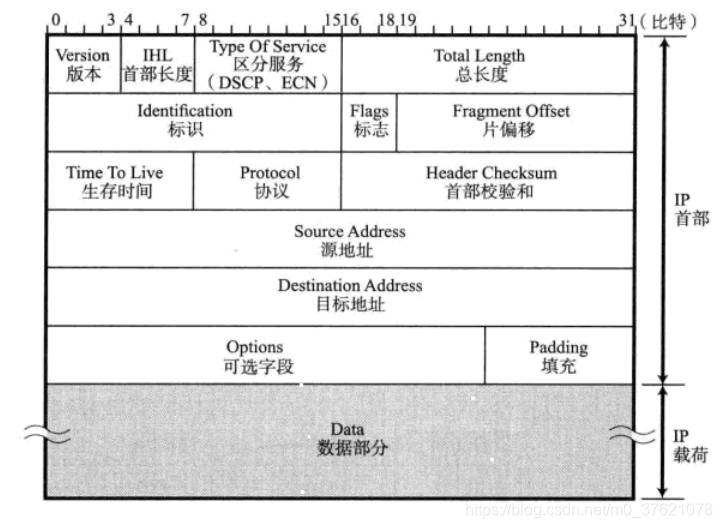
版本Ver字段标识IP首部的版本号信息,IPv4的版本号为4,IPv6的版本号为6。首部长度(IHL: Internet Header Length)表明首部大小,以4字节为单位,对于没有可选项的IP包首部长度则设置为5(4*5 = 20字节)。TOS字段表明服务质量(优先度、最低延迟、最大吞吐、最大可靠性、最小代价、最大安全等),但因实现TOS控制及其复杂目前几乎所有的网络都无视了该字段;有人提议将该字段分为DSCP(Differentiated Services Code Point)段与ECN(Explicit Congestion Notification)段进行质量控制。总长度TL字段表示IP首部与数据部分合起来的总字节数,因该字段长16比特,故IPv4包最大长度为65535字节。
标识ID字段用于分片重组,同一个分片的标识值相同,不同分片的标识值不同。片偏移FO用来标识被分片的每一个分段相对于原始数据的位置,因其有13位最多可表示8192个相对位置,以8字节为单位,最大可表示原始数据8*8192 = 65535字节的位置。标志Flags表示包被分片的相关信息,每一位含义如下图示:

生存时间TTL字段指可以中转多少个路由,每经过一个路由器该值减1,TTL减为0时丢弃该包。协议Protocol字段表示IP包传输层的上层协议编号,常用的协议如下表示:
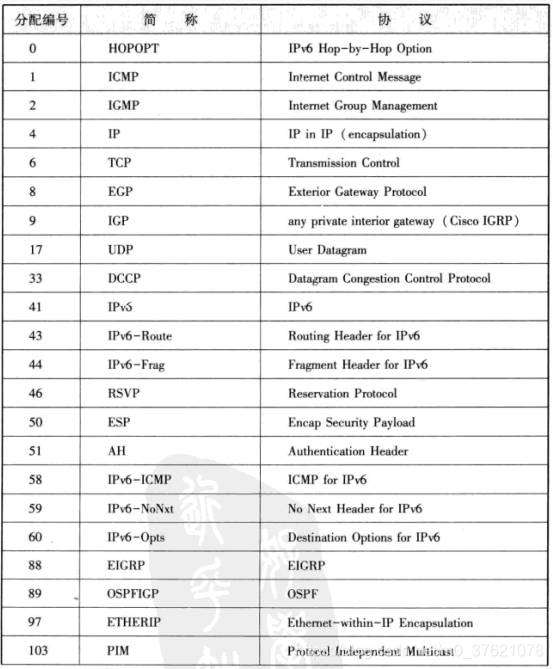
首部校验和HC只校验数据报的首部,不校验数据部分,主要用于确保IP数据报首部不被破坏,校验和采用二进制反码求和。源地址表示发送端IP地址,目的地址表示接收端IP地址。可选项包含安全级别、源路径、路径记录、时间戳等信息,通常只在进行实验或诊断时使用。填充项则为了将首部长度调整为32比特的整数倍。数据部分是实际要发送的数据,IP协议上层的首部也作为数据进行处理。在LwIP中描述IPv4的数据结构如下:
// rt-thread\components\net\lwip-1.4.1\src\include\ipv4\lwip\ip.h
PACK_STRUCT_BEGIN
struct ip_hdr {
/* version / header length */
PACK_STRUCT_FIELD(u8_t _v_hl);
/* type of service */
PACK_STRUCT_FIELD(u8_t _tos);
/* total length */
PACK_STRUCT_FIELD(u16_t _len);
/* identification */
PACK_STRUCT_FIELD(u16_t _id);
/* fragment offset field */
PACK_STRUCT_FIELD(u16_t _offset);
#define IP_RF 0x8000U /* reserved fragment flag */
#define IP_DF 0x4000U /* dont fragment flag */
#define IP_MF 0x2000U /* more fragments flag */
#define IP_OFFMASK 0x1fffU /* mask for fragmenting bits */
/* time to live */
PACK_STRUCT_FIELD(u8_t _ttl);
/* protocol*/
PACK_STRUCT_FIELD(u8_t _proto);
/* checksum */
PACK_STRUCT_FIELD(u16_t _chksum);
/* source and destination IP addresses */
PACK_STRUCT_FIELD(ip_addr_p_t src);
PACK_STRUCT_FIELD(ip_addr_p_t dest);
} PACK_STRUCT_STRUCT;
PACK_STRUCT_END
typedef struct ip_addr ip_addr_t;
struct ip_addr {
u32_t addr;
};
#define IPH_V(hdr) ((hdr)->_v_hl >> 4)
#define IPH_HL(hdr) ((hdr)->_v_hl & 0x0f)
#define IPH_TOS(hdr) ((hdr)->_tos)
#define IPH_LEN(hdr) ((hdr)->_len)
#define IPH_ID(hdr) ((hdr)->_id)
#define IPH_OFFSET(hdr) ((hdr)->_offset)
#define IPH_TTL(hdr) ((hdr)->_ttl)
#define IPH_PROTO(hdr) ((hdr)->_proto)
#define IPH_CHKSUM(hdr) ((hdr)->_chksum)
#define IPH_VHL_SET(hdr, v, hl) (hdr)->_v_hl = (((v) << 4) | (hl))
#define IPH_TOS_SET(hdr, tos) (hdr)->_tos = (tos)
#define IPH_LEN_SET(hdr, len) (hdr)->_len = (len)
#define IPH_ID_SET(hdr, id) (hdr)->_id = (id)
#define IPH_OFFSET_SET(hdr, off) (hdr)->_offset = (off)
#define IPH_TTL_SET(hdr, ttl) (hdr)->_ttl = (u8_t)(ttl)
#define IPH_PROTO_SET(hdr, proto) (hdr)->_proto = (u8_t)(proto)
#define IPH_CHKSUM_SET(hdr, chksum) (hdr)->_chksum = (chksum)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
IP数据报首部结构体依然使用PACK_STRUCT_FIELD禁止编译器自对齐,为了方便获取或设置IP首部相应字段的值,定义了一系列的宏如上面的代码所示,宏变量hdr为指向IP首部结构ip_hdr型变量的指针。
3.3 IPv4数据报操作函数
IP层数据报的处理任务并不复杂,除了前面介绍的IP数据报的分片重组外,主要是IP数据报的接收、发送、转发等操作,数据包处理函数的调用关系图(传输层以UDP协议为例)如下:
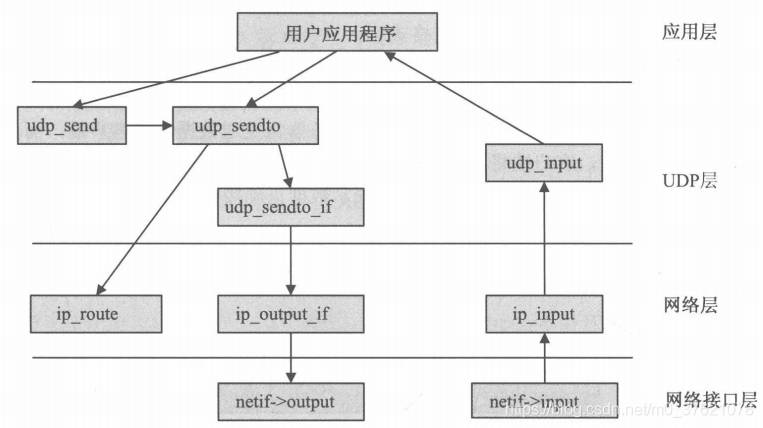
IPv4主要的操作函数如下表示:
| 操作函数 | 功能描述 |
|---|---|
| err_t ip_output(struct pbuf *p, ip_addr_t *src, ip_addr_t *dest, u8_t ttl, u8_t tos, u8_t proto) | 被上层传输层协议调用以发送数据报,该函数先 通过ip_route查找网络接口,再调用ip_output_if 完成数据报的发送; |
| struct netif *ip_route(ip_addr_t *dest) | 根据目的IP地址选择一个最合适的网路接口 (即与目的IP处于同一子网); |
| err_t ip_output_if(struct pbuf *p, ip_addr_t *src, ip_addr_t *dest, u8_t ttl, u8_t tos, u8_t proto, struct netif *netif) | 填写IP首部中的各个字段值,并发送数据报, 如果数据报太大则需分片发送; |
| u16_t inet_chksum(void *dataptr, u16_t len) | 计算校验和并取反码; |
| static u16_t lwip_standard_chksum( void *dataptr, int len) | 对数据区域数据进行16bit求和,返回网络字节序 的16bit结果; |
| err_t ip_frag(struct pbuf *p, struct netif *netif, ip_addr_t *dest) | 将数据报p进行分片发送; |
| err_t ip_input(struct pbuf *p, struct netif *inp) | 处理收到的IP数据报,如果为分片数据报则进行重组, 根据IP首部记录的协议类型字段递交给相应的上层协议 处理函数; |
| struct pbuf * ip_reass(struct pbuf *p) | 重装IP分片数据报; |
| void ip_reass_tmr(void) | 定时释放生存时间超时的重装结构体及其后挂接的数据 分片; |
| static void ip_forward(struct pbuf *p, struct ip_hdr *iphdr, struct netif *inp) | 将数据包p通过合适的接口转发出去。 |
下面以ip_output与ip_input函数为例,简单看下IP数据报是如何发送出去的,又是如何将接收到的数据报递交给上层的:
// rt-thread\components\net\lwip-1.4.1\src\core\ipv4\ip.c
err_t ip_output(struct pbuf *p, ip_addr_t *src, ip_addr_t *dest,
u8_t ttl, u8_t tos, u8_t proto)
{
struct netif *netif;
if ((netif = ip_route(dest)) == NULL) {
return ERR_RTE;
}
return ip_output_if(p, src, dest, ttl, tos, proto, netif);
}
struct netif *ip_route(ip_addr_t *dest)
{
struct netif *netif;
/* iterate through netifs */
for (netif = netif_list; netif != NULL; netif = netif->next) {
/* network mask matches? */
if (netif_is_up(netif)) {
if (ip_addr_netcmp(dest, &(netif->ip_addr), &(netif->netmask))) {
/* return netif on which to forward IP packet */
return netif;
}
}
}
if ((netif_default == NULL) || (!netif_is_up(netif_default))) {
return NULL;
}
/* no matching netif found, use default netif */
return netif_default;
}
err_t ip_output_if(struct pbuf *p, ip_addr_t *src, ip_addr_t *dest,
u8_t ttl, u8_t tos, u8_t proto, struct netif *netif)
{
struct ip_hdr *iphdr;
/* Should the IP header be generated or is it already included in p? */
if (dest != IP_HDRINCL) {
u16_t ip_hlen = IP_HLEN;
/* generate IP header */
if (pbuf_header(p, IP_HLEN)) {
return ERR_BUF;
}
iphdr = (struct ip_hdr *)p->payload;
IPH_TTL_SET(iphdr, ttl);
IPH_PROTO_SET(iphdr, proto);
/* dest cannot be NULL here */
ip_addr_copy(iphdr->dest, *dest);
IPH_VHL_SET(iphdr, 4, ip_hlen / 4);
IPH_TOS_SET(iphdr, tos);
IPH_LEN_SET(iphdr, htons(p->tot_len));
IPH_OFFSET_SET(iphdr, 0);
IPH_ID_SET(iphdr, htons(ip_id));
++ip_id;
if (ip_addr_isany(src)) {
ip_addr_copy(iphdr->src, netif->ip_addr);
} else {
/* src cannot be NULL here */
ip_addr_copy(iphdr->src, *src);
}
IPH_CHKSUM_SET(iphdr, 0);
IPH_CHKSUM_SET(iphdr, inet_chksum(iphdr, ip_hlen));
} else {
/* IP header already included in p */
iphdr = (struct ip_hdr *)p->payload;
ip_addr_copy(dest_addr, iphdr->dest);
dest = &dest_addr;
}
if (ip_addr_cmp(dest, &netif->ip_addr)) {
/* Packet to self, enqueue it for loopback */
return netif_loop_output(netif, p, dest);
}
/* don't fragment if interface has mtu set to 0 [loopif] */
if (netif->mtu && (p->tot_len > netif->mtu)) {
return ip_frag(p, netif, dest);
}
return netif->output(netif, p, dest);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
前两个函数比较简单,函数功能已经在上表介绍过了,从IP层发送数据包到数据链路层主要是靠函数ip_output_if实现的。ip_output_if的作用主要也是将数据包pbuf的payload指针移到IP首部,开始填充IP首部中的各字段值,最后发送数据分三种情况处理:如果目的IP是本网卡地址则调用环回输出函数(在前篇网络接口层介绍过netif_loop_output);如果数据报太大则调用ip_frag函数对数据报分片发送;剩下的情况直接调用接口注册的output函数(即网卡驱动接口函数)发送数据报。下面再介绍下从网络接口层传送到IP层的数据包如何处理:
// rt-thread\components\net\lwip-1.4.1\src\core\ipv4\ip.c
err_t ip_input(struct pbuf *p, struct netif *inp)
{
struct ip_hdr *iphdr;
struct netif *netif;
u16_t iphdr_hlen;
u16_t iphdr_len;
/* identify the IP header */
iphdr = (struct ip_hdr *)p->payload;
if (IPH_V(iphdr) != 4) {
pbuf_free(p);
return ERR_OK;
}
/* obtain IP header length in number of 32-bit words */
iphdr_hlen = IPH_HL(iphdr);
/* calculate IP header length in bytes */
iphdr_hlen *= 4;
/* obtain ip length in bytes */
iphdr_len = ntohs(IPH_LEN(iphdr));
/* header length exceeds first pbuf length, or ip length exceeds total pbuf length? */
if ((iphdr_hlen > p->len) || (iphdr_len > p->tot_len)) {
/* free (drop) packet pbufs */
pbuf_free(p);
return ERR_OK;
}
/* verify checksum */
if (inet_chksum(iphdr, iphdr_hlen) != 0) {
pbuf_free(p);
return ERR_OK;
}
/* Trim pbuf. This should have been done at the netif layer,
* but we'll do it anyway just to be sure that its done. */
pbuf_realloc(p, iphdr_len);
/* copy IP addresses to aligned ip_addr_t */
ip_addr_copy(current_iphdr_dest, iphdr->dest);
ip_addr_copy(current_iphdr_src, iphdr->src);
/* match packet against an interface, i.e. is this packet for us? */
{
/* start trying with inp. if that's not acceptable, start walking the
list of configured netifs.
'first' is used as a boolean to mark whether we started walking the list */
int first = 1;
netif = inp;
do {
/* interface is up and configured? */
if ((netif_is_up(netif)) && (!ip_addr_isany(&(netif->ip_addr)))) {
/* unicast to this interface address? */
if (ip_addr_cmp(¤t_iphdr_dest, &(netif->ip_addr)) ||
/* or broadcast on this interface network address? */
ip_addr_isbroadcast(¤t_iphdr_dest, netif)) {
/* break out of for loop */
break;
}
}
if (first) {
first = 0;
netif = netif_list;
} else {
netif = netif->next;
}
if (netif == inp) {
netif = netif->next;
}
} while(netif != NULL);
}
/* broadcast or multicast packet source address? Compliant with RFC 1122: 3.2.1.3 */
{ if ((ip_addr_isbroadcast(¤t_iphdr_src, inp)) ||
(ip_addr_ismulticast(¤t_iphdr_src))) {
/* free (drop) packet pbufs */
pbuf_free(p);
return ERR_OK;
}
}
/* packet not for us? */
if (netif == NULL) {
/* non-broadcast packet? */
if (!ip_addr_isbroadcast(¤t_iphdr_dest, inp)) {
/* try to forward IP packet on (other) interfaces */
ip_forward(p, iphdr, inp);
}
pbuf_free(p);
return ERR_OK;
}
/* packet consists of multiple fragments? */
if ((IPH_OFFSET(iphdr) & PP_HTONS(IP_OFFMASK | IP_MF)) != 0) {
/* reassemble the packet*/
p = ip_reass(p);
/* packet not fully reassembled yet? */
if (p == NULL) {
return ERR_OK;
}
iphdr = (struct ip_hdr *)p->payload;
}
if (iphdr_hlen > IP_HLEN) {
pbuf_free(p);
return ERR_OK;
}
current_netif = inp;
current_header = iphdr;
/* raw input did not eat the packet? */
if (raw_input(p, inp) == 0)
{
switch (IPH_PROTO(iphdr)) {
case IP_PROTO_UDP:
udp_input(p, inp);
break;
case IP_PROTO_TCP:
tcp_input(p, inp);
break;
case IP_PROTO_ICMP:
icmp_input(p, inp);
break;
case IP_PROTO_IGMP:
igmp_input(p, inp, ¤t_iphdr_dest);
break;
default:
/* send ICMP destination protocol unreachable unless is was a broadcast */
if (!ip_addr_isbroadcast(¤t_iphdr_dest, inp) &&
!ip_addr_ismulticast(¤t_iphdr_dest)) {
p->payload = iphdr;
icmp_dest_unreach(p, ICMP_DUR_PROTO);
}
pbuf_free(p);
}
}
current_netif = NULL;
current_header = NULL;
ip_addr_set_any(¤t_iphdr_src);
ip_addr_set_any(¤t_iphdr_dest);
return ERR_OK;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
函数ip_input内容看似比较多,主要也是数据校验与分类递交的工作。首先根据IP首部数据校验IP首部版本、长度、校验和、源地址是否为单播IP地址等信息,然后根据目的地址是否与本机IP匹配,如果目的地址与本机IP不匹配则根据情况转发数据报(广播地址不转发),如果该IP数据报分片标志置位则需进行数据报重组。如果通过了上述所有校验,则根据首部中协议类型字段,调用相应的上层协议数据包输入函数将IP数据报递交给对应的上层协议继续处理,如果找不到上层协议则向源主机返回目的不可达ICMP报文(下一篇将会介绍ICMP原理与实现)。这里还有一个raw_input函数,使用这个函数可以让应用程序直接读取IP层中的数据报,这点与BSD中提供的RawSocket(原始套接字)编程功能类似,下一篇介绍ICMP报文实现时会给出raw_input实现代码。
3.4 IPv6数据报描述
IPv6的IP数据报首部格式相比IPv4发生了很大变化:IPv6为了减轻路由器负担,省略了首部校验和字段,由于路由器不再需要计算校验和提高了包转发效率;分片重组处理相关的字段成为可选项;为了便于64位CPU处理数据更方便,IPv6首部及可选项长度都是8字节即64比特的整数倍(IPv4首部及可选字段长度都是4字节即32比特整数倍)。IPv6数据报的格式如下图示:
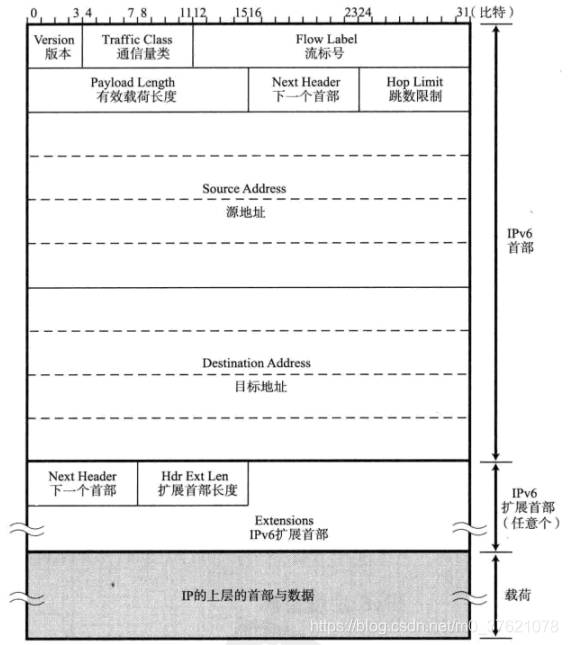
IPv6的版本号字段为6。通信量类(Traffic Class)字段相当于IPv4的TOS(Type Of Service)字段,属于保留字段。流标号(Flow Label)准备用于服务质量QoS(Quality Of Service)控制,不使用QoS时每一位可以全部设置为0,在进行QoS控制时将流标号设置为一个随机数,然后利用一种可以设置流的协议RSVP(Resource Reservation Protocol)在路由器上进行QoS设置,只有流标号、源地址与目标地址三项完全一致时才被认为是一个流。
IPv6有效载荷长度(Payload Length)类似于IPv4的总长度(指包含首部在内的所有长度),但IPv6的有效载荷长度不包括首部,只表示数据部分的长度。下一个首部(Next Header)相当于IPv4中的协议字段,通常表示IP的上一层协议类型,当有IPv6扩展首部时表示后面第一个扩展首部的协议类型。跳数限制(Hop Limit)相当于IPv4中的TTL字段,为了强调可通过路由器个数而重新取名的。源地址表示发送端IP地址,目的地址表示接收端IP地址,都由128比特即16字节构成。
IPv6的首部长度固定,无法将可选项加入其中,通过扩展首部对功能进行有效扩展。扩展首部常介于IPv6首部与TCP/UDP首部中间,可以连续使用多个扩展首部没有长度限制(IPv4中可选项长度固定为40字节),使用多个扩展首部的IPv6数据报结构如下图示:
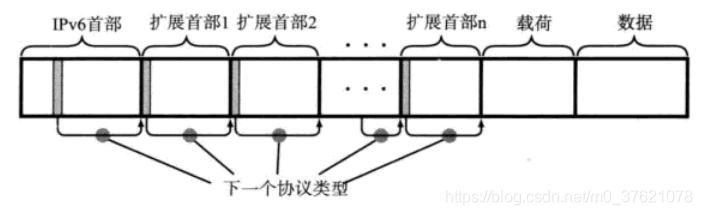
IPv6常用的扩展首部如下表示:
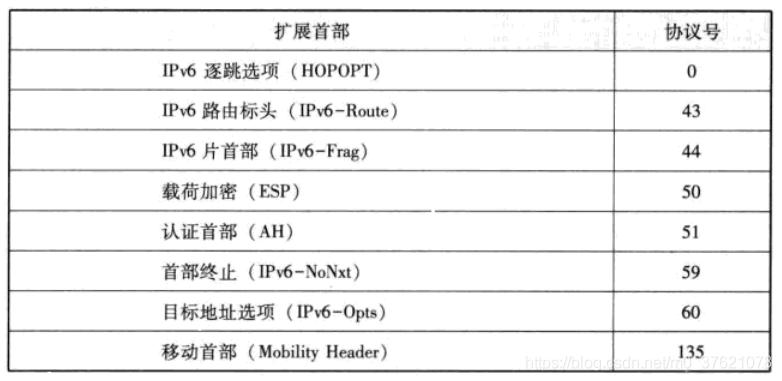
当需要对IPv6数据报进行分片时,可以添加扩展首部协议号44;使用IPsec(Internet Protocol Security,比如用于构建VPN: Virtual Private Network)时可以使用协议号50/51的ESP(Encapsulated Security Payload)与AH(Authentication Header);Mobile IPv6(常用于移动通信中当主机所连接子网IP发生变化时,主机IP仍保持不变以维持原通信不发生中断)的情况下可以采用协议号60/135的目标地址选项与移动首部。在LwIP中描述IPv6的数据结构如下:
// rt-thread\components\net\lwip-1.4.1\src\include\ipv6\lwip\ip.h
/* The IPv6 header. */
struct ip_hdr {
#if BYTE_ORDER == LITTLE_ENDIAN
u8_t tclass1:4, v:4;
u8_t flow1:4, tclass2:4;
#else
u8_t v:4, tclass1:4;
u8_t tclass2:8, flow1:4;
#endif
u16_t flow2;
u16_t len; /* payload length */
u8_t nexthdr; /* next header */
u8_t hoplim; /* hop limit (TTL) */
struct ip_addr src, dest; /* source and destination IP addresses */
};
PACK_STRUCT_BEGIN
struct ip_addr {
PACK_STRUCT_FIELD(u32_t addr[4]);
} PACK_STRUCT_STRUCT;
PACK_STRUCT_END
#define IPH_PROTO(hdr) (iphdr->nexthdr)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
IPv6的结构体相比IPv4更简单些,其中PACK_STRUCT_FIELD禁止编译器自对齐,宏变量hdr为指向IP首部结构ip_hdr型变量的指针。
3.5 IPv6数据报操作函数
IPv6的数据报处理函数跟IPv4差不多,没有专门的分片重组操作了,主要是IPv6数据报的接收、发送、转发等操作,数据包处理函数的调用关系依然可以参考IPv4中的图示,IPv6主要的操作函数如下表示:
| 操作函数 | 功能描述 |
|---|---|
| err_t ip_output(struct pbuf *p, struct ip_addr *src, struct ip_addr *dest, u8_t ttl, u8_t proto) | 被上层传输层协议调用以发送数据报,该函数先 通过ip_route查找网络接口,再调用ip_output_if 完成数据报的发送; |
| struct netif *ip_route(struct ip_addr *dest) | 根据目的IP地址选择一个最合适的网路接口 (即与目的IP处于同一子网); |
| err_t ip_output_if(struct pbuf *p, struct ip_addr *src, struct ip_addr *dest, u8_t ttl, u8_t proto,struct netif *netif) | 填写IP首部中的各个字段值,并发送数据报; |
| void ip_input(struct pbuf *p, struct netif *inp) | 处理收到的IP数据报,根据IP首部记录的协议 类型字段递交给相应的上层协议处理函数; |
| static void ip_forward(struct pbuf *p, struct ip_hdr *iphdr) | 将数据包p通过合适的接口转发出去。 |
评论记录:
回复评论: