
简介与效果
用python3+opencv3做的中国车牌识别,包括算法和客户端界面,只有2个文件,一个是界面代码,一个是算法代码,点击即可出结果,方便易用!
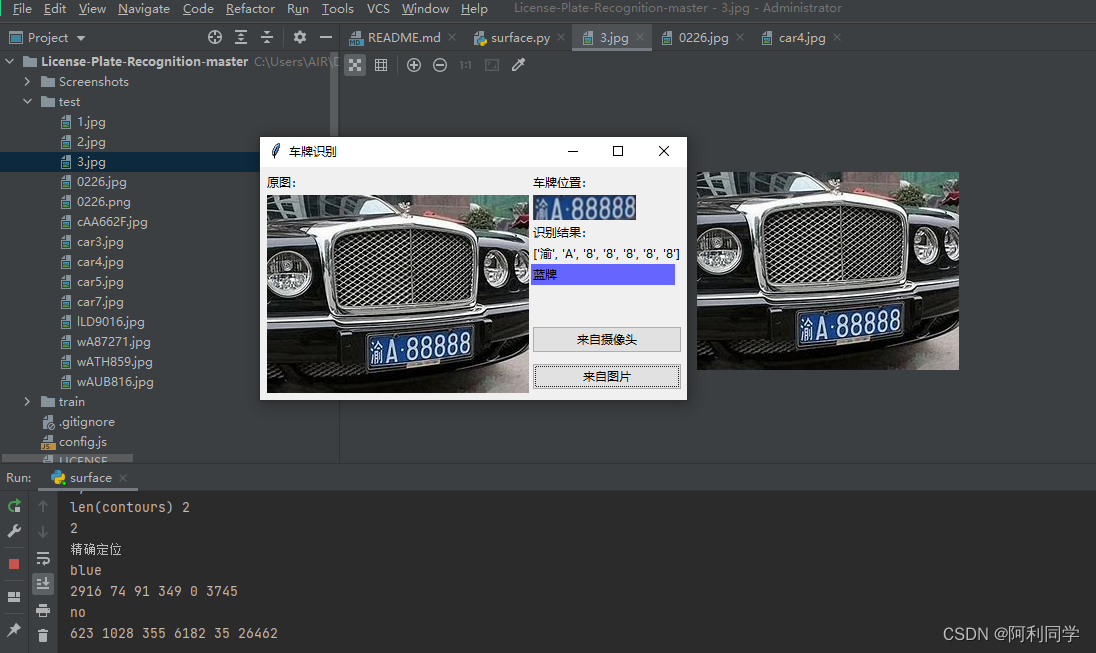
大致的UI界面如下,点击输入图片,右侧即可出现结果!
环境依赖
依赖库:非常容易安装:
版本:python3.4.4,opencv3.4和numpy1.14和PIL5
算法实现
算法思想来自于网上资源,先使用图像边缘和车牌颜色定位车牌,再识别字符。车牌定位在predict方法中,为说明清楚,完成代码和测试后,加了很多注释,请参看源码。
车牌字符识别也在predict方法中,请参看源码中的注释,需要说明的是,车牌字符识别使用的算法是opencv的SVM, opencv的SVM使用代码来自于opencv附带的sample,StatModel类和SVM类都是sample中的代码。
SVM训练使用的训练样本来自于c++版本。由于训练样本有限,你测试时会发现,车牌字符识别,可能存在误差,尤其是第一个中文字符出现的误差概率较大。
源码中,我上传训练样本,在train\目录下,如果要重新训练请解压在当前目录下,并删除原始训练数据文件svm.dat和svmchinese.dat
代码
额外说明:算法代码只有500行,测试中发现,车牌定位算法的参数受图像分辨率、色偏、车距影响(test目录下的车牌的像素都比较小,
--->qq 1309399183----------<代码交流
def from_pic(self):
self.thread_run = False
self.pic_path = askopenfilename(title="选择识别图片", filetypes=[("jpg图片", "*.jpg")])
if self.pic_path:
img_bgr = predict.imreadex(self.pic_path)
self.imgtk = self.get_imgtk(img_bgr)
self.image_ctl.configure(image=self.imgtk)
resize_rates = (1, 0.9, 0.8, 0.7, 0.6, 0.5, 0.4)
for resize_rate in resize_rates:
print("resize_rate:", resize_rate)
r, roi, color = self.predictor.predict(img_bgr, resize_rate)
if r:
break
#r, roi, color = self.predictor.predict(img_bgr, 1)
self.show_roi(r, roi, color)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
touch.me --->q1309399183----------<交流
- 1
处理具体流程

最终结果

其他图片很可能因为像素等问题识别不了,识别其他像素的车牌需要修改config文件里面的参数,此项目仅是抛砖引玉,提供一个思路)。
全部代码:可关注我进行私信或者上述方式交流!!!

代码获取/论文辅导/作业帮助
 QQ名片
QQ名片
QQ名片

评论记录:
回复评论: