
1.概念
独立成分分析是从多元(多维)统计数据中寻找潜在因子或成分的一种方法.ICA与其它的方法重要的区别在于,它寻找满足统计独立和非高斯的成分。这里我们简要介绍ICA的基本概念、应用和估计原理。
1.1 多元数据的线性表示
统计数据处理及相关领域中的一个重要和需要长期研究的问题就是,寻找多元数据一个恰当的表示,使得人们可以获得给定数据的本质特征或者使得数据的结构可视化。
在神经计算领域中,这个基本问题也就是非监督学习(unsupervised learning)问题,因为这种表示是从数据本身学习得来的,即给定某个数据集作为神经网络的输入,在没有导师的情况下,通过神经网络学习得到数据的本质特征.这种数据表示问题是数据挖掘、特征提取和信号处理的核心问题。
为了更为清楚的说明这个问题,假设我们已经获得了m维的观测数据集xi(t),其中{i=1,…,m及t=1,…,T,这里t表示观测样本点的个数,m和t的数目可以非常之大.我们可以提出这样一个问题:通过怎样的一个映射,使得m维数据空间变换到另一个n维数据空间,使得变换后的变量能够揭示观测数据的某些信息,而这些信息是隐藏在原始的大规模数据中的.变换后的变量就是所谓的“因子”或者是“成分”,能够描述数据的本质特征.
在绝大多数的例子中,我们仅考虑线性变换,这样不仅使表示的解释简单,计算上也简单易行.这样,每一个成分yi可以表示为观测变量的线性组合:
其中Wij(i=1,…,n,j=1,…,m)是某些常系数,这些系数就定义了这个线性表示.因此可以看出,为了得到数据yi的线性表示,必须求出未知系数Wij.简单起见,这种数据的表示可写成矩阵的形式:
在统计的框架下,问题转化为通过成分yi的某些统计特性来求解系数矩阵W。
选择矩阵W的一个统计原理是限制成分yi的个数相当之少,也许只有1或2,寻找矩阵W以便成分尽可能的包含原始数据的信息.这导致统计技术如主成分分析(principal component analysis,PCA)、因子分析(factor analysis,FA)的出现,它们是进行统计数据处理、特征提取、数据压缩等比较经典的技术。寻找矩阵W的另一个统计原理是统计独立性:假设成分yi之间是统计独立的.这意味着其中一个成分没有受到另一个成分的任何影响,成分之间没有任何信息传递.在因子分析中,经常声称因子之间是统计独立的,这个说法只是部分正确,因为因子分析假设因子是服从高斯分布的,找到独立的方法相当容易(对于高斯分布的成分来说,不相关与独立是等价的)。
而在现实世界中,数据通常并不服从高斯分布,假设成分服从高斯分布的方法在这种情况下是失效的.例如,许多真实世界的数据集是服从超高斯分布的(supergaussian).这意味着随机变量更经常的在零附近取值,与相同方差的高斯密度相比,超高斯分布在零点更尖!
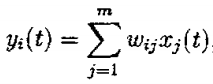
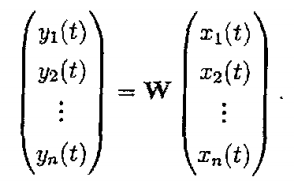
评论记录:
回复评论: