
目录
- 原理示意图
- Cache(高速缓存)的详细介绍
- 写缓冲器的介绍
- 重要概念:主存(内存)中的数据除了可以被 CPU 修改,也可能被其他硬件或设备修改
- pgprot_* 系列函数的详细介绍
- **1. `pgprot_cached`**
- **2. `pgprot_noncached`**
- **3. `pgprot_writecombine`**
- **4. `pgprot_device`**
- **5. `pgprot_writethrough`**
- **6. `pgprot_writeback`**
- **7. `pgprot_none`**
- **8. `pgprot_exec`**
- **9. `pgprot_user`**
- **10. `pgprot_kernel`**
- **11. `pgprot_modify`**
- **12. `pgprot_val` 和 `__pgprot`**
- **总结:缓存模式与实时性对比**
- 非缓存模式和设备内存模式的区别
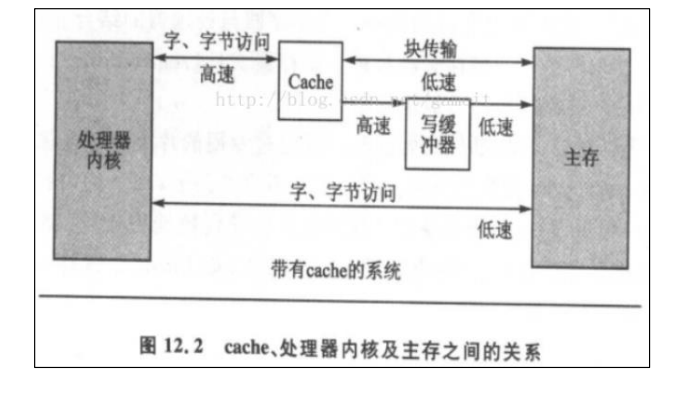
原理示意图
Cache 和 写缓冲器 是 CPU 的核心组成部分,属于 CPU 微架构设计的一部分。
下图是CPU核心、Cache(高速缓存)、写缓冲器、主存之间的关系。
Cache(高速缓存) 相当于是一块高速内存;写缓冲器相当于一个 FIFO,可以把多个写操作集合起来一次写入内存。
Cache(高速缓存)的详细介绍
Cache(高速缓存)的概要介绍
Cache 是 CPU 内部(或者在某些情况下,靠近 CPU 的芯片上)的一种高速存储器,用来存储近期访问的数据或指令的副本。
- 特性:
- Cache 通常分为多级(L1、L2、L3),L1 最靠近 CPU,速度最快,但容量最小。
- Cache 数据通常以缓存行(Cache Line)为单位存储和管理。
- 通过保持数据的局部性(时间局部性和空间局部性)来提高性能。
Cache(高速缓存)的读操作原理和流程
- 当 CPU 需要访问内存中的某块数据时,会首先检查 Cache 中是否有该数据(称为 Cache 命中)。
- 如果数据命中,则直接从 Cache 中读取,速度远高于从主内存读取。
- 如果数据未命中(Cache Miss),则需要从主存(RAM)中加载数据,同时可能更新 Cache。
Cache(高速缓存)的写操作原理和流程
在启用了 Cache 的情况下,写数据通常会遵循以下流程:数据优先写入 Cache,然后根据 Cache 的策略再写入主存(内存)。以下是主要的写策略策的工作原理。
1. Write-Through(写直达)
- 工作原理:
- 数据被写入 Cache 的同时,立即写入主存(内存)。
- Cache 和主存始终保持同步。
- 优点:
- 数据一致性较高,主存始终是最新的数据。
- 如果发生 Cache Miss,主存的数据仍然是有效的。
- 缺点:
- 写操作速度较慢,因为每次写入都需要同时更新主存,无法充分利用 Cache 的性能。
- 适用场景:
- 对数据一致性要求较高的场景。
2. Write-Back(写回)
- 工作原理:
- 数据只写入 Cache,并标记该 Cache Line 为“已修改”(Dirty)。
- 数据不会立即写入主存,只有在以下情况之一时才会写回主存:
- 该 Cache Line 被替换(即被新的数据占用时)。
- 主动使用指令或操作(如
flush)将数据刷新到主存。
- 优点:
- 写操作效率更高,因为减少了对主存的直接写入次数。
- 对多个连续写操作,可以在 Cache 中合并,从而提高性能。
- 缺点:
- 数据一致性较难维护,主存中的数据可能是旧的。
- 如果系统崩溃或电源中断,可能会导致 Cache 中的数据丢失。
- 适用场景:
- 对性能要求高且能容忍一定数据一致性延迟的场景。
3. Write Combining(写合并)
- 工作原理:
- 对多个连续的写操作进行合并,在写缓冲器中批量写入主存。
- 通常用于图像处理、DMA 传输等场景。
- 优点:
- 减少主存写操作次数,提高总的写性能。
- 缺点:
- 数据一致性依赖于合并策略,可能会引入延迟。
- 适用场景:
- 高吞吐量、低数据一致性要求的场景,如硬件设备缓冲区。
写数据的典型流程(以 Write-Back 为例)
-
写入 Cache:
- CPU 通过 Cache Controller 将数据存储到 Cache 中。
- 如果目标地址的 Cache Line 已存在(命中),更新对应的数据。
- 如果未命中,先从主存加载目标地址的 Cache Line,再写入新的数据。
-
标记 Dirty:
- 更新 Cache Line 的标志位,标记为“已修改”(Dirty)。
-
延迟写回:
- 数据不会立即写入主存。
- 当 Cache Line 被替换或需要刷新的时候,Cache Controller 会将 Dirty 数据写回主存。
数据一致性问题
由于数据在 Cache 和主存之间可能存在延迟写入,所以可能会导致以下问题:
-
数据一致性问题:
- 如果 CPU 或设备访问的是主存而不是 Cache,可能读取到旧数据。
- 多核 CPU 或其他硬件设备共享同一内存区域时,需要特别处理一致性。
-
解决方法:
- 内存屏障(Memory Barrier):
- 强制确保在屏障之前的所有操作完成后,才执行屏障之后的操作。
- Cache 刷新(Cache Flush):
- 使用指令(如
clflush)将 Cache 数据强制写回主存。
- 使用指令(如
- 禁止 Cache:
- 对某些关键内存区域(如设备寄存器),可以禁用 Cache 或使用 Non-Cached 模式。
- 内存屏障(Memory Barrier):
总结
启用 Cache 后,写数据是先写入 Cache,然后再根据策略写入主存。具体的写行为取决于 Cache 策略(Write-Through、Write-Back 或 Write Combining):
- Write-Through:实时同步到主存,数据一致性高,但效率较低。
- Write-Back:延迟写回主存,性能更高,但需要注意一致性问题。
- Write Combining:合并写入,适用于连续写操作,但一致性较弱。
写缓冲器的介绍
其实在看了上面的关于Cache(高速缓存)“写合并”策略,就知道了写缓冲器是怎么回事儿了。
重要概念:主存(内存)中的数据除了可以被 CPU 修改,也可能被其他硬件或设备修改
主存中的数据不仅可以被 CPU 修改,还可能通过以下途径被其他设备修改:
- DMA 设备(如硬盘、网卡、GPU 等)。
- 外设映射内存(Memory-Mapped I/O)。
- 多核 CPU。
- GPU。
- 硬件调试工具。
- 虚拟内存系统。
- 网络设备(如 RDMA)。
pgprot_* 系列函数的详细介绍
在搞清楚了Cache(高速缓存)的原理后,再来看pgprot_* 系列函数就要容易得多了。
pgprot_* 系列函数是用来设置内存映射区域的Cache(高速缓存)属性的函数。
以下是 pgprot_* 系列函数的完整介绍,包括每种模式对 数据实时性 的影响:
1. pgprot_cached
- 功能:将内存设置为 缓存模式(Cacheable)。
- 特性:
- 数据会存储在 CPU 缓存中,读取数据和写入数据都通过Cache进行,所以速度较快。
- 存在数据一致性问题,即Cache中的数据和主存中的数据可能不一致。
- 数据实时性:较差,可能存在缓存延迟,不适合实时性要求高的场景。
- 应用场景:普通内存区域,非实时性要求场景。
- 用法:
vma->vm_page_prot = pgprot_cached(vma->vm_page_prot);- 1
2. pgprot_noncached
- 功能:将内存设置为 非缓存模式(Uncacheable)。
- 特性:
- 禁用缓存,每次读取都直接访问物理内存。
- 保证数据的实时一致性。
- 数据实时性:非常高,适合需要确保数据最新的场景。
- 应用场景:设备寄存器映射、DMA 缓冲区等。
- 用法:
vma->vm_page_prot = pgprot_noncached(vma->vm_page_prot);- 1
3. pgprot_writecombine
- 功能:将内存设置为 写合并模式(Write Combine)。
- 特性:
- 写入数据时,CPU 会暂时存储在写缓冲区中,允许合并多次写入以减少内存交互。
- 提高写入效率,但读数据仍直接访问内存。
- 读数据的时候是直接从主存中读取,而不是从Cache中读取。
- 数据实时性:
- 写入:较差,写缓冲区可能导致写入延迟。
- 读取:较高,因为是直接访问主存,而不是从Cache中读取数据,所以读取到值为主存中的最新值,当主存中的值被别的因素更新时,它读取到的值是最新值。
- 应用场景:显存、帧缓冲区等需要高效写入的场景。
- 用法:
vma->vm_page_prot = pgprot_writecombine(vma->vm_page_prot);- 1
4. pgprot_device
- 功能:将内存设置为 设备内存模式(Device Memory)。
- 特性:
- 禁用缓存,确保所有读写操作按顺序执行(强序访问)。
- 适用于设备寄存器或 I/O 操作。
- 数据实时性:非常高,完全禁用缓存,保证操作顺序和实时性。
- 应用场景:设备寄存器、外设的强序访问。
- 用法:
vma->vm_page_prot = pgprot_device(vma->vm_page_prot);- 1
5. pgprot_writethrough
- 功能:将内存设置为 写透缓存模式(Write-Through Cacheable)。
- 特性:
- 写入数据时,会同时更新 CPU 缓存和物理内存。
- 读取操作优先从缓存中获取,提高读取效率。
- 数据实时性:较高,写入实时同步到内存,数据一致性较好。
- 应用场景:需要缓存性能且写入实时性要求高的场景。
- 用法:
vma->vm_page_prot = pgprot_writethrough(vma->vm_page_prot);- 1
6. pgprot_writeback
- 功能:将内存设置为 写回缓存模式(Write-Back Cacheable)。
- 特性:
- 写入数据时,仅更新 CPU 缓存,必要时才将数据写回到内存。
- 最大化写入性能,但数据可能会滞留在缓存中。
- 数据实时性:较差,写回机制可能导致数据更新延迟。
- 应用场景:高性能内存访问,不关心实时性的场景。
- 用法:
vma->vm_page_prot = pgprot_writeback(vma->vm_page_prot);- 1
7. pgprot_none
- 功能:设置内存区域为 无访问权限。
- 特性:
- 禁止对该内存区域的访问(读取、写入或执行)。
- 数据实时性:不适用,因为完全禁止访问。
- 应用场景:保护内存区域、防止非法访问。
- 用法:
vma->vm_page_prot = pgprot_none(vma->vm_page_prot);- 1
8. pgprot_exec
- 功能:设置内存区域为 可执行。
- 特性:
- 允许在该内存区域运行代码。
- 主要用于代码段内存或动态分配的可执行区域。
- 数据实时性:无直接影响,与缓存属性无关。
- 应用场景:执行代码段内存。
- 用法:
vma->vm_page_prot = pgprot_exec(vma->vm_page_prot);- 1
9. pgprot_user
- 功能:设置内存区域为 用户态访问权限。
- 特性:
- 用户态进程可以访问该内存区域。
- 数据实时性:与具体缓存模式相关,无直接影响。
- 应用场景:分配给用户态的内存。
- 用法:
vma->vm_page_prot = pgprot_user(vma->vm_page_prot);- 1
10. pgprot_kernel
- 功能:设置内存区域为 仅内核态访问权限。
- 特性:
- 只有内核态代码可以访问该内存区域。
- 数据实时性:与具体缓存模式相关,无直接影响。
- 应用场景:内核专用的内存区域。
- 用法:
vma->vm_page_prot = pgprot_kernel(vma->vm_page_prot);- 1
11. pgprot_modify
- 功能:修改现有
pgprot_t的缓存属性或权限。 - 特性:
- 动态调整页面的缓存模式或访问权限。
- 数据实时性:取决于修改后的缓存模式。
- 应用场景:需要动态调整内存区域属性时。
- 用法:
vma->vm_page_prot = pgprot_modify(vma->vm_page_prot, new_pgprot);- 1
12. pgprot_val 和 __pgprot
- 功能:
pgprot_val:从pgprot_t获取底层属性值。__pgprot:将属性值转换回pgprot_t。
- 特性:主要用于自定义或调试内存页面属性。
- 数据实时性:与具体的缓存属性无关。
- 应用场景:自定义页面保护或调试。
- 用法:
unsigned long val = pgprot_val(vma->vm_page_prot); vma->vm_page_prot = __pgprot(val | custom_flags);- 1
- 2
总结:缓存模式与实时性对比
| 函数 | 缓存属性 | 数据实时性 | 应用场景 |
|---|---|---|---|
pgprot_cached | 缓存模式 | 较差 | 普通内存访问,高效读取。 |
pgprot_noncached | 非缓存模式 | 非常高 | 设备寄存器或 DMA。 |
pgprot_writecombine | 写合并模式 | 写:较差 读:高 | 显存或帧缓冲区高频写入。 |
pgprot_device | 设备内存模式 | 非常高 | 外设寄存器、I/O 操作。 |
pgprot_writethrough | 写透缓存模式 | 较高 | 实时性较高且需要缓存的场景。 |
pgprot_writeback | 写回缓存模式 | 较差 | 高性能访问,但不关注实时性。 |
pgprot_none | 无访问权限 | 不适用 | 禁止访问的内存区域。 |
pgprot_exec | 可执行权限 | 无直接影响 | 动态分配的代码段或执行内存。 |
pgprot_user | 用户态访问权限 | 无直接影响 | 用户态进程分配的内存。 |
pgprot_kernel | 内核态访问权限 | 无直接影响 | 内核专用内存区域。 |
非缓存模式和设备内存模式的区别
设备内存模式(Device Memory)和非缓存模式(Non-cached Memory)在行为和使用场景上有一定区别,虽然两者都禁止普通缓存行为,但它们的设计目标和底层机制是不同的。以下是两者的区别及特点:
1. 定义和用途
设备内存模式(Device Memory)
- 定义:主要用于映射硬件设备寄存器或内存区域(如 MMIO,Memory-Mapped I/O)。
- 用途:
- 提供严格的访问顺序。
- 确保对设备寄存器的读写操作按预期执行。
- 适用于硬件设备的控制和数据访问。
非缓存模式(Non-cached Memory)
- 定义:内存区域不经过 CPU 的缓存,所有的读写直接访问主存。
- 用途:
- 适合需要频繁与主存交互且对性能要求较低的场景。
- 适用于需要与 DMA 或硬件设备共享内存的场景,确保数据一致性。
2. 缓存行为
设备内存模式
- 无缓存:禁止普通的缓存行为,不能将数据暂存到 CPU 的数据缓存(如 L1、L2 Cache)。
- 强序列化:对设备内存的读写严格按照程序顺序进行,不能被 CPU 或编译器重新排序。
- 读取:每次读取操作都会直接访问设备内存,确保数据是实时的。
- 写入:写入操作通常立即生效,不允许延迟。
非缓存模式
- 无缓存:和设备内存一样,不使用普通的 CPU 数据缓存。
- 弱序列化:允许一定程度的访问重排序(取决于架构和实现),但提供了一些保证:
- 读取:直接从主存读取数据。
- 写入:写入可能会被合并,但不会缓存。
- 通过内存屏障可以强制保证顺序访问。
3. 写入行为
设备内存模式
- 不可写合并(No Write Combining):
- 每次写操作会立即发出到设备。
- 写入行为对设备是完全可见的,每次写入设备都会实时处理。
非缓存模式
- 可能支持写合并(Write Combining):
- 在某些平台上,可以对多个写操作进行合并,提高写性能。
- 需要注意的是,写合并可能导致设备看不到中间状态(即等待合并完成后才写入)。
4. 内存屏障的使用
设备内存模式
- 通常不需要额外的内存屏障,因为设备内存本身已经强制了严格的访问顺序。
非缓存模式
- 可能需要插入内存屏障(如
wmb()和rmb())来保证读写的顺序。 - 例如,在与 DMA 设备交互时,内存屏障可以确保数据在主存中的可见性。
5. 典型应用场景
设备内存模式
- 用于硬件设备寄存器或 MMIO 区域。
- 适合对设备寄存器的严格控制,确保访问顺序和数据的实时性。
- 例如:
- 写入一个寄存器后,立即读取设备状态。
- 网络适配器、GPU、音频控制器等设备的寄存器映射。
非缓存模式
- 用于共享内存区域(例如,CPU 和 DMA 设备之间的内存)。
- 适合对访问顺序要求不高的场景,但需要数据一致性。
- 例如:
- 大量数据传输区域(缓冲区)。
- 视频或音频流的处理。
6. 总结对比
| 特性 | 设备内存模式 | 非缓存模式 |
|---|---|---|
| 缓存行为 | 禁用普通缓存 | 禁用普通缓存 |
| 读写顺序 | 强序列化,严格按程序顺序访问 | 弱序列化,需要屏障确保顺序 |
| 写合并 | 不支持写合并 | 可能支持写合并 |
| 应用场景 | 设备寄存器映射,适合小范围的精确控制 | DMA 或共享内存区域,适合大块数据传输 |
| 内存屏障需求 | 通常不需要 | 需要明确使用内存屏障 |
具体区别分析
- 实时性:设备内存模式优于非缓存模式,因为它确保写入立即生效,读取返回最新值。
- 性能:非缓存模式可能通过写合并优化性能,但实时性较差。
- 复杂性:非缓存模式需要更多手动控制(如屏障),设备内存模式使用更简单。
总结
两者的主要区别在于访问顺序控制和写合并支持。如果你的需求是严格控制硬件设备的行为,应该选择设备内存模式;如果你的需求是高效传输大量数据,同时允许一定程度的顺序优化,可以选择非缓存模式。

 QQ群名片
QQ群名片

评论记录:
回复评论: