
前言
关于为何写此文,说来同样话长啊,历程如下
- 我司LLM项目团队于23年11月份在给一些B端客户做文生图的应用时,对比了各种同类工具,发现DALLE 3确实强,加之也要在论文100课上讲DALLE三代的三篇论文,故此文的2.3节中重点写了下DALLE 3的训练细节:AI绘画与多模态原理解析:从CLIP、BLIP到DALLE 3、Stable Diffusion、MDJ
- 在精读DALLE 3的论文时,发现其解码器用到了Consistency Models
当然,后来OpenAI首届开发者大会还正式发布了这个模型,让我对它越发好奇
- Consistency Models的第一作者宋飏也证实了该模型是DALLE 3的解码器
宋飏不算扩散圈的新人,因为早在2019年,斯坦福一在读博士宋飏和其导师通过此文《Generative Modeling by Estimating Gradients of the Data Distribution》提出了一种新方法来构建生成模型:即不需要估计数据的概率分布(数据概率的分布类似高维曲面),相反,它估计的是分布的梯度(分布的梯度可以看成是高维曲面的斜率)
- 至此,已确定必须得研究下这个「AI绘画神器DALLE 3的解码器:一步生成的扩散模型之Consistency Models」了
且为照顾到不同读者对该模型了解的需求程度,本文会分为三个部分,一步一步、循序渐进、由浅入深,大家可以根据自身的需要重点看到哪一层(有的看到第一层即可,有的则可以看到第二层甚至第三层)
第一层 Consistency Models何以颠覆原来的扩散模型
1.1 什么是Consistency Models
今年5月,OpenAI的Yang Song、Prafulla Dhariwal、Mark Chen、Ilya Sutskever等人提出了Consistency Models,其中一作是华人宋飏(其本毕清华,博毕斯坦福)
- 其在连续时间扩散模型的概率流(PF)常微分方程(ODE)的基础上,其轨迹平滑过渡,将数据分布转化为可处理的噪声分布
- 通过该一致性模型模型,可将任何时间步长的任何点映射到轨迹的起点
比如给定一个可将“数据”转换为“噪声”概率流(PF) ODE,可将ODE轨迹上的任何点「例如,下图中的xtxt ,xt′xt′ 和xT),映射到它的原点(例如,生成建模的x0)」。这些映射的模型被称为一致性模型,因为它们的输出被训练为在同一轨迹上的点(有着一致性)
Given a Probability Flow (PF) ODE that smoothlyconverts data to noise, we learn to map any point (e.g., xt,xt1 , and xT ) on the ODE trajectory to its origin (e.g., x0)for generative modeling. Models of these mappings arecalled consistency models, as their outputs are trained to beconsistent for points on the same trajectory
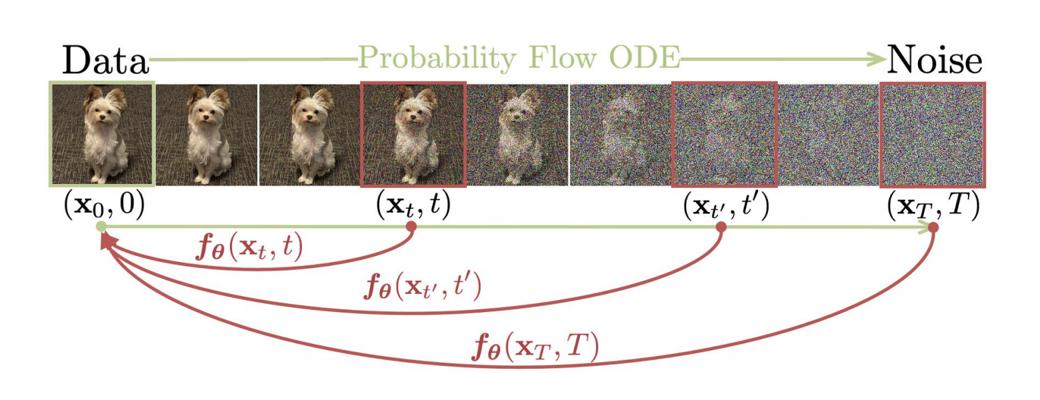
相比扩散模型,它主要有两大优势:
- 其一,无需对抗训练(adversarial training),就能直接生成高质量的图像样本
- 其二,相比扩散模型可能需要几百甚至上千次迭代,一致性模型只需要一两步就能搞定多种图像任务——包括上色、去噪、超分等,都可以在几步之内搞定,而不需要对这些任务进行明确训练(当然,如果进行少样本学习的话,生成效果也会更好)
原理上,一致性模型直接把随机的噪声映射到复杂图像上,输出都是同一轨迹上的同一点,所以实现了一步生成
1.2 Consistency Models的两种训练方法
一致性模型有两种训练方法
- 一种是通过蒸馏预训练扩散模型进行训练(Consistency models canbe trained either by distilling pre-trained diffu-sion models)
即先利用数值ODE求解器和预训练的扩散模型来生成PF ODE轨迹上的相邻点对(The first methodrelies on using numerical ODE solvers and a pre-trained diffusion model to generate pairs of adjacent points on a PF ODE trajectory)
之后通过最小化这些相邻点对的之间的差异,我们可以有效地将扩散模型提炼为一致性模型(这允许通过一次网络评估生成高质量的样本)
By minimizing the difference between model outputs for these pairs, we can effectively distill a diffusion model into a consistency model, which allows generating high-quality samples with one network evaluation - 另外一种,也可以完全作为独立的生成模型进行训练
该方法完全消除了对预训练扩散模型的需要,允许我们单独训练一致性模型。这种方法将一致性模型定位为一个独立的生成模型家族
重要的是,这两种方法都不需要对抗性训练,并且它们都对架构施加了较小的约束,允许使用灵活的神经网络对一致性模型进行参数化
实验结果表明,一致性模型在一步和少步采样方面优于现有的蒸馏技术,如渐进式蒸馏,且当作为独立的生成模型进行训练时,一致性模型可以与现有的一步非对抗生成模型在标准基准测试汇总媲美,如CIFAR-10、ImageNet 64×64和LSUN 256×256
第二层 Consistency Models的推导
2.1 对扩散模型推导的回顾
首先回顾一下diffusion的算法原理
- 假设我们有数据分布 pdata (x) , 扩散模型通过如下的随机微分方程(SDE)对数据分布进行
Let pdata(x) denote the data distribution. Diffusion models start by diffusing pdata(x) with a stochastic differential equation (SDE)
dxt=μ(xt,t)dt+σ(t)dwt
其中,t∈[0,T],T>0是一个固定的常数,μ(Xt,t)是漂移系数,σ(t)是扩散系数,dWt是维纳过程的增量 - 为了通过该式得到一个常微分方程(ODE),需要消除随机项dWt,在某些扩散模型中,比如Score-Based Generative Models,可以使用概率密度函数pt(x)来代替漂移项,进而定义一个无随机项的轨迹,称为ODE轨迹
- 一致性模型的作者宋飏等人推导出,上述 SDE 存在一个ODE形式的解轨迹(ODE trajectory)
dxt=[μ(xt,t)−12σ(t)2∇logpt(xt)]dt
其中∇logpt(x)是 pt(x)的得分函数,而这个得分函数是diffusion model 的直接或者间接学习目标 - 采用 EDM 中的 setting,设置μ(x,t)=0、σ(t)=√2t,训练一个得分模型
sϕ(x,t)≈∇logpt(x)
可将上述 ODE 转为
dxt dt=−tsϕ(xt,t) - 得到 ode 的具体形式后,利用现有的数值 ODE solver,如 Euler, Heun, Lms 等,即可解出 x(.)
当然,考虑到数值精确性,我们往往不会直接求出原图即x(0) ,而是计算出一个x(t−δt),持续这个过程来求出x(0)
// 待更
2.2 Consistency Models 的推导
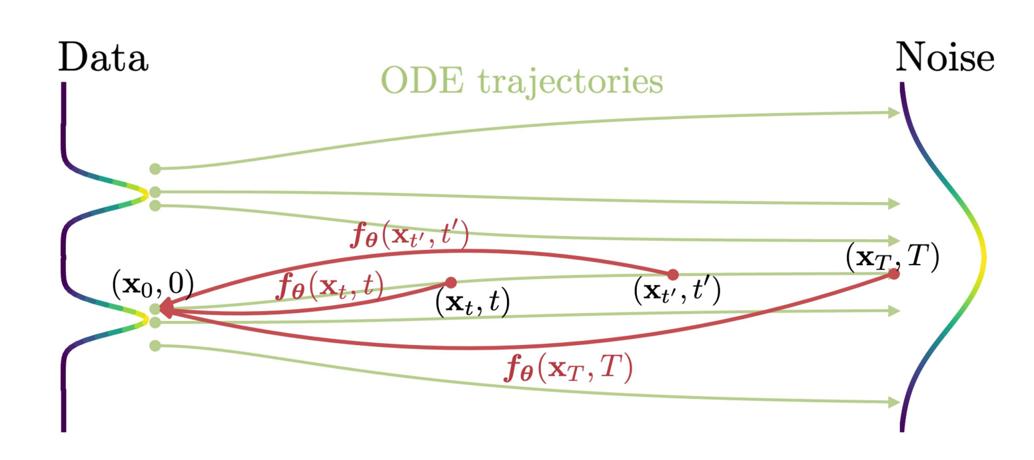
// 待更
第三层 Consistency Models的源码解读
// 待更
参考文献与推荐阅读
- AI绘画能力的起源:从VAE、扩散模型DDPM、DETR到ViT/MAE/Swin transformer
- AI绘画与多模态原理解析:从CLIP、BLIP到DALLE 3、Stable Diffusion、MDJ
- 几篇新闻稿
4.13,OpenAI新生成模型开源炸场!比Diffusion更快更强,清华校友一作
11.9,OpenAI上线新功能太强了,服务器瞬间被挤爆
11.11,OpenAI救了Stable Diffusion!开源Dall·E3同款解码器,来自Ilya宋飏等 - Consistency Models
Yang Song, Prafulla Dhariwal, Mark Chen, Ilya Sutskever - 一步生成的扩散模型:Consistency Models
评论记录:
回复评论: