
点击上方“朱小厮的博客”,选择“设为星标”
后台回复”1024“获取公众号专属1024GB资料

来源:rrd.me/fS8yz
一. 项目思考
由于项目发起了一个抽奖活动,发起活动之前给所有用户发短信提示他们购买了我们的产品有抽奖权益。然后用户上来进入抽奖页面点击爆增,过了一会儿页面就打不开了。后面查看了下各种日志,发现了瓶颈在数据库,由于读写冲突严重,导致响应变慢,有不少连接都超时了。后面看到监控和日志留下的数据,发现负责抽奖的微服务集群qps暴涨12倍,db的qps也涨了10倍。这很明显是一个高并发下如何摆脱数据库读写,I/O瓶颈的问题。
整点开抢后瞬时巨量的请求同时涌入,即使我们Nginx端做过初步限流,整个业务逻辑校验阶段运作良好,但是系统的瓶颈就转移到其他环节:大量的读写请求,导致后面的请求全部排队等待,等前面一个update完成释放行锁后才能处理下一个请求,大量请求等待,占用了数据库的连接。一旦数据库同一时间片内的连接数被打满,就会导致这个时间片内其他后来的全部请求因拿不到连接而超时,导致访问此数据库的其他环节也出现问题,所以RT就会异常飙高
于是我们在思考着怎么优化这个高并发下的抽奖问题
二. 优化思路
听了经验丰富的师兄的经验,也借鉴了下网上的一些思路,能采用的有效措施主要是:降级,限流,缓存,消息队列。主要原则是:尽量不暴露db,把大部分请求在服务的系统上层处理了。
三. 优化细节
1. 抽奖详情页
a. 线上开启缓存
线上已写缓存逻辑,但是没有用switch开启。开启后可以减少数据库的并发IO压力,减少锁冲突。
b. 关于本地缓存淘汰策略的细节处理
缓存超过或等于限制大小全部清空。建议等于时不清空,而使用缓存淘汰算法:比如LRU,LFU,NRU等,这样不会出现缓存过大清空后,从数据库更新数据到缓存,缓存里数据依旧很大。导致缓存清空频率过高,反而降低系统的吞吐量。例如guava cache中的参数是
- //设置缓存容器的初始容量为10
- initialCapacity(10)
- //设置缓存最大容量为100,超过100之后就会按照LRU最近虽少使用算法来移除缓存项
- maximumSize(100)
2. 抽奖逻辑
a.队列削峰
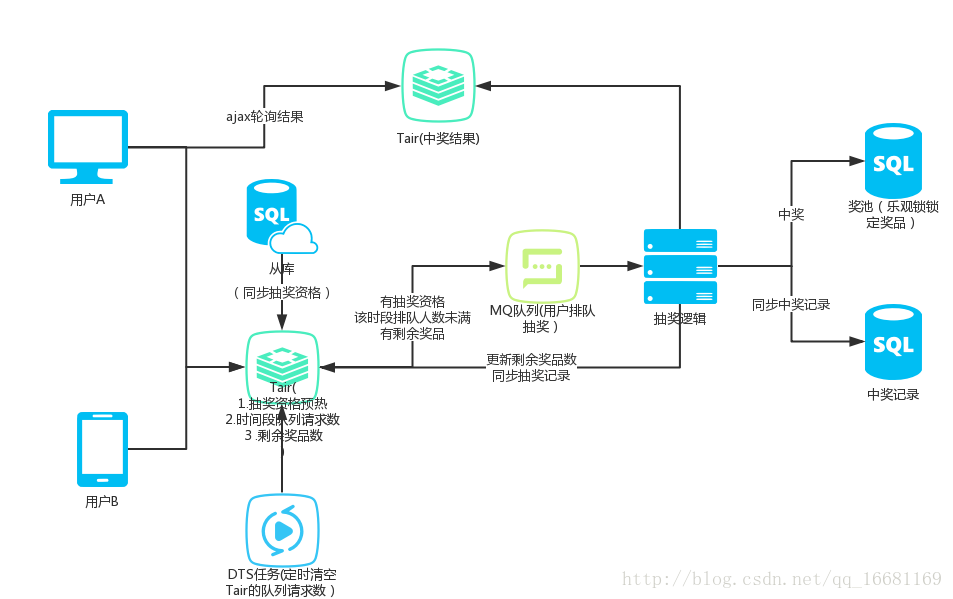
用额外的单进程处理一个队列,下单请求放到队列里,一个个处理,就不会有qps的高并发问题了。场景中抽奖用户会在到点的时间涌入,DB瞬间就接受暴击压力,hold不住就会宕机,然后影响整个业务。队列的长度保持固定,对于如果请求排队在队伍中靠后,比如奖品100个的情况下,中奖率10%,队列里请求任务超过1000时,就直接将后续的抽奖请求返回不中奖。用tair记录排队数,如果奖品没发完,再请空tair,允许请求继续入队列。这样队列起到了降级和削峰的作用。
b.将事务和行级悲观锁改成乐观锁
原来的代码是通过悲观锁来控制超发的情况。(比如一共有100个商品,在最后一刻,我们已经消耗了99个商品,仅剩最后一个。这个时候,系统发来多个并发请求,这批请求读取到的商品余量都是99个,然后都通过了这一个余量判断,最终导致超发。)
在原来的代码中用的是for update行锁,在高并发的情况下会很多这样的修改请求,每个请求都需要等待锁,某些线程可能永远都没有机会抢到这个锁,这种请求就会死在那里。同时,这种请求会很多,瞬间增大系统的平均响应时间,结果是可用连接数被耗尽,系统陷入异常。
可以采用乐观锁,是相对于“悲观锁”采用更为宽松的加锁机制,大都是采用带版本号(Version)更新。实现就是,这个数据所有请求都有资格去修改,但会获得一个该数据的版本号,只有版本号符合的才能更新成功,其他的返回抢购失败。
c.对于与抽奖无直接关系的流程采用异步
比如抽奖成功之后的发短信功能另起一个线程池专门处理。这样可以提高请求的处理速率,提高qps上升后的乘载能力。
d.数据库的读写分离
现在的数据库查询都是读的主库。将数据库的大量查询改为从库,减轻主库的读写压力。主服务器进行写操作时,不影响查询应用服务器的查询性能,降低阻塞,提高并发。
e.同一时间片内,采用信号量机制
确保进来的人数不会过多导致系统响应超时: 信号量的采用,能够使得抽奖高峰期内,同一时间片内不会进入过多的用户,从底层实现上规避了系统处理大数据量的风险。这个可以配合队列进行限流处理。
f. 消息存储机制
将数据请求先添加到信息队列中(比如Tair存储的数据结构中),然后再写工具启动定时任务从Tair中取出数据去入库,这样对于db的并发度大大降低到了定时任务的频率。但是问题可能会出在保持数据的一致性和完整性上。
g.必要时候采用限流降级的测流
当并发过多时为了保证系统整体可用性,抛弃一些请求。对于被限流的请求视为抽不到奖。
3.额外考虑
a.防止黑客刷奖
防止黑客恶意攻击(比如cc攻击)导致qps过高,可以考虑策略在服务入口为相同uid的账户请求限制每秒钟的最高访问数。
b. 中奖数据预热
中奖只是少数,大部分人并不会中奖,所以可以在第一步便限制只有少数用户的请求能够打到真正抽奖逻辑上。是否可以考虑在抽奖之前先用随机算法生成一批中奖候选人。然后当用户请求过来时如果其中绝大多数请求都非中奖候选人,则直接返回抽奖失败,不走抽奖拿奖品的流程。少部分用户请求是中奖候选人,则进入队列,排在队列前面的获得奖品,发完为止,先到先得。
举个例子:10万个用户抽奖,奖品100个,先随机选出中奖候选人500个。用户请求过来时,不走抽奖查库逻辑的用户过滤掉99500个,剩余的候选人的请求用队列处理,先到先得。这样可以把绝大多数的请求拦截在服务上游不用查库,但是缺点是不能保证奖品一定会被抽完(可能抽奖候选人只有不到100人参与抽奖)。
四.设计架构图

想知道更多?扫描下面的二维码关注我

【精彩推荐】
朕已阅 
评论记录:
回复评论: