

文 | ????????????????
编 | 王苏源 | 夕小瑶的卖萌屋
今天介绍的是一篇 NAACL'21 新鲜出炉的工作!NAACL 上周四出的结果,这篇工作本周一上传 arxiv,周二被王苏小哥哥发现,周三拜读了一下,今天就来和大家分享啦!!
给大家提个问题:如果训练样本只有几百条,这时候我们该怎么办呢?
传统的 RNN 在这个样本大小下很难被训练好,自然地,我们会想到使用预训练模型,在其基础上进行 finetune。具体来讲,就是将预训练模型作为模型的底层,在上面添加与当前任务特点相关的网络结构。这样就引入了预训练的知识,对当前任务能产生很大的帮助。

除了预训练的知识,是不是还有其他的信息我们没有用上呢?近年来,越来越多的人在使用另一种 finetune 方法,即结合具体场景,设计新的 finetune 任务形式,从而将与当前任务相关的提示信息(prompt)引入模型。我们大名鼎鼎的 GPT 系列就是这么干的。比如我们拿 GPT3 做 QA 的 finetune,直接喂给他一串“Question:问题内容 Answer:”,剩下的答案部分就让 GPT3 自己填完。

这类 finetune 技巧虽然陆续被使用,但并没有人论证:这种做法相比于传统的 finetune 方法,真的能带来提升吗?如果答案是肯定的,那么究竟能提升多少呢(能否量化这种提升)?
今天这篇来自 Huggingface 的文章就填补了上述两个问题的答案。他们通过大量实验证明:引入提示信息和多标注几百条数据带来的性能提升是相当的!所以,下次老板只给少量样本,就要你 finetune 模型——不要慌!我们今天又多学了一个 trick!
论文题目:
How Many Data Points is a Prompt Worth?
论文链接:
https://arxiv.org/abs/2103.08493
方法
前文提到,这一类 finetune 是将任务对应的输入改写成新的完形填空格式,让模型预测
引入描述集合
本文对这类方法进行了进一步简化:不要求
比如,对于判断题的阅读理解任务,就可以将阅读文本、问题和
小明天天码代码码到天明 [SEP] 小明有女朋友吗?
其中前半部分是阅读文本,后面加粗的部分是问题。模型只需要判断
可能读到这里,大家会疑惑:直接拼起来搞一个 True / False 的二分类不就好了嘛,何必让模型填空呢?嘿嘿,这恰好是作者的用意:通过让模型填空,模型可以习得描述集合中标签文本的语义信息。
引入提示信息
直接拼接是最朴素的,但这能让模型知道自己在做什么任务嘛?为此,作者引入了提示信息(prompt)。
还是判断题的阅读理解任务,对文章
和问题
,作者将他们与一些固定的词进行整合,以此输入模型,让模型预测

没错,就是这么简单!这些固定的词作为提示信息,让模型了解当前在做的任务;同时,提示词文本的含义也对于模型的理解产生了一定的帮助。
除了单选阅读理解,这篇文章还关注了文本蕴含、多选阅读理解、指代销歧等共六个任务。对于不同的任务,有不同的提示信息与输入格式:
对于文本蕴含任务,可以将前提 (premise, ) 与假设 (hyphothesis, ) 通过提示信息整合,作者提出了两种整合方式:

这样就只需要让模型预测
对于指代销歧任务,可以将句子 、带标记的介词 与名词 通过提示信息整合:

这样就只需要让模型预测
其他任务也采用类似的整合方式,感兴趣可以参考原文~
实验
作者发现,这种使用提示信息的整合方式,在低资源的情况下对模型性能有非常大的提升!
比如在阅读理解任务的 BoolQ 数据集上,作者将使用提示信息整合的 finetune 方法与增加一层分类层的 finetune 方法进行了对比。下图是在使用不同数量的样本训练时,模型准确率的对比。
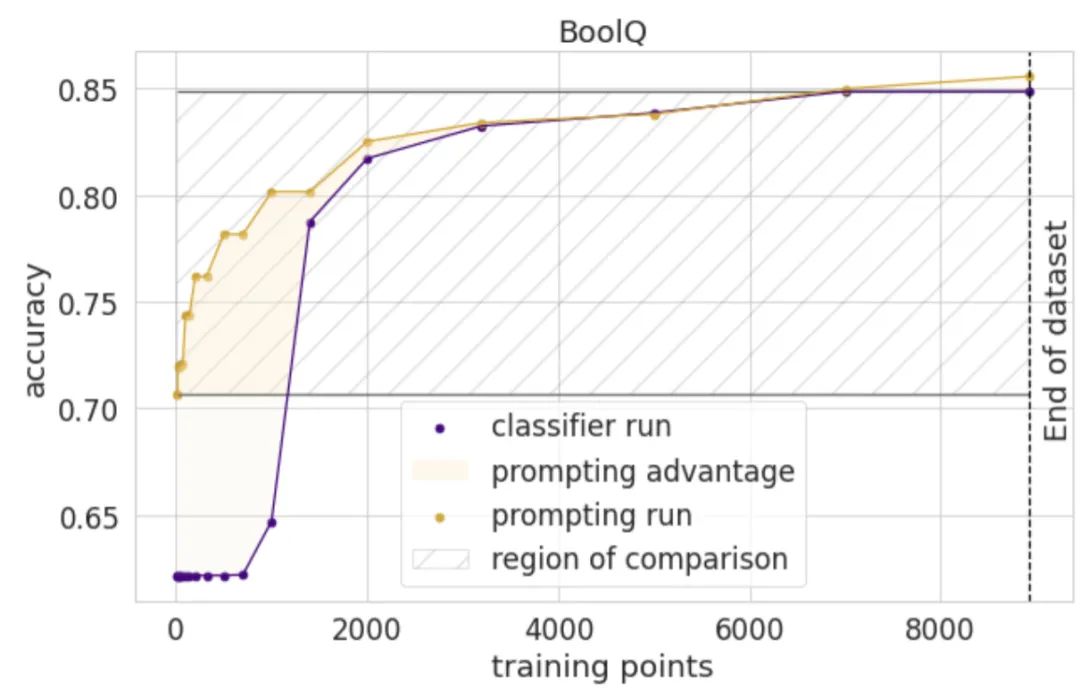
可以发现,在数据量比较小的时候,使用提示信息整合的 finetune 方法(黄色)比增加一层分类层的 finetune 方法(紫色)有更好的表现。
在某些任务上,这种表现的提升是惊人的:
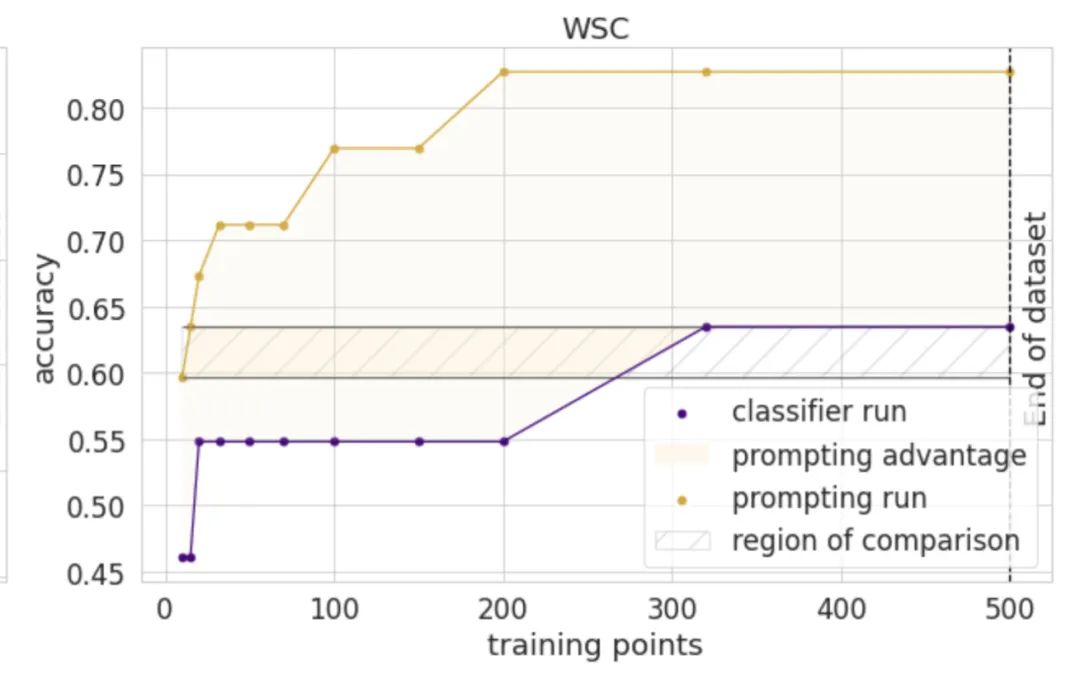
这是在指代销歧任务的 WSC 数据集上的实验结果。在水平方向看,仅使用 25 个样本,就达到传统 fintune 方法使用 300 个样本才能达到的效果!
此外,作者还进行了一系列的消融实验,得到一些有意思的结论:
模型通过预测
属于描述集合中的哪种,以此完成任务。如果将这里改为不带语义的单纯的分类,性能也会有所下降。 作者为每个任务都提供了多种整合提示信息的方式,但是发现,不同方式的区别对性能影响甚微。
总结
这篇文章对基于提示信息的 finetune 方法在进行了大量实验,证明了这类方法在低资源的情况下性能大幅优于传统方法。这种 finetune 的思路应该是可以应用于各类 NLP 下游任务的。尤其是低资源场景下,应该会非常有帮助。如果老板真的只给几百条数据让训练模型,这样的方法说不定就有奇效!
说个正事哈
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心 。
。
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!
评论记录:
回复评论: