
目录
(二)、从业务维度对服务做层次分类:基础服务+通用服务+定制服务+其他服务
一、服务建模切入点一:服务分类
(一)、服务的基本类别:工具服务+实体服务+任务服务
工具服务
代表可重用服务,区别业务模型,特点是业务领域无关,本质是面向技术、具备高可用性的底层处理服务,根据其用途也可以做进一步细分,一般包括以下表现形式:
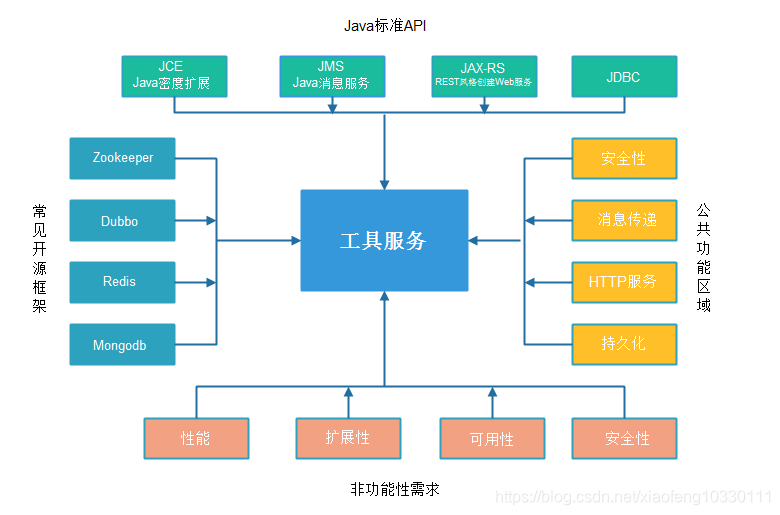
- 公共工具服务:面向多种应用程序,如安全性、记录和审核,通常设计成基于WEB的服务,并开放通用、松散类型接口。
- 资源工具服务:用于封装物理系统资源,如数据存储/消息资源,通常用于底层,使用服务门户暴露入口。
- 微服务工具服务:服务细粒度、高度特性化,如XML加密服务,通常用于本地调用,需要考虑性能、无状态性和线程安全,可以作为JAR包进行直接引用。
- 包装器工具服务:面向遗留系统,建立标准化服务契约,需要明确所支持的数据和消息模型。
实体服务
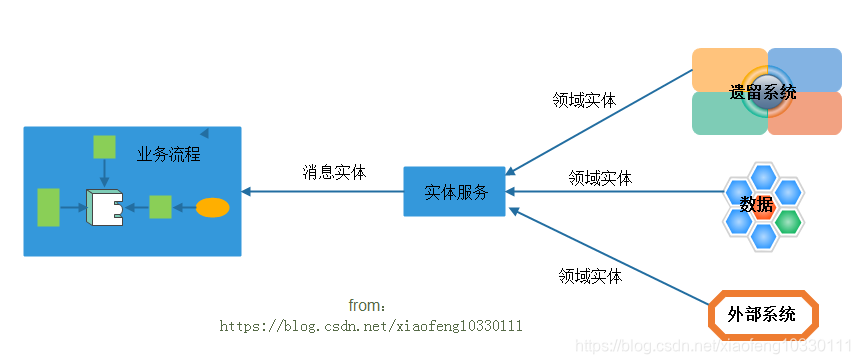
建立一种一致的方法访问和处理业务数据,对应基于业务的功能上下文,侧重于以数据为中心。同样可重用,一般被更高级的任务服务使用,具体包括领域实体和消息实体,领域实体是服务中规范化的业务数据模型,消息实体特定于实体服务契约的数据模型,具体分析如下图:
实体服务的层次讲解:
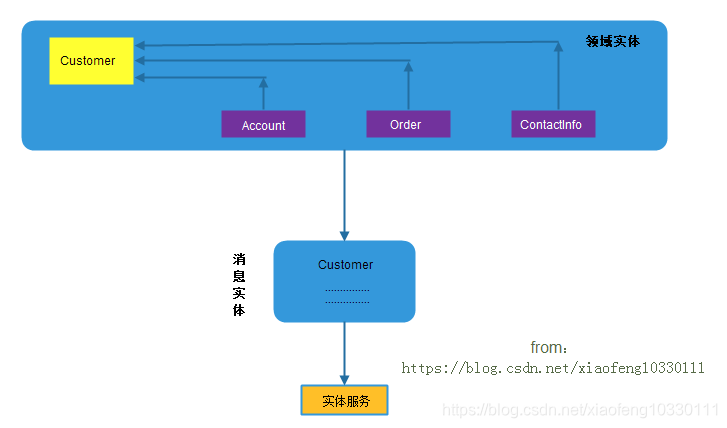
领域实体和消息实体示例讲解:
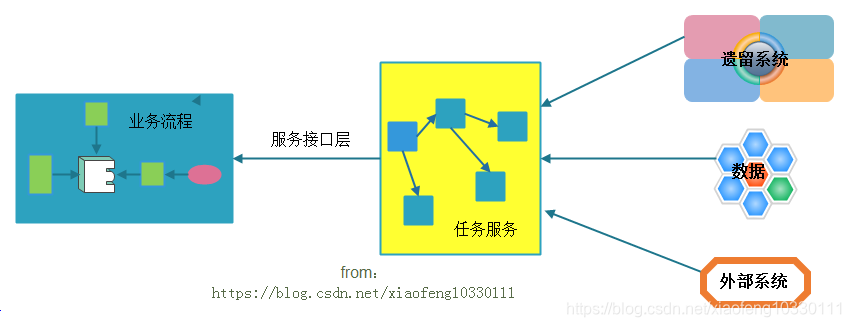
任务服务
关注实现业务相关逻辑,很大程度上有组合逻辑组成,通常需要维护状态,体现为一种组合结构。
总结下:工具服务因为不涉及业务,识别和提取相较另外两种服务而言比较简单。实体服务关注于数据,任务服务关注于业务组合,都需要根据业务本身抽象化。
(二)、从业务维度对服务做层次分类:基础服务+通用服务+定制服务+其他服务
- 基础服务:基础服务往往和技术整合在一起,比较典型的基础服务包括消息服务、路由服务等。
- 通用服务:与基础服务的区别是其完全面向业务,通用性非常高。取决于对业务的抽象程度,包含的内容可以很多,如账号服务、登录服务、通知服务等对于任何一个系统而言都可以认为是一种通用服务。
- 定制服务:定制服务相对而言不应该太多,主要面向外部、面向系统集成类的表现形式。常见的定制服务包括插件服务、外部账号和接口类服务。
- 其他服务:除以上三种类型的服务统称其他服务。
注:通用服务与基础服务区分上可能存在一定难度,可以做一个简单判断:如果一个服务依赖的层次和数量非常多,那么可能更偏向于基础服务,反而更偏向于通用服务。
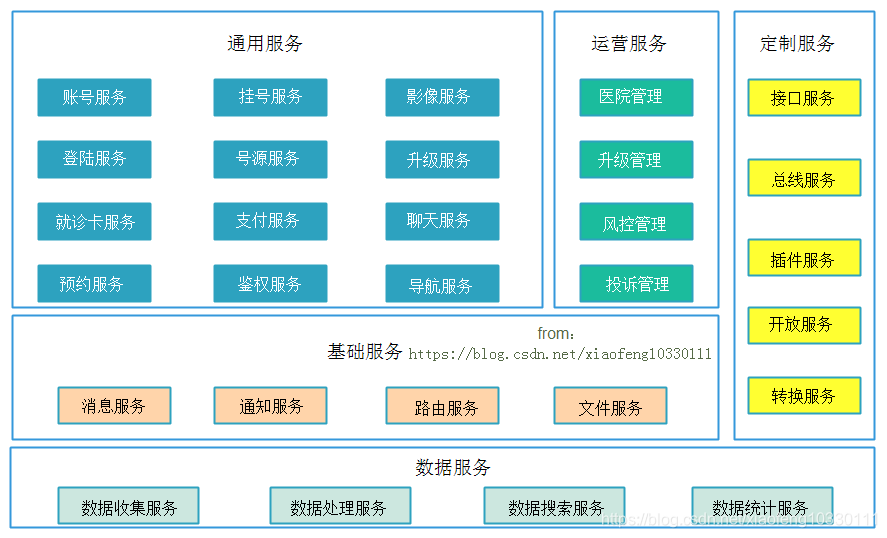
以下列举一个架构服务示例:(移动医疗系统服务架构图)
二、服务建模切入点二:服务模型
(一)、服务的概念模型维度:服务标准+服务级别
服务标准
- 服务无状态:服务应当不需要管理状态信息,因此能够维持送耦合性。服务应该被尽可能设计成无状态,即便意味着要将状态管理移至他处。
- 服务可重用:不管是否存在即时复用的机会,服务均被设计为支持潜在的可复用。
- 服务可发现:服务发布上线后,允许被其他消费者自动发现;当服务提供者下线后,允许消费者接收服务下线通知。
- 服务自治:逻辑由服务所控制,并位于一个清晰的边界内,服务已经在边界内被控制,不依赖其他服务。
- 服务松耦合:服务被设计为功能相对独立,尽量不依赖其他服务的独立功能提供者。
- 服务共享一个标准契约:为了与服务提供者交互,消费者需要导入服务提供者的服务契约。
- 服务是底层逻辑的抽象:只有经服务契约所暴露的服务队外部世界可见,契约之外底层的实现逻辑是不可见的。
服务级别
- 一级服务:具备完善的容错降级机制以及对低级别服务的熔断措施、定期检测、配置高级别的监控告警流程等。
- 二级服务:多采用异步方式进行系统交互,容忍暂时数据不一致性。
- 三级服务:可随时降级整个服务。
(二)、服务统一表现形式:服务契约化+文档服务
1.服务契约化:要求至少对服务的基本方面作出说明包括API、能力、约束、版本四个方面,减少多余及可能反复的口头沟通,降低协助成本。
2.文档服务:Swagger或HAL等文档服务要日常化规范化。
三、服务建模切入点三:服务边界
(一)、识别业务领域及边界:通用语言+子域+聚合
我们可以简单认为,我们所要设计的每一个特定的业务系统就是一个领域。在领域驱动设计中,有两个主要设计维度,即设计的策略维度和设计的技术维度,策略维度偏重于业务架构的梳理以及考虑如何把业务架构和技术架构相结合的问题,设计维度包含集合、领域事件等组件,有助于组织服务内部以及服务与服务之间进行交互的方式。
通用语言
思路是面向领域和业务,促进后续代码模型中的命名等使用领域词汇而不是技术词汇,能够将客户、体验设计师、业务分析师、技术人员集结在一起对业务需求进行沟通,随后对其进行领域划分,这是服务有效识别的前提。
子域
系统拆分的切入点,其来源往往取决于系统的特征和拆分的需求,如核心功能、辅助性功能、第三方功能等,业界将各个子域分成核心子域、支撑子域和通用子域三种:
- 核心业务属于核心子域;
- 专注于业务某一方面的子域属于支撑子域;
- 作为基础设施的功能属于通用子域。
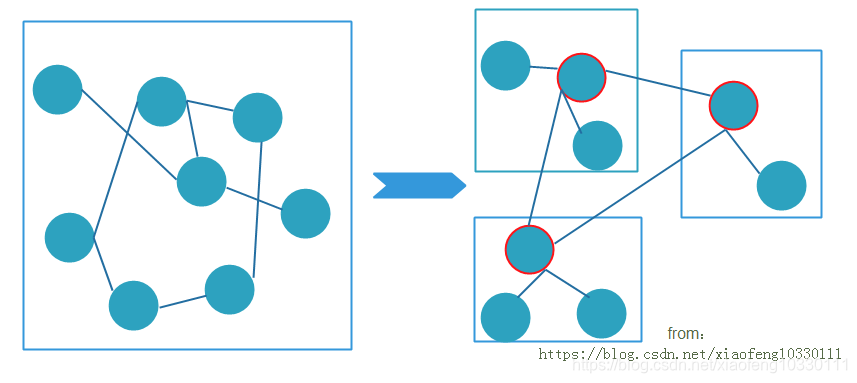
聚合
一个子域包含若干聚合。聚合的核心思想在于将关联降至最少有助于简化对象之间的遍历,使用一个抽象来封装模型中的引用,主要由两部分组成:根实体和边界,只有根对象之间才能直接交互,其他对象只能与该聚合中的根对象进行直接交互,如下图分析:将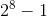 次交互降为
次交互降为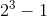 次交互。(聚合示意图)
次交互。(聚合示意图)
(二)、界限上下文:领域与界限上下文+界限上下文集成策略
领域与界限上下文
界限指的是每个模型概念、属性和操作,在特定边界之内具有特定的含义,这些含义只限定在该界限内,界限的划分能在很大程度上影响系统的设计和实现,也为确定服务边界提供了合理性依据。具体举例如下:
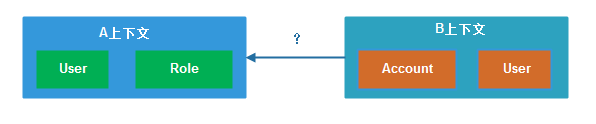
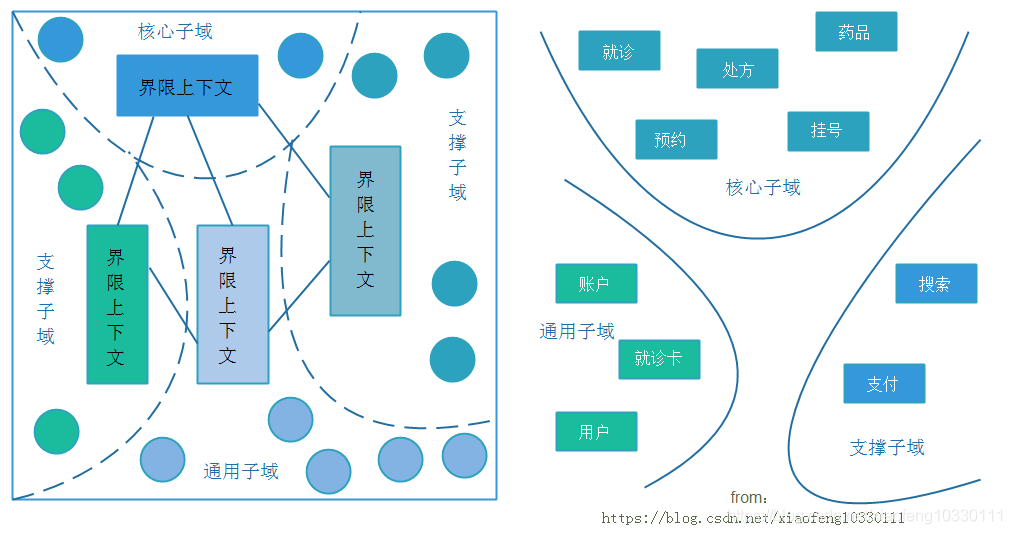
子域、聚合和界限上下文三者之间的关系如下,划分方法如图讲解:(子域、聚合和界限上下文关系及业务流程划分)
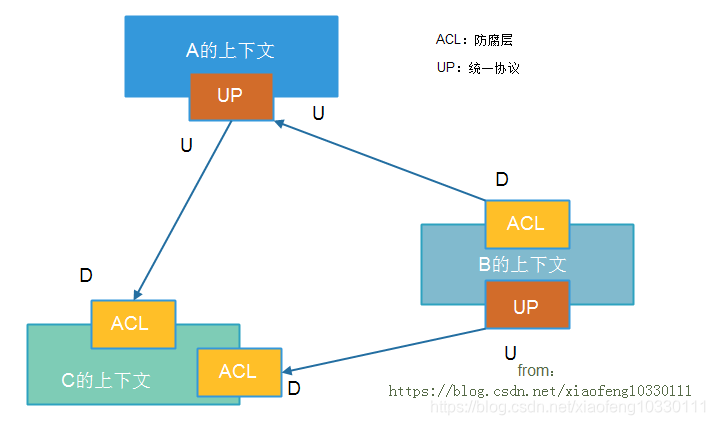
界限上下文集成策略
站在高层次的架构分析角度,任何一个系统都可以处在其他系统的上游,也可以处在其他系统的下游。系统集成实际上就是将上游系统和下游系统进行整合,共同完成某一业务的流程。
上下文集成的基本思路在于解耦和统一,具体要关注防腐层与统一协议+领域事件两个重要思想,具体问题具体分析:
(三)、服务边界划分的四大原则
- 服务关联度原则:该服务变化时是否导致其他服务的变化。
- 业务能力职责单一原则:边界内的业务能力职责应单一,不是完成同一业务能力的服务不应该放在同一个上下文中。
- 读写分离原则:数据读取类型服务应尽量放在单独子域,且该子域不应该为核心子域。
- 组织关系原则:设计团队组织和独特业务价值。
四、服务建模切入点四:服务数据
绝大多数服务都会依赖数据,而很多数据可能也会被一批服务所依赖。微服务架构中数据管理的基本思想就是数据去中心化。
(一)、数据去中心化的三大场景
主要设计对数据拆分需求的表现形式:
跨表查询场景解决
在数据层去掉各种连接操作,将连接查询转变为简单的单表查询,然后对各种表查询的结果在内存中进行动态组装,从而实现业务所需要的数据。注意:如果考虑到未来服务拆分或重构的需要,从一开始就保持数据单表查询是最佳实践。
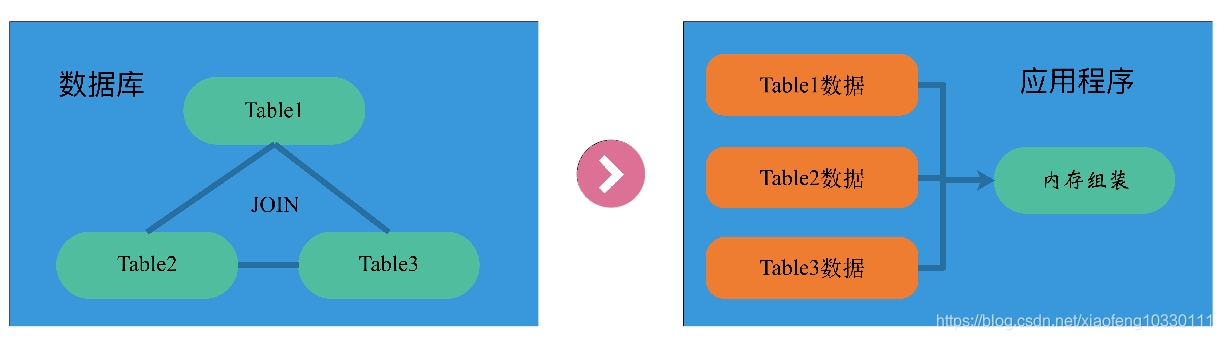
跨库查询场景解决
针对一些修改频率不高、相对静态的数据而言,可以采用数据复制的方式达到同一份数据在两个数据库中同时存在的效果,从而将跨库查询转变为同一库中表查询。
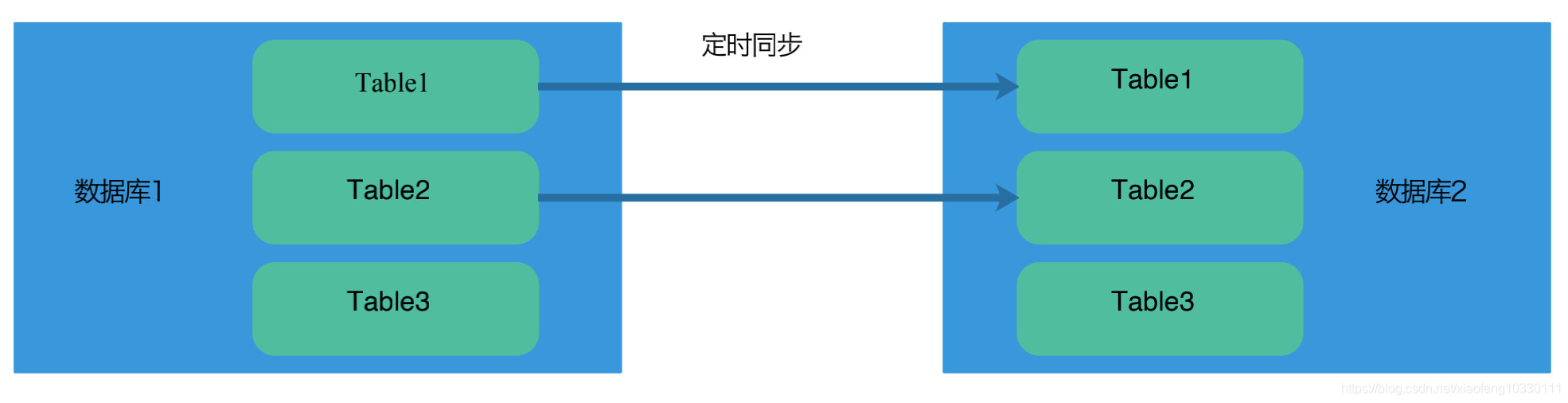
对于实时性要求比较高的数据,则可以开放接口的方式实现两个数据库之间的数据集成效果。
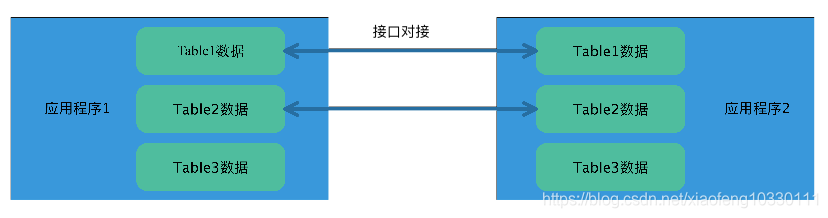
技术耦合场景及解决
技术耦合表现在使用了特定某种数据存储容器相关的技术体系,对于关系型数据库而言,存储过程、触发器就是典型的数据库工具级别的特有技术。
由于每种数据存储容器对这些技术的实现和支持都有所不同,所以在原则上,我们的业务功能都不应该使用这些技术进行数据处理。如果有,需坚决去掉。
(二)、数据去中心化流程
主要包含四大步骤,但涉及复杂的数据迁移工作,人力和时间成本都很大,也是目前微服务架构数据库去中心化的难度所在。
步骤1:代码分离
必须代码拆分,通过物理上代码拆分,即把原本单块系统中的代码拆分成几个组成部分就能实现。
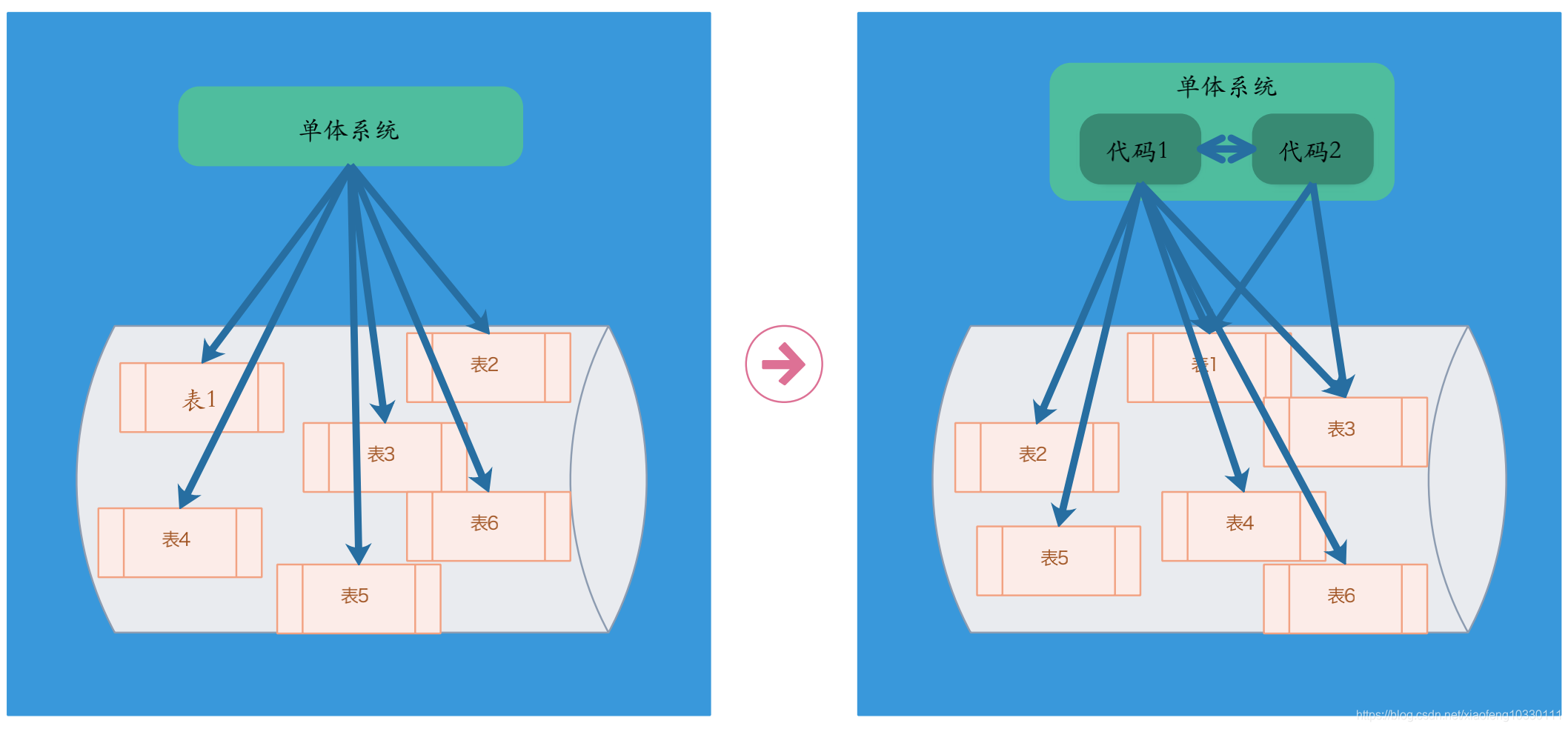
步骤2:重复数据库模式:代码拆分后,对数据访问会形成两种模式
一种是数据能够随着代码完成拆分,即这些数据不存在多个系统共用情况,简单把数据迁移出去供单个系统访问即可。
二是由于代码中包含了跨表查询、跨库查询和技术耦合场景,不能简单进行数据拆分,所以需要一个过渡环节,把几个系统共用的数据进行冗余处理,就是将同一份数据库模式和相应的数据同时保存在不同的数据库中。
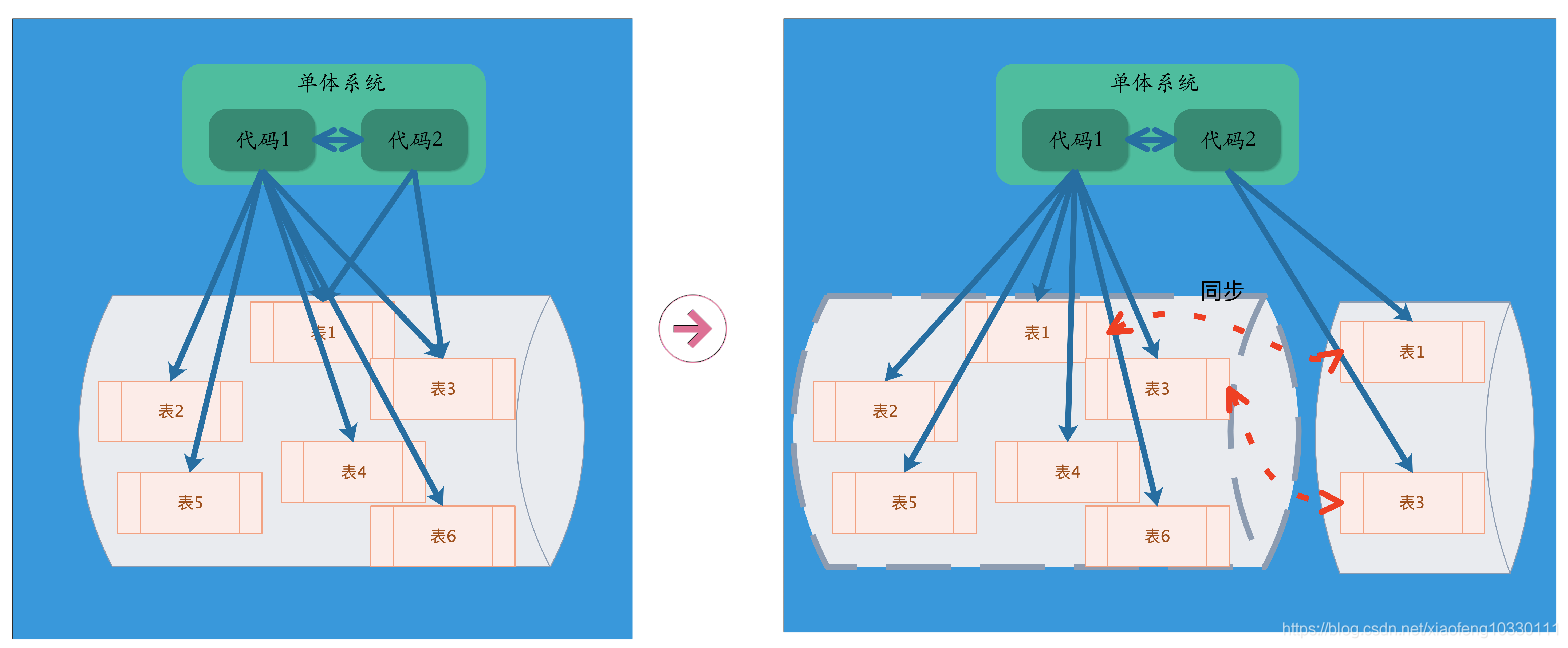
步骤3:迁移数据读写操作
将针对数据库写入和读取操作做单独抽离。
数据写入操作比较容易抽离,因为针对某个业务数据写入的源头通常只有一个,只要明确这个数据源就可以。
数去读取操作因为在没有进行专门的数据拆分之前,同一份数据可能通过各种方式被多业务共享,出现大量跨表查询、跨库查询和技术耦合场景,这是需要采用前文所述的各种解决方案进行读操作分离,这是最为复杂和最难的一步。
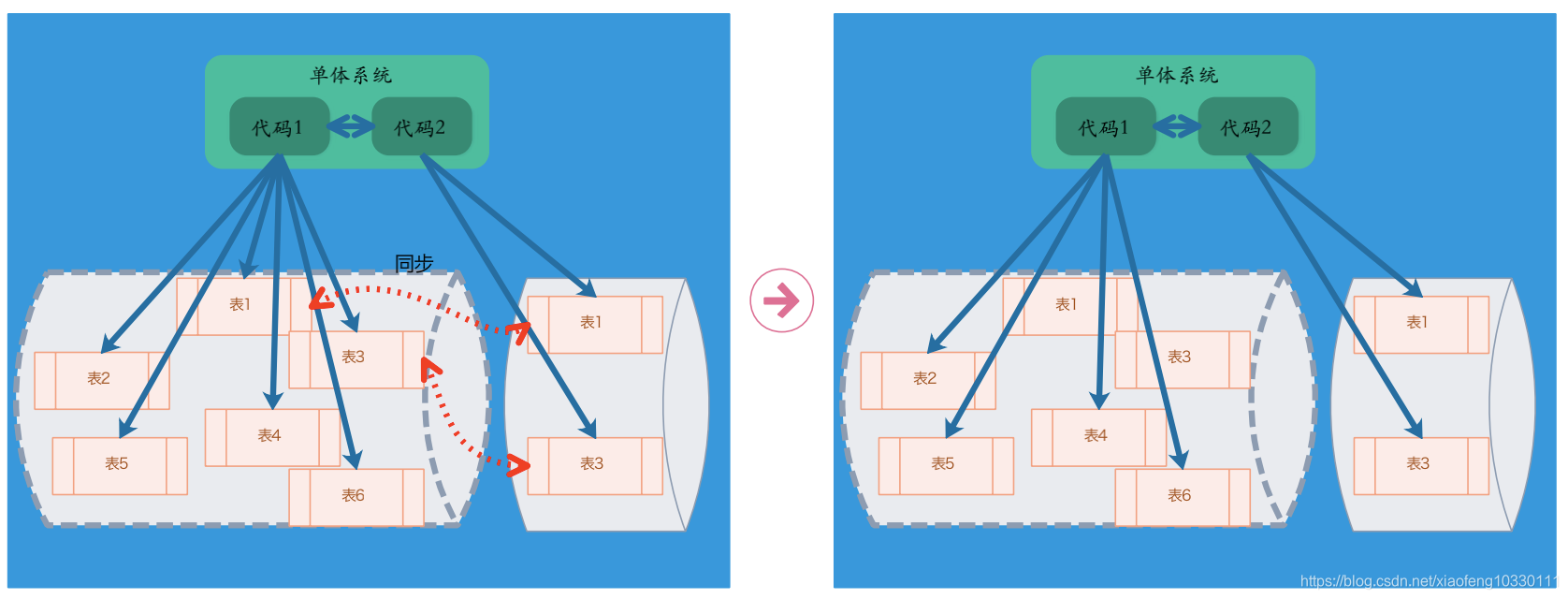
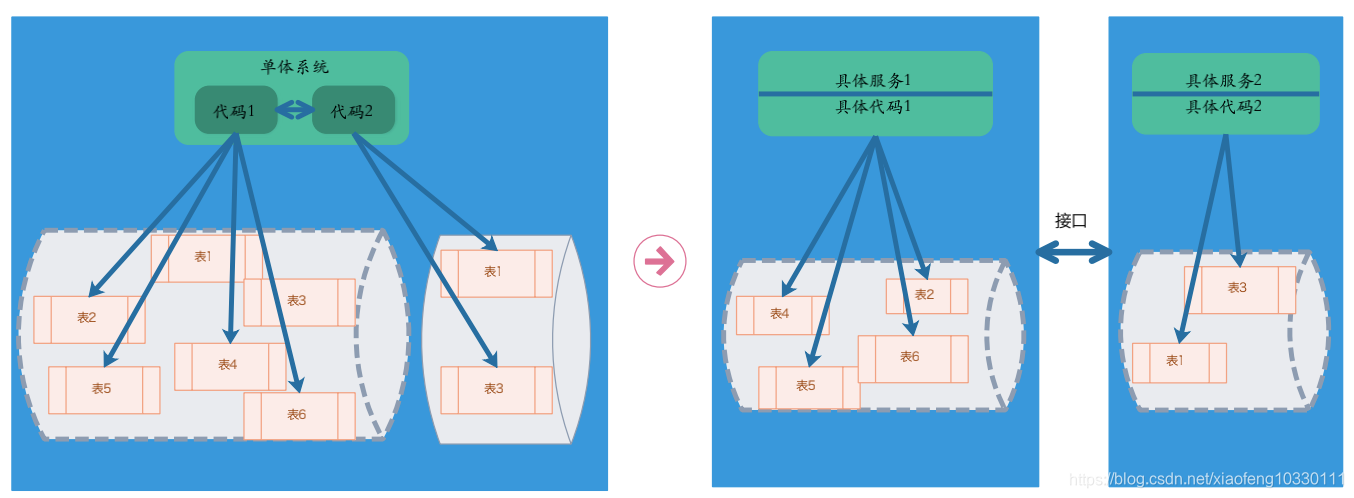
步骤4:抽离服务化接口
完成迁移数据读写操作迁移、去除数据定时同步机制以后,我们需要对代码进行拆分,从而实现服务化,抽离服务化接口是完成数据去中心化的最后一个环节。
参考书籍及文献:
【1】郑天民. 微服务设计原理与架构. 北京:人民邮电出版社,2018.
【2】Eric Evans. 领域驱动设计:软件核心复杂性应对之道. 赵莉,盛海燕,刘霞译. 北京:机械工业出版社,2018.
评论记录:
回复评论: