
论文解读:Knowledgeable Prompt-tuning: Incorporation Knowledge into Prompt Verbalizer for Text Classification
在预训练语言模型上使用与任务相关的prompt进行微调已经成为目前很有前途的方法。先前的研究表明了在小样本场景下采用基于prompt-tuning的效果比传统通过添加分类器的微调更有效。Prompt的核心思想是添加额外的上下文(即模板template),并一同与输入句子喂入语言模型中,并将分类任务转换为Masked Language Modeling的任务。其中重要的一个部分是构建一个映射关系——verbalizer(label word -> class)。先前的工作旨在人工构建,或基于模型自动搜索的方式获得label word,这容易带来高偏差和高方差。
本文,我们目标在于在verbalizer部分引入外部知识,提出 Knowledgable Prompt-tuning(KPT) 来提升和稳定prompt-tuning。具体地说,我们根据外部知识扩展来label word的搜索空间,在使用扩展的label word搜索空间进行预测之前,使用预训练语言模型本身细化扩展的标签词空间。在zero和few-shot场景下效果最佳。
简要信息:
| 序号 | 属性 | 值 |
|---|---|---|
| 1 | 模型名称 | KPT |
| 2 | 所属领域 | 自然语言处理;文本分类 |
| 3 | 研究内容 | 预训练语言模型;Prompt框架 |
| 4 | 核心内容 | Prompt-based Fine-tuning |
| 5 | GitHub源码 | https://github.com/timoschick/pet |
| 6 | 论文PDF | https://arxiv.org/pdf/2108.02035.pdf |
核心要点:
- Verbalizer的构建:利用外部知识搜索召回label word;
- 提出Few-shot和Zero-shot的多个label word的训练和推理方法;
一、动机
- 预训练语言模型被证明可以很好的学习到先验知识,因此最近研究者进一步研究如何将先验知识应用到具体的任务;
- 一种方法叫做Fine-Tuning,例如分类任务,在预训练语言模型的头部添加分类器,并给定充足的样本基础上进行微调;
- 然后现如今的这个微调方法,在few-shot或者zero-shot场景下效果很差。现如今GPT-3、LAMA等工作提出Prompt方法,进一步拉近预训练与下游任务之间的差距,并且验证了基于离散(人工、规则或搜索)或连续(例如pesudo token embedding)的Prompt的有效性;
- 一种方法是,在文本中插入一个带有[MASK]的template,因此任务的目标与MLM一致,即预测对应[MASK]的词,由于是分类问题,因此需要构建类标签到生成词的一个映射,称为verbalizer;
Verbalizer bridges a projection between the vocabulary and the label space and is proven to have a great influence on the performance of classification
- 先前构建verbalizer都是人工完成的,而且是一一对应,例如词science将对应于类别SCIENCE,但很显然不合理,因为还有一些词(例如math、physics)也能够满足这个类;
Such handcrafted one-one mapping limits the coverage of label words, thus lacking enough information for prediction and also inducing bias into the verbalizer.
- 最近有工作企图通过搜索的方法来降低人工构建verbalizer带来的局部最优问题,然后他们很难构建出一些映射关系(比如“physics”与“science”),因此如果能够拓展出这些其他词,则可以进一步提高准确性。
If we expand the verbalizer of the above example into {science, physics} → SCIENCE, the probability of predicting the true label will be considerably enhanced
因此本文提出KPT,通过融入外部知识的方法来构建verbalizer。
二、方法:KPT
本文工作旨在构建并使用verbalizer,例如给定一个问题x =“What’s the relation between speed and acceleration?”,假设是一个二分类,对应两个标签为:SCIENCE (labeled as 1) or SPORTS (labeled as 2),因此有:
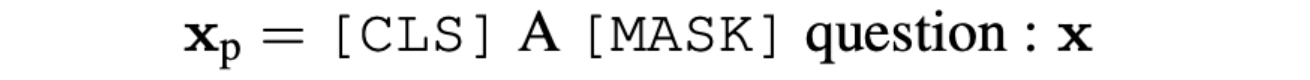
MLM将会得到[MASK]位置的对应整个词表的概率分布:
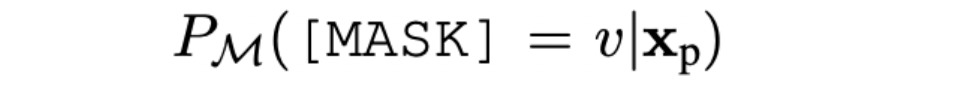
为了能够将生成的词与对应标签构建映射关系,提出verbalizer概念,即假设整个词表为 V \mathcal{V} V,标签 y y y 对应的label word集合则为 V \mathcal{V} V,因此,预测对应类别的概率分布则可记作:
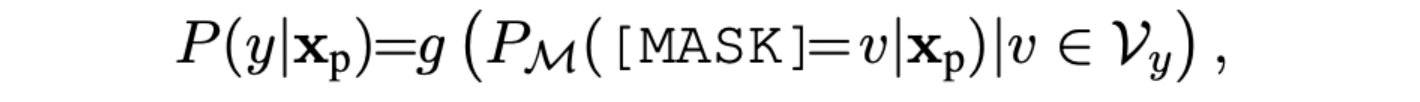
其中 g g g 函数作用是:transforming the probability of label words into the probability of the label.
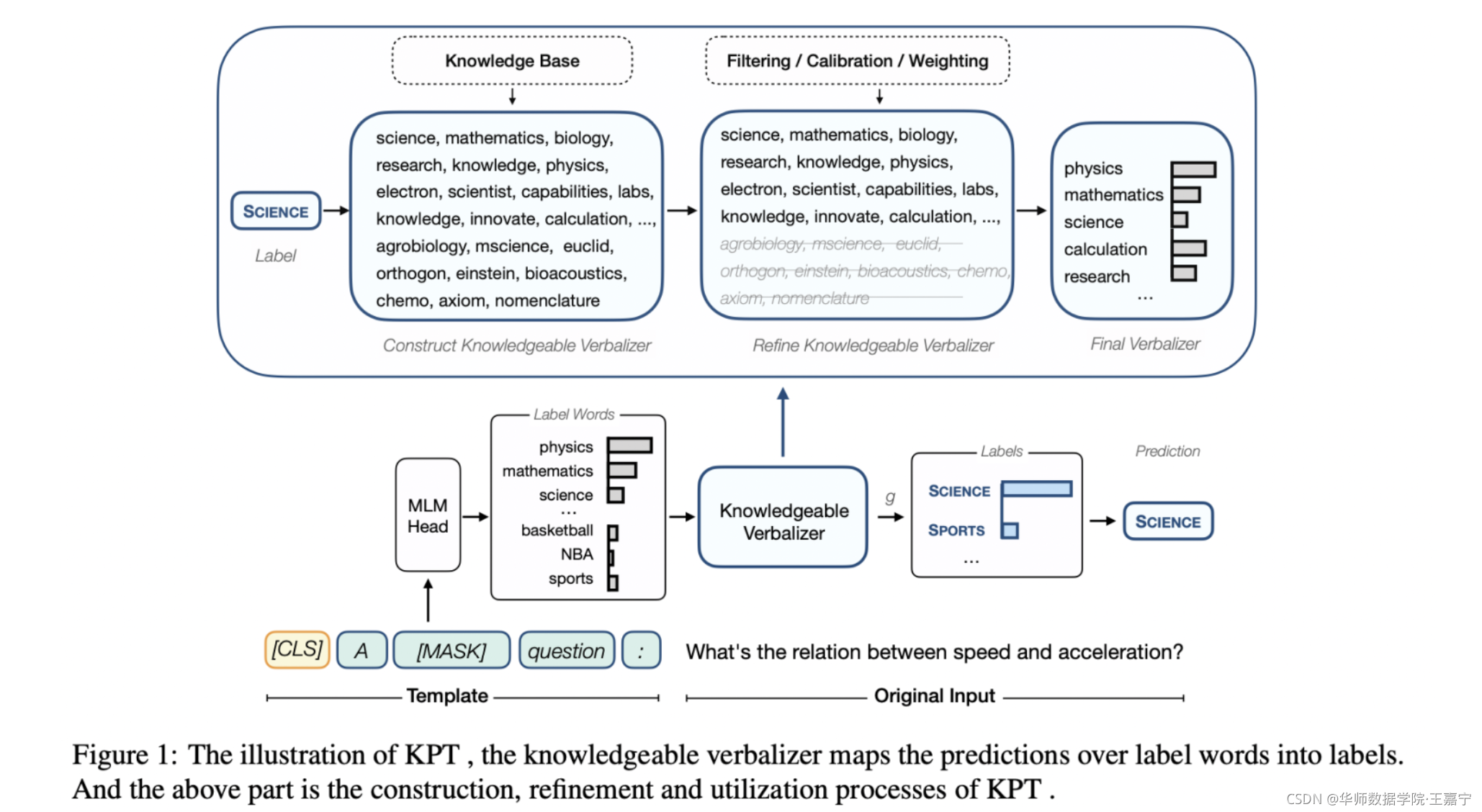
KPT包括三个步骤:
- construction:使用外部知识为每个label生成一个label word集合,这些词之间是不同粒度的“同义词”,可以避免某一个label word存在的有偏性;
- refinement:使用PLM来对label word集合进行denoise;
- utilization:采用平均或加权的方法,对verbalizer内的所有label的loss进行求和;
2.1 Verbalizer Construction
认为MLM用于分类并非是单选问题,可能有很多label word都可以反应对应的类,因此这些word需要满足wide coverage和little subjective bias两个要素。
那么如何利用外部知识来构建verbalizer呢?主要针对两种类型的分类,分别是topic classification和sentiment analysis:
- topic classification:每个文本都有对应的topic,选择Related Words(包含word embedding、ConceptNet和WordNet),图谱中node表示各个词,边表示词之间的相关性得分。挑选每个topic词对应的node,并获得所有超过阈值的边对应的邻接node,作为label word候选 V y = N G ( v ) ∪ { v } \mathcal{V}_y=N_{\mathcal{G}}(v)\cup\{v\} Vy=NG(v)∪{v}:
- sentiment analysis:使用现有的情感词表: https://www.enchantedlearning.com/wordlist/positivewords.shtml、https://www.enchantedlearning.com/wordlist/negativewords.shtml。
2.2 Verbalizer Refiner
认为获得的集合并非完全可以使用,因为含有一定的噪声,因此需要进行提炼(剔除或削弱噪声的影响),主要分为zero-shot和few-shot两个场景:
(1)zero-shot
主要面临三个问题:
- OOV问题:可以使用word piece解决;
- 罕见词:部分词对于PLM很少见,因此预测这些词很难,需要将其剔除掉。首先对training data采样一部分组成support set
C
~
\tilde{C}
C~,对support set的所有句子,获得每个label word的先验概率:
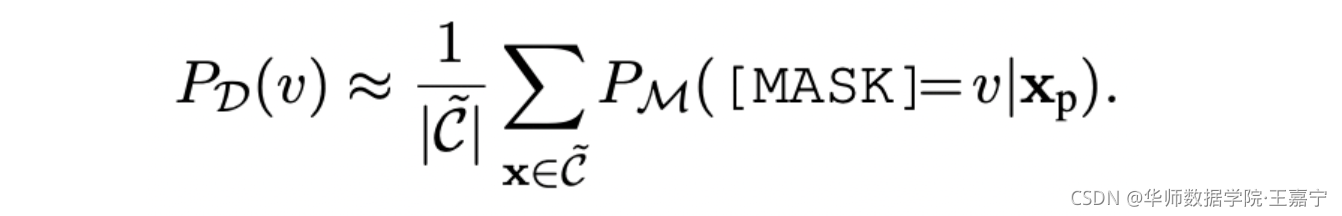
其可以代表所有句子语义层面上,当取 v v v 作为label word时的概率,对低于某个阈值的label word进行剔除; - 有偏性:避免不同的label word被预测的概率不同,降低label word之间的偏差,提出公式Contextualized Calibration (CC):
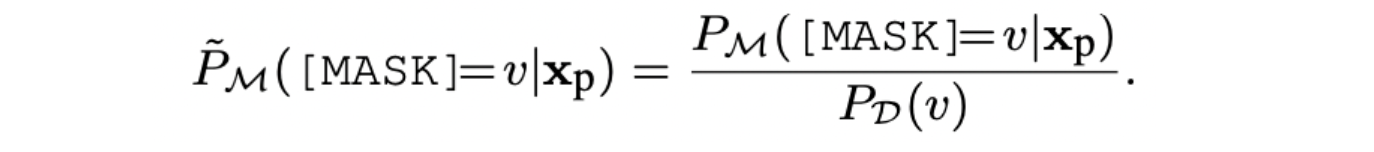
即:某一个句子的某一个label word的概率,除以这个label word的先验概率,获得的则是一个相对值。
假设label word A1和A2对应的先验概率分别是0.1和0.5,两者差距较大。给定某个句子S,其对应两个label word的概率分别是0.1和0.6,很显然,分别比值后为1.0和1.2。这样就尽可能避免来label word之间的偏差
(2)few-shot
在few-shot场景下,存在部分标注数据,因此可以通过训练获得每个label word的重要性,通过学习一个权重向量,为每个label word分配权重,以避免噪声带来的影响:
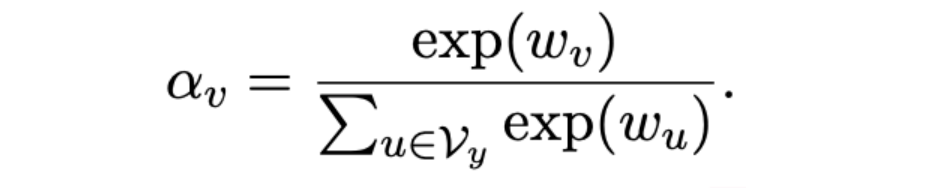
a small weight is expected to be learned for a noisy label word to minimize its influence on the prediction
2.3 Utilization
(1)平均法
给定一个标签,每个标签将会对应若干label word,假定每个label word重要性一样,因此这个标签的概率可以视为对应所有label word被预测的概率的均值,最终从所有标签中挑选概率最大:
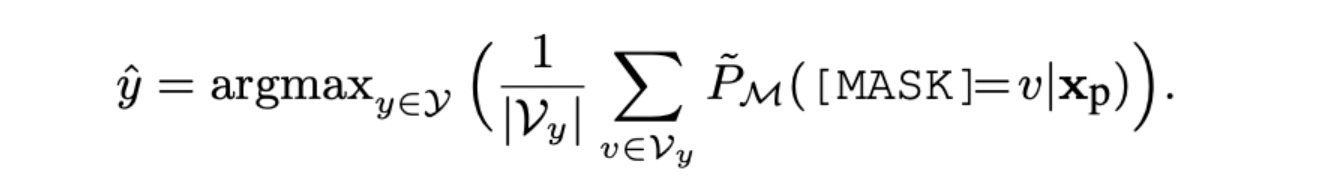
由于没有引入外部参数,该目标可以用于zero-shot;
(2)加权法
在few-shot场景,学习来一个权重向量,可以使用该权重来实现加权:
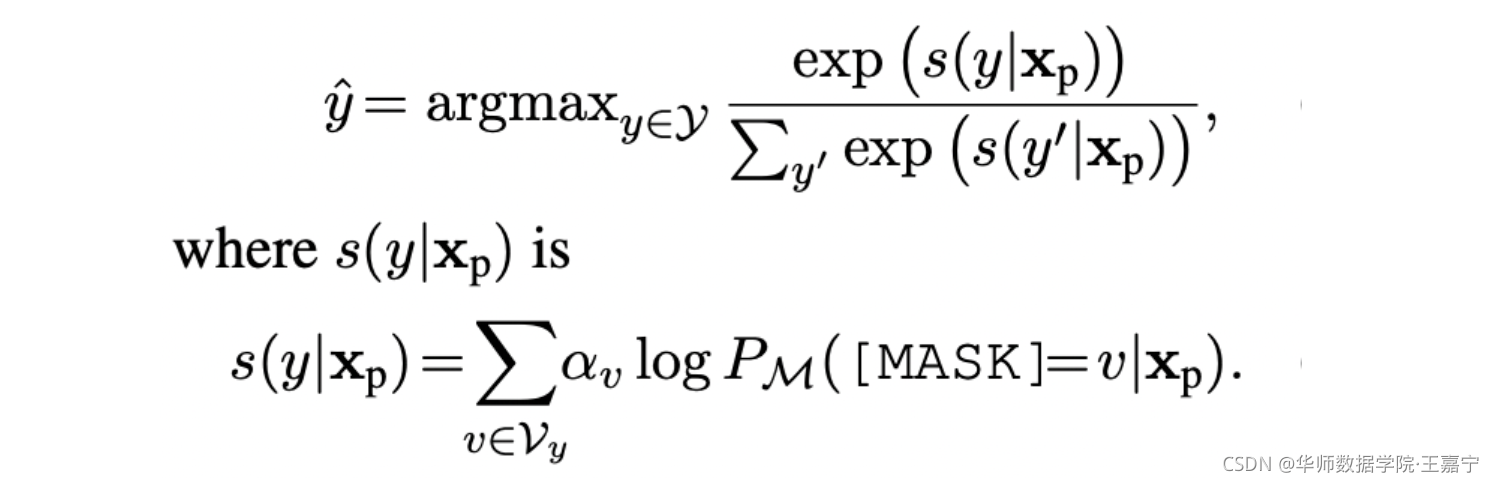
即给定一个句子 x p \mathbf{x}_p xp,获得某个标签 y y y 对应的所有label word的对数概率后,根据学习的权重进行加权求和,得到该标签的概率值。由于引入部分参数,则需要在few-shot场景。
三、实验
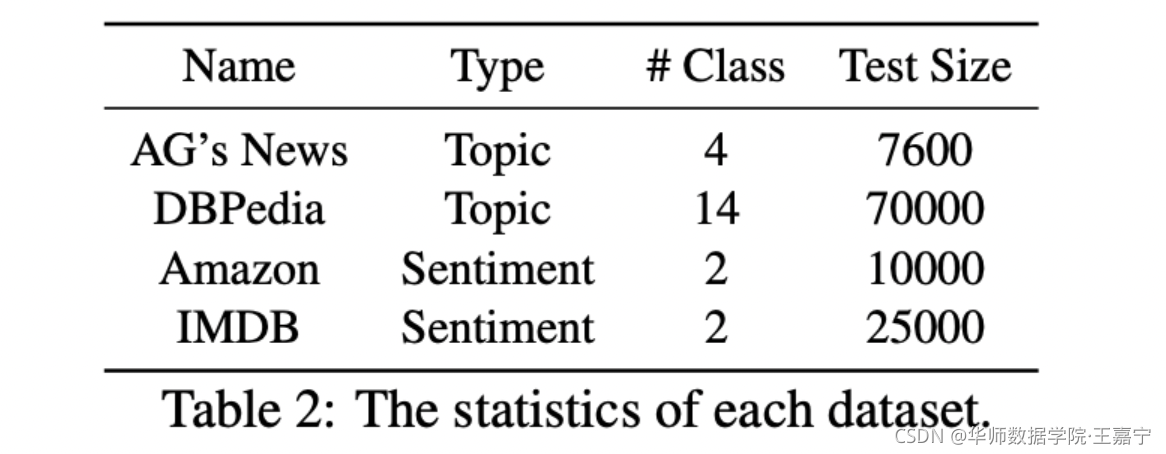
3.1 数据集
3.2 baseline
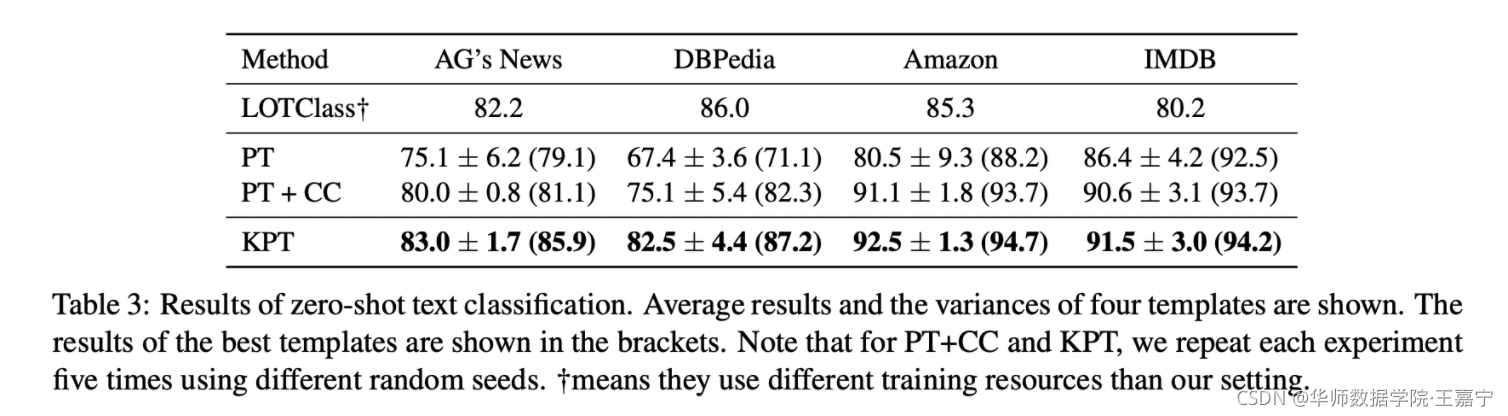
- LOTClass:通过预训练语言模型在无标注语料上获得topic-related word;
- PT:传统的Prompt-tuning方法,选择人工设计的template,label word直接选择class name;
- PT+CC:在Prompt基础上,直接使用本文提出的Contextualized Calibration;
3.3 zero-shot
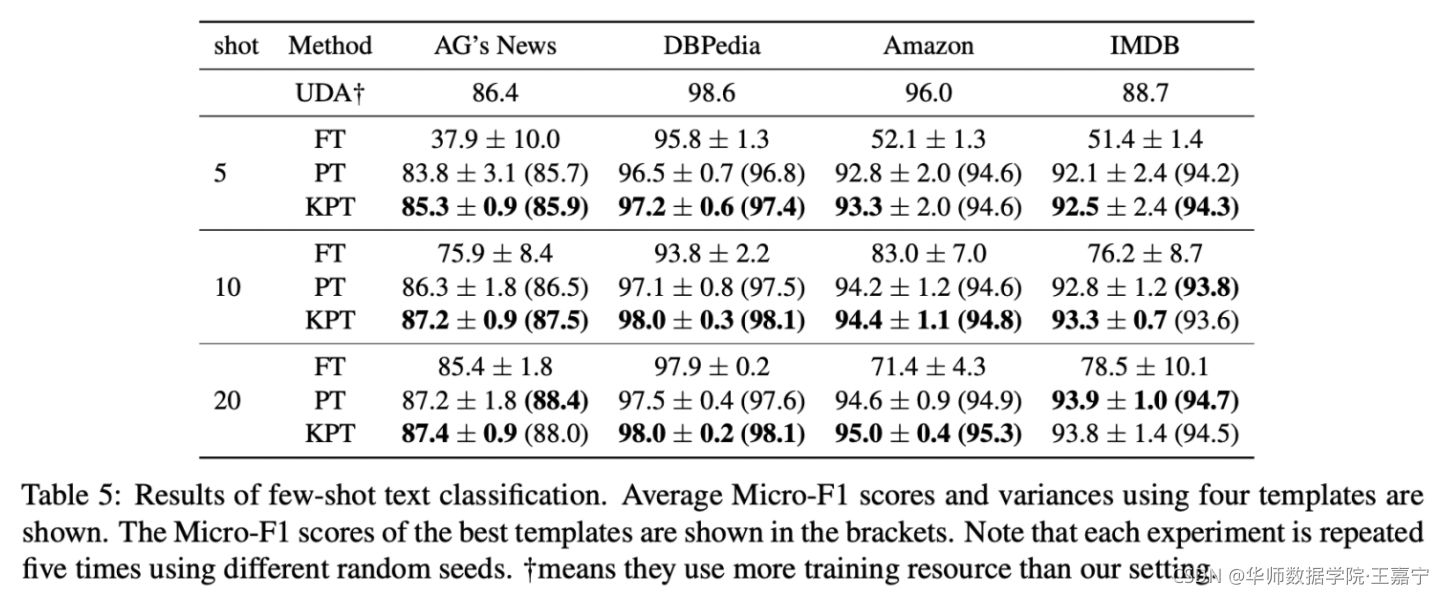
3.4 few-shot
3.5 验证Support set大小对实验效果
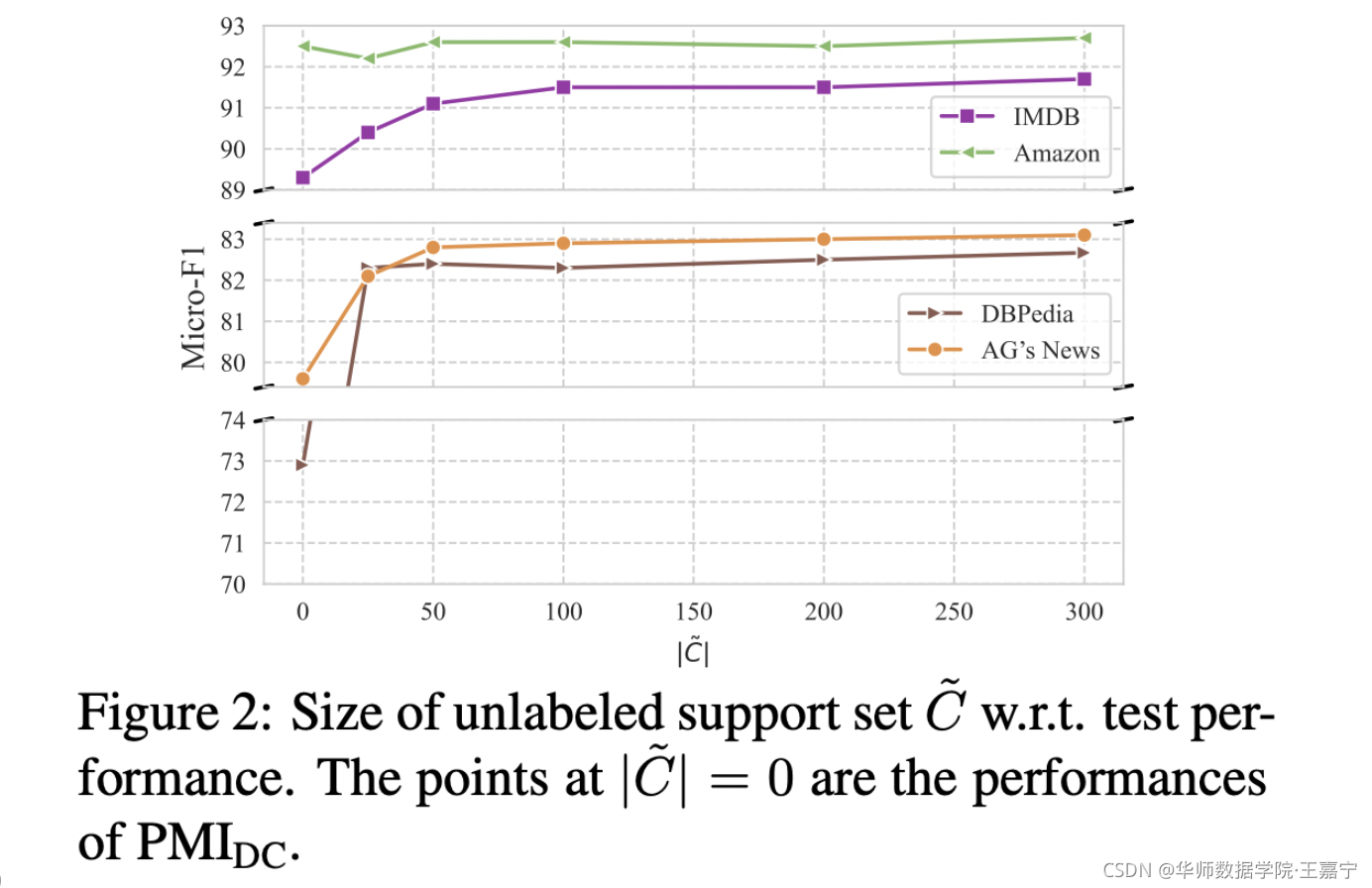
support set的作用是用于计算每个label word的先验概率,以提供筛除的依据。可以发现support set取100的时候已经基本可以达到不错的效果,说明100个样本足以代表整个样本上label word的先验分布。当support set大小为0时,等价于直接使用 P M I D C PMI_{DC} PMIDC方法,可知有很大提升。
3.6 Case Study
在AG’sNew上挑选了 POLITICS和SPORTS两个类,并统计了对应label word的词频的Top15:
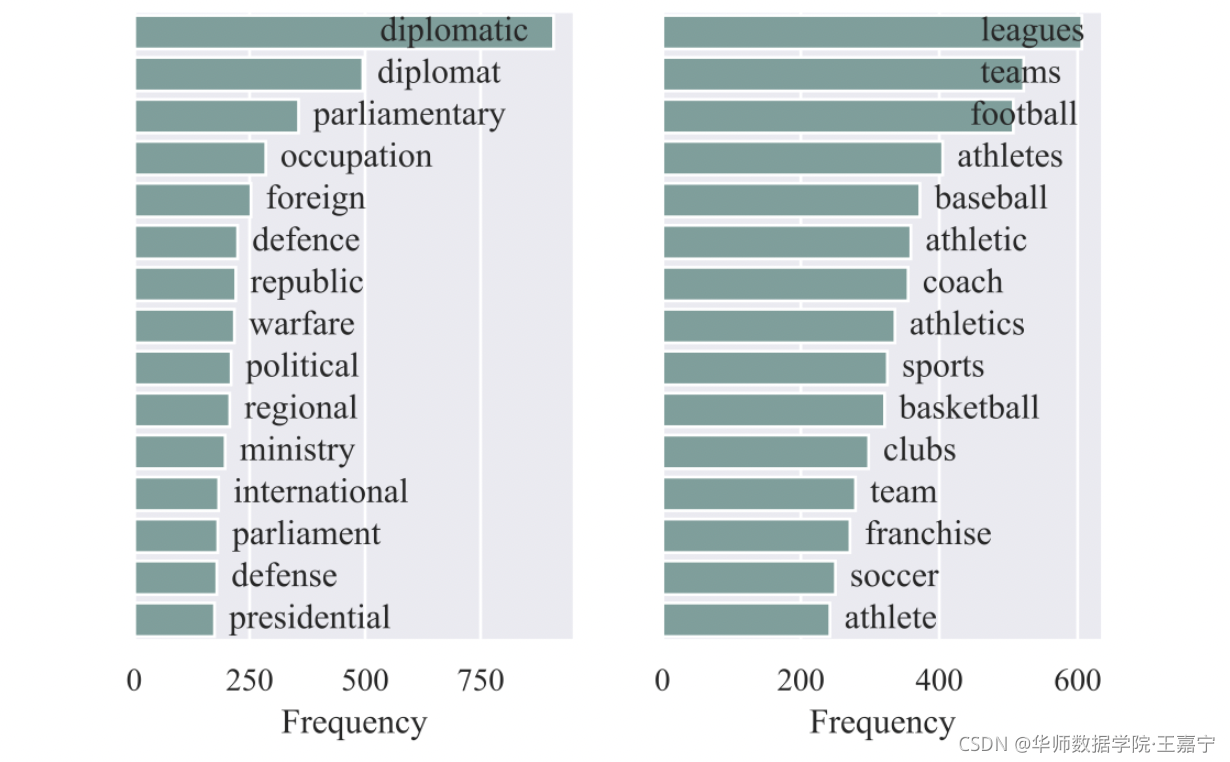
发现并非标签本身具有很大的代表性,同时同一个标签会涵盖很多label word涉及的各个方面。
评论记录:
回复评论: