
论文解读:PTR: Prompt Tuning with Rules fo Text Classification(2021)
预训练语言模型已经在许多NLP任务上达到不错的效果。通过添加prompt模板则可以积累预训练语言模型中丰富的知识。
By using additional prompts to fine-tune PLMs, we can further stimulate the rich knowledge distributed in PLMs to better serve downstream tasks.
prompt方法已经在许多few-shot文本分类任务上(情感分析/语义推理)有明显的提升。然而手动构建自然语言提示(language prompt)会显得cumbersom and fallible(麻烦且容易出错)。而对于自动生成的prompt,对其进行有效性验证也会很费时,尤其是在非小样本场景下。因此有必要解决many-class分类问题。
因此,本文提出一种方法(prompt tuning with rules,PTR),应用逻辑规则来构建prompts和一些sub-promtps。因此PTR可以在prompt tuning时从各个类中表征先验知识。
简要信息:
| 序号 | 属性 | 值 |
|---|---|---|
| 1 | 模型名称 | PTR |
| 2 | 所属领域 | 自然语言处理;文本分类 |
| 3 | 研究内容 | 预训练语言模型;Prompt框架 |
| 4 | 核心内容 | Prompt-based Fine-tuning |
| 5 | GitHub源码 | |
| 6 | 论文PDF | https://arxiv.org/pdf/2105.11259.pdf |
核心要点:
- template的构建:人工构建sub-prompt,再利用规则逻辑对特定任务生成相应的template;
- 将Prompt应用在关系抽取任务上;
一、动机
- 预训练语言模型在下游任务上进行微调,可以将先验知识自适应到具体的下游任务上;
- 最近相关研究发现一个至关重要的挑战:预训练目标与微调之间的gap;因为下游任务的微调与语言模型的预训练目标的不同,导致无法充分利用语言模型的先验知识;因此很难将先验知识迁移到下游任务上
- prompt方法的提出将可以拉近预训练与微调任务之间的差距。其通过设计一个prompt模板,并企图让模型预测[MASK]对应的label word,将传统的分类任务转换为完形填空问题。目前已经在情感分析/自然语言推理等任务上得以验证。
- 然而对于这些多类分类的任务,需要针对不同的类,手动寻找合理的模板以及label word。一种方法是自动生成prompt模板,自动从vocabulary中寻找label word。但是自动生成的方法带来的提升并非具有革命性的提升,同时还使得计算复杂度和时间复杂度变得很高。
- 因此,本文提出一种PTR方法,手动设计一些基本的sub-prompt,并使用逻辑规则将这些sub-prompt构建为与任务相关的prompt。
如下图,展示了传统的Fine-tunine与基于Prompt的Fine-tuning的区别:
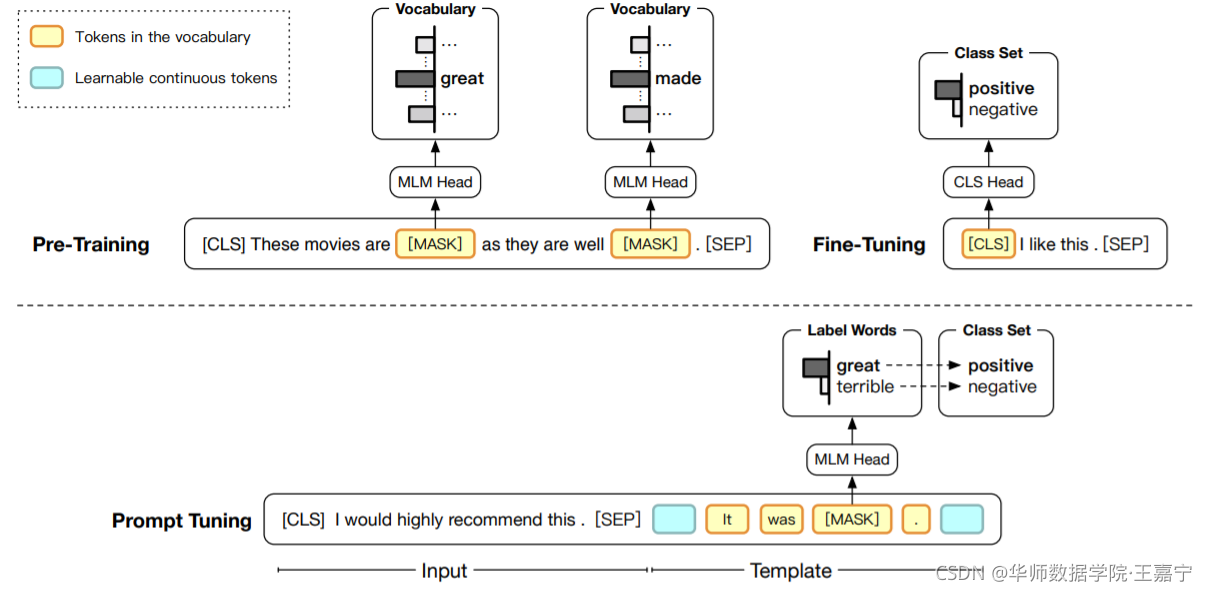
二、贡献
本文旨在改进先前的挑选Prompt Template的方法,在于两个方面:
- prior knowledge encoding:根据逻辑规则将与任务和类别相关的先验知识进行表征;
以关系分类为例,预测的关系通常与句子的关系表达和标记实体的类型相关。 我们可以为“person:parent”和“organization:parent”构建提示,通过子提示确定标记的实体是人还是组织,以及确定句子是否表达父语义的子提示 . - efficient prompt design:相比手动构建以及自动构建,使用逻辑规则更有效;
三、预备知识:Prompt Tuning描述
-
给定一个样本 x = { w 1 , . . . , w n } x=\{w_1,...,w_n\} x={w1,...,wn},其由多个token组成,对应的标签记作 y y y。prompt-tuning需要给定一个模板函数 T ( ⋅ ) T(\cdot) T(⋅) 和一系列的label word V \mathcal{V} V。
-
对于样本 x = { w 1 , . . . , w n } x=\{w_1,...,w_n\} x={w1,...,wn},需要先获得相应的prompt x p r o m p t = T ( x ) x_{prompt}=T(x) xprompt=T(x),需要保证至少存在一个[MASK]标记。
For instance, for a binary sentiment classification task, we set a template T (·) = “ · It was[MASK].”, and map x x x to x p r o m p t x_{prompt} xprompt = “x It was [MASK].”
- 喂入到预训练语言模型中,执行MLM任务来实现预测[MASK]对应的label word的概率分布:
p ( y ∣ x ) = p ( [ M A S K ] = ϕ ( y ) ∣ x p r o m p t ) p(y|x) = p([MASK]=\phi(y)|x_{prompt}) p(y∣x)=p([MASK]=ϕ(y)∣xprompt)
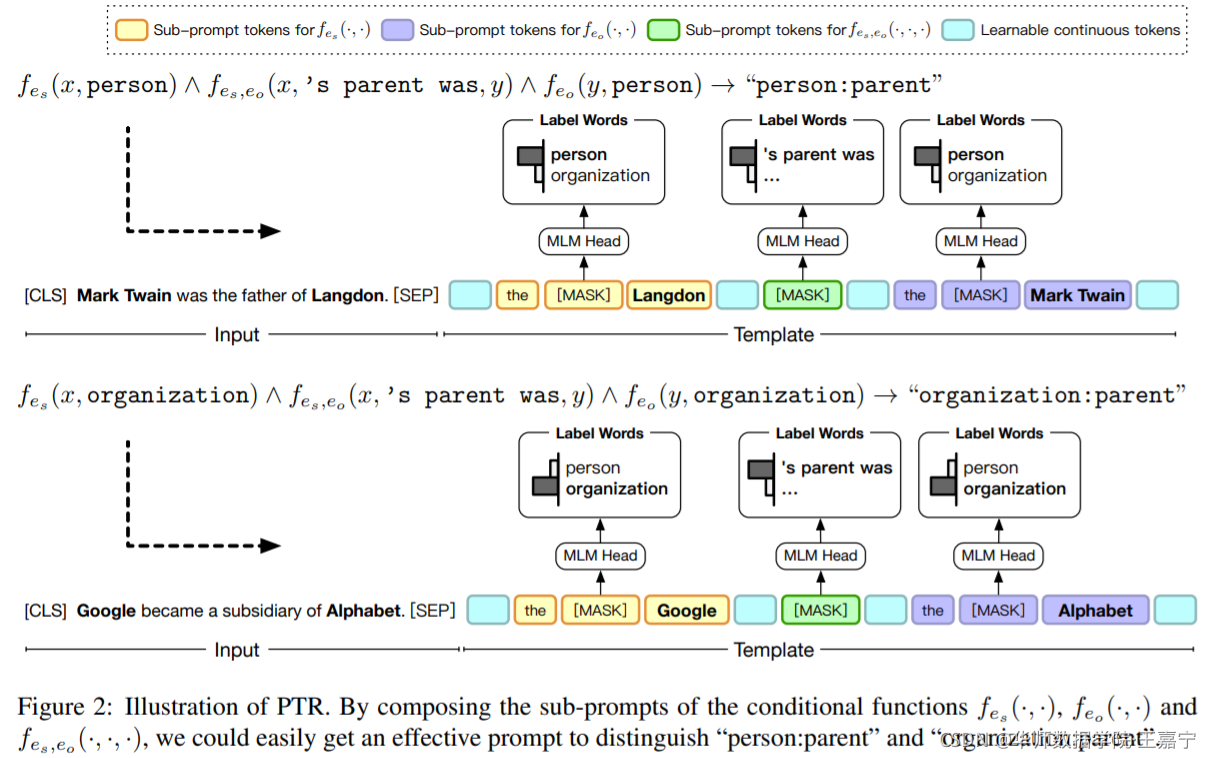
四、方法:PTR方法
- 定义conditional function
f
∈
F
f\in\mathcal{F}
f∈F,用于判断input是否满足条件。例如
f
(
x
,
p
e
r
s
o
n
)
f(x, person)
f(x,person) 用于判断输入
x
x
x 是否属于 person;
f
(
x
,
’s parent was
,
y
)
f(x, \text{'s parent was}, y)
f(x,’s parent was,y) 则用于判断
y
y
y 与
x
x
x 的关系是否是parent;
• 使用逻辑规则(logic rules)将分类任务转化为一系列conditional function的计算。
例如关系抽取任务中,判断两个实体x和y是否存在关系:
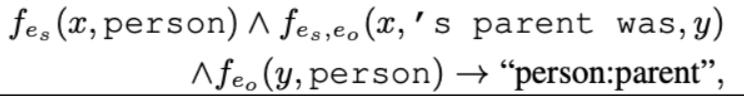
4.1 Sub-prompt for Conditional Functions
每个conditional function
f
∈
F
f\in\mathcal{F}
f∈F,手动构建sub-prompt,其包含模板和label word。以关系抽取为例,输入句子
{
⋯
,
e
s
,
⋯
,
e
o
,
⋯
}
\{\cdots, e_s, \cdots, e_o, \cdots\}
{⋯,es,⋯,eo,⋯},其中
e
s
,
e
o
e_s, e_o
es,eo分别为头实体和尾实体。因此针对头实体(和尾实体)。可以人工构建sub-prompt(包括离散的template和一组候选的label word):

对于关系,同样可以获得sub-prompt:
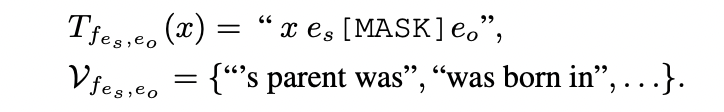
4.2 Composing Sub-Prompts for Tasks
本部分则考虑如何根据具体的任务,将sub-prompt集成起来。依然以关系抽取为例,输入的文本则可记作:
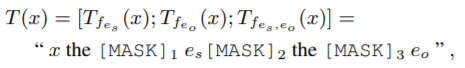
每个[MASK]位置都对应着相应的搜索空间,即label word,例如:

该句子中,每个[MASK]都等同于一个映射到label word上的分类,每个位置将会得到相应概率,显然,整个句子被预测正确的概率则为概率累乘:
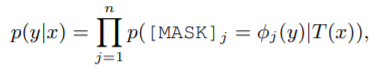
五、实验
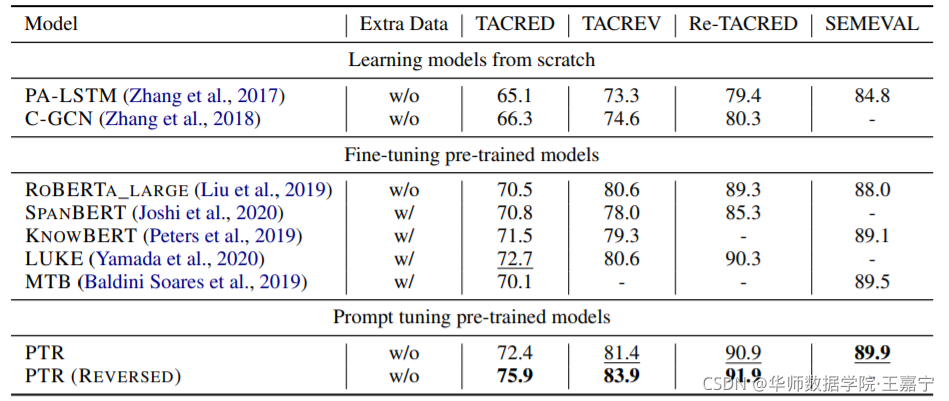
实验挑选了TACRED、TACREV、Re-TACRED和SemEval四个公开数据集,实验对比如下所示:
评论记录:
回复评论: