
曾经只是知道redis可以故障转移,但是不知道怎么转移,这次来见识一下:
前提
搭建了一个如下图的三主三从的集群。

并且集群处于运行中
一、故障模拟
我们首先停止一个主服务,看有什么变化:
我们停止了7002主服务器:
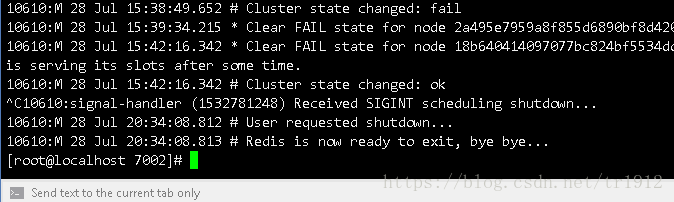
马上会在他的从机7004服务器上看到这些
然后其他主服务器看到这些:
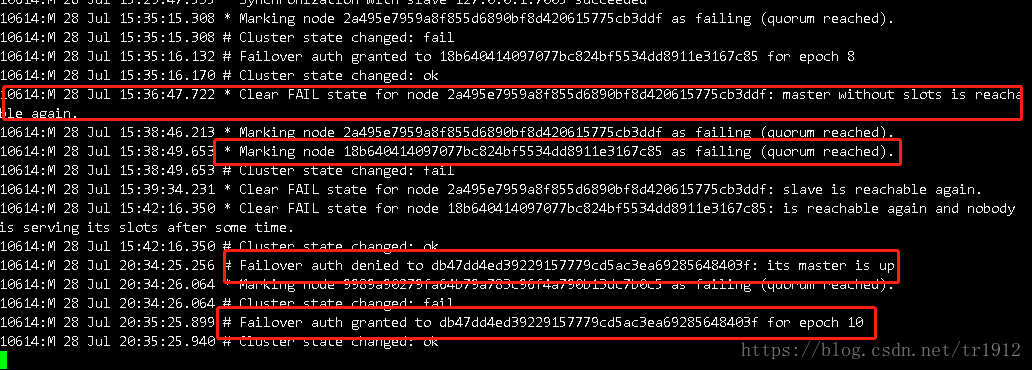
这里表示有一个节点down掉了,然后回收了他的哈希槽,然后选举出了一个新的master

其他从机只是标记了down掉的那台机子为访问失败
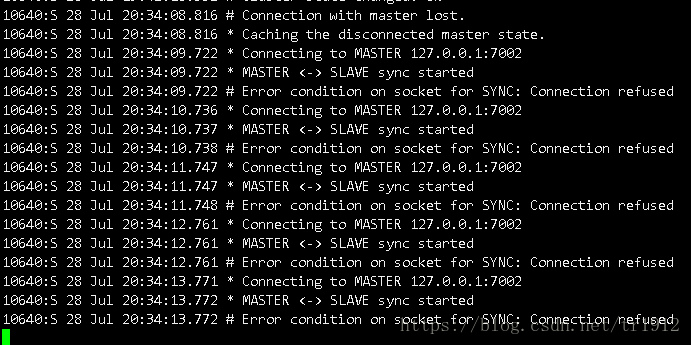
随后我们可以在down掉的那个主机器的从机上看到这些:

可以看到这个从机知道了选举的进行,并被选为了主机,至此整个选主就结束了。
然后我们再启动7002这个原主机
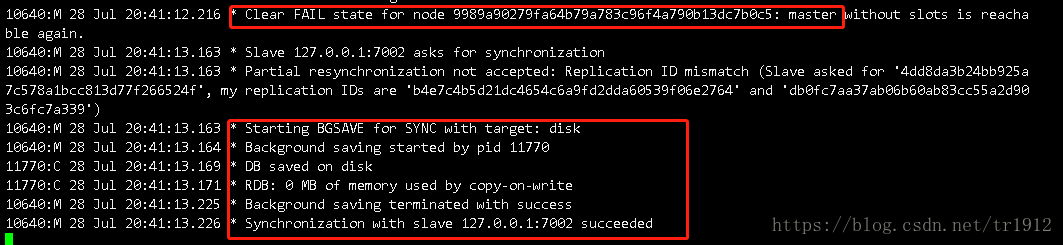
在看7004这个主机,发现他先把7002这个主机标记为了可达的状态,然后再和它同步数据。根据数据记录的pid
其他的机器只是把它标记为了可达的状态:
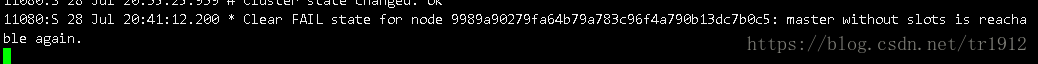
这次我们要把一个主从的两个机器都停止掉,看看是什么情况:
我们先停止7002这个从机:
他的主机:
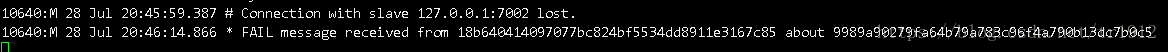
其他机器:
![]()
然后再停止7004这个主机:
其他从机:
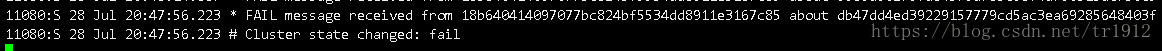
其他主机:
![]()
这个可以知道了,我们的节点中只要有一个分片的机能完全停止之后,整个集群就处于连接不能的状态。

然后我们先启动7002这个slave节点:
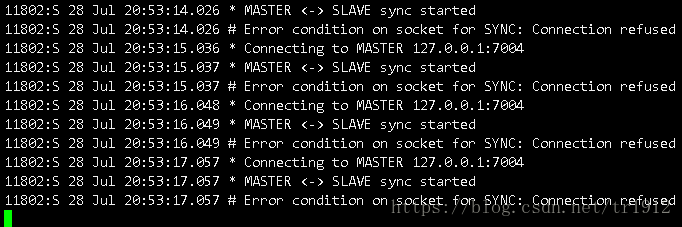
7002一直在扫描主节点
![]()
而其他节点就和之前7002恢复的时候一样,给他标记了可用的状态。
这个时候启动7004节点:
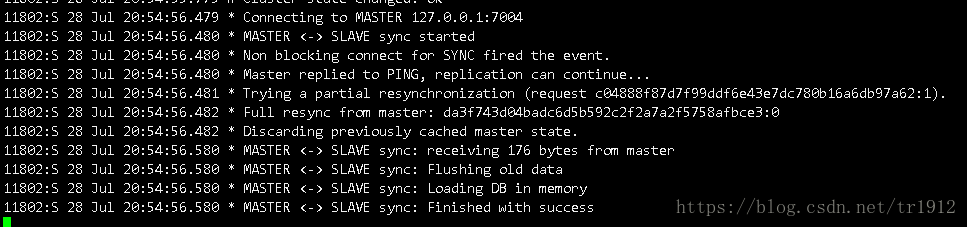
可以看到7002连接上了7004,并且同步了一波数据。
其他节点则表示这个节点恢复了连接,然后整个儿集群也都恢复了:
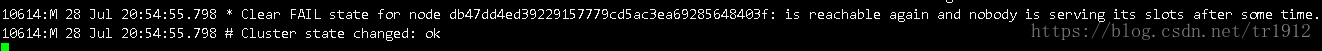
三、机制解读
这个就是redis的cluster的故障转移机制,redis的各个节点通过ping/pong进行消息通信,转播槽的信息和节点状态信息,故障发现也是通过这个动作发现的,他总共分为这么几步:
1.主观下线:某个节点认为另一个节点不可用,变为了下线的状态,这个是第一个实验中,首先断开7002节点的时候,7004就会马上发现7002不可达时候7004的认为的状态。
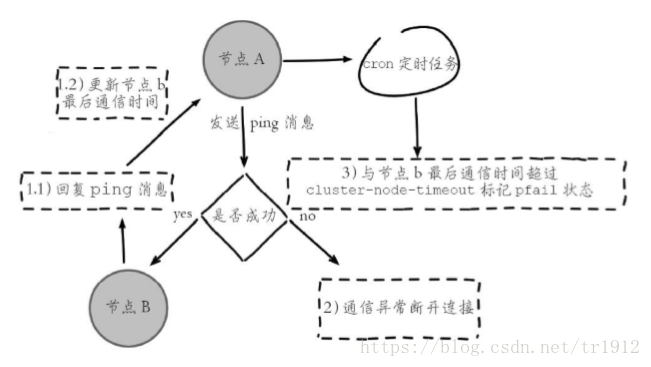
2.客观下线:指标记一个节点真正下线,集群内多个节点都认为该节点不可用的状态。如第一个实验中过了一会,其他节点都会标记7002为fail的状态。
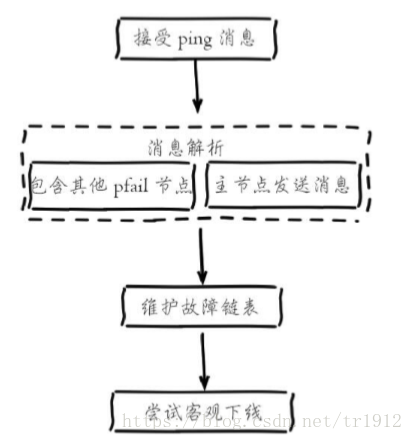
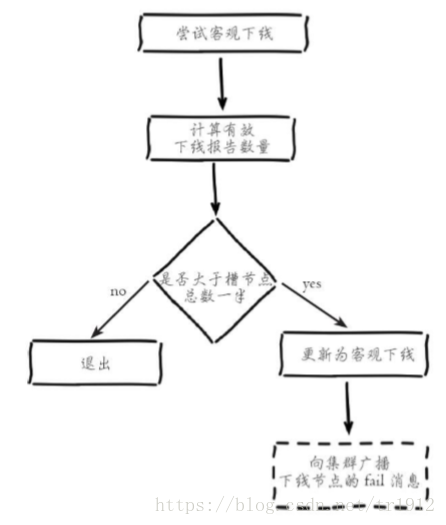
3.故障恢复:故障节点变为客观下线后,如果下线节点是持有槽的主节点则需要在它的从节点中选出一个替换它,从而保证集群的高可用。下线主节点的所有从节点承担故障恢复的义务,当从节点通过内部定时任务发现自身复制的主节 点进入客观下线时,将会触发故障恢复流程:
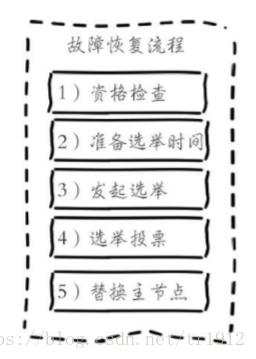
1). 资格检查:每个从节点都要检查最后与主节点断线时间,判断是否有资格替换故障 的主节点。如果从节点与主节点断线时间超过cluster-node-time*cluster-slave-validity-factor,则当前从节点不具备故障转移资格。参数cluster-slavevalidity-factor用于从节点的有效因子,默认为10。
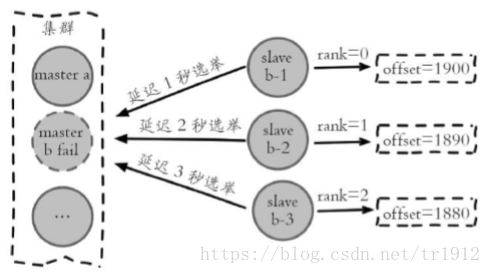
2).准备选举时间:当从节点符合故障转移资格后,更新触发故障选举的时间,只有到达该时间后才能执行后续流程。这里之所以采用延迟触发机制,主要是通过对多个从节点使用不同的延迟选举时间来支持优先级问题。复制偏移量越大说明从节点延迟越低,那么它应该具有更高的优先级来替换故障主节点。所有的从节点中复制偏移量最大的将提前触发故障选举流程。
主节点b进入客观下线后,它的三个从节点根据自身复制偏移量设置延 迟选举时间,如复制偏移量最大的节点slave b-1延迟1秒执行,保证复制延迟低的从节点优先发起选举。
3).发起选举:
当从节点定时任务检测到达故障选举时间(failover_auth_time)到达后,发起选举流程如下:
(1).更新配置纪元:配置纪元是一个只增不减的整数,每个主节点自身维护一个配置纪元 (clusterNode.configEpoch)标示当前主节点的版本,所有主节点的配置纪元都不相等,从节点会复制主节点的配置纪元。整个集群又维护一个全局的配 置纪元(clusterState.current Epoch),用于记录集群内所有主节点配置纪元 的最大版本。执行cluster info命令可以查看配置纪元信息。只要集群发生重要的关键事件,纪元数就会增加,所以在选从的时候需要选择一个纪元数最大的从。
(2).广播选举消息:在集群内广播选举消息(FAILOVER_AUTH_REQUEST),并记录已发送过消息的状态,保证该从节点在一个配置纪元内只能发起一次选举。消息 内容如同ping消息只是将type类型变为FAILOVER_AUTH_REQUEST。
4).选举投票:只有持有哈希槽的主节点才能参与投票,每个主节点有一票的权利,如集群内有N个主节点,那么只要有一个从节点获得了N/2+1的选票即认为胜出。
Ps.故障主节点也算在投票数内,假设集群内节点规模是3主3从,其中有2个主节点部署在一台机器上,当这台机器宕机时,由于从节点无法收集到 3/2+1个主节点选票将导致故障转移失败。这个问题也适用于故障发现环 节。因此部署集群时所有主节点最少需要部署在3台物理机上才能避免单点问题。
投票作废:每个配置纪元代表了一次选举周期,如果在开始投票之后的 cluster-node-timeout*2时间内从节点没有获取足够数量的投票,则本次选举作废。从节点对配置纪元自增并发起下一轮投票,直到选举成功为止。
5).替换主节点
当从节点收集到足够的选票之后,触发替换主节点操作:
- 当前从节点取消复制变为主节点。
- 执行clusterDelSlot操作撤销故障主节点负责的槽,并执行 clusterAddSlot把这些槽委派给自己。
- 向集群广播自己的pong消息,通知集群内所有的节点当前从节点变为主节点并接管了故障主节点的槽信息。
评论记录:
回复评论: