
目录
二、Spring Cloud Zuul典型基本配置:路由配置和功能配置
3.多实例映射(Zuul默认使用Eureka集成的负载均衡功能,所以若使用该功能需要做如下两件事:见注释)
5.相同路径的加载规则(只会不建议使用,yml解释器工作时,如果一个映射路径对应多个服务,按照加载顺序最末的规则覆盖最前的规则)
3.敏感头信息(如果系统需要与外部系统打交道时,在网关层可以指定具体敏感头,切断其与下层服务的交互)
5.重试机制:此功能需要慎用,有一些接口要保证幂等性,需做好相关工作
(二)OpenResty整合Nginx+Zuul实现动态感知增减机制
七、Spring Cloud Zuul主要的扩展功能(多级业务处理+使用Groovy编写Filier+权限集成+限流+动态路由+灰度发布+文件上传)
OAuth2.0 + JWT应用于Zuul(后续博客提供实战代码)
实现方式1:结合Spring Cloud Config + BUS,动态刷新配置文件。
实现方式2:重写Zuul的配置读取方式,采用时间刷新机制,从数据库读取路由映射规则。(后续博客提供实战代码)
注:以上所有只做理论性的总结与分析,相关实战代码会在后面的博客中和github中逐步增加。
干货分享,感谢您的阅读!
在微服务架构中,API网关作为核心组件之一,承担着请求路由、负载均衡、安全认证等重要功能。Spring Cloud Zuul作为一款功能强大的API网关解决方案,得到了广泛应用。本文将深入探讨Spring Cloud Zuul的各项功能,从基础配置到工作原理,再到多层负载和应用优化,全面解析其在实际应用中的最佳实践与实用技巧,为开发者提供一站式指导,助力其打造高性能、高可用的微服务架构。
一、Spring Cloud Zuul概述
Spring Cloud Zuul是Pivatal公司将Netflix公司 的Zuul方案整合于Spring Cloud体系的第一代网关组件,其在动态路由、监控、弹性、服务治理以及安全方面起着举足轻重的作用,是一个面向服务治理、服务编排的组件。对于Zuul的官方解释如下:(Home · Netflix/zuul Wiki · GitHub)
- Zuul is the front door for all requests from devices and web sites to the backend of
- the Netflix streaming application.
Zuul是从设备和网站到后端应用程序所有请求的前门,为内部服务提供可配置的对外URL到服务的映射关系,基于JVM的后端路由器。其底层基于Servlet,本质组件是一系列Filter所构成的结构链,也就是说Zuul的逻辑引擎与Filter可用其他基于JVM的语言编写,比如Groovy。基本具备以下功能:认证和鉴权+压力控制+金丝雀测试+动态路由+负载均衡+静态响应处理+主动流量控制+限流+文件上传+参数转换+其他逻辑与业务处理等。
我们必须对其原理和功能有充分认识,这样可以对它的某些特性进行优化且进行二次开发,定制适合自己应用的独特功能。在此,需注意一点,Zuul 1.0 是建立在Servlet上的同步阻塞架构,故在使用时对这部分的优化工作是必要的,Zuul 2.0 是建立在Servlet上的异步非阻塞架构,已经开源,但是Spring Cloud中国社区的笔者已通过官方Issue询问过Spring Cloud是否整合Zuul 2.0,得到的答案时否定的,所以,相对于第一代网关Zuul而言,Spring Cloud的第二代网关中间件Spring Cloud Gateway必将大放异彩。
二、Spring Cloud Zuul典型基本配置:路由配置和功能配置
(一)路由配置:配置简化与规则+路由通配符
1.单实例serviceId映射(可不短简化,具体如下)
- zuul:
- routes:
- client-a:
- path: /clent/**
- serviceId: client-a
可简化为:
- zuul:
- routes:
- client-a:
- path: /clent/**
更可简化为:
- zuul:
- routes:
- client-a:
2.单实例url映射
- zuul:
- routes:
- client-a:
- path: /clent/**
- url: http://localhost:8866 #client-a的地址,也就是此处可路由到具体的物理地址
3.多实例映射(Zuul默认使用Eureka集成的负载均衡功能,所以若使用该功能需要做如下两件事:见注释)
- zuul:
- routes:
- client-a:
- path: /ribbon/**
- serviceId: ribbon-route #第一件事:进行指定操作,见ribbon-route
- ribbon:
- eureka:
- enbaled: false #第二件事:禁止使用Eureka
- ribbon-route:
- ribbon:
- NIWSServiceListClassName: com.netflix.loadbalancer.ConfigurationBasedServerList
- NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule #Rinnon LB策略
- listOfServers: localhost:7070,localhost:7071 #客户端服务地址 for Rinnon LB策略
4.forward 本地跳转(针对一些逻辑处理)
- zuul:
- routes:
- client-a:
- path: /clent/**
- url: forward:/clientforZYF #直接跳转到特定方法上处理逻辑
在网关中编写对应逻辑接口:
- @RestController
- public class ZuulController {
- @GetMapping("/clientforZYF")
- public String clientforZYF() {
- return "本地跳转逻辑处理--------"
- }
- }
5.相同路径的加载规则(只会不建议使用,yml解释器工作时,如果一个映射路径对应多个服务,按照加载顺序最末的规则覆盖最前的规则)
- zuul:
- routes:
- client-a:
- path: /clent/**
- serviceId: client-a
- zuul:
- routes:
- client-a:
- path: /clent/**
- serviceId: client-b
6.路由通配符
在开发的时候要根据实际需求选择相应的通配符,选取的时候也要小心谨慎。
| 规则 | 释义 | 示例 |
|---|---|---|
| /** | 匹配任意数量的路径与字符 | /client/add,/client/mul,/client/a,/client/add/a, /client/mul/a/b,/client/del/d/f |
| /* | 匹配任意数量的字符 | /client/add,/client/mul,/client/a,/client/b |
| /? | 匹配单个字符 | /client/a,/client/b |
(二)功能配置
1.路由前缀(可以配置一个统一代理前缀)
- zuul:
- prefix: /pre #使用perfix指定前缀
- routes:
- client-a:
- path: /clent/**
- serviceId: client-a
2.服务屏蔽与路径屏蔽(避免某些服务或者路径的侵入)
- zuul:
- ignored-services: client-b #忽略的服务,对外屏蔽该服务
- ignored-patterns: /**/div/** #忽略的接口,屏蔽改接口
- prefix: /pre #使用perfix指定前缀
- routes:
- client-a:
- path: /clent/**
- serviceId: client-a
3.敏感头信息(如果系统需要与外部系统打交道时,在网关层可以指定具体敏感头,切断其与下层服务的交互)
- zuul:
- routes:
- client-a:
- path: /clent/**
- sensitiveHeagers: Cookie,Set-Cookie,Authorization
- serviceId: client-a
4.重定向问题(不暴露后端服务信息)
- zuul:
- add-host-header: true #不暴露后端服务client-a的相关地址信息
- routes:
- client-a:
- path: /clent/**
- serviceId: client-a
5.重试机制:此功能需要慎用,有一些接口要保证幂等性,需做好相关工作
- zuul:
- retryable: true #开启重试
- ribbon:
- MaxAutoRetries: 1 #同一个服务重试的次数(出去首次)
- MaxAutoRetriesNextServer: 1 #切换相同服务数量
三、Spring Cloud Zuul工作原理分析
Zuul的核心逻辑是由一系列紧密配合工作的Filter来实现的,没有Filter责任链就没有Zuul,更不可能构成丰富的“网关”,Zuul Filter 的主要特性有以下几点:
- Filter类型:决定了Filter在Filter链中的执行顺序, pre + route + post + error;
- Filter执行顺序:通过filterOrder()方法来设定执行顺序,一般根据业务的执行顺序需求,来设定自定义 Filter 的执行顺序。
- Filter 的执行条件:Filter 运行所需要的标准或条件。
- Filter 的执行效果:符合某个 Filter 执行条件,产生的执行效果。
Zuul 内部提供了一个动态读取、编译和运行这些 Filter 的机制。Filter 之间不直接通信,在请求线程中会通过 RequestContext 来共享状态,它的内部是用 ThreadLocal 实现的,当然你也可以在 Filter之间使用 ThreadLocal 来收集自己需要的状态或数据。Zuul 中不同类型 filter 的执行逻辑核心在 com.netflix.zuul.http.ZuulServlet 类中定义,这部分源码后面讲解。
官网给出的Zuul请求生命周期原图如下:
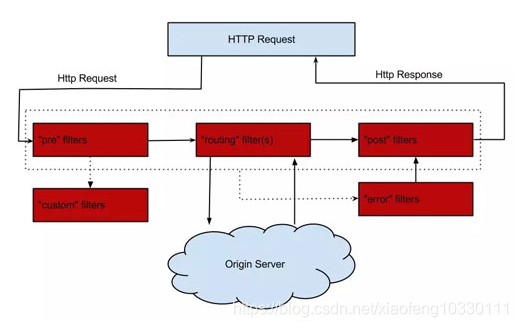
这张经典的官方流程图有些问题,其中 post Filter 抛错之后进入 error Filter,然后再进入 post Filter 是有失偏颇的。实际上 post Filter 抛错分两种情况:
- 在 post Filter 抛错之前,pre、route Filter 没有抛错,此时会进入 ZuulException 的逻辑,打印堆栈信息,然后再返回 status = 500 的 ERROR 信息。
- 在 post Filter 抛错之前,pre、route Filter 已有抛错,此时不会打印堆栈信息,直接返回status = 500 的 ERROR 信息。
也就是说,整个责任链流程终点不只是 post Filter,还可能是 error Filter,这里重新整理了一下,如图:
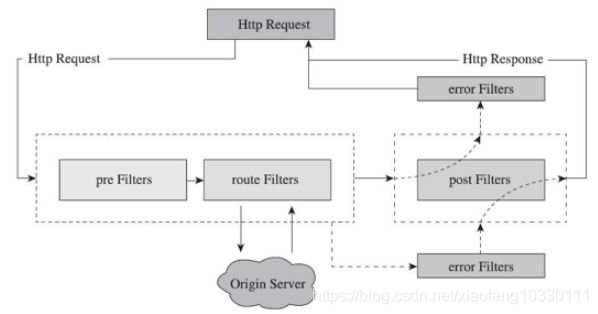
这样就比较直观地描述了 Zuul 关于 Filter 的请求生命周期。Zuul 中一共有四种不同生命周期的 Filter,分别是:
- pre:在 Zuul 按照规则路由到下级服务之前执行。如果需要对请求进行预处理,比如鉴权、限流等,都应考虑在此类 Filter 实现。
- route:这类 Filter 是 Zuul 路由动作的执行者,是 Apache Http Client 或 Netflix Ribbon 构建和发送原始 HTTP 请求的地方,目前已支持 Okhttp。
- post:这类 Filter 是在源服务返回结果或者异常信息发生后执行的,如果需要对返回信息做一些处理,则在此类 Filter 进行处理。
- error:在整个生命周期内如果发生异常,则会进入 error Filter,可做全局异常处理。
在实际项目中,往往需要自实现以上类型的 Filter 来对请求链路进行处理,根据业务的需求,选取相应生命周期的 Filter 来达成目的。在 Filter 之间,通过 com.netflix.zuul.context.RequestContext 类来进行通信,内部采用 ThreadLocal 保存每个请求的一些信息,包括请求路由、错误信息、HttpServletRequest、HttpServletResponse,这使得一些操作是十分可靠的,它还扩展了 ConcurrentHashMap,目的是为了在处理过程中保存任何形式的信息。
官方文档提到, Zuul Server 如果使用 @EnableZuulProxy 注解搭配 Spring Boot Actuator,会多两个管控端点(注意要开启对应的端点 /routes (/routes/details) + /filters)。在 /filters 接口中会返回很多的 Filter 信息,包括:类路径、执行顺序、是否被禁用、是否静态。可以组合成如下图:
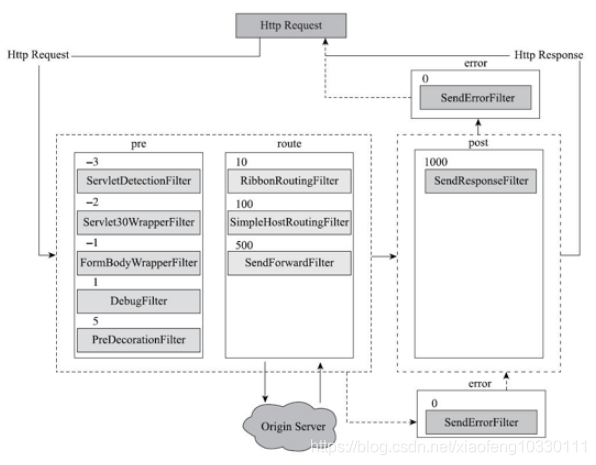
各内置Filter的详细说明如下表:
| 名称 | 类型 | 次序 | 描述 |
|---|---|---|---|
| ServletDetectionFilter | pre | -3 | 该过滤器用于检查请求是否通过Spring Dispatcher。检查后,通过isDispatcherServletRequest设置布尔值。 |
| Servlet30WrapperFilter | pre | -2 | 适配HttpServletRequest为Servlet30RequestWrapper对象 |
| FromBodyWrapperFilter | pre | -1 | 解析表单数据,并为请求重新编码。 |
| DebugFilter | pre | 1 | Debug路由标识,顾名思义,调试用的过滤器,可以通过zuul.debug.request=true,或在请求时,加上debug=true的参数,例如$ZUUL_HOST:ZUUL_PORT/path?debug=true 开启该过滤器。这样,该过滤器就会把RequestContext.setDebugRouting() 、RequestContext.setDebugRequest() 设为true。 |
| PreDecorationFilter | pre | 5 | 该过滤器根据提供的RouteLocator确定路由到的地址,以及怎样去路由。该路由器也可为后端请求设置各种代理相关的header。 |
| RibbonRoutingFilter | route | 10 | 该过滤器使用Ribbon,Hystrix和可插拔的HTTP客户端发送请求。 |
| SimpleHostRoutingFilter | route | 100 | 该过滤器通过Apache HttpClient向指定的URL发送请求。URL在RequestContext.getRouteHost() 中。 |
| SendForwardFilter | route | 500 | 该过滤器使用Servlet RequestDispatcher转发请求,转发位置存储在RequestContext.getCurrentContext().get("forward.to") 中。 |
| SendResponseFilter | post | 1000 | 将Zuul所代理的微服务的的响应写入当前响应。 |
| SendErrorFilter | error | 0 | 如果RequestContext.getThrowable() 不为null,那么默认就会转发到/error,也可以设置error.path属性修改默认的转发路径。 |
以上是使用 @EnableZuulProxy 注解后安装的 Filter,如果使用 @EnableZuulServer 将缺少 PreDecorationFilter、RibbonRoutingfilter、SimpleHostRoutingFilter。
如果你不想使用原生的这些功能,可以采取替代实现的方式,覆盖掉其原生代码,也可以采取禁用策略,语法如下:
zuul.
比如要禁用 SendErrorFilter,在配置文件中添加 zuul.SendErrorFilter.error.disable=true即可。
四、Spring Cloud Zuul多层负载思想
在Spring Cloud 微服务架构中,网关Zuul承担着请求转发的主要功能,对后端服务有举足轻重的作用。当业务体量猛增之后,得益于Spring Cloud的横向扩展能力,往往加节点、加机器就可以使得系统支撑性获得大大提升,但是仅仅加服务而不加网关会带带来网关性能瓶颈,因为单一Zuul的处理能力十分有限,故扩张节点往往连带Zuul一起扩张,然后再在请求上层加一层软负载。
(一)Nginx+Zuul所带来的痛点场景
软负载的策略往往使用Nginx解决问题,但是在线上运行时如果Zuul服务挂掉了,就会造成请求到改Zuul的请求直接失败,原因很简单,从Nginx到Zuul其实没有什么关联性,如果服务宕掉,Nginx还会将请求分过来,在Nginx没有采取应对措施的情况下是十分严重的事情,如下图。
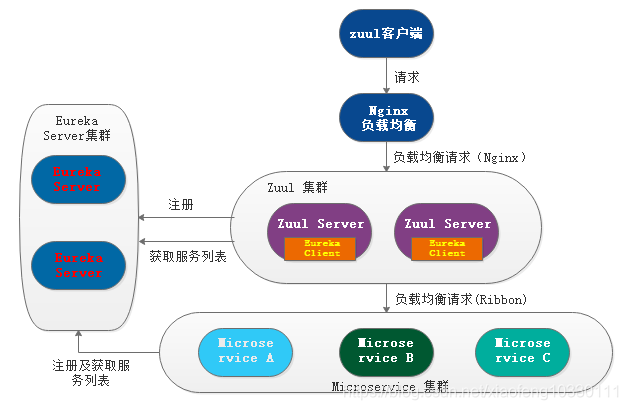
(二)OpenResty整合Nginx+Zuul实现动态感知增减机制
为了解决以上问题可以借助OpenResty整合的Nginx和Lua,使用Lua脚本模块与注册中心构建一个服务动态增减的机制,通过Lua获取注册中心状态为UP的服务,动态地加入到Nginx的负载均衡列表中,将其称之为“多层负载”。Spring Cloud已开源了相关Lua插件源码,如http://github.com/SpringCloud/nginx-zuul-dynamic-lb。
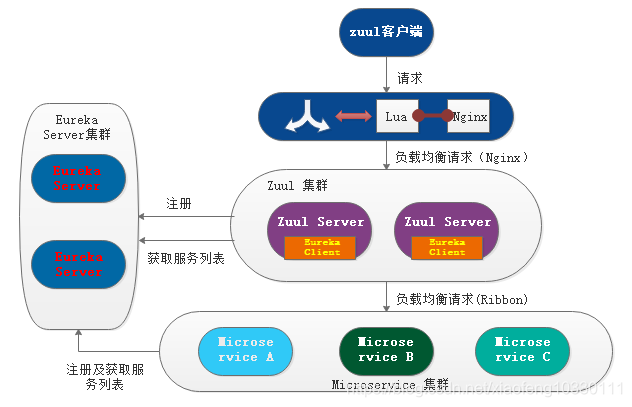
实现原理是使用Lua脚本定时根据配置的服务名与Eureka地址(在Eureka里面提供/eureka/apps/{serviceId}端点),去拉取该服务的信息,返回服务的注册信息,所以我们只需要取用状态为“UP”的服务,将它的地址加入Nginx负载列表即可。这样,可以使得Nginx与Zuul之间拥有一个动态感知的能力,不用手动配置Nginx与Zuul负载,这样对于应用弹性扩展极其友好。
具体主要代码如下:
- http {
- #缓存区大小
- lua_shared_dict dynamic_eureka_balancer 128m;
- init_worker_by_lua_block {
- -- 引入Lua插件文件
- local file = require "resty.dynamic_eureka_balancer"
- local balancer = file:new({dict_name="dynamic_eureka_balancer"})
- -- Eureka地址列表
- balancer.set_eureka_services_url({"127.0.0.1:8888","127.0.0.1:9999"})
- -- 配置初始被监听的服务名
- balancer.watch_service({"zuul","client"})
- }
-
- upstream springcloud_cn {
- server 127.0.0.1:6666;
- balancer_by_lua_block {
- -- 配置需要动态变化的服务名
- local service_name = "zuul"
- local file = require "resty.dynamic_eureka_balancer"
- local balancer = file:new({dict_name="dynamic_eureka_balancer"})
- -- balancer.ip_hash(service_name) -- IP Hash LB
- balancer.route_robin(service_name) -- Round Ribin LB
- }
- }
-
- server {
- listen 80;
- server_name localhost;
- location / {
- proxy_pass http://springcloud_cn/;
- proxy_set_header Host $http_host;
- proxy_set_header X-Real-IP $remote_addr;
- proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
- proxy_set_header X-Forwarded-Proto $scheme;
- }
- }
- }
五、Spring Cloud Zuul应用优化分析
Zuul 1.0 是一个基于JVM的后端路由器,同时是一个建立在Servlet上的同步阻塞架构,故在使用时对这部分的优化工作是必要的,根据实践经验,对Zuul的优化分为以下几个类型:
- 容器优化:内置容器Tomcat与Undertow的比较与参数设置;
- 组件优化:内部集成的组件优化,如Hytrix线程隔离、Ribbon、HttpClient与OkHttp选择;
- JVM参数优化:适合于网关应用的JVM参数建议;
- 内部优化:一些原生参数或者内部源码,以更适当的方式进行重写。
(一)容器优化
微服务兴起,spring boot 和spring cloud 越来越热的情况下,选择一款轻量级而性能优越的服务器是必要的选择。spring boot 完美集成了tomcat、jetty和undertow,通过对jetty和undertow服务器的分析以及测试,结合Zuul的特性,我们一般综合考虑使用Undertow,以下是三者压力测试对比:
| 服务器 | 命中 | 成功率 | 吞吐量 | 平均耗时 |
| Jetty | 11488 | 100% | 96.25 trans/sec | 0.00sec |
| 18393 | 100% | 153.92 trans/sec | 0.01sec | |
| 21484 | 99.99% | 179.51 trans/sec | 0.01sec | |
| Undertow | 11280 | 100% | 94.02 trans/sec | 0.00sec |
| 19442 | 100% | 163.35 trans/sec | 0.01sec | |
| 23277 | 100% | 195.54 tran/sec | 0.01sec | |
| Tomcat | 10845 | 100% | 90.95 trans/sec | 0.02sec |
| 21673 | 99.98% | 181 trans/sec | 0.01sec | |
| 25084 | 99.98% | 209.10 trans/sec | 0.01sec |
从中可以看出在高负载下Undertow的吞吐量高于Jetty而且随着压力增大Jetty和Undertow成功率差距会拉大。而在负载不是太大情况下服务器处理能力差不多,jetty还略微高于Undertow。
这里,我们给出web容器tomcat与undertow性能测试对比:web容器tomcat与undertow性能测试对比_undertower tomcat_LeeJohn_的博客-CSDN博客。
- 初始化:tomcat初始化线程数为32,undertow为19
- 运行时间:tomcat运行时间为36秒,undertow为22秒
- 结果对比:
- tomcat错误率0%,平均响应时间为3.45秒,99%响应时间在9.14秒内,最长响应时间为11.88秒,吞吐量为545/sec
- undertow错误率0%,平均响应时间为2.09秒,99%响应时间在3.99秒内,最长响应时间为5.21秒,吞吐量为897/sec
这里,可以将Spring Boot内嵌容器Tomcat替换为Undertow,Undertow提供阻塞或基于XNIO的非阻塞机制(包的大小不足1MB,内嵌模式运行时堆内存只有4MB)
- <!-- 下面的配置将使用undertow来做服务器而不是tomcat -->
- <dependency>
- <groupId>org.springframework.boot</groupId>
- <artifactId>spring-boot-starter-web</artifactId>
- <exclusions>
- <exclusion>
- <groupId>org.springframework.boot</groupId>
- <artifactId>spring-boot-starter-tomcat</artifactId>
- </exclusion>
- </exclusions>
- </dependency>
- <dependency>
- <groupId>org.springframework.boot</groupId>
- <artifactId>spring-boot-starter-undertow</artifactId>
- </dependency>
Undertow主要参数配置说明如下:
- server:
- port: 8081
- # 下面是配置undertow作为服务器的参数
- undertow:
- # 设置IO线程数, 它主要执行非阻塞的任务,它们会负责多个连接, 默认设置每个CPU核心一个线程
- io-threads: 4
- # 阻塞任务线程池, 当执行类似servlet请求阻塞操作, undertow会从这个线程池中取得线程,它的值设置取决于系统的负载
- worker-threads: 20
- # 以下的配置会影响buffer,这些buffer会用于服务器连接的IO操作,有点类似netty的池化内存管理
- # 每块buffer的空间大小,越小的空间被利用越充分
- buffer-size: 1024
- # 是否分配的直接内存
- direct-buffers: true
以上具体调优值的取值应以具体情况来定。
(二)组件优化
Zuul在Spring Cloud微服务体系中集成的组件最多,功能也很强大,主要用于智能路由,同时也支持认证、区域和内容感知路由,将多个底层服务聚合成统一的对外API,这就要求我们在使用Zuul时需要结合实际情况对内在的组件进行实际调优促使更好地支撑服务集群。
1.Hystrix组件调优
调优建议1:超时时间设置
Zuul默认集成了Hytrix熔断器,在第一次请求的时候,Zuul内部要初始化很多类信息,这是十分耗时的,而Hytrix恰恰对这个时间不买账,因此超过它的缺省超时时间1000ms后,就会返回错误信息,解决这个问题有以下两种方式:
方式一:加大超时时间
hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds=5000方式二:直接禁止掉Hytrix 的超时时间
hystrix.command.default.execution.timeout.enabled=false同时,建议通过CommandKey设置不同微服务的超时时间,对于zuul而言,CommandKey就是service id:
hystrix.command.[CommandKey].execution.isolation.thread.timeoutInMilliseconds调优建议2:线程隔离模式的选择:线程池模式or信号量模式
切换隔离模式的配置方式如下:
hystrix.command.default.execution.isolation.strategy=Thread | Semaphore总结一下:
- 当应用需要与外网交互,由于网络开销比较大与请求比较耗时,这时选用线程隔离策略,可以保证有剩余的容器线程可用;
- 当我们的应用只在内网交互,并且体量比较大,这时使用信号量隔离策略就比较好,因为响应比较快不会占用容器线程太长时间。
还有就是注意以下配置:
execution.isolation.semaphore.maxConcurrentRequestsHystrix最大的并发请求execution.isolation.semaphore.maxConcurrentRequests,这个值并非TPS、QPS、RPS等都是相对值,指的是1秒时间窗口内的事务/查询/请求,semaphore.maxConcurrentRequests是一个绝对值,无时间窗口,相当于亚毫秒级的。当请求达到或超过该设置值后,其其余就会被拒绝。默认值是100。
这个参数本来直接可以通过Hystrix的命名规则来设置,但被zuul重新设计了,使得在zuul中semaphores的最大并发请求有4个方法的参数可以设置,如果4个参数都存在优先级(1~4)由高到低:
- [优先级1]zuul.eureka.api.semaphore.maxSemaphores
- [优先级2]zuul.semaphore.max-semaphores
- [优先级3]hystrix.command.api.execution.isolation.semaphore.maxConcurrentRequests
- [优先级4]hystrix.command.default.execution.isolation.semaphore.maxConcurrentRequests
需要注意的是:在Camden.SR3版本的zuul中hystrix.command.default.execution.isolation.semaphore.maxConcurrentRequests设置不会起作用,这是因为在org.springframework.cloud.netflix.zuul.filters.ZuulProperties.HystrixSemaphore.maxSemaphores=100设置了默认值100,因此zuul.semaphore.max-semaphores的优先级高于hystrix.command.default.execution.isolation.semaphore.maxConcurrentRequests。
同时建议使用CommandKey设置最大信号量:
zuul.eureka.[commandKey].semaphore.maxSemaphores具体配置如下所示:
- zuul.host.maxTotalConnections: 200
- zuul.host.maxPerRouteConnections: 10
- #zuul.semaphore.max-Semaphores: 128
- #建议使用这种方式来设置,可以给每个不同的后端微服务设置不同的信号量
- zuul.eureka.[commandKey].semaphore.maxSemaphores: 128
2.Ribbon组件调优(以下为配置举例)
- ribbon:
- ConnectTimeout:1000
- ReadTimeout: 2000
- MaxAutoRetries: 1 #对第一次请求的服务的重试次数
- MaxAutoRetriesNextServer: 1 #要重试的下一个服务的最大数量(不包括第一个服务)
- OkToRetryOnAllOperations: true
对于Ribbon配置,需注意ConnectTimeout与ReadTimeout是当客户端使用HttpClient的时候生效,这个配置最终会被设置到HttpClient中去,在设置的时候要结合Hytrix的超时时间来综合考虑,针对应用场景,设置太小会导致很多请求失败,设置太大会导致熔断功能控制性变差,所以需要经过压力测试得来。
3.Zuul内置参数调优
zuul.host.maxTotalConnections
适用于ApacheHttpClient,如果是okhttp无效。每个服务的http客户端连接池最大连接,默认是200。
zuul.host.maxPerRouteConnections
适用于ApacheHttpClient,如果是okhttp无效。每个route可用的最大连接数,默认值是20。
打开zuul的重试配置:(特别注意zuul的重试配置需要依赖spring的retry,不然的话怎么配置都是徒劳)
- zuul:
- retryable: true
- <dependency>
- <groupId>org.springframework.retry</groupId>
- <artifactId>spring-retry</artifactId>
- </dependency>
(三)JVM参数优化
JVM调优是一个应用上线的必经之路。
对于Zuul来说,它起到的作用是“网关”,最需要就是吞吐量,故优化应以此为切入点来综合考虑,推介使用Parallel Scavenge收集器,老年代使用Parallel Old收集器,让网关彻底面向吞吐量。同时,建议让垃圾对象尽量在新生代被回收掉,以免进入老年代触发FGC(这也是一个技巧),这里使用的策略是在有限堆空间使用一个较大的新生代,并且Eden区要比Survivor区大。
以下是一些设置参数的注意事项:
1.UseAdaptiveSizePilicy参数
-XX:+UseAdaptiveSizePilicy,如果打来,JVM会自动选择年轻代区大小和相应的Survivor区比例,已达到目标系统规定的最低响应时间或者YGC频率,官方建议在使用并行收集器的时候一直打开;
但是实际在压力测试下效果并不理想,故建议将它关闭,改为-XX:-UseAdaptiveSizePilicy,在根据实际情况调整Eden区与Survivor区的比例。
2.TargetSurvivorRatio参数
XX:TargetSurvivorRatio, 即Survivor区对象的利用率,默认是50%,建议稍微调大,加大后YGC会看到明显的效果。
3.ScavengeBeforeFullGC参数
XX:+ScavengeBeforeFullGC,即FGC前先进行一次YGC,推荐使用该参数。
JVM参数优化是没有固定值的,不同压力环境下,不同JDK版本下的选择也不一样,注意:以上比较适合JDK1.7与1.8,JDK1.9以后建议使用G1。
以jar包模式启动JVM参数的设置方法如下:java -JVM参数 -jar application.jar
JVM优化是一个繁琐的过程,往往需要反复折腾多次,多尝试,在一定理论基础上敢于使用参数,就一定能够调出一套社和项目应用的JVM参数。
(四)内部优化
主要针对一些Zuul本身内置属性参数的调优处理,之前有提及。
其次就是对Zuul中有些Filter的设计并不是很合理的可以选择自实现替换掉或将其禁用:
zuul.<SimpleClassName>.<filterType>.disable=true六、Spring Cloud Zuul实用性技巧
1.饥饿加载
部署好应用组件以后,第一次请求Zuul调用往往会去注册中心读取服务注册表,初始化Ribbon负载信息,这是一种赖加载策略,过程很耗时,特别是服务过多的时候,为了避免这个问题,需要在启动Zuul的时候就饥饿加载应用程序上下文:
- zuul:
- ribbon:
- eager-load:
- enabled: true
2.请求体修改
由于某些原因,在请求道下游服务之前,需要对请求体进行修改,常见的是对form-data参数的增减,对application/json的修改,对请求体做UpperCase等,通过新增一个PRE类型的Filter对请求体进行修改就可以。(后续博客提供代码)
3.使用okhttp替换HttpClient
在当下微服务的场景下,HTTP请求方式成为了集成各服务的最佳方式。
在 Java 平台上,Java 标准库提供了 HttpURLConnection 类来支持 HTTP 通讯。不过 HttpURLConnection 本身的 API 不够友好,所提供的功能也有限。
在Spring Cloud中各个组件之间使用的通信协议都是HTTP,而HTTP客户端使用的是Apache公司的HttpClient,Apache HttpClient 库的功能强大,使用率也很高,基本上是 Java 平台中事实上的标准 HTTP 客户端,但是HttpClient难以扩展。
实际应用中我们建议基于springcloud采用Okhttp替换默认的HttpClient:主要是以下两方面:
- 1、Zuul中Okhttp应用;(后续博客提供代码)
- 2、Feign中Okhttp应用;(后续博客提供代码)
Okhttp的优势主要有以下几个方面:
- OkHttp 库的设计和实现的首要目标是高效。这也是选择 OkHttp 的重要理由之一。
- OkHttp 提供了对最新的 HTTP 协议版本 HTTP/2 和 SPDY 的支持,这使得对同一个主机发出的所有请求都可以共享相同的套接字连接。
- 如果 HTTP/2 和 SPDY 不可用,OkHttp 会使用连接池来复用连接以提高效率。
- OkHttp 提供了对 GZIP 的默认支持来降低传输内容的大小。
- OkHttp 也提供了对 HTTP 响应的缓存机制,可以避免不必要的网络请求。当网络出现问题时,OkHttp 会自动重试一个主机的多个 IP 地址。
4.重试机制
Zuul作为一个网关中间件,在出现偶然请求失败时进行适当重试是十分必要的,重试可以有效避免一些突发原因引起的请求丢失。Zuul中的重试机制是配合Spring Retry与Ribbon来使用的。(后续博客提供代码)
需要注意的是,在某些对幂等要求比较高的场景下,要慎用重试机制,因为如果没有相关处理的话,出现幂等问题是十分有可能的。
5.Header传递
如果需要对请求做一些处理,并把请求结果发给下游服务,但是又不能影响请求体的原始特性,Zuul中重要的类RequestContext可以帮我们解决这个问题,我们可以动态增加一个header来传递给下游微服务,这种方式与敏感头相反,需要注意传递信息的安全性。(后续博客提供代码)
6.整合Swagger2调试原服务
我们知道,Swagger2整合到项目中,可以非常方便地进行接口测试,是前后端对接效率提高。现在,我们可以在Zuul中整合Swagger2,通过Zuul配置文件配置的映射路径,来生成源服务接口的测试Dashboard。(后续博客提供代码)
swagger2 注解说明如:http://iyenn.com/rec/1691407.html
七、Spring Cloud Zuul主要的扩展功能(多级业务处理+使用Groovy编写Filier+权限集成+限流+动态路由+灰度发布+文件上传)
(一)多级业务处理
在Zuul的Filter链体系中,我们可以把一组业务逻辑细分,然后封装到一个个紧密结合的Filter中,设置处理顺序,组成一组全新的Filter链。
Zuul作为一个公用“网关”,原始的功能往往不能满足实际业务需求,为了解决这个问题,官方已预留API,使得我们能够实现自定义业务处理,加入到Zuul的逻辑处理。(后续博客提供实战代码)
第一步:实现自定义Filter,继承ZuulFilter类即可,并实现以下四个方法:
String filterType():设定Filter类型,可以设置为pre/route/post/error类型;
int filterOrder():使用返回值设定该Filter执行顺序;
boolean shouldFilter():使用返回值设定该Filter是否执行,可以作为开关来使用;
Object run():Filter里面核心执行逻辑,业务处理在此编写。
第二步:注入Spring Bean容器中。
(二)使用Groovy编写Filier
Groovy语言是 Apache 旗下的一门基于 JVM 平台的动态/敏捷编程语言,在语言的设计上它吸纳了 Python、Ruby 和 Smalltalk 语言的优秀特性,语法非常简练和优美,开发效率也非常高(编程语言的开发效率和性能是相互矛盾的,越高级的编程语言性能越差,因为意味着更多底层的封装,不过开发效率会更高,需结合使用场景做取舍)。并且,Groovy 可以与 Java 语言无缝对接,在写 Groovy 的时候如果忘记了语法可以直接按Java的语法继续写,也可以在 Java 中调用 Groovy 脚本,都可以很好的工作,这有效的降低了 Java 开发者学习 Groovy 的成本。Groovy 也并不会替代 Java,而是相辅相成、互补的关系,具体使用哪门语言这取决于要解决的问题和使用的场景。
相关简单学习见:https://www.cnblogs.com/amosli/p/3970810.html.
Zuul提供了Groovy的编译类com.netflix.zuul.groovy.GroovyCompiler,结合com.netflix.zuul.groovy.GroovyFileFilter类,可以使用Groovy来编写自定义的Filter。
在Zuul有没有存在的必要????-------------它可以不用编译(不用打进工程包),可以放在服务器上任意位置,可以再任何时候修改由它编写的Filter,且修改后还不用重启服务器,相当实用!!!(后续博客提供实战代码)
(三)权限集成
相比Spring Boot的Spring Security而言,比较流行的方式就是使用apache shiro是开源权限管理框架,如下图:
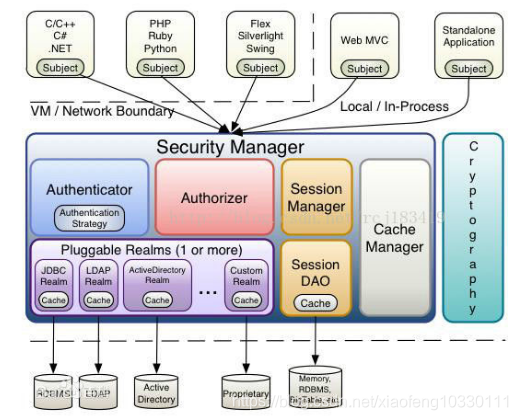
但是在Spring Cloud中面对成千上万的微服务而言且服务间无状态,使用apache shiro就力不从心了,在解决方案选择上,传统的譬如单点登录sso、分布式session,要么致使服务器集中化导致流量臃肿,要么需要实现一套复杂的存储同步机制,都不是最好的解决方案。所以,在Spring Cloud中,我们采取的更多的是以下两种实现方式:
实现方式1:自定义权限认证Filter
Zuul对请求转发全程可控,所以可以再REquestContext的基础上做任何事情,我们可以设置一个执行顺序靠前的Filter,就可以专门用于对请求特定内容做权限认证。
优点:实现灵活度高,可整合已有权限系统,对原始微服务化特别友好;
缺点:需要开发一套全新的逻辑,维护成本高,可能会是的调用链路变得絮乱。
实现方式2:Oauth2.0+JWT
OAuth简单说就是一种授权的协议,只要授权方和被授权方遵守这个协议去写代码提供服务,那双方就是实现了OAuth模式。举个例子,你想登录豆瓣去看看电影评论,但你从来没注册过豆瓣账号,又不想新注册一个再使用豆瓣,怎么办呢?不用担心,豆瓣已经为你这种懒人做了准备,用你的qq号可以授权给豆瓣进行登录。
OAuth在第三方应用与服务提供商之间设置了一个授权层。第三方应用不能直接登录服务提供商,只能登录授权层,以此将用户与客户端区分开来。第三方应用登录授权层所用的令牌,与用户的密码不同。用户可以在登录授权的时候,指定授权层令牌的权限范围和有效期。 第三方应用登录授权层以后,服务提供商根据令牌的权限范围和有效期,向第三方应用开放用户资源。
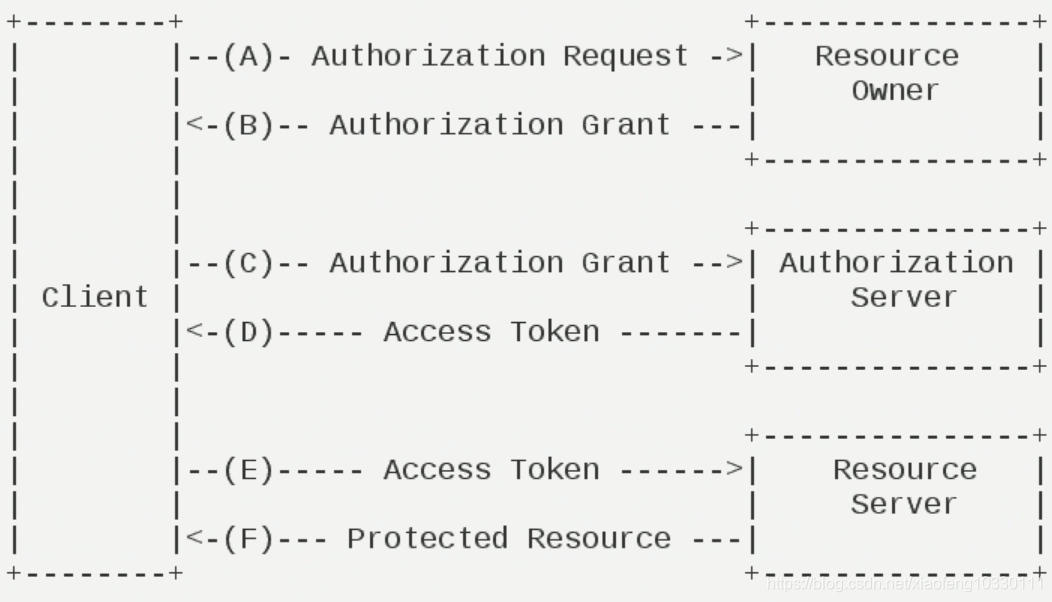
(A)用户打开客户端以后,客户端要求用户给予授权。
(B)用户同意给予客户端授权。
(C)客户端使用上一步获得的授权,向认证服务器申请令牌。
(D)认证服务器对客户端进行认证以后,确认无误,同意发放令牌。
(E)客户端使用令牌,向资源服务器申请获取资源。
(F)资源服务器确认令牌无误,同意向客户端开放资源。
不难看出来,上面六个步骤之中,B是关键,即用户怎样才能给于客户端授权。有了这个授权以后,客户端就可以获取令牌,进而凭令牌获取资源。
JSON Web Token (JWT)是一个开放标准(RFC 7519),它定义了一种紧凑的、自包含的方式,用于作为JSON对象在各方之间安全地传输信息。该信息可以被验证和信任,因为它是数字签名的。
下列场景中使用JSON Web Token是很有用的:
- Authorization (授权) : 这是使用JWT的最常见场景。一旦用户登录,后续每个请求都将包含JWT,允许用户访问该令牌允许的路由、服务和资源。单点登录是现在广泛使用的JWT的一个特性,因为它的开销很小,并且可以轻松地跨域使用。
- Information Exchange (信息交换) : 对于安全的在各方之间传输信息而言,JSON Web Tokens无疑是一种很好的方式。因为JWTs可以被签名,例如,用公钥/私钥对,你可以确定发送人就是它们所说的那个人。另外,由于签名是使用头和有效负载计算的,您还可以验证内容没有被篡改。
JSON Web Token由三部分组成,它们之间用圆点(.)连接。这三部分分别是:
- Header
- Payload
- Signature
因此,一个典型的JWT看起来是这个样子的:xxxxx.yyyyy.zzzzz (具体请查看相关书籍或博客)
用Token的好处:
- 无状态和可扩展性:Tokens存储在客户端。完全无状态,可扩展。我们的负载均衡器可以将用户传递到任意服务器,因为在任何地方都没有状态或会话信息。
- 安全:Token不是Cookie。(The token, not a cookie.)每次请求的时候Token都会被发送。而且,由于没有Cookie被发送,还有助于防止CSRF攻击。即使在你的实现中将token存储到客户端的Cookie中,这个Cookie也只是一种存储机制,而非身份认证机制。没有基于会话的信息可以操作,因为我们没有会话!
- token在一段时间以后会过期,这个时候用户需要重新登录。这有助于我们保持安全。还有一个概念叫token撤销,它允许我们根据相同的授权许可使特定的token甚至一组token无效。
OAuth2.0 + JWT的意义就在于,使用OAuth2.0协议思想拉取认证生成Token,使用JWT瞬时保存这个Token,在客户端与资源端进行对称或非对称加密,使得规约具有定时、定量的授权认证功能,免去Token存储所带来的安全或系统扩展问题。
(四)限流
1.限流算法
可以详见以下博客:
微服务架构-实现技术之三大关键要素3服务可靠性:服务访问失败的原因和应对策略+服务容错+服务隔离+服务限流+服务降级_张彦峰ZYF的博客-CSDN博客.
2.限流实战(后续博客提供实战代码)
最简单的方式就是使用定义Filter加上相关限流算法,可能考虑到Zuul多节点部署,因为算法的原因,需要一个K/V存储工具(推介使用Redis),如果Zuul只是单节点应用,限流方案就会广很多,完全可以将相关prefix放在内存中,方便快捷。
实战代推荐使用开箱即用工具spring-cloud-zuul-ratelimit,提供多种细粒度策略。
(五)动态路由
一个复杂的系统难免经历新服务上线过程,这个时候不能轻易停掉线上某些映射链路,Zuul在启动的时候将配置文件中的映射规则写入了内存,要新建映射规则,只能修改配置文件之后在重新启动Zuul应用。这样是有问题的,所以需要修改提供解决方案实现“动态路由”。了解动态路由实现原理剖析,也即对现有路由源码进行分析,从而实现修改,此处在实战代码中对路由源码进行分析。
实现方式1:结合Spring Cloud Config + BUS,动态刷新配置文件。
好处是不用Zuul来维护映射规则,可以随时修改,随时生效;
缺点是需要单独集成一些使用并不频繁的组件,Config无可视化界面,维护起来相对麻烦。
实现方式2:重写Zuul的配置读取方式,采用时间刷新机制,从数据库读取路由映射规则。(后续博客提供实战代码)
基于数据库,可轻松实现管理界面,灵活度较高。
(六)灰度发布
灰度发布是指在黑与白之间,能够平滑过渡的一种发布方式。AB Test 就是一种灰度发布方式,让一部分用户继续用 A,一部分用户开始用 B,如果用户对 B 没有什么反对意见,那么逐步扩大范围,把所有用户都迁移到 B 上面来。灰度发布可以保证整体系统的稳定,在初始灰度的时候就可以发现、调整问题,以保证其影响度。具体分为以下两种:
1. A/B Testing
A/B 测试是用来测试应用功能表现的方法,例如可用性、受欢迎程度、可见性等等。 A/B 测试通常用在应用的前端上,不过当然需要后端来支持。
A/B 测试与蓝绿部署的区别在于, A/B 测试目的在于通过科学的实验设计、采样样本代表性、流量分割与小流量测试等方式来获得具有代表性的实验结论,并确信该结论在推广到全部流量可信;蓝绿部署的目的是安全稳定地发布新版本应用,并在必要时回滚。
2.金丝雀发布
金丝雀部署也是灰度发布的一种方式,在原有版本可用的情况下,同时部署一个新版本应用作为「金丝雀」服务器来测试新版本的性能和表现,以保障整体系统稳定的情况下,尽早发现、调整问题。
矿井中的金丝雀:17 世纪,英国矿井工人发现,金丝雀对瓦斯这种气体十分敏感。空气中哪怕有极其微量的瓦斯,金丝雀也会停止歌唱;当瓦斯含量超过一定限度时,虽然鲁钝的人类毫无察觉,金丝雀却早已毒发身亡。当时在采矿设备相对简陋的条件下,工人们每次下井都会带上一只金丝雀作为瓦斯检测指标,以便在危险状况下紧急撤离。
灰度发布/金丝雀发布由以下几个步骤组成:
- 准备好部署各个阶段的工件,包括:构建工件,测试脚本,配置文件和部署清单文件。
- 从负载均衡列表中移除掉「金丝雀」服务器。
- 升级「金丝雀」应用(排掉原有流量并进行部署)。
- 对应用进行自动化测试。
- 将「金丝雀」服务器重新添加到负载均衡列表中(连通性和健康检查)。
- 如果「金丝雀」在线使用测试成功,升级剩余的其他服务器(否则就回滚)。
除此之外灰度发布还可以设置路由权重,动态调整不同的权重来进行新老版本的验证。
3.优势和不足
- 优势:用户体验影响小,灰度发布过程出现问题只影响少量用户。
- 不足:发布自动化程度不够,发布期间可引发服务中断。
对于Spring Cloud微服务生态来说,粒度一般是一个服务,往往通过使用某些带有特定标记的流量来充当发布过程中的“金丝雀”,并且目前已经有比较好的开源项目来做这个事。简单实现方式和结合开源项目实战见后续博客。(后续博客提供实战代码)
(七)文件上传功能
使用Zuul也可以进行文件上传处理,但是在文档中明确说明,Zuul在做文件上传的时候只支持小文件的上传,大文件上传会报错。但是Zuul给出了备选的方案,Zuul实质是一个Servlet,它会默认集成SpringMVC,当你上传小文件的时候,Zuul会将请求交给SpringMVC代理处理,但是如果你不想交给SpringMVC,此时你就需要使用Zuul提供Servlet路径绕过SpringMVC,这个Servlet的默认路径为:/zuul/*。当你提供的zuul.routes.customers=/customers/**,那么你访问"/zuul/customers/*"会直接访问对应微服务的接口。以下是常遇到的问题:
- Q : 对于上传中文文件会发生乱码
Zuul给出的方案是走Servlet而不是SpringMVC,也就是上传文件时,使用路径为/zuul/customers/*,customers指你配置的路由zuul.routes.customers=/customers/**,所有path中包含customers前缀的都会分发到customers这个微服务中。但是这样一来太不灵活了,因为有些需要经过Servlet,有些却不需要,所以我们可以直接设置ZuulServlet的路径为root,即zuul.servlet-path=/。
- Q:对于大文件的上传
Zuul针对大文件的上传会出现Requst Bad,但是在我实验的过程中没有走/zuul/customers/*却依然可以进行上传,只是当文件过大的时候会发生超时。但是通过设置超时时间就可以解决这个问题。但是这样带来后果无限的等待,调用任何的服务,只要服务出现错误就会一直等待,不能很好的进行熔断。
八、Spring Cloud Zuul核心源码分析
(一)Zuul 架构图
在zuul中, 整个请求的过程是这样的,首先将请求给zuulservlet处理,zuulservlet中有一个zuulRunner对象,该对象中初始化了RequestContext:作为存储整个请求的一些数据,并被所有的zuulfilter共享。zuulRunner中还有 FilterProcessor,FilterProcessor作为执行所有的zuulfilter的管理器。FilterProcessor从filterloader 中获取zuulfilter,而zuulfilter是被filterFileManager所加载,并支持groovy热加载,采用了轮询的方式热加载。有了这些filter之后,zuulservelet首先执行的Pre类型的过滤器,再执行route类型的过滤器,最后执行的是post 类型的过滤器,如果在执行这些过滤器有错误的时候则会执行error类型的过滤器。执行完这些过滤器,最终将请求的结果返回给客户端。
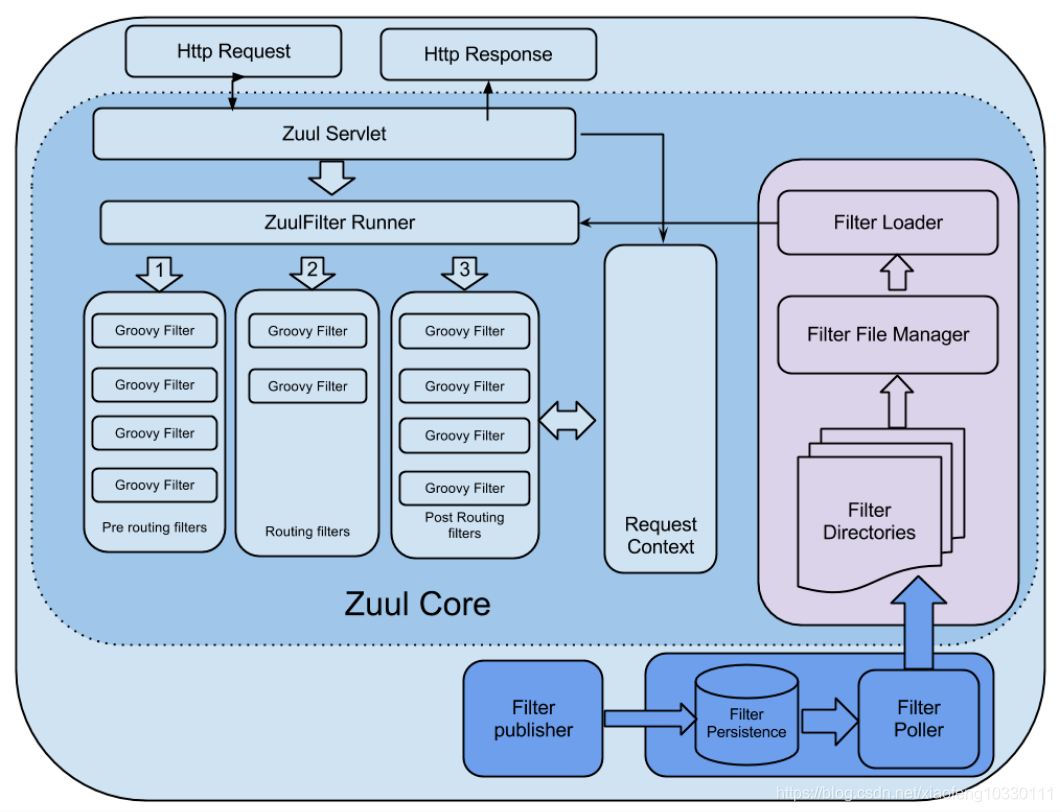
(二)zuul工作原理源码分析
在之前已经讲过,如何使用zuul,其中不可缺少的一个步骤就是在程序的启动类加上@EnableZuulProxy,该EnableZuulProxy类代码如下:
- @EnableCircuitBreaker
- @EnableDiscoveryClient
- @Target(ElementType.TYPE)
- @Retention(RetentionPolicy.RUNTIME)
- @Import(ZuulProxyConfiguration.class)
- public @interface EnableZuulProxy {
- }
其中,引用了ZuulProxyConfiguration,跟踪ZuulProxyConfiguration,该类注入了DiscoveryClient、RibbonCommandFactoryConfiguration用作负载均衡相关的。注入了一些列的filters,比如PreDecorationFilter、RibbonRoutingFilter、SimpleHostRoutingFilter,代码如如下:
- @Bean
- public PreDecorationFilter preDecorationFilter(RouteLocator routeLocator, ProxyRequestHelper proxyRequestHelper) {
- return new PreDecorationFilter(routeLocator, this.server.getServletPrefix(), this.zuulProperties,
- proxyRequestHelper);
- }
-
- // route filters
- @Bean
- public RibbonRoutingFilter ribbonRoutingFilter(ProxyRequestHelper helper,
- RibbonCommandFactory ribbonCommandFactory) {
- RibbonRoutingFilter filter = new RibbonRoutingFilter(helper, ribbonCommandFactory, this.requestCustomizers);
- return filter;
- }
-
- @Bean
- public SimpleHostRoutingFilter simpleHostRoutingFilter(ProxyRequestHelper helper, ZuulProperties zuulProperties) {
- return new SimpleHostRoutingFilter(helper, zuulProperties);
- }
它的父类ZuulConfiguration ,引用了一些相关的配置。在缺失zuulServlet bean的情况下注入了ZuulServlet,该类是zuul的核心类。
- @Bean
- @ConditionalOnMissingBean(name = "zuulServlet")
- public ServletRegistrationBean zuulServlet() {
- ServletRegistrationBean servlet = new ServletRegistrationBean(new ZuulServlet(),
- this.zuulProperties.getServletPattern());
- // The whole point of exposing this servlet is to provide a route that doesn't
- // buffer requests.
- servlet.addInitParameter("buffer-requests", "false");
- return servlet;
- }
同时也注入了其他的过滤器,比如ServletDetectionFilter、DebugFilter、Servlet30WrapperFilter,这些过滤器都是pre类型的。
- @Bean
- public ServletDetectionFilter servletDetectionFilter() {
- return new ServletDetectionFilter();
- }
-
- @Bean
- public FormBodyWrapperFilter formBodyWrapperFilter() {
- return new FormBodyWrapperFilter();
- }
-
- @Bean
- public DebugFilter debugFilter() {
- return new DebugFilter();
- }
-
- @Bean
- public Servlet30WrapperFilter servlet30WrapperFilter() {
- return new Servlet30WrapperFilter();
- }
-
它也注入了post类型的,比如 SendResponseFilter,error类型,比如 SendErrorFilter,route类型比如SendForwardFilter,代码如下:
- @Bean
- public SendResponseFilter sendResponseFilter() {
- return new SendResponseFilter();
- }
-
- @Bean
- public SendErrorFilter sendErrorFilter() {
- return new SendErrorFilter();
- }
-
- @Bean
- public SendForwardFilter sendForwardFilter() {
- return new SendForwardFilter();
- }
初始化ZuulFilterInitializer类,将所有的filter 向FilterRegistry注册。
- @Configuration
- protected static class ZuulFilterConfiguration {
-
- @Autowired
- private Map
filters; -
- @Bean
- public ZuulFilterInitializer zuulFilterInitializer(
- CounterFactory counterFactory, TracerFactory tracerFactory) {
- FilterLoader filterLoader = FilterLoader.getInstance();
- FilterRegistry filterRegistry = FilterRegistry.instance();
- return new ZuulFilterInitializer(this.filters, counterFactory, tracerFactory, filterLoader, filterRegistry);
- }
-
- }
而FilterRegistry管理了一个ConcurrentHashMap,用作存储过滤器的,并有一些基本的CURD过滤器的方法,代码如下:
- public class FilterRegistry {
-
- private static final FilterRegistry INSTANCE = new FilterRegistry();
-
- public static final FilterRegistry instance() {
- return INSTANCE;
- }
-
- private final ConcurrentHashMap
filters = new ConcurrentHashMap(); -
- private FilterRegistry() {
- }
-
- public ZuulFilter remove(String key) {
- return this.filters.remove(key);
- }
-
- public ZuulFilter get(String key) {
- return this.filters.get(key);
- }
-
- public void put(String key, ZuulFilter filter) {
- this.filters.putIfAbsent(key, filter);
- }
-
- public int size() {
- return this.filters.size();
- }
-
- public Collection
getAllFilters() { - return this.filters.values();
- }
-
- }
FilterLoader类持有FilterRegistry,FilterFileManager类持有FilterLoader,所以最终是由FilterFileManager注入 filterFilterRegistry的ConcurrentHashMap的。FilterFileManager到开启了轮询机制,定时的去加载过滤器,代码如下:
- void startPoller() {
- poller = new Thread("GroovyFilterFileManagerPoller") {
- public void run() {
- while (bRunning) {
- try {
- sleep(pollingIntervalSeconds * 1000);
- manageFiles();
- } catch (Exception e) {
- e.printStackTrace();
- }
- }
- }
- };
- poller.setDaemon(true);
- poller.start();
- }
Zuulservlet作为类似于Spring MVC中的DispatchServlet,起到了前端控制器的作用,所有的请求都由它接管。它的核心代码如下:
- @Override
- public void service(javax.servlet.ServletRequest servletRequest, javax.servlet.ServletResponse servletResponse) throws ServletException, IOException {
- try {
- init((HttpServletRequest) servletRequest, (HttpServletResponse) servletResponse);
-
- // Marks this request as having passed through the "Zuul engine", as opposed to servlets
- // explicitly bound in web.xml, for which requests will not have the same data attached
- RequestContext context = RequestContext.getCurrentContext();
- context.setZuulEngineRan();
-
- try {
- preRoute();
- } catch (ZuulException e) {
- error(e);
- postRoute();
- return;
- }
- try {
- route();
- } catch (ZuulException e) {
- error(e);
- postRoute();
- return;
- }
- try {
- postRoute();
- } catch (ZuulException e) {
- error(e);
- return;
- }
-
- } catch (Throwable e) {
- error(new ZuulException(e, 500, "UNHANDLED_EXCEPTION_" + e.getClass().getName()));
- } finally {
- RequestContext.getCurrentContext().unset();
- }
- }
跟踪init(),可以发现这个方法为每个请求生成了RequestContext,RequestContext继承了ConcurrentHashMap
RequestContext类在存储了很多重要的信息,包括HttpServletRequest、HttpServletRespons、ResponseDataStream、ResponseStatusCode等。 RequestContext对象在处理请求的过程中,一直存在,所以这个对象为所有Filter共享。
从ZuulServlet的service()方法可知,它是先处理pre()类型的处理器,然后在处理route()类型的处理器,最后再处理post类型的处理器。
首先来看一看pre()的处理过程,它会进入到ZuulRunner,该类的作用是将请求的HttpServletRequest、HttpServletRespons放在RequestContext类中,并包装了一个FilterProcessor,代码如下:
- public void init(HttpServletRequest servletRequest, HttpServletResponse servletResponse) {
-
- RequestContext ctx = RequestContext.getCurrentContext();
- if (bufferRequests) {
- ctx.setRequest(new HttpServletRequestWrapper(servletRequest));
- } else {
- ctx.setRequest(servletRequest);
- }
-
- ctx.setResponse(new HttpServletResponseWrapper(servletResponse));
-
- }
-
-
- public void preRoute() throws ZuulException {
- FilterProcessor.getInstance().preRoute();
- }
而FilterProcessor类为调用filters的类,比如调用pre类型所有的过滤器:
- public void preRoute() throws ZuulException {
- try {
- runFilters("pre");
- } catch (ZuulException e) {
- throw e;
- } catch (Throwable e) {
- throw new ZuulException(e, 500, "UNCAUGHT_EXCEPTION_IN_PRE_FILTER_" + e.getClass().getName());
- }
- }
跟踪runFilters()方法,可以发现,它最终调用了FilterLoader的getFiltersByType(sType)方法来获取同一类的过滤器,然后用for循环遍历所有的ZuulFilter,执行了 processZuulFilter()方法,跟踪该方法可以发现最终是执行了ZuulFilter的方法,最终返回了该方法返回的Object对象。
- public Object runFilters(String sType) throws Throwable {
- if (RequestContext.getCurrentContext().debugRouting()) {
- Debug.addRoutingDebug("Invoking {" + sType + "} type filters");
- }
- boolean bResult = false;
- List
list = FilterLoader.getInstance().getFiltersByType(sType); - if (list != null) {
- for (int i = 0; i < list.size(); i++) {
- ZuulFilter zuulFilter = list.get(i);
- Object result = processZuulFilter(zuulFilter);
- if (result != null && result instanceof Boolean) {
- bResult |= ((Boolean) result);
- }
- }
- }
- return bResult;
- }
route、post类型的过滤器的执行过程和pre执行过程类似。
注:以上所有只做理论性的总结与分析,相关实战代码会在后面的博客中和github中逐步增加。
参考书籍、文献和资料
【1】郑天民. 微服务设计原理与架构. 北京:人民邮电出版社,2018.
【2】徐进,叶志远,钟尊发,蔡波斯等. 重新定义Spring Cloud. 北京:机械工业出版社. 2018.
【3】Zuul Filter_zuulfilter_大漠知秋的博客-CSDN博客.
【4】提示信息.
【5】Zuul的高可用 | 周立的博客 - 关注Spring Cloud、Docker.
【6】Spring Boot 内嵌容器Undertow参数设置_ZhiYuanYe的博客-CSDN博客.
【7】SpringBoot使用Undertow做服务器_springboot 使用und_芸灵fly的博客-CSDN博客.
【8】https://www.cnblogs.com/interfacehwx/p/9920816.html.
【9】深入理解Zuul之源码解析_zuul源码如何梳理_方志朋的博客-CSDN博客.
【10】Zuul进阶篇-okhttp替换httpclient_帅天下的博客-CSDN博客.
【11】Zuul中整合Swagger2,实现对源服务API测试-阿里云开发者社区.
【12】Groovy 语言快速入门 - 简书.
【13】https://www.cnblogs.com/amosli/p/3970810.html.
【14】权限控制方案之——集成shiro_软件集成权限控制_我的推想毫无逻辑的博客-CSDN博客.
【15】https://www.cnblogs.com/flashsun/p/7424071.html.
【16】https://www.cnblogs.com/gavincoder/p/8999954.html.
【17】https://www.cnblogs.com/cjsblog/p/9277677.html.
评论记录:
回复评论: