
前言
本文一开始是属于此文的第四部分,但为避免原文篇幅过长,故把该部分抽取出来独立成文
过程中解读斯坦福人形机器人humanplus的代码时,还是充满乐趣的,比如又遇到了熟悉的ppo,想到
- 去年上半年啃了半年的ChatGPT原理没有白啃
- 去年下半年带队做大模型应用,直接促成我司「七月在线」从教育公司往科技公司的转型
- 今年上半年则是具身智能
也算是可谓三者合一、步步为赢了
大模型时代,技术更迭速度超过以往任何时期,而个人认为机器人(具身智能)将是未来几年最大的趋势,包括我司机器人线下营曾一天连报5人(开营后,将邀请一波人加入我司机器人开发队伍),期待与更多有缘人共同开发机器人以服务更多工厂
对于humanplus的整个代码框架,总计包含以下五个部分
- Humanoid Shadowing Transformer (HST)
这个部分的代码是基于仿真的强化学习实现,使用了legged_gym和rsl_rl
需要先安装IsaacGym v4,并将isaacgym文件夹放置在HST文件夹中
提供了训练HST的示例命令,以及如何使用训练好的策略 - Humanoid Imitation Transformer (HIT)
这部分代码用于现实世界中的模仿学习,基于ACT repo和Mobile ALOHA repo
提供了安装指南,包括创建conda环境和安装所需的Python库 - Pose Estimation
身体姿态估计使用WHAM,手部姿态估计使用HaMeR - Hardware Codebase
硬件代码基于unitree_ros2,适用于与真实机器人的交互
提供了安装指南,包括创建conda环境、安装unitree_sdk和unitree_ros2 - Example Usages
提供了训练HST和HIT的具体命令示例。
对于硬件代码,提供了如何放置训练好的策略文件以及如何运行硬件脚本的示例
第一部分 low-level控制策略Humanoid Shadowing Transformer(HST)
为了对整个humanplus的代码做更好的解读,先把整体的代码结构梳理一下(如下4张图所示,总计4个部分,前3个部分都是HST相关,第4个部分则是HIT相关)
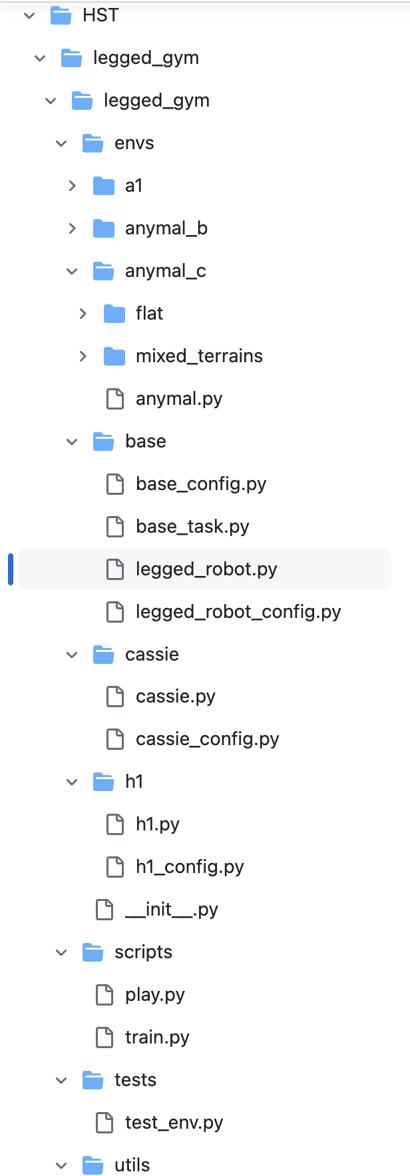
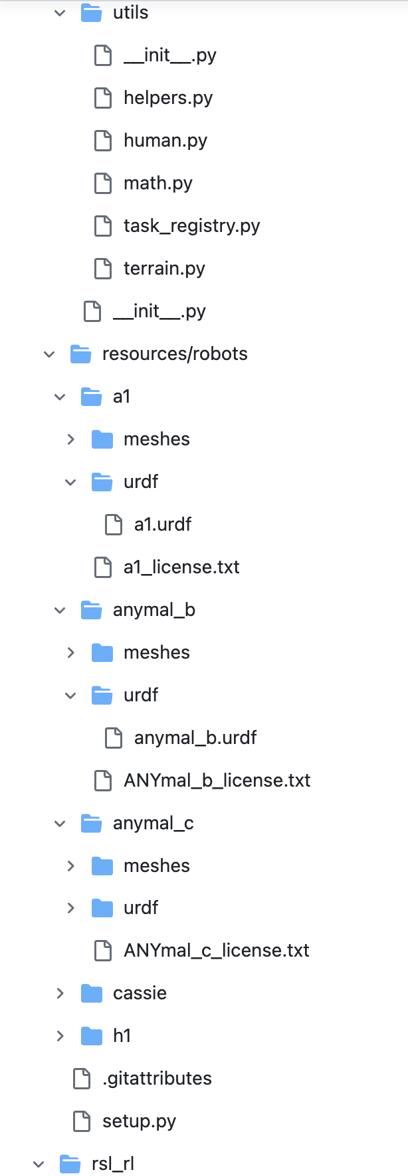

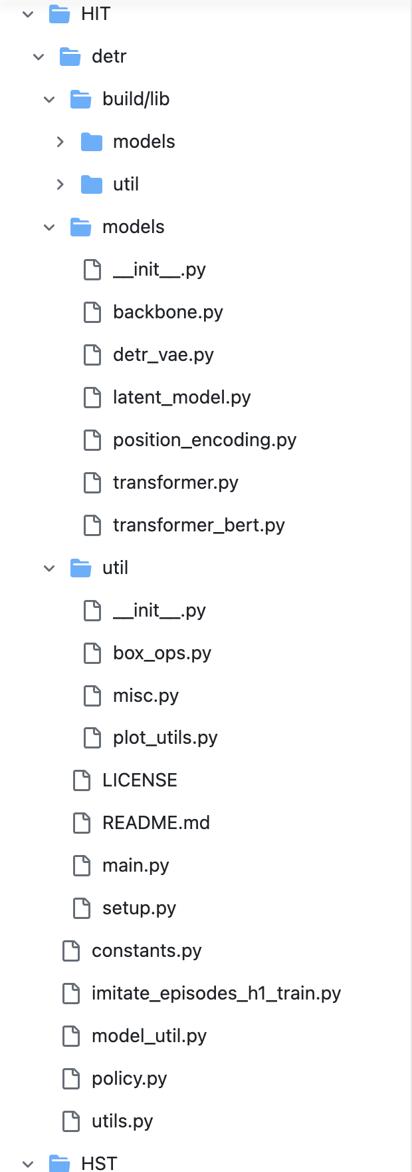
1.1 HST/rsl_rl/rsl_rl
在humanplus/HST/rsl_rl/rsl_rl文件夹里有以下分文件夹
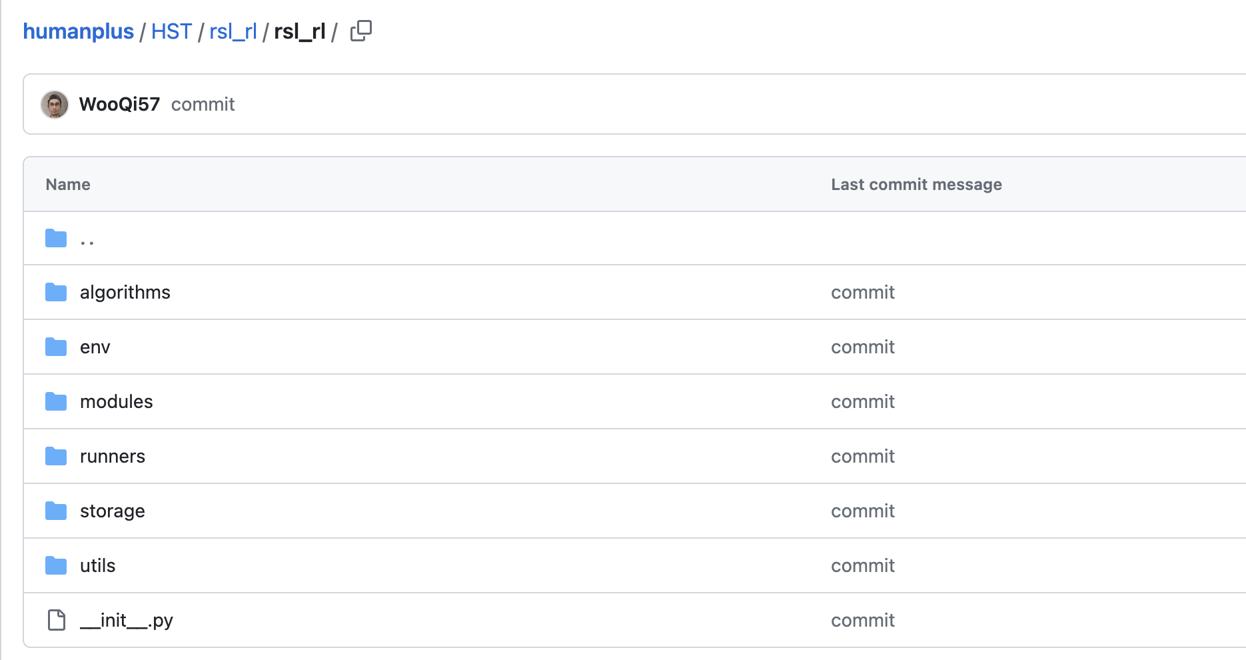
1.1.1 HST/rsl_rl/rsl_rl/algorithms/ppo.py
其中,algorithms文件夹里有两个文件:__init__.py、ppo.py
接下来,咱们重点看下HST/rsl_rl/rsl_rl/algorithms/ppo.py
首先是一些类的导入、与PPO类的定义
- import torch # 导入 PyTorch 库
- import torch.nn as nn # 导入 PyTorch 神经网络模块
- import torch.optim as optim # 导入 PyTorch 优化模块
-
- from rsl_rl.modules import ActorCriticTransformer # 从 rsl_rl.modules 导入 ActorCriticTransformer 类
- from rsl_rl.storage import RolloutStorage # 从 rsl_rl.storage 导入 RolloutStorage 类
-
- class PPO: # 定义 PPO 类
- actor_critic: ActorCriticTransformer # 定义 actor_critic 变量类型为 ActorCriticTransformer
- def __init__(self, # 定义 PPO 类的初始化函数
- actor_critic, # 定义 actor_critic 参数
- num_learning_epochs=1, # 定义 num_learning_epochs 参数,默认值为1
- num_mini_batches=1, # 定义 num_mini_batches 参数,默认值为1
- clip_param=0.2, # 定义 clip_param 参数,默认值为0.2
- gamma=0.998, # 定义 gamma 参数,默认值为0.998
- lam=0.95, # 定义 lam 参数,默认值为0.95
- value_loss_coef=1.0, # 定义 value_loss_coef 参数,默认值为1.0
- entropy_coef=0.0, # 定义 entropy_coef 参数,默认值为0.0
- learning_rate=1e-3, # 定义 learning_rate 参数,默认值为1e-3
- max_grad_norm=1.0, # 定义 max_grad_norm 参数,默认值为1.0
- use_clipped_value_loss=True, # 定义 use_clipped_value_loss 参数,默认值为 True
- schedule="fixed", # 定义 schedule 参数,默认值为 "fixed"
- desired_kl=0.01, # 定义 desired_kl 参数,默认值为 0.01
- device='cpu', # 定义 device 参数,默认值为 'cpu'
- ):
-
- self.device = device # 初始化 self.device 为传入的 device 参数
-
- self.desired_kl = desired_kl # 初始化 self.desired_kl 为传入的 desired_kl 参数
- self.schedule = schedule # 初始化 self.schedule 为传入的 schedule 参数
- self.learning_rate = learning_rate # 初始化 self.learning_rate 为传入的 learning_rate 参数
-
- # PPO components
- # 最上面PPO类里一系列参数的self初始化
-
- # PPO parameters
- # 最上面PPO类里一系列参数的self初始化

//..
待补充
-
- def init_storage(self, num_envs, num_transitions_per_env, actor_obs_shape, critic_obs_shape, action_shape):
- # 初始化存储
- self.storage = RolloutStorage(num_envs, num_transitions_per_env, actor_obs_shape, critic_obs_shape, action_shape, self.device)
-
- def test_mode(self): # 定义测试模式函数
- self.actor_critic.test() # 设置 actor_critic 为测试模式
-
- def train_mode(self): # 定义训练模式函数
- self.actor_critic.train() # 设置 actor_critic 为训练模式
-
- def act(self, obs, critic_obs): # 定义 act 函数
- if self.actor_critic.is_recurrent: # 如果 actor_critic 是循环的
- self.transition.hidden_states = self.actor_critic.get_hidden_states() # 获取隐藏状态
-
- # Compute the actions and values
- # 计算动作和值
- self.transition.actions = self.actor_critic.act(obs).detach() # 获取动作
- self.transition.values = self.actor_critic.evaluate(critic_obs).detach() # 获取值
- self.transition.actions_log_prob = self.actor_critic.get_actions_log_prob(self.transition.actions).detach() # 获取动作的对数概率
- self.transition.action_mean = self.actor_critic.action_mean.detach() # 获取动作均值
- self.transition.action_sigma = self.actor_critic.action_std.detach() # 获取动作标准差
-
- # need to record obs and critic_obs before env.step()
- # 在环境步之前需要记录 obs 和 critic_obs
- self.transition.observations = obs # 记录观察
- self.transition.critic_observations = critic_obs # 记录评论员观察
- return self.transition.actions # 返回动作
//..
待补充
-
- def process_env_step(self, rewards, dones, infos): # 定义处理环境步函数
- self.transition.rewards = rewards.clone() # 克隆奖励
- self.transition.dones = dones # 记录完成状态
- # Bootstrapping on time outs
- # 对超时进行引导
- if 'time_outs' in infos: # 如果信息中有 'time_outs'
- self.transition.rewards += self.gamma * torch.squeeze(self.transition.values * infos['time_outs'].unsqueeze(1).to(self.device), 1) # 更新奖励
-
- # Record the transition
- # 记录过渡
- self.storage.add_transitions(self.transition) # 添加过渡到存储中
- self.transition.clear() # 清除过渡数据
- self.actor_critic.reset(dones) # 重置 actor_critic
-
- def compute_returns(self, last_critic_obs): # 定义计算回报函数
- last_values = self.actor_critic.evaluate(last_critic_obs).detach() # 计算最后的值
- self.storage.compute_returns(last_values, self.gamma, self.lam) # 计算回报
//..
接下来重点分析下,这个update函数
- 首先,它根据模型是否是循环的来选择不同的mini-batch生成器。然后,它遍历生成器产生的每个mini-batch,对每个batch进行一系列的操作
在每个mini-batch中,首先使用[`actor_critic`]模型对观察值进行行动,并获取行动的对数概率,评估价值,以及行动的均值和标准差- def update(self): # 定义更新函数
- mean_value_loss = 0 # 初始化平均值损失
- mean_surrogate_loss = 0 # 初始化平均代理损失
- if self.actor_critic.is_recurrent: # 如果 actor_critic 是循环的
- generator = self.storage.recurrent_mini_batch_generator(self.num_mini_batches, self.num_learning_epochs) # 使用循环小批量生成器
- else: # 否则
- generator = self.storage.mini_batch_generator(self.num_mini_batches, self.num_learning_epochs) # 使用小批量生成器
- for obs_batch, critic_obs_batch, actions_batch, target_values_batch, advantages_batch, returns_batch, old_actions_log_prob_batch, \
- old_mu_batch, old_sigma_batch, hid_states_batch, masks_batch in generator: # 迭代生成器中的数据
- # 获取动作概率和价值
- self.actor_critic.act(obs_batch, masks=masks_batch, hidden_states=hid_states_batch[0]) # 获取动作
- actions_log_prob_batch = self.actor_critic.get_actions_log_prob(actions_batch) # 获取动作的对数概率
- value_batch = self.actor_critic.evaluate(critic_obs_batch, masks=masks_batch, hidden_states=hid_states_batch[1]) # 获取值
- mu_batch = self.actor_critic.action_mean # 获取动作均值
- sigma_batch = self.actor_critic.action_std # 获取动作标准差
- entropy_batch = self.actor_critic.entropy # 获取熵
运行 - 如果设置了期望的KL散度并且调度策略为'adaptive',则计算当前策略和旧策略之间的KL散度,并根据KL散度的大小动态调整学习率
- # KL
- if self.desired_kl != None and self.schedule == 'adaptive': # 如果期望的 KL 不为 None 且调度为 'adaptive'
- with torch.inference_mode(): # 使用推理模式
- kl = torch.sum(
- torch.log(sigma_batch / old_sigma_batch + 1.e-5) + (torch.square(old_sigma_batch) + torch.square(old_mu_batch - mu_batch)) / (2.0 * torch.square(sigma_batch)) - 0.5, axis=-1) # 计算 KL 散度
- kl_mean = torch.mean(kl) # 计算 KL 散度的均值
- # 如果 KL 散度均值大于期望的 KL 的两倍
- if kl_mean > self.desired_kl * 2.0:
- self.learning_rate = max(1e-5, self.learning_rate / 1.5) # 减小学习率
- # 如果 KL 散度均值小于期望的 KL 的一半且大于 0.0
- elif kl_mean < self.desired_kl / 2.0 and kl_mean > 0.0:
- self.learning_rate = min(1e-2, self.learning_rate * 1.5) # 增大学习率
- for param_group in self.optimizer.param_groups: # 对于优化器中的每个参数组
- param_group['lr'] = self.learning_rate # 更新学习率
上述代码是典型的自适应KL惩罚的过程
上述公式中的是怎么取值的呢,事实上,
- 先设一个可以接受的 KL 散度的最大值
假设优化完以后,KL 散度值太大导致
,意味着
与
差距过大(即学习率/步长过大),也就代表后面惩罚的项
惩罚效果太弱而没有发挥作用,故增大惩罚把
- 再设一个 KL 散度的最小值
如果优化完,意味着
至于详细了解请查看本博客内此文《强化学习极简入门:通俗理解MDP、DP MC TC和Q学习、策略梯度、PPO》的4.4.1 什么是近端策略优化PPO与PPO-penalty
![J_{\mathrm{PPO}}^{\theta^{\prime}}(\theta)=\mathbb{E}_{\left(s_{t}, a_{t}\right) \sim \pi_{\theta^{\prime}}}\left[\frac{p_{\theta}\left(a_{t} \mid s_{t}\right)}{p_{\theta^{\prime}}\left(a_{t} \mid s_{t}\right)} A^{\theta^{\prime}}\left(s_{t}, a_{t}\right)\right]-\beta \mathrm{KL}\left(\theta, \theta^{\prime}\right)](https://img1.iyenn.com/thumb02/c4a7c49ea7h6b2h6/7296172118582218166.jpeg)
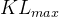
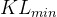
- 接下来,计算actor损失(surrogate loss),这是PPO算法的核心部分。它首先计算新旧策略的比率,然后计算未裁剪和裁剪的代理损失,并取两者的最大值作为最终的代理损失
- # Surrogate loss
- # 代理损失
- ratio = torch.exp(actions_log_prob_batch - torch.squeeze(old_actions_log_prob_batch)) # 计算比率
- surrogate = -torch.squeeze(advantages_batch) * ratio # 计算代理损失
- surrogate_clipped = -torch.squeeze(advantages_batch) * torch.clamp(ratio, 1.0 - self.clip_param, 1.0 + self.clip_param) # 计算剪切后的代理损失
- surrogate_loss = torch.max(surrogate, surrogate_clipped).mean() # 计算代理损失的均值
其实上面的代码就是对近端策略优化裁剪PPO-clip的直接实现,其对应的公式如下(详细了解请查看本博客内此文《强化学习极简入门:通俗理解MDP、DP MC TC和Q学习、策略梯度、PPO》的第4.4.2节PPO算法的另一个变种:近端策略优化裁剪PPO-clip)
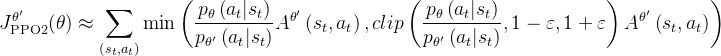
- 然后,计算价值函数的损失。如果设置了使用裁剪价值损失,那么会计算裁剪的价值损失和未裁剪的价值损失,并取两者的最大值作为最终的价值损失。否则,直接计算未裁剪的价值损失
- # Value function loss
- # 价值函数损失
- if self.use_clipped_value_loss:
- value_clipped = target_values_batch + (value_batch - target_values_batch).clamp(-self.clip_param, self.clip_param)
- value_losses = (value_batch - returns_batch).pow(2)
- value_losses_clipped = (value_clipped - returns_batch).pow(2)
- value_loss = torch.max(value_losses, value_losses_clipped).mean()
- else:
- value_loss = (returns_batch - value_batch).pow(2).mean()
- loss = surrogate_loss + self.value_loss_coef * value_loss - self.entropy_coef * entropy_batch.mean()
其实就是之前这篇文章《从零实现带RLHF的类ChatGPT:逐行解析微软DeepSpeed Chat的源码》中3.6中AC架构下的PPO训练:在加了β惩罚且截断后的RM之下,通过经验数据不断迭代策略且估计value讲过的
在1个ppo_batch中,critic的损失计算公式为:
裁剪新价值估计,使其不至于太偏离采集经验时的旧价值估计,使得经验回放仍能有效:
critic将拟合回报R:
可能有同学疑问上面的代码和我说的这个公式并没有一一对齐呀,为了方便大家一目了然,我们把代码逐行再分析下
- 对于这行代码
value_clipped = target_values_batch + (value_batch - target_values_batch).clamp(-self.clip_param,self.clip_param)
转换成公式便是
V_clipped = V_old + clip(V_new - V_old, -ε, ε)
它和我上面贴的公式表达的其实是一样的
因为我上面贴的公式要表达的是:,那该不等式两边都减去个,不就意味着- 而接下来这三行代码
value_losses = (value_batch - returns_batch).pow(2)
value_losses_clipped = (value_clipped - returns_batch).pow(2)
value_loss = torch.max(value_losses, value_losses_clipped).mean()
则表达的就是如下公式是不一目了然了..
- 最后,将代理损失、价值损失和熵损失结合起来,形成最终的损失函数
最后的最后,进行梯度下降,更新模型的参数,并在所有mini-batch更新完成后,计算平均的价值损失和代理损失,并清空存储器- # Gradient step
- # 梯度步
- self.optimizer.zero_grad() # 清零梯度
- loss.backward() # 反向传播
- nn.utils.clip_grad_norm_(self.actor_critic.parameters(), self.max_grad_norm) # 剪切梯度
- self.optimizer.step() # 更新优化器
- mean_value_loss += value_loss.item() # 累加平均值损失
- mean_surrogate_loss += surrogate_loss.item() # 累加平均代理损失
- num_updates = self.num_learning_epochs * self.num_mini_batches # 计算更新次数
- mean_value_loss /= num_updates # 计算平均值损失
- mean_surrogate_loss /= num_updates # 计算平均代理损失
- self.storage.clear() # 清除存储
- return mean_value_loss, mean_surrogate_loss # 返回平均值损失和平均代理损失
//..
第二部分 HIT
// 待更
评论记录:
回复评论: