
前言
本文一开始是属于此文的,但由于人体姿态估计WHAM与手势估计HaMeR比较重要,故导致越写越长,故独立抽取出来成为本文了
第一部分 姿态估计之 WHAM
1.1 WHAM的整体架构
根据arXiv的记录,此篇论文WHAM: Reconstructing World-grounded Humans with Accurate 3D Motion的提交记录为[Submitted on 12 Dec 2023 (v1), last revised 18 Apr 2024 (this version, v2)]
如下图所示,WHAM的输入是由可能具有未知运动的相机捕获的原始视频数据 ,接下来的目标是预测对应的SMPL模型参数序列
,接下来的目标是预测对应的SMPL模型参数序列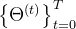 ,以及在世界坐标系中表达的根方向
,以及在世界坐标系中表达的根方向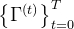 和平移
和平移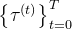 ,具体做法是
,具体做法是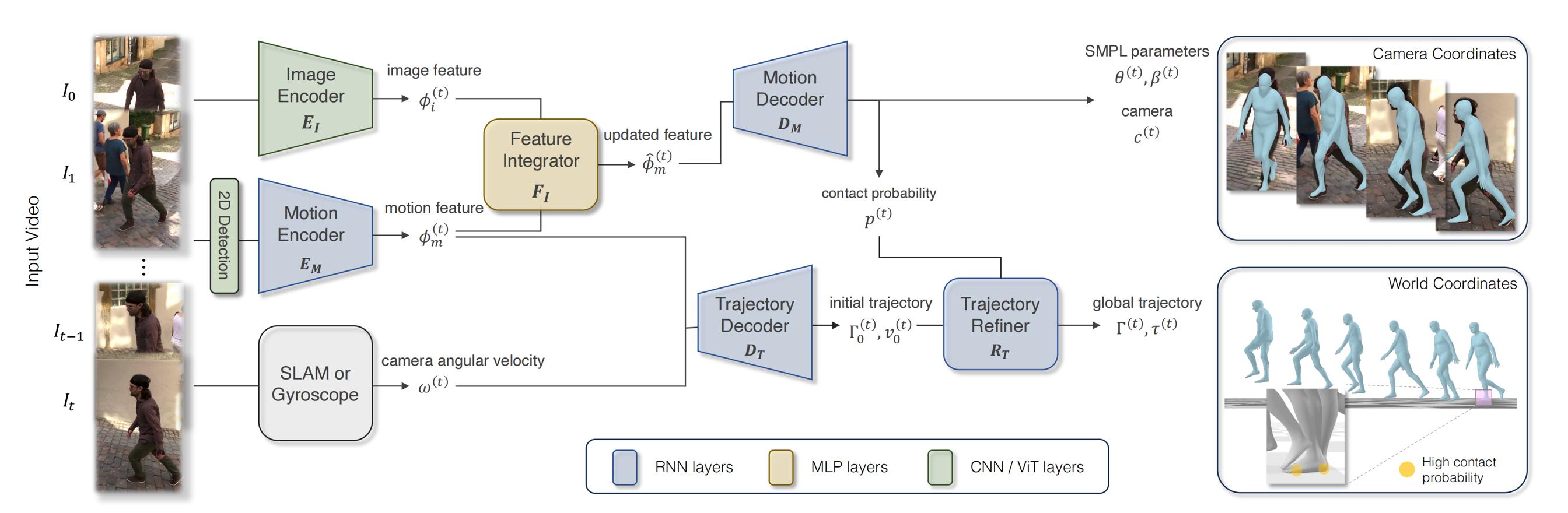
- 我们使用ViTPose [54] 检测2D关键点
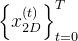 ,从中使用Motion Encoder获得运动特征
,从中使用Motion Encoder获得运动特征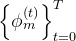
- 此外,我们使用预训练的Image Encoder[7,21,25] 提取静态图像特征
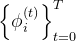 ,然后将这个图像特征与上面的运动特征结合,以获得细粒度的运动特征
,然后将这个图像特征与上面的运动特征结合,以获得细粒度的运动特征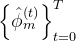
1.1.1 Motion Encoder and Decoder
对于 Motion Encoder and Decoder而言,与之前的方法使用固定时间窗口不同,这里使用RNN来作为运动编码器、运动解码器
- 运动编码器
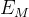 的目标是基于当前和之前的2D 关键点(keypoints)和初始隐藏状态
的目标是基于当前和之前的2D 关键点(keypoints)和初始隐藏状态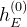 而提取运动上下文
而提取运动上下文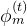 ,即
,即
过程中,We normalize keypoints to a bounding box around the person and concatenate the box’s center and scale to the keypoints,similar to CLIFF [ 25]. - 运动解码器
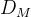 的作用是从运动特征历史中恢复:
的作用是从运动特征历史中恢复: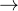 SMPL参数
SMPL参数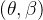 weak-perspective camera translation
weak-perspective camera translation  脚接触地面的概率(foot-ground contact probability)
脚接触地面的概率(foot-ground contact probability) 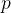
即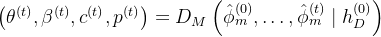
其中的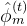 如上面说过的,是图像特征与运动特征结合而成的细粒度运动特征
如上面说过的,是图像特征与运动特征结合而成的细粒度运动特征
其中有一个关键点是咱们需要利用时间上的人体运动上下文,将2D关键点提升到3D网格,那如何做到呢,一个比较好的办法便是利用图像线索来增强这些2D关键点信息
具体而言,可以
- 先使用一个图像编码器,在人体网格恢复这个任务上做预训练,以提取图像特征
,这些特征包含与3D人体姿态和形状相关的密集视觉上下文信息
- 然后我们训练一个特征整合网络
,将
与

1.1.2 全局轨迹解码器Global Trajectory Decoder
作者团队还设计了一个额外的解码器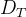 ,用于从运动特征中预测粗略的全局根方向
,用于从运动特征中预测粗略的全局根方向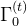 和根速度
和根速度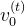 「We design an additional decoder, DT , to predict the rough global root orientation Γ(t)0 and root velocity v(t)0 from the motion feature ϕ(t)m」
「We design an additional decoder, DT , to predict the rough global root orientation Γ(t)0 and root velocity v(t)0 from the motion feature ϕ(t)m」
但由于是从相机坐标系中的输入信号派生的,因此将人类和相机运动从中解耦是非常具有挑战性的。为了解决这种模糊性,我们将相机的角速度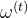 ,附加到运动特征,创建一个与相机无关的运动上下文。 这种设计选择使WHAM兼容现成的SLAM算法 [46, 47] 和现代数字相机广泛提供的陀螺仪测量
,附加到运动特征,创建一个与相机无关的运动上下文。 这种设计选择使WHAM兼容现成的SLAM算法 [46, 47] 和现代数字相机广泛提供的陀螺仪测量
再之后,使用单向RNN递归预测全局方向
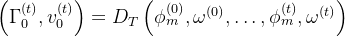
1.1.3 通过脚是否触地:做接触感知轨迹的优化(Contact Aware Trajectory Refinement)
具体来说,新轨迹优化器旨在解决脚滑问题,并使WHAM能够很好地泛化到各种运动(包括爬楼梯),而这个新轨迹优化涉及两个阶段
首先,根据从运动解码器估计的脚-地面接触概率 ,调整自我中心的根速度
,调整自我中心的根速度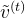 以最小化脚滑
以最小化脚滑

其中,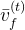 是当接触概率高于阈值时,脚趾和脚跟在世界坐标中的平均速度。 然而,当接触和姿态估计不准确时,这种速度调整往往会引入噪声平移
是当接触概率高于阈值时,脚趾和脚跟在世界坐标中的平均速度。 然而,当接触和姿态估计不准确时,这种速度调整往往会引入噪声平移
因此,我们提出了一种简单的学习机制,其中轨迹优化网络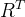 更新根部方向和速度以解决此问题。 最后,通过展开操作计算全局平移:
更新根部方向和速度以解决此问题。 最后,通过展开操作计算全局平移:
1.2 WHAM的两阶段训练
分两个阶段进行训练: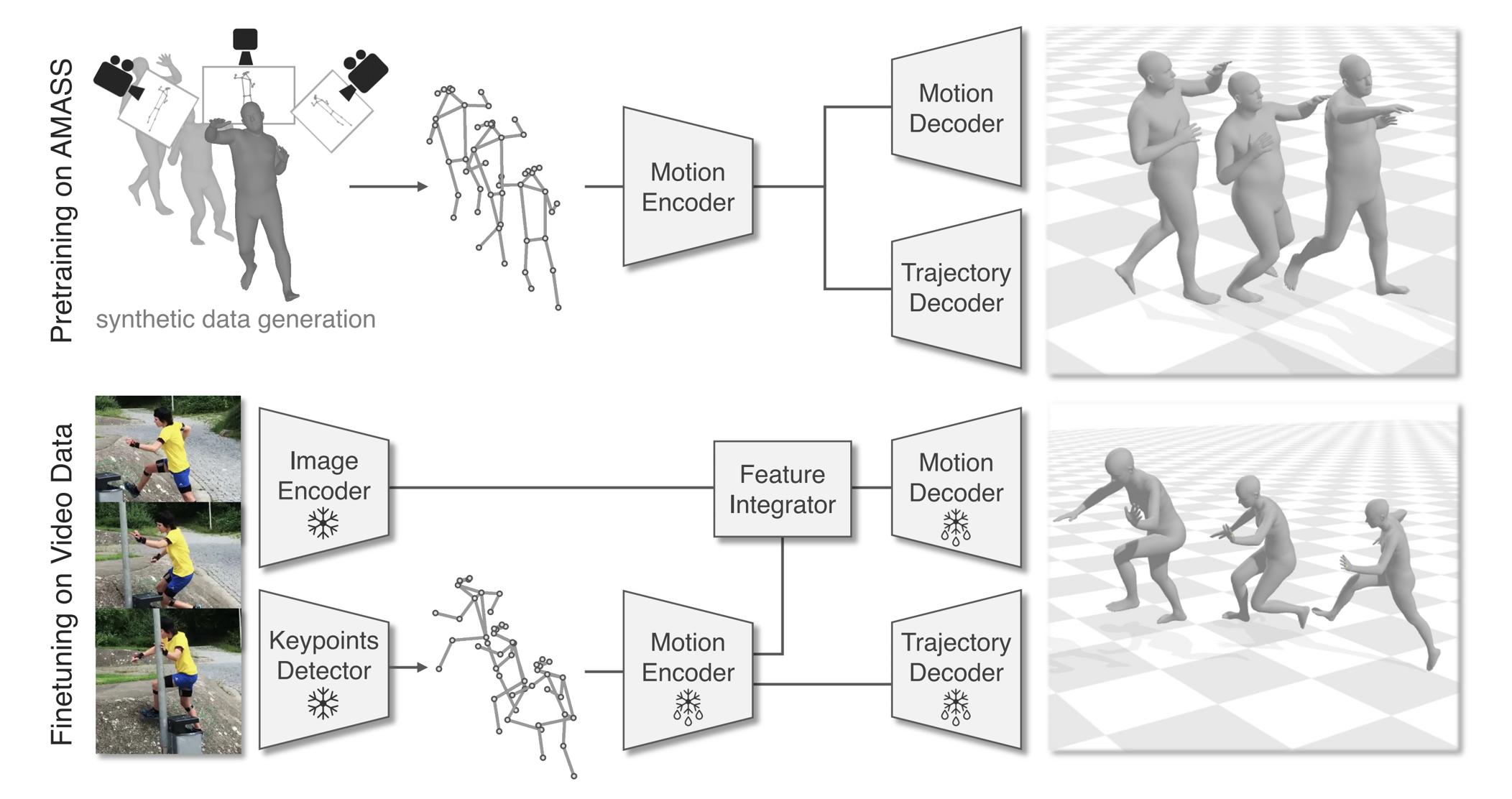
- 使用合成数据进行预训练
- 使用真实数据进行微调
1.2.1 在AMASS上进行预训练
预训练阶段的目标是教会运动编码器从输入的2D关键点序列中提取运动上下文。 然后,运动和轨迹解码器将此运动上下文映射到相应的3D运动和全局轨迹空间(即它们将编码提升到3D)
我们使用AMASS数据集[32]生成由2D关键点序列和真实SMPL参数组成的大量合成对。为了从AMASS合成2D关键点,我们创建了虚拟摄像机,将从真实网格派生的3D关键点投影到这些摄像机上
与MotionBERT[62]和ProxyCap[61]使用静态摄像机进行关键点投影不同,我们采用了结合旋转和平移运动的动态摄像机。 这个选择有两个主要动机
- 首先,它考虑到了在静态和动态相机设置中捕捉到的人类运动的固有差异
- 其次,它使得能够学习与相机无关的运动表示,从中轨迹解码器可以重建全局轨迹
我们还通过噪声和掩蔽来增强2D数据
1.2.2 在视频数据集上微调
从预训练网络开始,我们在四个视频数据集上微调WHAM:
- 3DPW[49]
- Human3.6M [11]
- MPI-INF-3DHP [33]
- InstaVariety [15]
对于人类网格恢复任务,我们在AMASS和3DPW的真实SMPL参数、Human3.6M和MPI-INF-3D
HP的3D关键点以及InstaVariety的2D关键点上监督WHAM
对于全局轨迹估计任务,我们使用AMASS、Human3.6M和MPI-INF-3DHP
此外,在训练期间,我们尝试添加BEDLAM [1],这是一个具有真实视频和真实SMPL参数的大型合成数据集
微调有两个目标:1)使网络暴露于真实的2D关键点,而不是仅在合成数据上训练,2)训练特征整合网络以聚合运动和图像特征
为了实现这些目标,我们在视频数据集上联合训练整个网络,同时在预训练模块上设置较小的学习率
与之前的工作一致[6, 17, 30, 43, 52],我们采用预训练和固定权重的图像编码器[21]来提取图像特征。然而,为了利用最近的网络架构和训练策略,我们在以下部分中还尝试了不同类型的编码器[1, 7, 25]
以下是有关训练的部分细节
- 在预训练阶段,我们在AMASS上训练WHAM 80个周期,学习率为5 × 10−4。 然后我们在3DPW、MPI-INF-3DHP、Human3.6M和InstaVariety上微调WHAM 30个周期
- 在微调期间,对特征整合器使用的学习率为 1 × 10−4,对预训练组件使用的学习率为1×10−5。在训练期间,使用Adam优化器和批量大小
// 待更
第二部分 手势估计HaMeR
Reconstructing Hands in 3D with Transformers在arXiv的提交记录为[Submitted on 8 Dec 2023]

// 待更
评论记录:
回复评论: