
前言
之所以关注到DINOV2,原因在于我解读多个具身机器人模型时——发现他们的视觉基座都用的DINOV2,比如
- rekep
- Open-TeleVision
- OpenVLA
- CogACT
- OKAMI
不过,实话讲,DINO论文的可读性是真的不高,使得本次解读不易..总之,本文目前只是个初稿,后面还得花不少时间 反复优化
第一部分 DINO
1.1 提出背景与相关工作
1.1.1 DINO的提出背景
近年来,Transformer [70] 已经成为视觉识别领域中卷积神经网络convnets的替代方案[19,69,83]。它们的采用伴随着一种受NLP启发的训练策略,即在大量数据上进行预训练,然后在目标数据集上进行微调[18,55]
由此产生的视觉Transformer(ViT)[19-详见此文《图像生成发展起源:从VAE、扩散模型DDPM、DDIM到DETR、ViT、Swin transformer》的第4部分] 与卷积网络具有竞争力,但尚未显现出明显的优势:它们在计算上更为苛刻,要求更多的训练数据,并且其特征没有表现出独特的属性
- 对此,作者质疑视觉领域中Transformer成功受限是否可以通过其预训练中的监督方式来解释。作者的动机是,Transformer在自然语言处理领域成功的一个主要因素是使用自监督预训练,例如BERT中的close procedure[18]或GPT中的语言建模[55]
- 这些自监督预训练目标使用句子中的词语来创建伪任务,比预测每个句子单一标签的监督目标提供了更丰富的学习信号。同样,在图像中,图像级别的监督通常将图像中包含的丰富视觉信息简化为从预定义的几千个类别中选择的单一概念[60]
受以上种种的启发,21年4月,Meta发布了DINO
- 其对应的paper为:Emerging Properties in Self-Supervised Vision Transformers
- 其对应的GitHub为:facebookresearch/dino
1.1.2 相关工作:自训练和知识蒸馏
自训练旨在通过将一小部分初始标注传播到大量未标注的实例来提高特征的质量。这种传播可以通过标签的硬分配[41,78,79]或软分配[76]来完成
- 当使用软标签时,该方法通常被称为知识蒸馏[7,35],其主要设计目的是训练一个小网络以模拟大网络的输出来压缩模型
- Xie等人[76]表明,蒸馏可以用于在自训练流程中将软伪标签传播到未标注的数据,从而在自训练和知识蒸馏之间建立了一个重要的联系
- 作者的工作基于这一关系,并将知识蒸馏扩展到无标签的情况。之前的工作也结合了自监督学习和知识蒸馏[25,63,13,47],实现了自监督模型压缩和性能提升。然而,这些工作依赖于预训练的固定教师,而作者的教师是在训练过程中动态构建的。这样,知识蒸馏不是作为自监督预训练的后处理步骤,而是直接作为自监督目标
- 最后,作者的工作也与协同蒸馏[1]相关,其中学生和教师具有相同的架构,并在训练过程中使用蒸馏。然而,在协同蒸馏中,教师也从学生中蒸馏,而在我们的工作中,教师通过学生的平均值进行更新
1.2 方法
1.2.1 知识蒸馏的自监督学习
本研究中使用的框架DINO,与最近的自监督方法[10-Unsupervised learning of visual features by contrasting cluster assignments,16,12,30,33]共享相同的整体结构
然而,作者的方法也与知识蒸馏[35- Distilling the knowledge in a neural network]有相似之处
下图图2中展示了DINO「模型将输入图像的两种不同随机变换传递给学生和教师网络。两个网络具有相同的架构但参数不同。教师网络的输出以批次计算的均值为中心。每个网络输出一个K维特征,该特征通过特征维度上的温度softmax进行归一化。然后用交叉熵损失测量它们的相似性。作者在教师上应用一个停止梯度(sg)操作符 只通过学生传播梯度——We apply astop-gradient (sg) operator on the teacher to propagate gradientsonly through the student。教师参数通过学生参数的指数移动平均(ema)进行更新」
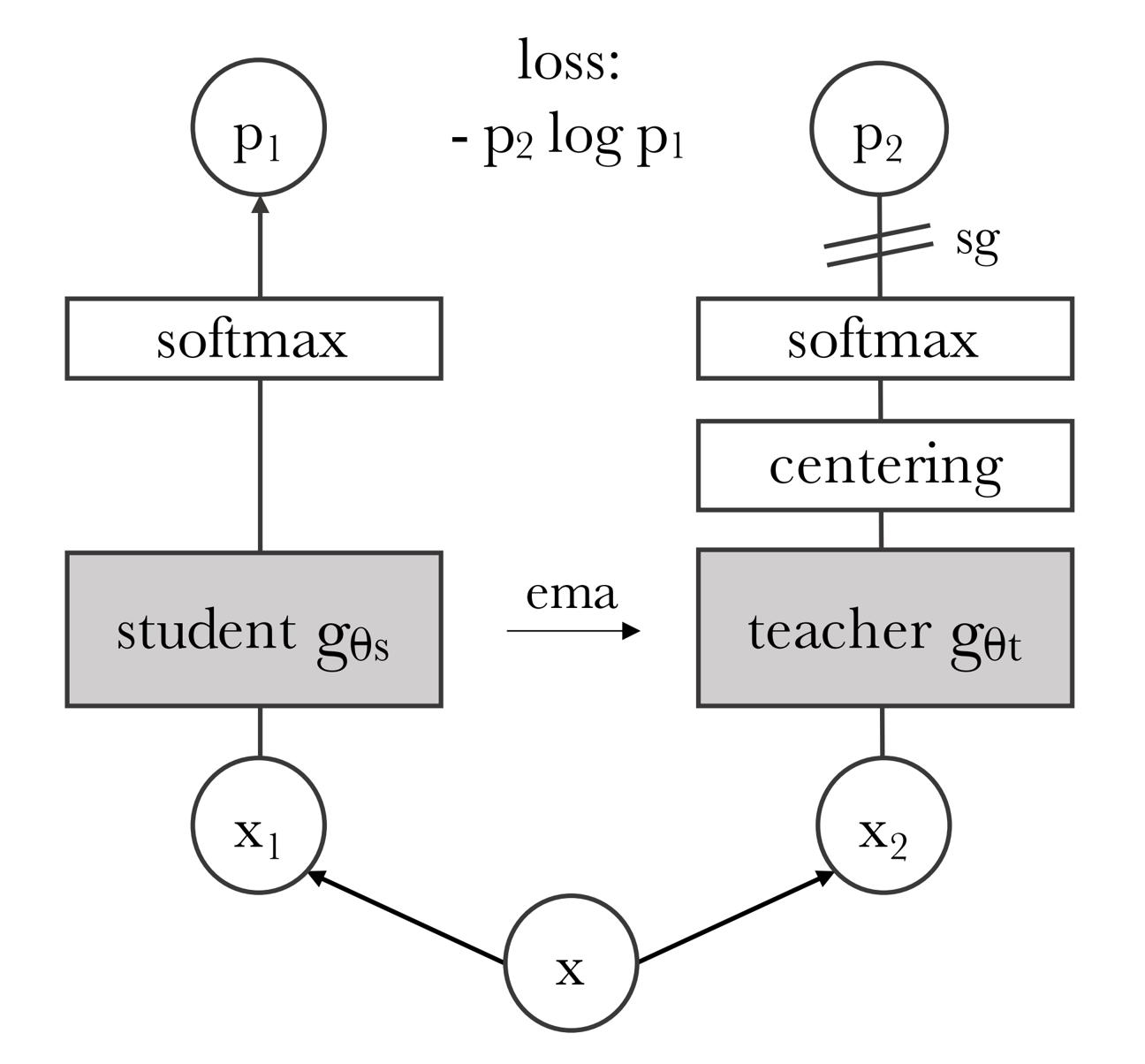
总之,知识蒸馏是一种学习范式,作者训练一个学生网络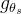 来匹配给定教师网络
来匹配给定教师网络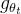 的输出,分别由
的输出,分别由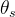 和
和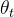 参数化
参数化
给定输入图像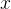 ,两个网络输出在
,两个网络输出在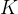 维上的概率分布,分别表示为
维上的概率分布,分别表示为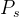 和
和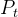 。概率P 是通过使用softmax函数对网络g 的输出进行归一化得到的。更准确地说
。概率P 是通过使用softmax函数对网络g 的输出进行归一化得到的。更准确地说

其中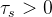 是控制的温度参数——输出分布的尖锐度,以及一个类似的公式适用于,其中温度为
是控制的温度参数——输出分布的尖锐度,以及一个类似的公式适用于,其中温度为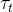 。给定一个固定的教师网络,作者通过最小化相对于学生网络参数的交叉熵损失来学习匹配这些分布(定义为方程2)
。给定一个固定的教师网络,作者通过最小化相对于学生网络参数的交叉熵损失来学习匹配这些分布(定义为方程2)
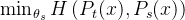
其中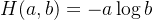
接下来,作者详细说明如何将方程(2)中的问题适应于自监督学习
- 首先,使用多裁剪策略[10] 构建图像的不同失真视图或裁剪。更具体地说,从给定的图像中,生成一组V 的不同视图。该集合包含两个全局视图,xg1 和xg2,以及几个较小分辨率的局部视图。所有裁剪都会通过学生模型,而只有全局视图会通过教师模型,因此鼓励” 局部到全局” 的对应关系
- 最小化损失(定义为方程3)
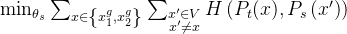
这种损失是通用的,可以用于任意数量的视图,甚至只有两个视图。然而,遵循多裁剪的标准设置,使用两个分辨率为224×224的全局视图。覆盖原始图像的大部分(例如大于50%)区域,以及几个分辨率为96×96的局部视图。仅覆盖原始图像的小区域(例如小于50%)。除非另有说明,否则将此设置称为DINO的基本参数化
两个网络共享相同的架构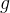 ,但具有不同的参数集 和。作者通过使用随机梯度下降法最小化方程(3)来学习参数θs
,但具有不同的参数集 和。作者通过使用随机梯度下降法最小化方程(3)来学习参数θs
额外说一句,作者还在算法1中提出了一个伪代码实现

对于教师网络
与知识蒸馏不同,作者没有先验给定的教师,因此作者从学生网络的过去迭代中构建它。作者在原论文的第5.2 节研究了教师的不同更新规则,并展示了在作者的框架中冻结教师网络在一个epoch 内出乎意料地有效,而将学生权重复制给教师则无法收敛
- 特别感兴趣的是,在学生权重上使用指数移动平均(EMA),即动量编码器[33],特别适合他们的框架。更新规则为
 ,其中λ 在训练过程中按照余弦调度从0.996 到1 [30]
,其中λ 在训练过程中按照余弦调度从0.996 到1 [30] - 最初,动量编码器被引入作为对比学习中队列的替代品[33]。然而,在他们的框架中,其角色有所不同,因为他们没有队列也没有对比损失,可能更接近于自我训练中使用的均值教师的角色[65]
- 事实上,作者观察到这个教师执行了一种类似于Polyak-Ruppert 平均的模型集成形式,具有指数衰减[51, 59]。使用Polyak-Ruppert 平均进行模型集成是提高模型性能的标准做法[38]。作者观察到这个教师在整个训练过程中表现优于学生,因此,通过提供更高质量的目标特征来指导学生的训练。这种动态在先前的工作中未被观察到[30, 58]
对于网络架构
神经网络g 由一个主干f(ViT [19] 或ResNet [34])和一个投影头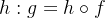 组成
组成
再简要回顾下视觉Transformer(ViT) [19, 70] 的机制
作者遵循DeiT [69-Training data-efficient image transformers & distillation through attention] 中使用的实现。且在下表1 中总结了本文中使用的不同网络的配置
其中,ViT 架构以分辨率为N ×N 的非重叠连续图像块网格作为输入
- 在本文中,作者通常使用N = 16(”/16”) 或N = 8 (”/8”)
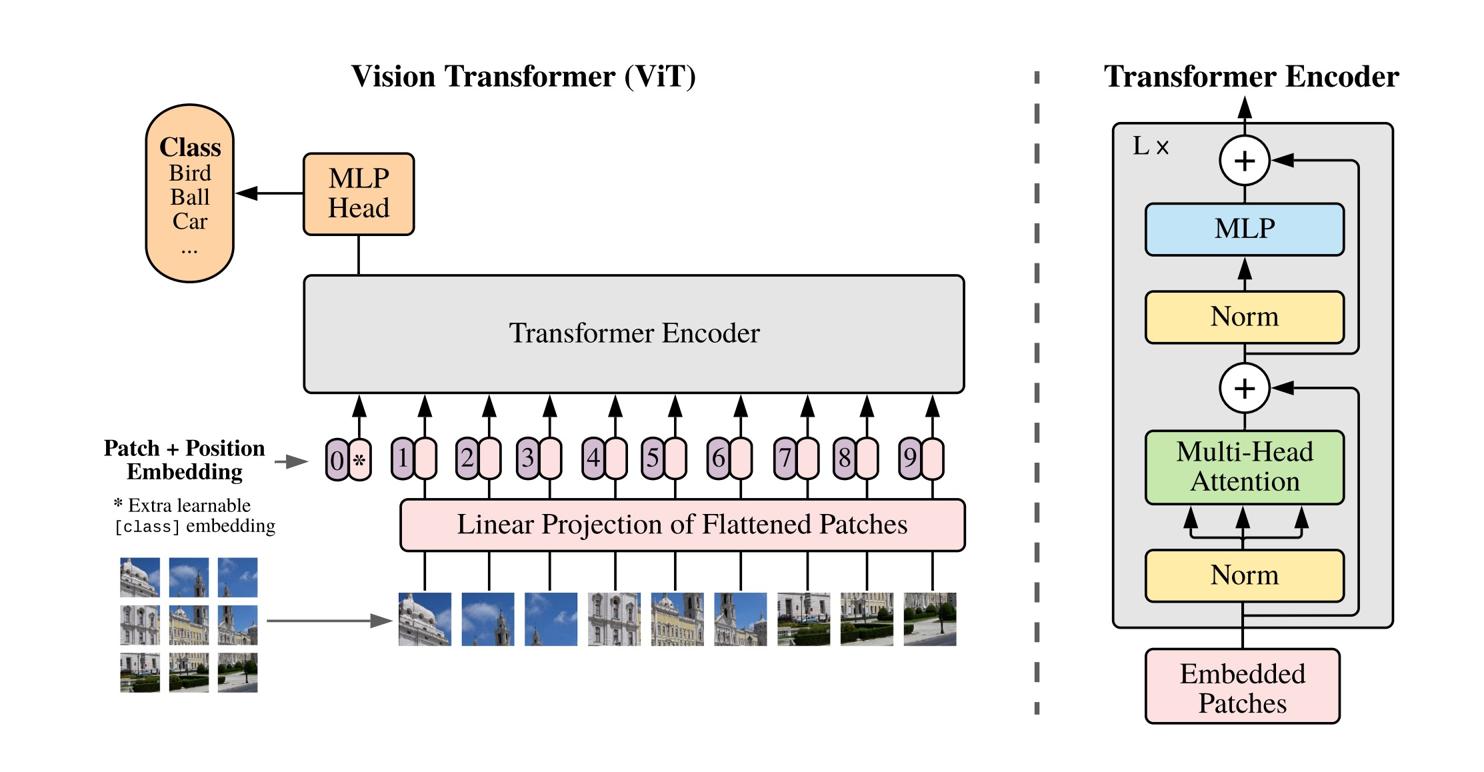
然后将这些图像块通过一个线性层以形成一组嵌入- 在序列中添加一个额外的可学习token [18, 19],这个token的作用是聚合整个序列的信息——为了与之前的研究保持一致,将此token称为分类token[CLS],且在其输出处附加投影头h「projection head h」
- patch token集和[CLS] token被输入到一个带有” 预归一化” 层归一化的标准Transformer 网络[11, 39]「The set of patch tokens and [CLS] token are fed to a standard Transformer network with a “pre-norm” layer normalization [11, 39],说白了,所谓的预归一化——就是先Norm再attention 或先Norm再MLP」
而其中的Transformer 是由自注意力和前馈层组成的序列,并与跳跃连接并行。自注意力层通过注意力机制[4] 查看其他token表示来更新token表示「如果对transformer的自注意力机制有所遗忘的话,详见此文《Transformer通俗笔记:从Word2Vec、Seq2Seq逐步理解到GPT、BERT》」
TheTransformer is a sequence of self-attention and feed-forwardlayers, paralleled with skip connections. The self-attentionlayers update the token representations by looking at the other token representations with an attention mechanism [4].
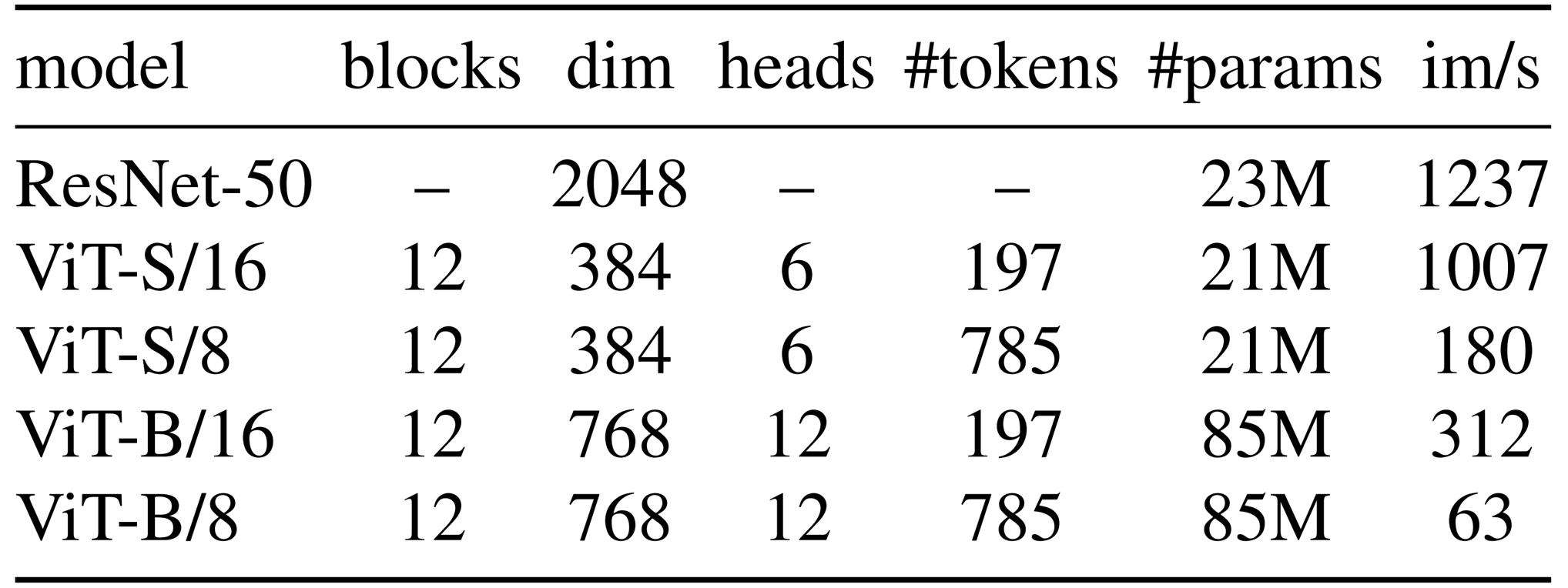
下游任务中使用的特征是主干f 的输出。投影头由一个3 层多层感知器(MLP)组成,隐藏维度为2048,后接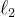 归一化和一个权重归一化的全连接层[61],具有K 维度,这与SwAV [10- Unsupervised learning of visual features by contrasting cluster assignments] 的设计相似
归一化和一个权重归一化的全连接层[61],具有K 维度,这与SwAV [10- Unsupervised learning of visual features by contrasting cluster assignments] 的设计相似
- 作者测试了其他投影头,这种特定设计似乎对DINO 效果最佳(附录C)。作者没有使用预测器[30,16],导致学生和教师网络中的架构完全相同
- 特别值得注意的是,与标准卷积神经网络不同,ViT架构默认不使用批量归一化(BN)。因此,当将DINO应用于ViT时,作者在投影头中也不使用任何BN,使系统完全不含BN
// 待更
第二部分 DINOV2
// 待更
第三部分 DINO-X
// 待更
评论记录:
回复评论: