
前两天,搞了个微信 AI 小助理-小爱(AI),爸妈玩的不亦乐乎。
最近一直在迭代中,挖掘小爱的无限潜力:
有朋友问小爱:能接收word、excel、pdf等各种文件吗?要是能帮我处理各种文件,岂不是很爽?
小爱:今天就安排!
今日分享,将继续基于wechatbot-wehook框架,带大家实操:如何接收微信文件,并进行处理,让小爱接管你的文件处理工作,助力你上班摸鱼!
1. 接收微信文件
微信消息中所有文件,在 FastAPI 中都可以用 UploadFile 类处理。
此外,UploadFile 是设计为异步的,故支持大文件的高效上传和处理。
其中,content_type 代表文件的 MIME 类型(媒体类型),主要分为以下几类:
- 文本类型
- 文本文件:如 text/plain
- HTML 文件:如 text/html
- CSS 文件:如 text/css
- 图像类型
- JPEG 图像:如 image/jpeg
- PNG 图像:如 image/png
- GIF 图像:如 image/gif
- 音频类型
- MP3 音频:如 audio/mpeg3 或 audio/mp3
- WAV 音频:如 audio/x-wav
- 视频类型
- MP4 视频:如 video/mp4
- MPEG 视频:如 video/mpeg
- 应用程序类型
- JSON 文件:如 application/json
- PDF 文件:如 application/pdf
- ZIP 文件:如 application/zip
- Microsoft Word 文档:如 application/vnd.openxmlformats-officedocument.wordprocessingml.document
下面是接收文件并下载的示例代码:
@app.post("/receive")
async def receive_message(request: Request):
data = await request.form()
message_type = data.get("type")
content = data.get("content")
# 下载文件
if message_type == 'file':
with open(f"./output/{content.filename}", "wb") as buffer:
bin = await content.read()
buffer.write(bin)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
上一篇,我们主要介绍了如何处理音频文件。
本篇将以最常见的 pdf 为例,介绍如何处理 pdf 并返回。
2. 文本提取
当你给小爱发送一份 pdf 文件,后台接收到的文件如下:
UploadFile(filename='学会写作.pdf', size=1381979, headers=Headers({'content-disposition': 'form-data; name="content"; filename="å\xad¦ä¼\x9aå\x86\x99ä½\x9c.pdf"', 'content-type': 'application/pdf'}))
- 1
文件类型为application/pdf。
关于如何处理pdf 文件,可以参看猴哥之前的【Python实战】教程:
这里我们以提取 pdf 文本为例进行演示:
from PyPDF2 import PdfReader
def pypdf_to_txt(input_pdf):
pdf_reader = PdfReader(input_pdf)
texts = []
for page_num in range(len(pdf_reader.pages)):
page = pdf_reader.pages[page_num]
text = page.extract_text()
texts.append(text)
return '\n'.join(texts)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
3. 文本摘要
得到文本后,就可以交给 LLM 帮我们提炼总结一下内容要点。有了文本摘要,我就无需再去翻阅长文,省时提效利器,有没有?
这个任务非常简单,甚至无需编写角色提示词:
unillm = UniLLM()
messages = [{'role': 'user', 'content': f'帮我提炼这篇文章的主要观点:{text}'}]
res = unillm(['glm4-9b'], messages=messages)
- 1
- 2
- 3
我把《学会写作》这本书发给了它,可以看到提炼的还是很精准的:
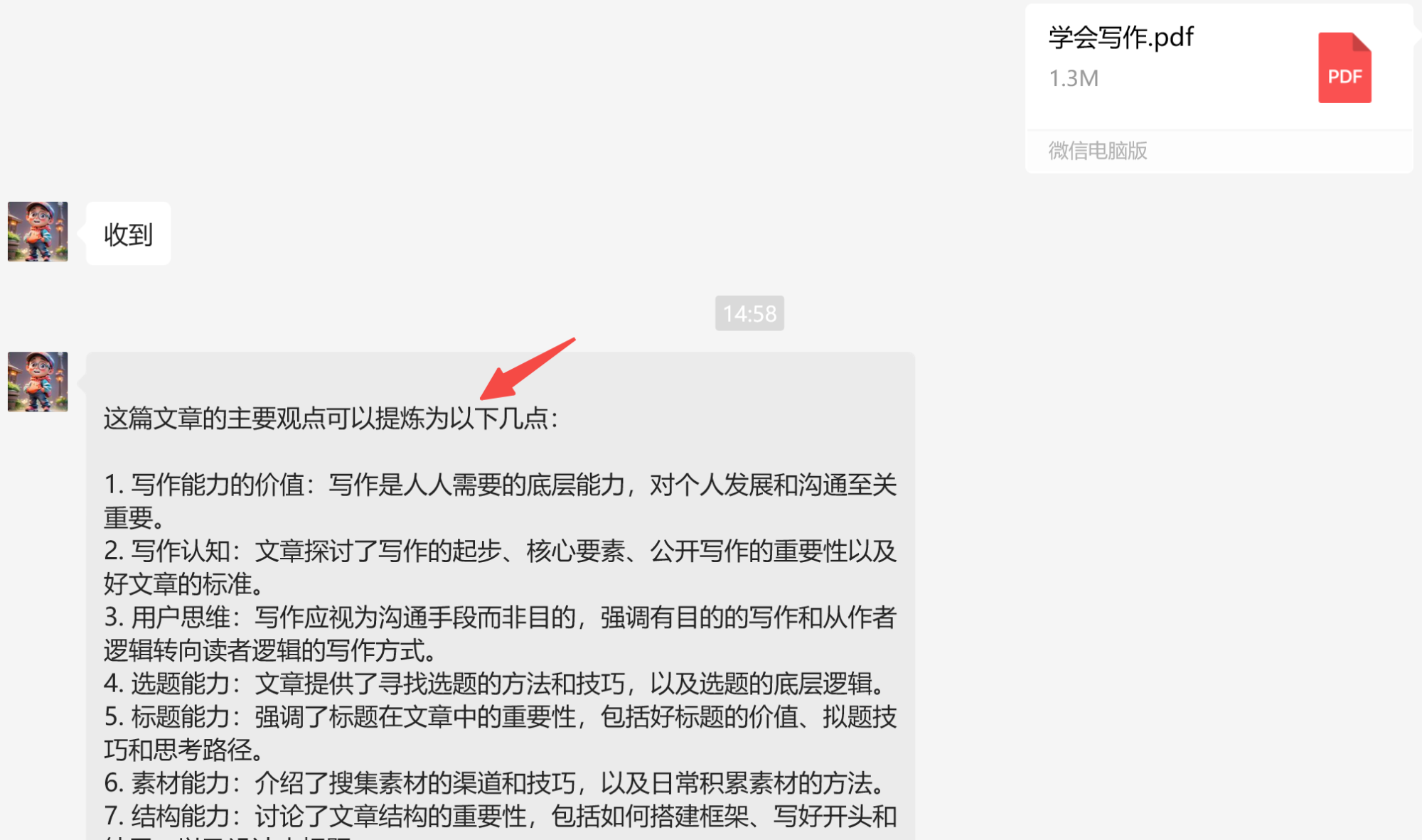
有需要这本书的公众号后台自取。
4. 更多玩法
不管是 word 还是 pdf,只要拿到源文件,你想实现任何功能,还不简单?底层逻辑都是一样的:把流程标准化,然后让程序自动执行,最终让小爱交给你~
比如,我可以让它帮我把 pdf 去水印/加水印,然后返回给我。
写在最后
本文给大家展示了一个处理pdf文件的简单案例,懒人必备神器!
大家有更好的想法,欢迎评论区交流。
如果本文对你有帮助,不妨点个免费的赞和收藏备用。
为了方便大家交流,新建了一个 AI 交流群,欢迎感兴趣的小伙伴加入。
小爱也在群里,想进群体验的朋友,公众号后台「联系我」即可,拉你进群。

 微信公众号
微信公众号

评论记录:
回复评论: