
前言
如之前的文章所述,我司下半年成立大模型项目团队之后,我虽兼管整个项目团队,但为让项目的推进效率更高,故分成了三大项目组
- 第一项目组由霍哥带头负责类似AIGC模特生成系统
- 第二项目组由阿荀带头负责论文审稿GPT以及AI agent项目
- 第三项目组由朝阳带头负责企业多文档的知识库问答系统,朝阳、bingo、猫药师等人贡献了本文的至少一半
对于知识库问答,现在有两种方案,一种基于llamaindex,一种基于langchain +LLM
- 对于前者,我近期会另外写一篇文章
- 对于后者,考虑到我已在此文《基于LangChain+LLM的本地知识库问答:从企业单文档问答到批量文档问答》中详细介绍了langchain、以及langchain-ChatGLM项目的源码剖析
如下图所示,整个系统流程是很清晰的,但涉及的点颇多,所以决定最终效果的关键点包括且不限于:文本分割算法、embedding、向量的存储 搜索 匹配 召回 排序、大模型本身的生成能力
本文重点则阐述“如何通过基于langchain-chatchat二次开发一个知识库问答系统”,包括其商用时的典型问题以及对应的改进方案,比如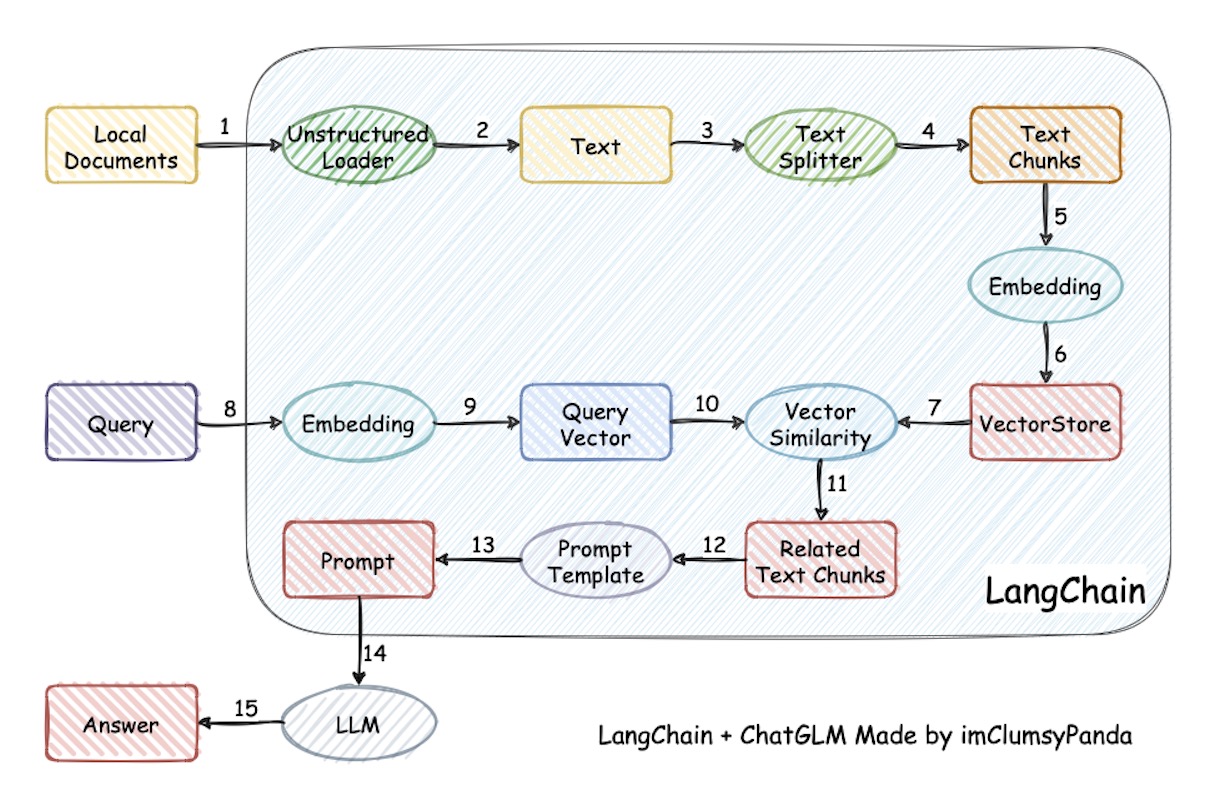
1 如何解决检索出错:embedding算法是关键之一
2 如何解决检索到相关但不根据知识库回答而是根据模型自有的预训练知识回答
3 如何针对结构化文档采取更好的chunk分割:基于规则
4 如何解决非结构化文档分割不够准确的问题:比如最好按照语义切分
5 如何确保召回结果的全面性与准确性:多路召回与最后的去重/精排
6 如何解决基于文档中表格的问答
最后强调一下,本文及后续相关的文章(比如embedding、文本语义分割、llamaindex等)更多是入门/梳理,其中的细节/深入,以及更多问题的解决暂在我司的「大模型项目开发线上营」里见
前置部分 知识库的构建:基于langchain-chatchat的V0.2.6版本(chatglm2+m3e)
将七月近两年整理的大厂面试题PDF文件作为源文件来进行知识库的构建

默认使用RapidOCRPDFLoader作为文档加载器
RapidOCR是目前已知运行速度最快、支持最广,完全开源免费并支持离线快速部署的多平台多语言OCR。由于PaddleOCR工程化不是太好,RapidOCR为了方便大家在各种端上进行OCR推理,将PaddleOCR中的模型转换为ONNX格式,使用Python/C++/Java/Swift/C# 将它移植到各个平台
更多详情参考:https://rapidai.github.io/RapidOCRDocs/docs/overview/
另,本文里的测试及二次开发主要针对langchain-chatchat的V0.2.6版本,资源及相关默认配置如下:
- 显卡:Tesla P100,16G(显存)
- 分词器:ChineseRecursiveTextSplitter
- chunk_size:250 (顺带说一下,250是默认分块大小,但该系统也有个可选项,可以选择达摩院开源的语义分割模型:nlp_bert_document-segmentation_chinese-base )
- embedding模型:默认为m3e-base
- LLM模型:chatglm2-6b (默认为该模型,但下文会有些结果来自chatglm3)
- 向量库:faiss
第一部分 如何解决检索的问题:比如检索出错等
1.1 如何解决检索出错:embedding算法是关键之一
1.1.1 针对「Bert的预训练过程是什么?」检索出的结果与问题不相关
使用原始的langchain-chatchat V0.2.6版本,会出现对某些问题检索不到的情况
比如问一个面试题:Bert的预训练过程是什么?
- 其在文档中的结果如下:

- 但基于m3e的系统实际检索得到的内容如下:
可以看出,是没有检索到相关内容的出处 [1] 2021Q2大厂面试题共121题(含答案及解析).pdf
成. 15.6 bert 的改进版有哪些 参考答案: RoBERTa:更强大的 BERT 加大训练数据 16GB -> 160GB,更大的batch size,训练时间加长 不需要 NSP Loss: natural inference 使用更长的训练 SequenceStatic vs. Dynamic Masking 模型训练成本在 6 万美金以上(估算) ALBERT:参数更少的 BERT一个轻量级的 BERT 模型 共享层与层之间的参数 (减少模型参数)
出处 [2] 2022Q1大厂面试题共65题(含答案及解析).pdf
可以从预训练方法角度解答。
… 20
5、RoBERTa 相比 BERT 有哪些改进?
…
20 6、BERT 的输入有哪几种 Embedding?
出处 [3] 2022Q2大厂面试题共92题(含答案及解析).pdf
保证模型的训练,pre-norm 显然更好一些。 5、GPT 与 Bert 的区别 1) GPT
是单向模型,无法利用上下文信息,只能利用上文;而 BERT 是双向模型。 2) GPT 是基于自回归模型,可以应用在 NLU 和 NLG两大任务,而原生的 BERT 采用的基于自编码模 型,只能完成 NLU 任务,无法直接应用在文本生成上面。 6、如何加速 Bert模型的训练 BERT 基线模型的训练使用 Adam with weight decay(Adam 优化器的变体)作为优化器,LAMB 是一款通用优化器,它适用于小批量和大批量,且除了学习率以外其他超参数均无需调整。LAMB 优化器支持自 -
在没检索对的情况下,接下来,大模型便只能根据自己的知识去回答(下图左侧是chatglm2-6b的回答,下图右侧是chatglm3-6b的回答)
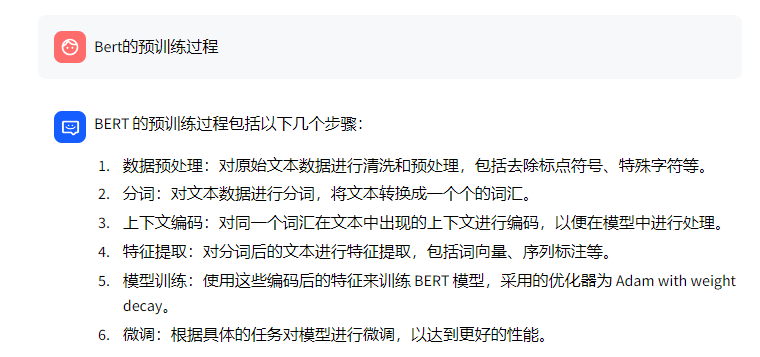

结果就是造成了大模型所谓的编造或幻觉问题,没有答到点子上:MLM和NSP
1.1.2 可能的原因分析与优化方法
使用默认配置时,虽然上传文档可以实现基础的问答,但效果并不是最好的,通常需要考虑以下几点原因
- 文件解析及预处理:对于PDF文件,可能出现解析不准确的情况,导致检索召回率低;
- 文件切分:不同的chunk_size切分出来的粒度不一样。如果设置的粒度太小,会出现信息丢失的情况;如果设置的粒度太大,又可能会造成噪声太多,导致模型输出的结果明显错误。且单纯根据chunk_size切分比较简单粗暴,需要根据数据进行针对性优化;
- embedding 模型效果:embedding效果不好也会影响检索结果
优化方法:
- 文件解析及预处理
一方面可以尝试不同的PDF解析工具,解析更加准确
另一方面可以考虑将解析后的内容加上标题,并保存成Markdown格式,这样可以提高召回率 - 文件切分
基于策略:对于特定的文档,比如有标题的,可以优先根据标题和对应内容进行划分(就是按照题目和对应答案切分成一个块),再考虑chunk_size
基于语义分割模型:还可以考虑使用语义分割模型 - 模型效果
尝试使用更多embedding模型,获得更精确的检索结果。如:piccolo-large-zh 或 bge-large-zh-v1.5等等,下文很快阐述 - 向量库
如果知识库比较庞大(文档数量多或文件较大),推荐使用pg向量数据库
如果文件中存在较多相似的内容,可以考虑分门别类存放数据,减少文件中冲突的内容 - 多路召回
结合传统方法进行多路召回 - 精排
对多路召回得到的结果进行精排
1.1.3 embedding优化:针对「Bert的预训练过程是什么?」把m3e替换成bge
关于各个embedding模型的介绍,请看此文:一文通透Text Embedding模型:从text2vec、openai-ada-002到m3e、bge
考虑到bge在各方面的表现不错,所以接下来,我们把m3e替换成bge再试下(至于如何更换embedding模型?1 找到condigs下的model_config.py文件;2 修改所用embedding模型的路径,即MODEL_PATH下的embed_model中的模型对应的路径,如:"bge-large-zh": "/data/datasets/bge-large-zh",3 修改选用的embedding模型:EMBEDDING_MODEL = "bge-large-zh"),得到的结果是:
- bge-large-zh检索到了与问题最相关的结果,但最相关的结果并没有排在第一位
- 而m3e是没有检索到最相关的结果的
如下图所示

最终大模型也正常答出来了(答到了点子上:MLM和NSP)

第二部分 如何解决检索到相关但不根据相关结果回答
2.1 开源LLM并没有完全根据文档内容来回答,而是根据模型自有的预训练知识回答
LLM问题主要有以下几点:
- LLM的回答会出现遗漏信息或补充多余信息的情况
- chatglm2-6b还会出现回答明显错误的情况
2.1.1 针对「用通俗的语言介绍下强化学习?」检索到部分相关
比如问一个面试题:用通俗的语言介绍下强化学习?
- 该问题在文档中的结果如下:

- m3e检索得到的内容如下:
可以看出出处 [1] 2022Q2大厂面试题共92题(含答案及解析).pdf
CART 树算法的核心是在生成过程中用基尼指数来选择特征。 4、用通俗的语言介绍下强化学习(Reinforcement Learning)监督学习的特点是有一个“老师”来“监督”我们,告诉我们正确的结果是什么。在我们在小的时候,会有老师来教我们,本质上监督学习是一种知识的传递,但不能发现新的知识。对于人类整体而言,真正(甚至唯一)的知识来源是实践——也就是强化学习。比如神农尝百草,最早人类并不知道哪些草能治病,但是通 过尝试,就能学到新的知识。学习与决策者被称为智能体,与智能体交互的部分则称为环境。智能体与环境不断进行交互,具体而言,这一交互的过程可以看做是多个时刻,每一时刻,智能体根据环境的状态,依据一定的策略选择一个动作(这
出处 [2] 2021Q3大厂面试题共107题(含答案及解析).pdf
20.2 集成学习的方式,随机森林讲一下,boost 讲一下, XGBOOST 是怎么回事讲一下。 集成学习的方式主要有 bagging,boosting,stacking 等,随机森林主要是采用了 bagging 的思想,通过自助法(bootstrap)重采样技术,从原始训练样本集 N 中有放回地重复随机抽取 n 个样本生成新的训练样本集合训练决策树,然后按以上步骤生成 m 棵决策树组成随机森林,新数据的分类结果按分类树 投票多少形成的分数而定。 boosting是分步学习每个弱分类器,最终的强分类器由分步产生的分类器组合而成,根据每步学习到的分类器去改变各个样本的权重(被错分的样本权重加大,反之减小) 它是一种基于 boosting增强策略的加法模型,训练的时候采用前向分布算法进行贪婪的学习,每次迭代
出处 [3] 2022Q2大厂面试题共92题(含答案及解析).pdf
特征工程可以并行开发,大大加快开发的速度。 训练速度较快。分类的时候,计算量仅仅只和特征的数目相关。 缺点:准确率欠佳。因为形式非常的简单,而现实中的数据非常复杂,因此,很难达到很高的准确性。很难处理 数据不平衡的问题。 3、介绍下决策树算法常见的决策树算法有三种:ID3、C4.5、CART 树 ID3 算法的核心是在决策树的每个节点上应用信息增益准则选择特征,递归地构架决策树。C4.5 算法的核心是在生成过程中用信息增益比来选择特征。 CART 树算法的核心是在生成过程中用基尼指数来选择特征。4、用通俗的语言介绍下强化学习(Reinforcement Learning)
第一个检索结果和问题是相关的
第二个检索结果和问题是完全没关系的
而第三个检索结果的最后一句话是和问题相关的
顺带提一下,如果把m3e替换成bge-large-zh,则其检索到的第1个结果和m3e的第1个结果是一致的,第2个结果则和m3e的第3个结果一样(只最后一句话是和问题相关),第3个结果则检索到的SVM(和问题完全无关),详见我司的「大模型项目开发线上营」之“bge-large-zh模型例子” - 最终,m3e + chatglm2基于知识库给的答案如下图左侧所示,bge-large-zh + chatglm2则如下图右侧所示:
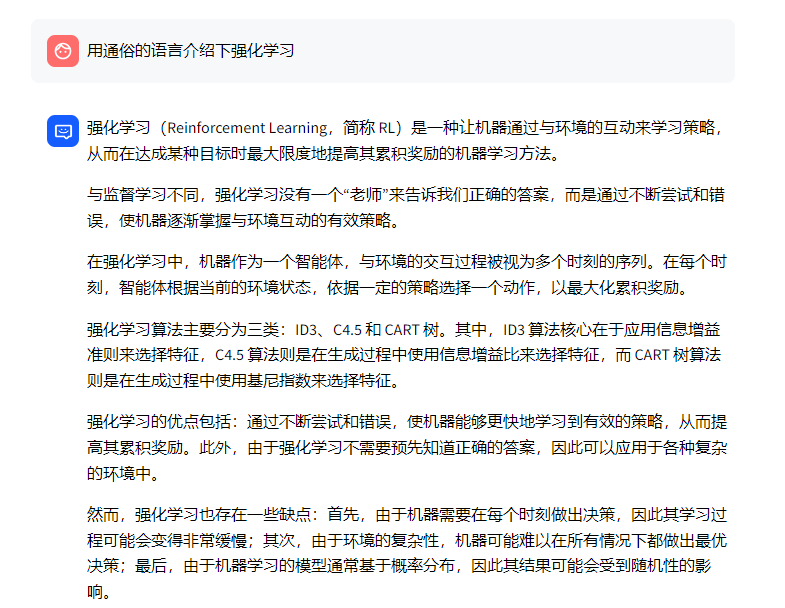
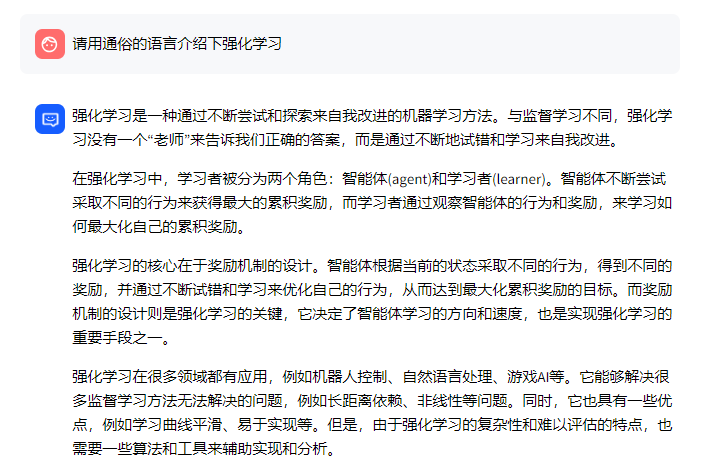
可以看出,m3e + chatglm2并没有完全根据文档内容来回答,而是基于自己的知识进行了相应回答,而对于回答的第三段话,强化学习算法主要有三种:ID3、C4.5和CART树。可以看出,这段话的表达是完全错误的
2.1.2 针对「生成式模型和判别式模型的区别并举一些例子」检索到的全是相关的
再看一个例子,即提问:生成式模型和判别式模型的区别并举一些例子
- 其在文档(知识库)中的答案如下

- m3e检索到的结果如下,很明显,三个检索结果都精准匹配到了问题

- 但,系统最终实际生成的答案如下(下图左侧是chatglm2-6b,下图右侧是chatglm3-6b)
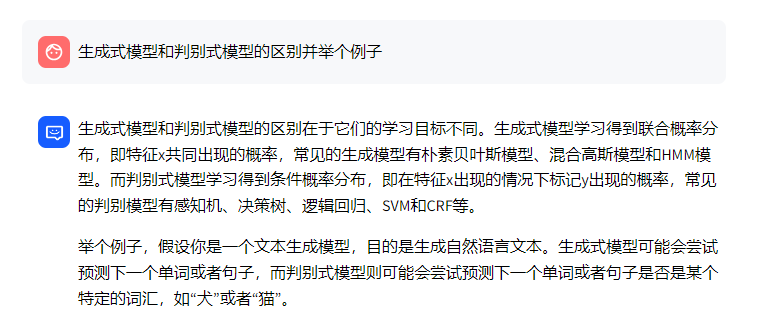
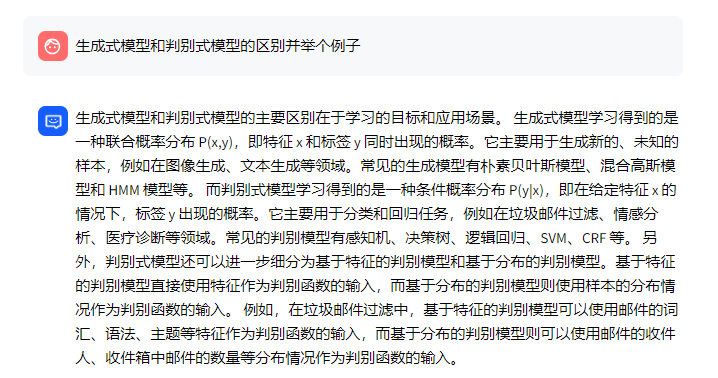
相当于即便在上步骤中,系统检索到的三个结果的内容都是和问题相关的,但大模型还是根据自己的知识进行了回答
2.2 LLM不按照知识库回答的优化方法
- 优先使用最新的6B/7B模型:ChatGLM3-6B、Baichuan2-7B、Qwen-7B
当然,即便有的模型换成到了能力更强的最新版,也不一定听话(依然不严格按照知识库中的回答),例如“2.1.1 针对「用通俗的语言介绍下强化学习?」”中,把chatglm2替换成最新的chatglm3,也未完全严格按照文档中的答案来回答(但GLM3这个结果相比GLM2的结果 至少是进步了,没有出现毫不相干的决策树之类的内容)
所以,如果资源可以支持48G以上的显卡,可以考虑使用Qwen-14B-Chat 或 Baichuan-13B-Chat,13B的模型通常好于6B/7B模型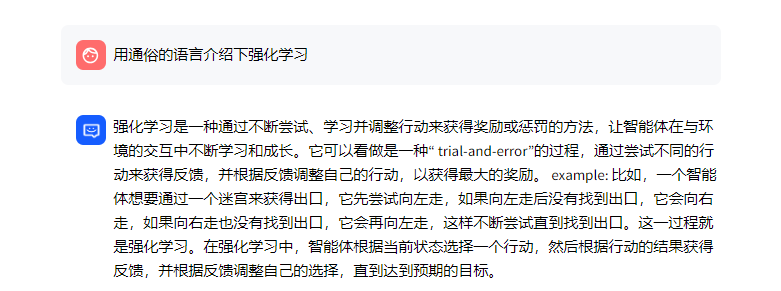
- 优化prompt,可能会有一定效果的。但由于随机性,结果并不能得到保证
- PDF文档解析优化方案,下文详述
第三部分 结构化文档与非结构化文档的典型问题:如何更好分割
3.1 针对结构化文档本身的特点:基于规则针对性分割
3.1.1 对特定结构PDF的解析方案之一:根据书签定位
首先确定咱们目标和步骤,我们需要先解析PDF,然后分别获取文本内容和图片内容,最后拼接文本内容和图片内容
而Langchian-Chatchat中对于不同类型的文件提供了不同的处理方式,从项目server/knoledge_base/utils.py文件中可以看到对于不同类型文件的加载方式,大体有HTML,Markdown,json,PDF,图片及其他类型等
- LOADER_DICT = {"UnstructuredHTMLLoader": ['.html'],
- "UnstructuredMarkdownLoader": ['.md'],
- "CustomJSONLoader": [".json"],
- "CSVLoader": [".csv"],
- # "FilteredCSVLoader": [".csv"], # 需要自己指定,目前还没有支持
- "RapidOCRPDFLoader": [".pdf"],
- "RapidOCRLoader": ['.png', '.jpg', '.jpeg', '.bmp'],
- "UnstructuredFileLoader": ['.eml', '.msg', '.rst',
- '.rtf', '.txt', '.xml',
- '.docx', '.epub', '.odt',
- '.ppt', '.pptx', '.tsv'],
- }
这里,我们重点关注PDF文件的解析方式,并探究其可能的优化方案
从上面的文件加载字典中可以看出,PDF文件使用的加载器为RapidOCRPDFLoader,该文件的方法在项目document_loaders/mypdfloader.py中
处理方法:
- 首先使用fitz(即pyMuPDF)的open方法解析PDF文件;
- 对于每一页的文本内容,通过get_text方法进行获取,而对于图片内容通过get_images方法进行获取,获取后通过RapidOCR对图片中的文本内容进行提取;
- 最后将从图片中提取的文本和原始的文本内容进行拼接,得到最终的所有文本内容。然后进行下一步的分词和文本切割。
这种方式的优点简单粗暴,基本上对于任何排版的PDF文件都能够提取到有效信息。但缺点也很明显,就是无差别,比如我们的文档本身就有较好结构,提取出来的内容也无法将结构反映出来。所以,通常情况下需要根据文档的具体情况对解析后的文档做进一步定制化处理
-
首先,分析七月在线大厂面试题PDF文档特点
以七月在线大厂面试题PDF文档为例,有以下特点:
文档具有书签,可以直接根据书签对应到具体的页码
文档结构不复杂,共有两级标题,一级标题表示一个大的章节,二级标题表示面试题的问题,文本内容为每道面试题对应的答案
因此,可以考虑根据文档的标题进行分割,即将文档中的标题和标题对应的内容分为一块,在放入向量库的时候可以尝试两种方式
一种是只将题目进行向量化表示存入向量库
另一种是将题目和答案一起进行向量化表示存入向量库
每道面试题是独立的,和其前后的面试题并没有明显的相关性
面试题题目的长度长短不一,短的有几个词组成,长的基本一句话
文档中除中文外,还有大量模型或算法英文词,且文档中包含部分公式和代码 -
然后考虑PDF文档解析可选方案
对此,尝试了几种PDF解析工具包:pdfplumber、PyPDF2、fitz(PyMuPDF)
通过fitz获取书签信息,得到面试题题目与其所在的页码,保存为一个字典
尝试用pdfplumber、PyPDF2、fitz抽取每一页的文本信息,与字典中的标题进行匹配(使用find方法)
通过面试题当前位置和下一个面试题位置(这里的位置指的是索引),对面试题进行分块;
最后,输出面试题与其对应的答案 -
当然,PDF文档解析会存在一些问题
比如
书签中的标题内容和文档中的标题内容并不完全一致,这种情况可能是解析后出现多余的空格导致的
需要考虑一道面试题可能存在跨页的情况,一般是会出现一道面试题出现在两页的情况,但也需要考虑一道面试跨三页或多页的情况
由于一级标题是有分页符的,每个一级标题会另起一页,因此在处理时也需要考虑此种情况。
解析的文本中带有页脚,如:第 4 页 共 46 页,由于页脚的内容对面试题是没有意义的,因此也需要考虑去掉 -
最终确定PDF文档解析的解决方案
解决方案:
对于书签中的标题内容和文档中的标题内容并不完全一致的问题
一种方式有考虑去除文档中标题的空格,实现困难在于无法精确定位,如果全去掉就会出现一些英文单词拼接在一块的情况,可能对语义或后续的检索产生影响
一种方式是不去除,如果出现这种情况,则将标题所在页的信息都提取出来;
对于一道面试题可能存在跨页的情况,可以通过设置起始页和终止页,对相邻标题(主要是下一个标题)所在页进行判断的方式来处理;
对于每个一级标题会另起一页的情况,可以通过添加对特殊字符“1、”判断的方式来处理;
对于页脚,可以使用正则表达式进行匹配去除
以上方案更多针对文档的书签是准确的,和对应的标题完全对应(代码实现则在七月在线的大模型项目开发线上营中见),那如果书签不够准确或者没有书签呢,则需要另寻办法,详见下节
3.1.2 对特定结构PDF的解析方案之二:通过字体大小或字体类型
如果文档中没有书签信息,则可以直接对每一页中的标题根据一定的规则进行识别,如可以通过字体的大小或字体类型进行规则设定
3.1.2.1 通过字体大小获取标题
- 通过get_text方法获取表的相关信息
该方法通过查看PDF文件中不同大小的字体,设置一定的规则获取面试题的题目
通过page_toc.get_text("dict")["blocks"]方法可以得到每一行的相关信息,然后查看其中一个block中的具体信息如下: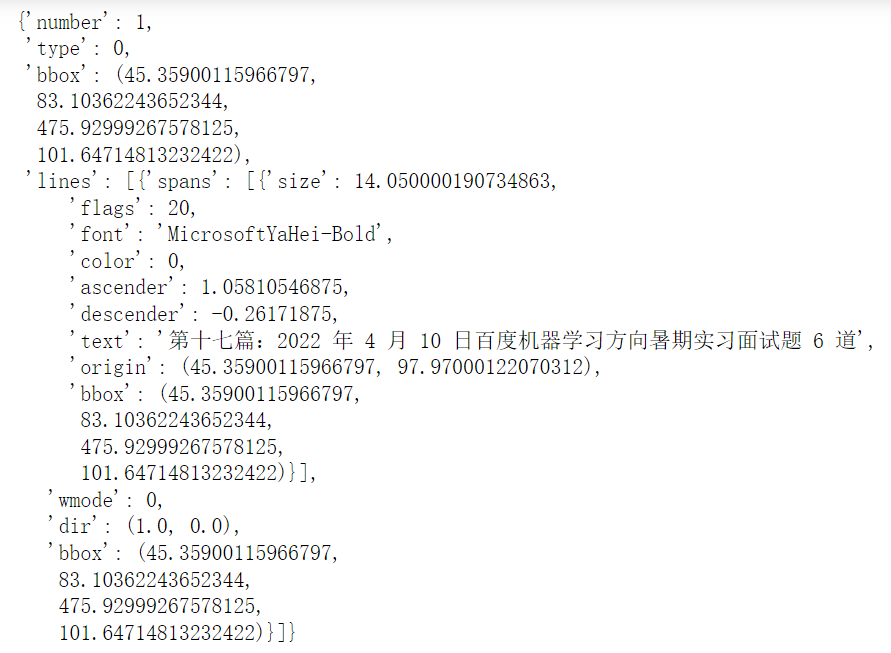
其中,number表示行的索引
font 表示的是文本的字体
text 表示的文本内容
bbox 包含:x0, y0, x1, y1,即文本块的左下角和右上角的坐标。这表示文本块在页面上的位置 - 计算文本字体高度,获取标题高度范围
分别查看第1,25,21行的关键信息:bbox,text,number,并根据bbox的坐标计算文本字体高度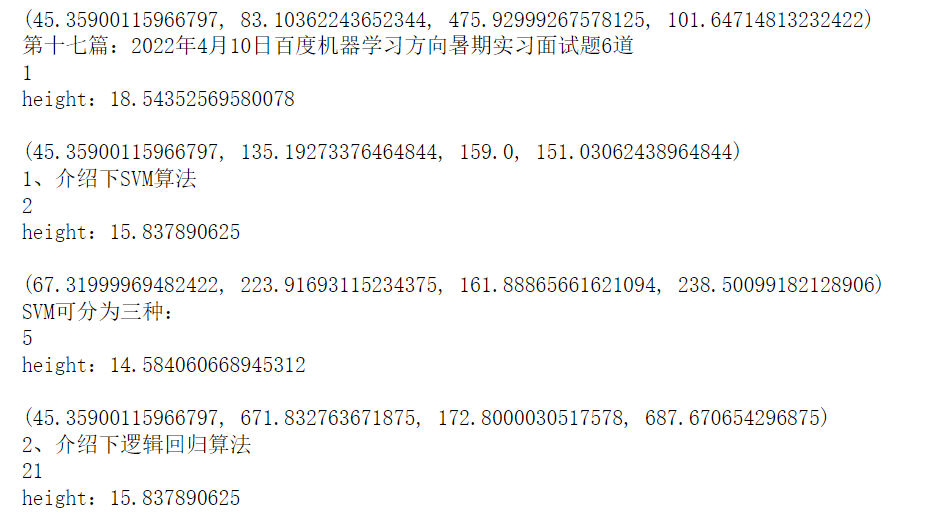
从结果可知,标题的高度介于15到18之间 - 顺道有个问题值得提一下,用于测试的PDF共有92题,但通过字体大小获取到的题目个数为95个,其中有一个为目录,另外两个的题目存在多行

故代码中对存在多行的标题进行了逻辑处理,处理后的数量为正常的92个(具体处理的代码见七月在线的大模型项目开发线上营)
3.1.2.2 通过字体类型和规则获取标题
- 查看只包含标点符号 、的文本

通过结果可以看到,只通过标点符号、是不能准确将所有标题找到。因此还可以从字体的角度出发来解决 - 标点符号 、结合字体类型获取标题

可以看出,通过标点符号、和字体MicrosoftYaHei-Bold,可以将所有的标题匹配出来,但对于多行标题来讲,与获取的题目并不能完全匹配(这个对多行标题额外处理下即可,具体怎么处理,详见大模型项目开发线上营)
通过正则表达式去除标题和页码信息
大标题,如:第十七篇:2022 年 4 月 10 日百度机器学习方向暑期实习面试题 6 道
页码信息,如:第 1 页 共 46 页

比较一下上述两种解决方案
- 通过字体大小获取的标题
可以得到对题目完全对应的标题,但在和每一页的信息匹配的时候,多行的标题并无法和正文信息中的标题成功匹配 - 通过字体类型和规则获取的标题
尽管对多行的标题与题目并不能完全匹配,但可以和正文中的标题成功匹配,且考虑到多行标题中第二行的信息很少并无太大影响,故相比下此方法会更好。
注意:本文档中只用了pymupdf解析器,这样可以保证面试题题目的获取与正文信息获取的一致性,而不会出现使用不同解析器可能导致匹配效果差的情况
接下来,咱们来看下语义分割的方案
3.2 如何解决非结构化文档分割不够准确的问题:比如最好按照语义切分
// 待更
第四部分 让召回结果更全面、准确,及基于表格的问答
4.1 如何确保召回结果的全面性与准确性:多路召回与最后的去重/精排
// 待更
4.2 如何解决基于文档中表格的问答
// 待更
评论记录:
回复评论: