
目录
(一)无重复字符的最长子串(Longest Substring Without Repeating Characters)
(三)最小覆盖子串(Minimum Window Substring)
(六)找到字符串中所有字母异位词(Find All Anagrams in a String)
(九)重复的DNA序列(Repeated DNA Sequences)
(十一)存在重复元素(Contains Duplicate)
(十二)存在重复元素 II(Contains Duplicate II)
(十四)前K个高频元素(Top K Frequent Elements)
(十五)字符串中的第一个唯一字符(First Unique Character in a String)
(十七)和为K的子数组(Subarray Sum Equals K)
(二十)两个数组的交集(Intersection of Two Arrays)
(二一)两个数组的交集 II(Intersection of Two Arrays II)
干货分享,感谢您的阅读!祝你编程题必过!
一、背景知识
散列(Hashing)是一种将任意长度的数据映射为固定长度值的技术。散列函数(Hash function)是执行这种映射的算法,它将原始数据(也称为消息或输入)作为输入,并生成固定长度的输出,称为散列值(Hash value)。这个过程通常被称为“散列”或“哈希”。
当我们使用散列函数时,需要了解以下基本概念:
- 输入数据:输入数据是指需要进行散列的数据,也称为消息或明文。输入数据可以是任意长度的二进制数据,例如文本、图像、音频等。
- 散列值:散列值是指散列函数对输入数据计算后得到的固定长度的二进制值。通常,散列值的长度固定为128、160、256、384或512位。散列值也称为哈希值。
- 散列函数的基本要求:散列函数需要满足以下三个基本要求:一致性、不可逆性和抗碰撞性。
- 一致性:对于同样的输入,散列函数应该始终返回相同的输出值。
- 不可逆性:对于不同的输入数据,生成的散列值应该是唯一的,但是从散列值推导出原始数据应该是非常困难的。
- 抗碰撞性:对于不同的输入数据,生成的散列值应该是不同的,但是在输入数据稍有不同的情况下,生成的散列值应该有很大的区别。
散列函数的基本要求决定了散列函数的应用范围,例如数据完整性检查、数字签名、安全认证等。
总的来说,使用散列函数一般需要进行以下两个步骤:
- 生成散列值:将输入数据通过散列函数转换为一段固定长度的散列值。生成散列值的过程一般可以通过散列函数库或编程语言提供的相关函数来实现。
- 验证散列值的正确性:在需要验证散列值正确性的场景下,一般需要将原始数据重新进行散列计算,并将计算得到的散列值与预先计算好的散列值进行比较。如果两个散列值相同,则说明原始数据没有被篡改或损坏。
Java中提供了相关的类库来实现散列函数的计算和验证。以下示例代码使用Java的MessageDigest类来计算SHA-256散列值。
- package org.zyf.javabasic.letcode.hash;
-
- import java.security.MessageDigest;
- import java.security.NoSuchAlgorithmException;
-
- /**
- * @author yanfengzhang
- * @description 首先指定输入数据为"Hello World",然后通过MessageDigest类创建散列函数对象,
- * 指定散列函数为SHA-256,接着通过update()方法将输入数据添加到散列函数中,
- * 并通过digest()方法计算散列值,最后将散列值转换为十六进制字符串并输出。
- *
- * 验证散列值的正确性可以通过类似的方式进行,即重新计算输入数据的散列值并将其与之前计算得到的散列值进行比较。
- * 可以将上述代码中的"Hello World"替换为其他字符串,重新计算散列值,
- * 并将其与之前计算得到的散列值进行比较,判断原始数据是否被篡改或损坏。
- * @date 2023/4/9 16:51
- */
- public class HashFunctionExample {
- public static void main(String[] args) {
- try {
- /*输入数据*/
- String data = "Hello World";
-
- /*创建MessageDigest对象,指定散列函数为SHA-256*/
- MessageDigest md = MessageDigest.getInstance("SHA-256");
-
- /*计算散列值*/
- md.update(data.getBytes());
- byte[] hash = md.digest();
-
- /*将字节数组转换为十六进制字符串*/
- StringBuilder hexString = new StringBuilder();
- for (byte b : hash) {
- hexString.append(String.format("%02X", b));
- }
-
- /*输出散列值*/
- System.out.println(hexString.toString());
-
- } catch (NoSuchAlgorithmException e) {
- e.printStackTrace();
- }
- }
- }
-
其算法可简单用下图示例:(图来自图灵社区)
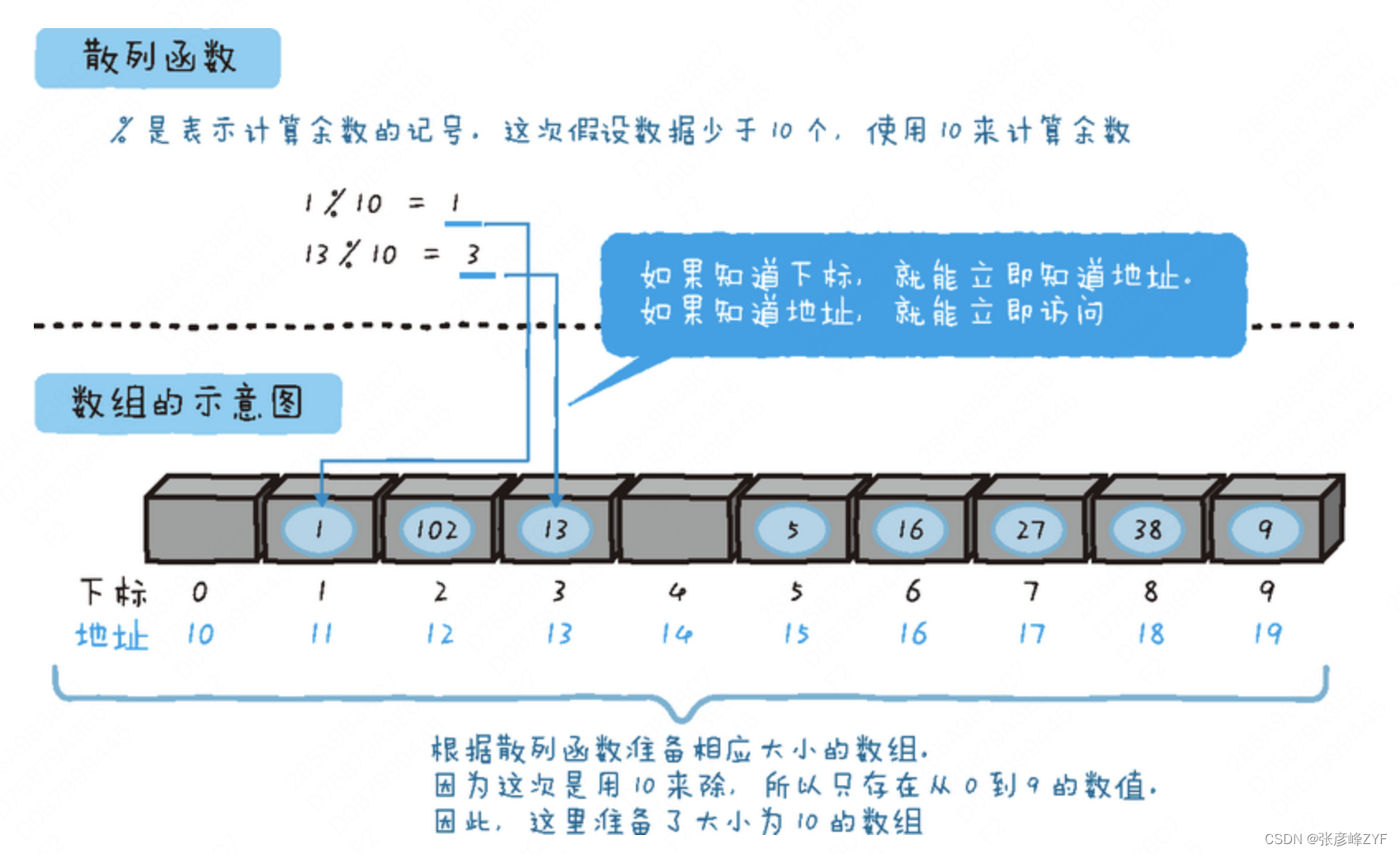
更多基础的散列知识简单统计可见:散列技术自问自答
二、应用举例
(一)Spring框架或其他框架中的应用举例
散列表在许多其他框架和库中也有广泛的应用。下面是一些例子:
- Java集合框架中的HashMap、LinkedHashMap、HashTable和ConcurrentHashMap等集合类都是使用散列表实现的。
- Redis中的Hash类型就是使用散列表来实现的。Redis中的散列表叫做哈希表,可以用于存储键值对,每个哈希表最多可以包含232-1个键值对。
- Hadoop中的MapReduce框架就是基于散列表的。在Map阶段,MapReduce框架将输入数据分成若干个小块,每个小块由Map任务处理,Map任务使用散列表来存储中间结果。在Reduce阶段,MapReduce框架将中间结果进行合并,使用散列表来统计相同键值对的数量。
- Couchbase是一个基于散列表的内存数据库,可以使用它来存储键值对,每个键值对的值可以是任何数据类型,包括字符串、数字、数组、对象等。
- Lucene是一个文本搜索引擎,可以使用它来构建全文搜索引擎。Lucene内部使用了散列表来存储倒排索引,通过倒排索引可以快速地定位包含特定单词的文档。
- 在 Spring 框架中,散列(哈希)算法主要应用在 Spring Security 模块中,用于加密用户密码并进行安全认证。Spring Security 为用户提供了多种加密算法,包括 SHA-256、BCrypt、PBKDF2、SCrypt 等,这些算法都是基于哈希算法实现的。具体来说,在 Spring Security 中,通过在注册时使用哈希算法对用户密码进行加密,然后将加密后的密码存储在数据库中。在用户登录时,Spring Security 会通过哈希算法将用户输入的密码进行加密,然后与数据库中的密码进行比较,从而完成安全认证。由于哈希算法的特性,即使数据库被攻击者窃取,也无法直接获得用户的密码明文。
(二)实际开发中的应用举例
哈希表在实际开发中有广泛应用,以下是几个例子:
- 缓存方面。缓存是应用哈希表最常见的场景之一。缓存中存储的数据可以是任意类型的,因此使用哈希表将其按照键值对的形式存储起来是非常方便的。当需要访问某个数据时,可以通过键值快速获取到对应的值,而无需进行耗时的查询操作。
- 路由方面。路由是另一个常见的应用场景。在路由过程中,需要将请求映射到对应的处理程序或服务。为了实现这一目的,可以使用哈希表将请求与对应的处理程序或服务建立映射关系。当收到请求时,可以通过哈希表快速找到对应的处理程序或服务,从而实现请求的路由。
- 计数方面。计数是哈希表的又一个常见应用场景。在实际开发中,我们需要对某些事件或数据进行计数。例如,我们可能需要统计网站的访问量,或者统计用户的行为次数。在这种情况下,可以使用哈希表将事件或数据的值作为键,将计数器作为值,从而快速进行计数。
- 安全方面。在安全领域中,哈希表也得到了广泛应用。例如,密码哈希可以通过哈希表来实现。在密码哈希中,用户输入的密码会被哈希成一个固定长度的字符串,然后存储在哈希表中。当用户再次登录时,系统会将用户输入的密码哈希后与之前存储的密码哈希进行比对,从而验证用户的身份。
三、相关编程练习
(一)无重复字符的最长子串(Longest Substring Without Repeating Characters)
题目描述:给定一个字符串,请你找出其中不含有重复字符的 最长子串 的长度。
示例1:输入: "abcabcbb" 输出: 3
解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。
示例2:输入: "bbbbb" 输出: 1
解释: 因为无重复字符的最长子串是 "b",所以其长度为 1。
示例3:输入: "pwwkew" 输出: 3
解释: 因为无重复字符的最长子串是 "wke",所以其长度为 3。
请注意,你的答案必须是 子串 的长度,"pwke" 是一个子序列,不是子串。
解题思路
该问题可以使用滑动窗口的方法来解决。
首先,我们需要明确什么是滑动窗口。滑动窗口指的是一个可以滑动的固定长度的窗口,通常用来解决子串或者子数组的问题。
对于本题,我们可以使用滑动窗口来维护一个无重复字符的子串。具体实现时,可以定义两个指针 left 和 right 分别表示无重复字符子串的左右边界。我们用哈希表来记录每个字符出现的位置,以便更新左指针的位置。
具体实现思路如下:
- 初始化 left 和 right 为 0,用一个哈希表来记录每个字符出现的位置。
- 从 left 开始向右遍历字符串,遍历过程中维护一个当前无重复字符子串的哈希表,并记录当前子串的最大长度。
- 如果当前字符 s[right] 在子串中出现过,则需要更新 left 的位置。具体来说,我们将 left 移动到 s[right] 上一次出现的位置的下一个位置。
- 在遍历过程中更新最大长度,并将 s[right] 的位置记录到哈希表中。
- 遍历完成后,返回最大长度即可。
该方法的时间复杂度为 O(n),空间复杂度为 O(min(m,n)),其中 m 表示字符集大小,n 表示字符串长度。
具体代码展示
- package org.zyf.javabasic.letcode.hash;
-
- import java.util.HashMap;
- import java.util.Map;
-
- /**
- * @author yanfengzhang
- * @description 给定一个字符串,请你找出其中不含有重复字符的 最长子串 的长度。
- * @date 2023/4/9 17:58
- */
- public class LongestSubstringWithoutRepeating {
-
- /**
- * 具体实现思路如下:
- * 初始化 left 和 right 为 0,用一个哈希表来记录每个字符出现的位置。
- * 从 left 开始向右遍历字符串,遍历过程中维护一个当前无重复字符子串的哈希表,并记录当前子串的最大长度。
- * 如果当前字符 s[right] 在子串中出现过,则需要更新 left 的位置。具体来说,我们将 left 移动到 s[right] 上一次出现的位置的下一个位置。
- * 在遍历过程中更新最大长度,并将 s[right] 的位置记录到哈希表中。
- * 遍历完成后,返回最大长度即可。
- * 该方法的时间复杂度为 O(n),空间复杂度为 O(min(m,n)),其中 m 表示字符集大小,n 表示字符串长度。
- */
- public int lengthOfLongestSubstring(String s) {
- if (s == null || s.length() == 0) {
- return 0;
- }
-
- int n = s.length();
- /*最大长度*/
- int maxLen = 0;
- /*左指针*/
- int left = 0;
- /*哈希表,记录每个字符的位置*/
- Map
map = new HashMap<>(); -
- /*右指针从 0 开始向右遍历字符串*/
- for (int right = 0; right < n; right++) {
- /*获取当前字符*/
- char c = s.charAt(right);
- /*如果当前字符在子串中出现过,则需要更新左指针的位置*/
- if (map.containsKey(c)) {
- /*左指针移动到当前字符上一次出现的位置的下一个位置*/
- left = Math.max(left, map.get(c) + 1);
- }
- /*记录当前字符的位置*/
- map.put(c, right);
- /*更新最大长度*/
- maxLen = Math.max(maxLen, right - left + 1);
- }
- /*返回最大长度*/
- return maxLen;
- }
-
- public static void main(String[] args) {
- String s = "abcabcbb";
- int res = new LongestSubstringWithoutRepeating().lengthOfLongestSubstring(s);
- /*该代码输出的结果应该为3,因为在字符串 "abcabcbb" 中,
- 无重复字符的最长子串为 "abc",长度为3。*/
- System.out.println(res);
- }
-
- }
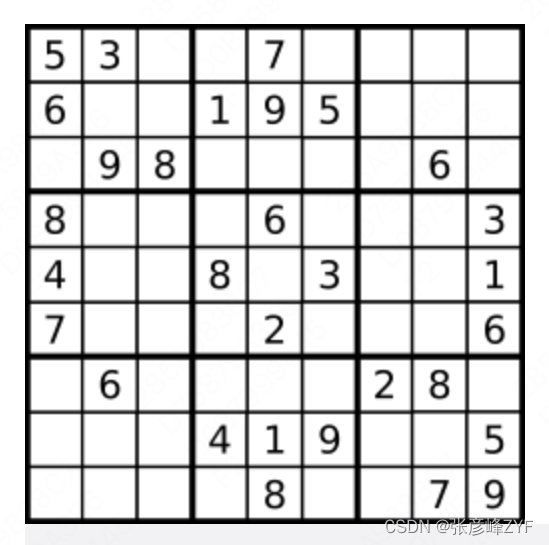
(二)有效的数独(Valid Sudoku)
题目描述:判断一个 9x9 的数独是否有效。只需要根据以下规则,验证已经填入的数字是否有效即可:
- 数字 1-9 在每一行只能出现一次。
- 数字 1-9 在每一列只能出现一次。
- 数字 1-9 在每一个以粗实线分隔的 3x3 宫内只能出现一次。(请参考示例图)
数独部分空格内已填入了数字,空白格用 '.' 表示。
示例:
提示:
- board.length == 9
- board[i].length == 9
- board[i][j] 是一位数字或者 '.'
- 题目数据保证输入数独仅有一个解。
来源:力扣(LeetCode)
链接:力扣

解题思路
该问题可以使用哈希表实现,对于每个数字和每个行、列和子数独,分别记录是否出现过,如果出现过则说明不是有效的数独。
具体实现思路如下:
- 分别使用三个二维布尔数组记录每个数字在每行、每列、每个3x3子数独中是否出现过。数组初始化为false。
- 遍历数独,如果当前位置是数字,则在对应的行、列、子数独的布尔数组中标记该数字已出现。
- 每次标记前先检查当前数字是否已经在对应的行、列、子数独中出现过,如果出现过则说明不是有效的数独。
- 遍历结束后,如果没有出现过重复数字,则说明是有效的数独。
该算法时间复杂度为O(81),空间复杂度为O(27),具有较高的时间和空间效率。
具体代码展示
- package org.zyf.javabasic.letcode.hash;
-
- /**
- * @author yanfengzhang
- * @description 判断一个 9x9 的数独是否有效。
- * @date 2023/4/9 18:11
- */
- public class ValidSudoku {
-
- /**
- * 具体实现思路如下:
- *
- * 分别使用三个二维布尔数组记录每个数字在每行、每列、每个3x3子数独中是否出现过。数组初始化为false。
- * 遍历数独,如果当前位置是数字,则在对应的行、列、子数独的布尔数组中标记该数字已出现。
- * 每次标记前先检查当前数字是否已经在对应的行、列、子数独中出现过,如果出现过则说明不是有效的数独。
- * 遍历结束后,如果没有出现过重复数字,则说明是有效的数独。
- *
- * 该算法时间复杂度为O(81),空间复杂度为O(27),具有较高的时间和空间效率。
- */
- public boolean isValidSudoku(char[][] board) {
- /*行*/
- boolean[][] rows = new boolean[9][9];
- /*列*/
- boolean[][] cols = new boolean[9][9];
- /*子数独*/
- boolean[][] boxes = new boolean[9][9];
-
- /*遍历数独中的每个数字*/
- for (int i = 0; i < 9; i++) {
- for (int j = 0; j < 9; j++) {
- if (board[i][j] != '.') {
- /*当前数字对应的索引*/
- int num = board[i][j] - '1';
- /*当前数字所在的子数独编号*/
- int boxIndex = (i / 3) * 3 + j / 3;
-
- /*若该数字在对应的行、列或子数独中已经出现过,则说明不是有效的数独*/
- if (rows[i][num] || cols[j][num] || boxes[boxIndex][num]) {
- return false;
- }
-
- /*标记该数字在对应的行、列和子数独中已经出现过*/
- rows[i][num] = true;
- cols[j][num] = true;
- boxes[boxIndex][num] = true;
- }
- }
- }
-
- /*遍历结束没有发现重复数字,则说明是有效的数独,返回true*/
- return true;
- }
-
- public static void main(String[] args) {
- char[][] board = {
- {'5', '3', '.', '.', '7', '.', '.', '.', '.'},
- {'6', '.', '.', '1', '9', '5', '.', '.', '.'},
- {'.', '9', '8', '.', '.', '.', '.', '6', '.'},
- {'8', '.', '.', '.', '6', '.', '.', '.', '3'},
- {'4', '.', '.', '8', '.', '3', '.', '.', '1'},
- {'7', '.', '.', '.', '2', '.', '.', '.', '6'},
- {'.', '6', '.', '.', '.', '.', '2', '8', '.'},
- {'.', '.', '.', '4', '1', '9', '.', '.', '5'},
- {'.', '.', '.', '.', '8', '.', '.', '7', '9'}
- };
- boolean isValid = new ValidSudoku().isValidSudoku(board);
- System.out.println(isValid);
- }
-
- }
(三)最小覆盖子串(Minimum Window Substring)
题目描述:给你一个字符串 S、一个字符串 T,请在字符串 S 里面找出:包含 T 所有字符的最小子串。
示例:输入: S = "ADOBECODEBANC", T = "ABC". 输出: "BANC"
说明:
- 如果 S 中不存这样的子串,则返回空字符串 ""。
- 如果 S 中存在这样的子串,我们保证它是唯一的答案。
来源:力扣(LeetCode)
链接:力扣
解题思路
该问题的最优解法是滑动窗口。
算法步骤如下:
- 1.创建两个哈希表:need 和 window,其中 need 用于存储 t 中包含的字符以及每个字符的个数,window 用于存储当前窗口中包含的字符以及每个字符的个数。
- 2.使用 left 和 right 两个指针表示窗口的左右边界。right 向右移动,直到窗口包含了 t 中所有的字符。此时记录窗口的大小和位置。
- 3.移动 left 指针,尝试缩小窗口的大小,直到窗口中的字符串不再完全包含 t 中的所有字符。在每次移动 left 指针时,需要将 window 中对应字符的个数减去 1,并更新窗口的大小和位置。
- 4.重复步骤 2 和 3,直到 right 指针到达 s 的末尾。
算法分析:
- 时间复杂度:O(|s|+|t|),其中 |s| 和 |t| 分别表示字符串 s 和 t 的长度。需要遍历两个字符串一次,因此时间复杂度是线性的。
- 空间复杂度:O(|s|+|t|)。需要使用两个哈希表来存储字符以及字符出现的次数,因此需要额外的空间。
具体代码展示
- package org.zyf.javabasic.letcode.hash;
-
- import java.util.HashMap;
- import java.util.Map;
-
- /**
- * @author yanfengzhang
- * @description 给你一个字符串 S、一个字符串 T,请在字符串 S 里面找出:包含 T 所有字符的最小子串。
- * @date 2023/4/9 18:21
- */
- public class MinimumWindowSubstring {
-
- /**
- * 1.创建两个哈希表:need 和 window,其中 need 用于存储 t 中包含的字符以及每个字符的个数,window 用于存储当前窗口中包含的字符以及每个字符的个数。
- * 2.使用 left 和 right 两个指针表示窗口的左右边界。right 向右移动,直到窗口包含了 t 中所有的字符。此时记录窗口的大小和位置。
- * 3.移动 left 指针,尝试缩小窗口的大小,直到窗口中的字符串不再完全包含 t 中的所有字符。在每次移动 left 指针时,需要将 window 中对应字符的个数减去 1,并更新窗口的大小和位置。
- * 4.重复步骤 2 和 3,直到 right 指针到达 s 的末尾。
- */
- public String minWindow(String s, String t) {
- /*need 哈希表用于存储 t 中包含的字符以及每个字符的个数*/
- Map
need = new HashMap<>(); - /*window 哈希表用于存储当前窗口中包含的字符以及每个字符的个数*/
- Map
window = new HashMap<>(); - /*初始化 need 哈希表*/
- for (char c : t.toCharArray()) {
- need.put(c, need.getOrDefault(c, 0) + 1);
- }
- /*左右指针*/
- int left = 0, right = 0;
- /*valid 表示当前窗口中已经包含了 t 中的字符个数*/
- int valid = 0;
- /*记录最小覆盖子串的起始位置和长度*/
- int start = 0, len = Integer.MAX_VALUE;
- /*当右指针未到达 s 的末尾时循环*/
- while (right < s.length()) {
- /*取出当前窗口的右边界字符*/
- char c = s.charAt(right);
- /*右指针右移*/
- right++;
- /*如果 c 是 t 中的字符*/
- if (need.containsKey(c)) {
- /*将 c 加入到 window 哈希表中*/
- window.put(c, window.getOrDefault(c, 0) + 1);
- /*如果 window 中 c 的数量等于 need 中 c 的数量*/
- if (window.get(c).equals(need.get(c))) {
- /*更新 valid 值*/
- valid++;
- }
- }
- /*当前窗口已经包含了 t 中的所有字符时*/
- while (valid == need.size()) {
- /*更新最小覆盖子串的起始位置和长度*/
- if (right - left < len) {
- start = left;
- len = right - left;
- }
- /*取出当前窗口的左边界字符*/
- char d = s.charAt(left);
- /*左指针右移*/
- left++;
- /*如果 d 是 t 中的字符*/
- if (need.containsKey(d)) {
- /*如果 window 中 d 的数量等于 need 中 d 的数量*/
- if (window.get(d).equals(need.get(d))) {
- /*更新 valid 值*/
- valid--;
- }
- /*将 d 从 window 中减少一个*/
- window.put(d, window.get(d) - 1);
- }
- }
- }
- /*返回最小覆盖子串*/
- return len == Integer.MAX_VALUE ? "" : s.substring(start, start + len);
- }
-
- public static void main(String[] args) {
- String s = "ADOBECODEBANC";
- String t = "ABC";
- String res = new MinimumWindowSubstring().minWindow(s, t);
- /*输出 "BANC"*/
- System.out.println(res);
- }
-
- }
(四)字母异位词分组(Group Anagrams)
题目描述:给定一个字符串数组 strs,将由相同字母异位词组成的组合在一起,返回这些组合。可以按任意顺序返回答案。
字母异位词指字母相同,但排列不同的字符串。
示例 1:输入: strs = ["eat", "tea", "tan", "ate", "nat", "bat"]
输出: [["bat"],["nat","tan"],["ate","eat","tea"]]
示例 2:输入: strs = [""] 输出: [[""]]
示例 3:输入: strs = ["a"] 输出: [["a"]]
提示:
- 1 <= strs.length <= 10^4
- 0 <= strs[i].length <= 100
- strs[i] 仅包含小写字母
解题思路
使用哈希表思路
将每个字符串排序,相同排序后的字符串即为字母异位词,将其分到同一组中。具体实现时,可以使用哈希表来存储每个排序后的字符串对应的原始字符串集合。
时间复杂度为 O(nklogk),其中 n 是字符串数组的长度,k 是字符串的最大长度。主要的时间消耗在排序操作上,排序的时间复杂度为 O(klogk),而对于每个字符串,需要进行一次排序,因此总时间复杂度为 O(nklogk)。
空间复杂度为 O(nk),其中 n 是字符串数组的长度,k 是字符串的最大长度。空间复杂度主要取决于哈希表存储的空间。
具体代码展示
- package org.zyf.javabasic.letcode.hash;
-
- import java.util.ArrayList;
- import java.util.Arrays;
- import java.util.HashMap;
- import java.util.List;
- import java.util.Map;
-
- /**
- * @author yanfengzhang
- * @description 给定一个字符串数组 strs,将由相同字母异位词组成的组合在一起,返回这些组合。可以按任意顺序返回答案。
- * 字母异位词指字母相同,但排列不同的字符串。
- * @date 2023/4/9 18:35
- */
- public class GroupAnagrams {
-
- /**
- * 使用哈希表思路
- * 将每个字符串排序,相同排序后的字符串即为字母异位词,将其分到同一组中。
- * 具体实现时,可以使用哈希表来存储每个排序后的字符串对应的原始字符串集合。
- */
- public List
> groupAnagrams(String[] strs) { - Map
> map = new HashMap<>(); - for (String s : strs) {
- /*将字符串排序后作为键*/
- char[] ch = s.toCharArray();
- Arrays.sort(ch);
- String key = new String(ch);
- /*将原字符串添加到对应的值列表中*/
- if (!map.containsKey(key)) {
- map.put(key, new ArrayList
()); - }
- map.get(key).add(s);
- }
- /*返回哈希表中所有的值列表*/
- return new ArrayList<>(map.values());
- }
-
- public static void main(String[] args) {
- String[] strs = {"eat", "tea", "tan", "ate", "nat", "bat"};
- List
> res = new GroupAnagrams().groupAnagrams(strs); - /*[[eat, tea, ate], [tan, nat], [bat]]*/
- System.out.println(res);
- }
-
- }
(五)有效的字母异位词(Valid Anagram)
题目描述:给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的字母异位词。
示例 1:输入: s = "anagram", t = "nagaram". 输出: true
示例 2:输入: s = "rat", t = "car". 输出: false
说明:你可以假设字符串只包含小写字母。
进阶:如果输入字符串包含 unicode 字符怎么办?你能否调整你的解法来应对这种情况?
解题思路
这道题可以使用哈希表来解决。具体实现步骤如下:
- 创建一个哈希表,用于记录每个字符出现的次数。
- 遍历字符串 s,将其中的每个字符及其出现次数加入哈希表。
- 遍历字符串 t,对于其中的每个字符,在哈希表中将其出现次数减一。
- 如果在哈希表中对应字符的出现次数已经为 0,说明字符串 t 中出现了一个字符串 s 中不存在的字符,直接返回 false。
- 如果遍历字符串 t 后没有出现不相等的字符,返回 true
算法分析:
- 时间复杂度:O(n),其中 n 是字符串 s 和字符串 t 的长度。需要遍历字符串 s 和字符串 t 各一次,因此时间复杂度是线性的。
- 空间复杂度:O(n),需要使用哈希表来记录每个字符出现的次数,因此需要额外的空间。
注:另外,本问题也可以使用排序的方法解决,时间复杂度也是 O(n log n),空间复杂度为 O(1),但排序方法需要修改字符串,因此不太实用,这里不再赘述。
具体代码展示
- package org.zyf.javabasic.letcode.hash;
-
- import java.util.HashMap;
- import java.util.Map;
-
- /**
- * @author yanfengzhang
- * @description 给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的字母异位词。
- * @date 2023/4/9 18:46
- */
- public class ValidAnagram {
- /**
- * 这道题可以使用哈希表来解决。具体实现步骤如下:
- *
- * 创建一个哈希表,用于记录每个字符出现的次数。
- * 遍历字符串 s,将其中的每个字符及其出现次数加入哈希表。
- * 遍历字符串 t,对于其中的每个字符,在哈希表中将其出现次数减一。
- * 如果在哈希表中对应字符的出现次数已经为 0,说明字符串 t 中出现了一个字符串 s 中不存在的字符,直接返回 false。
- * 如果遍历字符串 t 后没有出现不相等的字符,返回 true
- */
- public boolean isAnagram(String s, String t) {
- /*如果两个字符串的长度不相等,直接返回 false*/
- if (s.length() != t.length()) {
- return false;
- }
- /*创建一个哈希表,用于记录每个字符出现的次数*/
- Map
map = new HashMap<>(); - /*遍历字符串 s,将其中的每个字符及其出现次数加入哈希表*/
- for (int i = 0; i < s.length(); i++) {
- char c = s.charAt(i);
- map.put(c, map.getOrDefault(c, 0) + 1);
- }
- /*遍历字符串 t,对于其中的每个字符,在哈希表中将其出现次数减一*/
- /*如果在哈希表中对应字符的出现次数已经为 0,说明字符串 t 中出现了一个字符串 s 中不存在的字符,直接返回 false*/
- for (int i = 0; i < t.length(); i++) {
- char c = t.charAt(i);
- if (!map.containsKey(c)) {
- return false;
- }
- int count = map.get(c);
- if (count == 0) {
- return false;
- }
- map.put(c, count - 1);
- }
- /*如果遍历字符串 t 后没有出现不相等的字符,返回 true*/
- return true;
- }
-
- public static void main(String[] args) {
- String s = "anagram";
- String t = "nagaram";
- /*输出 true*/
- System.out.println(new ValidAnagram().isAnagram(s, t));
-
- String s2 = "rat";
- String t2 = "car";
- /*输出 false*/
- System.out.println(new ValidAnagram().isAnagram(s2, t2));
- }
-
- }
(六)找到字符串中所有字母异位词(Find All Anagrams in a String)
题目描述:给定一个字符串 s 和一个非空字符串 p,找到 s 中所有是 p 的字母异位词的子串,返回这些子串的起始索引。
字符串只包含小写英文字母,并且字符串 s 和 p 的长度都不超过 20100。
示例 1:输入:s: "cbaebabacd" p: "abc". 输出:[0, 6]
解释:起始索引等于 0 的子串是 "cba",它是 "abc" 的字母异位词。
起始索引等于 6 的子串是 "bac",它是 "abc" 的字母异位词。
示例 2:输入:s: "abab" p: "ab". 输出:[0, 1, 2]
解释:起始索引等于 0 的子串是 "ab",它是 "ab" 的字母异位词。
起始索引等于 1 的子串是 "ba",它是 "ab" 的字母异位词。
起始索引等于 2 的子串是 "ab",它是 "ab" 的字母异位词。
来源:力扣(LeetCode)
链接:力扣
解题思路
该问题可以通过哈希表来解决。具体步骤如下:
- 创建一个哈希表,用于存储每个字符在目标字符串 p 中出现的次数。
- 初始化窗口指针 left 和 right,分别指向字符串 s 的开头。
- 进入循环,不断移动右指针,每次将右指针指向的字符在哈希表中的计数器减 1。
- 当发现某个字符在哈希表中的计数器等于 0 时,说明该字符已经在窗口中出现了足够多的次数,可以将左指针向右移动,缩小窗口的大小。
- 如果发现当前窗口的大小等于 p 的长度,说明找到了一个字母异位词,将左指针加入结果集中。
- 重复步骤 3 到 5,直到右指针移动到字符串 s 的末尾。
时间复杂度分析:在最坏情况下,需要对字符串 s 中的每个字符进行两次操作,因此时间复杂度为 O(n),其中 n 是字符串 s 的长度。同时,由于只用了常数个额外变量,空间复杂度为 O(1)。
具体代码展示
- package org.zyf.javabasic.letcode.hash;
-
- import java.util.ArrayList;
- import java.util.List;
-
- /**
- * @author yanfengzhang
- * @description 给定一个字符串 s 和一个非空字符串 p,找到 s 中所有是 p 的字母异位词的子串,返回这些子串的起始索引。
- * 字符串只包含小写英文字母,并且字符串 s 和 p 的长度都不超过 20100。
- * @date 2023/4/9 19:01
- */
- public class FindAllAnagrams {
-
- /**
- * 该问题可以通过哈希表来解决。具体步骤如下:
- *
- * 创建一个哈希表,用于存储每个字符在目标字符串 p 中出现的次数。
- * 初始化窗口指针 left 和 right,分别指向字符串 s 的开头。
- * 进入循环,不断移动右指针,每次将右指针指向的字符在哈希表中的计数器减 1。
- * 当发现某个字符在哈希表中的计数器等于 0 时,说明该字符已经在窗口中出现了足够多的次数,可以将左指针向右移动,缩小窗口的大小。
- * 如果发现当前窗口的大小等于 p 的长度,说明找到了一个字母异位词,将左指针加入结果集中。
- * 重复步骤 3 到 5,直到右指针移动到字符串 s 的末尾。
- */
- public List
findAnagrams(String s, String p) { - List
result = new ArrayList<>(); - if (s == null || s.length() == 0 || p == null || p.length() == 0) {
- return result;
- }
-
- /*创建哈希表,记录 p 中每个字符出现的次数*/
- int[] hash = new int[26];
- for (char c : p.toCharArray()) {
- hash[c - 'a']++;
- }
-
- /*初始化窗口指针*/
- int left = 0;
- int right = 0;
-
- /*记录窗口中未匹配的字符数量*/
- int count = p.length();
-
- /*进入循环,不断移动右指针*/
- while (right < s.length()) {
- char c = s.charAt(right);
-
- /*如果 s 中的字符在 p 中出现过,将 hash 值减 1,并且 count 减 1*/
- if (hash[c - 'a'] > 0) {
- count--;
- }
- hash[c - 'a']--;
-
- /*如果窗口大小等于 p 的长度,说明找到了一个字母异位词*/
- if (right - left + 1 == p.length()) {
- if (count == 0) {
- result.add(left);
- }
-
- /*将左指针向右移动,缩小窗口的大小*/
- char leftChar = s.charAt(left);
- if (hash[leftChar - 'a'] >= 0) {
- count++;
- }
- hash[leftChar - 'a']++;
- left++;
- }
-
- /*右指针向右移动*/
- right++;
- }
-
- return result;
- }
-
- public static void main(String[] args) {
- String s = "cbaebabacd";
- String p = "abc";
- List
result = new FindAllAnagrams().findAnagrams(s, p); - /*expects [0, 6]*/
- System.out.println(result);
- }
-
- }
(七)LRU缓存机制(LRU Cache)
题目描述:设计和实现一个 LRU (最近最少使用) 缓存机制。它应该支持以下操作:获取数据 get 和写入数据 put 。
获取数据 get(key) - 如果密钥 (key) 存在于缓存中,则获取密钥的值(总是正数),否则返回 -1。
写入数据 put(key, value) - 如果密钥不存在,则写入其数据值。当缓存容量达到上限时,它应该在写入新数据之前删除最近最少使用的数据值,从而为新的数据值留出空间。
进阶:你是否可以在 O(1) 时间复杂度内完成这两种操作?
示例:
LRUCache cache = new LRUCache(2);
cache.put(1, 1);
cache.put(2, 2);
cache.get(1); // 返回 1
cache.put(3, 3); // 该操作会使得密钥 2 作废
cache.get(2); // 返回 -1 (未找到)
cache.put(4, 4); // 该操作会使得密钥 1 作废
cache.get(1); // 返回 -1 (未找到)
cache.get(3); // 返回 3
cache.get(4); // 返回 4
解题思路
LRU(Least Recently Used)缓存机制是一种常见的缓存淘汰算法。它根据数据最近被访问的时间来进行淘汰,即当缓存达到最大容量时,优先淘汰最近最少使用的数据。
为了实现 LRU 缓存机制,我们需要用到哈希表和双向链表两个数据结构。其中,哈希表用于实现快速的查找和删除操作,双向链表则用于实现有序的存储和删除操作。
具体实现步骤如下:
- 使用哈希表(HashMap)存储键值对,其中键为缓存的键,值为对应节点在双向链表中的位置。
- 使用双向链表(LinkedList)存储节点,其中每个节点包括键、值和前驱节点、后继节点。
- 每当缓存被访问时,将对应节点移动到双向链表的头部。
- 当缓存容量达到最大值时,将双向链表尾部节点删除并在哈希表中删除对应的键值对。
算法分析:
- 时间复杂度:get 和 put 操作的时间复杂度均为 O(1)。
- 空间复杂度:存储 n 个缓存节点的空间复杂度为 O(n)。
具体代码展示
- package org.zyf.javabasic.letcode.hash;
-
- import java.util.HashMap;
- import java.util.Map;
-
- /**
- * @author yanfengzhang
- * @description 设计和实现一个 LRU (最近最少使用) 缓存机制。它应该支持以下操作:获取数据 get 和写入数据 put 。
- * 获取数据 get(key) - 如果密钥 (key) 存在于缓存中,则获取密钥的值(总是正数),否则返回 -1。
- * 写入数据 put(key, value) - 如果密钥不存在,则写入其数据值。当缓存容量达到上限时,
- * 它应该在写入新数据之前删除最近最少使用的数据值,从而为新的数据值留出空间。
- *
- * 进阶:你是否可以在 O(1) 时间复杂度内完成这两种操作?
- * @date 2023/4/9 19:11
- */
- public class LRUCache {
- class DLinkedNode {
- int key;
- int value;
- DLinkedNode prev;
- DLinkedNode next;
- }
-
- private Map
cache = new HashMap<>(); - private int size;
- private int capacity;
- private DLinkedNode head, tail;
-
- public LRUCache(int capacity) {
- this.size = 0;
- this.capacity = capacity;
- head = new DLinkedNode();
- tail = new DLinkedNode();
- head.next = tail;
- tail.prev = head;
- }
-
- public int get(int key) {
- DLinkedNode node = cache.get(key);
- if (node == null) {
- return -1;
- }
- /*将节点移动到双向链表头部*/
- moveToHead(node);
- return node.value;
- }
-
- public void put(int key, int value) {
- DLinkedNode node = cache.get(key);
- if (node == null) {
- /*如果节点不存在,则创建一个新节点并加入到双向链表头部和哈希表中*/
- DLinkedNode newNode = new DLinkedNode();
- newNode.key = key;
- newNode.value = value;
- cache.put(key, newNode);
- addToHead(newNode);
- size++;
- if (size > capacity) {
- /*如果超出容量,则删除双向链表尾部节点并在哈希表中删除对应的键值对*/
- DLinkedNode tail = removeTail();
- cache.remove(tail.key);
- size--;
- }
- } else {
- /*如果节点存在,则更新节点的值,并将节点移动到双向链表头部*/
- node.value = value;
- moveToHead(node);
- }
- }
-
- private void addToHead(DLinkedNode node) {
- /*将节点加入到双向链表头部*/
- node.prev = head;
- node.next = head.next;
- head.next.prev = node;
- head.next = node;
- }
-
- private void removeNode(DLinkedNode node) {
- /*从双向链表中删除节点*/
- node.prev.next = node.next;
- node.next.prev = node.prev;
- }
-
- private void moveToHead(DLinkedNode node) {
- /*将节点移动到双向链表头部*/
- removeNode(node);
- addToHead(node);
- }
-
- private DLinkedNode removeTail() {
- /*删除双向链表尾部节点,并返回被删除的节点*/
- DLinkedNode tail = this.tail.prev;
- removeNode(tail);
- return tail;
- }
-
- /**
- * 可以看到,LRU 缓存机制在存储容量达到最大值时,
- * 能够正确地淘汰最近最少使用的节点,
- * 并保证每个节点的访问顺序符合 LRU 缓存机制的要求。
- */
- public static void main(String[] args) {
- LRUCache cache = new LRUCache(2);
- cache.put(1, 1);
- cache.put(2, 2);
- /*output: 1*/
- System.out.println(cache.get(1));
- cache.put(3, 3);
- /*output: -1*/
- System.out.println(cache.get(2));
- cache.put(4, 4);
- /*output: -1*/
- System.out.println(cache.get(1));
- /*output: 3*/
- System.out.println(cache.get(3));
- /*output: 4*/
- System.out.println(cache.get(4));
- }
-
- }
-
(八)多数元素(Majority Element)
题目描述:给定一个大小为 n 的数组,找到其中的多数元素。多数元素指在数组中出现次数大于 ⌊n/2⌋ 的元素。
你可以假设数组是非空的,并且给定的数组总是存在多数元素。
示例 1:输入: [3,2,3]. 输出: 3
示例 2:输入: [2,2,1,1,1,2,2]. 输出: 2
解题思路
摩尔投票法:该算法基于一个事实,即在一个数组中,若某个元素出现次数大于数组长度的一半,则该元素必定存在。
算法步骤如下:
- 设置一个候选众数 candidate 和一个计数器 count,初始值分别为任意值和 0。
- 遍历数组 nums 中的每个元素,如果计数器 count 为 0,则将当前元素设置为候选众数 candidate,并将计数器 count 设置为 1;否则,如果当前元素等于候选众数 candidate,则将计数器 count 加 1,否则将计数器 count 减 1。
- 遍历完数组后,candidate 即为众数。
算法分析:
- 时间复杂度:O(n),其中 n 为数组的长度。遍历一遍数组即可找到众数。
- 空间复杂度:O(1),使用常数空间。
具体代码展示
- package org.zyf.javabasic.letcode.hash;
-
- /**
- * @author yanfengzhang
- * @description 给定一个大小为 n 的数组,找到其中的多数元素。
- * 多数元素指在数组中出现次数大于 ⌊n/2⌋ 的元素。
- * @date 2023/4/9 19:21
- */
- public class MajorityElement {
-
- /**
- * 摩尔投票法:该算法基于一个事实,即在一个数组中,若某个元素出现次数大于数组长度的一半,则该元素必定存在。
- *
- * 算法步骤如下:
- * 1 设置一个候选众数 candidate 和一个计数器 count,初始值分别为任意值和 0。
- * 2 遍历数组 nums 中的每个元素,如果计数器 count 为 0,则将当前元素设置为候选众数 candidate,并将计数器 count 设置为 1;
- * 否则,如果当前元素等于候选众数 candidate,则将计数器 count 加 1,否则将计数器 count 减 1。
- * 3 遍历完数组后,candidate 即为众数。
- */
- public static int findMajorityElement(int[] nums) {
- // 候选元素
- int candidate = 0;
- // 候选元素的出现次数
- int count = 0;
-
- for (int num : nums) {
- if (count == 0) {
- // 如果当前候选元素的出现次数为0,则将当前元素设为候选元素,并将出现次数设为1
- candidate = num;
- count = 1;
- } else if (num == candidate) {
- // 如果当前元素与候选元素相同,则候选元素的出现次数加1
- count++;
- } else {
- // 如果当前元素与候选元素不同,则候选元素的出现次数减1
- count--;
- }
- }
-
- // 最终候选元素可能是多数元素,需要再次验证
- int countCandidate = 0;
- for (int num : nums) {
- if (num == candidate) {
- countCandidate++;
- }
- }
-
- // -1 表示没有多数元素
- return countCandidate > nums.length / 2 ? candidate : -1;
- }
-
-
- public static void main(String[] args) {
- int[] nums = {3, 3, 3, 2, 5};
- int result = new MajorityElement().findMajorityElement(nums);
- /*输出 3*/
- System.out.println(result);
- }
-
- }
(九)重复的DNA序列(Repeated DNA Sequences)
题目描述:重复的DNA序列是指长度为10的DNA序列中出现次数大于1的子序列。
给定一个长度为 n 的字符串 s,查找其中所有长度为10的子序列中出现次数大于1的子序列并返回。
原题目链接:力扣
示例:输入:s = "AAAAACCCCCAAAAACCCCCCAAAAAGGGTTT"
输出:["AAAAACCCCC","CCCCCAAAAA"]
输入:s = "AAAAAAAAAAAAA"
输出:["AAAAAAAAAA"]
提示:
- 0 <= s.length <= 105
- s[i] 为小写英文字母或大写英文字母或数字
解题思路
本题可以使用哈希表(HashMap)来解决。我们可以遍历字符串 s,每次取出长度为 10 的子串,判断该子串在哈希表中是否已经存在。如果已经存在,则将该子串加入结果集;否则,在哈希表中将该子串加入,并将对应的值设为 1。
具体实现步骤如下:
- 创建哈希表(HashMap),用于存储子串以及子串出现的次数。
- 遍历字符串 s,每次取出长度为 10 的子串。
- 判断子串是否在哈希表中已经存在,如果已经存在,则将该子串加入结果集;否则,在哈希表中将该子串加入,并将对应的值设为 1。
- 重复步骤 2 和 3,直到遍历完整个字符串 s。
算法分析:
- 时间复杂度:O(n),其中 n 是字符串 s 的长度。需要遍历整个字符串 s 一次,因此时间复杂度是线性的。
- 空间复杂度:O(n),需要使用哈希表来存储子串以及子串出现的次数,因此需要额外的空间。
具体代码展示
- package org.zyf.javabasic.letcode.hash;
-
- import java.util.ArrayList;
- import java.util.HashMap;
- import java.util.List;
- import java.util.Map;
-
- /**
- * @author yanfengzhang
- * @description 重复的DNA序列是指长度为10的DNA序列中出现次数大于1的子序列。
- * 给定一个长度为 n 的字符串 s,查找其中所有长度为10的子序列中出现次数大于1的子序列并返回。
- * @date 2023/4/9 19:30
- */
- public class RepeatedDNASequences {
-
- /**
- * 本题可以使用哈希表(HashMap)来解决。
- * 我们可以遍历字符串 s,每次取出长度为 10 的子串,判断该子串在哈希表中是否已经存在。
- * 如果已经存在,则将该子串加入结果集;否则,在哈希表中将该子串加入,并将对应的值设为 1。
- *
- * 具体实现步骤如下:
- * 创建哈希表(HashMap),用于存储子串以及子串出现的次数。
- * 遍历字符串 s,每次取出长度为 10 的子串。
- * 判断子串是否在哈希表中已经存在,如果已经存在,则将该子串加入结果集;否则,在哈希表中将该子串加入,并将对应的值设为 1。
- * 重复步骤 2 和 3,直到遍历完整个字符串 s。
- */
- public List
findRepeatedDnaSequences(String s) { - /*初始化哈希表和结果集*/
- Map
map = new HashMap<>(); - List
res = new ArrayList<>(); -
- /*遍历字符串 s,每次取出长度为 10 的子串*/
- for (int i = 0; i <= s.length() - 10; i++) {
- String substr = s.substring(i, i + 10);
- /*判断子串是否在哈希表中已经存在*/
- if (map.containsKey(substr)) {
- /*如果已经存在,则将该子串加入结果集*/
- if (map.get(substr) == 1) {
- res.add(substr);
- }
- /*将对应的值加 1*/
- map.put(substr, map.get(substr) + 1);
- } else {
- /*如果不存在,则将该子串加入哈希表,并将对应的值设为 1*/
- map.put(substr, 1);
- }
- }
-
- return res;
- }
-
- public static void main(String[] args) {
- String s1 = "AAAAACCCCCAAAAACCCCCCAAAAAGGGTTT";
- /*Output: [AAAAACCCCC, CCCCCAAAAA]*/
- System.out.println(new RepeatedDNASequences().findRepeatedDnaSequences(s1));
-
- String s2 = "AAAAAAAAAAAA";
- /*Output: [AAAAAAAAAA]*/
- System.out.println(new RepeatedDNASequences().findRepeatedDnaSequences(s2));
-
- String s3 = "AAAAAAAAAAA";
- /*Output: [AAAAAAAAAA]*/
- System.out.println(new RepeatedDNASequences().findRepeatedDnaSequences(s3));
-
- String s4 = "GAGAGAGAGAGAGAGAGAGAGAGAGAGAGAGAGAGAGAGAGAGAGAGAGAGAGAGAGAGAGAGA";
- /*Output: [GAGAGAGAGA]*/
- System.out.println(new RepeatedDNASequences().findRepeatedDnaSequences(s4));
- }
-
- }
(十)快乐数(Happy Number)
题目描述:编写一个算法来判断一个数 n 是不是快乐数。
「快乐数」定义为:对于一个正整数,每一次将该数替换为它每个位置上的数字的平方和。然后重复这个过程直到这个数变为 1,也可能是无限循环但始终变不到 1。如果可以变为 1,那么这个数就是快乐数。
如果 n 是快乐数就返回 true ;不是,则返回 false 。
示例 1:输入:19. 输出:true
解释:1^2 + 9^2 = 82
8^2 + 2^2 = 68
6^2 + 8^2 = 100
1^2 + 0^2 + 0^2 = 1
示例 2:输入:n = 2. 输出:false
提示:
1 <= n <= 2^31 - 1
解题思路
使用哈希集合(HashSet)来存储每一次计算得到的结果,当出现重复的结果时,就说明进入了循环,可以直接返回 false。如果计算得到的结果为 1,则说明该数是快乐数,返回 true。
具体实现步骤如下:
- 将给定的整数 n 转换为字符串类型,以便于对每个位上的数字进行计算。
- 创建一个 HashSet,用于存储每次计算得到的结果。
- 计算数字 n 的各位数字的平方和,并将结果存储到 HashSet 中。
- 重复步骤 3,直到计算得到的结果为 1,此时返回 true;或者得到的结果在 HashSet 中已经存在,此时返回 false。
算法分析:
- 时间复杂度:O(log n),n 表示数字 n 的位数。在每次计算平方和时,需要将数字 n 的每个位上的数字分离出来,因此时间复杂度为 O(log n)。最坏情况下,平方和会一直循环,因此时间复杂度最差情况下为 O(log n)。
- 空间复杂度:O(log n),需要使用 HashSet 来存储计算得到的结果,最坏情况下需要存储 O(log n) 个结果。
具体代码展示
- package org.zyf.javabasic.letcode.hash;
-
- import java.util.HashSet;
- import java.util.Set;
-
- /**
- * @author yanfengzhang
- * @description 编写一个算法来判断一个数 n 是不是快乐数。
- * @date 2023/4/9 19:42
- */
- public class HappyNumber {
-
- /**
- * 使用哈希集合(HashSet)来存储每一次计算得到的结果,
- * 当出现重复的结果时,就说明进入了循环,可以直接返回 false。
- * 如果计算得到的结果为 1,则说明该数是快乐数,返回 true。
- */
- public boolean isHappy(int n) {
- Set
seen = new HashSet<>(); - /*哈希集合判断循环*/
- while (n != 1 && !seen.contains(n)) {
- seen.add(n);
- n = getNext(n);
- }
- return n == 1;
- }
-
- /*计算下一个数*/
- private int getNext(int n) {
- int sum = 0;
- while (n > 0) {
- int digit = n % 10;
- sum += digit * digit;
- n /= 10;
- }
- return sum;
- }
-
- public static void main(String[] args) {
- int n1 = 19;
- /*true*/
- System.out.println(new HappyNumber().isHappy(n1));
-
- int n2 = 2;
- /*false*/
- System.out.println(new HappyNumber().isHappy(n2));
- }
-
- }
备注:最优解法-Floyd 判圈算法
思路
最优解法使用快慢指针(Floyd 判圈算法)来判断是否为快乐数。假设我们要判断的数字为 n,我们可以将 n 看成一个链表,每个数字位上的数字就是链表中的节点值。例如,数字 19 可以看作如下的链表:
1 -> 9 -> 81 -> 82 -> 68 -> 100 -> 1
我们可以使用快慢指针来遍历这个链表,如果最终快指针和慢指针指向了同一个节点,那么这个数字就是快乐数;否则,这个数字不是快乐数。
具体实现步骤如下:
- 使用快慢指针来遍历数字 n 对应的链表,慢指针每次移动一个节点,快指针每次移动两个节点。
- 如果快指针和慢指针指向了同一个节点,那么这个数字就是快乐数;否则,继续遍历链表。
- 如果遍历过程中出现了一个节点在之前已经出现过,那么这个数字就不是快乐数。
算法分析:
- 时间复杂度:时间复杂度是 O(log n),其中 n 是数字的位数,每次计算下一个数字的时间复杂度为 O(log n),最坏情况下需要计算 O(log n) 次。
- 空间复杂度:空间复杂度是 O(1),只需要常数级别的额外空间来存储快慢指针。
代码展示
- public class FloydSolution {
- public boolean isHappy(int n) {
- int slow = n, fast = getNext(n);
- /*快慢指针判断循环*/
- while (fast != 1 && slow != fast) {
- slow = getNext(slow);
- fast = getNext(getNext(fast));
- }
- /*如果最终得到的是 1,则 n 是快乐数*/
- return fast == 1;
- }
-
- /*计算下一个数*/
- private int getNext(int n) {
- int sum = 0;
- while (n > 0) {
- int digit = n % 10;
- sum += digit * digit;
- n /= 10;
- }
- return sum;
- }
- }
(十一)存在重复元素(Contains Duplicate)
题目描述:给定一个整数数组,判断是否存在重复元素。
如果存在一值在数组中出现至少两次,函数返回 true 。如果数组中每个元素都不相同,则返回 false 。
示例 1:输入: [1,2,3,1]. 输出: true
示例 2:输入: [1,2,3,4]. 输出: false
示例 3:输入: [1,1,1,3,3,4,3,2,4,2]. 输出: true
来源:力扣(LeetCode)
链接:力扣
解题思路
最优解法使用哈希表(HashMap)来解决,思路如下:
- 创建一个哈希表,用于存储数组中的元素及其出现的次数。
- 遍历数组中的每个元素,判断该元素是否已经在哈希表中存在。
- 如果该元素在哈希表中已经存在,则说明数组中存在重复元素,返回 true。
- 否则,在哈希表中将该元素加入,并将对应的值设为 1。
- 重复步骤 2、3、4,直到遍历完整个数组。
时间复杂度:O(n),其中 n 是数组的长度。需要遍历整个数组一次,因此时间复杂度是线性的。
空间复杂度:O(n),最坏情况下哈希表需要存储整个数组中的元素,因此需要额外的空间。
具体代码展示
- package org.zyf.javabasic.letcode.hash;
-
- import java.util.HashSet;
- import java.util.Set;
-
- /**
- * @author yanfengzhang
- * @description
- * @date 2023/4/9 19:51
- */
- public class ContainsDuplicate {
- /**
- * 最优解法使用哈希表(HashMap)来解决,思路如下:
- *
- * 创建一个哈希表,用于存储数组中的元素及其出现的次数。
- * 遍历数组中的每个元素,判断该元素是否已经在哈希表中存在。
- * 如果该元素在哈希表中已经存在,则说明数组中存在重复元素,返回 true。
- * 否则,在哈希表中将该元素加入,并将对应的值设为 1。
- * 重复步骤 2、3、4,直到遍历完整个数组。
- */
- public boolean containsDuplicate(int[] nums) {
- /*创建哈希表,用于存储已经遍历过的元素*/
- Set
set = new HashSet<>(); -
- /*遍历整个数组*/
- for (int num : nums) {
- /*如果当前元素已经在哈希表中存在,说明数组中存在重复元素,返回 true*/
- if (set.contains(num)) {
- return true;
- } else {
- /*否则,将当前元素加入哈希表中*/
- set.add(num);
- }
- }
- /*如果遍历完整个数组,都没有发现重复元素,则返回 false*/
- return false;
- }
-
- public static void main(String[] args) {
- int[] nums1 = {1, 2, 3, 1};
- int[] nums2 = {1, 2, 3, 4};
- int[] nums3 = {1, 1, 1, 3, 3, 4, 3, 2, 4, 2};
- /*输出 true*/
- System.out.println(new ContainsDuplicate().containsDuplicate(nums1));
- /*输出 false*/
- System.out.println(new ContainsDuplicate().containsDuplicate(nums2));
- /*输出 true*/
- System.out.println(new ContainsDuplicate().containsDuplicate(nums3));
- }
-
- }
(十二)存在重复元素 II(Contains Duplicate II)
题目描述:给定一个整数数组和一个整数 k,判断数组中是否存在两个不同的索引 i 和 j,使得 nums[i] = nums[j],并且 i 和 j 的差的绝对值最大为 k。
示例 1:输入: nums = [1,2,3,1], k = 3. 输出: true
示例 2:输入: nums = [1,0,1,1], k = 1. 输出: true
示例 3:输入: nums = [1,2,3,1,2,3], k = 2. 输出: false
解题思路
存在重复元素 II 可以使用哈希表来解决。具体步骤如下:
- 创建一个哈希表用于存储元素及其下标的映射。
- 遍历数组 nums 中的每个元素,如果元素已经在哈希表中存在,则计算其下标与哈希表中存储的下标之差是否小于等于 k。如果满足条件,说明存在重复元素,直接返回 true。
- 如果元素不在哈希表中,则将其添加到哈希表中。
- 遍历完整个数组 nums 后,仍然没有发现符合条件的重复元素,则返回 false。
时间复杂度分析:遍历一遍数组 nums 需要 O(n) 的时间,其中 n 是数组的长度。同时,由于只用了一个哈希表,空间复杂度为 O(n)。
具体代码展示
- package org.zyf.javabasic.letcode.hash;
-
- import java.util.HashMap;
- import java.util.Map;
-
- /**
- * @author yanfengzhang
- * @description 给定一个整数数组和一个整数 k,判断数组中是否存在两个不同的索引 i 和 j,
- * 使得 nums[i] = nums[j],并且 i 和 j 的差的绝对值最大为 k。
- * @date 2023/4/9 20:33
- */
- public class ContainsDuplicateII {
-
- /**
- * 存在重复元素 II 可以使用哈希表来解决。具体步骤如下:
- *
- * 创建一个哈希表用于存储元素及其下标的映射。
- * 遍历数组 nums 中的每个元素,如果元素已经在哈希表中存在,则计算其下标与哈希表中存储的下标之差是否小于等于 k。
- * 如果满足条件,说明存在重复元素,直接返回 true。
- * 如果元素不在哈希表中,则将其添加到哈希表中。
- * 遍历完整个数组 nums 后,仍然没有发现符合条件的重复元素,则返回 false。
- * 时间复杂度分析:遍历一遍数组 nums 需要 O(n) 的时间,其中 n 是数组的长度。同时,由于只用了一个哈希表,空间复杂度为 O(n)。
- */
- public boolean containsNearbyDuplicate(int[] nums, int k) {
- /*创建一个哈希表用于存储元素及其下标的映射*/
- Map
map = new HashMap<>(); - for (int i = 0; i < nums.length; i++) {
- /*如果元素已经在哈希表中存在,则计算其下标与哈希表中存储的下标之差是否小于等于 k*/
- if (map.containsKey(nums[i]) && i - map.get(nums[i]) <= k) {
- /*如果满足条件,说明存在重复元素,直接返回 true*/
- return true;
- }
- /*如果元素不在哈希表中,则将其添加到哈希表中*/
- map.put(nums[i], i);
- }
- /*遍历完整个数组 nums 后,仍然没有发现符合条件的重复元素,则返回 false*/
- return false;
- }
-
- public static void main(String[] args) {
- int[] nums = {1, 2, 3, 1};
- int k = 3;
- boolean result = new ContainsDuplicateII().containsNearbyDuplicate(nums, k);
- /*输入的数组 nums 为 {1, 2, 3, 1},k 的值为 3。
- 函数的返回值为 true,因为数组中有两个值为 1 的元素,
- 它们的下标之差为 3,满足题目要求。所以输出为 true。*/
- System.out.println(result);
- }
-
- }
(十三)单词规律(Word Pattern)
题目描述:给定一种规律 pattern 和一个字符串 str,判断 str 是否遵循相同的规律。
这里的遵循指完全匹配,例如,pattern 里的每个字母和字符串 str 中的每个非空单词之间存在着双向连接的对应规律。
示例 1:输入: pattern = "abba", str = "dog cat cat dog". 输出: true
示例 2:输入:pattern = "abba", str = "dog cat cat fish". 输出: false
示例 3:输入: pattern = "aaaa", str = "dog cat cat dog". 输出: false
示例 4:输入: pattern = "abba", str = "dog dog dog dog". 输出: false
说明:你可以假设 pattern 只包含小写字母, str 包含了由单个空格分隔的小写字母。
解题思路
主要思路是使用两个哈希表,一个用于存储 pattern 中每个字符对应的字符串,另一个用于存储字符串对应的 pattern 中的字符。在遍历 pattern 和 words 数组时,对于每个字符和字符串,都在两个哈希表中进行查找,如果存在冲突,则返回 false。如果没有出现冲突,则返回 true。
- 时间复杂度:O(n),其中 n 是字符串words和模式串 pattern 的长度。需要遍历整个字符串words和模式串 pattern 一次,因此时间复杂度是线性的。
- 空间复杂度:O(n),需要使用两个哈希表来存储字符和它们在字符串words和模式串 pattern 中出现的位置,因此需要额外的空间。
具体代码展示
- package org.zyf.javabasic.letcode.hash;
-
- import java.util.HashMap;
- import java.util.Map;
-
- /**
- * @author yanfengzhang
- * @description 给定一种规律 pattern 和一个字符串 str,判断 str 是否遵循相同的规律。
- * 这里的遵循指完全匹配,
- * 例如,pattern 里的每个字母和字符串 str 中的每个非空单词之间存在着双向连接的对应规律。
- * @date 2023/4/9 20:44
- */
- public class WordPattern {
-
- /**
- * 使用两个哈希表,一个用于存储 pattern 中每个字符对应的字符串,
- * 另一个用于存储字符串对应的 pattern 中的字符。
- * 在遍历 pattern 和 words 数组时,
- * 对于每个字符和字符串,都在两个哈希表中进行查找,如果存在冲突,则返回 false。
- * 如果没有出现冲突,则返回 true。
- */
- public boolean wordPattern(String pattern, String s) {
- /*将字符串 s 按照空格分隔为字符串数组*/
- String[] words = s.split(" ");
- /*如果字符串 pattern 和字符串数组 words 的长度不相等,则返回 false*/
- if (pattern.length() != words.length) {
- return false;
- }
- /*创建两个哈希表,一个用于存储 pattern 中每个字符对应的字符串,另一个用于存储字符串对应的 pattern 中的字符*/
- Map
charToString = new HashMap<>(); - Map
stringToChar = new HashMap<>(); - /*遍历 pattern 和 words 数组*/
- for (int i = 0; i < pattern.length(); i++) {
- char c = pattern.charAt(i);
- String word = words[i];
- /*如果哈希表 charToString 中已经包含了该字符,但是对应的字符串不是当前的 word,说明出现了冲突,返回 false*/
- if (charToString.containsKey(c) && !charToString.get(c).equals(word)) {
- return false;
- }
- /*如果哈希表 stringToChar 中已经包含了该字符串,但是对应的字符不是当前的 c,说明出现了冲突,返回 false*/
- if (stringToChar.containsKey(word) && stringToChar.get(word) != c) {
- return false;
- }
- /*将当前的字符和字符串加入两个哈希表中*/
- charToString.put(c, word);
- stringToChar.put(word, c);
- }
- /*如果没有出现冲突,则返回 true*/
- return true;
- }
-
- public static void main(String[] args) {
- String pattern1 = "abba", str1 = "dog cat cat dog";
- boolean res1 = new WordPattern().wordPattern(pattern1, str1);
- /*输出 true*/
- System.out.println(res1);
-
- String pattern2 = "abba", str2 = "dog cat cat fish";
- boolean res2 = new WordPattern().wordPattern(pattern2, str2);
- /*输出 false*/
- System.out.println(res2);
-
- String pattern3 = "aaaa", str3 = "dog cat cat dog";
- boolean res3 = new WordPattern().wordPattern(pattern3, str3);
- /*输出 false*/
- System.out.println(res3);
-
- String pattern4 = "abba", str4 = "dog dog dog dog";
- boolean res4 = new WordPattern().wordPattern(pattern4, str4);
- /*输出 false*/
- System.out.println(res4);
- }
-
- }
(十四)前K个高频元素(Top K Frequent Elements)
题目描述:给定一个非空的整数数组,返回其中出现频率前 k 高的元素。
示例 1:输入: nums = [1,1,1,2,2,3], k = 2. 输出: [1,2]
示例 2:输入: nums = [1], k = 1 输出: [1]
提示:
- 你可以假设给定的 k 总是合理的,且 1 ≤ k ≤ 数组中不相同的元素的个数。
- 你的算法的时间复杂度必须优于 O(n log n) , n 是数组的大小。
题目链接:力扣
解题思路
该问题可以使用哈希表和桶排序来解决,具体思路如下:
- 遍历数组,统计每个元素出现的次数,可以使用哈希表来实现,键为元素值,值为元素出现的次数。
- 将哈希表中的元素放入桶中,桶的下标为元素出现的次数,桶中存放的是出现次数相同的元素值。
- 从桶的末尾开始遍历,依次取出前 k 个出现频率最高的元素。
算法分析:
- 时间复杂度:O(n+k),其中 n 是数组的长度,k 是前 k 大元素的数量。需要遍历整个数组一次,统计每个元素出现的次数,时间复杂度是 O(n)。然后需要遍历每个桶,从后往前取出前 k 个元素,时间复杂度是 O(k)。因此总时间复杂度是 O(n+k)。
- 空间复杂度:O(n),需要使用哈希表存储每个元素出现的次数,以及使用桶来存储每个出现次数对应的元素值,需要额外的空间。
备注:
需要注意的是,桶排序中桶的数量是元素的数量加 1,因为出现频率最高的元素可能会出现 nums.length 次。同时,由于可能会有多个元素出现的频率相同,因此每个桶需要使用 ArrayList 等数据结构来存储多个元素。
使用哈希表和桶排序实现的 Java 代码中,第一步遍历数组 nums,计算每个元素出现的频率并存储到哈希表 frequencyMap 中。第二步,创建一个大小为 nums.length + 1 的桶数组 bucket,将出现频率相同的元素存储在同一个桶中。第三步,从后向前遍历桶数组,将桶中的元素加入结果集中,直到结果集中的元素数量达到 k。
具体代码展示
- package org.zyf.javabasic.letcode.hash;
-
- import java.util.ArrayList;
- import java.util.Arrays;
- import java.util.HashMap;
- import java.util.List;
- import java.util.Map;
-
- /**
- * @author yanfengzhang
- * @description 给定一个非空的整数数组,返回其中出现频率前 k 高的元素。
- * @date 2023/4/9 20:52
- */
- public class TopKFrequentElements {
-
- /**
- * 该问题可以使用哈希表和桶排序来解决,具体思路如下:
- * 遍历数组,统计每个元素出现的次数,可以使用哈希表来实现,键为元素值,值为元素出现的次数。
- * 将哈希表中的元素放入桶中,桶的下标为元素出现的次数,桶中存放的是出现次数相同的元素值。
- * 从桶的末尾开始遍历,依次取出前 k 个出现频率最高的元素。
- */
- public int[] topKFrequent(int[] nums, int k) {
- /*第 1 步:使用哈希表统计每个元素出现的频率*/
- Map
frequencyMap = new HashMap<>(); - for (int num : nums) {
- frequencyMap.put(num, frequencyMap.getOrDefault(num, 0) + 1);
- }
-
- /*第 2 步:使用桶排序,将出现频率作为桶的下标*/
- List
[] bucket = new ArrayList[nums.length + 1]; - for (int key : frequencyMap.keySet()) {
- int frequency = frequencyMap.get(key);
- if (bucket[frequency] == null) {
- bucket[frequency] = new ArrayList<>();
- }
- bucket[frequency].add(key);
- }
-
- /*第 3 步:从后向前遍历桶,并将桶中的元素加入结果集中*/
- int[] result = new int[k];
- int index = 0;
- for (int i = bucket.length - 1; i >= 0 && index < k; i--) {
- if (bucket[i] == null) {
- continue;
- }
- for (int num : bucket[i]) {
- result[index++] = num;
- if (index == k) {
- break;
- }
- }
- }
- return result;
- }
-
- public static void main(String[] args) {
- int[] nums = {1, 1, 1, 2, 2, 3};
- int k = 2;
- int[] res = new TopKFrequentElements().topKFrequent(nums, k);
- /*[1, 2]*/
- System.out.println(Arrays.toString(res));
- }
- }
(十五)字符串中的第一个唯一字符(First Unique Character in a String)
题目描述:给定一个字符串 s ,找到 s 中第一个不重复的字符,并返回它的索引。如果不存在,则返回 -1。
示例:输入:s = "leetcode". 输出:0
输入:s = "loveleetcode". 输出:2
输入:s = "aabb" 输出:-1
提示:
- 1 <= s.length <= 10^5
- s 由小写英文字母组成
来源:力扣(LeetCode)
链接:力扣
解题思路
最优解法是使用哈希表(HashMap)来解决。我们可以先遍历一次字符串 s,统计每个字符出现的次数,并将其存储在哈希表中。然后再遍历一次字符串 s,找到第一个在哈希表中出现次数为 1 的字符,返回该字符在字符串 s 中的位置。
具体实现步骤如下:
- 创建哈希表(HashMap),用于存储每个字符出现的次数。
- 遍历字符串 s,统计每个字符出现的次数,并将其存储在哈希表中。
- 遍历字符串 s,找到第一个在哈希表中出现次数为 1 的字符,返回该字符在字符串 s 中的位置。
- 如果字符串 s 中所有字符都不满足出现次数为 1,则返回 -1。
算法分析:
- 时间复杂度:O(n),其中 n 是字符串 s 的长度。需要遍历字符串 s 两次,因此时间复杂度是线性的。
- 空间复杂度:O(k),其中 k 是字符集的大小。需要使用哈希表来存储每个字符出现的次数,因此需要额外的空间。
具体代码展示
- package org.zyf.javabasic.letcode.hash;
-
- import java.util.HashMap;
- import java.util.Map;
-
- /**
- * @author yanfengzhang
- * @description 给定一个字符串 s ,找到 s 中第一个不重复的字符,并返回它的索引。
- * 如果不存在,则返回 -1。
- * @date 2023/4/9 21:00
- */
- public class FirstUniqueCharacter {
- /**
- * 使用哈希表(HashMap)来解决。
- * 我们可以先遍历一次字符串 s,统计每个字符出现的次数,并将其存储在哈希表中。
- * 然后再遍历一次字符串 s,找到第一个在哈希表中出现次数为 1 的字符,
- * 返回该字符在字符串 s 中的位置。
- */
- public int firstUniqChar(String s) {
- /*创建哈希表,用于存储每个字符出现的次数*/
- Map
map = new HashMap<>(); - /*遍历字符串,统计每个字符出现的次数*/
- for (int i = 0; i < s.length(); i++) {
- char c = s.charAt(i);
- /*如果哈希表中已经有该字符,则将其对应的值加 1*/
- if (map.containsKey(c)) {
- map.put(c, map.get(c) + 1);
- }
- /*否则,在哈希表中添加该字符,并将其对应的值设为 1*/
- else {
- map.put(c, 1);
- }
- }
- /*再次遍历字符串,找到第一个出现次数为 1 的字符*/
- for (int i = 0; i < s.length(); i++) {
- char c = s.charAt(i);
- if (map.get(c) == 1) {
- return i;
- }
- }
- /*如果所有字符都不止出现一次,则返回 -1*/
- return -1;
- }
-
- public static void main(String[] args) {
- String s1 = "leetcode";
- /*xpected output: 0*/
- System.out.println(new FirstUniqueCharacter().firstUniqChar(s1));
-
- String s2 = "loveleetcode";
- /*xpected output: 2*/
- System.out.println(new FirstUniqueCharacter().firstUniqChar(s2));
-
- String s3 = "abcabc";
- /*xpected output: -1*/
- System.out.println(new FirstUniqueCharacter().firstUniqChar(s3));
- }
-
- }
(十六)四数相加 II(4Sum II)
题目描述:给定四个包含整数的数组列表 A , B , C , D ,计算有多少个元组 (i, j, k, l) ,使得 A[i] + B[j] + C[k] + D[l] = 0。
注意:答案中不可以包含重复的四元组。
例如:输入:
A = [ 1, 2]
B = [-2,-1]
C = [-1, 2]
D = [ 0, 2]
输出:2
解释:
两个元组如下:
- (0, 0, 0, 1) -> A[0] + B[0] + C[0] + D[1] = 1 + (-2) + (-1) + 2 = 0
- (1, 1, 0, 1) -> A[1] + B[1] + C[0] + D[1] = 2 + (-1) + (-1) + 2 = 2
解题思路
四数相加 II 问题可以通过将其分解为两个两数相加的问题来解决。具体步骤如下:
- 创建哈希表,分别用于存储 A 数组和 B 数组中所有两个数之和的情况。
- 遍历 A 数组和 B 数组,统计每个数字对应的出现次数,并将其加入哈希表中。
- 遍历 C 数组和 D 数组,对于每个数字,在哈希表中查找其相反数的出现次数,并将计数器累加至结果中。
- 返回结果。
时间复杂度分析:由于需要遍历 A、B、C、D 四个数组,因此时间复杂度为 O(n^2),其中 n 是数组的长度。同时,由于只用了常数个额外变量,空间复杂度为 O(n^2)。
具体代码展示
- package org.zyf.javabasic.letcode.hash;
-
- import java.util.HashMap;
- import java.util.Map;
-
- /**
- * @author yanfengzhang
- * @description 给定四个包含整数的数组列表 A , B , C , D ,
- * 计算有多少个元组 (i, j, k, l) ,使得 A[i] + B[j] + C[k] + D[l] = 0。
- * @date 2023/4/9 21:07
- */
- public class FourNumberSum {
-
- /**
- * 四数相加 II 问题可以通过将其分解为两个两数相加的问题来解决。
- * 具体步骤如下:
- * 创建哈希表,分别用于存储 A 数组和 B 数组中所有两个数之和的情况。
- * 遍历 A 数组和 B 数组,统计每个数字对应的出现次数,并将其加入哈希表中。
- * 遍历 C 数组和 D 数组,对于每个数字,在哈希表中查找其相反数的出现次数,并将计数器累加至结果中。
- * 返回结果。
- */
- public int fourSumCount(int[] nums1, int[] nums2, int[] nums3, int[] nums4) {
- /*创建两个哈希表,分别用于存储 A 数组和 B 数组中所有两个数之和的情况*/
- Map
map = new HashMap<>(); -
- /*遍历 A 数组和 B 数组,统计每个数字对应的出现次数,并将其加入哈希表中*/
- for (int i = 0; i < nums1.length; i++) {
- for (int j = 0; j < nums2.length; j++) {
- int sum = nums1[i] + nums2[j];
- map.put(sum, map.getOrDefault(sum, 0) + 1);
- }
- }
-
- /*遍历 C 数组和 D 数组,对于每个数字,在哈希表中查找其相反数的出现次数,并将计数器累加至结果中*/
- int count = 0;
- for (int i = 0; i < nums3.length; i++) {
- for (int j = 0; j < nums4.length; j++) {
- int sum = nums3[i] + nums4[j];
- if (map.containsKey(-sum)) {
- count += map.get(-sum);
- }
- }
- }
-
- /*返回结果*/
- return count;
- }
-
- public static void main(String[] args) {
- int[] A = {1, 2};
- int[] B = {-2, -1};
- int[] C = {-1, 2};
- int[] D = {0, 2};
-
- int count = new FourNumberSum().fourSumCount(A, B, C, D);
- /*输出 2*/
- System.out.println(count);
- }
- }
(十七)和为K的子数组(Subarray Sum Equals K)
题目描述:给定一个整数数组 nums 和一个整数 k ,请找到该数组中和为 k 的连续子数组的个数。
示例 1:输入:nums = [1,1,1], k = 2. 输出:2
示例 2:输入:nums = [1,2,3], k = 3. 输出:2
提示:
- 1 <= nums.length <= 2 * 10^4
- -1000 <= nums[i] <= 1000
- -10^7 <= k <= 10^7
来源:力扣(LeetCode)
链接:力扣
解题思路
这个问题可以通过前缀和和哈希表来解决。具体步骤如下:
- 创建一个哈希表,用于存储前缀和的计数器。同时初始化前缀和为 0。
- 初始化计数器 count 和当前前缀和为 0。
- 遍历整个数组 nums,对于每个数字,更新当前前缀和并计算前缀和之差。
- 如果发现当前前缀和已经在哈希表中出现过了,说明之前出现过一个前缀和与当前前缀和之差为 k 的位置。将这个位置出现的次数累加至结果中。
- 将当前前缀和的计数器加 1,继续遍历下一个数字。
- 最终返回结果。
时间复杂度分析:由于只需要遍历一遍数组,因此时间复杂度为 O(n),其中 n 是数组的长度。同时,由于只用了常数个额外变量,空间复杂度为 O(n)。
具体代码展示
- package org.zyf.javabasic.letcode.hash;
-
- import java.util.HashMap;
- import java.util.Map;
-
- /**
- * @author yanfengzhang
- * @description 给定一个整数数组 nums 和一个整数 k ,
- * 请找到该数组中和为 k 的连续子数组的个数。
- * @date 2023/4/9 22:14
- */
- public class SubarraySumEqualsK {
-
- public int subarraySum(int[] nums, int k) {
- /*创建哈希表,用于存储前缀和的计数器*/
- Map
map = new HashMap<>(); - /*初始化前缀和为 0,并将其计数器设为 1*/
- map.put(0, 1);
- /*初始化计数器 count 和当前前缀和为 0*/
- int count = 0, sum = 0;
- /*遍历整个数组 nums*/
- for (int num : nums) {
- /*更新当前前缀和*/
- sum += num;
- /*计算前缀和之差*/
- int diff = sum - k;
- /*如果发现当前前缀和已经在哈希表中出现过了*/
- if (map.containsKey(diff)) {
- /*将这个位置出现的次数累加至结果中*/
- count += map.get(diff);
- }
- /*将当前前缀和的计数器加 1,并将其存入哈希表中*/
- map.put(sum, map.getOrDefault(sum, 0) + 1);
- }
- /*返回最终结果*/
- return count;
- }
-
- public static void main(String[] args) {
- int[] nums1 = {1, 1, 1};
- int k1 = 2;
- /*Expected output: 2*/
- System.out.println(new SubarraySumEqualsK().subarraySum(nums1, k1));
-
- int[] nums2 = {1, 2, 3};
- int k2 = 3;
- /*Expected output: 2*/
- System.out.println(new SubarraySumEqualsK().subarraySum(nums2, k2));
-
- int[] nums3 = {3, 2, 1};
- int k3 = 3;
- /*Expected output: 3*/
- System.out.println(new SubarraySumEqualsK().subarraySum(nums3, k3));
-
- int[] nums4 = {1};
- int k4 = 1;
- /*Expected output: 1*/
- System.out.println(new SubarraySumEqualsK().subarraySum(nums4, k4));
-
- int[] nums5 = {1, -1, 0};
- int k5 = 0;
- /*Expected output: 3*/
- System.out.println(new SubarraySumEqualsK().subarraySum(nums5, k5));
- }
- }
(十八)最常见的单词(Most Common Word)
题目描述:给定一个段落 (paragraph) 和一个禁用单词列表 (banned)。返回出现次数最多,同时不在禁用列表中的单词。题目保证至少有一个出现次数最多的单词。
段落中的单词不区分大小写。答案都是小写字母。
示例:
输入:paragraph = "Bob hit a ball, the hit BALL flew far after it was hit." banned = ["hit"]
输出: "ball"
解释:"hit" 出现了3次,但它是一个禁用的单词。
"ball" 出现了2次(大小写不敏感),所以它是段落中出现次数最多的非禁用单词。
注意,此例中出现次数最多的单词也是答案。
提示:
- 1 <= 段落长度 <= 1000
- 0 <= 禁用单词个数 <= 100
- 1 <= 禁用单词长度 <= 10
答案是唯一的,且都是小写字母 (See full description at: 力扣)
解题思路
最常见的单词问题可以通过哈希表和字符串处理来解决。具体步骤如下:
- 创建一个哈希表,用于存储每个单词的出现次数。
- 将原始字符串中所有非字母字符都替换为空格,并将整个字符串转换成小写字母形式。
- 将字符串按照空格分割成一个个单词,并在哈希表中统计每个单词出现的次数。
- 遍历禁用单词列表 banned,将其对应的出现次数都设为 0。
- 遍历哈希表,找到出现次数最多的单词,排除禁用单词列表中的单词。
- 返回出现次数最多的单词。
时间复杂度分析:由于需要遍历原始字符串、禁用单词列表和哈希表,因此时间复杂度为 O(n+m+k),其中 n 是原始字符串的长度,m 是禁用单词列表的长度,k 是哈希表的长度。同时,由于只用了常数个额外变量,空间复杂度为 O(k)。
具体代码展示
- package org.zyf.javabasic.letcode.hash;
-
- import java.util.HashMap;
- import java.util.Map;
-
- /**
- * @author yanfengzhang
- * @description 给定一个段落 (paragraph) 和一个禁用单词列表 (banned)。
- * 返回出现次数最多,同时不在禁用列表中的单词。题目保证至少有一个出现次数最多的单词。
- * 段落中的单词不区分大小写。答案都是小写字母。
- * @date 2023/4/9 22:21
- */
- public class MostCommonWord {
-
- /**
- * 通过哈希表和字符串处理来解决。具体步骤如下:
- *
- * 创建一个哈希表,用于存储每个单词的出现次数。
- * 将原始字符串中所有非字母字符都替换为空格,并将整个字符串转换成小写字母形式。
- * 将字符串按照空格分割成一个个单词,并在哈希表中统计每个单词出现的次数。
- * 遍历禁用单词列表 banned,将其对应的出现次数都设为 0。
- * 遍历哈希表,找到出现次数最多的单词,排除禁用单词列表中的单词。
- * 返回出现次数最多的单词。
- */
- public String mostCommonWord(String paragraph, String[] banned) {
- /*Step 1: 创建哈希表并初始化*/
- Map
wordCount = new HashMap<>(); - for (String word : banned) {
- wordCount.put(word, 0);
- }
-
- /*Step 2: 将字符串中所有非字母字符替换为空格,并将整个字符串转换成小写字母形式*/
- paragraph = paragraph.replaceAll("[^a-zA-Z ]", " ").toLowerCase();
-
- /*Step 3: 统计每个单词出现的次数*/
- String[] words = paragraph.split("\\s+");
- for (String word : words) {
- wordCount.put(word, wordCount.getOrDefault(word, 0) + 1);
- }
-
- /*Step 4: 将禁用单词列表中的单词对应的出现次数都设为 0*/
- for (String word : banned) {
- wordCount.put(word, 0);
- }
-
- /*Step 5: 找到出现次数最多的单词,排除禁用单词列表中的单词*/
- int maxCount = 0;
- String result = "";
- for (String word : wordCount.keySet()) {
- if (wordCount.get(word) > maxCount) {
- maxCount = wordCount.get(word);
- result = word;
- }
- }
-
- /*Step 6: 返回出现次数最多的单词*/
- return result;
- }
-
- public static void main(String[] args) {
- String paragraph = "Bob hit a ball, the hit BALL flew far after it was hit.";
- String[] banned = {"hit"};
- String result = new MostCommonWord().mostCommonWord(paragraph, banned);
- System.out.println(result);
- }
-
- }
(十九)同构字符串(Isomorphic Strings)
题目描述:给定两个字符串 s 和 t,判断它们是否是同构字符串。
如果 s 中的字符可以被替换得到 t ,那么这两个字符串是同构的。
所有出现的字符都必须用另一个字符替换,同时保留字符的顺序。两个字符不能映射到同一个字符上,但字符可以映射自己本身。
示例 1:输入: s = "egg", t = "add". 输出: true
示例 2:输入: s = "foo", t = "bar". 输出: false
示例 3:输入: s = "paper", t = "title". 输出: true
说明:
你可以假设 s 和 t 具有相同的长度。
来源:力扣(LeetCode)
链接:力扣
解题思路
同构字符串问题可以通过哈希表和字符映射来解决。具体步骤如下:
- 创建两个哈希表,分别用于记录 s 到 t 的字符映射和 t 到 s 的字符映射。
- 遍历字符串 s 和 t,对于每个字符,分别在两个哈希表中查找其对应的字符映射。
- 如果两个哈希表中都能找到对应的字符映射,但不相同,则说明 s 和 t 不是同构字符串,直接返回 false。
- 如果两个哈希表中只有其中一个哈希表中能找到对应的字符映射,则说明 s 和 t 不是同构字符串,直接返回 false。
- 如果两个哈希表中都找不到对应的字符映射,则将当前字符的映射加入两个哈希表中。
- 遍历结束后,没有发现不同的字符映射,则说明 s 和 t 是同构字符串,返回 true。
时间复杂度分析:由于需要遍历字符串 s 和 t,因此时间复杂度为 O(n),其中 n 是字符串的长度。同时,由于只用了常数个额外变量,空间复杂度为 O(字符集大小)。
具体代码展示
- package org.zyf.javabasic.letcode.hash;
-
- import java.util.HashMap;
- import java.util.Map;
-
- /**
- * @author yanfengzhang
- * @description 给定两个字符串 s 和 t,判断它们是否是同构字符串。
- * 如果 s 中的字符可以被替换得到 t ,那么这两个字符串是同构的。
- * 所有出现的字符都必须用另一个字符替换,同时保留字符的顺序。两个字符不能映射到同一个字符上,但字符可以映射自己本身。
- * @date 2023/4/10 23:30
- */
- public class IsomorphicStrings {
-
- /**
- * 同构字符串问题可以通过哈希表和字符映射来解决。具体步骤如下:
- *
- * 创建两个哈希表,分别用于记录 s 到 t 的字符映射和 t 到 s 的字符映射。
- * 遍历字符串 s 和 t,对于每个字符,分别在两个哈希表中查找其对应的字符映射。
- * 如果两个哈希表中都能找到对应的字符映射,但不相同,则说明 s 和 t 不是同构字符串,直接返回 false。
- * 如果两个哈希表中只有其中一个哈希表中能找到对应的字符映射,则说明 s 和 t 不是同构字符串,直接返回 false。
- * 如果两个哈希表中都找不到对应的字符映射,则将当前字符的映射加入两个哈希表中。
- * 遍历结束后,没有发现不同的字符映射,则说明 s 和 t 是同构字符串,返回 true。
- */
- public boolean isIsomorphic(String s, String t) {
- if (s.length() != t.length()) {
- return false;
- }
- /*s 到 t 的字符映射*/
- Map
s2t = new HashMap<>(); - /*t 到 s 的字符映射*/
- Map
t2s = new HashMap<>(); - for (int i = 0; i < s.length(); i++) {
- char x = s.charAt(i);
- char y = t.charAt(i);
- if ((s2t.containsKey(x) && s2t.get(x) != y) || (t2s.containsKey(y) && t2s.get(y) != x)) {
- /*如果两个哈希表中都能找到对应的字符映射,但不相同,则说明 s 和 t 不是同构字符串,直接返回 false。*/
- return false;
- }
- if (!s2t.containsKey(x) && !t2s.containsKey(y)) {
- /*如果两个哈希表中都找不到对应的字符映射,则将当前字符的映射加入两个哈希表中。*/
- s2t.put(x, y);
- t2s.put(y, x);
- }
- }
- return true;
- }
-
- public static void main(String[] args) {
- String s1 = "egg";
- String t1 = "add";
- /*true*/
- System.out.println(new IsomorphicStrings().isIsomorphic(s1, t1));
-
- String s2 = "foo";
- String t2 = "bar";
- /*false*/
- System.out.println(new IsomorphicStrings().isIsomorphic(s2, t2));
-
- String s3 = "paper";
- String t3 = "title";
- /*true*/
- System.out.println(new IsomorphicStrings().isIsomorphic(s3, t3));
- }
- }
(二十)两个数组的交集(Intersection of Two Arrays)
题目描述:给定两个数组,编写一个函数来计算它们的交集。
示例 1:输入:nums1 = [1,2,2,1], nums2 = [2,2]. 输出:[2]
示例 2:输入:nums1 = [4,9,5], nums2 = [9,4,9,8,4]. 输出:[9,4]
说明:
- 输出结果中的每个元素一定是唯一的。
- 我们可以不考虑输出结果的顺序。
解题思路
该问题可以通过哈希表来解决。具体步骤如下:
- 首先创建了一个 set,用于存储 nums1 中的元素。
- 然后,遍历 nums2 中的元素,如果其在 set 中存在,则将其添加到另一个 set 中。
- 最后,将新 set 转换为数组并返回。
时间复杂度分析:由于需要遍历 nums1 和 nums2,因此时间复杂度为 O(m+n),其中 m 和 n 分别为 nums1 和 nums2 的长度。同时,由于使用了两个 set,空间复杂度为 O(m+n)。
具体代码展示
- package org.zyf.javabasic.letcode.hash;
-
- import java.util.Arrays;
- import java.util.HashSet;
- import java.util.Set;
-
- /**
- * @author yanfengzhang
- * @description 给定两个数组,编写一个函数来计算它们的交集。
- * @date 2023/4/10 23:45
- */
- public class IntersectionTwoArrays {
-
- /**
- * 该问题可以通过哈希表来解决。具体步骤如下:
- *
- * 首先创建了一个 set,用于存储 nums1 中的元素。
- * 然后,遍历 nums2 中的元素,如果其在 set 中存在,则将其添加到另一个 set 中。
- * 最后,将新 set 转换为数组并返回。
- */
- public int[] intersection(int[] nums1, int[] nums2) {
- /*创建一个 set,用于存储 nums1 中的元素*/
- Set
set = new HashSet<>(); - for (int num : nums1) {
- set.add(num);
- }
-
- /*创建一个 set,用于存储 nums2 和 nums1 中的交集*/
- Set
intersect = new HashSet<>(); - for (int num : nums2) {
- /*如果 num 存在于 set 中,则将其添加到 intersect 中*/
- if (set.contains(num)) {
- intersect.add(num);
- }
- }
-
- /*将 intersect 转换为数组*/
- int[] res = new int[intersect.size()];
- int i = 0;
- for (int num : intersect) {
- res[i++] = num;
- }
-
- return res;
- }
-
- public static void main(String[] args) {
- int[] nums1 = {1, 2, 2, 1};
- int[] nums2 = {2, 2};
- int[] result = new IntersectionTwoArrays().intersection(nums1, nums2);
- System.out.println("Intersection of nums1 and nums2: " + Arrays.toString(result));
- }
- }
(二一)两个数组的交集 II(Intersection of Two Arrays II)
题目描述:给定两个数组,编写一个函数来计算它们的交集。
示例 1:输入:nums1 = [1,2,2,1], nums2 = [2,2] 输出:[2,2]
示例 2:输入:nums1 = [4,9,5], nums2 = [9,4,9,8,4] 输出:[4,9]
说明:
- 输出结果中每个元素出现的次数,应与元素在两个数组中出现的次数一致。
- 我们可以不考虑输出结果的顺序。
进阶:
- 如果给定的数组已经排好序呢?你将如何优化你的算法?
- 如果 nums1 的大小比 nums2 小很多,哪种方法更优?
- 如果 nums2 的元素存储在磁盘上,内存是有限的,并且你不能一次加载所有的元素到内存中,你该怎么办?
解题思路
思路如下:
- 创建一个哈希表,用于存储 nums1 中的所有数及其出现次数。
- 遍历 nums2,对于每个数,判断其是否在哈希表中出现过。
- 如果当前数在哈希表中出现过,则将其添加到列表中,并将哈希表中该数的出现次数减一。
- 将列表转换成数组,并返回。
时间复杂度分析:由于需要遍历 nums1 和 nums2,因此时间复杂度为 O(n+m),其中 n 和 m 分别是 nums1 和 nums2 的长度。同时,由于需要使用哈希表存储 nums1 中的数及其出现次数,空间复杂度为 O(n)。
具体代码展示
- package org.zyf.javabasic.letcode.hash;
-
- import java.util.ArrayList;
- import java.util.Arrays;
- import java.util.HashMap;
- import java.util.List;
- import java.util.Map;
-
- /**
- * @author yanfengzhang
- * @description 给定两个数组,编写一个函数来计算它们的交集。
- * @date 2023/4/10 23:32
- */
- public class IntersectionTwoArrays {
-
- /**
- * 该问题可以通过哈希表来解决。具体步骤如下:
- *
- * 遍历 nums1 数组,将其中的每个元素加入哈希表中,并记录其出现次数。
- * 遍历 nums2 数组,对于其中的每个元素,如果在哈希表中出现过,则将该元素加入答案数组,并在哈希表中将其出现次数减 1。
- * 遍历结束后,返回答案数组。
- */
- public int[] intersect(int[] nums1, int[] nums2) {
- /*创建一个哈希表,用于存储 nums1 中的所有数及其出现次数*/
- Map
map = new HashMap<>(); - for (int num : nums1) {
- map.put(num, map.getOrDefault(num, 0) + 1);
- }
-
- /*创建一个列表,用于存储 nums1 和 nums2 的交集*/
- List
list = new ArrayList<>(); - for (int num : nums2) {
- if (map.containsKey(num) && map.get(num) > 0) {
- /*如果当前数在哈希表中出现过,则将其添加到列表中,并将哈希表中该数的出现次数减一*/
- list.add(num);
- map.put(num, map.get(num) - 1);
- }
- }
-
- /*将列表转换成数组,并返回*/
- int[] result = new int[list.size()];
- for (int i = 0; i < list.size(); i++) {
- result[i] = list.get(i);
- }
- return result;
- }
-
-
- public static void main(String[] args) {
- int[] nums1 = {1, 2, 2, 1};
- int[] nums2 = {2, 2};
- int[] intersection = new IntersectionTwoArrays().intersect(nums1, nums2);
- /*[2, 2]*/
- System.out.println(Arrays.toString(intersection));
-
- int[] nums3 = {4, 9, 5};
- int[] nums4 = {9, 4, 9, 8, 4};
- intersection = new IntersectionTwoArrays().intersect(nums3, nums4);
- /*[4, 9]*/
- System.out.println(Arrays.toString(intersection));
-
- }
-
- }
(二二)分糖果(Distribute Candies)
题目描述:给定一个偶数长度的数组,其中不同的数字代表着不同种类的糖果,每个数字代表一个糖果。你需要把这些糖果平均分给一个弟弟和一个妹妹。返回妹妹可以获得的最大糖果的种类数。
示例 1:输入: candies = [1,1,2,2,3,3]. 输出: 3
解析: 一共有三种种类的糖果,每一种都有两个。
只能将其中一种分给妹妹,所以最大种类数为 3。
示例 2:输入: candies = [1,1,2,3]. 输出: 2
解析: 只有两种不同种类的糖果,每一种都有两个。
妹妹分别分到了一种和二种的糖果,所以最大种类数为 2。
提示:
- 2 <= candies.length <= 10^4
- candies.length 是偶数
- -10^5 <= candies[i] <= 10^5
解题思路
分糖果问题可以使用哈希表来解决。具体步骤如下:
- 遍历糖果数组 candies,使用哈希表统计糖果的种类数。
- 如果糖果的种类数大于糖果数组长度的一半,则最多只能拥有糖果数组长度的一半种糖果。否则,能够拥有所有的糖果种类。
- 返回最终结果。
时间复杂度分析:遍历一遍糖果数组需要 O(n) 的时间,其中 n 是糖果数组的长度。同时,由于只用了一个哈希表,空间复杂度为 O(n)。
具体代码展示
- package org.zyf.javabasic.letcode.hash;
-
- import java.util.HashSet;
- import java.util.Set;
-
- /**
- * @author yanfengzhang
- * @description 给定一个偶数长度的数组,其中不同的数字代表着不同种类的糖果,每个数字代表一个糖果。
- * 你需要把这些糖果平均分给一个弟弟和一个妹妹。返回妹妹可以获得的最大糖果的种类数。
- * @date 2023/4/10 23:50
- */
- public class DistributeCandies {
-
- /**
- * 分糖果问题可以使用哈希表来解决。具体步骤如下:
- *
- * 遍历糖果数组 candies,使用哈希表统计糖果的种类数。
- * 如果糖果的种类数大于糖果数组长度的一半,则最多只能拥有糖果数组长度的一半种糖果。否则,能够拥有所有的糖果种类。
- * 返回最终结果。
- */
- public int distributeCandies(int[] candies) {
- /*统计糖果的种类数*/
- Set
set = new HashSet<>(); - for (int candy : candies) {
- set.add(candy);
- }
- /*如果糖果的种类数大于糖果数组长度的一半,最多只能拥有糖果数组长度的一半种糖果*/
- int n = candies.length;
- int maxNum = n / 2;
- int candyType = set.size();
- return candyType >= maxNum ? maxNum : candyType;
- }
-
- public static void main(String[] args) {
- int[] candies1 = {1, 1, 2, 2, 3, 3};
- int[] candies2 = {1, 1, 2, 3};
- int[] candies3 = {6, 6, 6, 6};
- int[] candies4 = {1, 1, 1, 1, 2, 2, 2, 3, 3, 3};
-
- /*Output: 3*/
- System.out.println(new DistributeCandies().distributeCandies(candies1));
- /*Output: 2*/
- System.out.println(new DistributeCandies().distributeCandies(candies2));
- /*Output: 1*/
- System.out.println(new DistributeCandies().distributeCandies(candies3));
- /*Output: 3*/
- System.out.println(new DistributeCandies().distributeCandies(candies4));
- }
-
- }
(二三)宝石与石头(Jewels and Stones)
题目描述:给定字符串 J 代表石头中宝石的类型,和字符串 S 代表你拥有的石头。 S 中每个字符代表了一种你拥有的石头的类型,你想知道你拥有的石头中有多少是宝石。
J 中的字母不重复,J 和 S 中的所有字符都是字母。字母区分大小写,因此"a"和"A"是不同类型的石头。
示例 1:输入: J = "aA", S = "aAAbbbb". 输出: 3
示例 2:输入: J = "z", S = "ZZ" 输出: 0
注意:
- S 和 J 最多含有50个字母。
- J 中的字符不重复。
解题思路
宝石与石头问题可以使用哈希表来解决。具体步骤如下:
- 遍历字符串 J 中的每个字符,使用哈希表记录宝石的种类和数量。
- 遍历字符串 S 中的每个字符,如果该字符是宝石,则更新计数器。
- 返回计数器的值即为宝石的数量。
时间复杂度分析:遍历一遍字符串 J 和 S 需要 O(n) 的时间,其中 n 是字符串的长度。同时,由于只用了一个哈希表,空间复杂度为 O(n)。
具体代码展示
- package org.zyf.javabasic.letcode.hash;
-
- import java.util.HashMap;
- import java.util.Map;
-
- /**
- * @author yanfengzhang
- * @description 给定字符串 J 代表石头中宝石的类型,和字符串 S 代表你拥有的石头。
- * S 中每个字符代表了一种你拥有的石头的类型,你想知道你拥有的石头中有多少是宝石。
- *
- * J中的字母不重复,J和S 中的所有字符都是字母。字母区分大小写,因此"a"和"A"是不同类型的石头。
- * @date 2023/4/10 23:53
- */
- public class JewelsAndStones {
-
- /**
- * 宝石与石头问题可以使用哈希表来解决。具体步骤如下:
- *
- * 遍历字符串 J 中的每个字符,使用哈希表记录宝石的种类和数量。
- * 遍历字符串 S 中的每个字符,如果该字符是宝石,则更新计数器。
- * 返回计数器的值即为宝石的数量。
- */
- public int numJewelsInStones(String J, String S) {
- /*创建哈希表用于记录宝石的种类和数量*/
- Map
map = new HashMap<>(); -
- /*遍历字符串 J 中的每个字符,记录宝石的种类和数量*/
- for (char c : J.toCharArray()) {
- map.put(c, map.getOrDefault(c, 0) + 1);
- }
- /*计数器,用于记录宝石的数量*/
- int count = 0;
-
- /*遍历字符串 S 中的每个字符,如果该字符是宝石,则更新计数器*/
- for (char c : S.toCharArray()) {
- if (map.containsKey(c)) {
- count++;
- }
- }
- /*返回计数器的值即为宝石的数量*/
- return count;
- }
-
- public static void main(String[] args) {
- String J = "aA";
- String S = "aAAbbbb";
- int result = new JewelsAndStones().numJewelsInStones(J, S);
- /*Output: 3*/
- System.out.println(result);
- }
- }
评论记录:
回复评论: