
前言
我司审稿项目组一直在迭代论文审稿GPT(截止到24年3月底,审稿项目组成员除我之外,包括:阿荀、阿李、三太子、鸿飞、文弱等12人),比如
- 七月论文审稿GPT第1版:通过3万多篇paper和10多万的review数据微调RWKV
- 七月论文审稿GPT第2版:用一万多条paper-review数据集微调LLaMA2 7B最终反超GPT4
- 七月论文审稿GPT第2.5和第3版:分别微调GPT3.5、Llama2 13B以扩大对GPT4的优势
所以每个星期都在关注各大公司和科研机构推出的最新技术、最新模型
而Google作为曾经的AI老大,我司自然紧密关注,所以当Google总算开源了一个gemma 7b,作为有技术追求、技术信仰的我司,那必须得支持一下,比如用我司的paper-review数据集微调试下,彰显一下gemma的价值与威力
此外,去年Mistral instruct 0.1因为各种原因导致没跑成功时(详见此文的4.2.2节直接通过llama factory微调Mistral-instruct),我总感觉Mistral应该没那么拉胯,总感觉得多实验几次,所以打算再次尝试下Mistral instruct 0.2「当然,本文只展示部分细节,更多细节则见七月的《大模型商用项目审稿GPT微调实战》」
最后值得一提的是,我司审稿项目组还在通过80G的A100微调mixtral 8×7b中了,历经9个月,连续迭代7个版本,只为把审稿效果不断做到极致(超越GPT4在第2个版本就做到了),最终以「无限接近人工reviewer的效果」辅助审稿者审稿、辅助作者修订论文,但如下图所示,过程中也走了不少弯路

第一部分 论文审稿GPT第3.2版:微调Mistral 7B instruct 0.2
1.1 23年12月版的Mistral-7b-Instruct-v0.2:上下文长度8K
关于Mistral 7B的介绍,请看此文《从Mistral 7B到MoE模型Mixtral 8x7B的全面解析:从原理分析到代码解读》的1.1节Mistral 7B:通过分组查询注意力 + 滑动窗口注意力超越13B模型
1.1.1 Mistral 7B-Instruct:微调时其长度扩展的能力从何而来
由于Mistral 7B-Instruct(特指在24年3.24之前的版本)和Mistral 7B一样,其长下文长度都只有8192

而论文审稿GPT这个项目对模型上下文的长度要求12K以上,故需要扩展Mistral 7B-Instruct的上下文长度,如何扩展呢
考虑到如此文《七月论文审稿GPT第2版:用一万多条paper-review数据集微调LLaMA2 7B最终反超GPT4》4.1节所介绍的
- Yarn-Mistral-7b-64k自己实现了modeling,即把mistral的sliding windows attention改了,相当于把sliding windows的范围从滑窗大小直接调到了65536即64K(即直接滑65536那么个范围的滑窗,其实就是全局)
那类似的,给Mistral 7B–Instruct加YaRN行不行?
然问题是不好实现:YaRN-Mistral 7B – Instruct,因为Yarn是全量训的方案,而大滑窗范围+全量很吃资源- 受LongLora LLaMA的启发,既然没法给Mistral 7B–Instruct加YaRN,那可以给其加longlora么?
然问题是mistral又没法享有longlora,因为mistral的sliding windows attention和longlora的shift short attention无法同时兼容,但要对原chat模型的上下文长度进行有效扩展又会需要shift short attention
不得已,故再考察下它所用的RoPE(相关代码见:transformers/src/transformers/models/mistral/modeling_mistral.py),毕竟RoPE可以使得模型的上下文长度直接外推10-20%
然,在我们后续实际微调23年12月份版本的Mistral 7B-Instruct 0.2时(其上下文长度还只有8K),实际支持其获得更长上下文能力的还是归结于其滑动窗口注意力(sliding window attention,简称SWA),毕竟SWA可以有效处理任意长度的序列
- 怎么发现的呢?如下图所示的“大海捞针”实验,纵轴是对应语句放在文章中的位置(从头到尾),如果是外推的话 不会有图中那个斜杠(因为外推的话无论输入多长的序列,它的ppl都是稳定的,即右上角应该是绿色才对),故从图中可以很明显的看出来Mistral的window size就是4k(每次只计算4k范围内的注意力)
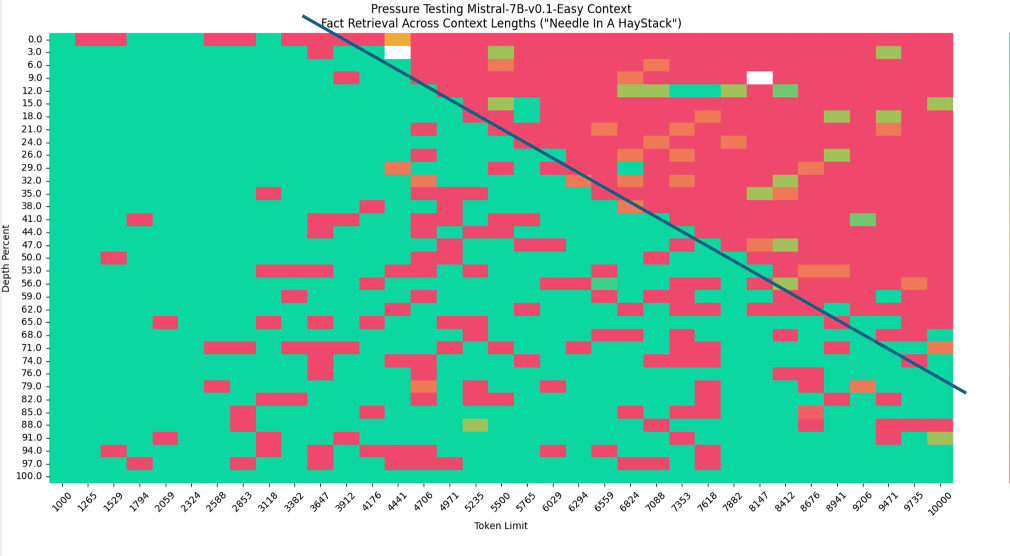
- 总之,对于Mistral或gemma如果通过rope去外推,算是没有办法的办法,但Mistral有滑动窗口注意力的话,反正无论输入长度多长,它每一个token只计算在它之前(含它自己)的4096个token的注意力,相当灵活,故自然也就轮不到用rope去外推了
1.1.2 7b-Instruct-v0.2基于「新上线的Mistral-7B-v0.2」把上下文长度升级到32K
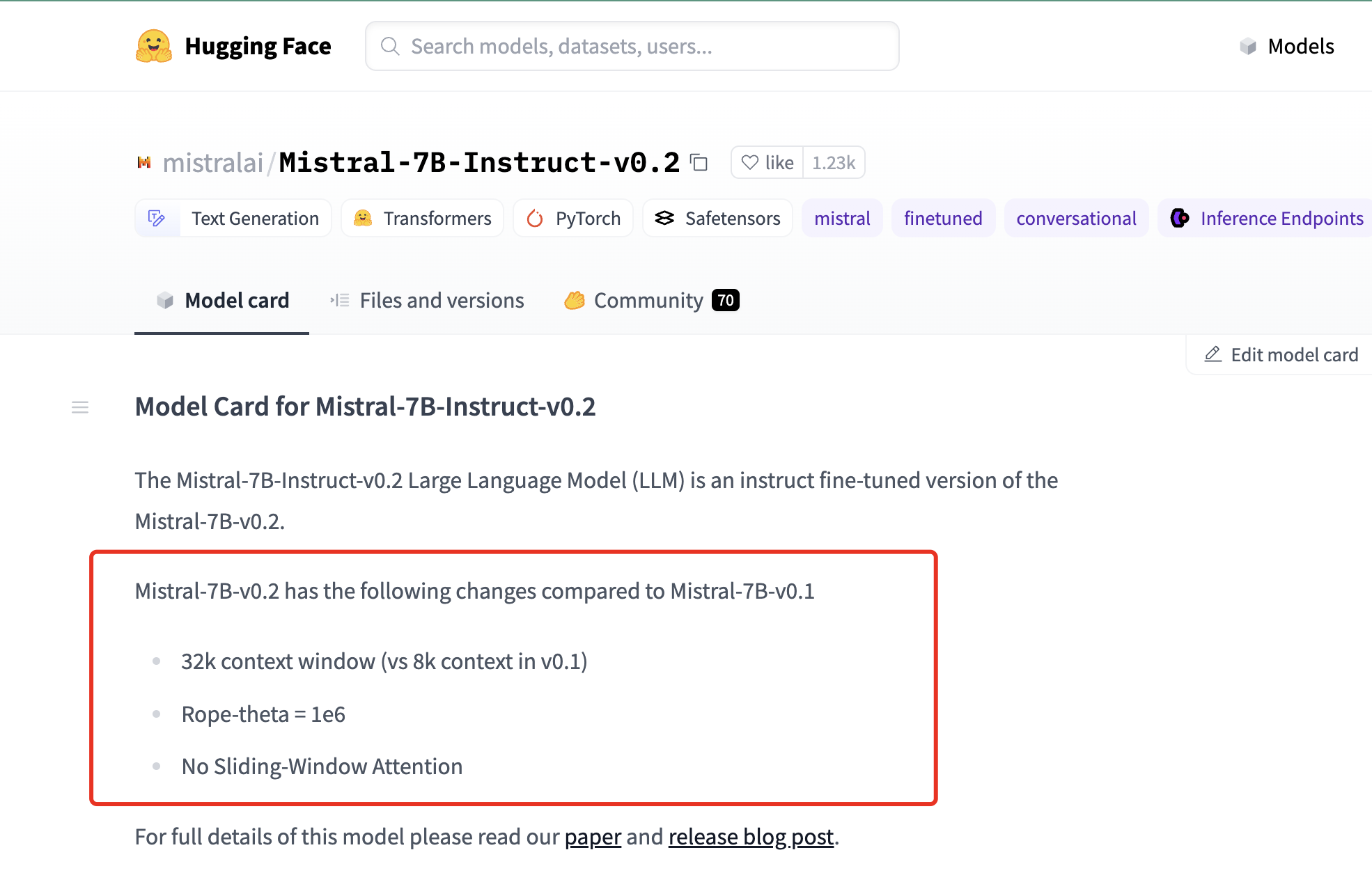
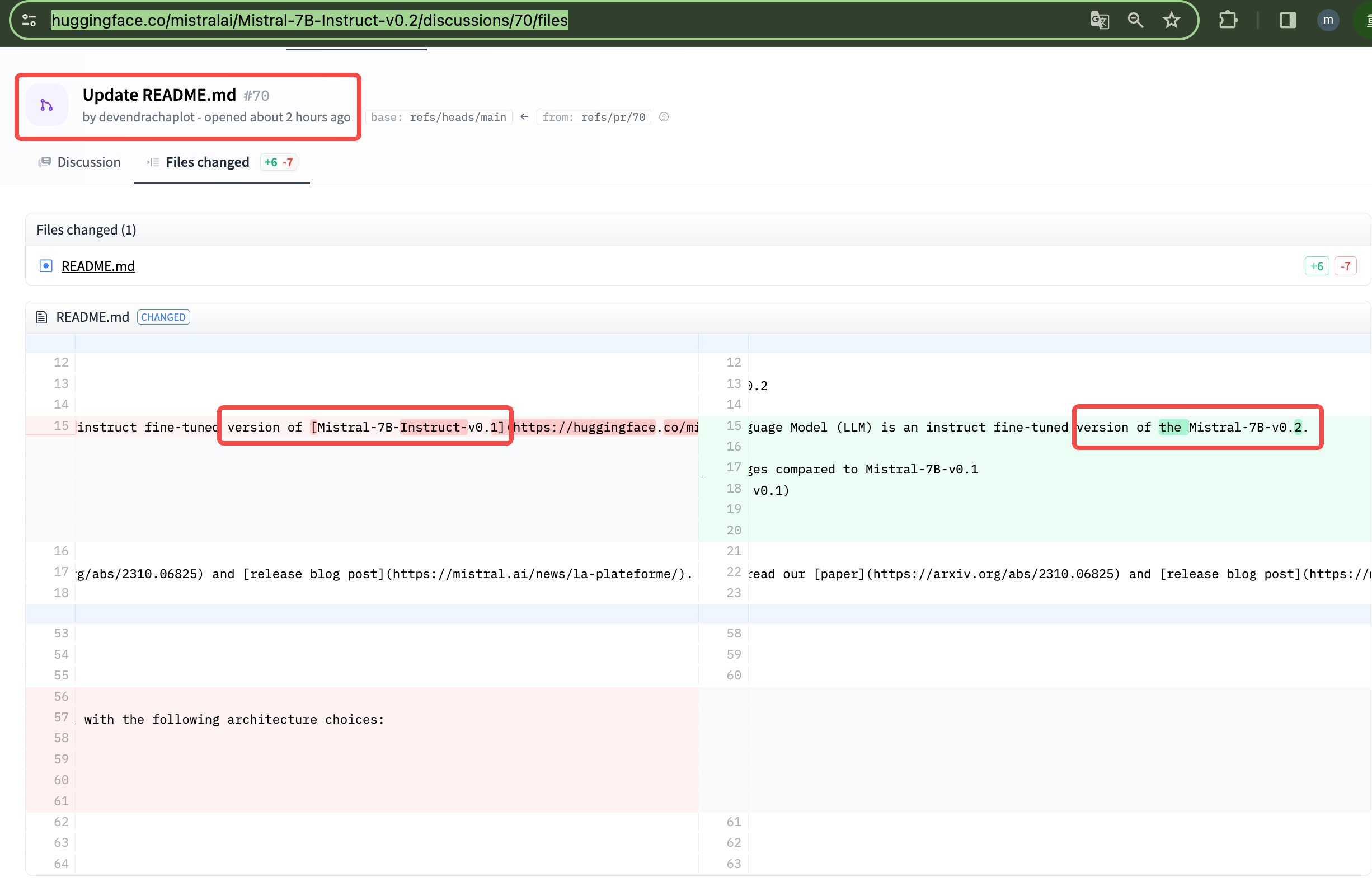
24年3.24日,我司审稿项目组的文弱发现,Mistral AI悄悄发布了Mistral-7B-v0.2(我们最早是在mistralai/Mistral-7B-Instruct-v0.2在hg上的页面上确认到的,其次是redit上有用户说Mistral-7B-v0.2已上传至HF )
Mistral-7B-v0.2 has the following changes compared to Mistral-7B-v0.1
然后他们又把三个月之前发布的Mistral-7b-instruct-0.2基于最新的Mistral-7b-v0.2升级了下(但他们当天只是更新一下readme,32K的instruct-0.2在当天还没有正式放出来啊 )
相当于
- Mistral于23年9月 就发了7b第一个版本,和Mistral-7b-instruct-0.1(当时,他们用滑动窗口注意力 把7b-0.1扩展到的8K上下文)
- 再后来(即大概23年12月),他们推出了Mistral-7b-instruct-0.2
- 然后现在(大约24年3.24日早上8点),推出了Mistral-7b-0.2版本(7b-0.2版本 没用滑动窗口注意力了,毕竟现在上下文扩展 没半年前那么困难了,所以不需要再依赖滑窗 便可让7b-0.2直接干到32K,当然 还没看到怎么直接干到32K的 )
同时把之前的Mistral-7b-instruct-0.2 基于Mistral-7b-0.2 升级了下,升级之后还是叫Mistral-7b-instruct-0.2,但上下文窗口从升级之前的8K到了现在的32K了
但遗憾的是,截止到3.25,Mistral AI还未对外上传32K的instruct-0.2
1.2 基于llama factory + 5K/15K数据微调Mistral-7b-Instruct-v0.2(23年12月份的版本) by鸿飞
把训练数据,格式是:{"input":"论文内容", "output": "review data"}}的数据,按照LLama-Factory目录下面的dataset_info_zh.md中的步骤,把数据整理成为羊驼alpaca的格式
- 一开始--per_device_train_batch_size 1设置为1,启动程序,还会发生内存不足的问题
经过检查以后,发现是论文长度比较长,又把论文和review数据截断为12288的数据长度,再放到data目录下面,per_device_train_batch_size设置为3,正常运行,但是内存已经到了47G了,但是早上发现在运行到了晚上4点,程序因为内存不足而退出了 - 断点续跑:
重新启动程序,设置--resume_from_checkpoint checkpoint-660,修改运行的batch_size为2,重新把程序从上次退出的地方跑起来。发现内存占用为33G/48G。剩余时间大约12个小时跑完
以下是训练过程中的其他细节
- 模型超时解决:--ddp_timeout 180000000
- 长度外推方式
目前只支持Linear和dynamic NTK
为了加快训练速度,使用deepspeed s2 + 4bit+NF 量化 - 使用了flash-attn:不过训练速度没有明显地提升
- 租的机器的cuda版本是11.8,安装了最新的torch,发现和cuda不匹配,更新cuda的话太麻烦,所以按照llama factory开发者的建议:
pip uninstall torch torchvision torchaudio
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 - LLamaFactory推荐deepspeed==0.13.5
但运行以后,json.dumps表示不能保存这种数据,怎么办?- {
- 'loss': 1.9611,
- 'grad_norm': tensor(4.6666),
- 'learning_rate': 2.5e-05,
- 'epoch': 0.0
- },
如鸿飞如说
- 运行程序的时候,尽量留够一定的内存空间,否则会出现中途退出的问题
- 对于一些特定的错误,不会解决的时候,最好找LLama-Factory的开发者去解决,否则自己很难定位出错误的位置。trick: LLama-Factory上面的多加几个群,这样子可以多学习官方人员的解决思路
- 机器cuda与python的版本号最好是一致的。
- 量化后的模型与主模型不能合并。量化模型不能合并
最后推理时,务必注意把推理时的数据组织格式 改成「Mistral推理时所要求的格式」
- 即用Mistral提供的API,进行组织数据格式
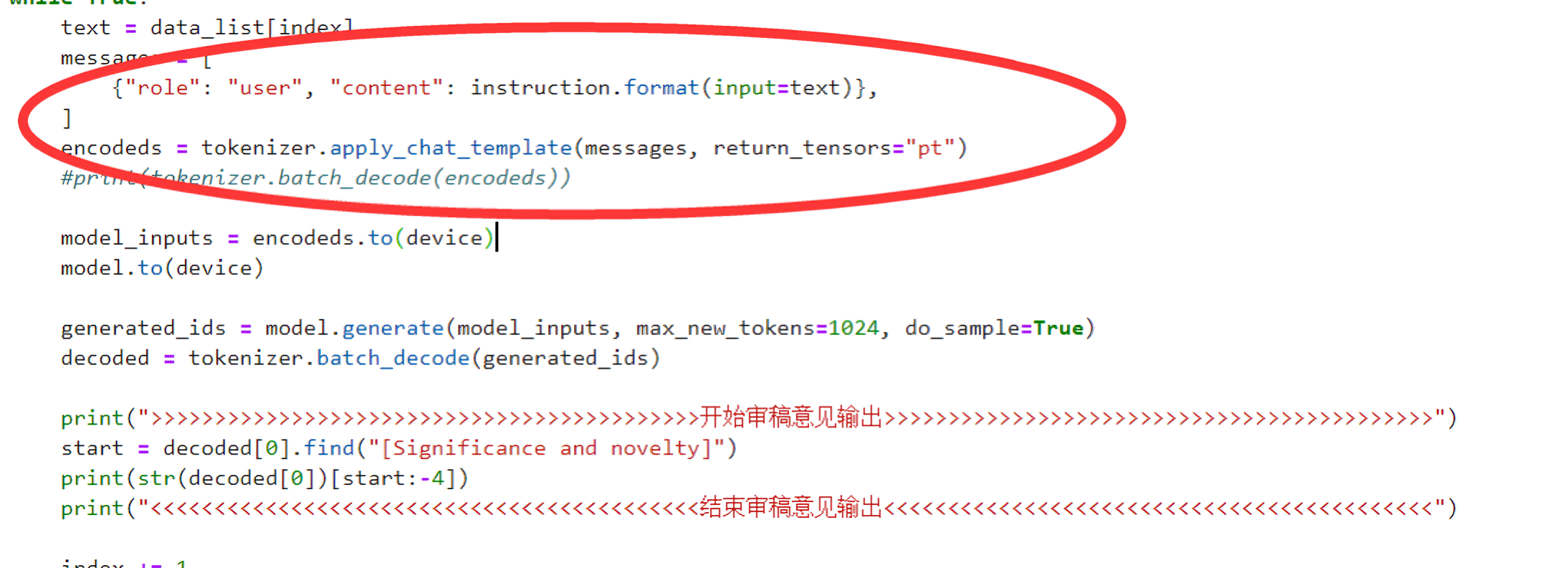
- 总之,如鸿飞所说,在预测的时候,我自己不瞎组织测试数据。严格按照mistral要求的数据格式进行输入,然后输出就没有问题了
更多见七月的《大模型商用项目审稿GPT微调实战》
1.3 对「Mistral-7b-Instruct-v0.2(23年12月版)之paper-review微调版」的评估
下图是通过5K数据微调Mistral 7B instruct的评估结果

更多见七月的《大模型商用项目之审稿GPT微调实战》
第二部分 论文审稿GPT第3.5版:微调Google gemma
提前说下,Google gemma的介绍,请见此文《一文速览Google的Gemma:从gemma1到gemma2(2代27B的能力接近llama3 70B)》的第一部分
2.1 基于TRL通过15K数据对gemma-7b-it进行微调与模型评估 by阿李
2.1.1 通过A40微调时设置为模型的默认长度8K
由于gemma所用的rope可以从8096外推到增长10-20%,即吃我们12K以上长度的paper-review数据条,不是啥问题
不过,我们在训练时用的48G的A40,如果把模型长度设置为12K 则会爆显存(9 10 11 12中,9k能跑,其他都显存爆掉),最终不得已,还是把模型的长度设置为默认长度8K,最终基于1台A40耗费了差不多1周的时间
2.1.2 通过TRL包对gemma-7b-it进行微调的关键结论/细节与环境配置
以下是一些关键结论
- 使用TRL的SFT Trainer对gemma-7b-it进行微调(关于TRL包的介绍请看此文的第一部分)
- 其中模型的max_seq_length设置为1024*8,也就是没有外推,直接使用默认8K。
- 在train阶段没有对paper+review的组合进行截断,在inference则对paper做截断(即只保留paper的前1024*7长度)
以下是一些关键的微调细节
- 微调参考gemma官方在huggingface公布的微调样例代码:https://huggingface.co/google/gemma-7b/blob/main/examples/example_sft_qlora.py
本质是用trl的SFT Trainer和transformers的模型加载,写一个微调脚本 - 主要修改点是dataset的适配以及超参数
- 主要难点是解决python包的冲突(官网案例只有代码没有环境),以及预测时候的维度不一致的问题解决
- 另外网上还有一种方案:clone trl的github的框架代码,然后在这个项目框架里面写微调样例,这个方案在环境配置的时候总有包版本冲突,故该方案暂时搁置
以下是本次微调所涉及到的环境配置
- conda create -n gemma python=3.9 pip
- source activate
- conda activate gemma
- pip install torch==1.13.0+cu117 torchvision==0.14.0+cu117 torchaudio==0.13.0 --extra-index-url https://download.pytorch.org/whl/cu117
- pip install accelerate==0.27.2 trl==0.7.11 transformers==4.38.2 datasets==2.16.0 peft==0.9.0
2.1.3 微调代码修改
- 超参数
- per_device_train_batch_size=1
- per_device_eval_batch_size=1
- gradient_accumulation_steps=16
- learning_rate=2e-4
- max_grad_norm=0.3
- weight_decay=0.001
- lora_alpha=16
- lora_dropout=0.1
- lora_r=64
- max_seq_length=1024*8
- dataset_name="./data/paper_review/paper_review_data_longqlora_15565.jsonl"
- fp16=False
- bf16=True
- packing=False
- gradient_checkpointing=True
- use_flash_attention_2=True
- optim="paged_adamw_32bit"
- lr_scheduler_type="constant"
- warmup_ratio=0.03
- save_steps=10
- save_total_limit=3
- logging_steps=10
- num_train_epochs=2
- 模型加载和量化以及lora配置,代码见七月的《大模型商用项目审稿GPT微调实战》
- 数据集加载格式定义以及prompt设置
- def formatting_func(example):
- # text = f"### USER: {example['data'][0]}\n### ASSISTANT: {example['data'][1]}"
- text = """
- Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
- ### Instruction:
- You are a professional machine learning conference reviewer who reviews a given paper and considers 4 criteria: ** importance and novelty **, ** potential reasons for acceptance **, ** potential reasons for rejection **, and ** suggestions for improvement **. The given paper is as follows.
- ### Input:
- {paper}
- ### Response:
- {review}
- """.format(example[0],example[1])
- return text
- 微调和保存,代码见七月的《大模型商用项目之审稿GPT微调实战》

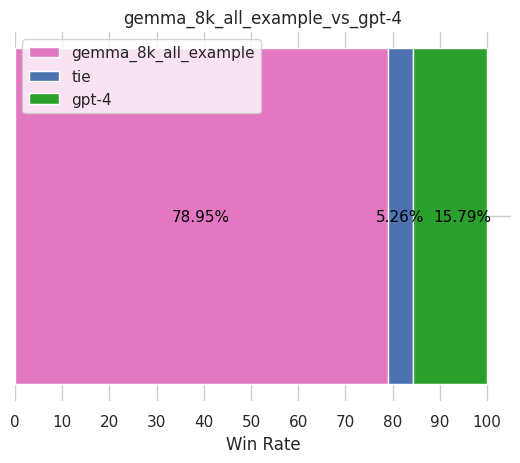
2.1.4 gemma评估结果:审稿效果超越GPT4不少,是目前sota
预测时,如果遇到同一个文章的多次结果都预测一样,则记得:do_sample=True
- 最终的评估结果告诉我们,大家不要小看Google的gemma,在同样的论文审稿场景下、同样的数据集下,微调后在目前的几个模型中取得了目前最好的效果(当然,24年4月初先后被mixtral 8x7b超过了)
- 比如略微超过之前微调llama2的结果(在GPT4-1106做裁判的情况下,之前微调过后的llama2 7B对GPT4-1106的胜率仅为63.16%,微调过后的llama2 13B对GPT4-1106胜率仅为75.44%)
所以,当微调后审稿效果超过GPT4-1106(裁判也使用的gpt-4-1106-preview),则很自然了
2.2 基于llama factory通过5K/15K数据微调gemma-7b-it by文弱
2.2.1 微调gemma-7b-it的详细过程
- 下载模型
需要先在hugging face 页面生成access token:
然后先在服务器上下载lfs- # 安装git-lfs
- curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash
- sudo apt-get install git-lfs
- # 激活git-lfs
- git lfs install
source /etc/network_turbogit lfs clone https://huggingface.co/google/gemma-7b-it - 下载llama-factory的repo:
git clone https://github.com/hiyouga/LLaMA-Factory.git - 配置环境:
conda create -n llama_factory python=3.10- conda activate llama_factory
- cd LLaMA-Factory
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
然后需要这种方式安装bitsandbytes:pip install bitsandbytes==0.41.3 --default-timeout=100
将requirements.txt中的包修改为适配本机cuda版本以及llama-factory推荐版本:- transformers==4.38.2
- datasets==2.17.1
- accelerate==0.27.2
- peft==0.9.0
- trl==0.7.11
- gradio>=3.38.0,<4.0.0
- scipy
- einops
- sentencepiece
- protobuf
- uvicorn
- pydantic
- fastapi
- sse-starlette
- matplotlib
- deepspeed==0.13.1
pip install -r requirements.txt - 修改数据集为适配llama-factory的alpaca模式:
首先把instruction存入一个json文件中(文弱这边命名为extra.json):{"instruction":"You are a professional machine learning conference reviewer who reviews a given paper and considers 4 criteria: ** importance and novelty **, ** potential reasons for acceptance **, ** potential reasons for rejection **, and ** suggestions for improvement **. The given paper is as follows.\n"}- while IFS= read -r line; do
- echo $line | jq -c --slurpfile extra extra.json '. + $extra[0]' >> addtest.jsonl
- done < paper_review_test.jsonl
- "addtest": {
- "file_name": "addtest.jsonl",
- "columns": {
- "prompt": "instruction",
- "query": "input",
- "response": "output"
- }
- }
- 微调步骤:
5.1) 先将train_web.py修改为:- from llmtuner import create_ui
- def main():
- demo = create_ui()
- demo.queue()
- demo.launch(server_name="0.0.0.0", server_port=6006,share=False, inbrowser=True)
- if __name__ == "__main__":
- main()
nohup python train_web.py > web.log 2>&1 &
5.4) 然后在webui中,选择好微调好的参数并复制预览命令,并写入脚本「详见七月的《大模型商用项目之审稿GPT微调实战》」
5.5) 运行脚本文件:nohup ./sft.sh> sft.log 2>&1 & - 合并模型权重
「详见七月的《大模型商用项目之审稿GPT微调实战》」 - 利用合并后的模型进行推理:
刚开始在webui界面生成发现老报错,最初以为是截断长度仍然过长,但是将截断长度设为100的时候仍然报错,后来用了命令行来debug,在log中发现了进行推理需要再安装几个包 首先安装好这几个包:
首先安装好这几个包: - pip install jieba
- pip install nltk
- pip install rouge_chinese
启动推理: 提取模型推理输出:
「以上没有介绍的相关细节,详见七月的《大模型商用项目之审稿GPT微调实战》」 - 可能会用到的其他工具:
- pip install jupyterlab
- apt install jq
- apt install dos2unix
2.2.2 对gemma-7b-it微调之后的效果评估
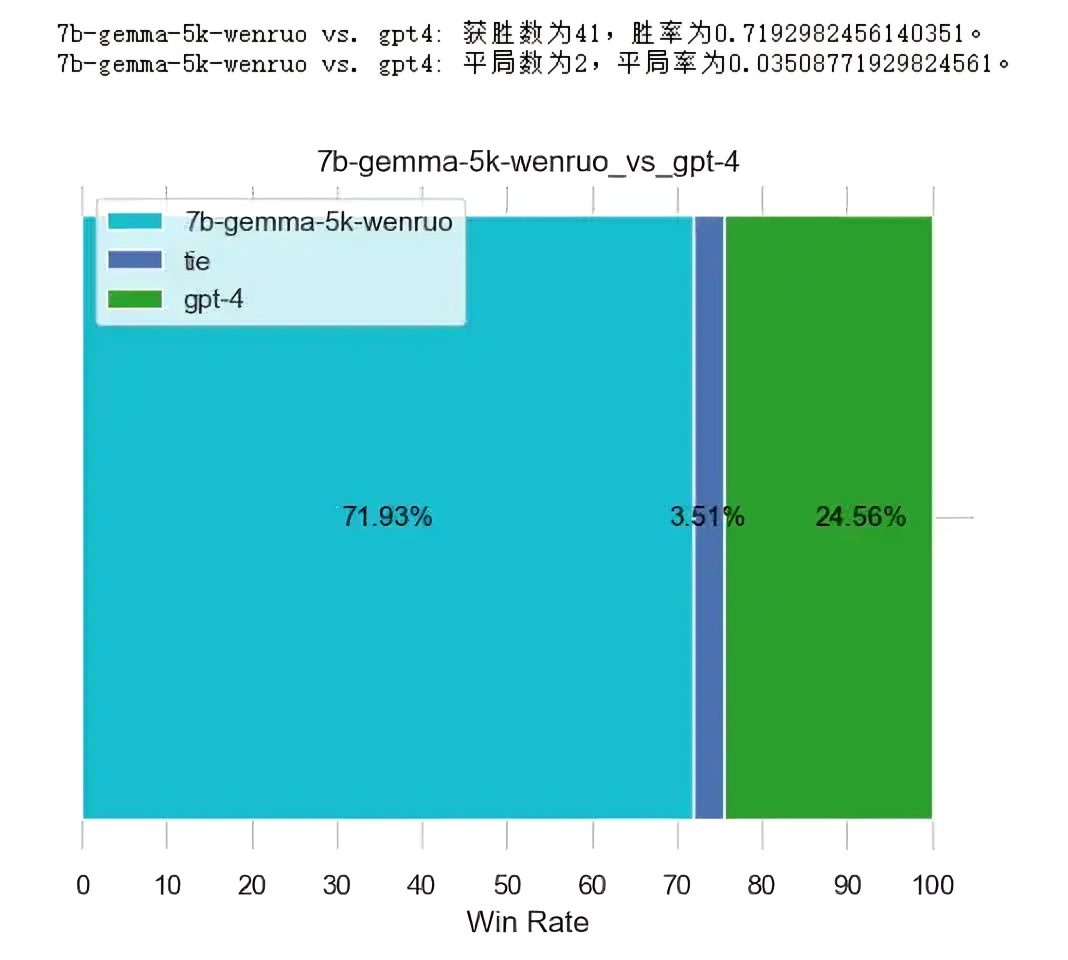
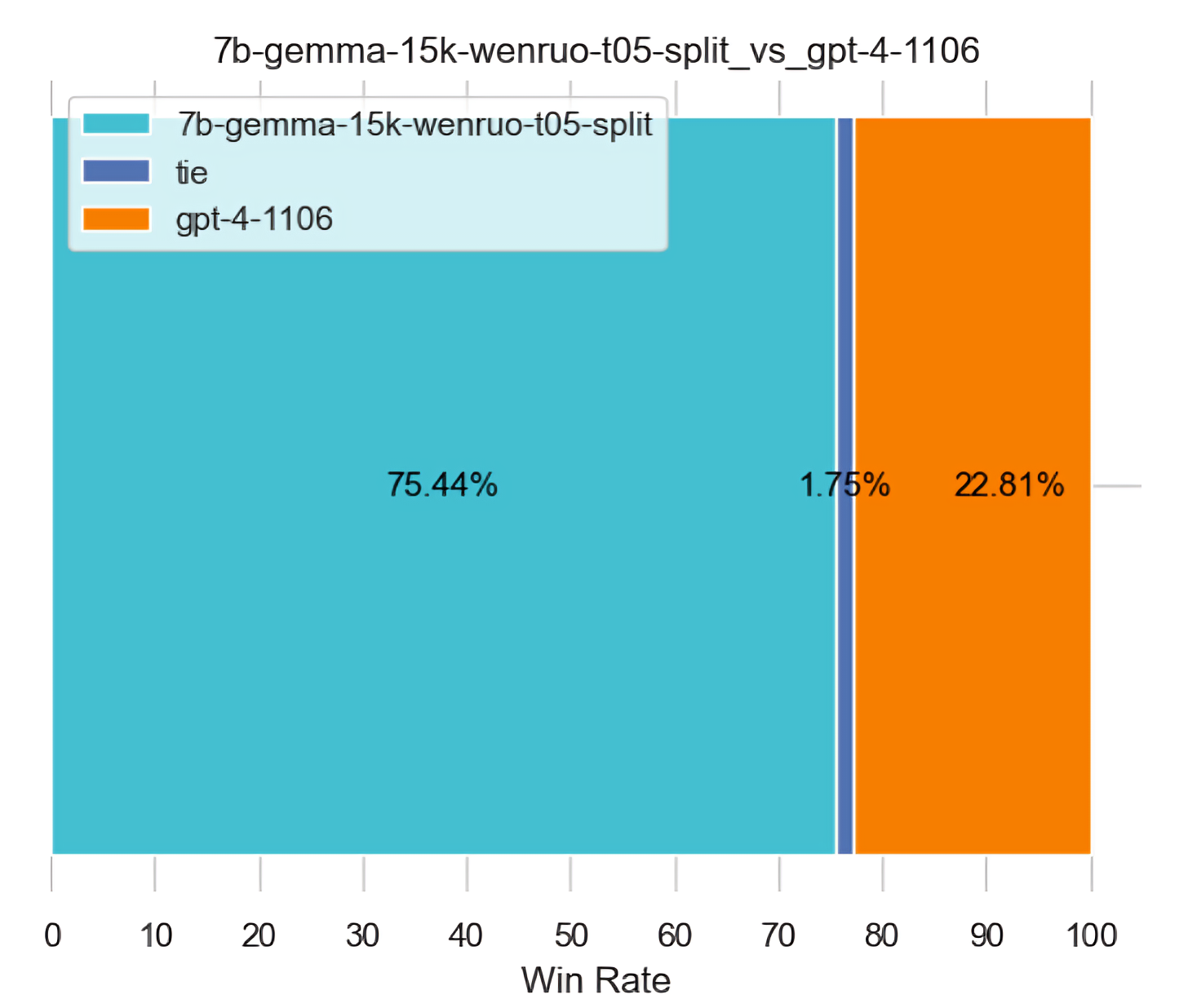
一开始文弱通过5K数据基于llama factory微调gemma-7b-it,后来又通过15K数据再微调一遍
- 一张48g的a40,至于微调时长,5k是35个小时,15k是110小时
- 都是默认温度0.35的话,5k比15k好,但是15k提高温度到0.5就好于5k了(不管5k温度是0.35还是0.5)
下图左侧的温度是0.35,下图右侧的温度是0.5
更多细节,详见七月的《大模型商用项目之审稿GPT微调实战》
评论记录:
回复评论: