
集成学习:
所谓兼听则明,偏信则暗。

集成学习本身并不是一个单纯的新算法,它的目的是通过结合多个其他的机器学习模型来完成某个一个任务以提升最终结果的准确率,即三个臭皮匠赛过诸葛亮。从该思想出发自然可以想到,如何得到多个机器学习模型?又如何整合?基于此,集成学习也就有了多种形态。如果对不同类别的机器学习模型进行整合,如用SVM和朴素贝叶斯结合等等,不过一般来说提到集成学习都是指同类的模型,如多个决策树,多个神经网络来集成。如果根据这些模型之间是否强相关又可分为Boosting系列,Bagging和随机森林(Random Forest)系列这两种。
Bagging:
又称自举汇聚法(bootstrap aggregating),专注多模型,即在训练集合里,多次随机抽取的n个样本进行训练,高度并行化, 然后用结合策略()直接投票法,结果平均法,stacking)进行结合。它对最后结果的影响是能减小方差variance,所以能抑制过拟合。
Random Forest:基本思想和Bagging一致,只是在对树做特征划分选择的时候不是每次选择最好的,而是在其中随机选择,通过这种方式可以带来更好的多样性(diversity)。它的优点在于可以处理高维度,不用做特征选择;训练完后还能知道什么特征最重要;训练快,并且容易做成并行化方法;训练中,能检测到feature间的相互影响;对于不平衡的数据,也能平衡误差;如果有特征遗失,任然可以维持准确度。只是,在某些噪音很大的问题上会过拟合,对于有不同取值的属性数据,取值划分多的属性会有很大的影响,所以这种情况下往往不可信。
- OOB问题。即袋外错误率,Bagging方法中有1/3的样本不会出现在boostrap的样本集合中,不会参与决策树的建立,那么这些数据交袋外数据,通过测试它可以代替测试集误差,已经被证明过它是无偏估计的。
Boosting:
就思想上Bagging的并行投票组合很合理也很适用,但是如果每个模型都在同一个地方摔倒了,那么整个模型相对来说还是没有提高,所以从失败中吸取教训似乎才是更加好的方法。这就是串行学习的Boosting了。
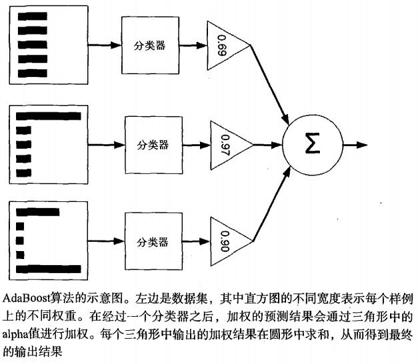
想要从失败汇总学习,就需要先专注错误样本,关键点就是权重,对于预测错误的点在下次训练时需要格外的注意。Boosting泛化错误率低,易编码,可以用于大多数分类器上,无需调参数,但对离群点敏感。从算法思想可以看出性能好的模型权重会大,对最后结果的影响就是能减少偏差Bias。
AdaBoost算法:
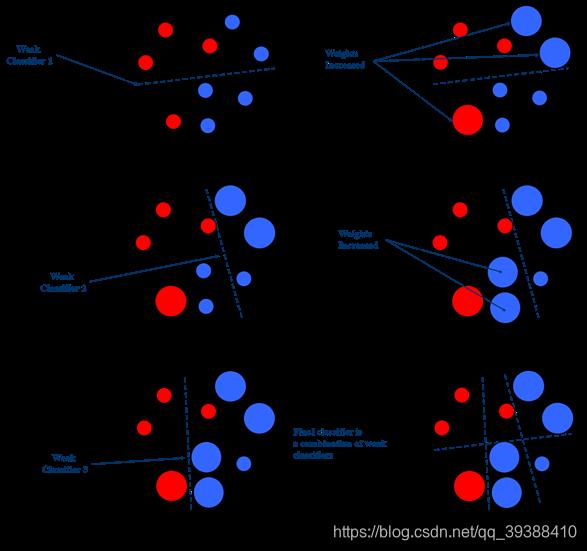
所以AdaBoost的处理是:先对所有样本初始化一个权重(一般为均匀分布),然后对这个样本进行训练,可以得到一个的误差率,根据误差率大小赋以权重,误差越大权重就越小,对误分的样本增加它的权重,使训练的下一个模型侧重于误分的样本,然后再次根据误差率更新权重,依次迭代,最后将会得到强模型,即就是多个弱模型的加权和。

AdaBoost简单来说就是每次迭代找到最佳的单个模型,计算alpha,权重向量D,更新类别估计值,如果错误率为0或者达到迭代次数,则退出程序。它相比一般的Boosting来说,就是一般的Boosting需要知道准确率下限,而它直接利用错误率更新权重克服了这一限制!如下图的三个模型,不断的在前一个模型基础上学习自己的数据子集,并且利用误差更新权重,最后结合每次分类结果。
算法实现:(Python)
def adaBoostTrainDS(dataArr,classLabels,numIt=40):
weakClassArr = []
m = shape(dataArr)[0]
D = mat(ones((m,1))/m) #初始化权重
aggClassEst = mat(zeros((m,1)))#记录每一个数据点的类别估计值
for i in range(numIt):
bestStump,error,classEst = buildStump(dataArr,classLabels,D)
alpha = float(0.5*log((1.0-error)/max(error,1e-16)))#防止分母变成0。Alpha表示的是模型的权重。错误率越低,权重越高
bestStump['alpha'] = alpha
weakClassArr.append(bestStump)
expon = multiply(-1*alpha*mat(classLabels).T,classEst) #区分正确或错误的样本
D = multiply(D,exp(expon))
D = D/D.sum()#归一化
aggClassEst += alpha*classEst#累加变成强模型
aggErrors = multiply(sign(aggClassEst) != mat(classLabels).T,ones((m,1)))#sign()通过投票预测的类别,计算正零负
errorRate = aggErrors.sum()/m
Print( "total error: ",errorRate)
if errorRate == 0.0: break
return weakClassArr,aggClassEst.T

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
其他融合技巧
- 同样参数,不同初始化方式
- 不同参数,通过cross-validation选取最好的几组
- 同样参数,迭代次数不同
- 不同的模型,进行线性融合,如RNN和传统的模型。
梯度提升树(Gradient Boosting Decison Tree, GBDT):
又称MART(Multiple Additive Regression Tree),与AdaBoost利用误差率迭代的更新权重的思想不同,GBDT是利用前向分布算法,迭代寻找更弱的模型。正如它的名字,梯度提升树,在学习前一个模型时,往往希望能够学习得更加的准确,即希望损失函数能尽快的减小,那么就学习最快的方向–梯度。
也就是说,学习之前树的残差。比如预测一个月生活费,第一棵树训练后的预测600,而实际是1000,那么残差为400,于是在学习第二棵树时将生活费更新设为400,第二棵树预测300,那么残差为100,继续更新生活费为100,然后继续迭代。在最后做预测时,只需要将每棵树(可以理解为每天的花费)的结果进行综合就好,比如在这个例子中总的生活费最后还会是 第一棵的600+第二棵的300+剩下棵的约等于100,那么最后的结果会和实际的1000很相近。
拟合残差?
实际上GBDT是拟合的是f的负梯度,在f为均方误差时,正好是残差而已。同时还可以使用其他一些的损失函数如:绝对损失,负梯度是
L
=
∣
y
−
f
(
x
)
∣
L=|y-f(x)|
L=∣y−f(x)∣,
s
i
g
n
(
y
−
f
(
x
)
)
sign(y-f(x))
sign(y−f(x))。Huber损失,是均方差和绝对损失的折衷,对于远离中心的异常点用均方差,中心附近用绝对损失,这个界限一般用分位数做度量。分位数损失,是分位数回归的损失函数。当然这两个损失函数主要用于健壮回归,即减少异常点对损失函数的影响。
GBDT正则化
- Shrinkage。每次对残差进行估计迭代时,不直接用而是乘一个正则化系数 α \alpha α,当它很小时,就需要更多的弱学习器来维持一个误差恒量。
- Subsample。子采样比例,不放回抽样(而随机森林是放回采样)进行训练,此时它也被称为是随机梯度随机树(stochastic)
- 剪枝。
- 早停。如树迭代数,树棵树,深度等,验证集误差不再下降等
- Dropout。每次增加一棵树,不是用所有树的残差,而是随机抽取一些树。
如何处理多分类问题
实际上是用树来模拟了softmax的每个分支的结果。即在每轮迭代的时候都建多棵树,每类一棵。最后预测时,将每类树的预测值用softmax算一下即可。
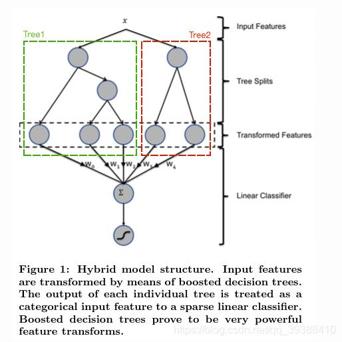
核心是采用迭代多棵回归树来共同决策。 (每次的划分标准当然可以是不一样的树,每次迭代后的更新都会对接下来的训练有影响。)在训练整个模型时,如下图中分为了两颗树一共有五个叶子节点。当输入变量样本X 落在了第一棵树的第二个叶子节点,第二颗树的第一个叶子节点,于是我们便可以依次构建一个五纬的特征向量【0,1,0,1,0】),然后再和原来的特征一起输入到逻辑回归当中进行训练。而它被广泛使用的原因:
- 1.毫无疑问:使用起来效果非常好。
- 2.GBDT相对来说能适用于处理各种类型的数据,不容易受异常噪音的影响。但是由于弱模型之间的依赖关系,难以并行训练数据,不过可以通过自采样的SGBT来达到部分并行。还有xgboost(eXtreme Gradient Boosting),它能够自动利用CPU的多线程并行,而且在计算速度和准确率上有更好的表现。
- 3.可做分类可回归,差别也就是输出为类别还是值的问题。但是GBDT具体每棵树的建立方式还是普通的CART树,不过都是使用的cart回归树,因为为了学习梯度,每次需要得到负梯度的值,所以输出必须为一个确定的值,而不是类别。
- 4.筛选特征。利用树这一天然的特征生成器,可以起到自动筛选特征的作用,也相当吸引人。
缺点:
- 1 在高维度稀疏的数据集上表情不如支持向量机或者神经网络
- 2 在处理文本问题上不如数值明显
- 训练时需要串行,只能在决策树内部用一些局部并行的手段。
随机森林与GBDT的比较
- 随机森林可分类可回归,GBDT只能由回归树组成
- 随机森林可并行,GBDT串行
- 随机森林多数表决,GBDT是多树累加
- 随机森林是减少方差,GBDT减少偏差
- 随机森林不需要归一化,GBDT需要
- 随机森林对异常值不敏感,GBDT需要
GBDT和随机森林的比较?
原始的Boost算法是,为每一个样本初识化同样大小的一个权重值。在之后的每一步训练中得到的模型,会根据数据点估计的对错,增加分错的权重,减少分对的权重,然后等进行了N次迭代,将会得到N个简单的分类器,然后组合起来,得到一个最终的模型。而Gradient Boost与传统的Boost的区别是,每一次的计算是为了减少上一次的残差(residual),而为了消除残差,在残差减少的梯度(Gradient)方向上建立一个新的模型。所以说,在Gradient Boost中,每个新的模型的简历是为了使得之前模型的残差往梯度方向减少,与传统Boost对正确、错误的样本进行加权有着很大的区别。
Xgboost:
但gbdt往往要生成一定数量的树才能达到令我们满意的准确率,所需要的计算量很大,所以出现了基于它的升级版本:Xgboost。
Xgboost实际所对应的模型同样是多个CART树,然后同样将每课树加到一起作为最后的预测值。
对于普通CART,它的改造点在于:
1.正则化。在损失函数中加入了正则化项:
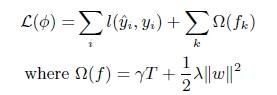
其中T是叶子节点数,显然,当γ越大,对较多叶子节点的树的惩罚越大,而λ越大也是为了同一个目的:获得更简单的树,这样2个方法可以在建树后不用考虑剪枝问题 (但建树完成最好仍然需要从底向上检查一遍,最大树深的参数建议为5),因为已经提前考虑到了树本身的复杂性。快。
2.利用损失函数的二阶导展开式拟合残差。
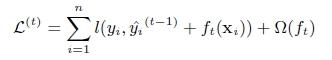
对上式的损失函数做二阶展开:
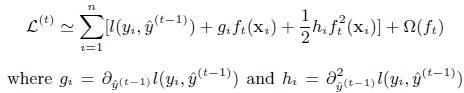
其中g为损失函数的一阶导数,h为二阶导数。而非要用二阶的目的是能够提升一阶的精度,更加逼近损失函数,同时两者不依赖损失函数形式,所以便于可以更换成自自定义的样子,而不是单单的残差)。快。
3.CART回归树中寻找最佳分割点(它的本质任然是树)是利用最小化均方差,而xgboost是最大化,停止建树1gain不再增加2最大深度3叶子权重阈值。计算同样是计算了g,h,快。
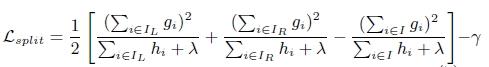
4.列采样:为了防止过拟合(还有shrinkage的方法,即学习率,可以给后面的训练更大的空间,从0.1开始探索,一般0.01-0.1),与随机森林类似。
5.缺失值处理:稀疏感知,会被划分到默认的分支。分别假设特征缺失的样本属于右子树和左子树,而且只在不缺失的样本上迭代,分别计算缺失样本属于右子树和左子树的增益,选择增益最大的方向为缺失数据的默认方向。
并行化在哪里?
并不是tree维度的并行,而是特征维度的并行。以往的算法的耗时往往在遍历枚举所有的特征,以获得最佳的特征分割点。所以它会预先按每个特征的特征值升值排好序,存储为块结构,分裂节点时可以多线程找每个特征的最佳分裂点,极大的提升速度。
特征的计算只与输入的样本与树本身的结构有关,即为了并行计算的时候可以提前对特征按特征值进行预排序(升序排练后,用贪心法找最佳特征,这是因为每次换分结点的不同,只是划分节点的那一个节点对loss有影响,如【1,2】【3,4】和【1,2,3】【4】,那么可以考虑直接衡量3的重要程度然后贪心,就不用全部遍历了),预排序时特征的重要性衡量主要有三种根据方法:
- 1.importance_type=weight(默认值),特征重要性使用特征在所有树中作为划分属性的次数。
- 2.importance_type=gain,特征重要性使用特征在作为划分属性时loss平均的降低量。
- 3.importance_type=cover,特征重要性使用特征在作为划分属性时对样本的覆盖度
https://xgboost.readthedocs.io/en/latest/tutorials/model.html
from sklearn import datasets
iris = datasets.load_iris()#iris数据集
data = iris.data[:100]
label = iris.target[:100]
from sklearn.cross_validation import train_test_split
train_x, test_x, train_y, test_y = train_test_split(data, label, random_state=0)#训练集与测试集
import xgboost as xgb #使用Xgboost库
dtrain=xgb.DMatrix(train_x,label=train_y)
dtest=xgb.DMatrix(test_x)
#设定参数
params={'booster':'gbtree',
'objective': 'binary:logistic',
'eval_metric': 'auc',
'max_depth':4,
'lambda':10,
'subsample':0.75,
'colsample_bytree':0.75,
'min_child_weight':2,
'eta': 0.025,
'seed':0,
'nthread':8,
'silent':1}
watchlist = [(dtrain,'train')]
bst=xgb.train(params,dtrain,num_boost_round=100,evals=watchlist)#训练
ypred=bst.predict(dtest)#预测
y_pred = (ypred >= 0.5)*1
from sklearn import metrics#输出一些评价指标
print ('AUC: %.4f' , metrics.roc_auc_score(test_y,ypred))
print ('ACC: %.4f' , metrics.accuracy_score(test_y,y_pred))
print ('Recall: %.4f' , metrics.recall_score(test_y,y_pred))
print ('F1-score: %.4f' ,metrics.f1_score(test_y,y_pred))
print ('Precesion: %.4f' ,metrics.precision_score(test_y,y_pred))
metrics.confusion_matrix(test_y,y_pred)
#输出模型
bst.dump_model("model.txt")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
LightGBM
xgboost预排需要消耗空间,在特征值很多的情况下,对cache不友好。那么在大规模数据上,就提出了lightGBM–速度更快,内存更小。
- Histogram决策树。直方图算法,将连续值离散成直方图,根据离散值寻找最优分割点。这样做不仅不需要占大量内存的预排序结果,而且离散之后再找最优分割点的遍历次数更少,只有k直方图的k次。
- 单边梯度采样(GOSS)。排除大部分小梯度样本,,仅仅用剩下的样本进行计算,GOSS是一种采样方法。
- 互斥特征捆绑(EFB)。将互斥的特征进行绑定可以有效的减少特征数量。
- 带深度限制的叶子生长。不再按层增长,只限制叶子的深度,这样既可以高效的长树,深度限制之后也可以减轻过拟合。
- 支持并行。不同的机器在不同的特征集合上分别找最优分割点。
- cache命中优化
最后顺便总结一下方差与偏差之间的差别与联系:
首先在ensemble learning中,Bagging方法能减少方差,而Boosting方法减少了偏差。根本在于Bagging方法通过并行处理,复杂化了整个大模型形成了森林,以群体的智慧代替决策,统一了预测的期望值,减少了波动程度即方差,而且森林也不太容易过度拟合,所以森林的规模往往可以更大;而Boosting方法通过串行学习,不断从错误中寻找新的方向,对数据的预测将会更准确,即减少了偏差。所以训练更多的树其实会增加过度拟合的可能性。
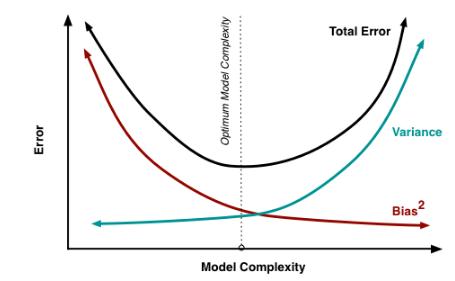
偏差指的是期望值与真实值之间的偏差程度,代表了算法的拟合能力;方差是样本在期望值附近的波动程度,度量了在有数据扰动情况下所带来的影响。从上图可以看出,模型复杂程度越高,拟合的程度就越高,训练偏差就越小。但如果用新数据对该模型进行测试,结果可能不佳,即模型的方差很大。整体的误差呈现出先降后升的情况,所以在选择模型时应该好好的调配两者之间的关系,比如像Xgboost所惩罚的正则化,Shrinkage,Subsampling,Dropout 。

EL应用:
AdaBoostClassifier参数说明:
AdaBoostClassifier(algorithm=‘SAMME.R’, base_estimator=None,learning_rate=1.0, n_estimators=50, random_state=None)
algorithm:权重的度量,SAMME.R是预测概率大小作权重。SAMME是Adaboost算法的扩展
base_estimator:用于评估的学习模型算法
n_estimators:最大迭代次数
random_state:是否随机
- 1
- 2
- 3
- 4
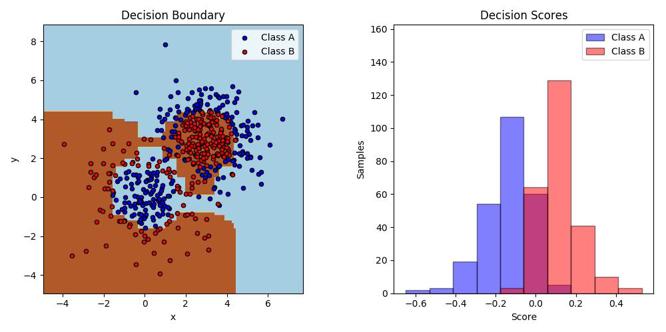
完成分类和每棵决策树的评分:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import make_gaussian_quantiles
X1, y1 = make_gaussian_quantiles(cov=2.,
n_samples=200, n_features=2,
n_classes=2, random_state=1)
X2, y2 = make_gaussian_quantiles(mean=(3, 3), cov=1.5,
n_samples=300, n_features=2,
n_classes=2, random_state=1)
X = np.concatenate((X1, X2))
y = np.concatenate((y1, - y2 + 1))
bdt = AdaBoostClassifier(DecisionTreeClassifier(max_depth=1),
algorithm="SAMME",
n_estimators=200)
bdt.fit(X, y)
plot_colors = "br"
plot_step = 0.02
class_names = "AB"
plt.figure(figsize=(10, 5))
plt.subplot(121)
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, plot_step),
np.arange(y_min, y_max, plot_step))
Z = bdt.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
cs = plt.contourf(xx, yy, Z, cmap=plt.cm.Paired)
plt.axis("tight")
for i, n, c in zip(range(2), class_names, plot_colors):
idx = np.where(y == i)
plt.scatter(X[idx, 0], X[idx, 1],
c=c, cmap=plt.cm.Paired,
s=20, edgecolor='k',
label="Class %s" % n)
plt.xlim(x_min, x_max)
plt.ylim(y_min, y_max)
plt.legend(loc='upper right')
plt.xlabel('x')
plt.ylabel('y')
plt.title('Decision Boundary')
# 得分
twoclass_output = bdt.decision_function(X)
plot_range = (twoclass_output.min(), twoclass_output.max())
plt.subplot(122)
for i, n, c in zip(range(2), class_names, plot_colors):
plt.hist(twoclass_output[y == i],
bins=10,
range=plot_range,
facecolor=c,
label='Class %s' % n,
alpha=.5,
edgecolor='k')
x1, x2, y1, y2 = plt.axis()
plt.axis((x1, x2, y1, y2 * 1.2))
plt.legend(loc='upper right')
plt.ylabel('Samples')
plt.xlabel('Score')
plt.title('Decision Scores')
plt.tight_layout()#自动控制边缘间距
plt.subplots_adjust(wspace=0.35)
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
AdaBoostRegressor参数说明:
AdaBoostRegressor(base_estimator=DecisionTreeRegressor(criterion=‘mse’, max_depth=4, max_features=None,max_leaf_nodes=None, min_impurity_split=1e-07,min_samples_leaf=1, min_samples_split=2,min_weight_fraction_leaf=0.0, presort=False, random_state=None,splitter=‘best’),learning_rate=1.0, loss=‘linear’, n_estimators=300,random_state)
base_estimator:默认是决策树
learning_rate=1.0:学习率
loss='linear':损失函数
n_estimators=300:最大迭代次数
random_state=是否随机
- 1
- 2
- 3
- 4
- 5
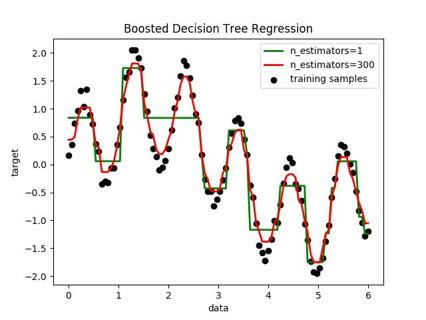
完成回归的任务:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import AdaBoostRegressor
rng = np.random.RandomState(1)
X = np.linspace(0, 6, 100)[:, np.newaxis]
y = np.sin(X).ravel() + np.sin(6 * X).ravel() + rng.normal(0, 0.1, X.shape[0])
regr_1 = DecisionTreeRegressor(max_depth=4)
regr_2 = AdaBoostRegressor(DecisionTreeRegressor(max_depth=4),
n_estimators=300, random_state=rng)
print(regr_2)
regr_1.fit(X, y)
regr_2.fit(X, y)
y_1 = regr_1.predict(X)
y_2 = regr_2.predict(X)
plt.figure()
plt.scatter(X, y, c="k", label="training samples")
plt.plot(X, y_1, c="g", label="n_estimators=1", linewidth=2)
plt.plot(X, y_2, c="r", label="n_estimators=300", linewidth=2)
plt.xlabel("data")
plt.ylabel("target")
plt.title("Boosted Decision Tree Regression")
plt.legend()
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
背景
本人普通二本本科毕业 4 年,目前是在广州工作,是一家大型的人力外包公司外包到银行的开发人员,这可能也是长期在各大招聘软件上最积极的招聘岗位。
从入职到现在已经有四个月了,也大概了解了外包的主要工作情况,也有了一些心得体会,借此机会也简单和大家分享一下自己的一些想法。
是否和行内员工有什么不一样,是否会有歧视
首先从工作内容上来说,外包等级一般最多就是高级程序员,上层有很多架构师做技术选型和业务分析,这些一般是轮不到你做的。
而如果是日常的开发任务的话,其实是并没有太大的不一样,一般你分配到哪个组,行内人员做什么工作,你就会做什么工作,开发设备大家也是一样的,电脑配置都不会太高,处于让你刚好能开发,但是别想打游戏的程度。
不过作为外包人员,一些操作权限上的确有所限制,比如如果出现一些网络环境升级的事情,行内人员不会变动,外包同事就会需要重新申请访问权限的情况,其实就和公司级别高低不同,手中账号权限也有不同一样而已。
银行大部分的人素质都很高,大家彼此之间也非常和气,有刚大学毕业的小伙子,也有工作十几二十年的二级、三级经理,大家彼此之间都是互称老师,同事之间有问题互相帮助是非常正常的事情,刚进来有很多环境和工具的不适应,处于到处问人的阶段,也基本找谁都能得到一定的回应,不用担心自己成为一座孤岛。
同时,也不会出现说让你加班赶工而他们歇着的情况,甚至可以说他们因为是体制内的人员,抱着的饭碗比你的珍贵得多得多,比你认真努力的也多得多,经常会出现我回到家里,他们还打电话过来询问工作问题,如果发现你已经下班了,也不会说什么,就说明天继续跟进就好。
使用的技术栈是否很落后,有提升空间吗
以刚从一家小创业公司出来的程序员的技术能力和视野来说,银行的整体技术方向其实并不算很是落后,还有专门的技术中台组,中间件组等技术支持部门,行内最大的业务系统每日访问流量也有上亿的,同时有很丰富的技术社区,会分享技术选型的一些分析文章,以及一些使用文档,使用过程中有什么问题也可以随时上去发表讨论,跟进修改等。
但是,银行开发真的如同冰火两重天。你具体会用到什么技术,做什么方向的开发,就看你进到什么部门了。如果是新的业务部门,可能就是用最新的框架技术;最大的业务部门,就会面临最大的业务流量的挑战。 但是如果运气不好,进到老系统部门,就可能维护年纪甚至比你大的主机代码,不一定是你常用的语言写的。甚至进到测试部门,天天做测试工具人也是有可能的,所以面试的时候问一下自己的对口部门是哪里,提前有个心理准备否则落差会很大。
这一点深有体会,大部分小伙伴可能对于银行这种组织的第一印象就是使用的技术特别老,系统或者 APP 很久都不更新一次,而且做得贼丑,用户体验贼差。实际上,很多银行实际也在改变,拥抱数字化。据我了解,很多银行每年的研发投入都非常多比如招商银行。个人觉得招商银行的 APP 体验最好,而且招商银行内部很多项目的技术都是紧跟潮流的!
而对比小公司开发经验来说,银行的开发就是体现一个大而重,但是分工挺明确的,至少之前在小公司从需求分析到页面后端数据库都会写,现在就是纯粹的后台,数据库和页面都不用管。只是内部沟通系统特别多,任务管理系统,需求分析系统,接口登记系统等等,写一个功能编码可能两小时,问清楚要做什么,开会宣讲讨论,业务沟通,完成后的需要找数据自测,跟进测试组测试等真的能花掉你很多时间。同时银行使用内部网络,网络环境不稳定,访问出错不一定是程序问题,无法登陆也是常有的事情,这个也不是针对你,是每个人都面临的问题,所以沟通成本,测试成本会很高,用不惯邮件沟通的人,看到别人发“好的”都用邮件回复你有可能会两眼一黑。
关于技术进步上,业务工作中用到的是一部分,然后社区的分享内容是一部分,最后还是得靠自己多在业余时间多去学习和成长了,也有听说有同事后面去了阿里的,也有出去面试被说技术栈和业务线太过片面的,至于最终成什么样子,终究是看你自己。
技术线路的职业发展
职业发展一阶:
技术技能要求:执行测试用例,记录测试发现的Bug,跟踪Bug生命周期状态,回归Bug,参与项目测试方案与用例设计等的评审。
对象:一般为刚踏入测试行业的新手。
职业发展二阶:
技术技能要求: 以设计模块级测试方案、测试用例、测试代码为工作重点,执行测试用例为辅;组织模块测试设计评审;参与模块级开发设计方案评审,能独立完成规范的测试流程个节点的工作。
对象:一般为有1-3年经验的测试人员。
职业发展三阶:
技术技能要求: 设计某项目总体测试方案,制订测试计划;对项目的某类或某特性进行测试,如自动化测试、内存泄露、性能测试、安全性测试等;对有一定技术深度或难度方面的测试有独当一面的能力,且收到效果;培养测试新人成为合格的测试工程师。
对象:有3-5年项目测试经验者。
职业发展四阶:
技术技能要求: 制定某类产品测试总体策略、测试流程,制定相关测试规范、指南;负责某类产品测试平台建设;指导重点测试方案设计,对测试设计有一定的创新能力,并收到效果;资深测试工程师的导师。
对象:有5-10年的测试经验者。
职业发展五阶:
技术技能要求: 负责某产品先测试策略、测试方法、流程规范的制定;规划、设计和开发测试平台;为了不断降低公司研发成本而进行新测试技术的研究、实践和推广;技术线上测试人才梯队的结构设计。
做为一名测试人,我想分享一下这些年来,我对于技术一些归纳和总结,和自己对作为一名测试员需要掌握那些技能的笔记分享,希望能帮助到有心在技术这条道路上一路走到底的朋友!
内容涉及:测试理论、Linux基础、MySQL基础、Web测试、接口测试、App测试、管理工具、Python基础、Selenium相关、性能测试、LordRunner相关等
作为一位过来人也是希望你们少走一些弯路,在这里我给大家分享一些进阶自动化测试的路线资源,希望帮你们更好的突破自己!
《软件测试工程师发展规划路线》
一、测试基础
了解测试的基础技能,掌握主流缺陷管理工具的使用,熟练测试环境的操作与运维
class="table-box">| 程序员威子 | 测试基础 |
|---|---|
| 测试计划/测试用例 | 黑盒用例设计等价类/边界值/场景分析/判定表/因果图分析/错误推断 |
| 缺陷 | 缺陷生命周期/缺陷分级/缺陷管理工具禅道/Jira |
| 数据库 | Mysql/环境搭建/增删改查/关联查询/存储过程 |
| Linux | 系统搭建/基本指令/日志分析/环境搭建 |
 class="blog_extension_card_cont">
class="blog_extension_card_cont">


评论记录:
回复评论: