
1. 什么是智能指针
- C++智能指针是包含重载运算符的类,其行为像常规指针,但智能指针能够及时、妥善地销毁动态分配的数据,并实现了明确的对象生命周期,因此更有价值
1.1 常规(原始)指针存在的问题
- 与其他现代编程语言不同,C++在内存分配、释放和管理方面向程序员提供了全面的灵活性
- 但同时,也制造了与内存相关的问题,如动态分配的对象没有正确地释放时将导致内存泄露
SomeClass* ptrData = anObject.GetData();
ptrData->DoSomething();
- 1
- 2
- 在上述代码中,没有显而易见的方法获悉 ptrData 指向的内存
- 是否是从堆中分配的,因此最终需要释放
- 是否由调用者负责释放
- 对象的析构函数是否会自动销毁该对象
1.2 智能指针有何帮助
- 当需要管理堆(自由存储区)中数据时,可在程序中使用智能指针,以更智能的方式分配和管理内存
smart_pointer<SomeClass> spData = anObject.GetData();
spData->Display();
(*spData).Display();
// 智能指针的行为类似常规指针,但通过重载的运算符和析构函数可确保动态分配的数据能够及时地销毁
- 1
- 2
- 3
- 4
2. 智能指针是如何实现的
- 智能指针类重载了解除引用运算符(*)和成员选择运算符(->),可以像使用常规指针那样使用它们
- 另外,为了能够在堆中管理各种类型,几乎所有的智能指针类都是模板类,包含其功能的泛型实现。由于模板是通用的,可以根据要管理的对象类型进行具体化
template<typename T>
class smart_pointer {
private:
T* rawPtr;
public:
// 构造函数接受一个指针,并将其保存到该智能指针类内部的一个指针对象中
smart_pointer (T* pData) : rawPtr (pData) {}
// 析构函数释放该指针,从而实现了自动内存释放
~smart_pointer () {delete rawPtr;};
// copy constructor
smart_pointer (const smart_pointer & anotherSP);
// copy assignment operator
smart_pointer& operator= (const smart_pointer& anotherSP);
T& operator* () const { // 重载了 * 运算符
return *(rawPtr);
}
T* operator-> () const { // 重载了 -> 运算符
return rawPtr;
}
};
int main() {
return 0;
}

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
使智能指针真正“智能”的是复制构造函数、赋值运算符和析构函数的实现,它们决定了智能指针对象被传递给函数、赋值或离开作用域(即像其他类对象一样被销毁)时的行为
3. 智能指针类型
- 智能指针决定在复制和赋值时如何处理内存资源
- 智能指针的分类实际上就是内存资源管理策略的分类,可分为如下几类
- 深复制
- 写时复制(Copy on Write,COW)
- 引用计数
- 引用链接
- 破坏性复制
3.1 深复制
- 在实现深复制的智能指针中,每个智能指针实例都保存一个它管理的对象的完整副本
- 每当智能指针被复制时,将复制它指向的对象(因此称为深复制)
- 每当智能指针离开作用域时,将(通过析构函数)释放它指向的内存
虽然基于深复制的智能指针看起来并不比按值传递对象优越,但在处理多态对象时,其优点将显现出来
// 使用基于深复制的智能指针将多态对象作为基类对象进行传递
template<typename T>
class deepcopy_smart_ptr {
private:
T* object;
public:
//... other functions
// 深复制指针的复制构造函数
// 使得能够通过Clone()函数对多态对象进行深复制——类必须实现函数Clone()
deepcopy_smart_ptr (const deepcopy_smart_ptr& source) {
// Clone() is virtual: ensures deep copy of Derived class object
object = source->Clone();
}
// 复制赋值运算符
deepcopy_smart_ptr& operator= (const deepcopy_smart_ptr& source) {
if (object) {
delete object;
}
object = source->Clone();
}
};
int main() {
deepcopy_smart_ptr<Carp> freshWaterFish(new Carp);
MakeFishSwim (freshWaterFish);
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
基于深复制的机制的不足之处在于性能,这可能不使用智能指针,而将指向基类的指针(常规指针Fish*)传递给函数
3.2 写时复制机制
- 写时复制机制(Copy on Write,COW)试图对深复制智能指针的性能进行优化,它共享指针,直到首次写入对象
- 首次调用非 const 函数时,COW 指针通常为该非 const 函数操作的对象创建一个副本,而其他指针实例仍共享源对象
3.3 引用计数智能指针
- 引用计数是一种记录对象的用户数量的机制,当计数降低到零后,便将对象释放
- 引用计数提供了一种优良的机制,使得可共享对象而无法对其进行复制
这种智能指针被复制时,需要将对象的引用计数加1,至少有两种常用的方法来跟踪计数
- 在对象中维护引用计数(称为入侵式引用计数,因为需要修改对象以维护和递增引用计数,并将其提供给管理对象的智能指针,COM 采取的就是这种方法)
- 引用计数由共享对象中的指针类维护 { 智能指针类将计数保存在自由存储区(如动态分配的整型),复制时复制构造函数将这个值加1 }
- 使用引用计数机制,程序员只应通过智能指针来处理对象。在使用智能指针管理对象的同时让原始指针指向它是一种糟糕的做法,因为智能指针将在它维护的引用计数减为零时释放对象,而原始指针将继续指向已不属于当前应用程序的内存
- 引用计数还有一个独特的问题
- 如果两个对象分别存储指向对方的指针,这两个对象将永远不会被释放,因为它们的生命周期依赖性导致其引用计数最少为1
3.4 引用链接智能指针
- 引用链接智能指针不主动维护对象的引用计数,而只需知道计数什么时候变为零,以便能够释放对象
- 之所以称为引用链接,是因为其实现是基于双向链表的,通过复制智能指针来创建新智能指针时,新指针将被插入到链表中;当智能指针离开作用域进而被销毁时,析构函数将把它从链表中删除
- 与引用计数的指针一样,引用链接指针也存在生命周期依赖性导致的问题
3.5 破坏性复制
- 破坏性复制是这样一种机制,即在智能指针被复制时,将对象的所有权转交给目标指针并重置原来的指针
- 虽然破坏性复制机制使用起来并不直观,但它有一个优点:即可确保任何时刻只有一个活动指针指向对象。因此,它非常适合从函数返回指针以及需要利用其“破坏性”的情形
- std::auto_ptr 是最流行的破坏性复制指针,被传递给函数或复制给另一个指针后,这种智能指针就没有用了(该智能指针类的复制构造函数和赋值运算符不能接受const 引用)
C++11 摒弃了 std::auto_ptr,应使用 std::unque_ptr,这种指针不能按值传递,而只能按引用传递,因为其复制构造函数和复制赋值运算符都是私有的
template<typename T>
class destructivecopy_ptr {
private:
T* object;
public:
destructivecopy_ptr(T* input):object(input) {}
~destructivecopy_ptr() { delete object; }
// 这些函数实际上在源指针被复制后失效,即复制构造函数在复制后将源指针设
// 置为NULL,这就是“破坏性复制”的由来
destructivecopy_ptr(destructivecopy_ptr& source) {
// Take ownership on copy
object = source.object;
// destroy source
source.object = 0;
}
// 复制赋值运算符亦如此
destructivecopy_ptr& operator= (destructivecopy_ptr& source) {
if (object != source.object) {
delete object;
object = source.object;
source.object = 0;
}
}
};
int main() {
destructivecopy_ptr<int> num (new int);
destructivecopy_ptr<int> copy = num;
// num is now invalid
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
3.6 使用std::unique_ptr
- std::unique_ptr 是 C++11 新增的,与 auto_ptr 稍有不同,因为它不允许复制和赋值
- 其复制构造函数和赋值运算符被声明为私有的,故不能复制它,即不能将其按值传递给函数,也不能将其赋给其他指针
#include - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
Fish: Constructed!
Fish swims in water
Fish swims in water
Fish: Destructed!
- 1
- 2
- 3
- 4
编写多线程的应用程序时,可考虑使用 std::shared_ptr 和 std::weak_ptr,它们可帮助实现线程安全和引用计数对象共享
Q&A
- string 类在自由存储区中动态地管理字符数组,它也是智能指针吗?
- 不是。string 类通常没有实现运算符*和−>,因此不属于智能指针。
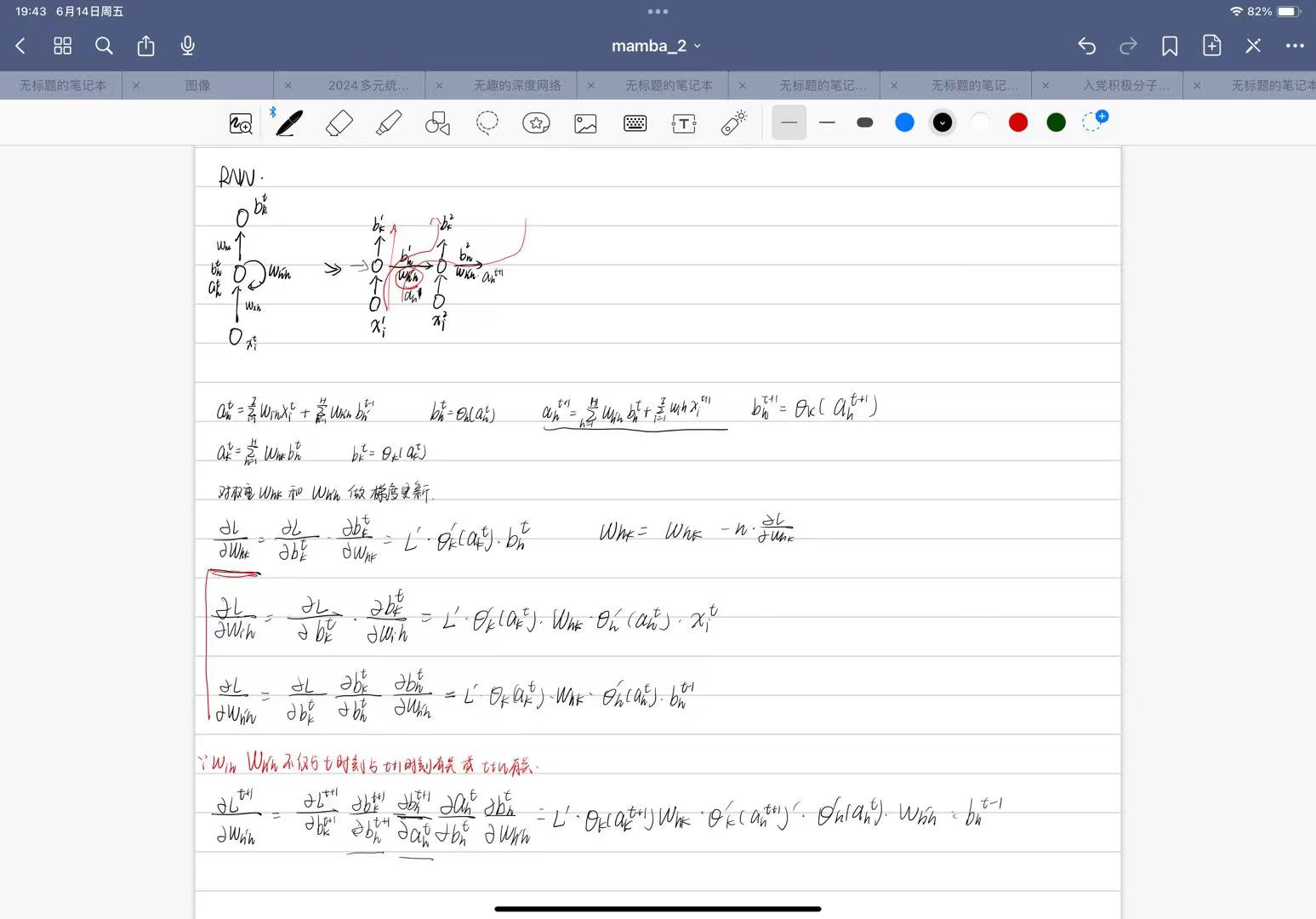
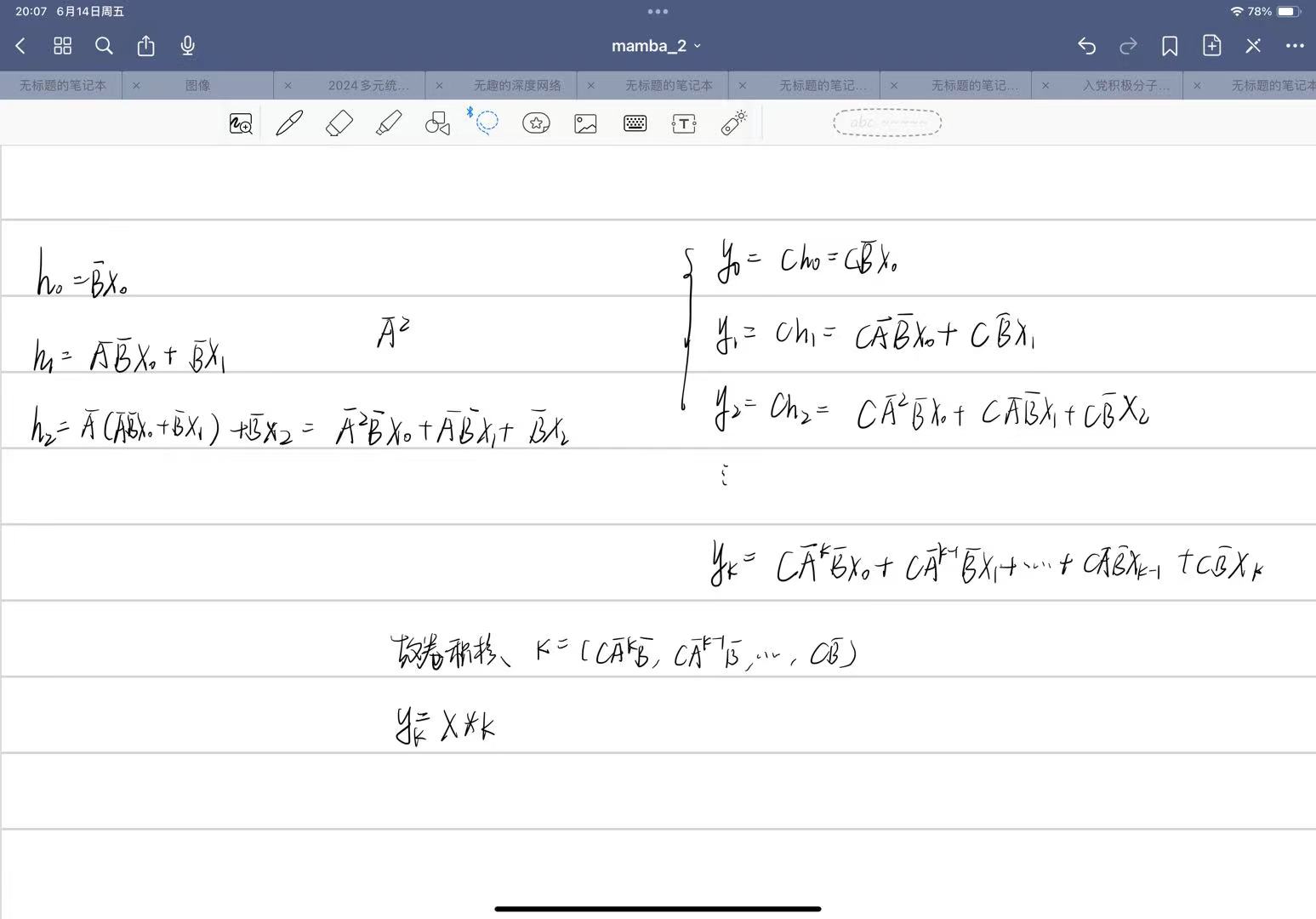
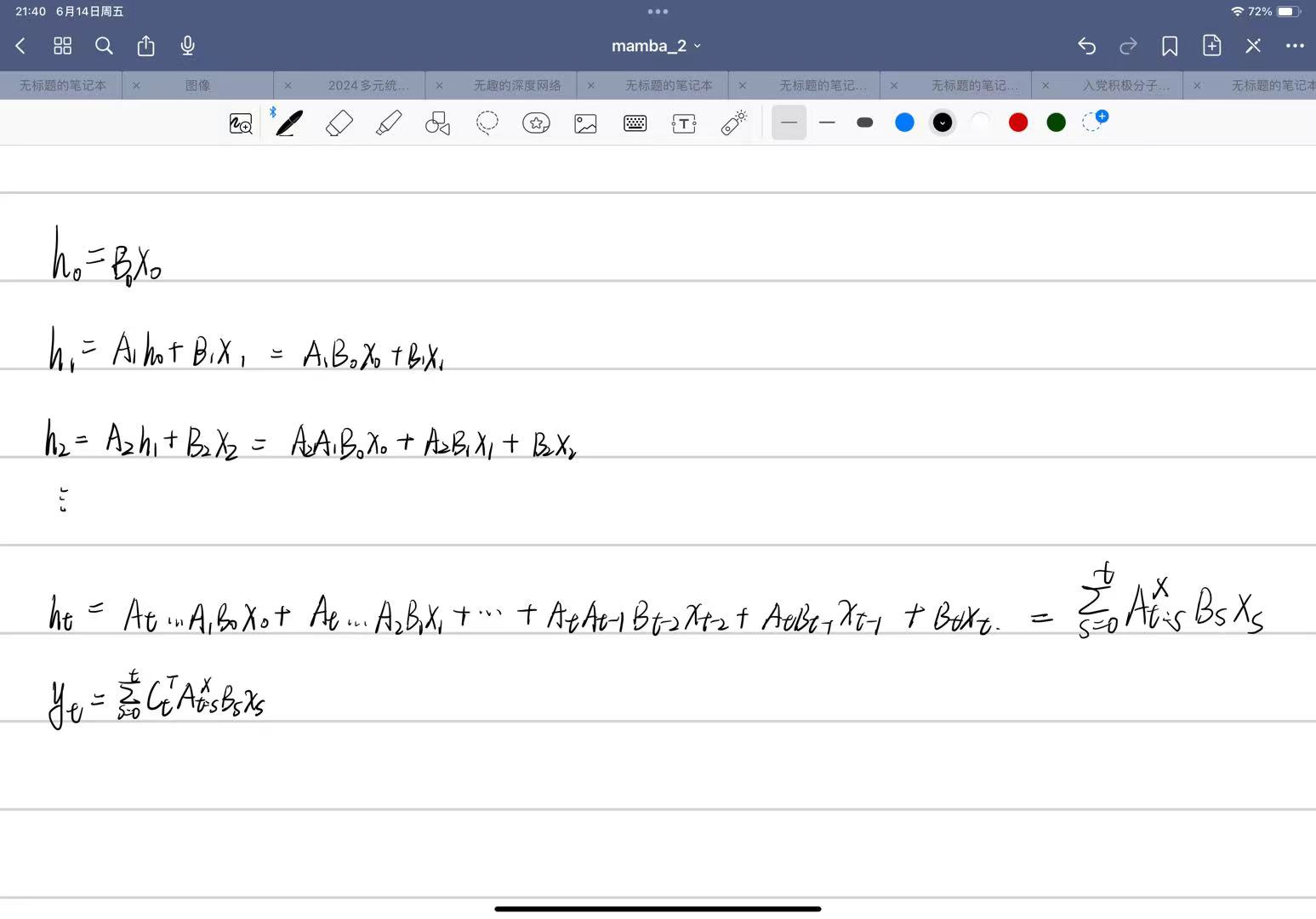
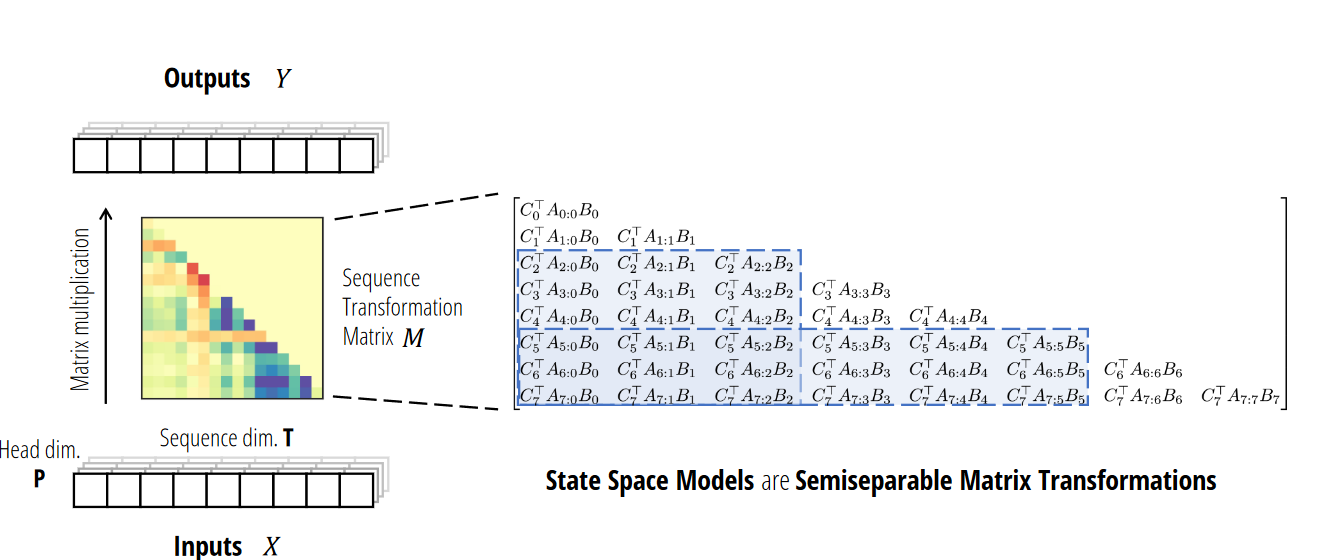
Question 1: What are the conceptual connections between state space models and attention? Can we combine them?
从概念的角度来看,发现 SSM 如此迷人的原因之一是给人的感觉就像_基础_一样。其中一个例子就是它们与许多主要的序列模型范式有着密切的联系。正在结构化 SSM 方面的工作中所阐述的那样,它们似乎抓住了连续、卷积和循环序列模型的本质——所有这些都包含在一个简单而优雅的模型中。(底下会介绍)
当然,除了这些之外,还有另一个主要的序列模型范式:无处不在的注意力机制的变体。SSM 总是让人感觉与注意力有些脱节,我们尝试了一段时间来更好地理解它们之间的关系
_Question 2: _Can we speed up the training of Mamba models by recasting them as matrix multiplications?
从计算的角度来看,尽管 Mamba 为提高速度付出了很多努力(特别是其硬件感知选择性扫描实现),但它的硬件效率仍然远低于注意力机制。缺少的一点是,现代加速器(如 GPU 和 TPU)_高度_专门用于矩阵乘法。虽然这对于推理来说不是问题,因为推理的瓶颈在于不同的考虑因素,但这在训练期间可能是一个大问题。
环境配置
安装依赖
conda create -n mamba python=3.10
conda activate mamba
conda install cudatoolkit==11.8 -c nvidia
pip install torch==2.3.1 torchvision==0.18.1 torchaudio==2.3.1 --index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip install triton==2.3.1
pip install transformers==4.43.3
pip install ninja --index-url https://pypi.tuna.tsinghua.edu.cn/simple
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}">
评论记录:
回复评论: