
一、本文的实例说明
本文旨在用Pytorch构建一个GAN网络,这个GAN网络可以生成手写数字。
二、GAN原理说明
这块不做赘述,CSDN上(及baidu上)关于GAN(生成对抗网络)的说明实在太多,这里推荐一篇文章,写的通俗易懂:一文看懂「生成对抗网络 - GAN」基本原理+10种典型算法+13种应用
三、GAN网络架构说明
GAN由生成器(generator)和判别器(discriminator)组成。
1)生成器架构
由9个CBR模块串联形成,结构及参数如下:
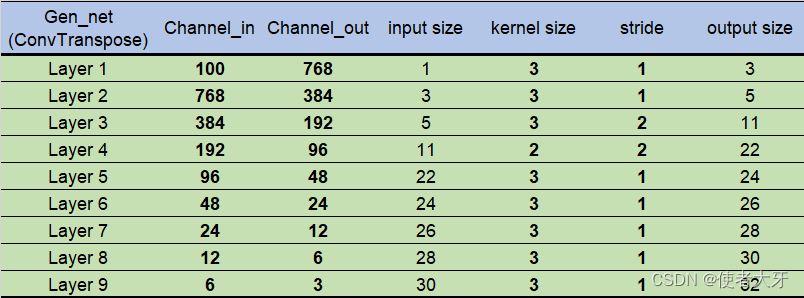
CBR=C+B+R
C=ConvTranspose *注意!这里是逆卷积,因为生成器要把一个简单的向量(或者数值)生成一个图片(矩阵),这是一个“扩大”(上采样)的过程,所以要用逆卷积。这里再推荐一篇文章:ConvTranspose2d原理,深度网络如何进行上采样?
B=Batch Normalization;
R=ReLU;
2)判别器架构
也有9层,由9个CBL模块串联组成,结构及参数如下:
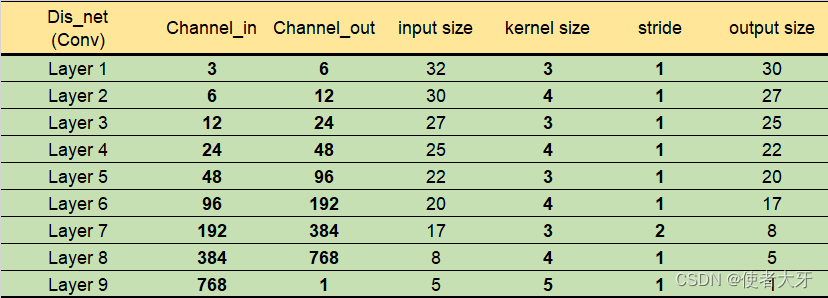
CBL=C+B+L
C=Conv *这里就是卷积层;
B=Batch Normalization;
L=LeakyReLu;
3)训练数据
从网上下载图片格式的MNIST数据集,然后取前900个训练(当然,计算机性能允许的话MNIST数据全部拿来训练更好。图片格式的MNIST数据集一般要付费,如果需要请留邮箱)
四、Pytorch代码
附在最后
五、生成结果
取训练过程的前100个epoch的图片,可以看出已经基本能生成一个比较像样的“9”,还有比较模糊的“7”和“8”。

六、一些理解
1)为什么在代码中生成器每训练5次判别器才训练一次?
直观理解,相比于“识别”图像,“创造”图像是一个更加复杂的任务,所以训练的次数要更多。从loss上也可以看出。(蓝色为生成器loss,红色为判别器loss)
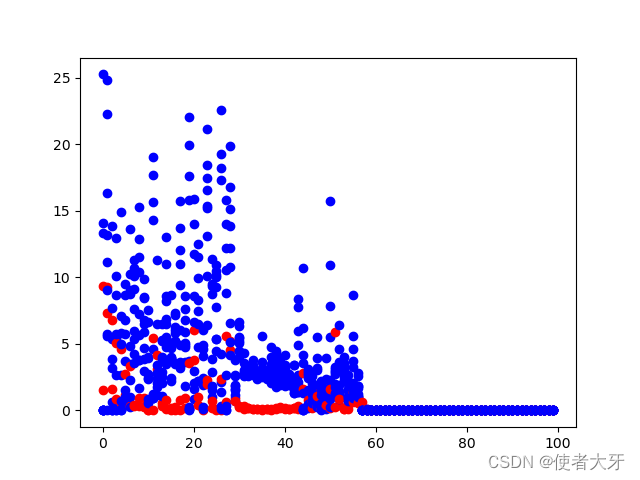
2)为什么最终生成的数字还是不太清晰?
个人理解,按影响从大到小有以下3个方面:
①网络模型不太合理:本次只采用了CBR模块的简单串联,如果加入些池化层,全连接层,网络可能不用这么“深”,而且效果可能更好;
写完这篇文章之后,发现确实有不少用GAN生成手写数字的实例,基本都是用全连接层做的,而且效果都不错。但是对于复杂的图像肯定是要用到CNN卷积神经网络的,比如生成Dota2英雄头像:
没错,最开始我是想做这个实例的。但是无奈做了几次都不成功,最大的问题可能是因为训练数据太少了,英雄头像总共就123个,而且差异非常大(有人类,精灵,有没有眼睛的,没有嘴的,既没有眼睛也没有嘴的,有一个头的,两个头的,三个头的。。。。)
②设置参数不合理:卷积层的Channel数量,Kernel size,stride,padding,learning rate等等这些都有影响;
③训练数据样本太少:参考上面Dota2头像的说明,但是MNIST数据集确实够大了,这个原因应该影响不大。
import torch
import torch.nn as nn
import torchvision
from torch.utils.data import DataLoader
from tqdm import tqdm #tqdm含义tqdm derives from the Arabic word taqaddum (تقدّم) which can mean “progress,” and is an abbreviation for “I love you so much” in Spanish (te quiero demasiado).
import matplotlib.pyplot as plt
img_size = 32
batch_size = 100
max_epoch = 200 #迭代次数,这个参数可以自己设计
init_channel = 100 #初始通道数,这个参数可以自己设计
# 数据集有900张图片(从MNIST选择900张图)
class Gen_net(nn.Module):
def __init__(self):
super(Gen_net, self).__init__()
self.net = nn.Sequential(
# 第一层
nn.ConvTranspose2d(in_channels=init_channel, out_channels=768, kernel_size=3, stride=1,
padding=0,
bias=False),
nn.BatchNorm2d(768),
nn.ReLU(inplace=True),
# 第二层
nn.ConvTranspose2d(in_channels=768, out_channels=384, kernel_size=3, stride=1,
padding=0,
bias=False),
nn.BatchNorm2d(384),
nn.ReLU(inplace=True),
# 第三层
nn.ConvTranspose2d(in_channels=384, out_channels=192, kernel_size=3, stride=2,
padding=0,
bias=False),
nn.BatchNorm2d(192),
nn.ReLU(inplace=True),
# 第四层
nn.ConvTranspose2d(in_channels=192, out_channels=96, kernel_size=2, stride=2, padding=0,
bias=False),
nn.BatchNorm2d(96),
nn.ReLU(inplace=True),
# 第五层
nn.ConvTranspose2d(in_channels=96, out_channels=48, kernel_size=3, stride=1, padding=0, bias=False),
nn.BatchNorm2d(48),
nn.ReLU(),
#第六层
nn.ConvTranspose2d(in_channels=48, out_channels=24, kernel_size=3, stride=1, padding=0, bias=False),
nn.BatchNorm2d(24),
nn.ReLU(),
#第七层
nn.ConvTranspose2d(in_channels=24, out_channels=12, kernel_size=3, stride=1, padding=0, bias=False),
nn.BatchNorm2d(12),
nn.ReLU(),
#第八层
nn.ConvTranspose2d(in_channels=12, out_channels=6, kernel_size=3, stride=1, padding=0, bias=False),
nn.BatchNorm2d(6),
nn.ReLU(),
#第九层
nn.ConvTranspose2d(in_channels=6, out_channels=3, kernel_size=3, stride=1, padding=0, bias=False),
nn.BatchNorm2d(3),
nn.Sigmoid()
)
def forward(self,x):
return self.net(x)
class Dis_net(nn.Module):
def __init__(self):
super(Dis_net,self).__init__()
self.net = nn.Sequential(
#第一层
nn.Conv2d(in_channels=3, out_channels= 6, kernel_size= 3, stride= 1, padding= 0, bias=False),
nn.BatchNorm2d(6),
nn.LeakyReLU(0.2, inplace= True),
#第二层
nn.Conv2d(in_channels= 6, out_channels=12, kernel_size= 4, stride= 1, padding= 0, bias=False),
nn.BatchNorm2d(12),
nn.LeakyReLU(0.2, True),
#第三层
nn.Conv2d(in_channels= 12, out_channels= 24, kernel_size= 3, stride= 1, padding= 0,bias=False),
nn.BatchNorm2d(24),
nn.LeakyReLU(0.2, True),
#第四层
nn.Conv2d(in_channels= 24, out_channels= 48, kernel_size= 4, stride=1, padding= 0, bias=False),
nn.BatchNorm2d(48),
nn.LeakyReLU(0.2, True),
#第五层
nn.Conv2d(in_channels= 48, out_channels= 96, kernel_size= 3, stride= 1, padding= 0, bias=True),
nn.BatchNorm2d(96),
nn.LeakyReLU(0.2, True),
#第六层
nn.Conv2d(in_channels=96, out_channels=192, kernel_size=4, stride=1, padding=0, bias=True),
nn.BatchNorm2d(192),
nn.LeakyReLU(0.2, True),
#第七层
nn.Conv2d(in_channels=192, out_channels=384, kernel_size=3, stride=2, padding=0, bias=True),
nn.BatchNorm2d(384),
nn.LeakyReLU(0.2, True),
#第八层
nn.Conv2d(in_channels=384, out_channels=768, kernel_size=4, stride=1, padding=0, bias=True),
nn.BatchNorm2d(768),
nn.LeakyReLU(0.2, True),
#第九层
nn.Conv2d(in_channels=768, out_channels=1, kernel_size=5, stride=1, padding=0, bias=True),
nn.Sigmoid()
)
def forward(self,x):
return self.net(x).view(-1)
gen_net = Gen_net()
dis_net = Dis_net()
#图像处理
transforms = torchvision.transforms.Compose([
torchvision.transforms.Resize([img_size, img_size]),
torchvision.transforms.ToTensor()
])
datasets = torchvision.datasets.ImageFolder(root='train_net_pic', transform=transforms)
dataloader = DataLoader(datasets, batch_size=batch_size, num_workers=0)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
gen_net.to(device)
dis_net.to(device)
#定义loss函数为二分交叉熵(discriminator的“评分”在0~1之间)
loss = nn.BCELoss().to(device)
#定义loss函数优化方法为Adadelta
opt_gen = torch.optim.Adadelta(gen_net.parameters(), lr= 0.001)
opt_dis = torch.optim.Adadelta(dis_net.parameters(), lr= 0.001)
true_label = torch.ones(batch_size).to(device)
fake_label = torch.zeros(batch_size).to(device) #真实照片评分为1,假照片评分为0
init_tensor = torch.randn(batch_size,init_channel,1,1).to(device) #初始矩阵,给gen_net生成图像。(这个矩阵可以自己定义大小,并不限于1×1,但是对应的网络架构也要改)
gen_init_tensor = torch.randn(batch_size,init_channel,1,1).to(device)
test_init_tensor = torch.randn(batch_size,init_channel,1,1).to(device)
for epoch in range(max_epoch): #迭代max_epoch次
for it, (img, _) in tqdm(enumerate(dataloader)): #遍历所有真实的图像( “_”是enumerate的用法,可以用变量代替)
real_pic = img.to(device)
#----------------------训练dis_net----------------------
if it%5 == 0 :
opt_dis.zero_grad() # zero_grad(), step()的用法参考前一篇文章
real_output = dis_net(real_pic) # 得到真实图片的discriminator网络输出一个0~1的“评分”,期望为1
dis_real_loss = loss(real_output, true_label) # 真实图片经过discriminator网络获得的输出和1矩阵的二分交叉熵作为loss
fake_pic = gen_net(init_tensor.detach()).detach()
fake_output = dis_net(fake_pic) # 得到假图片(生成网络生成的图片)的discriminator网络输出一个0~1的“评分”,期望为0
dis_fake_loss = loss(fake_output, fake_label)
dis_loss = (dis_fake_loss + dis_real_loss) # 判别网络的总loss
dis_loss.backward()
opt_dis.step()
dis_loss_numpy = dis_loss.detach().numpy()
plt.scatter(epoch, dis_loss_numpy, c='r')
#--------------------训练gen_net-------------------------
if it%1 == 0 :
opt_gen.zero_grad()
gen_pic = gen_net(gen_init_tensor)
gen_output = dis_net(gen_pic)
gen_loss = loss(gen_output, true_label) #期望生成的图片评分为1(生成网络期望“骗过”评价网络)
gen_loss.backward()
opt_gen.step()
gen_loss_numpy = gen_loss.detach().numpy()
plt.scatter(epoch, gen_loss_numpy, c='b')
img = gen_net(test_init_tensor)
torchvision.utils.save_image(img.data[:8], "%s/GAN_MNISTER_deep_3rd_%s.png" % ('gen_pic_deep', epoch), #取每个batch的前8张图
normalize=True)
torch.save(img.data[0] ,'gen_pic_deep/tensor.txt')
print('save_%s'%epoch)
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
评论记录:
回复评论: