

Pre
DDD - 服务、实体与值对象的两种设计思路:贫血模型与充血模型
概述
在事件风暴中,我们会根据一些业务操作和行为找出实体(Entity)或值对象(ValueObject),进而将业务关联紧密的实体和值对象进行组合,构成聚合,再根据业务语义将多个聚合划定到同一个限界上下文(Bounded Context)中,并在限界上下文内完成领域建模。
DDD - 服务、实体与值对象的两种设计思路:贫血模型与充血模型中我们知道了,要将领域模型最终转换为程序设计,可以落实到 3 种类型的对象设计,即服务、实体与值对象,然后进行一些贫血模型与充血模型的设计思路。但这远远不够,还需要有聚合、仓库与工厂的设计。
聚合(Aggregate)
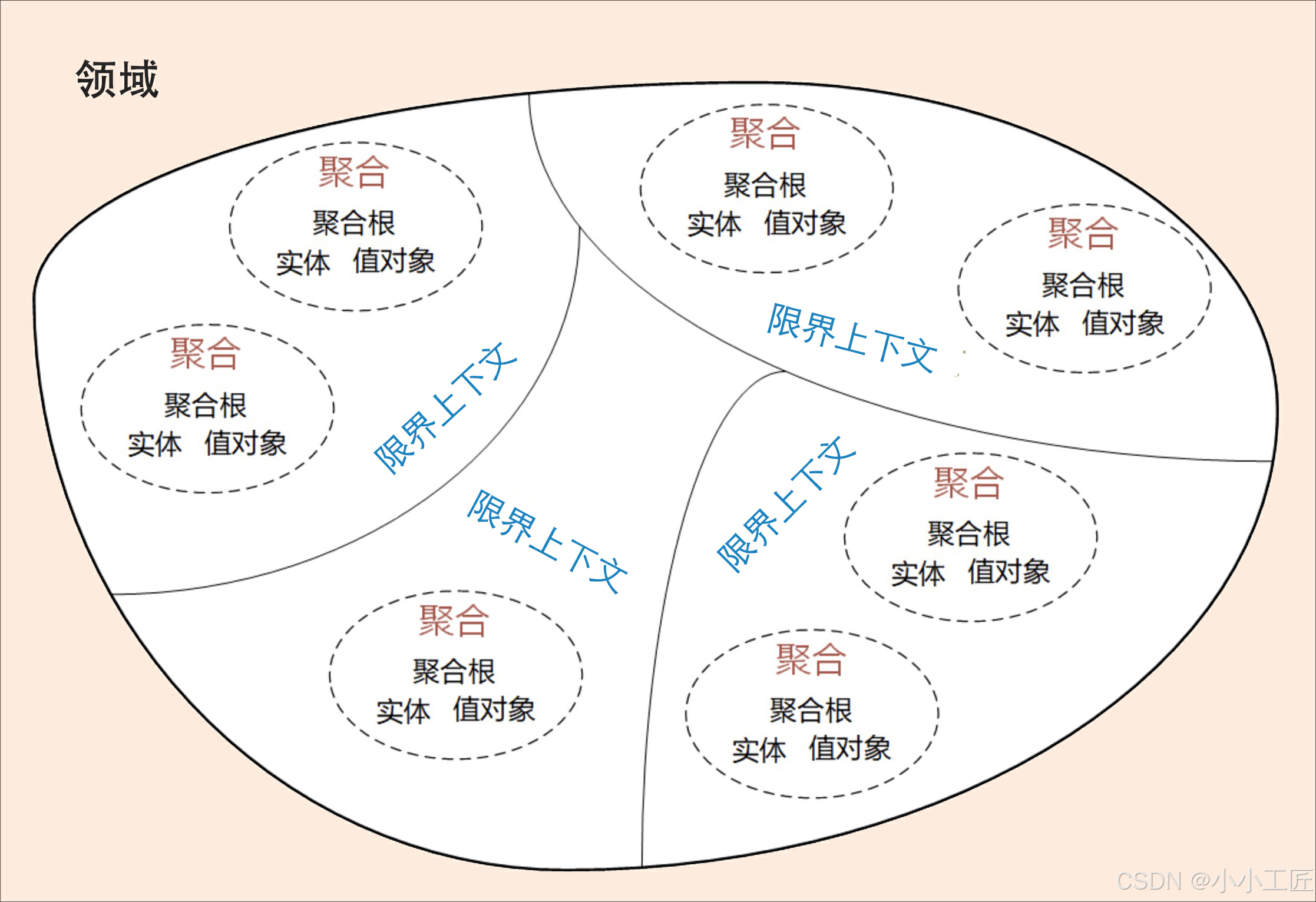
为什么要在限界上下文和实体之间增加聚合和聚合根这两个概念吗?它们的作用是什么?怎么设计聚合?
那聚合在其中起什么作用呢?
举个例子。社会是由一个个的个体组成的,象征着我们每一个人。随着社会的发展,慢慢出现了社团、机构、部门等组织,我们开始从个人变成了组织的一员,大家可以协同一致的工作,朝着一个最大的目标前进,发挥出更大的力量。
领域模型内的实体和值对象就好比个体,而能让实体和值对象协同工作的组织就是聚合,它用来确保这些领域对象在实现共同的业务逻辑时,能保证数据的一致性。
可以这么理解,聚合就是由业务和逻辑紧密关联的实体和值对象组合而成的,聚合是数据修改和持久化的基本单元,每一个聚合对应一个仓储,实现数据的持久化。
聚合有一个聚合根和上下文边界,这个边界根据业务单一职责和高内聚原则,定义了聚合内部应该包含哪些实体和值对象,而聚合之间的边界是松耦合的。按照这种方式设计出来的微服务很自然就是“高内聚、低耦合”的。
聚合在 DDD 分层架构里属于领域层,领域层包含了多个聚合,共同实现核心业务逻辑。聚合内实体以充血模型实现个体业务能力,以及业务逻辑的高内聚。
跨多个实体的业务逻辑通过领域服务来实现,跨多个聚合的业务逻辑通过应用服务来实现。比如有的业务场景需要同一个聚合的 A 和 B 两个实体来共同完成,我们就可以将这段业务逻辑用领域服务来实现;而有的业务逻辑需要聚合 C 和聚合 D 中的两个服务共同完成,这时就可以用应用服务来组合这两个服务
聚合的设计思路
在 DDD 中,实体和值对象是很基础的领域对象。实体一般对应业务对象,它具有业务属性和业务行为;而值对象主要是属性集合,对实体的状态和特征进行描述。但实体和值对象都只是个体化的对象,它们的行为表现出来的是个体的能力
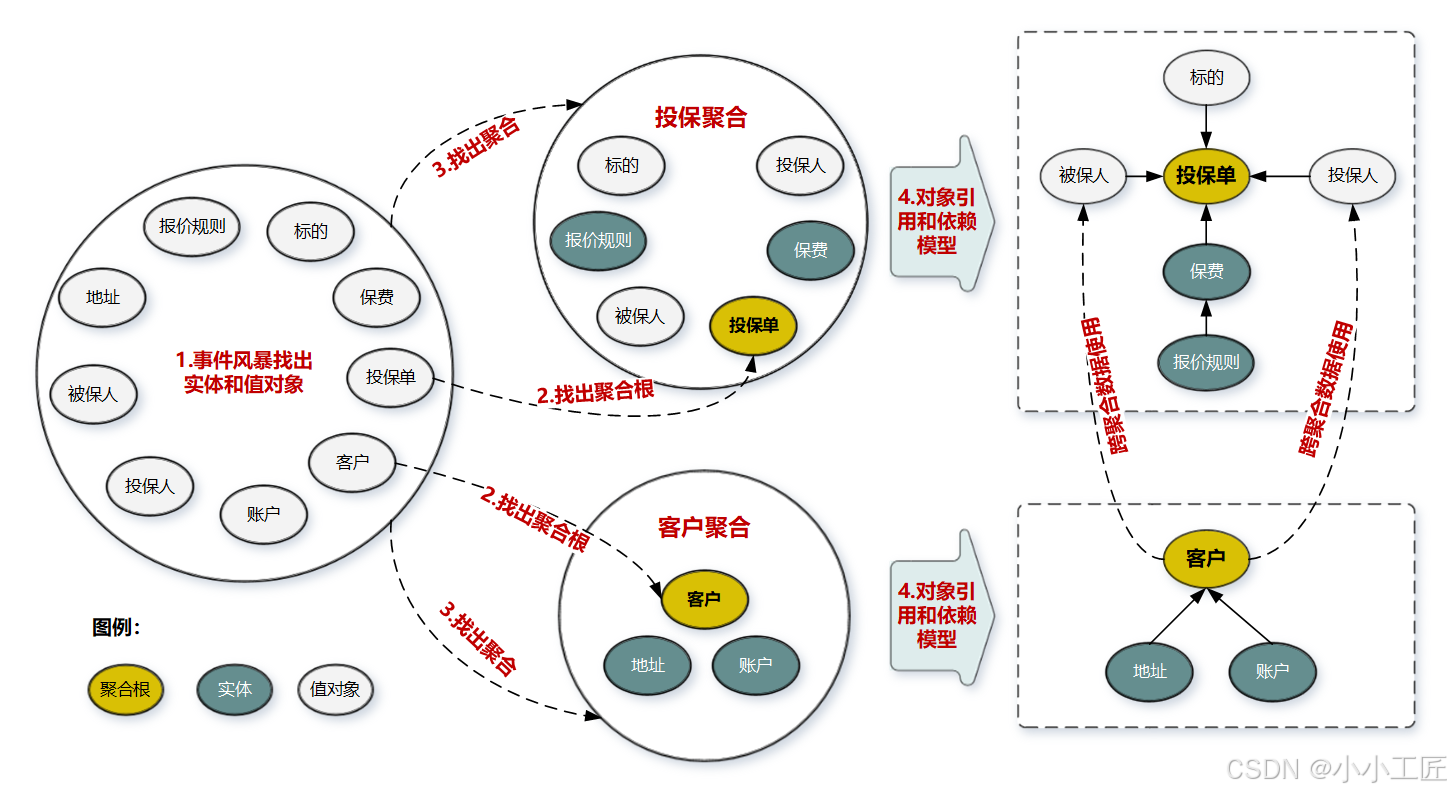
聚合是领域驱动设计中一项非常重要的设计与概念,它表达的是真实世界中那些整体与部分的关系,比如订单与订单明细、表单与表单明细、发票与发票明细。
以订单为例,在真实世界中,订单与订单明细本来是同一个事物,订单明细是订单中的一个属性。但是,由于在关系型数据库中没有办法在一个字段中表达一对多的关系,因此必须将订单明细设计成另外一张表。
尽管如此,在领域模型的设计中,我们又将其还原到真实世界中,以“聚合”的形式进行设计。在领域模型中,即将订单明细设计成订单中的一个属性,具体代码如下:
public class Order {
private Set<Items> items;
public void setItems(Set<Item> items){
this.items = items;
}
public Set<Item> getItems(){
return this.items;
}
……
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
有了这样的设计,
- 在创建订单的时候,将不再单独创建订单明细了,而是将订单明细创建在订单中;
- 在保存订单的时候,应当同时保存订单表与订单明细表,并放在同一事务中;
- 在查询订单时,应当同时查询订单表与订单明细表,并将其装配成一个订单对象。

这时候,订单就作为一个整体在进行操作,不需要再单独去操作订单明细。
也就是说,对订单明细的操作是封装在订单对象内部的设计实现。对于客户程序来说,去使用订单对象就好了,这就包括了作为属性去访问订单对象中的订单明细,而不再需要关注它内部是如何操作的。
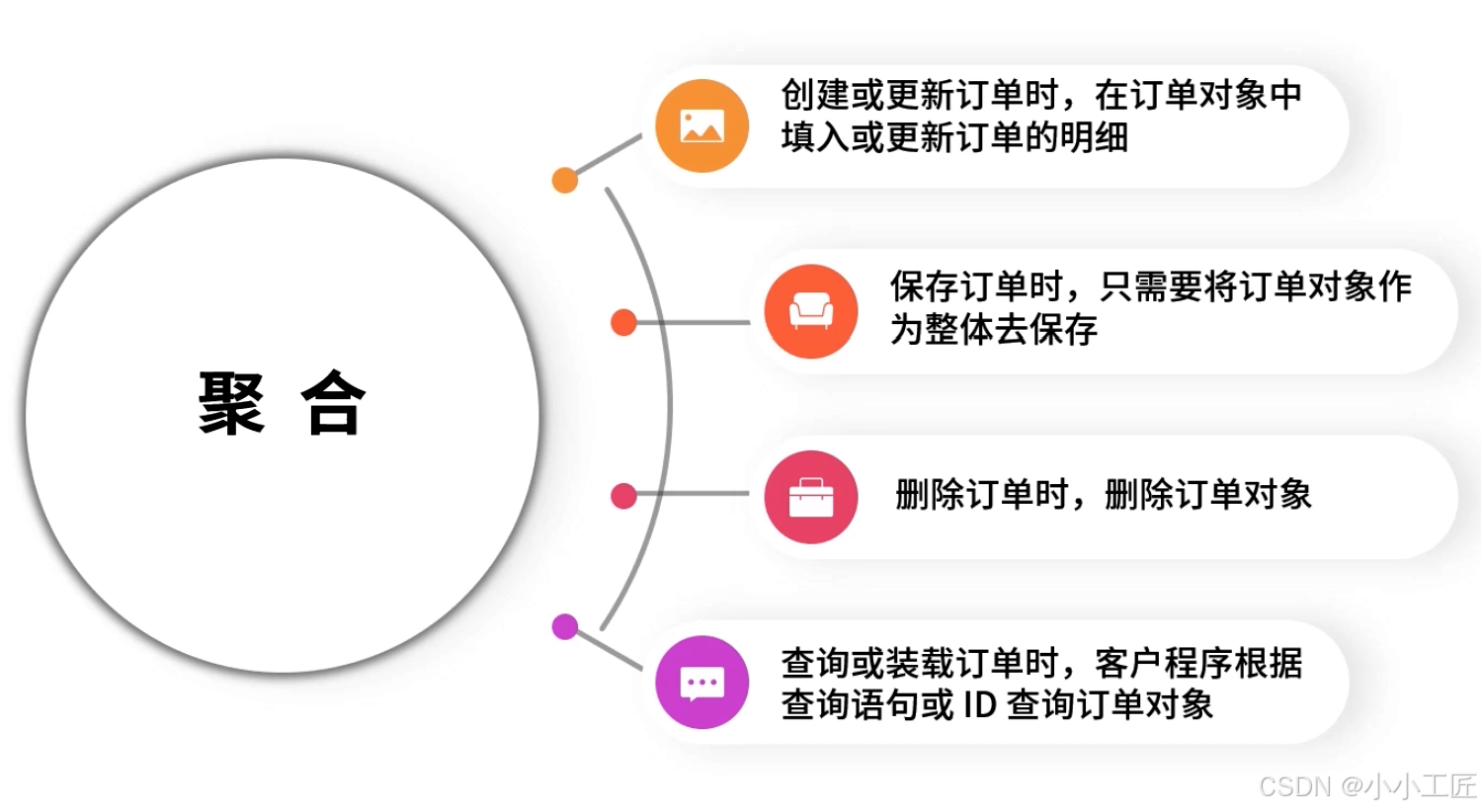
按照以下思路进行的设计就是聚合:
-
当创建或更新订单时,在订单对象中填入或更新订单的明细就好了;
-
当保存订单时,只需要将订单对象作为整体去保存,而不需要关心订单数据是怎么保存的、保存到哪几张表中、是不是有事务,保存数据库的所有细节都封装在了订单对象内部;
-
当删除订单时,删除订单对象就好了,至于如何删除订单明细,是订单对象内部的实现,外部的程序不需要关注;
-
当查询或装载订单时,客户程序只需要根据查询语句或 ID 查询订单对象就好了,查询程序会在查询过程中自动地去补填订单对应的订单明细。
聚合体现的是一种整体与部分的关系。正是因为有这样的关系,在操作整体的时候,整体就封装了对部分的操作。但并非所有对象间的关系都有整体与部分的关系,而那些不是整体与部分的关系是不能设计成聚合的。因此,正确地识别聚合关系就变得尤为重要。
所谓的整体与部分的关系,就是当整体不存在时,部分就变得没有了意义。部分是整体的一个部分,与整体有相同的生命周期。比如,只有创建了这张订单,才能创建它的订单明细;如果没有了这张订单,那么它的订单明细就变得没有意义,就需要同时删除掉。这样的关系才具备整体与部分的关系,才是聚合。
譬如:订单与用户之间的关系就不是聚合。因为用户不是创建订单时才存在的,而是在创建订单时早就存在了;当删除订单时,用户不会随着订单的删除而删除,因为删除了订单,用户依然还是那个用户。
那么,饭店和菜单的关系是不是聚合关系呢?关键要看系统如何设计。如果系统设计成每个饭店都有各不相同的菜单,每个菜单都是隶属于某个饭店,则饭店和菜单是聚合关系。这种设计让各个饭店都有“宫保鸡丁”,但每个饭店都是各自不同的“宫保鸡丁”,比如在描述、图片或价格上的不同,甚至在数据库中也是有各不相同的记录。这时,要查询菜单就要先查询饭店,离开了饭店的菜单是没有意义的。
但是,饭店和菜单还可以有另外一种设计思路,那就是所有的菜单都是公用的,去每个饭店只是选择有还是没有这个菜品。这时,系统中有一个菜单对象,“宫保鸡丁”只是这个对象中的一条记录,其他各个饭店,如果他们的菜单上有“宫保鸡丁”,则去引用这个对象,否则不引用。这时,菜单就不再是饭店的一个部分,没有这个饭店,这个菜品依然存在,就不再是聚合关系。
因此,判断聚合关系最有效的方法就是去探讨:如果整体不存在时,部分是否存在。如果不存在,就是聚合;反之,则不是。
聚合根——外部访问的唯一入口
聚合根的主要目的是为了避免由于复杂数据模型缺少统一的业务规则控制,而导致聚合、实体之间数据不一致性的问题。传统数据模型中的每一个实体都是对等的,如果任由实体进行无控制地调用和数据修改,很可能会导致实体之间数据逻辑的不一致。而如果采用锁的方式则会增加软件的复杂度,也会降低系统的性能。
如果把聚合比作组织,那聚合根就是这个组织的负责人。聚合根也称为根实体,它不仅是实体,还是聚合的管理者。
-
首先它作为实体本身,拥有实体的属性和业务行为,实现自身的业务逻辑。
-
其次它作为聚合的管理者,在聚合内部负责协调实体和值对象按照固定的业务规则协同完成共同的业务逻辑。
-
最后在聚合之间,它还是聚合对外的接口人,以聚合根 ID 关联的方式接受外部任务和请求,在上下文内实现聚合之间的业务协同。也就是说,聚合之间通过聚合根 ID 关联引用,如果需要访问其它聚合的实体,就要先访问聚合根,再导航到聚合内部实体,外部对象不能直接访问聚合内实体。
有了聚合关系,部分就会被封装在整体里面,这时就会形成一种约束,即外部程序不能跳过整体去操作部分,对部分的操作都必须要通过整体。这时,整体就成了外部访问的唯一入口,被称为 “聚合根”。
也就是说,一旦将对象间的关系设计成了聚合,那么外部程序只能访问聚合根,而不能访问聚合中的其他对象。这样带来的好处就是,当聚合内部的业务逻辑发生变更时,只与聚合内部有关,只需要对聚合内部进行更新,与外部程序无关,从而有效降低了变更的维护成本,提高了系统的设计质量。
然而,这样的设计有时是有效的,但并非都有效。譬如,在管理订单时,对订单进行增删改,聚合是有效的。但是,如果要统计销量、分析销售趋势、销售占比时,则需要对大量的订单明细进行汇总、进行统计;如果每次对订单明细的汇总与统计都必须经过订单的查询,必然使得查询统计变得效率极低而无法使用。
因此,领域驱动设计通常适用于增删改的业务操作,但不适用于分析统计。在一个系统中,增删改的业务可以采用领域驱动的设计,但在非增删改的分析汇总场景中,则不必采用领域驱动的设计,直接 SQL 查询就好了,也就不必再遵循聚合的约束了。

聚合的设计实现
前面谈到了领域驱动设计中一个非常重要的概念:聚合。通过聚合的设计,可以真实地反映现实世界的状况,提高软件设计的质量,有效降低日后变更的成本。然而,前面只提出了聚合的概念,要想真正将聚合落实到软件设计中,还需要两个非常重要的组件:仓库与工厂。

比如,现在创建了一个订单,订单中包含了多条订单明细,并将它们做成了一个聚合。这时,当订单完成了创建,就需要保存到数据库里,怎么保存呢?需要同时保存订单表与订单明细表,并将其做到一个事务中。这时候谁来负责保存,并对其添加事务呢?

过去我们采用贫血模型,那就是通过订单 DAO 与订单明细 DAO 去完成数据库的保存,然后由订单 Service 去添加事务。这样的设计没有聚合、缺乏封装性,不利于日后的维护。那么,采用聚合的设计应当是什么样呢?
实现一个仓库(Repository) 去完成对数据库的访问
采用了聚合以后,订单与订单明细的保存就会封装在订单仓库中去实现。也就是说采用了领域驱动设计以后,通常就会实现一个仓库(Repository) 去完成对数据库的访问。那么,仓库与数据访问层(DAO)有什么区别呢?
仓库 vs 数据访问层(DAO)
一般来说,数据访问层就是对数据库中某个表的访问,比如订单有订单 DAO、订单明细有订单明细 DAO、用户有用户 DAO。
-
当数据要保存到数据库中时,由 DAO 负责保存,但保存的是某个单表,如订单 DAO 保存订单表、订单明细 DAO 保存订单明细表、用户 DAO 保存用户表;
-
当数据要查询时,还是通过 DAO 去查询,但查询的也是某个单表,如订单 DAO 查订单表、订单明细 DAO 查订单明细表。
那么,如果在查询订单的时候要显示用户名称,怎么办呢?做另一个订单对象,并在该对象里增加“用户名称”。这样,通过订单 DAO 查订单表时,在 SQL 语句中 Join 用户表,就可以完成数据的查询。
这时会发现,在系统中非常别扭地设计了两个或多个订单对象,并且新添加的订单对象与领域模型中的订单对象有较大的差别,显得不够直观。系统简单时还好说,但系统的业务逻辑变得越来越复杂时,程序阅读起来越来越困难,变更就变得越来越麻烦。
因此,在应对复杂业务系统时,我们希望程序设计能较好地与领域模型对应上:领域模型是啥样,程序就设计成啥样。我们就将订单对象设计成这样,订单对象的关联设计代码如下:
public class Order {
......
private Long customer_id;
private Customer customer;
private List<OrderItem> orderItems;
/**
* @return the customerId
*/
public Long getCustomerId() {
return customer_id;
}
/**
* @param customerId the customerId to set
*/
public void setCustomerId(Long customerId) {
this.customer_id = customerId;
}
/**
* @return the customer
*/
public Customer getCustomer() {
return customer;
}
/**
* @param customer the customer to set
*/
public void setCustomer(Customer customer) {
this.customer = customer;
}
/**
* @return the orderItems
*/
public List<OrderItem> getOrderItems() {
return orderItems;
}
/**
* @param orderItems the orderItems to set
*/
public void setOrderItems(List<OrderItem> orderItems) {
this.orderItems = orderItems;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42

可以看到,在订单对象中加入了对用户对象和订单明细对象的引用:
-
订单对象与用户对象是多对一关系,做成对象引用;
-
订单对象与订单明细对象是一对多关系,做成对集合对象的引用。
这样,当订单对象在创建时,在该对象中填入 customerId,以及它对应的订单明细集合 orderItems;然后交给订单仓库去保存,在保存时,就进行了一个封装,同时保存订单表与订单明细表,并在其上添加了一个事务。
这里要特别注意,对象间的关系是否是聚合关系,它们在保存的时候是有差别的。譬如,在本案例中,
- 订单与订单明细是聚合关系,因此在保存订单时还要保存订单明细,并放到同一事务中;
- 然而,订单与用户不是聚合关系,那在保存订单时不会去操作用户表,只有在查询时,比如在查询订单的同时,才要查询与该订单对应的用户。
这是一个比较复杂的保存过程。然而,通过订单仓库的封装,对于客户程序来说不需要关心它是怎么保存的,它只需要在领域对象建模的时候设定对象间的关系,即将其设定为“聚合”就可以了。既保持了与领域模型的一致性、又简化了开发,使得日后的变更与维护变得简单。至于仓库的设计实现,将在后面讲解。
有了这样的设计,装载与查询又应当怎样去做呢?所谓的 “装载(Load)”,就是通过主键 ID 去查询某条记录。比如,要装载一个订单,就是通过订单 ID 去查询该订单,那么订单仓库是如何实现对订单的装载呢?
首先,比较容易想到的是,用 SQL 语句到数据库里去查询这张订单。与 DAO 不同的是:
-
订单仓库在查询订单时,只是简单地查询订单表,不会去 Join 其他表,比如 Join 用户表,不会做这些事情;
-
当查询到该订单以后,将其封装在订单对象中,然后再去通过查询补填用户对象、订单明细对象;
-
通过补填以后,就会得到一个用户对象、多个订单明细对象,需要将它们装配到订单对象中。

这时,那些创建、装配的工作都交给了另外一个组件——工厂来完成。
DDD 的工厂
DDD 中的工厂,与设计模式中的工厂不是同一个概念,它们是有差别的。在设计模式中,为了避免调用方与被调方的依赖,将被调方设计成一个接口下的多个实现,将这些实现放入工厂中。这样,调用方通过一个 key 值就可以从工厂中获得某个实现类。工厂就负责通过 key 值找到对应的实现类,创建出来,返回给调用方,从而降低了调用方与被调方的耦合度。
而 DDD 中的工厂,与设计模式中的工厂唯一的共同点可能就是,它们都要去做创建对象的工作。
DDD 中的工厂,主要的工作是通过装配,创建领域对象,是领域对象生命周期的起点。譬如,系统要通过 ID 装载一个订单:
-
这时订单仓库会将这个任务交给订单工厂,订单工厂就会分别调用订单 DAO、订单明细 DAO 和用户 DAO 去进行查询;
-
然后将得到的订单对象、订单明细对象、用户对象进行装配,即将订单明细对象与用户对象,分别 set 到订单对象的“订单明细”与“用户”属性中;
-
最后,订单工厂将装配好的订单对象返回给订单仓库。

这些就是 DDD 中工厂要做的事情。
DDD 的仓库
然而,当订单工厂将订单对象返回给订单仓库以后,订单仓库不是简单地将该对象返回给客户程序,它还有一个缓存的功能。在DDD 中“仓库”的概念,就是如果服务器是一个非常强大的服务器,那么我们不需要任何数据库。系统创建的所有领域对象都放在仓库中,当需要这些对象时,通过 ID 到仓库中去获取。
但是,在现实中没有那么强大的仓库,因此仓库在内部实现时,会将领域对象持久化到数据库中。数据库是仓库进行数据持久化的一种内部实现,它也可以有另外一种内部实现,就是将最近反复使用的领域对象放入缓存中。
通过 ID 去获取某个领域对象
这样,当客户程序通过 ID 去获取某个领域对象时,仓库会通过这个 ID 先到缓存中进行查找:
-
查找到了,则直接返回,不需要查询数据库;
- 没有找到,则通知工厂,工厂调用 DAO 去数据库中查询,然后装配成领域对象返回给仓库。

仓库在收到这个领域对象以后,在返回给客户程序的同时,将该对象放到缓存中。以上是通过 ID 装载订单的过程.
通过某些条件查询
那么通过某些条件查询订单的过程又是怎么做呢?查询订单的操作同样是交给订单仓库去完成。
-
订单仓库会先通过订单 DAO 去查询订单表,但这里是只查询订单表,不做 Join 操作;
-
订单 DAO 查询了订单表以后,会进行一个分页,将某一页的数据返回给订单仓库;

这时,订单仓库就会将查询结果交给订单工厂,让它去补填其对应的用户与订单明细,完成相应的装配,最终将装配好的订单对象集合返回给仓库。
简而言之,采用领域驱动的设计以后,对数据库的访问就不是一个简单的 DAO 了,这不是一种好的设计。通过仓库与工厂,对原有的 DAO 进行了一层封装,在保存、装载、查询等操作中,加入聚合、装配等操作。并将这些操作封装起来,对上层的客户程序屏蔽。这样,客户程序不需要以上这些操作,就能完成领域模型中的各自业务。技术门槛降低了,变更与维护也变得简便了。
Code
下面用一个简单的Java代码示例,展示了如何使用领域驱动设计(DDD)中的聚合、仓库和工厂来实现订单和订单明细的管理, 模拟了订单的创建、保存、查询等操作。
1. 领域模型
订单(Order)和订单明细(OrderItem)
import java.util.List;
public class Order {
private Long id;
private Long customerId;
private Customer customer;
private List<OrderItem> orderItems;
// Getters and Setters
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public Long getCustomerId() {
return customerId;
}
public void setCustomerId(Long customerId) {
this.customerId = customerId;
}
public Customer getCustomer() {
return customer;
}
public void setCustomer(Customer customer) {
this.customer = customer;
}
public List<OrderItem> getOrderItems() {
return orderItems;
}
public void setOrderItems(List<OrderItem> orderItems) {
this.orderItems = orderItems;
}
}
public class OrderItem {
private Long id;
private Long orderId;
private String productName;
private int quantity;
// Getters and Setters
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public Long getOrderId() {
return orderId;
}
public void setOrderId(Long orderId) {
this.orderId = orderId;
}
public String getProductName() {
return productName;
}
public void setProductName(String productName) {
this.productName = productName;
}
public int getQuantity() {
return quantity;
}
public void setQuantity(int quantity) {
this.quantity = quantity;
}
}
public class Customer {
private Long id;
private String name;
// Getters and Setters
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
2. 仓库(Repository)
订单仓库(OrderRepository)
import java.util.List;
public interface OrderRepository {
void save(Order order);
Order findById(Long id);
List<Order> findByCustomerId(Long customerId);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
订单仓库实现(OrderRepositoryImpl)
import java.util.ArrayList;
import java.util.List;
public class OrderRepositoryImpl implements OrderRepository {
private OrderFactory orderFactory;
public OrderRepositoryImpl(OrderFactory orderFactory) {
this.orderFactory = orderFactory;
}
@Override
public void save(Order order) {
// Save order to database
// Save order items to database
// Ensure both operations are in the same transaction
System.out.println("Order saved: " + order.getId());
}
@Override
public Order findById(Long id) {
// Fetch order from database
Order order = new Order();
order.setId(id);
order.setCustomerId(1L); // Example customer ID
// Use factory to fill customer and order items
order = orderFactory.createOrder(order);
return order;
}
@Override
public List<Order> findByCustomerId(Long customerId) {
// Fetch orders from database by customer ID
List<Order> orders = new ArrayList<>();
Order order = new Order();
order.setId(1L);
order.setCustomerId(customerId);
// Use factory to fill customer and order items
order = orderFactory.createOrder(order);
orders.add(order);
return orders;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
3. 工厂(Factory)
订单工厂(OrderFactory)
import java.util.Arrays;
public class OrderFactory {
public Order createOrder(Order order) {
// Fetch customer from database
Customer customer = new Customer();
customer.setId(order.getCustomerId());
customer.setName("John Doe"); // Example customer name
order.setCustomer(customer);
// Fetch order items from database
OrderItem item1 = new OrderItem();
item1.setId(1L);
item1.setOrderId(order.getId());
item1.setProductName("Product A");
item1.setQuantity(2);
OrderItem item2 = new OrderItem();
item2.setId(2L);
item2.setOrderId(order.getId());
item2.setProductName("Product B");
item2.setQuantity(1);
order.setOrderItems(Arrays.asList(item1, item2));
return order;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
4. 服务层(Service)
订单服务(OrderService)
public class OrderService {
private OrderRepository orderRepository;
public OrderService(OrderRepository orderRepository) {
this.orderRepository = orderRepository;
}
public void createOrder(Order order) {
orderRepository.save(order);
}
public Order getOrderById(Long id) {
return orderRepository.findById(id);
}
public List<Order> getOrdersByCustomerId(Long customerId) {
return orderRepository.findByCustomerId(customerId);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
5. 主程序
public class Main {
public static void main(String[] args) {
OrderFactory orderFactory = new OrderFactory();
OrderRepository orderRepository = new OrderRepositoryImpl(orderFactory);
OrderService orderService = new OrderService(orderRepository);
// Create a new order
Order order = new Order();
order.setId(1L);
order.setCustomerId(1L);
orderService.createOrder(order);
// Fetch order by ID
Order fetchedOrder = orderService.getOrderById(1L);
System.out.println("Fetched Order: " + fetchedOrder.getId());
// Fetch orders by customer ID
List<Order> orders = orderService.getOrdersByCustomerId(1L);
System.out.println("Orders for customer: " + orders.size());
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
6. 运行结果
Order saved: 1
Fetched Order: 1
Orders for customer: 1
- 1
- 2
- 3
总结
DDD 中一个非常重要的设计思想:聚合,以及它的设计实现:工厂与仓库,它们是 DDD 中充血模型设计的重要支柱。通过这些设计我们会发现,它们与我们传统的基于 DAO 的贫血模型设计有诸多的不同。
-
通过聚合实现了整体与部分的关系,客户程序只能操作整体,而将对部分的操作封装在了仓库与工厂中;
-
客户程序不必关注对数据库的操作,操作仓库就好了。对缓存、对数据库的操作都封装在了仓库与工厂中,从而降低了业务开发的技术门槛与开发工作量;
-
对数据的查询不再通过 SQL 语句进行 Join,而是通过工厂进行补填与装配。这样的设计更有利于微服务的设计与大数据的调优。

它们为软件系统提高设计质量、降低维护成本以及应对高并发,提供了很好的设计。
另外,一个值得思考的问题就是,传统的领域驱动设计,是每个模块自己去实现各自的仓库与工厂,这样会大大增加开发工作量。但这些仓库与工厂的设计大致都是相同的,会催生大量的重复代码。能不能通过抽象,提取出共性,形成通用的仓库与工厂,下沉到底层技术中台中,从而进一步降低领域驱动的开发成本与技术门槛?也就是说,实现领域驱动设计还需要相应的平台架构支持。

评论记录:
回复评论: