
在复杂场景中实现抓取检测,Graspness是一种端到端的方法;
输入点云数据,输出抓取角度、抓取深度、夹具宽度等信息。
开源地址:https://github.com/rhett-chen/graspness_implementation?tab=readme-ov-file
论文地址:Graspness Discovery in Clutters for Fast and Accurate Grasp Detection
目录
1、准备GPU加速环境
推荐在Conda环境中搭建环境,方便不同项目的管理~
首先需要安装好Nvidia 显卡驱动,后面还要安装CUDA11.1
输入命令:nvidia-smi,能看到显卡信息,说明Nvidia 显卡驱动安装好了
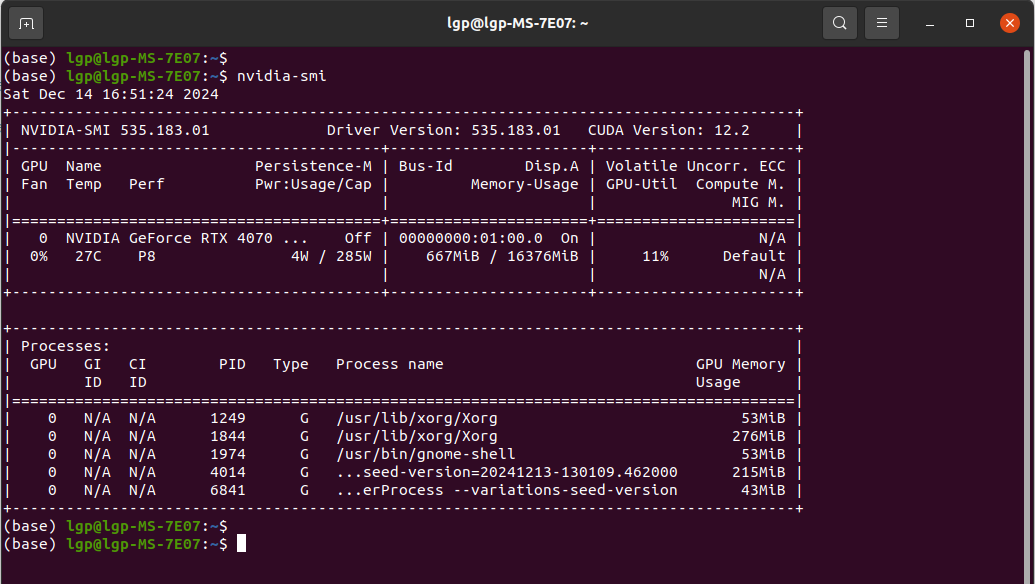
然后需要单独安装CUDA11.1了,上面虽然安装了CUDA12.2也不影响的
各种CUDA版本:https://developer.nvidia.com/cuda-toolkit-archive
CUDA11.1下载地址:https://developer.nvidia.com/cuda-11.1.0-download-archive
然后根据电脑的系统(Linux)、CPU类型,选择runfile方式
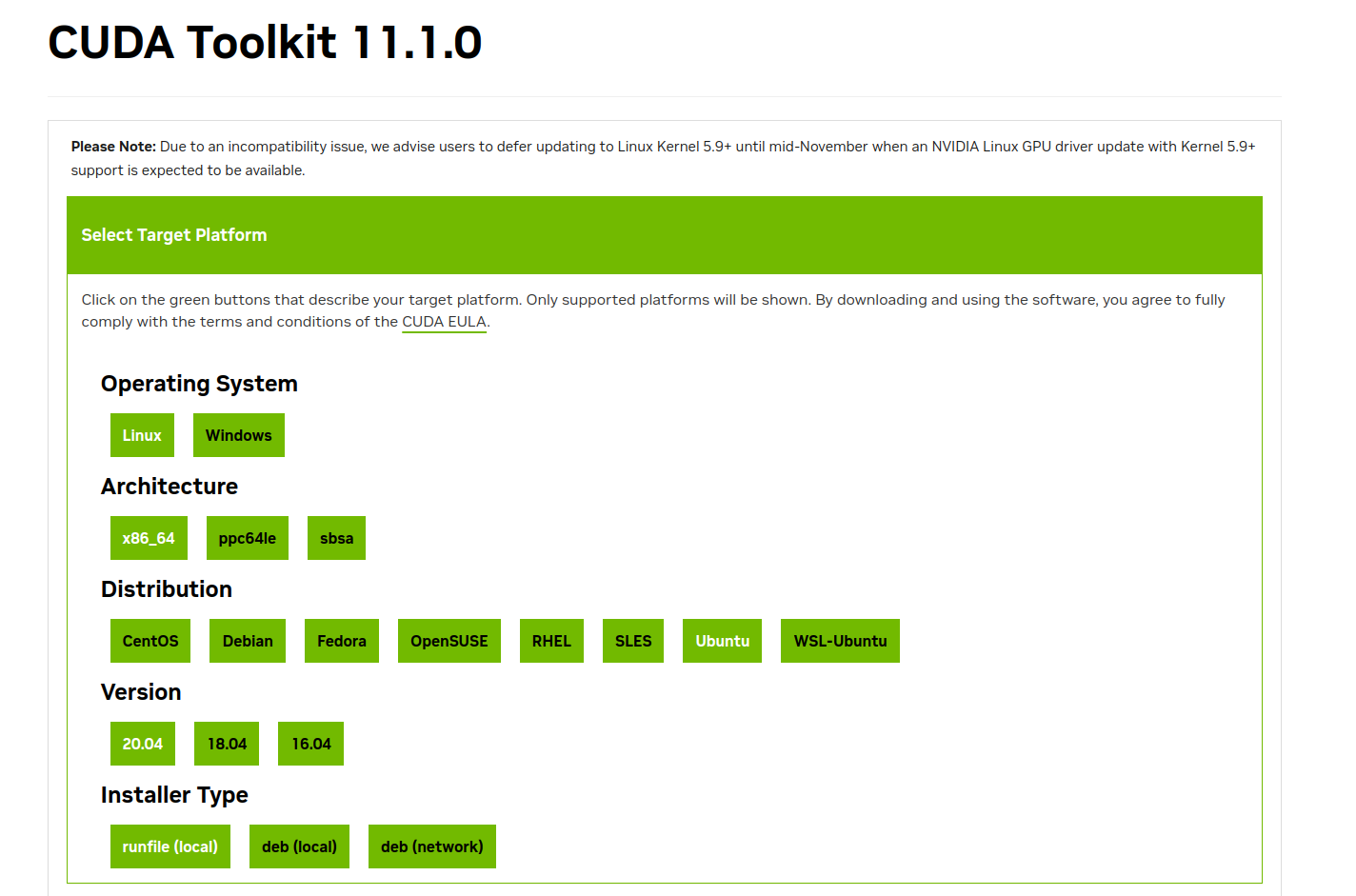
然后下载cuda_11.1.0_455.23.05_linux.run文件
wget https://developer.download.nvidia.com/compute/cuda/11.1.0/local_installers/cuda_11.1.0_455.23.05_linux.run开始安装
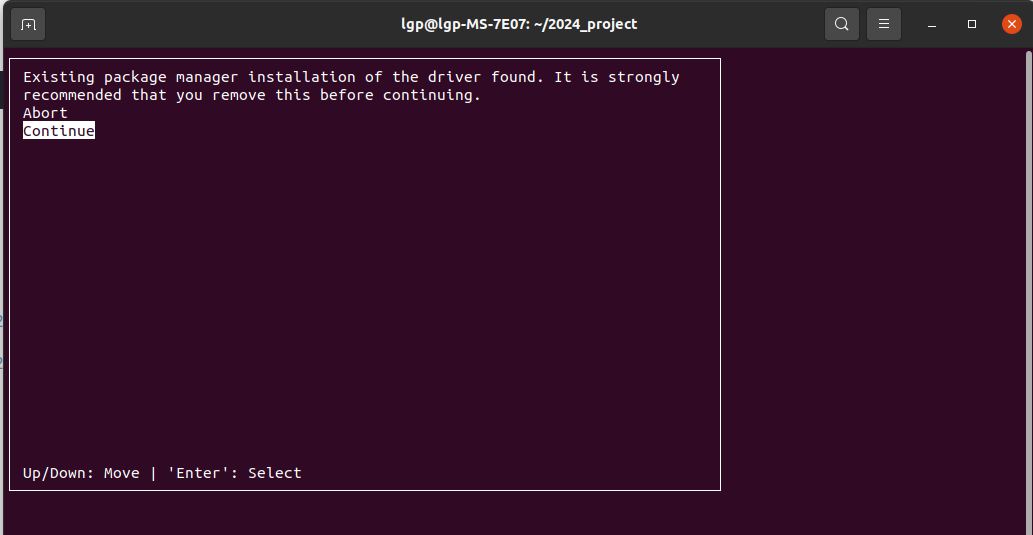
sudo sh cuda_11.1.0_455.23.05_linux.run来到下面的界面,点击“Continue”
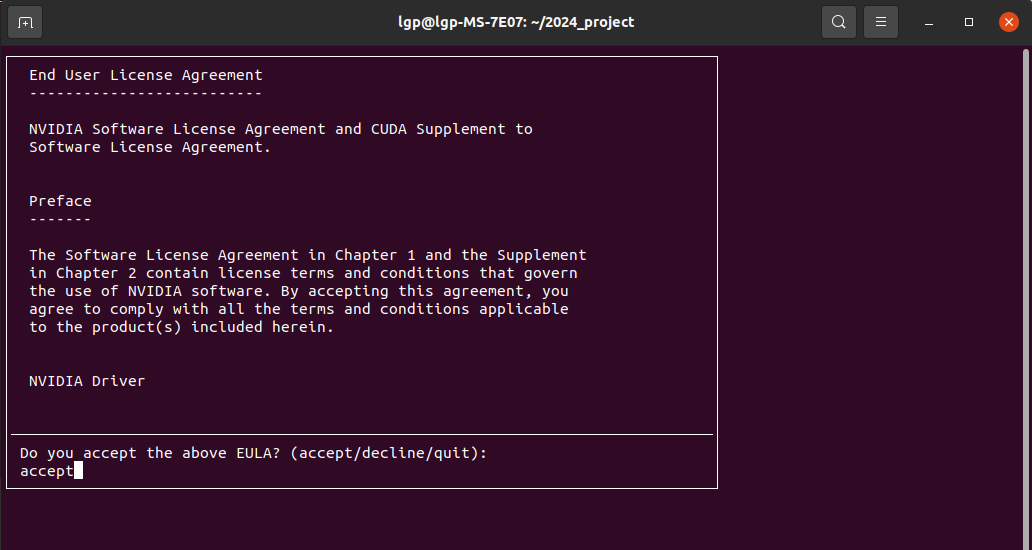
输入“accept”
下面是关键,在455.23.05这里“回车”,取消安装;
这里X是表示需要安装的,我们只需安装CUDA11相关的即可
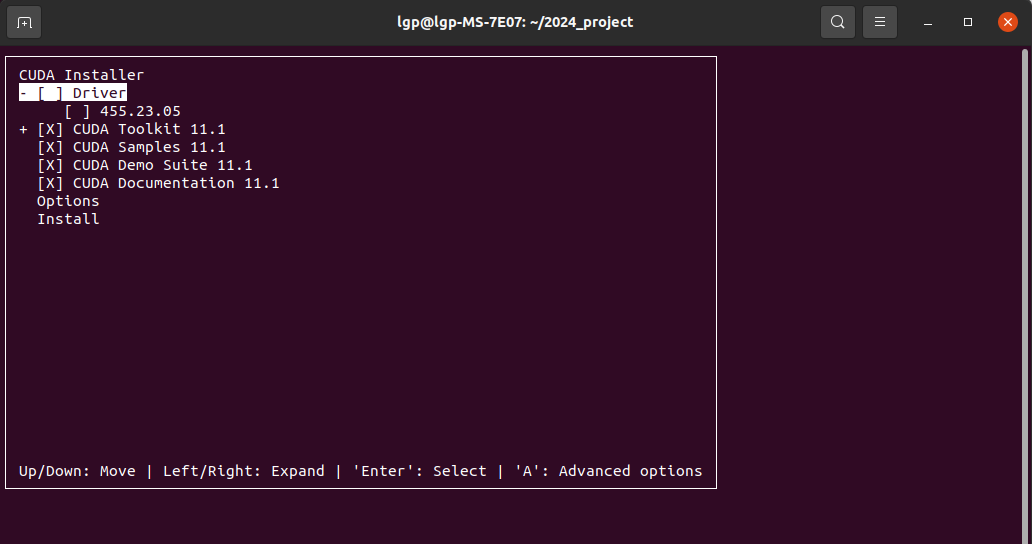
安装完成后,能看到/usr/local/cuda-11.1目录啦
- (base) lgp@lgp-MS-7E07:~/2024_project$ ls /usr/local/cuda-11.1
- bin EULA.txt libnvvp nsight-systems-2020.3.4 nvvm samples targets
- DOCS extras nsight-compute-2020.2.0 nvml README src tools
参考1:https://blog.csdn.net/weixin_37926734/article/details/123033286
参考2:https://blog.csdn.net/weixin_49223002/article/details/120509776
2、安装torch和cudatoolkit
首先创建一个Conda环境,名字为graspness,python版本为3.8
然后进行graspness环境
- conda create -n graspness python=3.8
- conda activate graspness
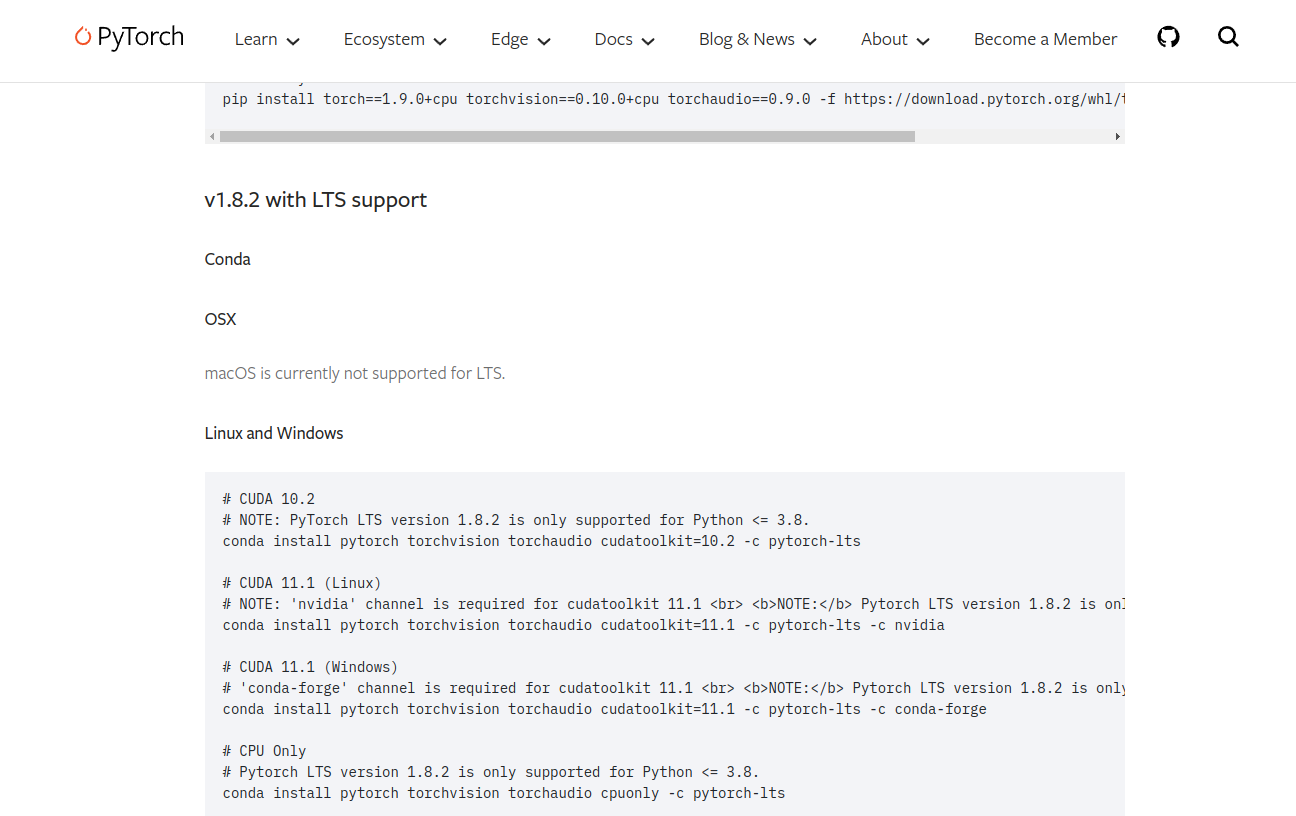
这里需要安装pytorch1.8.2,cudatoolkit=11.1
conda install pytorch torchvision torchaudio cudatoolkit=11.1 -c pytorch-lts -c nvidiapytorch1.8.2官网地址:https://pytorch.org/get-started/previous-versions/
3、安装Graspness相关依赖库
下载graspness代码
- git clone https://github.com/rhett-chen/graspness_implementation.git
- cd graspnet-graspness
编辑 requirements.txt,注释torch和MinkowskiEngine
- # pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
- # torch>=1.8
- tensorboard==2.3
- numpy==1.23.5
- scipy
- open3d>=0.8
- Pillow
- tqdm
- # MinkowskiEngine==0.5.4
开始安装Graspness相关依赖库
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple4、安装MinkowskiEngine
在安装MinkowskiEngine之前,需要先安装相关的依赖
pip install ninja -i https://pypi.tuna.tsinghua.edu.cn/simpleconda install openblas-devel -c anaconda然后本地安装的流程:
- export CUDA_HOME=/usr/local/cuda-11.1 # 指定CUDA_HOME为cuda-11.1
- export MAX_JOBS=2 # 降低占用CPU的核心数目,避免卡死(可选)
- git clone https://github.com/NVIDIA/MinkowskiEngine.git
- cd MinkowskiEngine
- python setup.py install --blas_include_dirs=${CONDA_PREFIX}/include --blas=openblas
等待安装完成
5、安装pointnet2和knn
这些两个的安装需要CUDA编译的,依赖于前面的export CUDA_HOME=/usr/local/cuda-11.1
首先来到graspnet-graspness工程中,安装pointnet2
- cd pointnet2
- python setup.py install
再安装knn
- cd knn
- python setup.py install
6、安装graspnetAPI
这里安装的流程如下,逐条命令执行
- git clone https://github.com/graspnet/graspnetAPI.git
- cd graspnetAPI
- pip install . -i https://pypi.tuna.tsinghua.edu.cn/simple
成功安装后,需要再安装numpy==1.23.5
pip install numpy==1.23.5 -i https://pypi.tuna.tsinghua.edu.cn/simple到这里安装完成啦~
7、模型推理——抓取点估计
跑一下模型推理的demo,看看可视化的效果:

2024.12.17 更新~
这里分享一下模型推理和可视化的代码
- import os
- import sys
- import numpy as np
- import argparse
- from PIL import Image
- import time
- import scipy.io as scio
- import torch
- import open3d as o3d
- from graspnetAPI.graspnet_eval import GraspGroup
-
- ROOT_DIR = os.path.dirname(os.path.abspath(__file__))
- sys.path.append(ROOT_DIR)
- sys.path.append(os.path.join(ROOT_DIR, 'utils'))
- from models.graspnet import GraspNet, pred_decode
- from dataset.graspnet_dataset import minkowski_collate_fn
- from collision_detector import ModelFreeCollisionDetector
- from data_utils import CameraInfo, create_point_cloud_from_depth_image, get_workspace_mask
-
- # 参数解析器
- parser = argparse.ArgumentParser()
- parser.add_argument('--dataset_root', default='/home/lgp/2024_project/datasets/test_seen/', help='数据集根目录路径')
- parser.add_argument('--checkpoint_path', default='logs/log_kn/minkuresunet_kinect.tar', help='模型权重文件路径')
- parser.add_argument('--dump_dir', help='输出结果保存目录', default='logs/infer/')
- parser.add_argument('--seed_feat_dim', default=512, type=int, help='每个点的特征维度')
- parser.add_argument('--camera', default='kinect', help='摄像头类型 [realsense/kinect]')
- parser.add_argument('--num_point', type=int, default=50000, help='点云采样点数 [默认: 15000]')
- parser.add_argument('--batch_size', type=int, default=1, help='推理时的批大小 [默认: 1]')
- parser.add_argument('--voxel_size', type=float, default=0.005, help='稀疏卷积的体素大小[默认: 0.005]')
- parser.add_argument('--collision_thresh', type=float, default=0.06,help='碰撞检测阈值 [默认: 0.01], -1表示不进行碰撞检测')
- parser.add_argument('--voxel_size_cd', type=float, default=0.01, help='碰撞检测时体素大小[默认: 0.01]')
- parser.add_argument('--infer', action='store_true', default=True, help='是否进行推理')
- parser.add_argument('--vis', action='store_true', default=True, help='是否进行可视化')
- parser.add_argument('--scene', type=str, default='0102', help='场景ID')
- parser.add_argument('--index', type=str, default='0000', help='深度图索引')
- cfgs = parser.parse_args()
-
- # 如果输出目录不存在则创建
- if not os.path.exists(cfgs.dump_dir):
- os.mkdir(cfgs.dump_dir)
-
-
- def data_process():
- # 根据用户输入构造场景ID和索引
- root = cfgs.dataset_root
- camera_type = cfgs.camera
-
- depth_path = os.path.join(root, 'scenes', scene_id, camera_type, 'depth', index + '.png')
- seg_path = os.path.join(root, 'scenes', scene_id, camera_type, 'label', index + '.png')
- meta_path = os.path.join(root, 'scenes', scene_id, camera_type, 'meta', index + '.mat')
-
- # 新增:RGB图像路径
- rgb_path = os.path.join(root, 'scenes', scene_id, camera_type, 'rgb', index + '.png')
-
- # 加载深度图、语义分割图和RGB图像
- depth = np.array(Image.open(depth_path))
- seg = np.array(Image.open(seg_path))
- rgb = np.array(Image.open(rgb_path)) # 形状通常为(H, W, 3)
-
- # 加载相机内参和深度因子
- meta = scio.loadmat(meta_path)
- intrinsic = meta['intrinsic_matrix']
- factor_depth = meta['factor_depth']
-
- # 构造相机参数对象
- camera = CameraInfo(1280.0, 720.0, intrinsic[0][0], intrinsic[1][1], intrinsic[0][2], intrinsic[1][2],factor_depth)
-
- # 利用深度图生成点云 (H,W,3) 并保留组织结构
- cloud = create_point_cloud_from_depth_image(depth, camera, organized=True)
-
- # 创建有效深度掩码
- depth_mask = (depth > 0)
-
- # 加载相机位姿和对齐矩阵,用于获取工作空间mask
- camera_poses = np.load(os.path.join(root, 'scenes', scene_id, camera_type, 'camera_poses.npy'))
- align_mat = np.load(os.path.join(root, 'scenes', scene_id, camera_type, 'cam0_wrt_table.npy'))
- trans = np.dot(align_mat, camera_poses[int(index)])
- workspace_mask = get_workspace_mask(cloud, seg, trans=trans, organized=True, outlier=0.02)
-
- # 最终有效点的mask
- mask = (depth_mask & workspace_mask)
-
- # 根据mask过滤点云和对应的RGB颜色
- cloud_masked = cloud[mask] # (N,3)
- rgb_masked = rgb[mask] # (N,3)
-
- # 随机下采样点云至指定数量
- if len(cloud_masked) >= cfgs.num_point:
- idxs = np.random.choice(len(cloud_masked), cfgs.num_point, replace=False)
- else:
- # 如果点不够则有放回采样
- idxs1 = np.arange(len(cloud_masked))
- idxs2 = np.random.choice(len(cloud_masked), cfgs.num_point - len(cloud_masked), replace=True)
- idxs = np.concatenate([idxs1, idxs2], axis=0)
-
- cloud_sampled = cloud_masked[idxs] # (num_point, 3)
- rgb_sampled = rgb_masked[idxs] # (num_point, 3)
-
- # 返回包含点云、坐标、特征和颜色的字典
- ret_dict = {
- 'point_clouds': cloud_sampled.astype(np.float32),
- 'coors': (cloud_sampled / cfgs.voxel_size).astype(np.float32),
- 'feats': np.ones_like(cloud_sampled).astype(np.float32),
- 'colors': (rgb_sampled / 255.0).astype(np.float32) # 将RGB归一化到[0,1]
- }
- return ret_dict
-
-
- def my_worker_init_fn(worker_id):
- # 初始化worker随机种子(如果需要)
- np.random.seed(np.random.get_state()[1][0] + worker_id)
- pass
-
-
- def inference(data_input):
- # 将数据打包成Minkowski兼容格式
- batch_data = minkowski_collate_fn([data_input])
-
- # 实例化GraspNet模型
- net = GraspNet(seed_feat_dim=cfgs.seed_feat_dim, is_training=False)
- # 设置设备(GPU优先)
- device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
- net.to(device)
-
- # 加载模型权重
- checkpoint = torch.load(cfgs.checkpoint_path)
- net.load_state_dict(checkpoint['model_state_dict'])
- start_epoch = checkpoint['epoch']
- print("-> loaded checkpoint %s (epoch: %d)" % (cfgs.checkpoint_path, start_epoch))
-
- net.eval()
- tic = time.time()
-
- # 将batch数据移到GPU(若可用)
- for key in batch_data:
- if 'list' in key:
- for i in range(len(batch_data[key])):
- for j in range(len(batch_data[key][i])):
- batch_data[key][i][j] = batch_data[key][i][j].to(device)
- else:
- batch_data[key] = batch_data[key].to(device)
-
- # 前向推理
- with torch.no_grad():
- end_points = net(batch_data)
- grasp_preds = pred_decode(end_points)
-
- preds = grasp_preds[0].detach().cpu().numpy()
- gg = GraspGroup(preds)
-
- # 若设置了碰撞检测阈值则进行碰撞检测
- if cfgs.collision_thresh > 0:
- cloud = data_input['point_clouds']
- mfcdetector = ModelFreeCollisionDetector(cloud, voxel_size=cfgs.voxel_size_cd)
- collision_mask = mfcdetector.detect(gg, approach_dist=0.05, collision_thresh=cfgs.collision_thresh)
- gg = gg[~collision_mask]
-
- # 保存抓取结果
- save_dir = os.path.join(cfgs.dump_dir, scene_id, cfgs.camera)
- save_path = os.path.join(save_dir, cfgs.index + '.npy')
- if not os.path.exists(save_dir):
- os.makedirs(save_dir)
- gg.save_npy(save_path)
-
- toc = time.time()
- print('inference time: %fs' % (toc - tic))
-
-
- if __name__ == '__main__':
- # 根据参数构造scene_id和index
- scene_id = 'scene_' + cfgs.scene
- index = cfgs.index
- data_dict = data_process()
-
- # 若需要推理则调用inference函数
- if cfgs.infer:
- inference(data_dict)
-
- # 若需要可视化(彩色)
- if cfgs.vis:
- pc = data_dict['point_clouds']
- colors = data_dict['colors'] # 获取采样后点的颜色信息
- gg = np.load(os.path.join(cfgs.dump_dir, scene_id, cfgs.camera, cfgs.index + '.npy'))
- gg = GraspGroup(gg)
- gg = gg.nms() # 非极大值抑制去重
- gg = gg.sort_by_score() # 按置信度排序
- if gg.__len__() > 30:
- gg = gg[:30]
- grippers = gg.to_open3d_geometry_list()
-
- # 创建彩色点云对象
- cloud = o3d.geometry.PointCloud()
- cloud.points = o3d.utility.Vector3dVector(pc.astype(np.float32))
- cloud.colors = o3d.utility.Vector3dVector(colors)
-
- # 创建Open3D可视化窗口
- vis = o3d.visualization.Visualizer()
- vis.create_window(visible=True) # 若不需显示窗口可设False
- vis.add_geometry(cloud)
- for g in grippers:
- vis.add_geometry(g)
-
- # 刷新渲染器和事件循环,确保图像更新
- vis.update_renderer()
- vis.poll_events()
- vis.run() # 若想交互查看可保留run()
-
- # 截图保存
- screenshot_path = os.path.join(cfgs.dump_dir, scene_id, cfgs.camera, cfgs.index + '_vis-RGB.png')
- vis.capture_screen_image(screenshot_path)
- # 销毁窗口
- vis.destroy_window()
- print("Screenshot saved at:", screenshot_path)
-
- # 若需要可视化(纯点云版本)
- if cfgs.vis:
- pc = data_dict['point_clouds']
- gg = np.load(os.path.join(cfgs.dump_dir, scene_id, cfgs.camera, cfgs.index + '.npy'))
- gg = GraspGroup(gg)
- gg = gg.nms()
- gg = gg.sort_by_score()
- if gg.__len__() > 30:
- gg = gg[:30]
- grippers = gg.to_open3d_geometry_list()
- cloud = o3d.geometry.PointCloud()
- cloud.points = o3d.utility.Vector3dVector(pc.astype(np.float32))
-
- # 创建可视化窗口(纯点云)
- vis = o3d.visualization.Visualizer()
- vis.create_window(visible=True)
- vis.add_geometry(cloud)
- for g in grippers:
- vis.add_geometry(g)
-
- vis.update_renderer()
- vis.poll_events()
- vis.run()
-
- # 保存截图
- screenshot_path = os.path.join(cfgs.dump_dir, scene_id, cfgs.camera, cfgs.index + '_vis.png')
- vis.capture_screen_image(screenshot_path)
- vis.destroy_window()
- print("Screenshot saved at:", screenshot_path)

看看检测效果,会输出彩色+点云的抓取效果:

然后输出纯三维点云的抓取效果:

看看其他示例,首先看看输出彩色+点云的抓取效果:

然后输出纯三维点云的抓取效果:

GraspNess的原理分析,参考我这篇文章
【机器人】Graspness 端到端 抓取点估计 | 论文解读-CSDN博客
分享完成~
评论记录:
回复评论: