
1. 接口(interface)
1.1 介绍
接口就是规范,定义的是一组规则,体现了现实世界中“如果你是/要…则必须能…”的思想。继承是一个"是不是"的 is-a 关系,而接口实现则是 "能不能"的has-a 关系。
1.2 接口内部结构的说明
可以声明:
- 属性:必须使用public static final修饰(开发中可以省略)
- 方法:JDK8之前声明抽象方法修饰为public abstract(开发中可以省略),JDK8声明静态方法、默认方法,JDK9声明私有方法。
不可以声明:构造器
interface Flyable{
int MIN_SPEED = 0;
void fly();
}
- 1
- 2
- 3
- 4
1.3 接口的使用规则
1.3.1 类实现接口
- 接口不能创建对象,但是可以被类实现(implements ,类似于被继承)。类与接口的关系为实现关系,即类实现接口,该类可以称为接口的实现类。实现的动作类似继承,格式相仿,只是关键字不同,实现使用 implements 关键字。
- 接口的多实现(implements):之前学过,在继承体系中,一个类只能继承一个父类。而对于接口而言,一个类是可以实现多个接口的,这叫做接口的多实现。并且,一个类能继承一个父类,同时实现多个接口。
- 注意:
• 如果接口的实现类是非抽象类,那么必须重写接口中所有抽象方法。
• 默认方法可以选择保留,也可以重写。
• 重写时,default 单词就不要再写了,它只用于在接口中表示默认方法,到类中就没有默认方法的概念。
• 接口中的静态方法不能被继承也不能被重写。
interface Flyable{
int MIN_SPEED = 0;
void fly();
}
interface Attackable{
void attack();
}
class Plane implements Flyable,Attackable{
@Override
public void fly() {
}
@Override
public void attack() {
}
}

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
1.3.2 接口之间的继承
一个接口能继承另一个或者多个接口,接口的继承也使用 extends 关键字,子接口继承父接口的方法。
interface A{
void method1();
}
interface B{
void method2();
}
interface C extends A,B{
void method3();
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
1.3.3 接口的多态性
实现类实现接口,类似于子类继承父类,因此,接口类型的变量与实现类的对象之间,也可以构成多态引用。通过接口类型的变量调用方法,最终执行的是new 的实现类对象实现的方法体。
1.3.4 区分抽象类和接口
- 共性:
- 都可以声明抽象方法。
- 都不能实例化。
- 不同
- 抽象类一定有构造器,接口没有构造器。
- 类和类之间是继承关系,类与接口之间是实现关系,接口和接口之间是多继承关系。
2. 内部类
2.1 介绍
将一个类 A 定义在另一个类 B 里面,里面的那个类 A 就称为内部类(InnerClass),类 B 则称为外部类(OuterClass)。
2.2 作用
具体来说,当一个事物 A 的内部,还有一个部分需要一个完整的结构 B 进行描述,而这个内部的完整的结构 B 又只为外部事物 A 提供服务,不在其他地方单独使用,那么整个内部的完整结构 B 最好使用内部类。
总的来说,遵循高内聚、低耦合的面向对象开发原则。
2.3 分类
内部类可以分为成员内部类和局部内部类。成员内部类又分为静态成员内部类和非静态成员内部类,局部内部类(声明在方法内、构造器内、代码块内的内部类)又分为非匿名局部内部类和匿名局部内部类。
2.4 成员内部类
2.4.1 介绍
- 从类的角度看:
- 内部类可以声明属性、方法、构造器、代码块、内部类等结构。
- 此内部类可以声明父类,可以实现接口。
- 可以使用final修饰。
- 可以使用abstract修饰。
- 从外部类的成员的角度看:
- 在内部可以调用外部类的结构。比如:属性、方法等。
- 除了使用public、缺省权限修饰之外,还可以使用private、protected修饰。
- 可以使用static修饰。
- 如果成员内部类中不使用外部类的非静态成员,那么通常将内部类声明为静态内部类,否则声明为非静态内部类。
2.4.2 创建成员内部类对象
- 实例化静态内部类:
外部类名.静态内部类名 变量 = 外部类名.静态内部类名();
变量.非静态方法(); - 实例化非静态内部类:
外部类名 变量 1 = new 外部类();
外部类名.非静态内部类名 变量 2 = 变量 1.new 非静态内部类名();
变量 2.非静态方法();
关注作者了解更多
我的其他CSDN专栏
关注作者了解更多
资料来源于网络,如有侵权请联系编者
目录
智能控制理论及应用
第一章 绪论
1.1 学习智能控制的意义
《智能控制》在自动化课程体系中的位置
《智能控制》是一门控制理论课程,研究如何运用人工智能的方法来构造控制系统和设计控制器。与《自动控制原理》和《现代控制原理》一起构成了自动控制课程体系的理论基础。
《智能控制》在控制理论中的位置
《智能控制》是目前控制理论的最高级形式,代表了控制理论的发展趋势,能有效地处理复杂的控制问题。其相关技术可以推广应用于控制之外的领域:金融、管理、土木、设计等等。
1.2 智能控制的产生和发展
产生的背景






智能控制的两个发展方向
智能控制的三个发展阶段
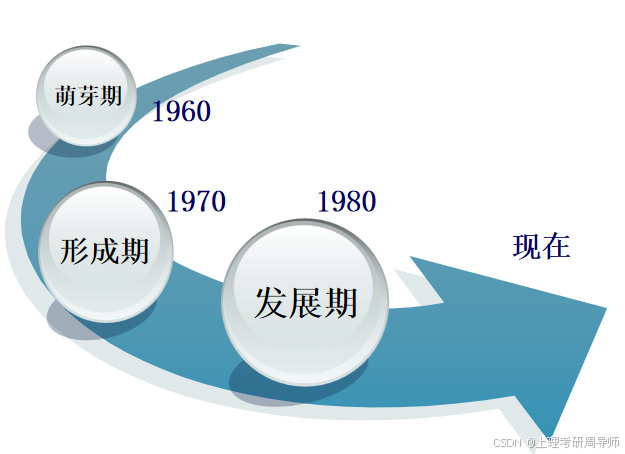
1)萌芽期(1960-1970)
2)形成期(1970-1980)

3)发展期(1980- )

1.3 智能控制的定义和特点
智能控制的定义
IEEE定义:智能控制必须具有模拟人类学习和自适应的能力。
一般来说,一个智能控制系统要具有对环境的敏感,进行决策和控制的功能,根据其性能要求的不同.可以有各种人工智能的水平。

智能控制的特点

1.4 智能控制的主要形式
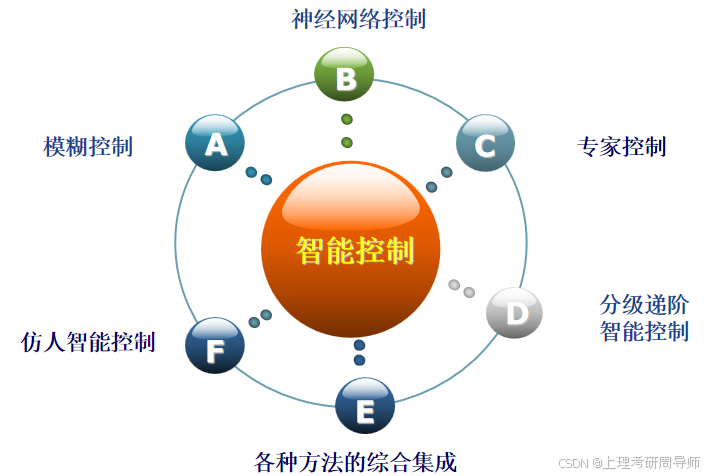
基于信息论的分级递阶智能控制


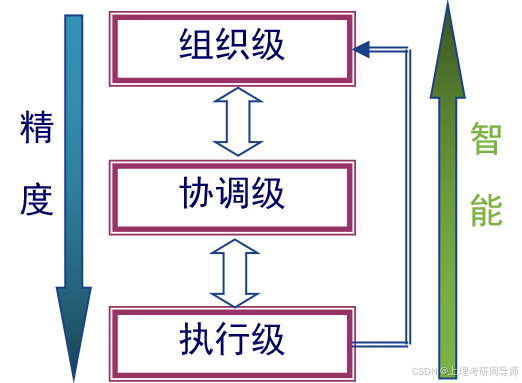
以模糊系统理论为基础的模糊控制

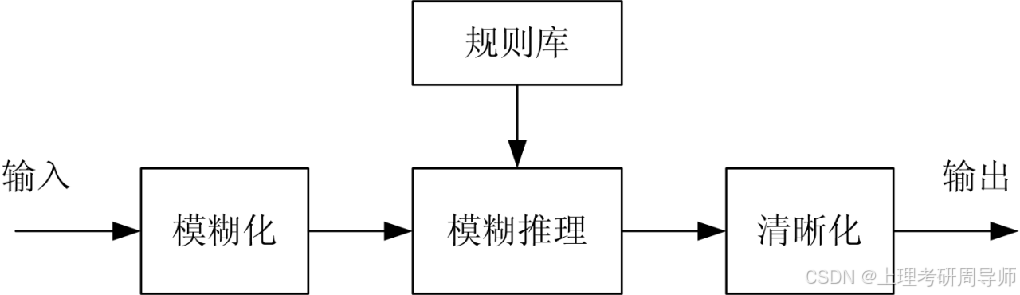
基于脑模型的神经网络控制
人工神经网络采用仿生学的观点与方法来研究人脑和智能系统中的高级信息处理。
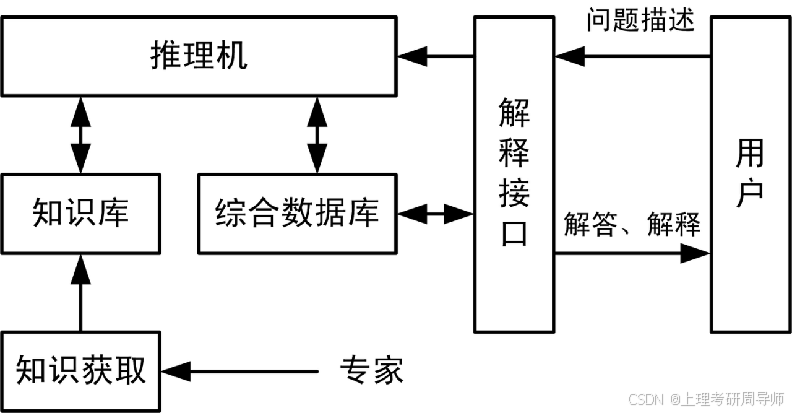
基于知识工程的专家控制系统
专家控制可定义为:具有模糊专家智能的功能,采用专家系统技术与控制理论相结合的方法设计控制系统。
基于规则的仿人智能控制
仿人智能控制的核心思想是在控制过程中,利用计算机模拟人的控制行为功能,最大限度地识别和利用控制系统动态过程提供的特征信息,进行启发和直觉推理,从而实现对缺乏精确模型的对象迸行有效的控制。其基本原理是模仿人的启发式直觉推理逻辑,即通过特征辩识判断系统当前所处的特怔状态,确定控制的策略,进行多模态控制。
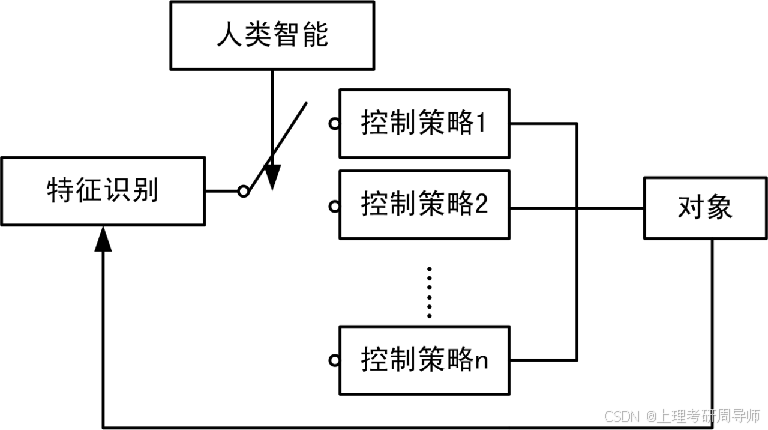
1.5 智能控制的现状和发展趋势
目前的主要研究方向和内容

发展趋势

第二章 模糊控制的数学基础
2.1 概述
模糊数学(模糊集)是模糊控制的数学基础,它是由美国加利福尼亚大学Zadeh教授最先提出的。他将模糊性和集合论统一起来,在不放弃集合的数学严格性的同时,使其吸取人脑思维中对于模糊现象认识和推理的优点。
“模糊”,是指客观事物彼此间的差异在中间过渡时,界限不明显,呈现出的“亦此亦彼”性。“模糊”是相对于“精确”而言的。
“精确”:“老师”、“学生”、“工人”
“模糊”:“高个子”、“热天气”、“年轻人”
模糊数学并不是让数学变成模模糊糊的东西,而是用数学工具对模糊现象进行描述和分析。模糊数学是对经典数学的扩展,它在经典集合理论的基础上引入了“隶属函数”的概念,来描述事物对模糊概念的从属程度。
2.3 模糊集合
(1)模糊集合的定义:
给定论域E中的一个模糊集 A,是指任意元素x∈E,都不同程度地属于这个集合,元素属于这个集合的程度可以用隶属函数 UA(x) ∈[0,1]来表示。
例2.3.1 论域为15到35岁之间的人,模糊集 表示“年轻人”,则模糊集的隶属函数可定义为
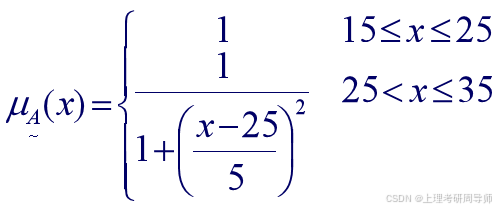
则年龄为30岁的人属于“年轻人”的程度为:
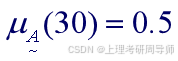
(2) 模糊集合的表示法:
1) Zadeh表示法 当论域上的元素为有限个时,定义在该论域上的模糊集可表示为:
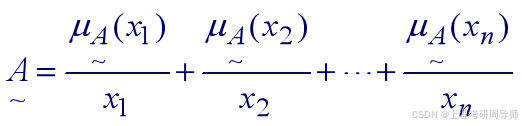
注意:式中的“+”和“/”,仅仅是分隔符号,并不代表“加”和“除”。
例2.3.2 假设论域为5个人的身高,分别为172cm、165cm、175cm、180cm、178cm,他们的身高对于“高个子”的模糊概念的隶属度分别为0.8、0.78、0.85、0.90、0.88。则模糊集“高个子”可以表示为
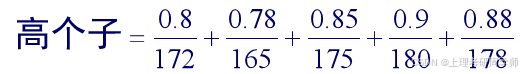
2)序偶表示法 当论域上的元素为有限个时,定义在该论域上的模糊集还可用序偶的形式表示为:
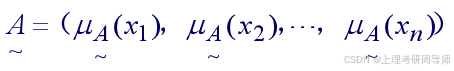
对于上例的模糊集“高个子”可以用序偶法表示为
高个子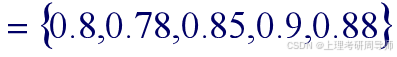
3)隶属函数描述法
论域U上的模糊子集可以完全由其隶属函数表示。
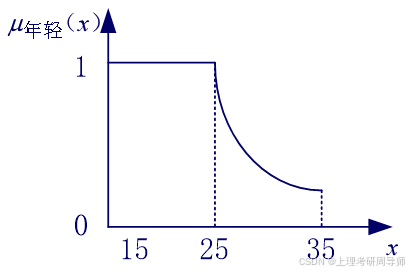
假设年龄的论域为U=[15,35],则模糊集“年轻”可用隶属函数表征为:
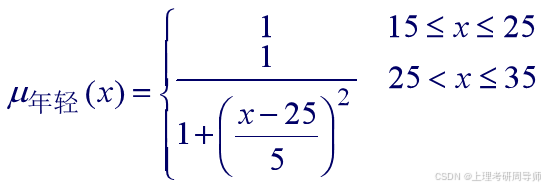
该隶属函数的形状如图

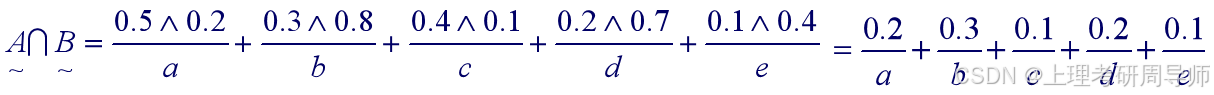
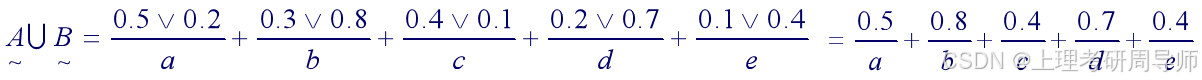
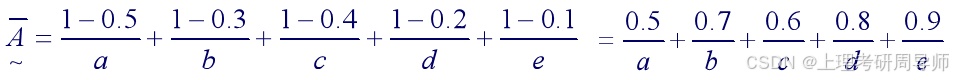
2.5 模糊关系
模糊关系
人和人之间关系的“亲密”与否? 儿子和父亲之间长相的“相像”与否? 家庭是否“和睦”?
这些关系就无法简单的用“是”或“否”来描述,而只能描述为“在多大程度上是”或“在多大程度上否“。这些关系就是模糊关系。我们可以将普通关系的概念进行扩展,从而得出模糊关系的定义。
① 模糊关系的定义


模糊关系常常用矩阵的形式来描述。假设x∈U,y∈V ,则U到V的模糊关系可以用矩阵描述为
则上例中的模糊关系又可以用矩阵描述为:

例2.5.3 已知


解:根据模糊关系的运算规则得:


小结
模糊集理论是模糊控制的数学基础,是描述模糊性概念的有效的数学工具。模糊集合理论是普通集合理论的拓展,它通过引入隶属函数的概念达到了对模糊概念描述的目的。
本章详细地介绍了模糊集合、模糊关系的概念及其与普通集合、普通关系之间的关系、并给出了如何从人类自然语言规则中提取其蕴涵的模糊关系的方法,介绍了如何根据模糊关系进行模糊推理。
第三章 模糊控制
3.1 模糊控制的工作原理
模糊控制的基本思想
将人类专家对特定对象的控制经验,运用模糊集理论进行量化,转化为可数学实现的控制器,从而实现对被控对象的控制。
人类专家的控制经验是如何转化为数字控制器的 ?
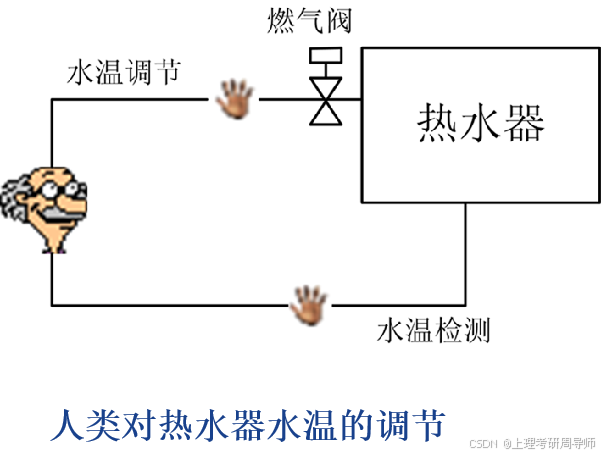

模仿人类的调节经验,可以构造一个模糊控制系统来实现对热水器的控制。



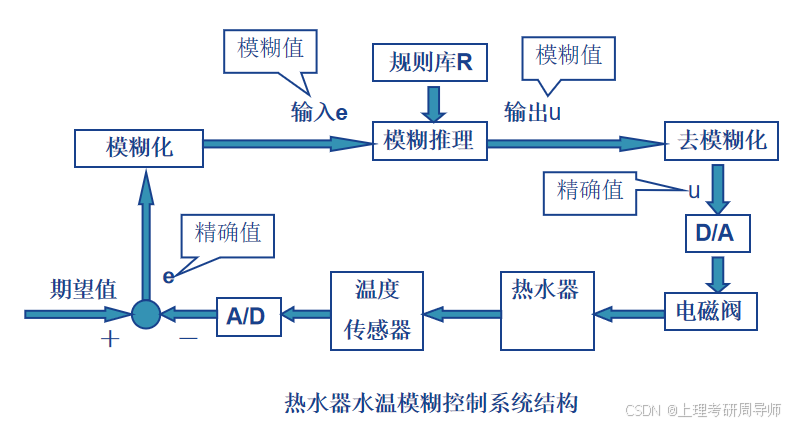
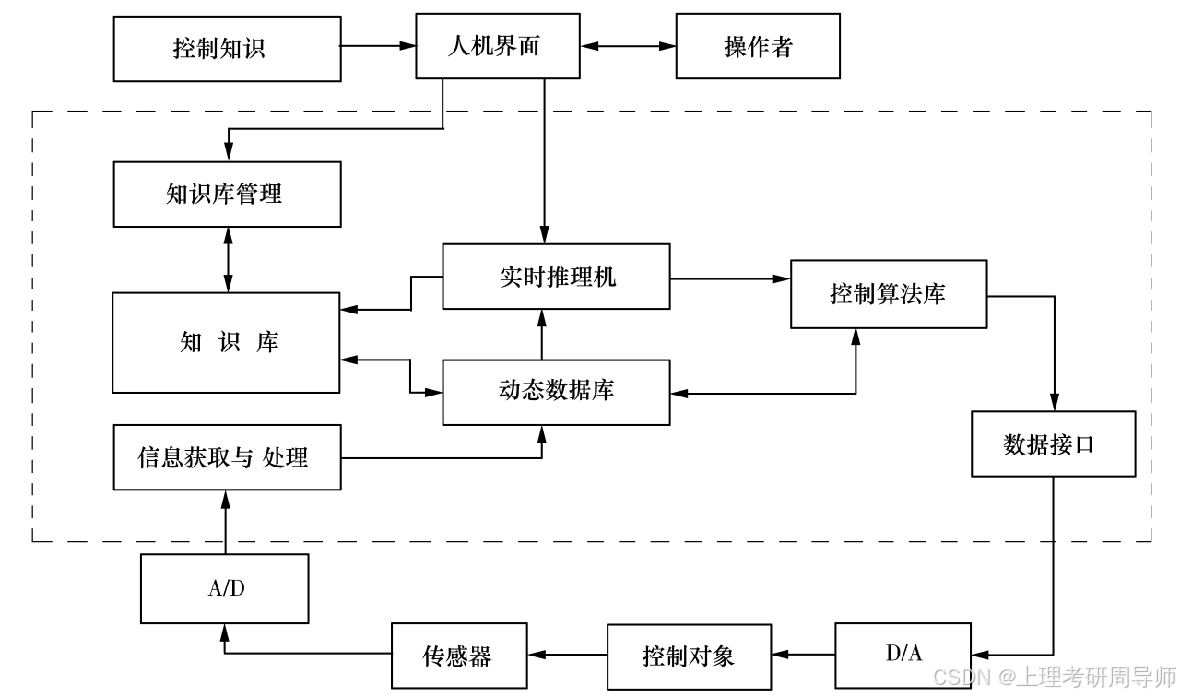
模糊控制器的基本工作原理

3.2 模糊控制器的结构和设计

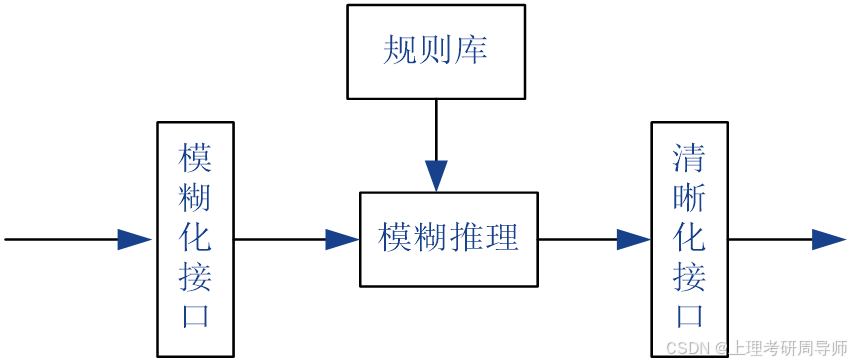
3.2.1 模糊化接口
模糊化就是通过在控制器的输入、输出论域上定义语言变量,来将精确的输入、输出值转换为模糊的语言值。
模糊化接口的设计步骤事实上就是定义语言变量的过程,可分为以下几步:
1) 语言变量的确定
针对模糊控制器每个输入、输出空间,各自定义一个语言变量。

2)语言变量论域的设计

为了提高实时性,模糊控制器常常以控制查询表的形式出现。该表反映了通过模糊控制算法求出的模糊控制器输入量和输出量在给定离散点上的对应关系。为了能方便地产生控制查询表,在模糊控制器的设计中,通常就把语言变量的论域定义为有限整数的离散论域。
3) 定义各语言变量的语言值

档级多,规则制定灵活,规则细致,但规则多、复杂,编制程序困难,占用的内存较多; 档级少,规则少,规则实现方便,但过少的规则会使控制作用变粗而达不到预期的效果。 因此在选择模糊状态时要兼顾简单性和控制效果。
4)定义各语言值的隶属函数
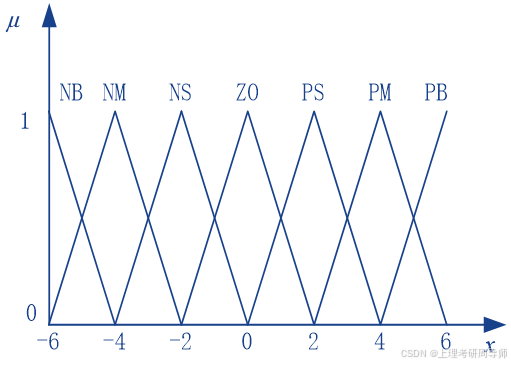
隶属函数的类型
正态分布型(高斯基函数 )
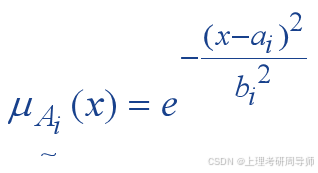
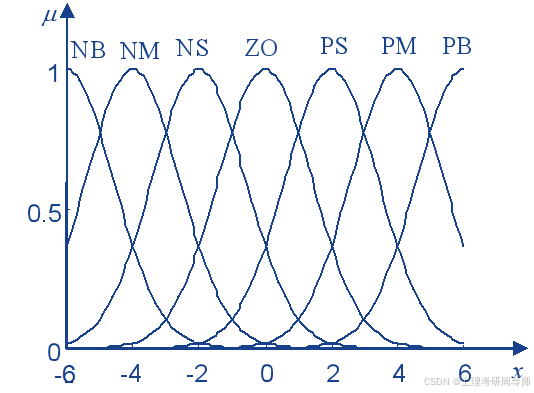

三角型
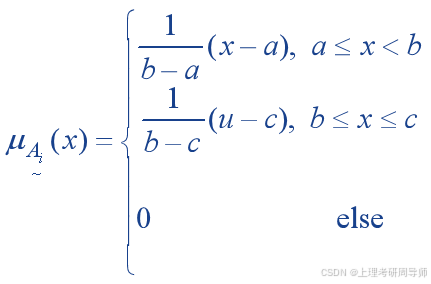
梯型
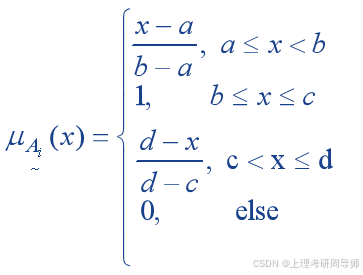
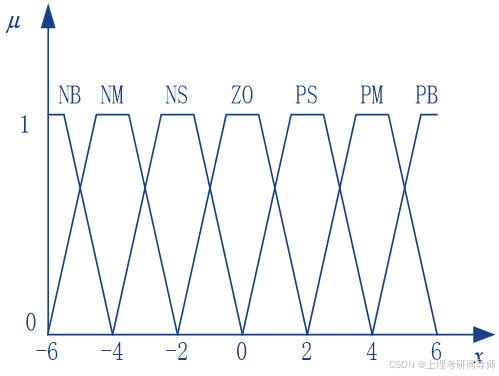
隶属函数确定时需要考虑的几个问题
隶属函数曲线形状对控制性能的影响。

3.2.2 规则库
规则库的描述
规则库由若干条控制规则组成,这些控制规则根据人类控制专家的经验总结得出,按照 IF …is …AND …is …THEN …is…的形式表达。
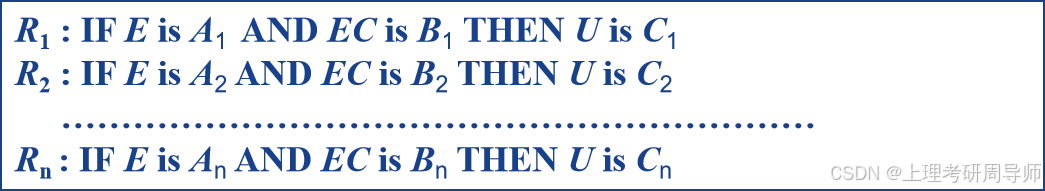

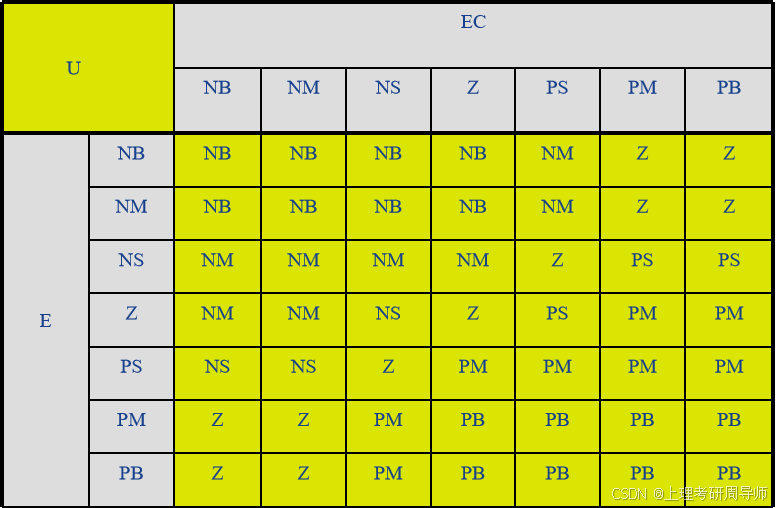
规则库也可以用矩阵表的形式进行描述。
例如在模糊控制直流电机调速系统中,模糊控制器的输入为E(转速误差)、EC(转速误差变化率),输出为U(电机的力矩电流值)。
在E、EC、U的论域上各定义了7个语言子集:{PB,PM,PS,ZO,NS,NM,NB} 对于E、EC可能的每种取值,进行专家分析和总结后,则总结出的控制规则为:
3.2.3 模糊推理
根据模糊输入和规则库中蕴涵的输入输出关系,通过第二章描述的模糊推理方法得到模糊控制器的输出模糊值
3.2.4 清晰化接口
由模糊推理得到的模糊输出值C*是输出论域上的模糊子集,只有其转化为精确控制量u,才能施加于对象。我们实行这种转化的方法叫做清晰化/去模糊化/模糊判决。
3.2.6 模糊控制器的设计内容

第四章 神经网络基本理论
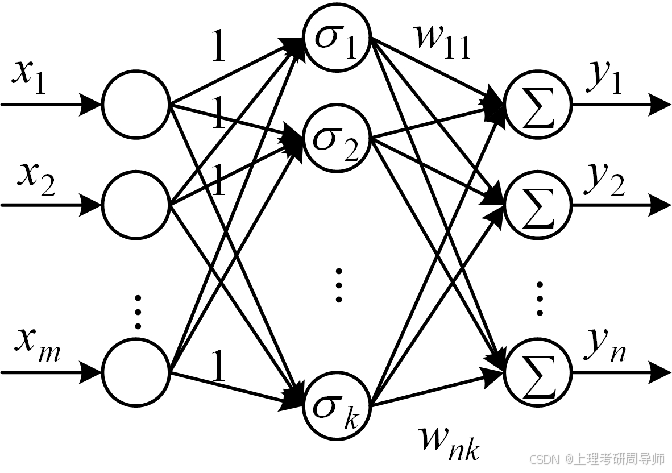
4.1 人工神经元模型
人工神经元是对人或其它生物的神经元细胞的若干基本特性的抽象和模拟。
生物神经元模型
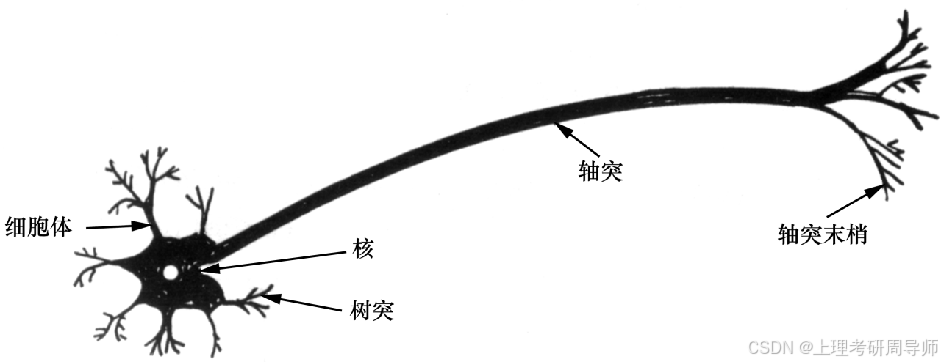
生物神经元主要由细胞体、树突和轴突组成,树突和轴突负责传入和传出信息,兴奋性的冲动沿树突抵达细胞体,在细胞膜上累积形成兴奋性电位;相反,抑制性冲动到达细胞膜则形成抑制性电位。两种电位进行累加,若代数和超过某个阈值,神经元将产生冲动。
人工神经元模型
模仿生物神经元产生冲动的过程,可以建立一个典型的人工神经元数学模型
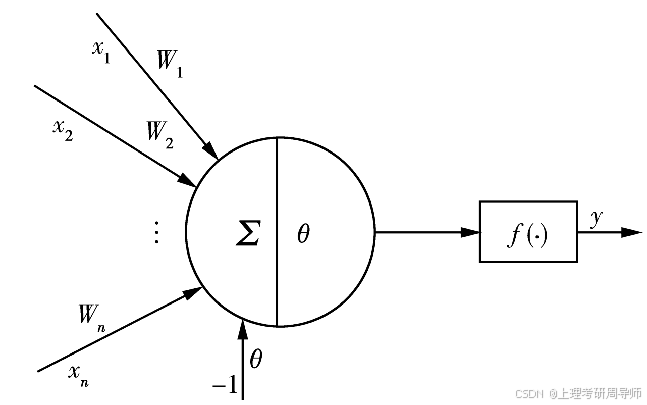

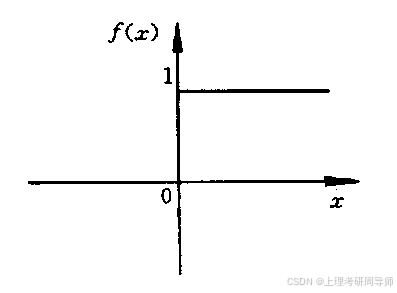
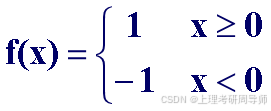
常用的激发函数f 的种类 :
1)阈值型函数
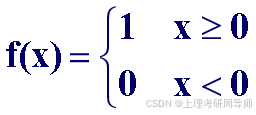
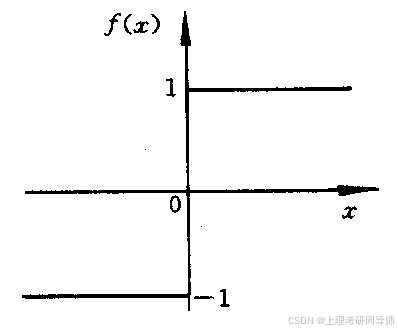
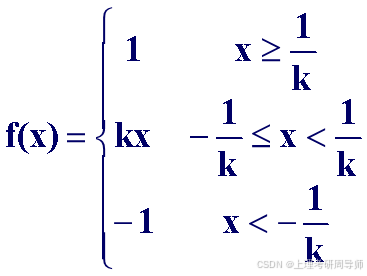
2)饱和型函数
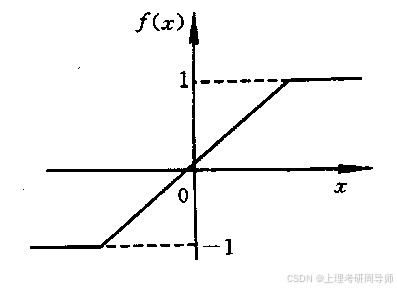
3)双曲函数

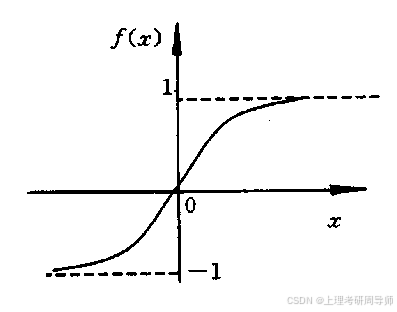
4)S型函数
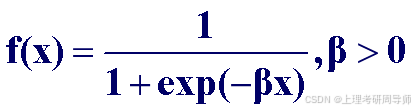
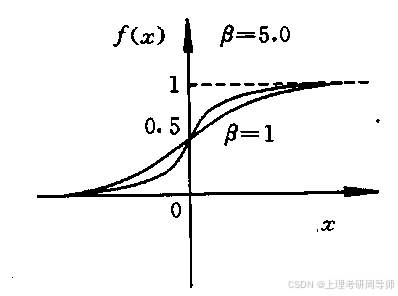
5)高斯函数
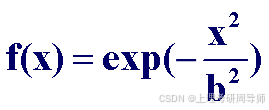
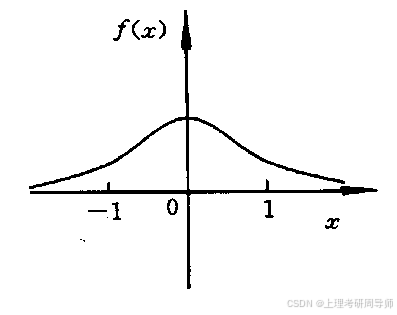
4.2 神经网络的定义和特点
定义
神经网络系统是由大量的神经元,通过广泛地互相连接而形成的复杂网络系统。
特点
(1)非线性映射逼近能力。任意的连续非线性函数映射关系可由多层神经网络以任意精度加以逼近。
(2)自适应性和自组织性。神经元之间的连接具有多样性,各神经元之间的连接强度具有可塑性,网络可以通过学习与训练进行自组织,以适应不同信息处理的要求。
(3) 并行处理性。网络的各单元可以同时进行类似的处理过程,整个网络的信息处理方式是大规模并行的,可以大大加快对信息处理的速度。
(4)分布存储和容错性。信息在神经网络内的存储按内容分布于许多神经元中,而且每个神经元存储多种信息的部分内容。网络的每部分对信息的存储具有等势作用,部分的信息丢失仍可以使完整的信息得到恢复,因而使网络具有容错性和联想记忆功能。
(5)便于集成实现和计算模拟。神经网络在结构上是相同神经元的大规模组合,特别适合于用大规模集成电路实现。
4.4 神经网络的构成和分类
分类
(1)从结构上划分
通常所说的网络结构,主要是指它的联接方式。神经网络从拓扑结构上来说,主要分为层状和网状结构。
①层状结构:网络由若干层组成,每层中有一定数量的神经元,相邻层中神经元单向联接,一般同层内神经元不能联接。
前向网络:只有前后相邻两层之间神经元相互联接,各神经元之间没有反馈。每个神经元从前一层接收输入,发送输出给下一层。
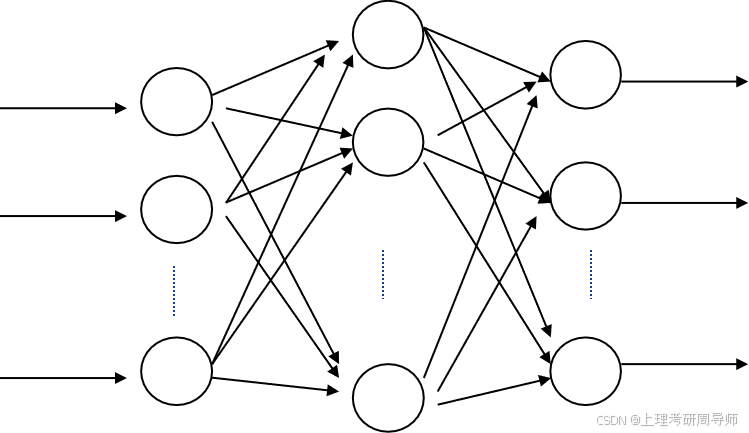
②网状结构:网络中任何两个神经元之间都可能双向联接。
反馈网络:从输出层到输入层有反馈,每一个神经元同时接收外来输入和来自其它神经元的反馈输入,其中包括神经元输出信号引回自身输入的自环反馈。

混合型网络:前向网络的同一层神经元之间有互联的网络。
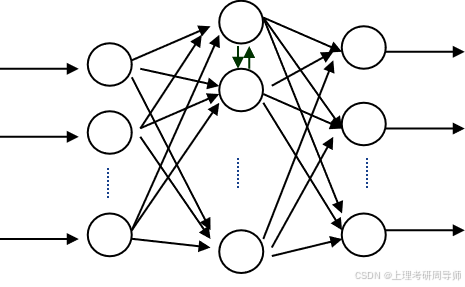
(2)从激发函数的类型上划分
高斯基函数神经网络、小波基函数神经网络、样条基函数神经网络等等
(3)从网络的学习方式上划分
①有导师学习神经网络 为神经网络提供样本数据,对网络进行训练,使网络的输入输出关系逼近样本数据的输入输出关系。
②有导师学习神经网络 不为神经网络提供样本数据,学习过程中网络自动将输入数据的特征提取出来。
(4)从学习算法上来划分:
基于BP算法的网络、基于Hebb算法的网络、基于竞争式学习算法的网络、基于遗传算法的网络。
4.4 多层前向BP神经网络
最早由werbos在1974年提出的,1985年由Rumelhart再次进行发展。
多层前向神经网络的结构
多层前向神经网络由输入层、隐层(不少于1层)、输出层组成,信号沿输入——>输出的方向逐层传递。
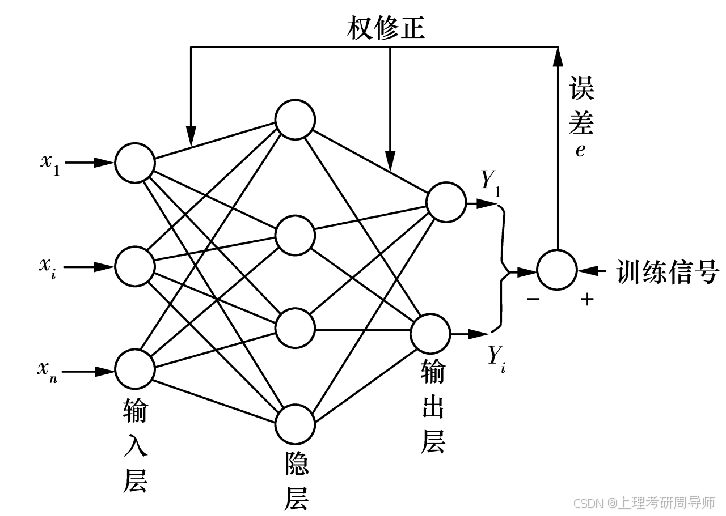
第七章 专家控制技术
7.1 概述
专家系统是一个具有大量专门知识与经验的程序系统,根据某个领域的专家提供的知识和经验进行推理和判断,模拟人类专家的决策过程。
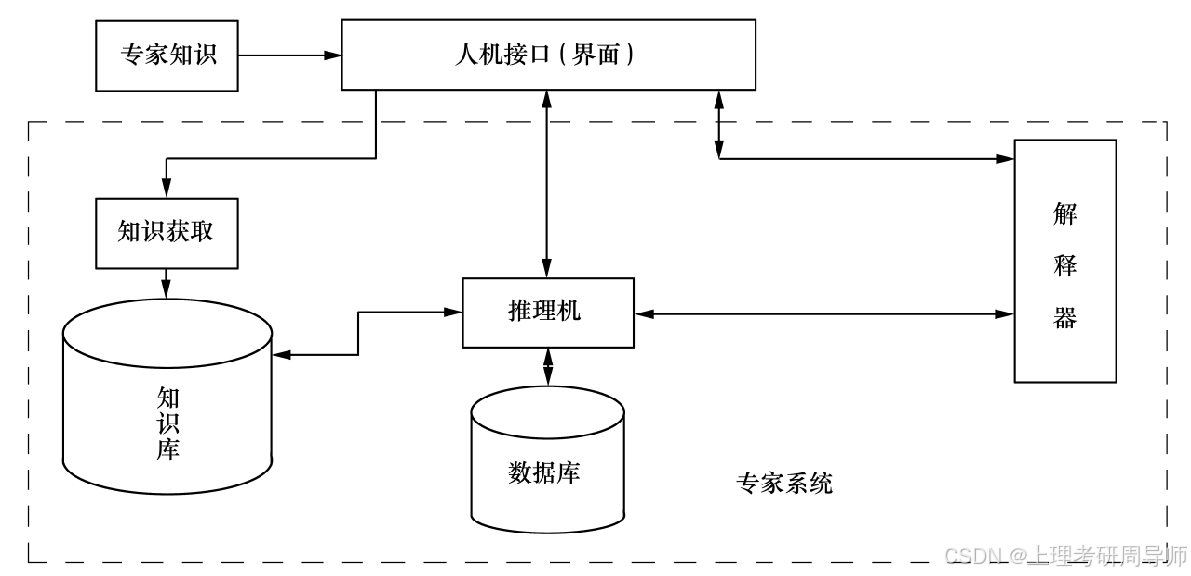
一般专家系统由知识库、数据库、推理机、解释器及知识获取器五个部分组成。
(1) 知识库。知识库用于存取和管理所获取的专家知识和经验,供推理机利用,具有知识存储、检索、编辑、增删、修改和扩充等功能。
(2) 数据库。用来存放系统推理过程中用到的控制信息、中间假设和中间结果。
(3) 推理机。用于利用知识进行推理,求解专门问题,具有启发推理、算法推理;正向、反向或双向推理;串行或并行推理等功能。
(4) 解释器。解释器用于作为专家系统与用户之间的“人-机”接口,其功能是向用户解释系统的行为。
(5) 知识获取。知识获取是专家系统与专家的“界面”。知识库中的知识一般都是通过“人工移植”方法获得,“界面”就是知识工程师(专家系统的设计者),采用“专题面谈”、“口语记录分析”等方式获取知识,经过整理以后,再输入知识库。
具有专家水平的知识:必须表现专家的技能和高度的技巧以及足够的鲁棒性。系统的鲁棒性是指不管数据正确与否,都能够得到正确的结论或者指出错误。
能进行有效的推理:能够运用专家的经验和知识进行搜索、推理。
具有透明性:在推理时,不仅能够得到答案,而且还能给出推理的依据 具有灵活性:知识的更新和扩充灵活方便
复杂性:人类的知识可以定性或定量的表示,专家系统经常表现为定性推理和定量计算的混合形式,比较复杂
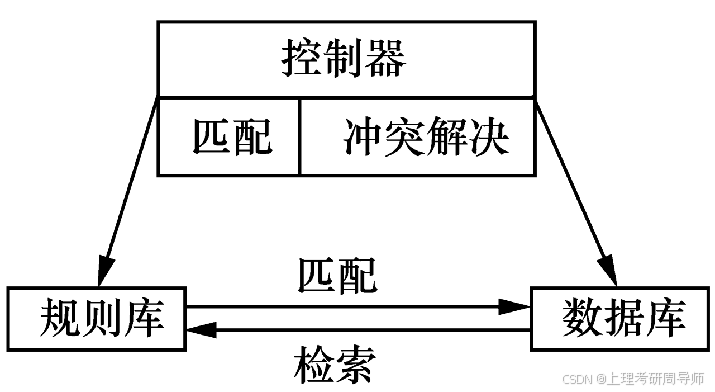
1)规则库
该库存放了若干规则,每条产生式规则是一个以“如果满足这个条件,就应当采取这个操作”形式表示的语句。各条规则之间相互作用不大。规则可有如下形式

2) 数据库
数据库是产生式规则的中心,每个产生式的左边表示在启用这一规则之前数据库内必须准备好的条件。执行产生式规则的操作会引起数据库的变化,这就使得其它产生式规则的条件可能被满足。
3) 控制器
其作用是说明下一步应该选用什么规则,也就是如何运用规则。通常从选择规则到执行规则分成三步:匹配、冲突解决和操作。
① 匹配。把数据库和规则的条件部分相匹配。如果两者完全匹配,则把这条规则称为触发规则。当按规则的操作部分去执行时,这条规则称为被启用规则。
② 冲突解决。当有一个以上的规则条件和当前数据库相匹配时,就需要决定首先使用哪一条规则,这称为冲突解决。
③ 操作。操作就是执行规则的操作部分,经过操作以后,当前数据库将被修改。然后,其他的规则有可能被使用。
7.3 专家系统的推理机制
根据问题求解的推理过程中推理的方向,知识推理方法可分为正向推理、反向推理和正反向混合推理三类。
(1) 正向推理。正向推理是由原始数据出发,按照一定策略,运用知识库中专家的知识,推断出结论的方法。这种推理方式,由于是由数据到结论,也叫数据驱动策略。
(2) 反向推理。反向推理是先提出假设(结论),然后去找支持这个结论的证据的方法。这种由结论到数据的策略称为目标驱动策略。
(3)正反向混合推理。运用正向推理帮助系统提出假设,然后运用反向推理寻找支持该假设的证据。
第八章 遗传算法
遗传算法(Genetic Algorithm,简称GA)作为一种解决复杂问题的优化搜索方法,是由美国密执安大学的John Holland教授首先提出来的(Holland,1975)。遗传算法是以达尔文的生物进化论为启发而创建的,是一种基于进化论中优胜劣汰、自然选择、适者生存和物种遗传思想的优化算法。
遗传算法广泛应用于人工智能、机器学习、知识工程、函数优化、自动控制、模式识别、图像处理、生物工程等众多领域。目前,遗传算法正在向其它学科和领域渗透,正在形成遗传算法、神经网络和模糊控制相结合,从而构成一种新型的智能控制系统整体优化的结构形式。
8.1.1 遗传算法的由来
GA的基本思想来源于Darwin的进化论和Mendel的遗传学说。Darwin的进化论认为每一物种在不断的发展过程中都是越来越适应环境。物种的每个个体的基本特征被后代所继承,但后代又不完全同于父代,这些新的变化,若适应环境,则被保留下来。在某一环境中也是那些更能适应环境的个体特征能被保留下来,这就是适者生存的原理。
遗传算法的出发点是一个简单的群体遗传模型,该模型基于如下假设:
(1)染色体(基因型)由一固定长度的字符串组成,其中的每一位具有有限数目的等位基因。
(2)群体由有限数目的基因型组成。
(3)每一基因型有一相应的适应度(Fitness),表示该基因型生存与复制的能力。适应度为大于零的实数,适应度越大表示生存能力越强。
8.1.2 遗传算法的基本操作
8.1.2.2 交叉(Crossover) 复制(又称繁殖),是从一个旧种群( old population)中选择生命力强的个体位串(或称字符串)产生新种群的过程。或者说,复制是个体位串根据其目标函数(即适应度函数)拷贝自己的过程。根据位串的适应度值拷贝位串意味着,具有较高适应度值的位串更有可能在下一代中产生一个或多个后代。显然,这个操作是模仿自然选择现象,将达尔文的适者生存理论应用于位串的复制,适应度值是该位串被复制或被淘汰的决定因素。
8.1.2.2 交叉(Crossover)交叉是在两个基因型之间进行的,指其中部分内容进行了互换。 A = a1a2…al 和 B = b1b2…bl 若在位置i交换,则产生两个新的串 A′=a1…albi+1…bl 和 B′=b1…blai+1…al
8.1.2.3 变异(Mutation) 若基因型中某个或某几个位置上的等位基因从一种状态跳变到另一种状态(0变为1或1变为0),则称该基因型发生了变异。其中变异的位置也是随机的。
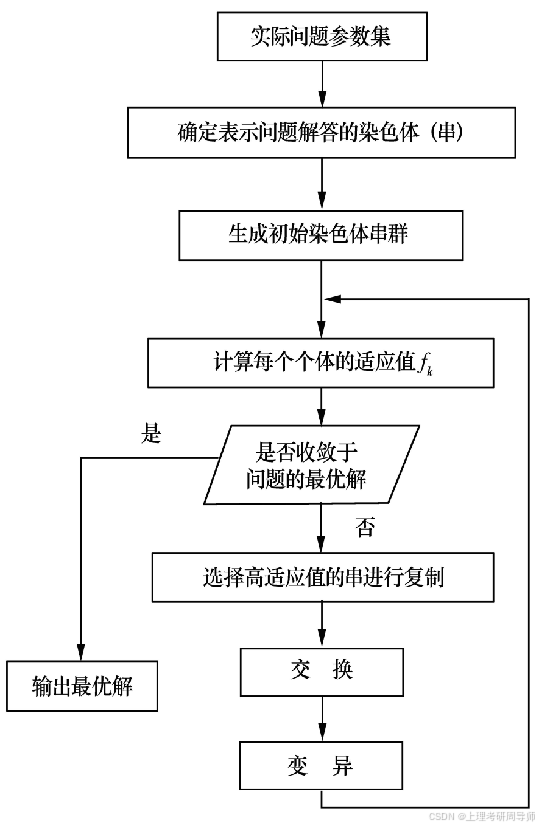
遗传算法的基本步骤
8.1.3 遗传算法的特点
1)GA是对问题参数的编码(染色体)进行操作,而不是参数本身。
(2)GA计算简单,便于计算机编程,功能强。
(3)GA是从问题解的串集开始搜索,而不是从单个解开始,更有利于搜索到全局最优解。
(4)GA使用对象函数值(即适应值)这一信息进行搜索,而不需导数等其它信息。
(5)GA的复制、交叉、变异这三个算子都是由概率决定的,而非确定性的。
(6)GA算法具有隐含的并行性,因而可通过大规模并行计算来提高计算速度。
(7)GA更适合大规模复杂问题的优化,但解决简单问题效率并不高。
评论记录:
回复评论: