
一. 背景
ECharts 作为一款功能强大的前端数据可视化库,为开发者提供了丰富多样的图表类型和灵活的配置选项,广泛应用于各行业的数据展示和分析中。在当今数字化的时代,数据量呈现爆炸性增长,大规模数据的可视化需求变得越来越迫切。
然而,当数据量达到十万级甚至更高级别时,ECharts 的渲染性能也面临挑战。传统的渲染方式可能会导致页面卡顿、加载时间过长等问题,影响用户体验。因此,针对 ECharts 渲染大规模数据时的性能问题,我们迫切需要探讨并实践适用的优化方案。
本篇文章将从实践出发,深入探讨 ECharts 渲染十万级数据的性能优化方案,通过实际案例和经验总结,探讨如何提升大规模数据可视化的渲染效率和用户体验。
通过本篇文章,我希望能够帮助大家更好地理解 ECharts 渲染十万级数据的性能挑战,并掌握实用的优化方法,从而实现更流畅、高效的大规模数据可视化展示。
二. 为什么要进行渲染优化?
在我的一个实际项目中,有一个应用场景是:用户要通过时间范围选择框,查询最近半年的数据量,进而通过 ECharts 折线图一次性渲染大概十万+以上的数据量。可想而知,数据量大带来的用户体验效果会非常不好,如下图所示:
-
接口请求回来的数据量大概有七万条数据,如下图所示:
-
接口请求时间为 11 秒,数据包的大小为 3.6 MB,如下图所示:

-
ECharts 最终渲染效果如下所示:
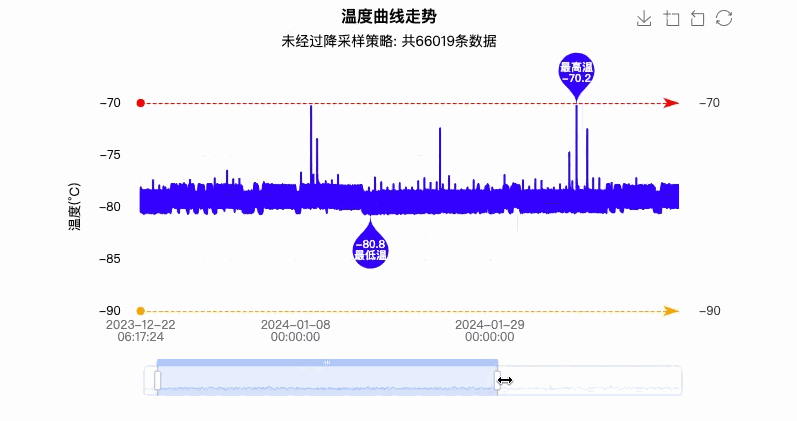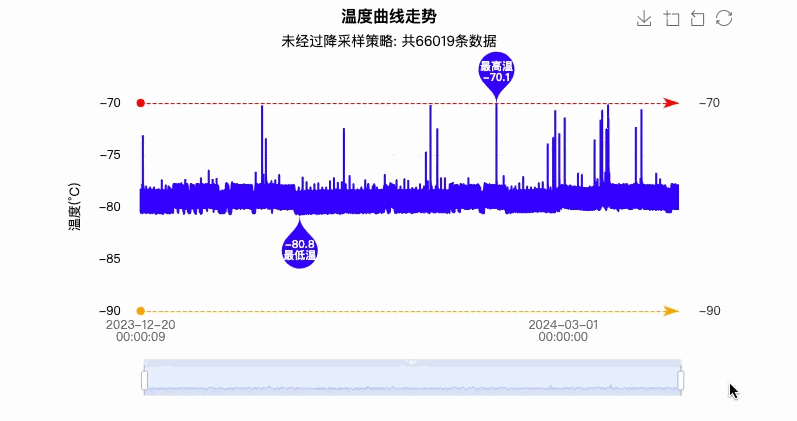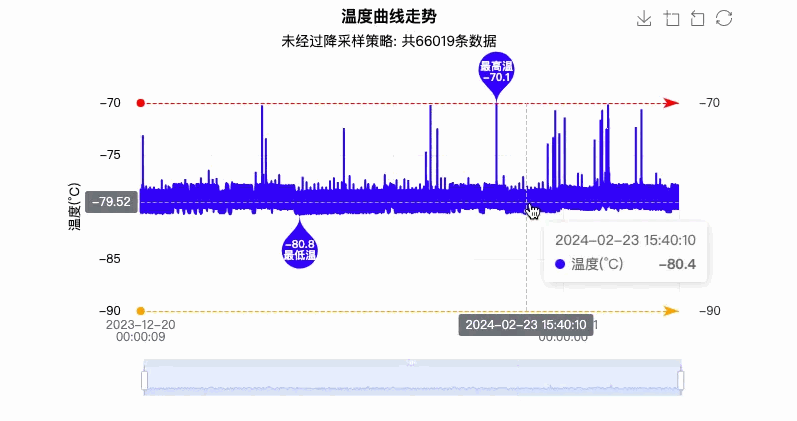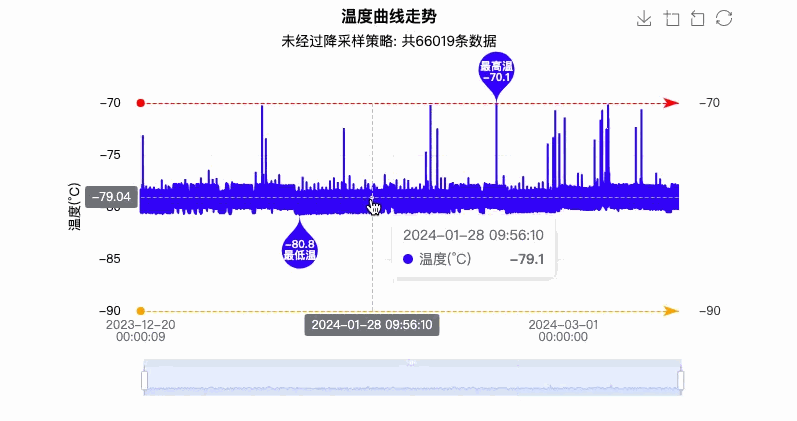
如上图所示的效果反应,用户体验效果非常不好,网络请求 10 秒以上,图表渲染至少要 5 秒以上,渲染成功后用户操作卡顿、延迟还特别严重。
但是这并不能说明 ECharts 图表渲染性能不好,而是有些时候 ECharts 有提供的方案,但是我们并没有按照官方策略去执行,去优化。图中面对的数据量才是十万级,相比较而言,在目前大数据的时代,百万级、千万级的数据量也会经常出现在我们的日常项目开发中,那么试想一下,如果还是以上这种方式渲染,我相信只有崩溃一条路可以走。
因此,在 ECharts 图表渲染这种场景下,面对庞大的数据量时,我们应该如何进行优化?提升用户体验呢?接下来我们就聊一下在实际项目中 ECharts 渲染海量数据的几个优化方案。
三. 方案一:数据分段渲染
1. 方案简介
随着数据量的增加,直接一次性加载所有数据可能导致页面性能下降和用户体验变差,因此考虑将数据分段加载也是一种常见的性能优化方案。
ECharts dataZoom 组件常用于区域缩放,从而让用户能自由关注细节的数据信息,或者概览数据整体,或者去除离群点的影响。为了能让 ECharts 避免一次性渲染的数据量过大,因此可以考虑使用 dataZoom 的区域缩放属性实现首次渲染 ECharts 图表时就进行区域渲染,减少整体渲染带来的性能消耗。
2. 实现步骤
dataZoom 组件提供了几个属性,利用这几个属性可以控制图表渲染时的性能问题,如下所示:
-
start: 数据窗口范围的起始百分比。范围是:0 ~ 100。表示 0% ~ 100%。 -
end: 数据窗口范围的结束百分比。范围是:0 ~ 100。 -
minSpan: 用于限制窗口大小的最小值(百分比值),取值范围是 0 ~ 100。 -
maxSpan: 用于限制窗口大小的最大值(百分比值),取值范围是 0 ~ 100。
具体方案是使用 start 和 end 控制 ECharts 图表初次渲染时滑块所处的位置以及数据窗口范围,使用 minSpan 和 maxSpan 用于限制窗口大小的最小值和最大值,最终限制的图表的可视区域显示范围,如下代码所示:
- var option = {
- dataZoom: [
- {
- type: "slider",
- xAxisIndex: [0],
- start: 0,
- end: 1,
- minSpan: 0,
- maxSpan: 10,
- },
- ],
- };
以上代码表示 ECharts 图表初始化时,数据窗口从 x 轴 0 ~ 1% 范围内显示,最大的窗口显示范围为 10%
3. 实际效果
通过配置 dataZoom 区域缩放组件,实现数据分段加载的实现方案,可以有效降低页面加载时间,减少资源占用,提升用户体验。大幅度减少一次性加载大数据量带来的性能压力,实现更加流畅的大规模数据可视化展示。
最终实现效果图如下图所示:
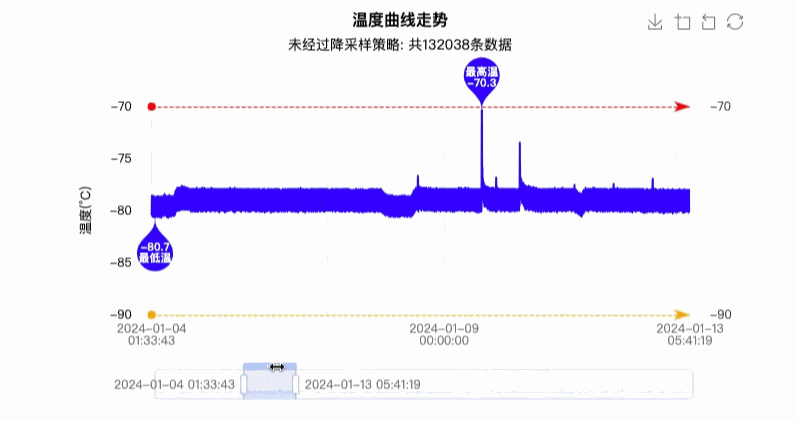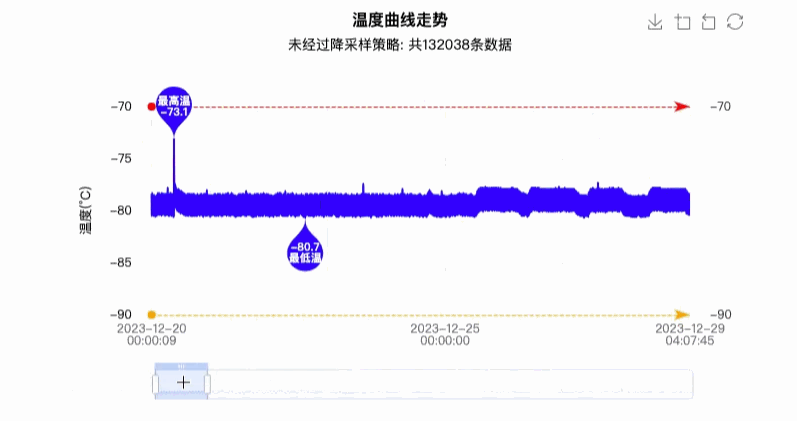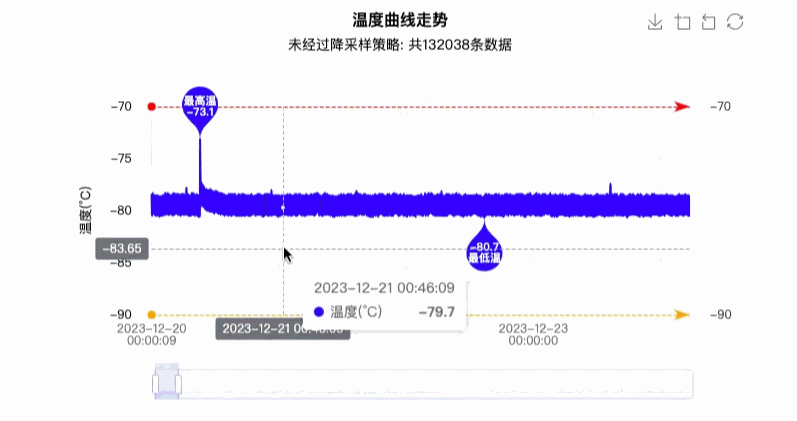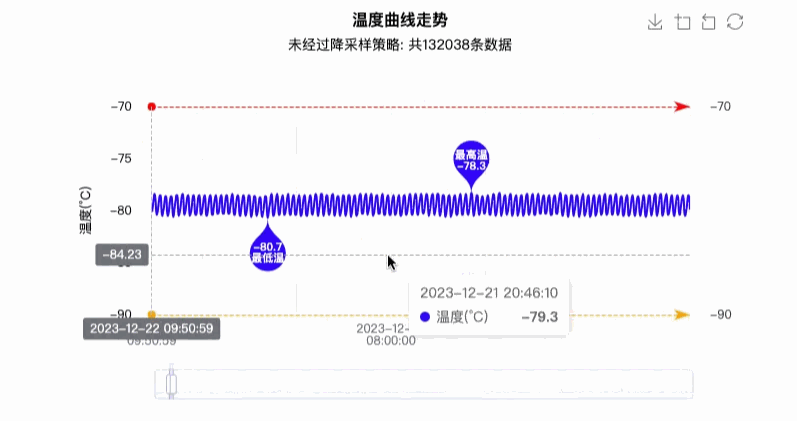
4. 优缺点
以上的这种方案,优缺点很明显,如下几点总结:
优点
可以很好的解决 ECharts 首次进行大数据量渲染造成的卡顿体验问题,不需要额外的数据处理,只需要通过简单的配置 dataZoom 缩放组件就可以实现
缺点
-
无法进行全局概览数据,只能分段查看数据
-
可能需要根据数据量动态的配置属性值,start、end、minSpan 和 maxSpan
四. 方案二:降采样策略
1. 方案简介
ECharts 还提供了另一种提高渲染性能的方式,那就是降采样策略 series-line.sampling,通过配置sampling采样参数可以告诉 ECharts 按照哪一种采样策略,可以有效的优化图表的绘制效率。
折线图在数据量远大于像素点时候的降采样策略,开启后可以有效的优化图表的绘制效率,默认关闭,也就是全部绘制不过滤数据点。
2. 实现步骤
sampling 属性提供了几个可选值,配置不同的值可以有效的优化图表的绘制效率,如下所示:
sampling 的可选值有以下几个:
-
lttb: 采用Largest-Triangle-Three-Bucket算法,可以最大程度保证采样后线条的趋势,形状和极值。 -
average: 取过滤点的平均值 -
min: 取过滤点的最小值 -
max: 取过滤点的最大值 -
minmax: 取过滤点绝对值的最大极值 (从 v5.5.0 开始支持) -
sum: 取过滤点的和
具体方案是配置 series 的 sampling,最终表示使用的是 ECharts 的哪一种采样策略,ECharts 内部机制实现优化策略:
- var option = {
- series: {
- type: "line",
- sampling: "lttb", // 最大程度保证采样后线条的趋势,形状和极值。
- },
- };
以上代码表示使用 'lttb' 降采样策略,实现降低性能消耗的效果。
3. 实际效果
通过配置 series 的 sampling 为 lttb 模式,对比之前的曲线,可以最大程度保证采样后线条的趋势,形状和极值,如下图所示:
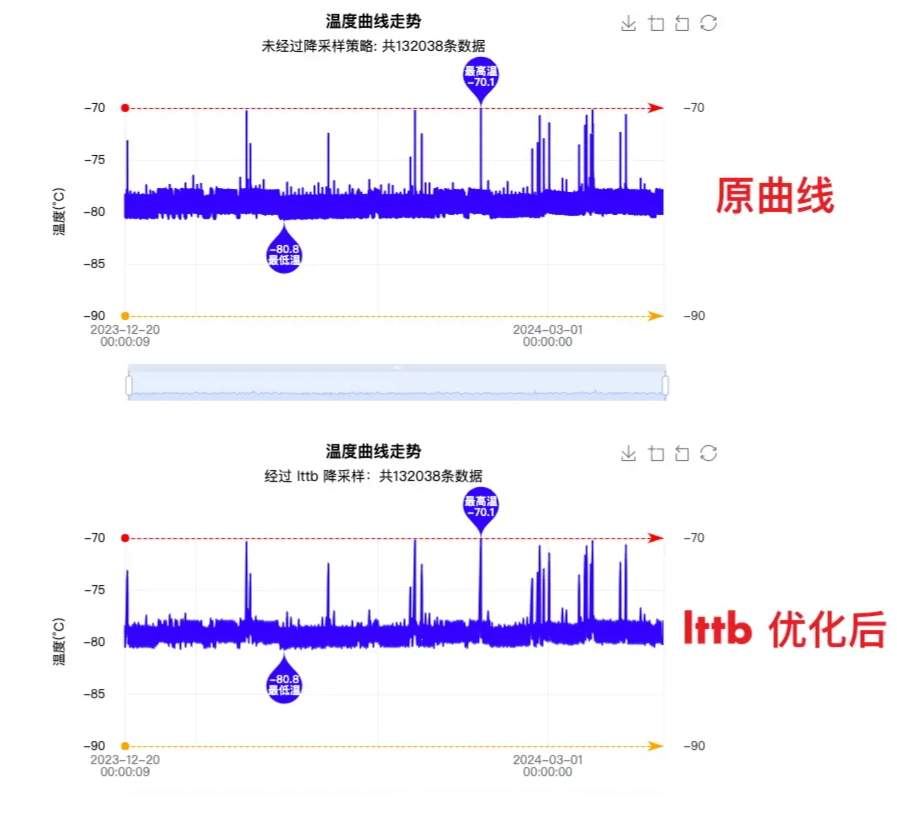
对比之前的效果,可以说是体验效果有质的飞跃,最终实现效果图如下图所示:
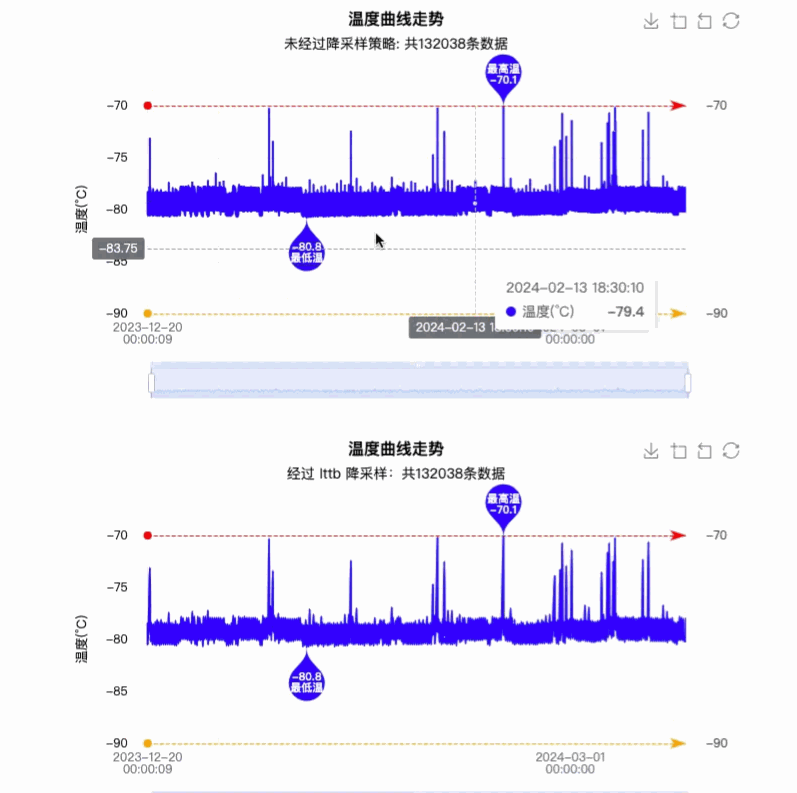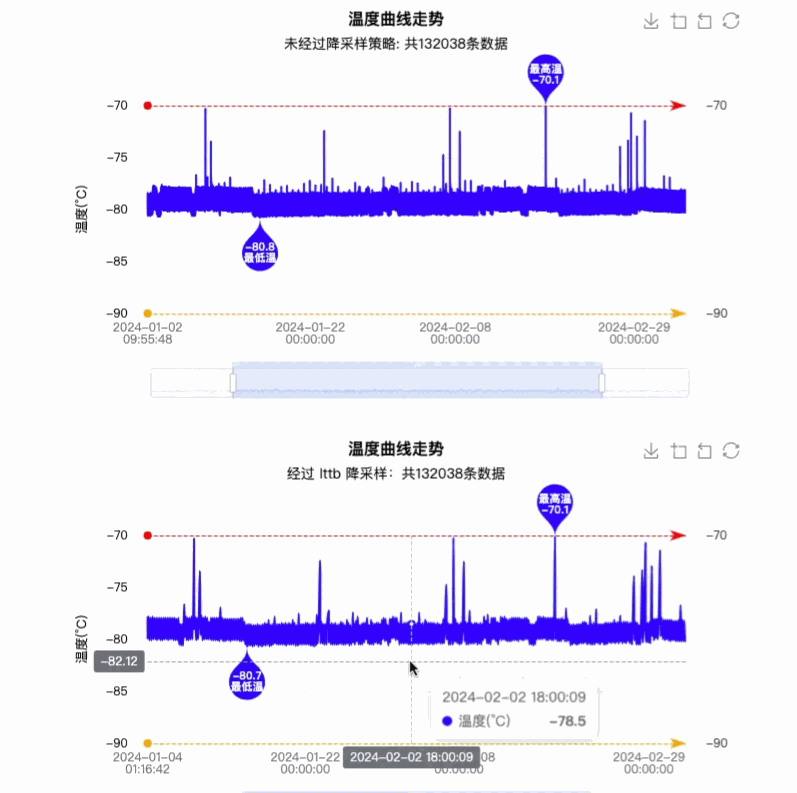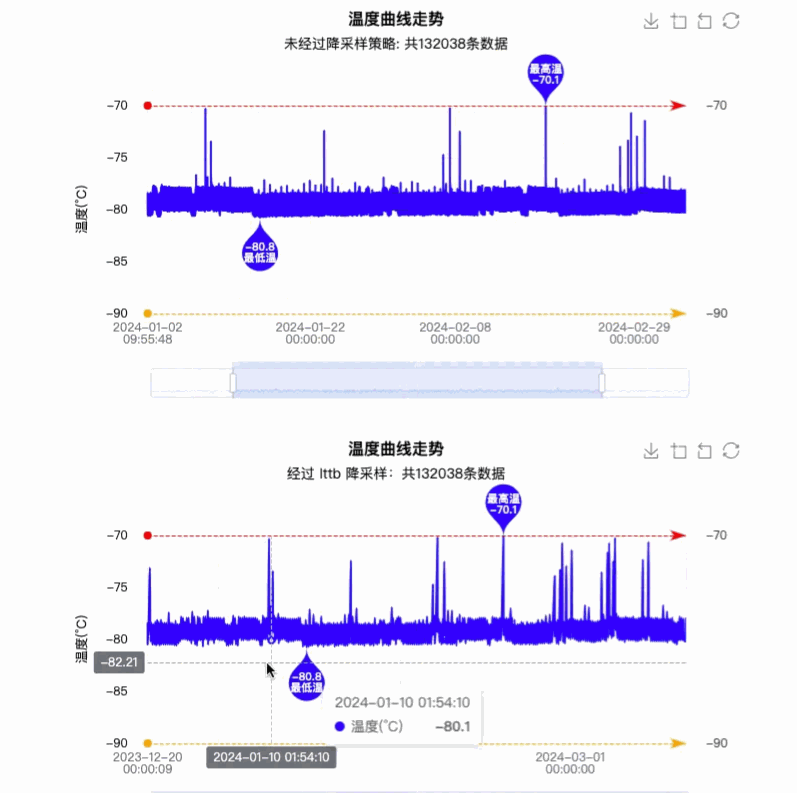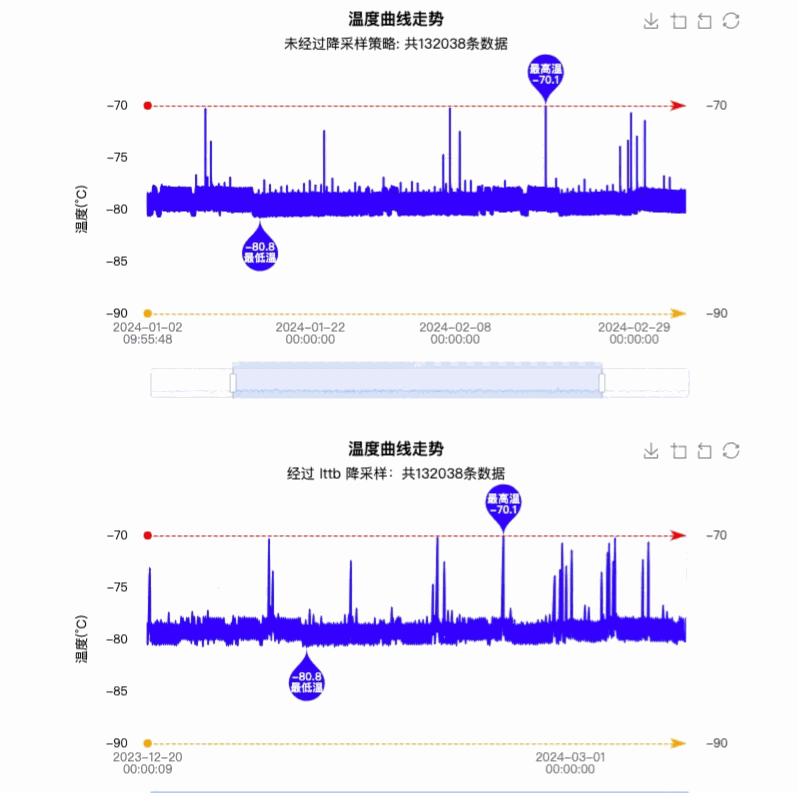
4. 优缺点
优点
-
使用简单,ECharts 内部降采样算法,效果显著
-
可以完整的将曲线趋势展示出来,和原曲线基本一致
缺点
-
并不是展示的所有点,会删除一些无用的点,保证渲染性能
-
最大程度保证采样后线条的趋势,形状和极值,但是某些情况下,极值有偏差,测试中发现
说明:本项目只使用了 lttb 和 minmax 这两种采样策略,相对比来说 lttb 有更流程的性能体验,但是测试中发现在一些情况下,极值出现偏差,也就是最大值最小值显示失误,但是使用 minmax 正常,原因未排查,如下图所示:
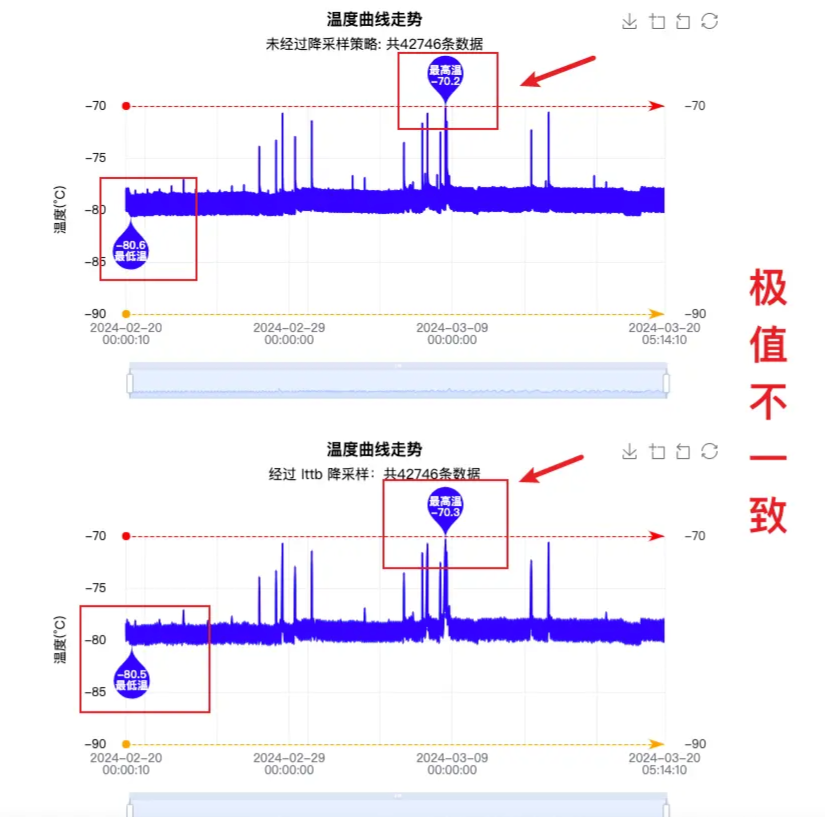
其他的降采样策略并不适合本项目,因此没有进行详细测试,感兴趣的同学可以按需进行研究!
五. 其他拓展
1. 服务器提速
-
优化数据结构,精简数据返回字段,降低数据包大小
-
开启 gzip 压缩,加快海量数据下载速度
2. 数据处理
-
数据聚合:对于特别密集的数据点,使用聚合算法在源头对数据降采样,进行数据聚合,减少渲染的数据点数量。
-
数据过滤:数据中存在一些无关的信息或数据噪音,服务端对数据进行过滤,只需要保留有用的数据即可,剔除无效的数据。
六. 总结
在本篇文章中,我主要介绍了在实际项目开发中,我遇到的 ECharts 渲染十万级+数据的性能优化方案,由此作为文章总结分享出来,主要想和大家交流一下如何解决在海量数据可视化中面临的性能挑战。
在实际应用中,通过数据分段渲染和官方降采样的实现方案,可以看到在优化渲染海量数据时,它们是有效的策略之一。除了以上介绍的方式外,其实还可以结合数据聚合处理、延迟渲染、硬件加速、Web Worker 等多种优化手段,综合运用以实现更高效的海量数据可视化展示。
渲染十万级+的数据量是一个挑战性的任务,但通过合理的优化方案和技巧,可以提升页面性能,改善用户体验,实现数据可视化的更好展示效果。
本篇文章是在实际项目中的一些实践以及思考,对于 ECharts 海量数据的渲染性能优化,还有更多的可能性,也还有更多优秀的实现方案。如果你有更好的实现方案,欢迎分享交流。
七. 参考资源文档链接
-
ECharts dataZoom 配置文档:https://echarts.apache.org/zh/option.html#dataZoom
-
ECharts series-line.sampling 降采样:https://echarts.apache.org/zh/option.html#series-line.sampling
-
ECharts 分片加载数据和增量渲染:https://echarts.apache.org/zh/api.html#echartsInstance.appendData
如果你有更好的实现方案,欢迎评论区讨论!

 微信公众号
微信公众号

评论记录:
回复评论: