
前言
2024 年,作者全身心投入计算机视觉领域的研究,其中目标检测方向成为重点攻坚领域。在这一年中,围绕 YOLO 系列模型展开了一系列深入实验,积极探索模型优化策略,力求在实际应用中开拓全新思路。
计算机视觉(Computer Vision,CV)作为人工智能(AI)的重要分支,其核心目标是让计算机学会理解和解析图像、视频以及各类视觉数据,从而模拟并延伸人类的视觉感知能力。如今,计算机视觉技术已广泛渗透到各个领域。从自动驾驶的智能决策,到医疗影像分析的精准诊断;从安防监控的实时预警,到智能零售的个性化服务;从虚拟现实(VR)与增强现实(AR)的沉浸式体验,都离不开计算机视觉技术的强力支撑。
计算机视觉的核心步骤
计算机视觉致力于赋予计算机类似人类的视觉理解能力,这一复杂过程通常包含以下几个紧密相连的关键步骤:
-
图像获取:利用摄像头、传感器等设备收集图像或视频数据,这些原始数据是后续所有处理的源头,数据的质量和多样性直接影响着最终的分析结果。
-
图像处理与特征提取:对采集到的原始图像进行预处理,去除噪声、增强对比度等,随后运用各种算法提取图像中的关键特征,这些特征如同图像的 “指纹”,是计算机理解图像内容的关键依据。
-
图像分析:基于提取出的特征,开展目标识别、分类、分割、跟踪等任务,深入挖掘图像中隐藏的信息,将图像内容转化为有意义的知识。
-
决策与应用:根据图像分析的结果做出决策,并将其应用到实际场景中,如自动驾驶中根据交通标志识别结果进行驾驶决策,安防监控中基于目标跟踪结果发出警报,医疗领域依据病变识别结果辅助诊断治疗等。
计算机视觉的核心任务
计算机视觉的核心任务丰富多元,涵盖了多个关键领域:
-
目标检测:目标检测不仅要识别出图像或视频中存在的物体类别,如行人、车辆、动物等,还要精确确定每个物体的具体位置,通常采用边界框的方式进行标注。在智能安防监控系统中,目标检测技术能够快速准确地捕捉到异常人员或物体,为安全防范提供有力保障。基于卷积神经网络(CNN)的 YOLO(You Only Look Once)系列、Faster R-CNN 等算法是目前目标检测领域的常用方法。
-
图像分类:将整幅图像归入预定义的类别集合,判断其所属类别,例如判断一张图片是宠物猫、宠物狗,还是风景图、人物照等。早期的图像分类主要依赖手工设计的特征和传统机器学习算法,而随着深度学习的发展,CNN 模型凭借强大的自动特征学习能力,在图像分类任务中取得了突破性进展,AlexNet、VGG、ResNet 等经典网络结构已成为该领域的标杆。
-
图像分割:把图像分割成多个具有语义意义的区域,每个区域对应图像中的特定物体或背景部分。根据分割的粒度和目标不同,可细分为语义分割(将图像中每个像素分类到特定类别)、实例分割(不仅区分不同类别,还区分同一类别的不同实例)和全景分割(融合语义分割和实例分割)。在医学影像分析中,图像分割技术可精确勾勒出病变组织;在自动驾驶场景中,能够清晰分割出道路、车辆、行人等不同对象。常见的图像分割方法包括全卷积网络(FCN)、Mask R-CNN 等。
-
目标跟踪:在视频序列中持续追踪特定目标物体的位置和状态变化。在体育赛事转播中,目标跟踪技术可自动追踪运动员的运动轨迹,为观众提供精彩的赛事回放;在自动驾驶场景中,对前方车辆、行人等目标进行实时跟踪,为车辆的安全行驶提供关键信息。目标跟踪算法通常结合目标检测结果,综合利用物体的外观特征、运动信息等实现对目标的持续追踪。
-
三维重建:通过获取多个视角的图像信息,恢复场景或物体的三维结构,构建出具有立体感的三维模型。这一技术在虚拟现实(VR)、增强现实(AR)、自动驾驶环境感知以及文物数字化保护等领域发挥着重要作用。例如,利用多视角图像重建古建筑的三维模型,既有助于文物的保护与修复,也为文化传承提供了新的方式。
-
图像理解与语义分析:这是计算机视觉中较为高级的任务,旨在让计算机不仅能识别图像中的物体,还能理解图像所表达的语义内容和场景含义,甚至生成自然语言描述。图像字幕生成(Image Captioning)就是一个典型应用,它能根据图像内容自动生成一段描述性文本,如 “一个男孩在公园里放风筝”,这一过程涉及计算机视觉与自然语言处理的深度融合,为跨领域研究开辟了新的方向。
计算机视觉的实现依赖于两个基本要素:特征提取和目标识别。这两个要素相互协作,使计算机能够对视觉数据进行有效解释和响应,从而实现各种复杂的视觉任务。
特征提取
特征提取是一个复杂且精细的过程,旨在从原始数据中精准识别并提取出能够定义对象的独特属性。这些属性涵盖了边缘、角落、纹理、形状以及运动模式等多个关键维度 。其中,边缘是图像中灰度值发生急剧变化的区域,能够勾勒出物体的轮廓;角落则是两条边缘的交汇点,在图像匹配和目标定位中发挥着重要作用;纹理反映了图像中局部区域的重复模式,有助于区分不同材质的物体;形状是物体的几何形态,为识别物体类别提供关键线索;而运动模式则主要应用于视频数据,用于追踪目标物体的动态变化。
这些属性对于机器理解视觉数据起着不可或缺的作用,是计算机视觉系统实现准确分析和决策的基石。在这一过程中,算法扮演着至关重要的角色。不同的特征提取算法,如经典的 SIFT(尺度不变特征变换)、HOG(方向梯度直方图)以及基于深度学习的卷积神经网络(CNN)算法等,各自基于独特的原理和数学模型,将原始的、复杂的视觉数据转化为计算机易于处理和理解的特征表示。它们通过对数据进行筛选、变换和抽象,去除冗余信息,保留关键特征,从而极大地简化了数据,提升了计算机处理数据的效率和准确性,为后续的目标检测、图像分类、图像分割等计算机视觉任务奠定了坚实基础。
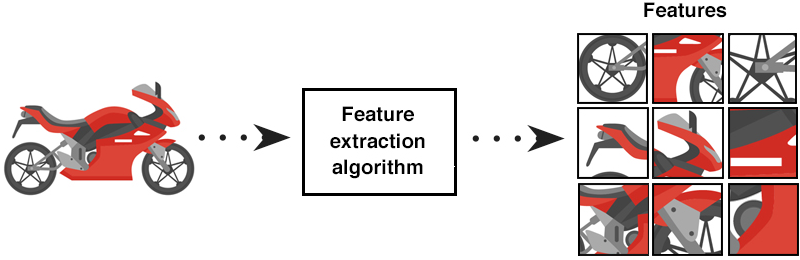
目标识别
目标识别(Object Recognition)是计算机视觉领域的一个重要任务,涉及到检测和识别图像或视频中的特定物体或类别。对象识别技术广泛应用于自动驾驶、图像搜索、安防监控、医疗图像分析等领域。
对象识别通常分为以下几个子任务:
1. 物体检测(Object Detection)
目标是检测图像中的所有目标物体,并为每个物体生成一个边界框(bounding box)。物体检测不仅需要识别物体的类别,还需要定位物体在图像中的位置。常用的算法包括:
2. 物体分类(Object Classification)
任务是识别图像中物体的类别,但不需要考虑物体的位置。一般来说,物体分类任务会根据图像的内容来分配一个标签,例如 “猫”,“狗” 等。常见的模型包括:
3. 物体分割(Semantic Segmentation / Instance Segmentation)
-
语义分割(Semantic Segmentation)目标是为每个像素分配一个类别标签,所有同类物体像素属于同一类别。
-
实例分割(Instance Segmentation)在语义分割的基础上进一步区分不同实例,即不同的物体。
4. 物体追踪(Object Tracking)
在视频流中,物体追踪关注在连续帧中跟踪某个物体的运动。追踪算法通常基于物体的检测结果进行,但它们在追踪时可能不需要重新检测每一帧。常见的算法包括:
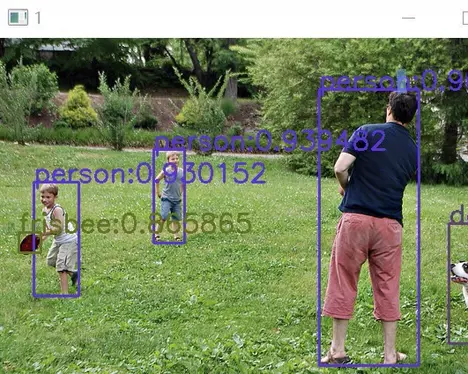
算法和模型
1. 目标检测(Object Detection)
目标检测是计算机视觉中的一个重要任务,旨在识别图像中多个物体的类别和位置(通常表示为边界框)。目标检测不仅要判断图像中有哪些物体,还要为每个物体提供一个定位框。
常见的目标检测框架:
-
R-CNN(Regions with CNN Features):
-
简介:R-CNN 将图像分成多个候选区域(Region Proposals),然后对每个区域使用卷积神经网络(CNN)提取特征,最后通过分类器(如 SVM)进行分类。
-
优点:高精度,适用于较小的物体检测。
-
缺点:计算量大,速度慢,处理复杂场景时效率较低,且每个候选区域都需要单独计算特征。
-
-
Fast R-CNN:
-
简介:Fast R-CNN 改进了 R-CNN 的方法,使用 ROI 池化(Region of Interest Pooling)来减少计算量,避免了对每个候选区域都要运行 CNN 的冗余计算。
-
优点:计算效率比 R-CNN 更高,速度更快,减少了训练和推理时的计算资源消耗。
-
缺点:仍然需要外部区域提议算法,速度相较于 YOLO 等方法仍然不够快,适合于精度要求较高的场景。
-
-
Faster R-CNN:
-
简介:Faster R-CNN 进一步改进了 Fast R-CNN,通过引入区域提议网络(RPN,Region Proposal Network),将候选区域生成与物体检测整合在一起,从而大幅提升了速度。
-
优点:更高效,无需外部的区域提议算法,速度更快,精度更高,成为最流行的目标检测框架之一。
-
缺点:虽然速度较快,但与 YOLO、SSD 相比,仍然较慢,计算复杂度较高,且在复杂背景下可能表现不如预期。
-
-
YOLO(You Only Look Once):
-
-
简介:YOLO 是一种基于回归的方法,它将目标检测问题转化为一个单一的回归问题,通过一个神经网络同时预测多个边界框和物体类别。
-
优点:速度极快,适合实时检测,并且能够处理多个物体的同时检测,适合动态场景下的检测。
-
缺点:对于小物体的检测精度较低,因为它使用全局特征进行预测,容易错过细节,尤其在高密度环境下效果差。
-
-
SSD(Single Shot MultiBox Detector):
-
简介:SSD 通过在不同尺度的特征图上进行预测,结合多尺度信息,增强了对不同大小物体的检测能力。
-
优点:具有较高的检测速度和精度,能够有效地平衡速度和精度,尤其在中等大小的物体检测上表现优异。
-
缺点:在非常小的物体上表现稍逊色,因为它对小物体的感受野较小,可能导致误检或漏检。
-
-
RetinaNet:
-
简介:RetinaNet 使用 Focal Loss 来解决目标检测中的类别不平衡问题,尤其对于小物体的检测具有较好的性能。
-
优点:解决了 YOLO 和 SSD 在类别不平衡问题上的缺陷,在小物体和长尾类别的检测上表现较好。
-
缺点:相比 YOLO,其速度稍慢,适合处理较为复杂的场景,但实时性要求较高时可能不如 YOLO。
-
2. 图像分割(Image Segmentation)
图像分割的任务是将图像分成多个部分(通常是物体或区域),每个部分可以是图像的一个语义区域。它包括语义分割和实例分割。
常见的图像分割框架:
-
FCN(Fully Convolutional Network):
-
简介:FCN 是第一个将卷积神经网络扩展到像素级分割的网络。通过使用全卷积层替代传统 CNN 中的全连接层,FCN 能够处理任意大小的输入图像,并输出每个像素的类别。
-
优点:适合语义分割任务,能够进行像素级别的预测,适用于各种大小和形状的物体。
-
缺点:无法处理实例分割任务,即无法区分同类的不同实例,因此在复杂场景下表现有限。
-
-
U-Net:
-
简介:U-Net 是一种针对医学图像分割设计的网络结构,它使用编码器 - 解码器结构,通过跳跃连接(skip connections)来增强低级特征与高级特征之间的融合。
-
优点:在小样本数据集上也能获得良好的分割效果,尤其适用于医学图像分割,能够较好地处理不均匀的图像分布。
-
缺点:对于大规模数据集的泛化能力较弱,可能会在多样化数据集上表现较差。
-
-
Mask R-CNN:
-
简介:Mask R-CNN 是一个结合目标检测和图像分割的框架,它在 Faster R-CNN 的基础上增加了分支用于生成每个物体实例的分割掩码(mask),实现了实例分割。
-
优点:能够同时进行目标检测和实例分割,精度高,适用于复杂场景中的精细物体分割。
-
缺点:速度相对较慢,需要较高的计算资源,尤其是在大规模数据集和高分辨率图像上计算负担较重。
-
-
DeepLab:
-
简介:DeepLab 系列采用空洞卷积(dilated convolution)来扩大感受野,同时避免了池化操作丢失空间信息,能够更精确地进行图像分割。
-
优点:在语义分割任务上表现优异,尤其是在复杂背景的分割任务中,能够有效保留图像的空间信息。
-
缺点:模型较大,推理速度较慢,计算资源消耗较大,且在实时应用中的表现有限。
-
-
SegNet:
-
简介:SegNet 也是一种编码器 - 解码器结构,用于语义分割。它的特点是通过最大池化索引来实现解码过程,提高了分割效果。
-
优点:在某些小数据集上具有较好的分割效果,特别是在较为简化的图像数据上。
-
缺点:与 U-Net 相比,表现稍逊色,尤其在大规模数据集上,可能会受到网络结构限制,处理能力不如 U-Net。
-
3. 姿态估计(Pose Estimation)
姿态估计的目标是推断图像中物体或人体的空间位置、方向和姿势,广泛应用于人体姿态估计、物体姿态估计等任务。
常见的姿态估计框架:
-
OpenPose:
-
简介:OpenPose 是一种基于卷积神经网络的人体姿态估计框架,能够检测和追踪人体关键点的二维坐标。
-
优点:能够实时检测人体的关键点,如头部、肩膀、肘部、膝盖等,对于人体行为分析、动作识别等任务非常有效。
-
缺点:对于遮挡、复杂背景的处理相对较差,尤其在多人场景下,精度会受到影响。
-
-
AlphaPose:
-
简介:AlphaPose 是一种高精度的多人姿态估计方法,采用了更深的网络结构和创新的多尺度方法来提高检测精度。
-
优点:精度高,尤其是在多人复杂场景下的姿态估计,能更好地处理多人重叠或遮挡问题。
-
-
缺点:计算资源需求较高,速度较慢,对于实时应用不太适合。
-
HRNet:
-
简介:HRNet 是一种高分辨率网络,它通过维持高分辨率的特征图进行多分辨率的特征融合,从而提高姿态估计的精度。
-
优点:高精度,在人体姿态估计中表现非常出色,能够在复杂场景下保持较高的精度。
-
缺点:相较于传统方法,它需要更大的计算资源,且计算量较大,适用于高性能硬件。
-
-
PoseNet:
-
简介:PoseNet 主要用于单张图片的物体或人体的姿态估计,能高效估算物体的位姿(位置和朝向)。
-
优点:较快且精度较高,适用于实时应用,尤其是手机或边缘设备上的应用。
-
缺点:对复杂环境或大规模数据集的适应性较差,可能无法有效处理非常复杂的场景或多物体交互的情况。
-
2025 年计算机视觉的热门方向预测
生成式人工智能
自 2022 年 OpenAI 发布 ChatGPT 以来,生成式人工智能(Generative AI)逐渐成为技术领域的焦点。生成式人工智能能够根据文本、图像、音频、视频等多种输入形式,创作出高质量的文本、图像、音频和视频内容。利用生成对抗网络(GANs)和扩散模型(Diffusion Models)等技术,生成式人工智能不仅能生成高度逼真的数据,还能够产生创新性内容。
到了 2025 年,生成式人工智能将在多个领域发挥重要作用,尤其在娱乐相关特征,并捕捉图像的全局上下文。
与传统的卷积神经网络(CNNs)相比,ViTs 在多个基准测试中展现出了更高的准确性,特别是在图像分类和目标检测任务中。它们能够捕捉像素之间的复杂关系,使得在医疗成像、自动驾驶和工业自动化等高精度应用中具有广泛的应用潜力。ViTs 提供了更好的可扩展性和适应性,能够高效地处理大规模数据集,且需要更少的资源,这使得其在资源受限的边缘设备上也能发挥出色的性能。
多模态人工智能集成
多模态人工智能通过同时处理和集成多种数据类型,如文本、图像、视频和音频,为基于上下文的决策提供支持。在计算机视觉领域,多模态集成使视觉系统能够整合来自文本、语音命令或环境传感器等非视觉源的数据。
随着对机器学习理解更接近人类的需求增加,多模态人工智能正在迅速发展。人类依靠视觉、听觉和语言来全面理解信息,类似地,多模态人工智能系统能够融合多种感知方式,使其在医疗、自主系统、客户服务和智能设备等领域得到广泛应用。在医疗诊断中,结合医学影像和患者病历文本信息,能更准确地判断病情;自动驾驶汽车通过融合摄像头图像、雷达数据和地图信息,提升行驶安全性和决策准确性。
视觉系统对深度伪造人工智能的检测
深度伪造技术利用人工智能生成极具欺骗性的音视频内容,这些内容能够展示虚假的场景或人物,甚至是不存在的人物,给媒体、政治甚至个人安全带来了重大挑战。随着深度伪造工具的不断进步,检测这些伪造内容的需求日益增长。
到 2025 年,计算机视觉将在新闻、金融、执法等行业发挥越来越重要的作用,帮助验证数字内容的真实性,确保信息的可信度。预计随着对深度伪造的关注增多,相关法律和技术将得到加强,计算机视觉将成为打击这一问题的重要工具。基于卷积神经网络的检测模型能够识别图像和视频中的细微痕迹,判断其是否为深度伪造,未来还可能结合区块链技术,为数字内容提供不可篡改的溯源信息。
沉浸式体验中的 3D 视觉与深度感应
三维计算机视觉涉及图像处理和分析三维视觉数据,包括结构光、飞行时间传感器和立体视觉等技术。这些技术能够创建详细的三维环境地图,推动虚拟现实(VR)、增强现实(AR)和机器人技术的突破。
随着对更引人入胜、互动性更强的数字体验需求增加,3D 视觉技术正成为推动元宇宙、自动驾驶和增强现实导航等领域的重要力量。通过提供精准的空间感知能力,3D 视觉技术正在为沉浸式体验提供基础。在元宇宙中,用户能够借助 3D 视觉技术获得更加真实的虚拟环境交互体验;自动驾驶汽车利用 3D 视觉实现更精确的环境感知,提高自动驾驶的安全性和可靠性。
实时处理的边缘人工智能设备
边缘人工智能(Edge AI)结合了人工智能和边缘计算,使得数据在接近源头的地方进行处理,避免了将所有数据上传到远程云服务器的需求。这一技术可在无需延迟的情况下实现实时处理,特别是在实时监控、自动驾驶和工业自动化等领域。
边缘人工智能的兴起不仅降低了延迟,还能提高数据处理效率,特别适用于物联网(IoT)环境中的大规模数据流。随着对快速、安全视觉系统需求的增加,边缘人工智能设备将在日益互联的世界中发挥越来越重要的作用。在智能工厂中,边缘 AI 设备能够实时分析生产线上的图像数据,检测产品缺陷;在智能安防监控中,实现对异常行为的实时预警,减少数据传输成本和隐私风险。
零样本学习与少样本学习
零样本学习(Zero-shot learning)使得人工智能能够识别从未见过的物体,而少样本学习则依赖少量样本(通常只有一到五个样本)进行训练。这两项技术减少了对大量数据集的需求,成为小样本应用领域的关键突破。
这类技术的重要性在于,它们降低了对大量标注数据的依赖,从而减少了成本并加快了模型部署的速度,对创业公司和特殊行业尤为重要。在文物保护领域,零样本学习可以帮助识别罕见文物;在医疗影像分析中,少样本学习能够基于少量病例数据进行疾病诊断模型的训练,提高医疗服务的效率和覆盖范围。

 QQ群名片
QQ群名片

评论记录:
回复评论: