
Pytorch版本的模型推理速度有限,为了提高检测速率,使用TensorRT部署。
注意:tensorrt转换出来的模型实际上是和硬件绑定的,也就是在部署的过程中,如果你的显卡和显卡相关驱动软件(cuda、cudnn)发生了改变,那么模型就得需要重新做转换。
1)克隆TensorRT代码
首先克隆TensorRT编译YOLOv5的代码
git clone https://github.com/wang-xinyu/tensorrtx.git
- 1
可以看到TensorRT文件夹中包含编译多种神经网络的文件,只保留yolov5文件夹,如图:
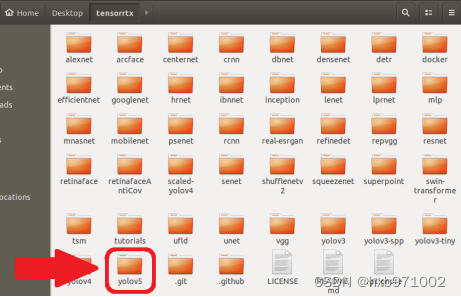
图22- 38 TensorRT文件夹
2)模型转换
在tensorrtx/yolov5文件夹中可找到gen_wts.py,该脚本可将Pytorch模型(.pt格式)转换成权重文本文件(.wts格式)。将gen_wts.py拷贝到{ultralytics}/yolov5文件夹中,并在此文件夹中打开终端,输入
python gen_wts.py -w best.pt -o 713best.wts
- 1
`` 
图22- 39 模型转换
这样就在{ultralytics}/yolov5文件夹中生成了best.wts文件。
3)修改yololayer.h参数
打开tensorrtx\yolov5文件夹,找到yololater.h文件,修改CLASS_NUM,使其与pytorch模型一致: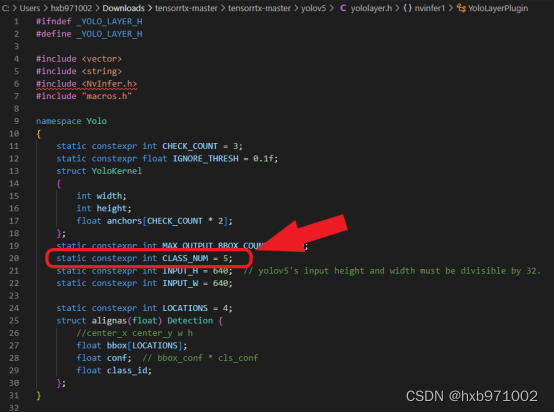
图22- 40 修改yololayer.h参数
4)编译并生成引擎文件
终端依次输入下列指令,可在tensortrtx/yolov5目录下新建build文件夹
cd work/tensorrtx/yolov5
mkdir bulid
- 1
- 2
将上一步生成的713best.wts拷贝到build文件夹下,再依次输入下列指令对其进行编译
cmake ..
make
- 1
- 2
图22- 41 编译713best.wts文件_cmake
图22- 42 编译713best.wts文件_make
再输入下列指令,可使用713best.wts生成713best.engine,注意末尾的n代表模型尺度,可选项有n/s/m/l/x/n6/s6/m6/l6/x6 or c/c6 gd gw,必须与pytorch模型一致:
sudo ./yolov5 -s 713best.wts 713best.engine n
- 1

图22- 43 生成engine文件
5)进行检测
输入下列指令,可对指定路径下的图片进行检测,这里的图片路径是…/samples:
sudo ./yolov5 -d 713best.engine ../samples
- 1

图22- 44 图片检测
与使用Pytorch模型检测所耗时间(55ms80ms)进行对比,TensorRT加速后单幅图片耗时明显缩短(17ms27ms)。

图22- 45 检测结果
评论记录:
回复评论: