

引言
Attention model(AM)最先在计算机视觉中被应用于图片识别的问题,之后在自然语言处理(NLP)和计算机视觉(CV)中经常结合递归神经网络结构RNN、GRU、LSTM等深度学习算法,被称之为Recurrent Attention Model(RAM),其核心就是一个Encoder-Decoder的过程。
传统的Encoder-Decoder模型例如RNN在做文本翻译是把一个输入语句(x1,x2,...,xi
Encoder-Decoder模型
传统RNN的Encoder-Decoder模型是没有注意力权重的,下图是文本处理领域里常用的Encoder-Decoder框架最抽象的一种表示:
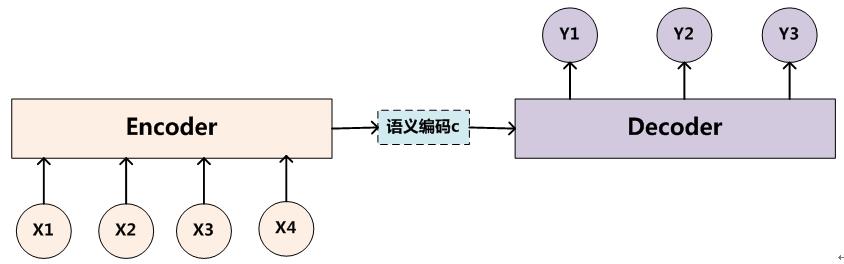
Encoder-Decoder框架可以这么直观地去理解:可以把它看作适合处理由一个句子(或篇章)生成另外一个句子(或篇章)的通用处理模型。对于句子对
class="MathJax_Display" style="text-align: center;">
评论记录:
回复评论: