
目录
1 模型微调代码实例:
本节我们要做的就是只使用tokenizer和model来做一个文本分类(酒店好评、差评)的解决方案。

2 数据集:
label,review:好评为1,差评为0


3 步骤:
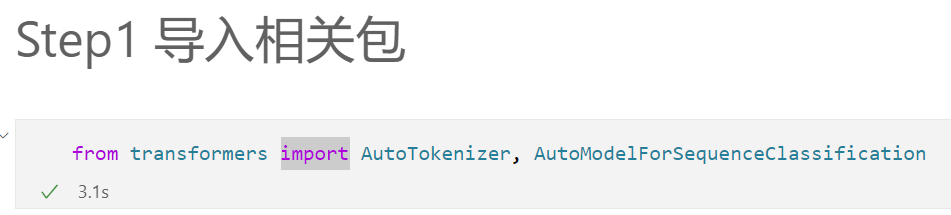
3.1 导包:
3.2 导入数据:
处理csv数据一般会使用python的panda这个库
Pandas是一个在Python中非常流行的数据处理和分析库。它提供了高效的数据结构和数据分析工具,使得在Python中进行数据操作变得更加简单和灵活。
以下是Pandas库的一些主要功能和特点:
数据结构:Pandas提供了两个主要的数据结构:Series和DataFrame。
- Series是一维标记数组,类似于带有索引的数组或列。它可以容纳不同类型的数据,并具有许多方便的方法和函数。
- DataFrame是一个二维表格数据结构,由多个Series组成。它类似于电子表格或关系型数据库表,可以方便地处理和操作结构化数据。
数据导入和导出:Pandas支持从各种数据源(如CSV、Excel、数据库、JSON等)导入数据,并提供了简单的API来将数据导出为不同的格式。
数据清洗和处理:Pandas提供了广泛的数据清洗和处理功能,包括数据过滤、排序、删除重复值、填充缺失值、数据转换、重塑和合并等操作。这些功能使得数据预处理变得更加高效和方便。
数据分析和统计:Pandas提供了丰富的统计和聚合函数,可以对数据进行各种分析和计算。例如,你可以计算平均值、总和、标准差,进行分组和透视表操作,执行时间序列分析等。
数据可视化:Pandas结合了Matplotlib等可视化库,可以方便地进行数据可视化。它提供了简单易用的绘图函数和工具,可以创建直方图、折线图、散点图等常见的图表,帮助用户更好地理解和展示数据。
高性能和内存优化:Pandas通过使用NumPy数组和优化的算法,提供了高性能的数据操作。它还针对大型数据集的内存使用进行了优化,可以高效地处理大量数据。

3.3 数据清洗(dropna):
由于数据量较大,因此在使用之前,我们有必要做一个空数据删除处理:
dropna()是DataFrame对象的一个方法。dropna()方法用于删除包含缺失值(NaN)的行或列,并返回一个新的DataFrame对象,其中已删除了缺失值。
处理前:
![]()
处理后:
![]()
说明里面真的是有一个空数据。
3.4 创建数据集:
为了在训练模型时加载和处理数据,我们需要对导入的数据进行处理,创建自己的数据集:
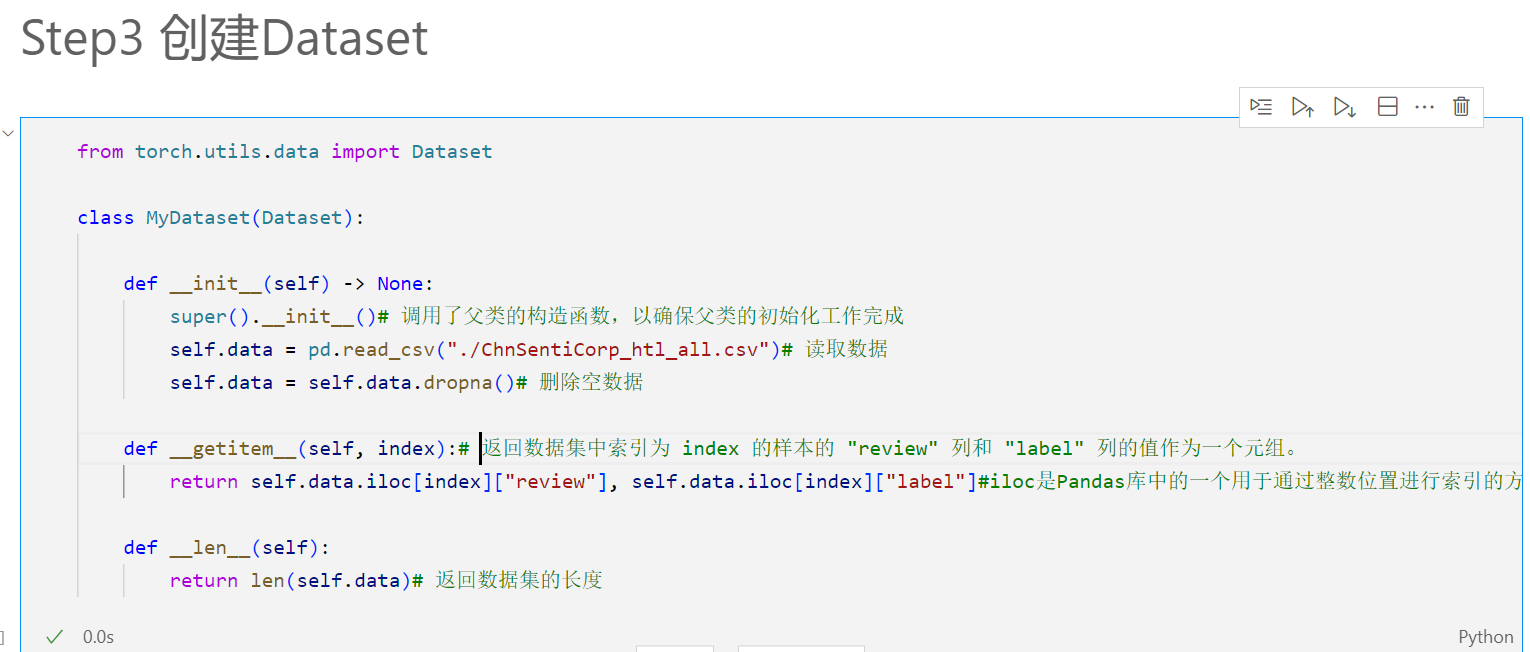
torch.utils.data.Dataset是PyTorch中的一个抽象类,用于表示数据集的抽象接口。它定义了用于访问数据集的方法和属性,包括__getitem__()和__len__()等。因此我们要先引入这个。然后对继承的父类的属性和方法进行修改和扩展。
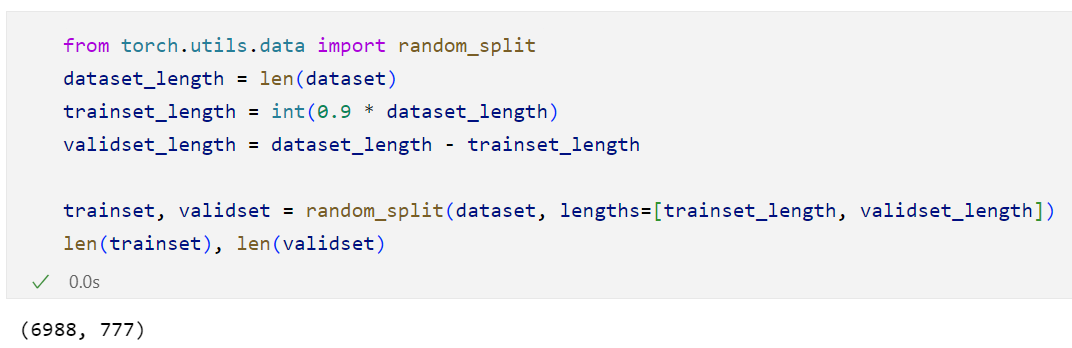
3.5 划分数据集:
pytorch1.13的版本支持通过小数比例划分:

以前的版本可以使用具体长度来划分:
3.6 创建Dataloader:
为了更方便地对数据进行批量处理和迭代,我们需要创建DataLoader,它可以将数据集封装成一个可迭代的对象,使得我们可以按批次加载和处理数据。这里的shuffle是指进行随机化处理

这个代码我们得到的结果是:


可以看到只执行这个操作后,我们得到的labels确实是一个张量tensor了,方便我们后续在PyTorch模型中直接进行使用,但是reviews确实仍然是原始的形式,因此我们要想办法对reviews进行处理。
既然Dataloader本身的聚合collate_fn没办法达到预期的效果,那么我们就自己写一个这个聚合函数。同时对数据进行Tokenizer处理
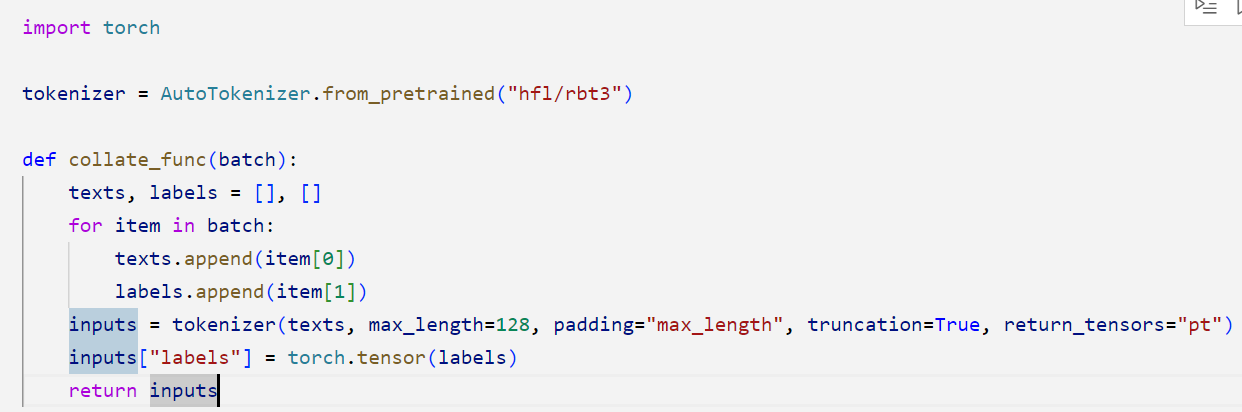
我们可以看到现在打印的结果就是一个list了
 在进行tokenizer处理之后,我们就可以得到如下结果:
在进行tokenizer处理之后,我们就可以得到如下结果:
3.7 创建模型及优化器:
首先导入文本分类模型,接着创建优化器,由于我们做的是迁移学习(是在已有模型的基础上,所以学习率不宜设的过高),有GPU的话可以采用GPU训练
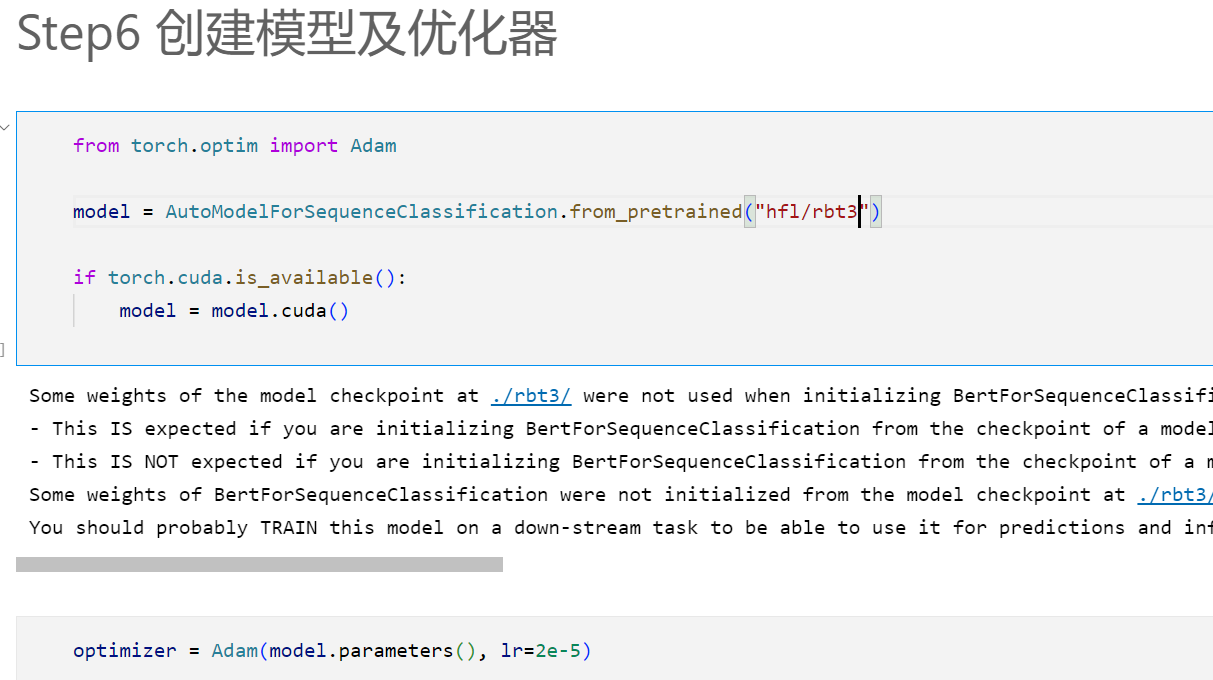
optimizer = Adam(model.parameters(), lr=2e-5)这行代码创建了一个使用 Adam 优化算法的优化器,并将模型的参数传递给该优化器进行参数更新。具体解释如下:
model.parameters():这部分代码获取了模型中需要进行优化的参数。model.parameters()返回一个包含了模型中所有可学习参数的迭代器或生成器。这些参数包括模型的权重(weights)和偏置(biases)等。这些参数将在训练过程中通过优化器进行更新。
Adam():这是用于创建 Adam 优化器的函数。Adam是一种常用的优化算法,特别适用于深度学习模型的训练。它结合了动量(momentum)和自适应学习率机制,能够有效地调整参数更新的步长。
lr=2e-5:这是学习率(learning rate)的设置。学习率决定了参数在每次更新中的调整步长。在这个例子中,学习率被设置为2e-5,即0.00002。较小的学习率可以使参数更新更加稳定,避免过大的调整。
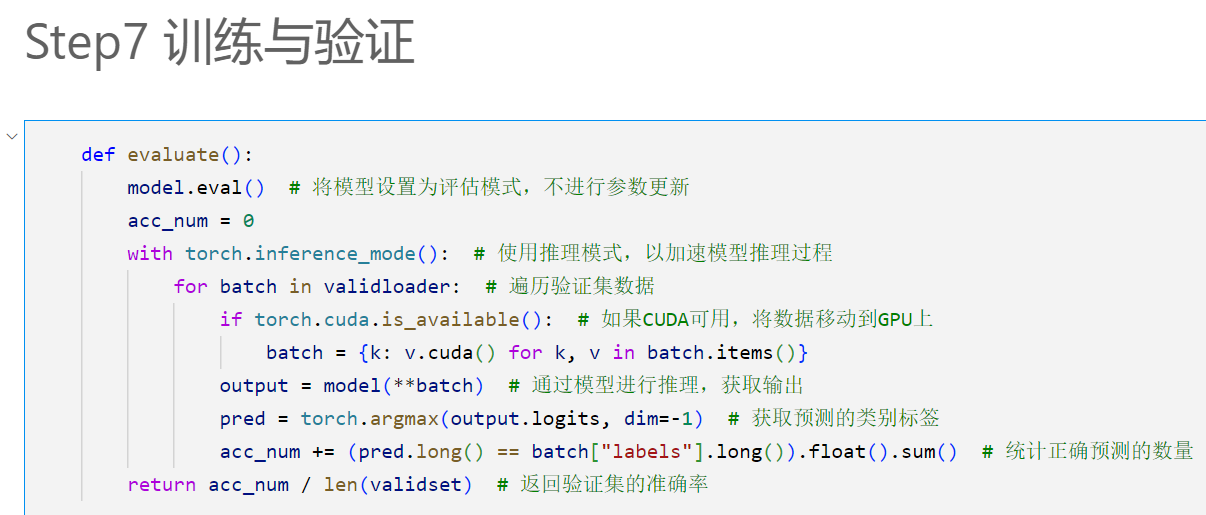
3.8 训练与验证:

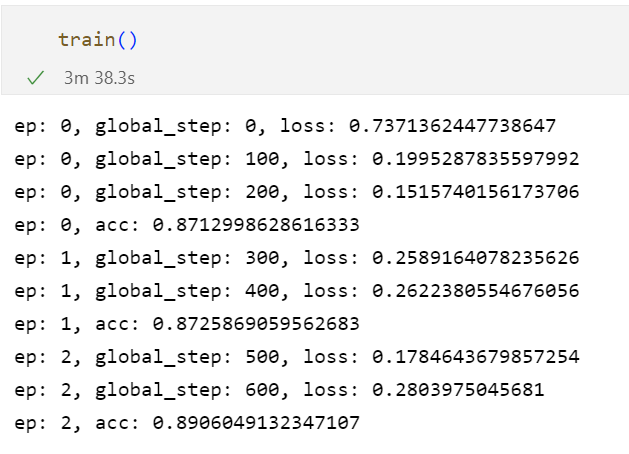
3.9 模型训练:
可以看到,经过三个epoch,accuracy确实是在逐步提升的。
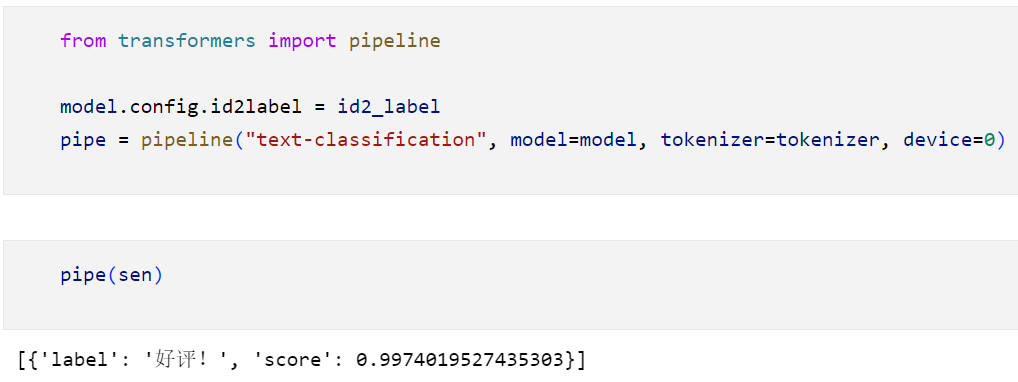
3.10 模型预测:


可以使用pipeline简便一下:
评论记录:
回复评论: