
目录
8.7 语音版语言模型的代表性技术
9 语音版语言模型的关键技术挑战——背景音与噪声的干扰
16 语音交互与文字交互的本质区别——两大核心挑战
0 完整章节内容
本文为李宏毅学习笔记——2024春《GENERATIVE AI》篇——“Extra lesson”章节的课堂笔记,完整内容参见:
李宏毅学习笔记——2024春《GENERATIVE AI》篇
本章节主要浅谈“GPT-4o背后可能的语音技术猜测”。

1 GPT-4 的语音模式(Voice Mode)
-
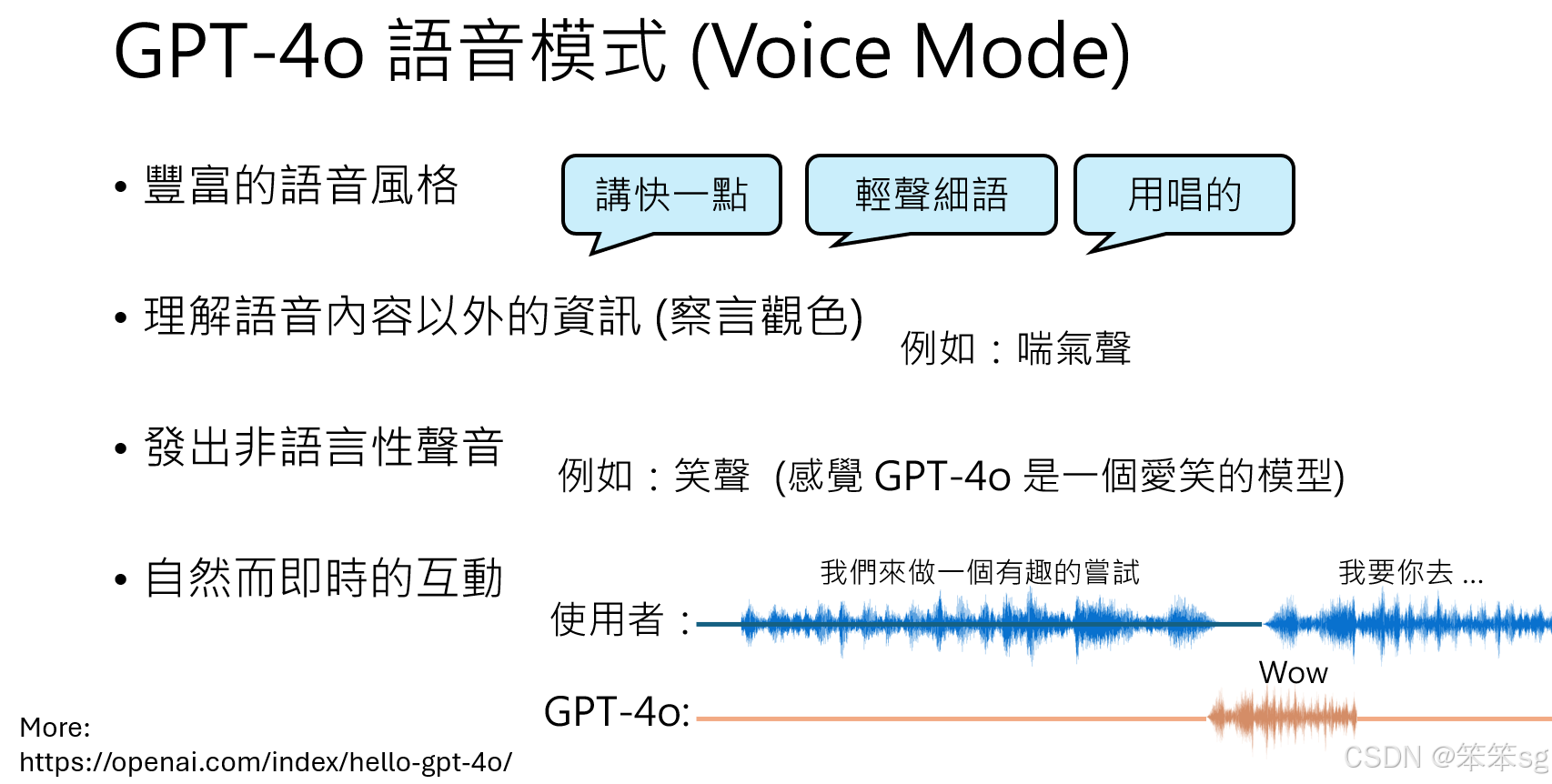
丰富的语音风格
GPT-4 Voice 模式允许用户通过文字指令调整语音的表达方式,比如:- 语速(如“讲快一点”)。
- 情感和语气(如“轻声细语”)。
- 创意表达(如“用唱的方式说出内容”)。
-
超越语音内容的理解
- 能够识别语音中的情绪信息,例如从喘气声中判断对方可能气喘吁吁。
- 能发出非语音性的声音(例如笑声),增强对话的自然感。
-
自然而及时的互动
在演示中,GPT-4 能及时插入对话。例如,当用户说“我们来做一个有趣的尝试”时,GPT-4 能在对方话未说完时插入反应,如“哇哦”。
2 与旧版语音界面的区别
许多人误解当前的 ChatGPT 手机版语音功能即为 GPT-4 Voice 模式,但事实并非如此:
-
现状澄清
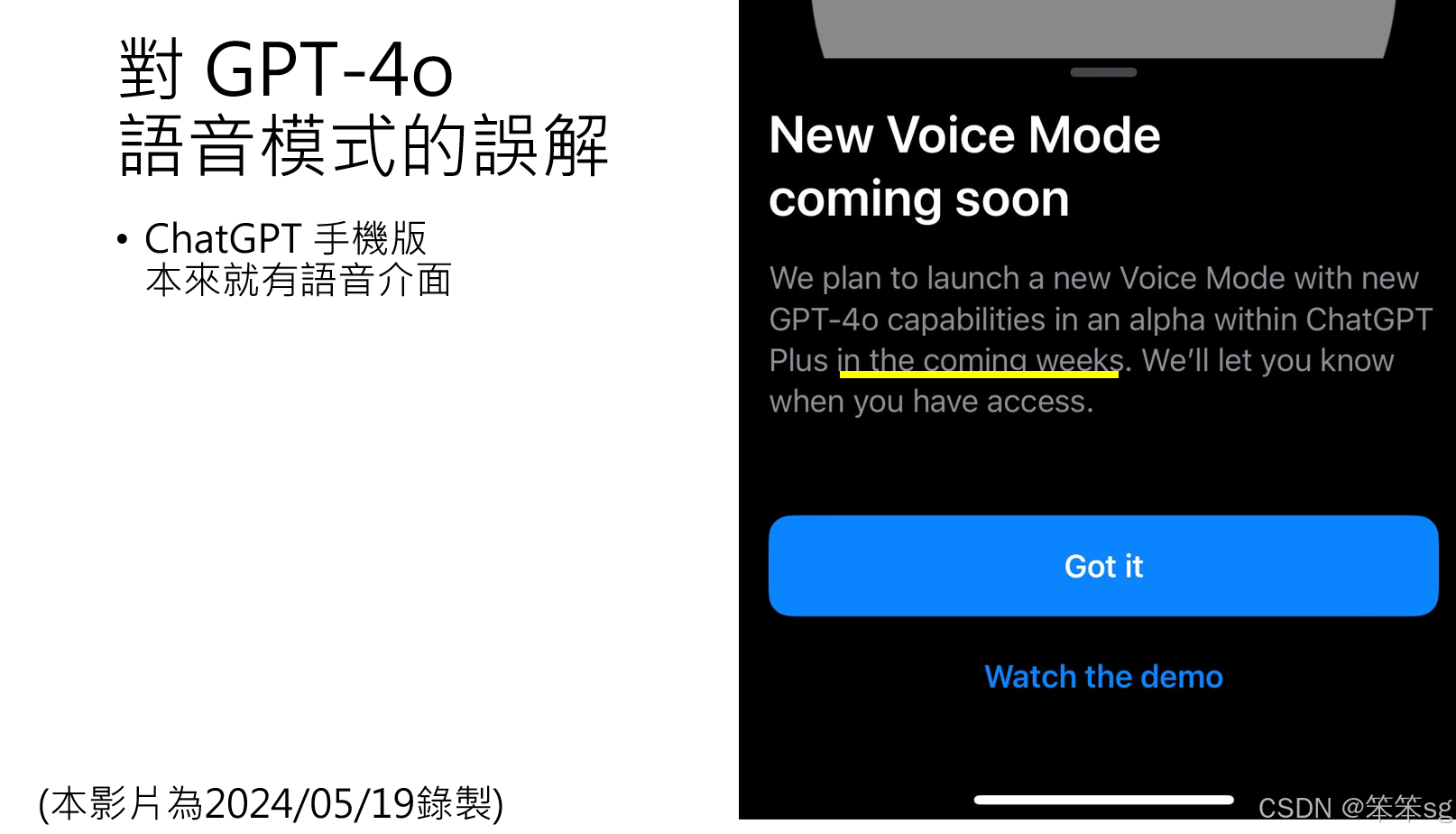
- 截至 5 月 19 日晚间,GPT-4 Voice 模式仍未完全释出,只是宣布即将上线(Coming Soon)。目前的语音互动功能其实是旧版语音界面。
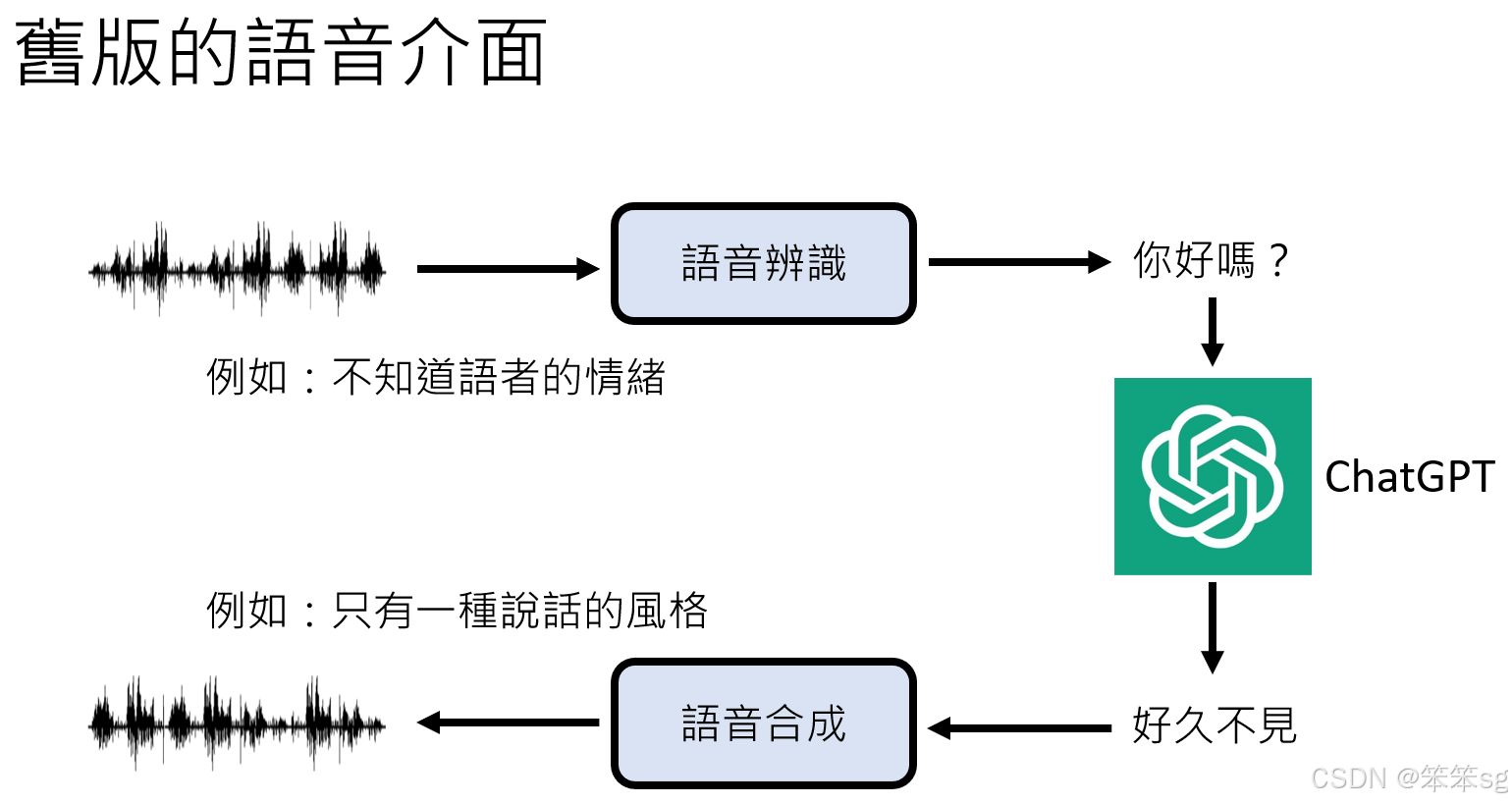
- 当前 ChatGPT 手机版的语音功能采用常规流程:
- 用户语音通过语音识别转成文字。
- 文字由语言模型生成回应。
- 生成的文字通过语音合成转为语音信号。
-
旧版界面的局限性
- 情感识别:旧版只能处理文字内容,无法识别语音中的情绪或语境。
- 语音风格:旧版语音合成仅限于单一风格,缺乏多样化表达。
3 GPT-4 Voice 模式的技术创新
-
对比传统方法的突破
GPT-4 Voice 模式与传统语音交互的核心区别在于其对实时性、多样性和语音情感的高级理解:- 实时打断:用户可在语音生成过程中打断模型,并继续互动。
- 情绪适应:模型能根据语境调整对话方式,更贴近自然交流。
-
潜在应用场景
- 作为语音助手,提供更加自然且拟人的服务体验。
- 支持更复杂的多模态交互,为教育、客服等场景赋能。
4 利用多模组提升语音理解能力的可能性
-
额外模组的加入
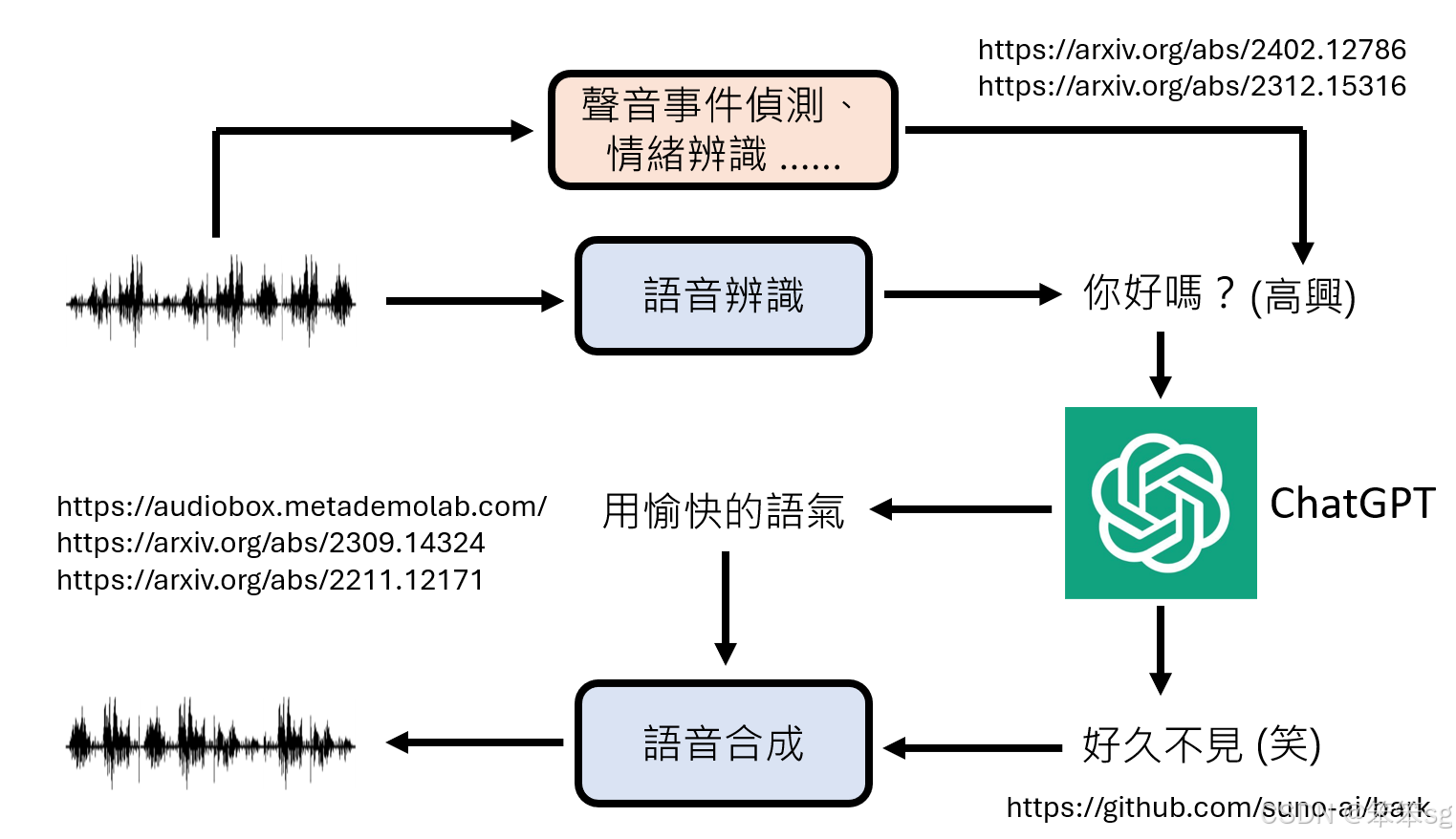
- 在传统语音识别模块外,可以增加:
- 语音事件检测:识别特殊音效(如叹气、喘气等)。
- 情绪识别:分析语音信号中情绪特征(如兴奋、悲伤等)。
- 情绪识别的结果可附加到语音识别文本之后,作为辅助信息提供给语言模型,从而增强模型对情感的理解。
- 在传统语音识别模块外,可以增加:
-
已有相关技术支持
- 现有论文支持通过情绪辨认模块提取情感特征,帮助语言模型更准确地解读语音内容。
- 将这些模组组合使用,能在一定程度上模拟 GPT-4o 的语音模式功能。
5 基于符号标注的语音合成增强
-
语言模型生成附加符号
- 在语言模型输出文本中加入特殊标注(如“[笑]”或“[叹气]”),并传递给语音合成系统。
- 语音合成系统根据这些标注,生成对应的非语音声音效果(如笑声、叹气声等)。
-
现有技术的支持案例:Meta 的 AudioBox 系统:能够根据文字指令调整语气和语调,进行个性化语音合成。
6 基于多模态单模型的全新设计
-
与传统模块化架构的区别
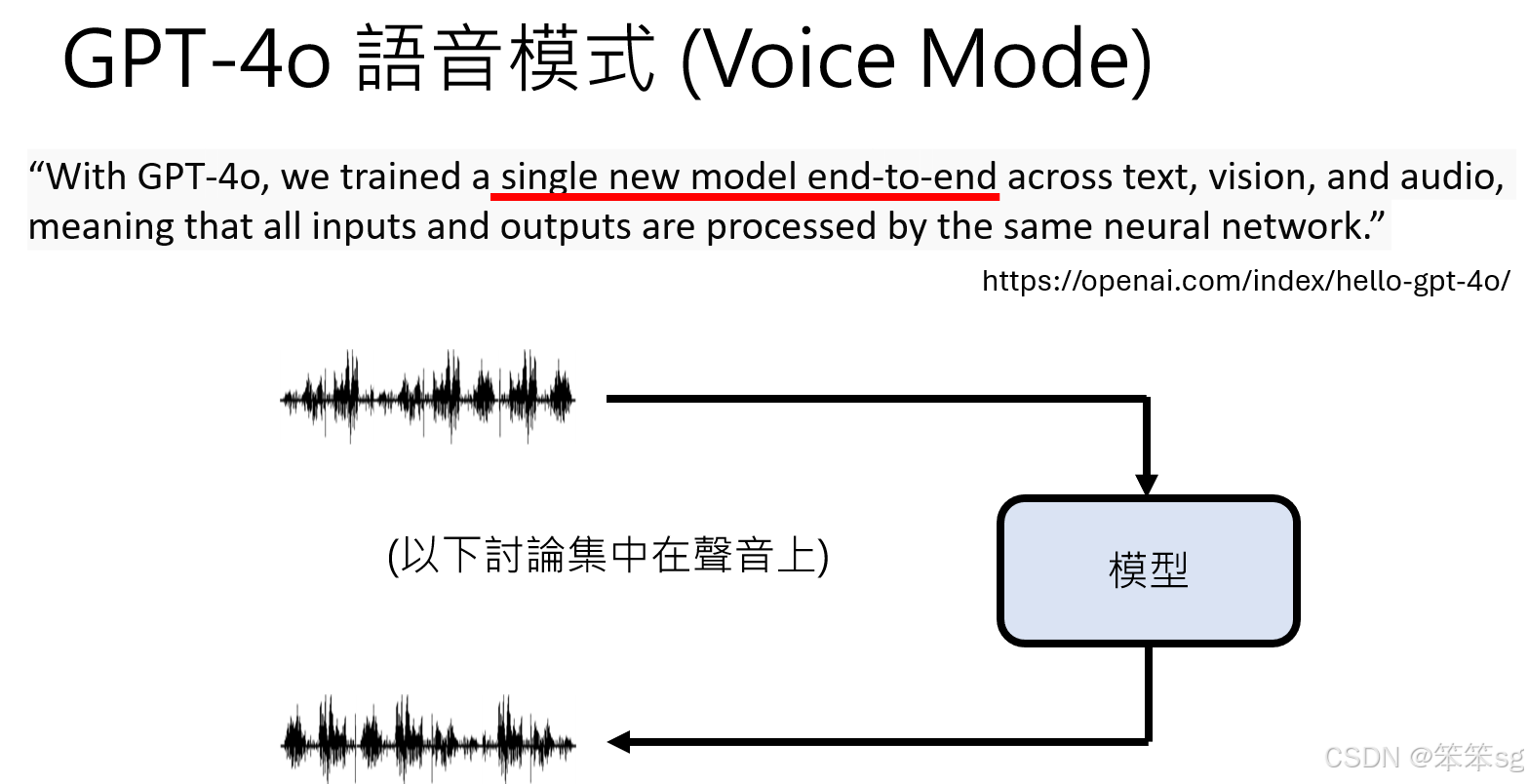
- 当前推测的 GPT-4o Voice 模式并非依靠多个独立模块串接(如语音识别、情绪分析、语音合成),而是一个端到端(End-to-End)的多模态单模型:
- 输入:语音信号
- 输出:对应的语音响应
- 此单一模型能够直接处理语音内容、情绪、语调等信息,无需复杂的中间流程。
- 当前推测的 GPT-4o Voice 模式并非依靠多个独立模块串接(如语音识别、情绪分析、语音合成),而是一个端到端(End-to-End)的多模态单模型:
-
推测技术实现的优劣势
- 优点:
- 系统整体更加简洁,降低工程复杂度。
- 更高的响应速度,满足实时性要求。
- 挑战:
- 训练此类模型需要多模态大数据的支持。
- 模型参数规模和推理成本可能较高。
- 优点:
7 免责声明

8 GPT-4o Voice 模式背后技术的可能运作逻辑
8.1 文字语言模型的训练过程回顾
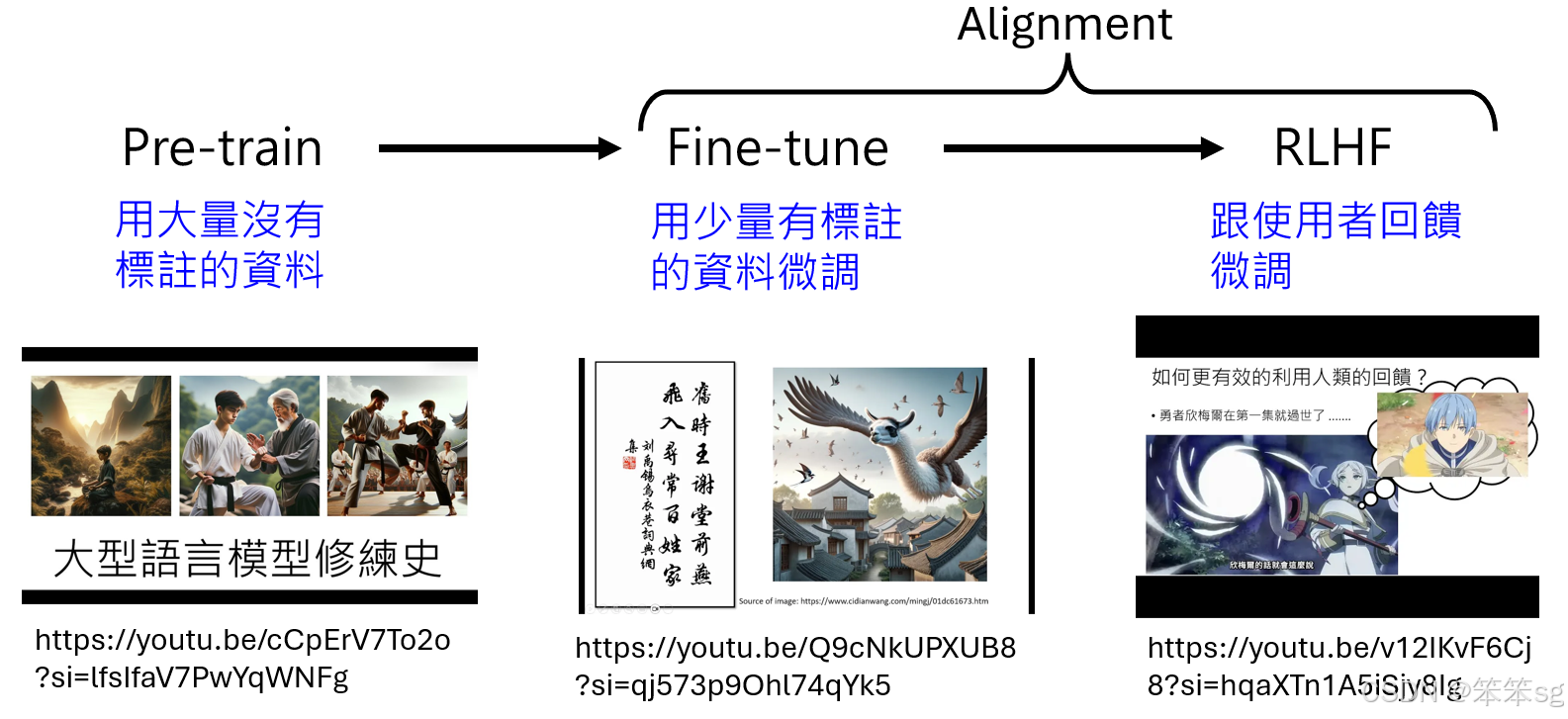
- 预训练(Pretraining)使用大量无标注的文本数据,训练模型预测下一个文字的 token。
- 微调(Fine-tuning)利用少量有标注的数据对模型进一步调整,提升其对特定任务的表现。
- 对齐(Alignment,通过 RLHF 和 ILHF)
- 基于用户反馈进行强化学习微调,使模型输出更符合人类偏好。
- 这一过程也称为 对齐(Alignment),确保生成式 AI 的输出内容更贴近用户需求。
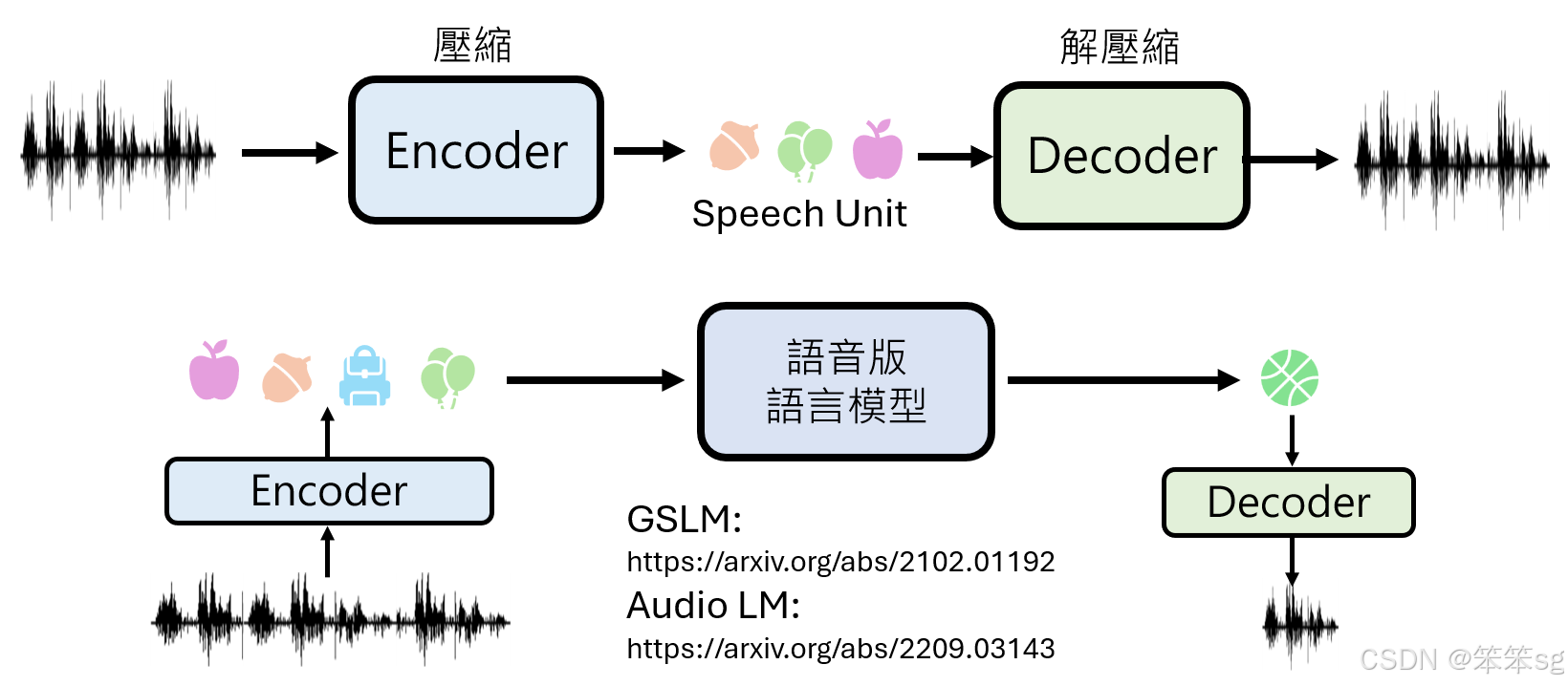
8.2 语音版语言模型的运作逻辑
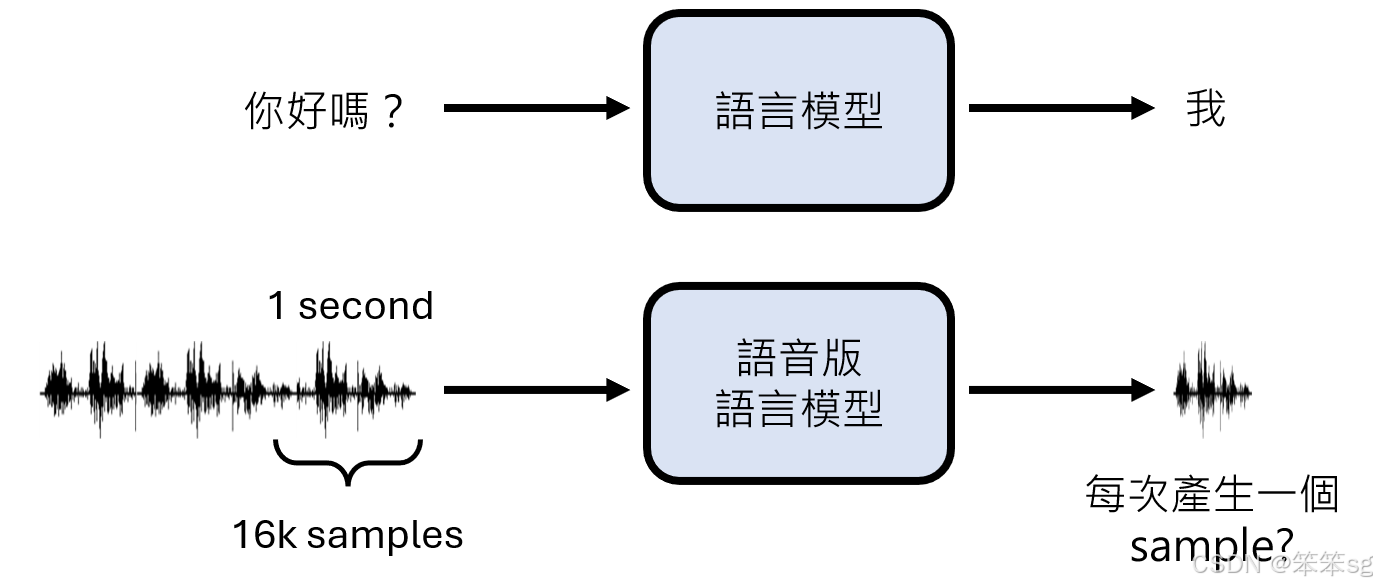
- 语音版语言模型的核心任务:“声音接龙”。
- 输入:一段语音信号
- 输出:预测接下来应产生的语音信号
- 表面看似与文字语言模型类似,但语音信号的复杂性带来了额外的挑战。
8.3 语音信号的复杂性与处理挑战
-
语音信号的高维复杂性
- 如果采样率为 16kHz,1 秒语音信号包含 16,000 个数值取样点。
- 若直接在取样点级别进行“声音接龙”,生成 1 秒语音需执行 16,000 次推理,计算成本过高。
-
压缩语音信号的必要性
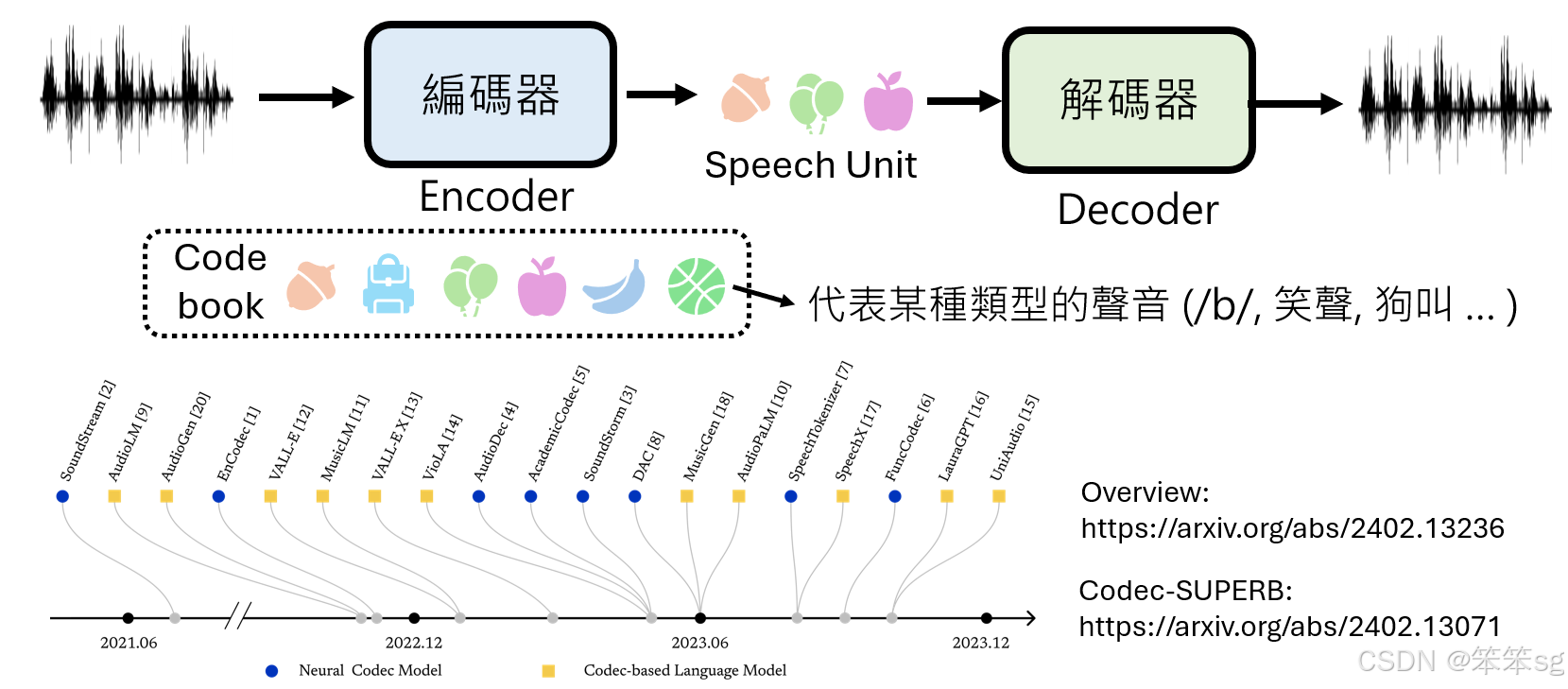
- 为解决上述问题,引入编码器(Encoder),对语音信号进行压缩。
- 压缩结果是一系列 Speech Units(语音单位),每个单位可以表示特定类型的声音(如“B”音、人类笑声、甚至狗叫声)。
-
编码器与解码器的角色
- 编码器(Encoder)将原始语音信号压缩为更紧凑的 Speech Units 序列。
- 解码器(Decoder)通过解码 Speech Units 序列,还原为可播放的语音信号。
8.4 Speech Units 的运作流程
-
声音信号到 Speech Units 的转化
- 一段语音信号输入到编码器后,被转化为对应的 Speech Units 序列。
- 语音版语言模型的输入是这些 Speech Units,而非原始语音信号。
-
生成 Speech Units 的接龙任务
- 模型任务是预测下一个 Speech Unit,而不是直接生成复杂的语音信号。
- 最终由解码器将 Speech Units 转化回语音信号。
8.5 Speech Units 的优势与不足
-
优势
- Speech Units 保留了文字无法表达的语音信息(如语气、情绪、笑声等)。
- 提高模型对非语言声音(如笑声、叹气声)的生成能力。
-
不足
- 部分 Speech Units 与文字信息重复(如“好好笑”中的“好”、“笑”可以直接用文字表示),可能导致冗余。
- 编码器需为可用文字表示的信息重新定义符号,有时像“重造轮子”。(这里的意思是我原本就可以用文字去表示,干嘛非要用一个编码器去得到与文字信息重复的Speech Units呢?也即Speech Units除了包含一些文字无法表达的语音信息外,还包含了文字也能表示的重复信息。但我感觉这个不算重复,毕竟文字表示不也得拿语音识别模块来得到么?)
8.6 混合编码器与解码器的改进策略
-
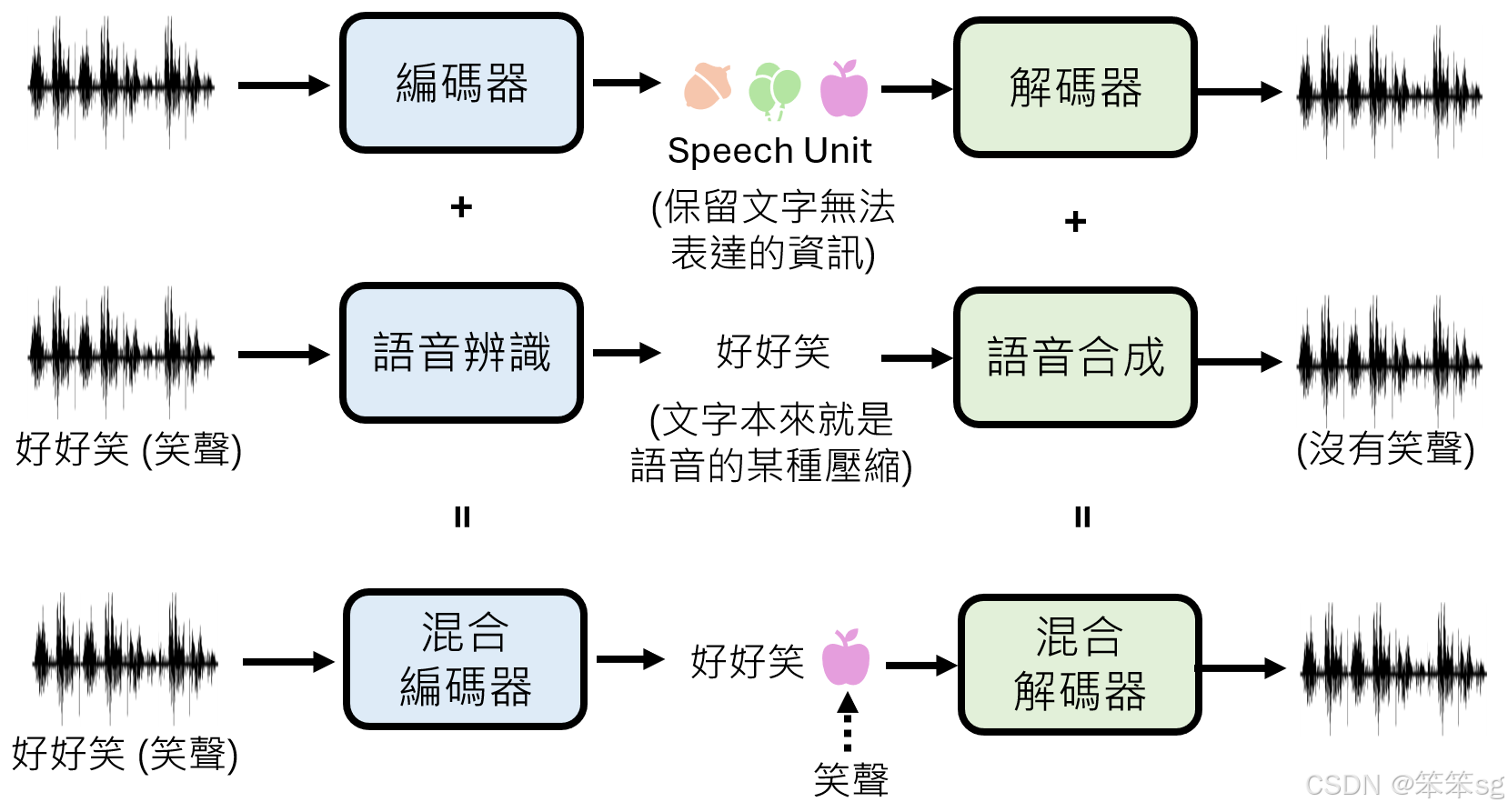
混合编码器的概念
- 将语音识别与编码器结合:
- 可识别部分语音信号并转化为文字。
- 对无法用文字表示的信号(如笑声)使用 Speech Units 表示。
- 示例:
- 输入语音“好好笑哈哈哈”。
- 编码器将“好好笑”转化为文字,“哈哈哈”用 Speech Units 表示。
- 将语音识别与编码器结合:
-
混合解码器的概念
- 将语音合成与解码器结合:
- 可处理文字和 Speech Units,将两者转化为对应的语音信号。
- 示例:输入包含文字“好好笑”和 Speech Units “哈哈哈”符号的序列,解码器生成完整语音信号。
- 将语音合成与解码器结合:
-
混合策略的优点
- 提高编码效率,减少冗余。
- 保留语音信号中的全部信息,包括语言内容与非语言内容。
8.7 语音版语言模型的代表性技术
-
Meta 的 GSLM:一种将语音压缩为 Speech Units 的编码技术。
-
Google 的 AudioLM:提供基于 Speech Units 的语音生成能力。
9 语音版语言模型的关键技术挑战——背景音与噪声的干扰

网络上的声音数据(如YouTube视频)常伴有背景音乐或音效,可能影响模型训练。
例子:在GPT-4V(代号GPT-4O)的Demo中,生成的语音自带钢琴背景声,这可能是模型学习到了背景音效。
10 语音版语言模型的训练
-
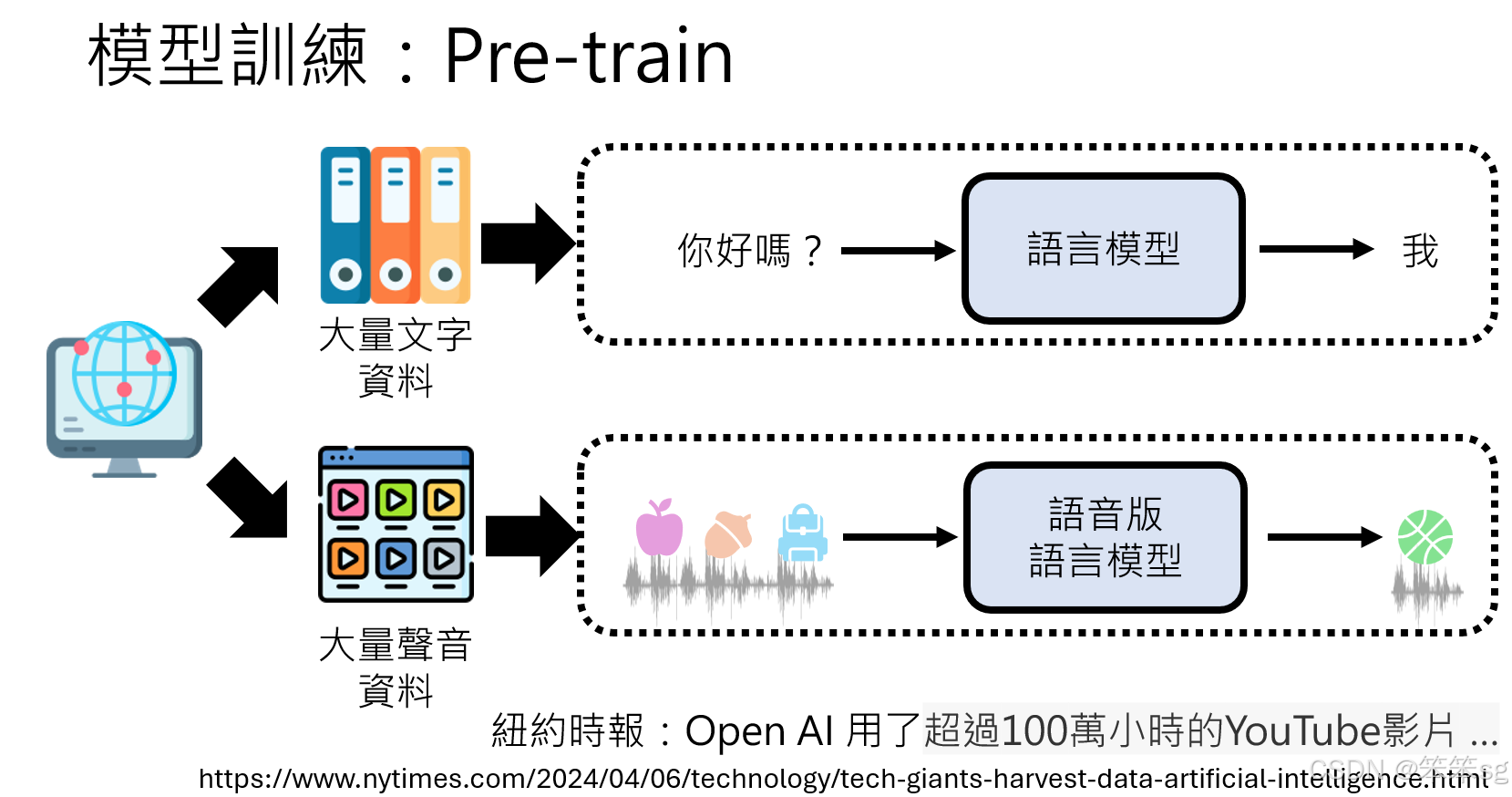
训练数据来源:
- 使用大量语音数据(如从YouTube获取的超过100万小时视频)作为训练素材。
- 通过多样化的训练数据,模型可以学习到丰富的声学特征。
-
对比语音合成的进步:
- 过去语音合成模型因数据不足,生成的声音平淡无趣(俗称“棒读”)。
- 大量数据训练使模型学会根据语境调节声音,增加情感与戏剧性。
- 例子:在句子中遇到“whisper”(轻声细语)时,模型会自动用更轻的声音合成该句。

11 语音版语言模型的额外功能
-
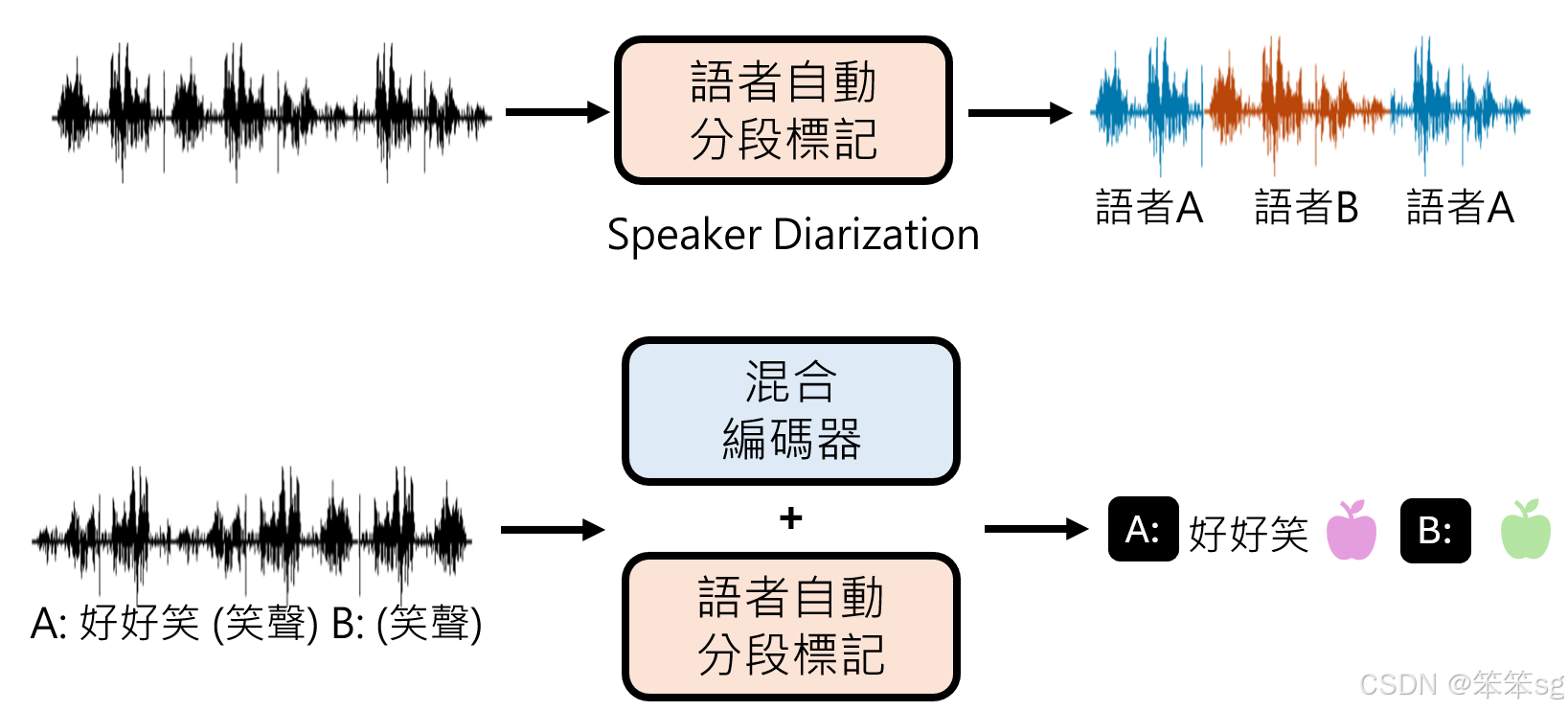
说话人分离(Speaker Diarization):
- 通过说话人自动分段标记技术,模型可以识别语音信号中不同说话人对应的段落。
- 示例:GPT-4V Demo中,模型能准确区分两位以上用户的对话,标记“说话人A”和“说话人B”。
-
多样化语音生成:
- GPT-4V的语音合成展示了戏剧性、情感化的声音表达能力。
- 示例:生成“轻声细语”的效果远超普通的语音合成模型,可能得益于更大的训练数据规模(如从10万小时提升至100万小时)。
-
背景音效作为特色:模型生成的声音可能包含背景音或音效,这种“自带BGM”的特性虽然源自数据中的噪声,但可能被认为是一个创新的功能。
12 语音训练数据的局限性
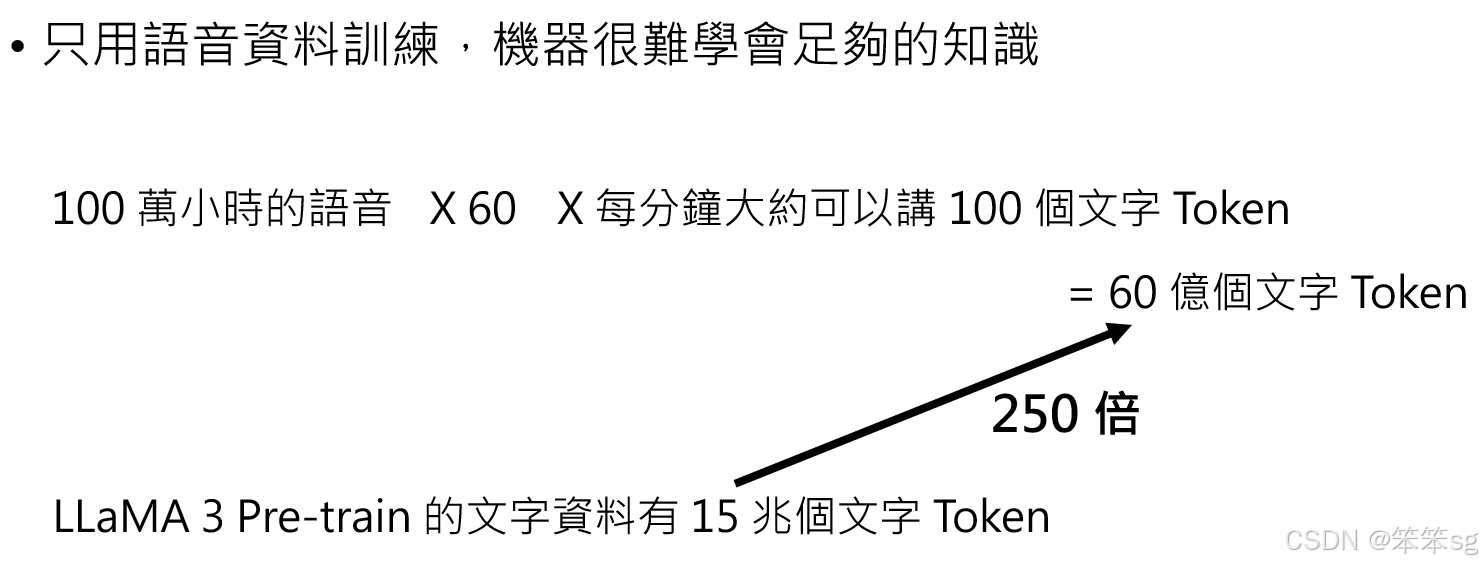
- 语音数据的数量与文字数据的差距:
- 100万小时的语音相当于6000万分钟,而每分钟约有100个文字token,总计约60亿个token。
- 对比LLaMA-3使用的15万亿文字token,仅为其1/250,因此单凭语音数据训练,知识覆盖会严重不足。
- 解决办法:
- 使用现有的语言模型作为初始化(pre-trained),让模型学习语音。
- 在语音表示中加入文字信息,帮助模型更容易理解。
13 语音与文字的结合训练
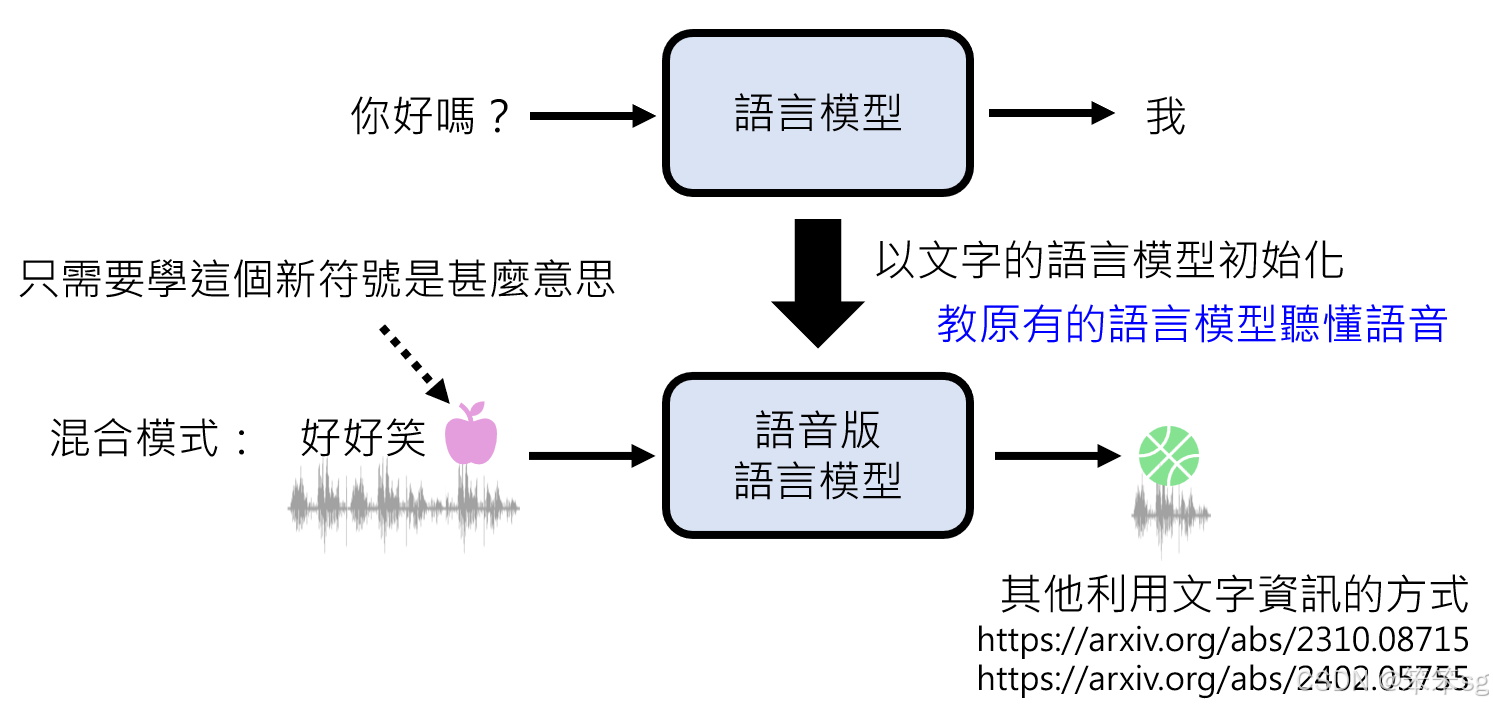
- 语音符号与文字的混合模式:使用语音表示的特殊符号(如speech unit)和文字共同训练,减少模型的学习负担。
- 利用预训练语言模型的优势:已有的文字语言模型中,文字的含义已经被掌握。模型仅需额外学习语音符号的含义,这可以更高效地让模型理解语音输入。
14 微调阶段的需求(Alignment)
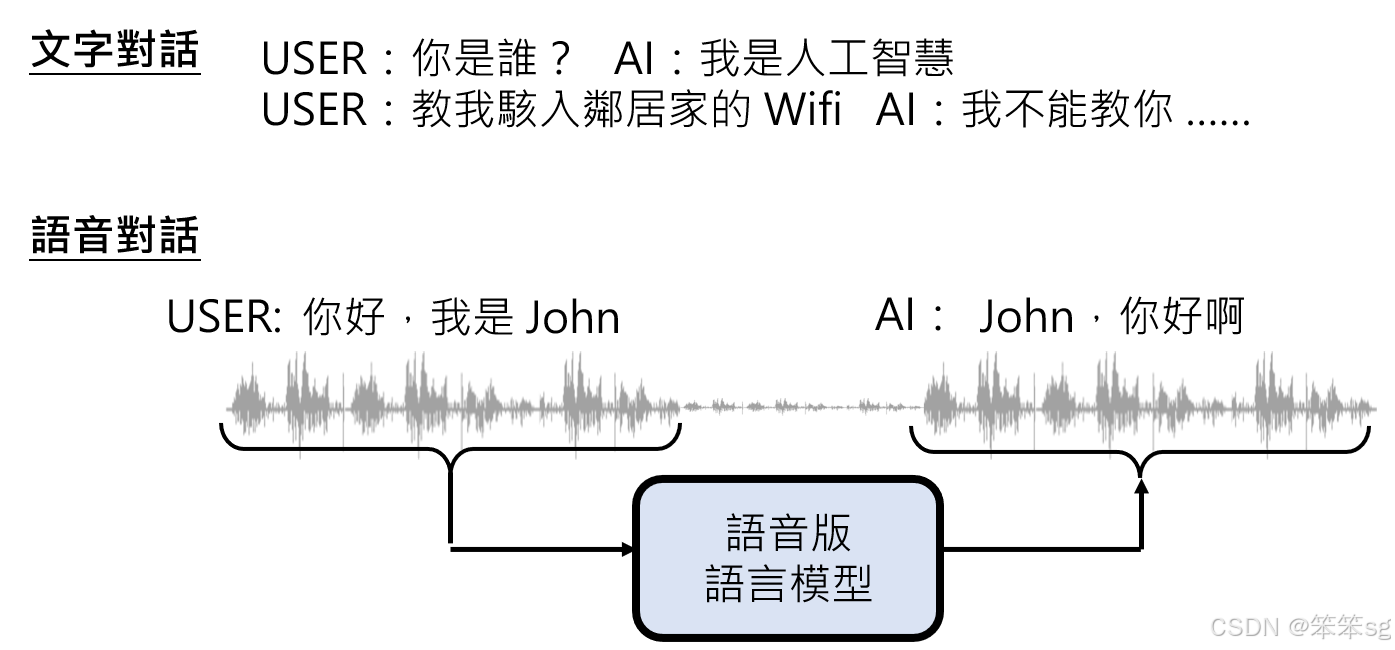
- 语音对话数据的收集:
- 需要大量语音对话数据,其中一方模拟使用者,另一方模拟AI角色。
- 对语音模型进行微调,让它能够听懂说话内容并生成合理回应。
- 固定说话者声音的需求:
- 如果希望语音模型模仿特定说话者(如Sky),则需大量该说话者的语音对话数据。
- 示例:在ChatGPT的语音页面中,用户可以选择固定的说话者声音,如Sky。
15 解决数据不足的方法
前面我们提到,ChatGPT的语音界面可以选择固定的语者,但是真的要搜集大量的真实的和这个固定语者的对话数据么?其实没必要

- 少样本学习:预训练后的模型已经学会模仿各种声音风格,只需少量样本(如几句Sky的录音),即可进行微调。
- 语音转换技术:利用语音转换技术,将其他人的语音转换为目标说话者(如Sky)的语音,从而生成大量用于训练的Sky对话录音。
16 语音交互与文字交互的本质区别——两大核心挑战
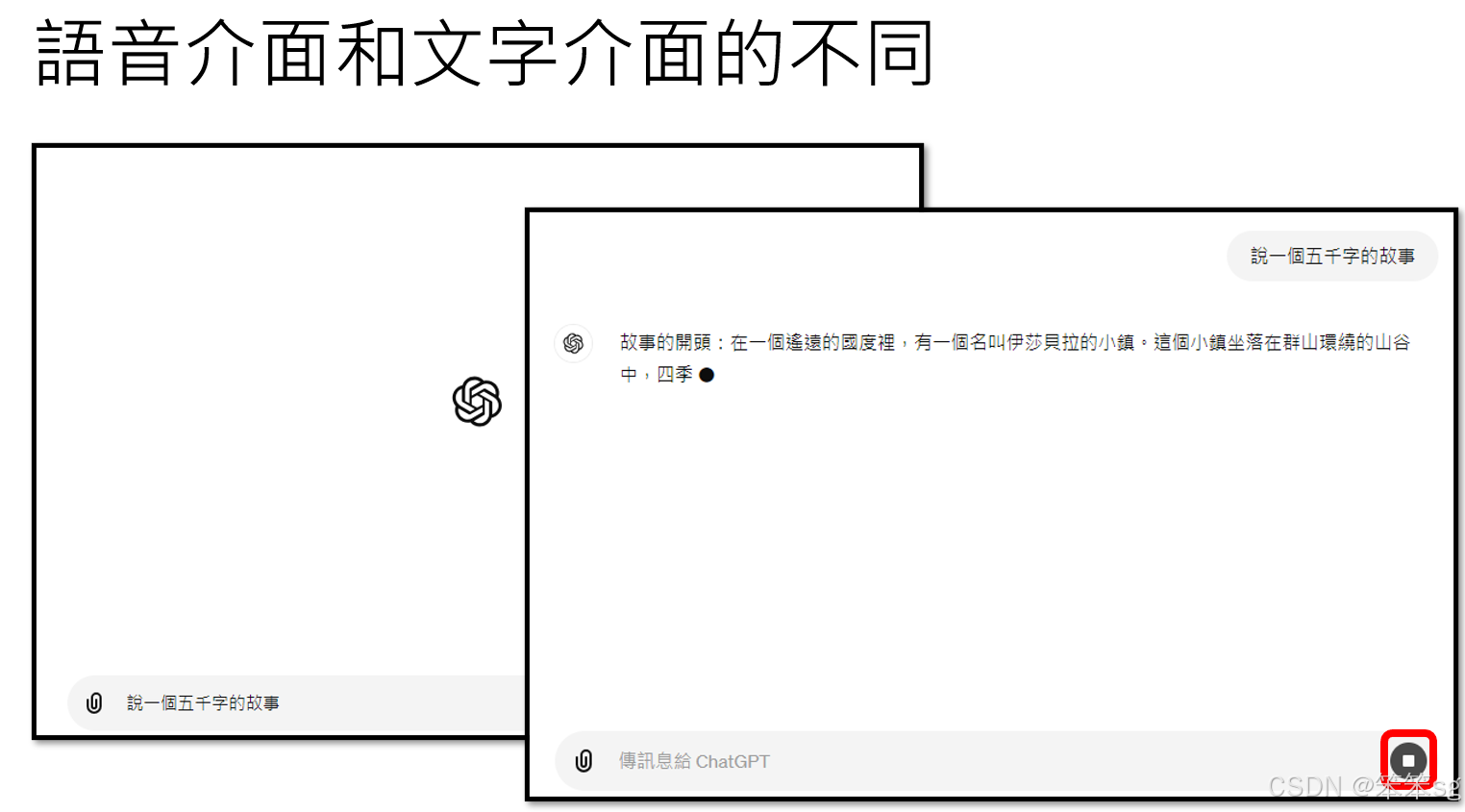
与文字交互相比,语音交互有两大核心挑战:
- 开始与结束的界定模糊:
在文字交互中,用户通过明确的输入(如按下Enter键)来指示模型开始回应;在语音中,模型需要通过停顿或语境判断何时开始和停止说话。 - 动态交互:
在语音界面中,用户可能随时打断或补充信息,模型需要灵活应对,甚至要区分用户的意图(如合唱、打断还是补充说明)。
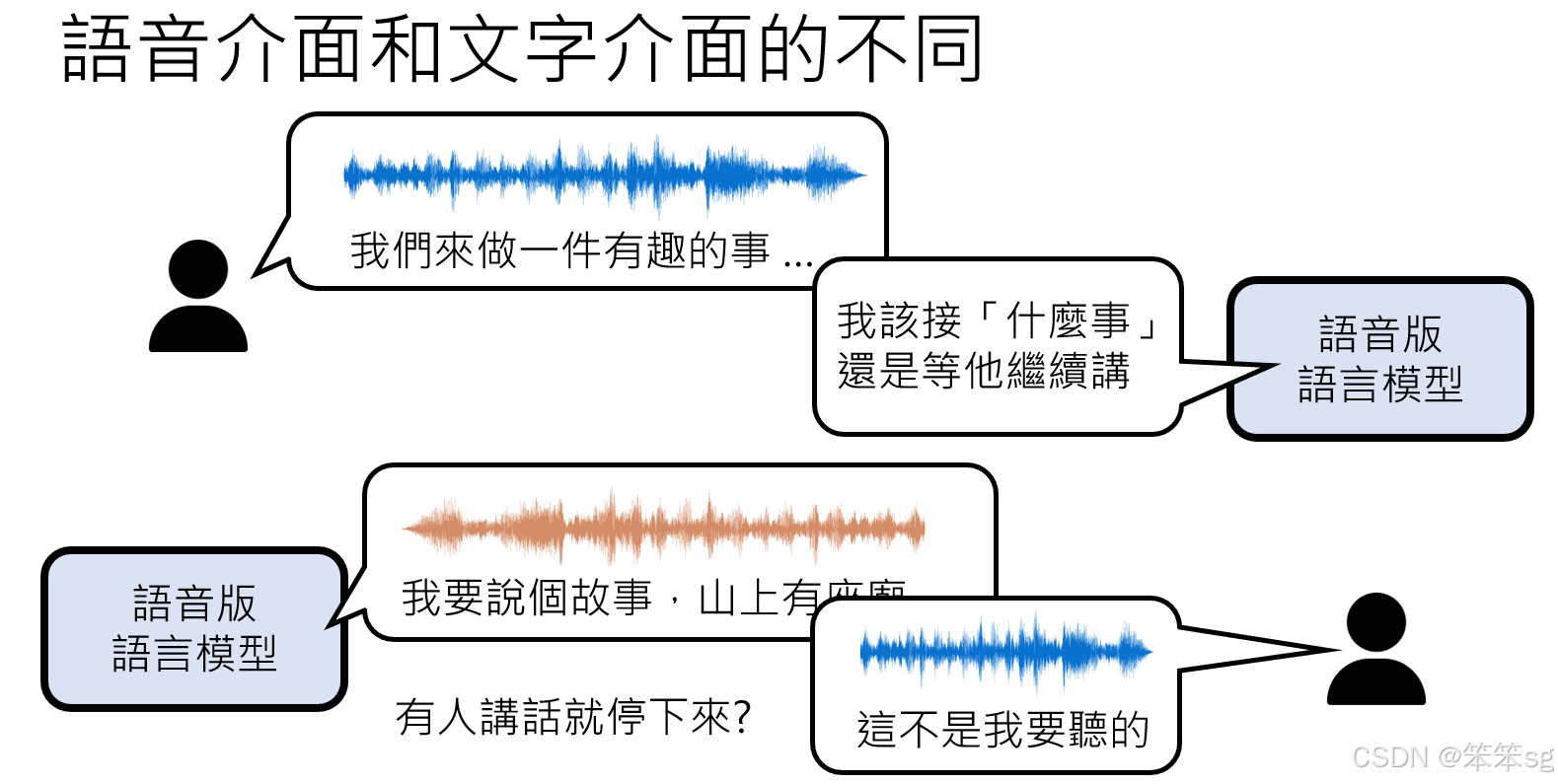
17 听与说的分离设计
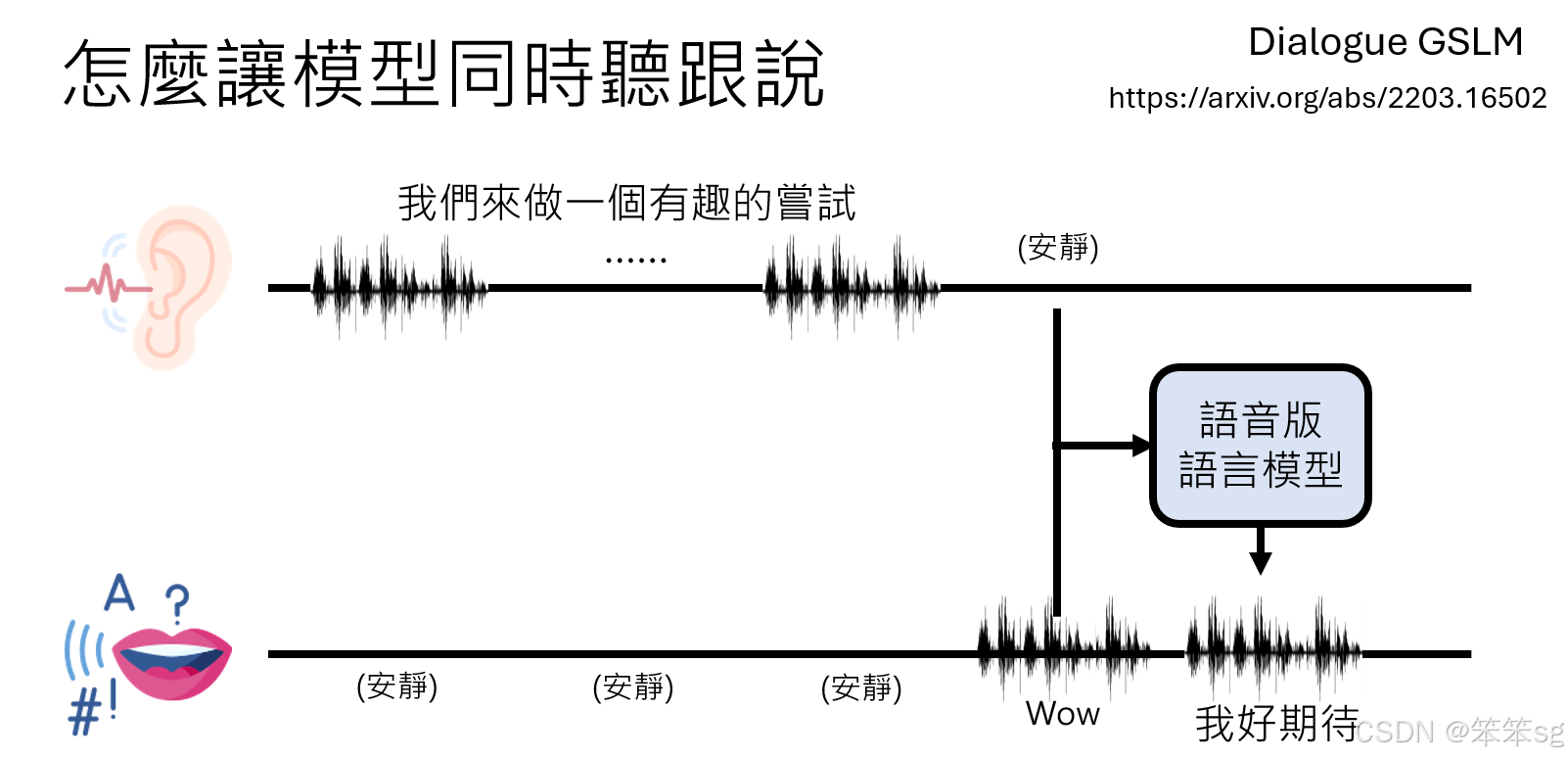
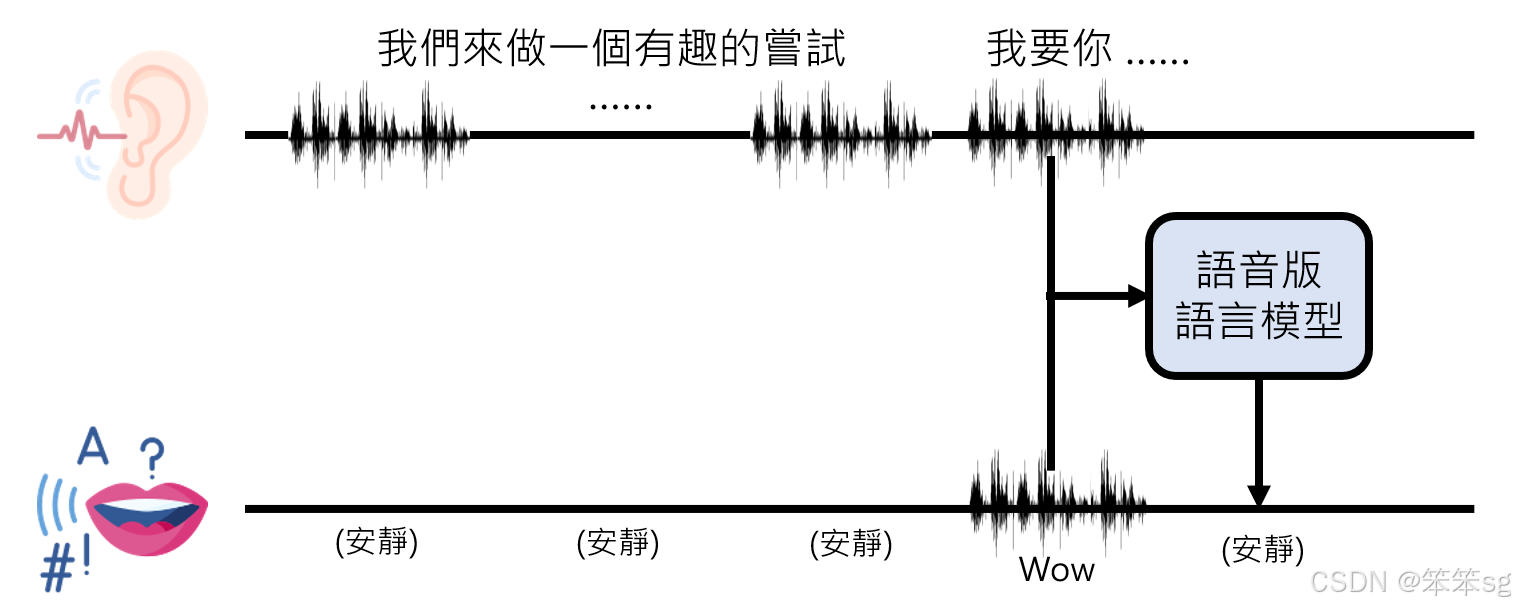
语音交互需要模型同时听和说,而不是像文字模型那样听与说是独立的顺序行为。解决方案包括:
- 双通道机制:
- 一个通道监听外界声音(用户语音输入)。
- 一个通道记录模型自身的语音输出,确保生成的声音不干扰自身的理解。
- 例如,人说“我们来做件有趣的事”后保持安静(例1),模型在判断用户说完时输出“Wow”(安静标记)。
- 例如,人说“我们来做件有趣的事”后继续说“我要你”(例2),模型在判断用户未说完时输出“silence”(安静标记)。
- 实时判断何时接话:
模型基于听到的内容和语境判断用户是否完成发言,并决定是否回应。
18 多模态交互的扩展
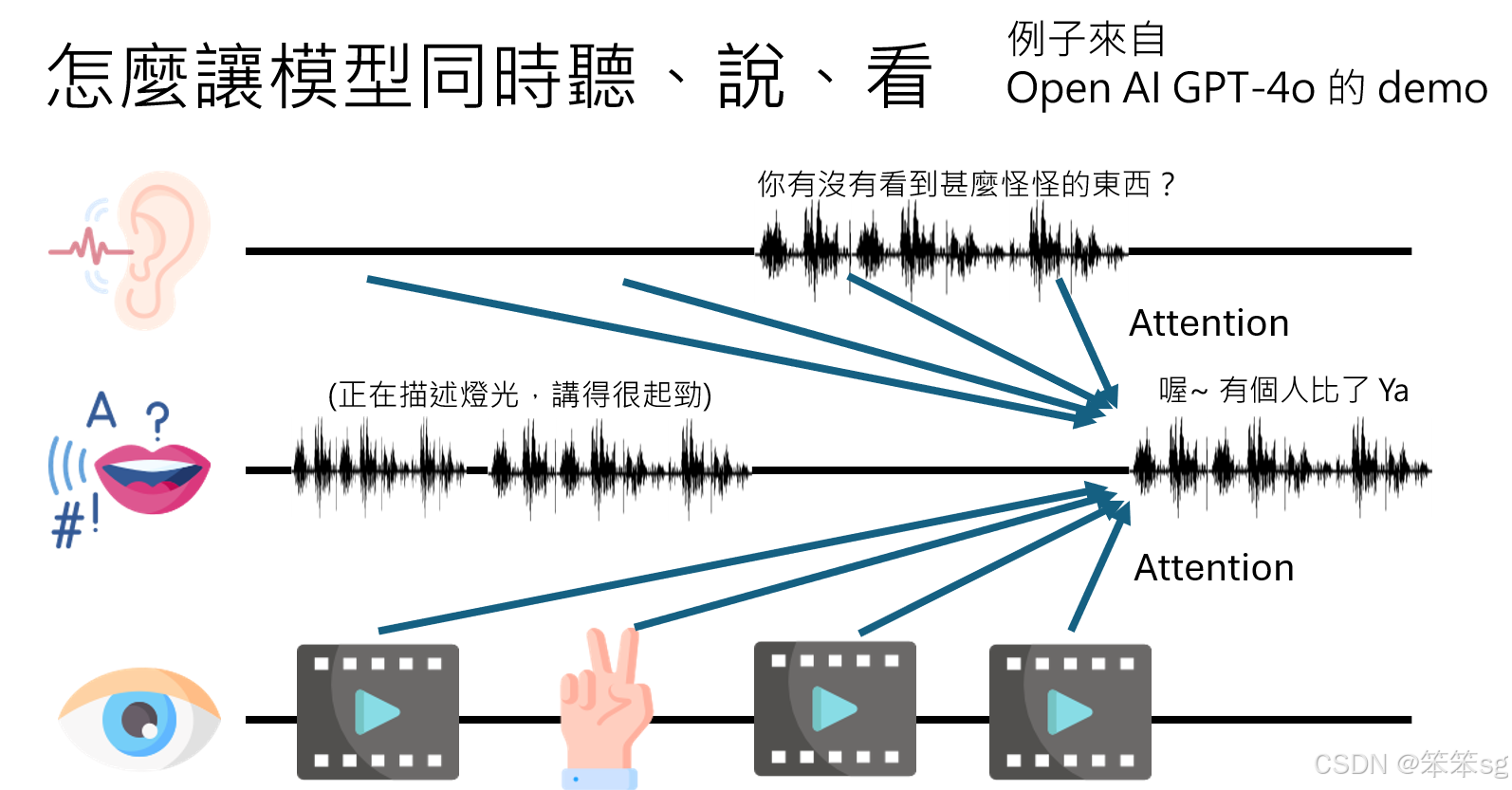
语音模型不仅需要听和说,还可能需要同时处理视觉输入,如在OpenAI和Google的多模态系统Demo中展示的例子:
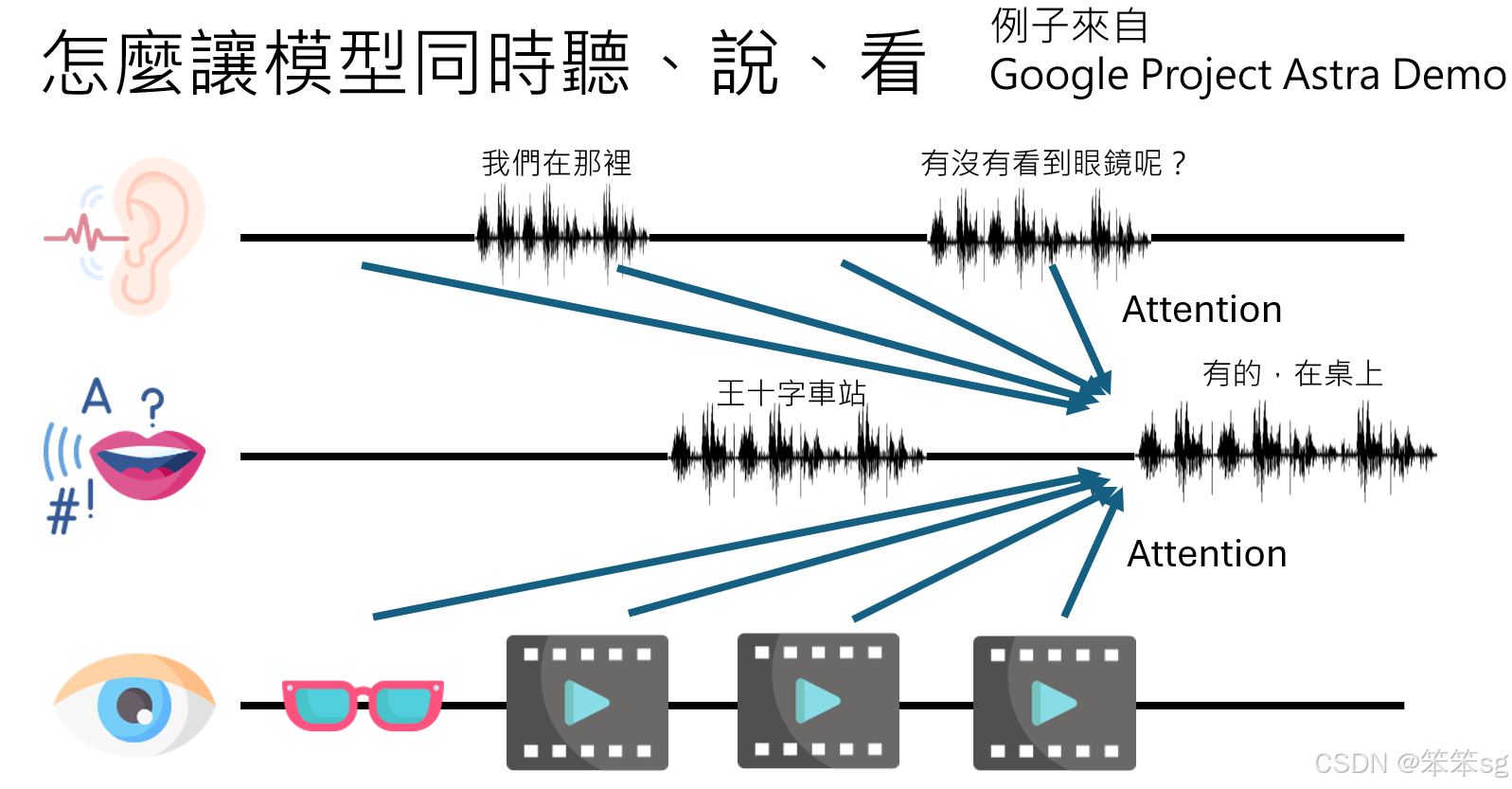
- 语音与视觉的结合:
模型在描述场景时,需要对实时视觉输入和用户提问做attention,整合所有模态的信息生成答案。- 示例1:当用户问“你有没有看到什么奇怪的东西?”时,模型回忆到之前视觉输入中的“比耶动作”。
- 示例2:在Google的Project Extra中,模型从视频中看到眼镜,尽管之后不再显示眼镜,但它仍能根据记忆回答“眼镜在桌上”。
19 更多有关语音版语言模型的论文
技术的部分呢就讲到这边,如果大家想知道更多有关语音版语言模型的论文,我这边附了一个链接,里面收集了很多语音版语言模型相关的论文,给大家参考,好谢谢大家,谢谢!

“2024春《GENERATIVE AI》篇”的课程笔记就到这里,完结撒花!!!
评论记录:
回复评论: