
目录
5 Non-Auto-Regressive (NAR) 生成方式
7 Auto-Regressive 与 Non-Auto-Regressive 的运算对比
10 克服NAR(Non-Auto-Regressive)生成的局限性—方法一
10.3 Auto-Regressive与Non-Auto-Regressive模型结合的策略:
11 克服NAR(Non-Auto-Regressive)生成的局限性—方法二
12.1 将部分auto-regressive生成替换为non-auto-regressive生成:
12.3 典型的生成过程(如MidJourney、Stable Diffusion等):
0 完整章节内容
本文为李宏毅学习笔记——2024春《GENERATIVE AI》篇——“第15讲”章节的课堂笔记,完整内容参见:
李宏毅学习笔记——2024春《GENERATIVE AI》篇
本章节主要浅谈“生成式人工智能的生成策略”。
1 生成式人工智能的本质

定义:生成式人工智能旨在让机器生成复杂且有结构的物件,如文字、影像和声音。
- 复杂性:这些生成的内容因其可能性极为庞大,几乎无法穷举。
- 基本单位:尽管复杂性高,但它们是由有限的基本单位(如文字的 token、影像的像素、声音的取样点)构成的。
2 从三大角度剖析生成机制
2.1 文字生成
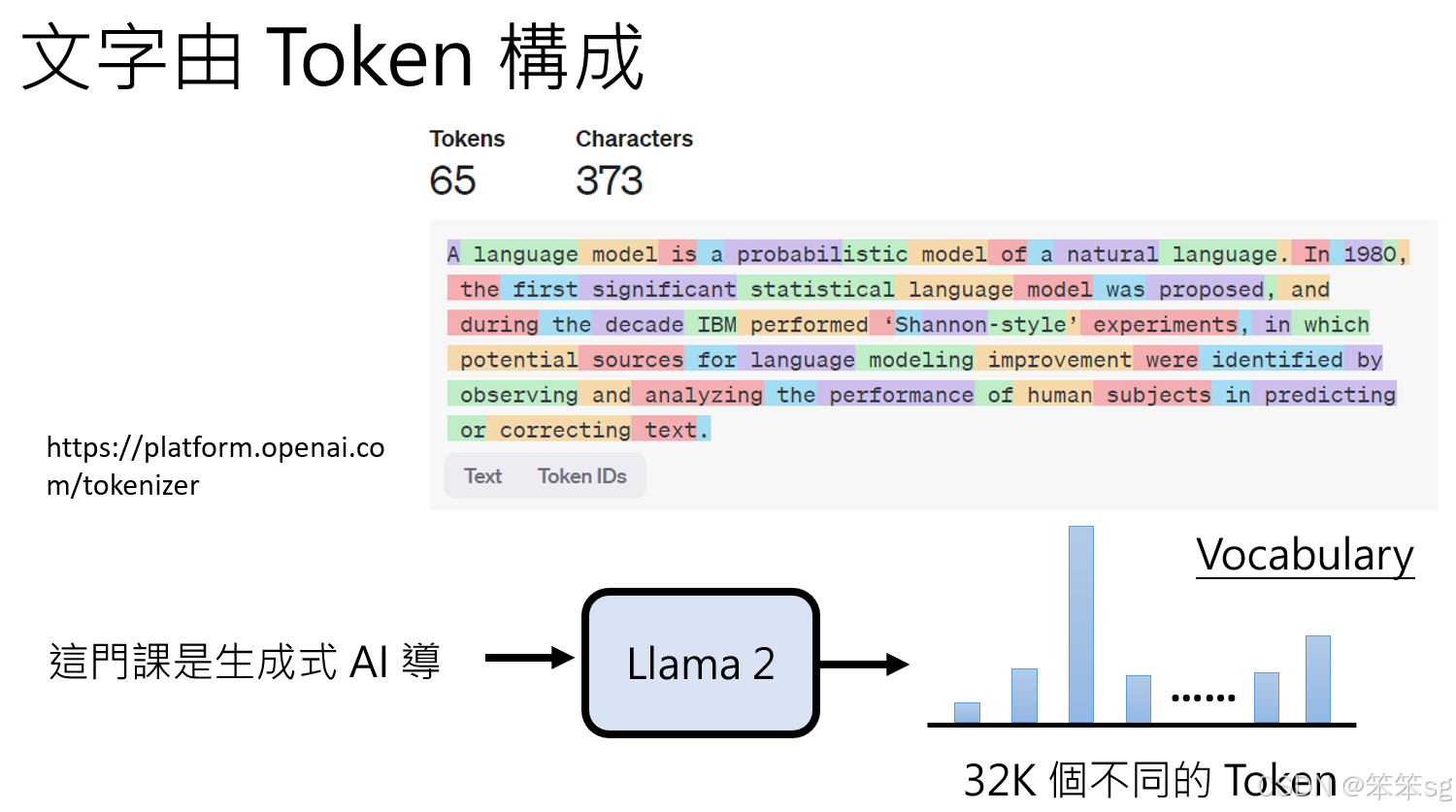
- 基本单位:
- 文字生成的基本单位是 token。
- Token 定义:一种语言模型在处理文本时的最小单位,可能是字母、单词、字符或子词。
- 模型的 Vocabulary:
- Vocabulary 是 token 的集合,定义了模型在生成或理解文字时可用的符号范围。
- 例如:LLaMA 2 的 vocabulary 包含 32,000 个 token。
- 生成过程:
- 模型在每次预测下一个 token 时,从 Vocabulary 中选取一个最可能的 token。
- 这个选择过程基于概率分布,通过模型的训练数据和参数决定。
2.2 影像生成

- 基本单位:
- 影像的最小构成单位是 像素(Pixel)。
- 每个像素由颜色表示,其值由位深度(BPP, Bits Per Pixel)决定:
- 8 BPP:256 种颜色。(每位都是0或1,因此共有2^8=256种组合)
- 24 BPP(真彩色):16,777,216 种颜色(1670 万色)。
- 组合原理:
- 像素按二维网格排列,通过颜色值组合形成图像。
- 例如,生成一张分辨率为 1920×1080 的图像需要生成 2,073,600 个像素。
2.3 声音生成
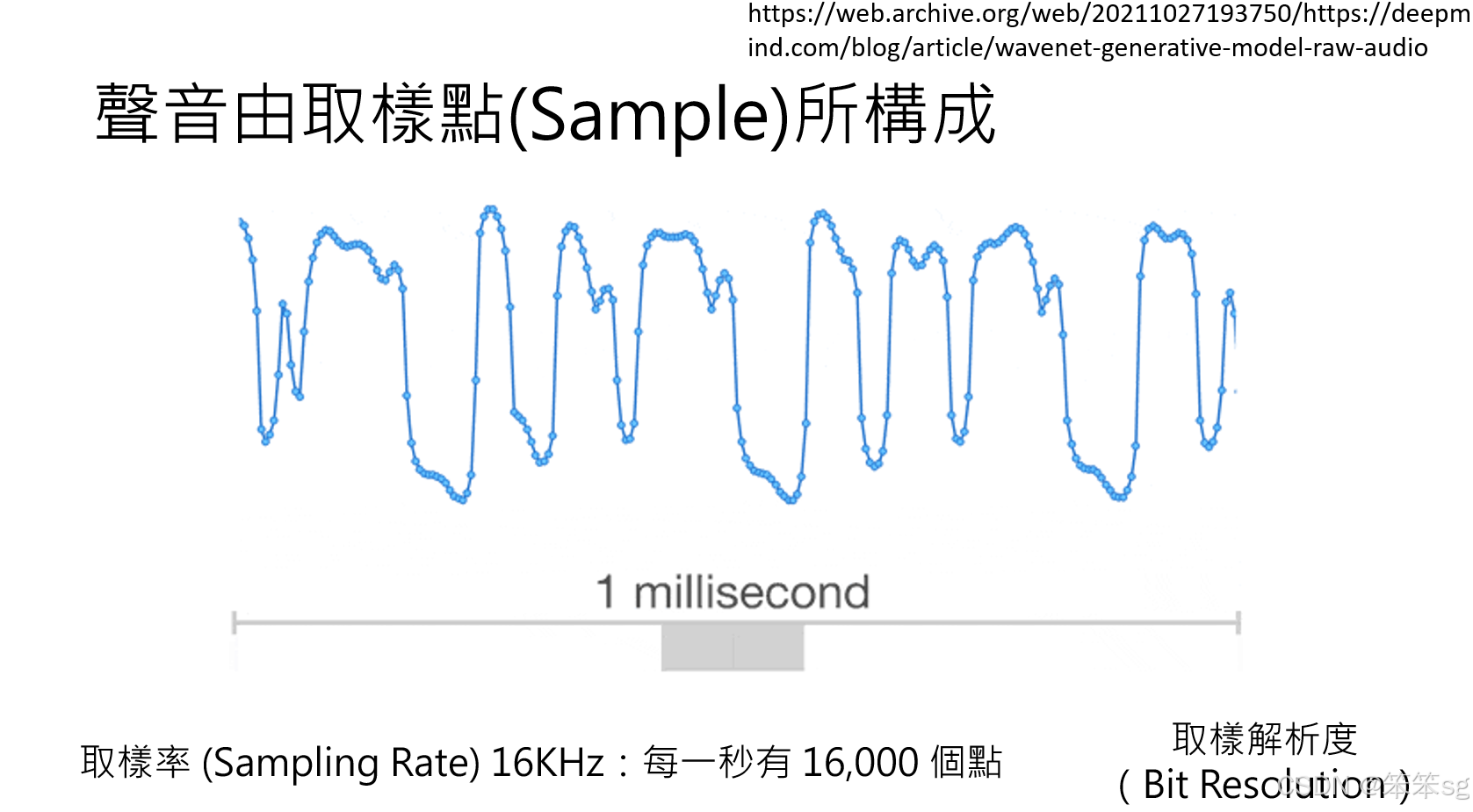
-
基本单位:
- 声音生成的基本单位是 取样点(Sample Point)。
- 声音是连续信号,通过离散化后的取样点表示,具体特性包括:
- 采样率(Sampling Rate):每秒采样的点数。
- 例如,16K 采样率表示每秒有 16,000 个采样点。
- 通常,采样率越高,声音质量越好,如 44.1K(CD 音质)。
- 取样解析度(Sampling Resolution):每个采样点的数值范围。
- 解析度越高,声音细节越丰富。
- 采样率(Sampling Rate):每秒采样的点数。
-
生成过程:
- 模型需要逐点生成或预测采样值,这些点组合形成连续音频信号。
- 声音的生成尤其考验模型的连续性和一致性能力。
3 生成式人工智能的核心任务
定义:生成式人工智能的核心目标是:根据一个条件(Condition),将基本单位以正确的顺序组合起来,形成复杂的输出。
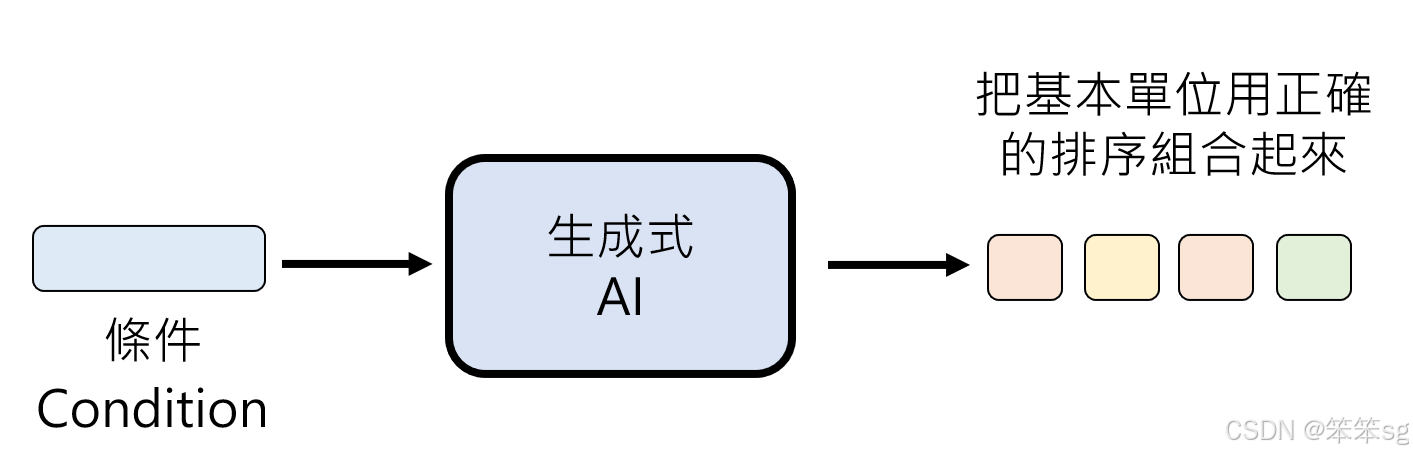
条件(Condition)的作用
- 条件是什么:
- 条件是输入给生成式 AI 的指导信息。
- 它可以是文本描述、图片、声音片段,甚至是更抽象的提示(Prompt)。
- 条件的任务:指导模型将基本单位进行合理的排序和组合,输出符合条件的复杂内容。
3.1 不同应用下的生成逻辑
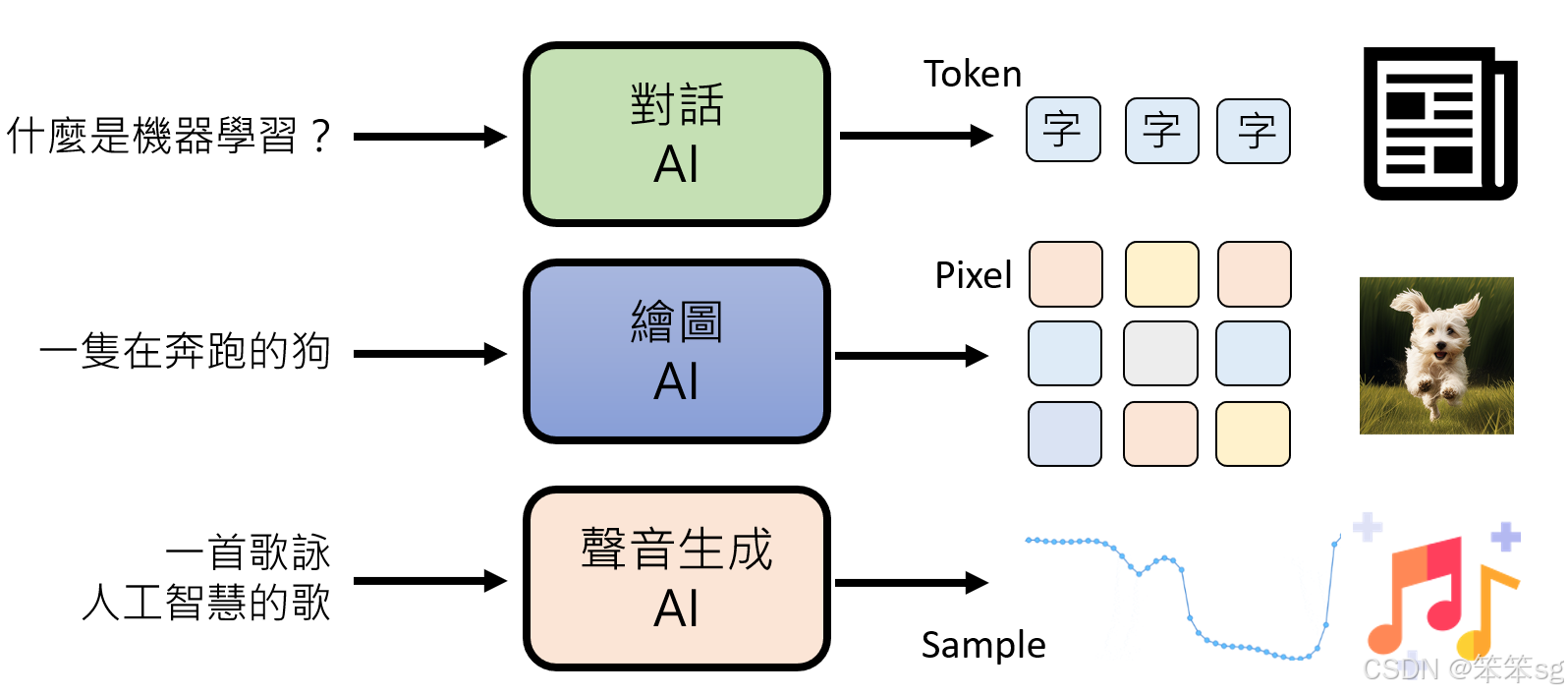
1 文本生成
- 条件:输入文本或问题(例如对话中的问题)。
- 基本单位:Token。
- 生成过程:
- 根据输入条件预测每个 token 的最优选择。
- 将这些 token 按序组合,形成完整的输出句子或段落。
- 例子:
- 用户输入:“请解释生成式人工智能的原理。”
- AI 输出一段符合条件的文本作为回答。
2. 图像生成
- 条件:描述性文本(Prompt)或输入图片。
- 基本单位:像素(Pixel)。
- 生成过程:
- 模型解读输入条件,如“生成一只正在弹钢琴的猫”。
- 根据条件预测每个像素的颜色和位置,组合成符合描述的图片。
- 例子:
- 输入描述:“一片宁静的秋日森林。”
- AI 输出一张展现秋日森林的图片。
3. 声音生成
- 条件:文本(例如语音合成的台词)或声音片段(如音乐生成的基础旋律)。
- 基本单位:取样点(Sample)。
- 生成过程:
- 根据输入条件预测每个取样点的数值。
- 将这些取样点组合形成连续的声音信号,如语音、音乐或效果音。
- 例子:
- 输入:“请将这段文字转成语音。”
- AI 输出对应的语音文件。
3.2 通用生成框架
尽管应用场景不同,但生成式 AI 的核心问题始终是如何根据条件生成输出:
-
输入条件:条件定义了输出的目标和限制。
-
基本单位:不同任务的基本单位可能是 token、pixel 或 sample,但其作用一致:作为组合的最小构件。
-
生成过程:
- 模型从条件中提取信息,按概率分布预测下一步基本单位的选择。
- 通过逐步迭代,最终生成复杂的输出。
-
输出结果:根据条件生成符合期望的完整作品。
4 Auto-Regressive (AR) 生成方式
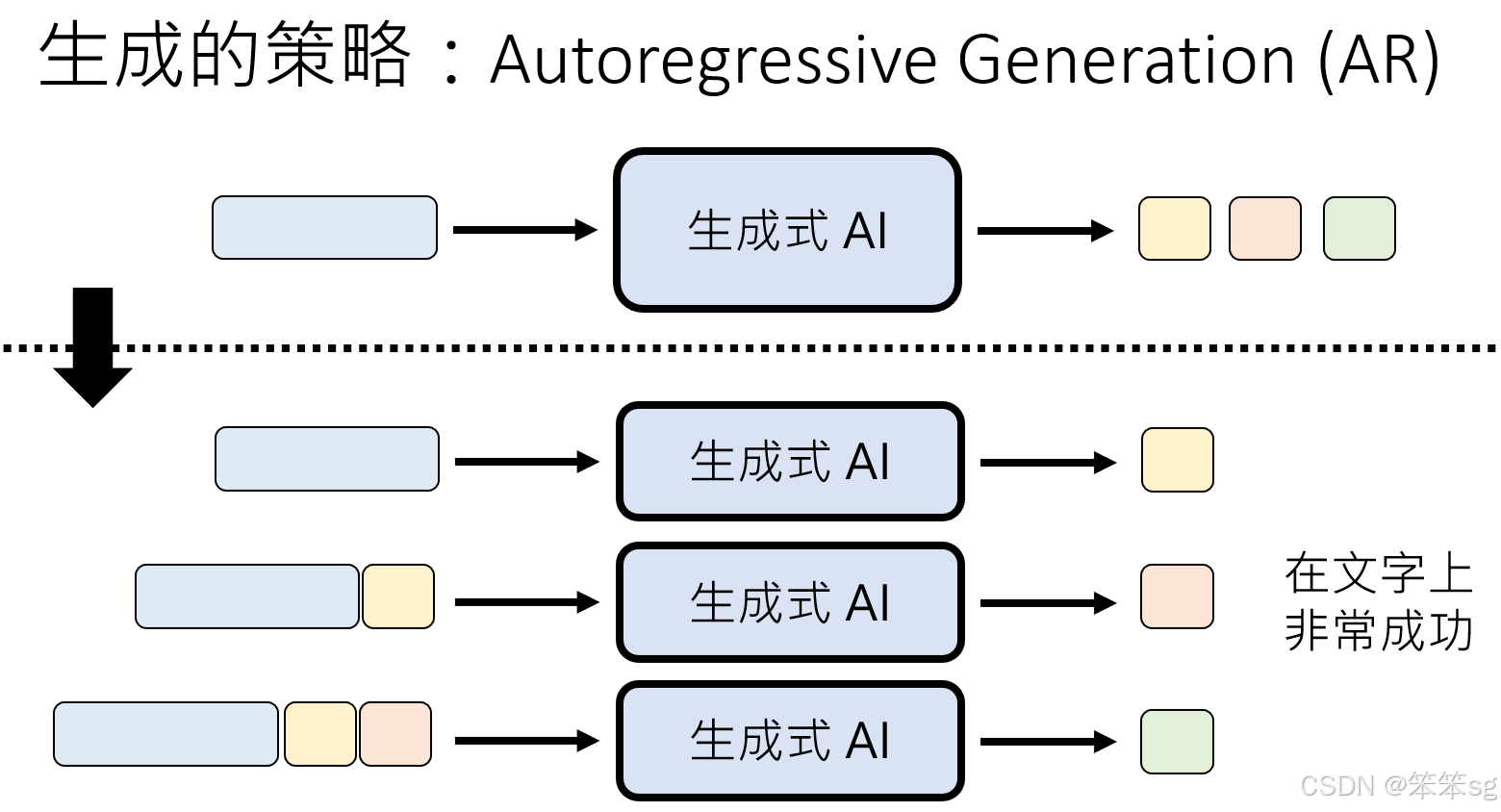
4.1 原理
- 逐步生成:
- 每次只生成一个基本单位(如 token、像素、sample)。
- 将上一次生成的结果作为输入,继续生成下一个单位。
4.2 优点
- 生成逻辑严谨:每次生成依赖前面的结果,因此生成序列具有很强的上下文一致性。
- 适合语言任务:自然语言的逻辑性和连贯性对顺序依赖性要求高,AR 方法表现优异。
4.3 缺点

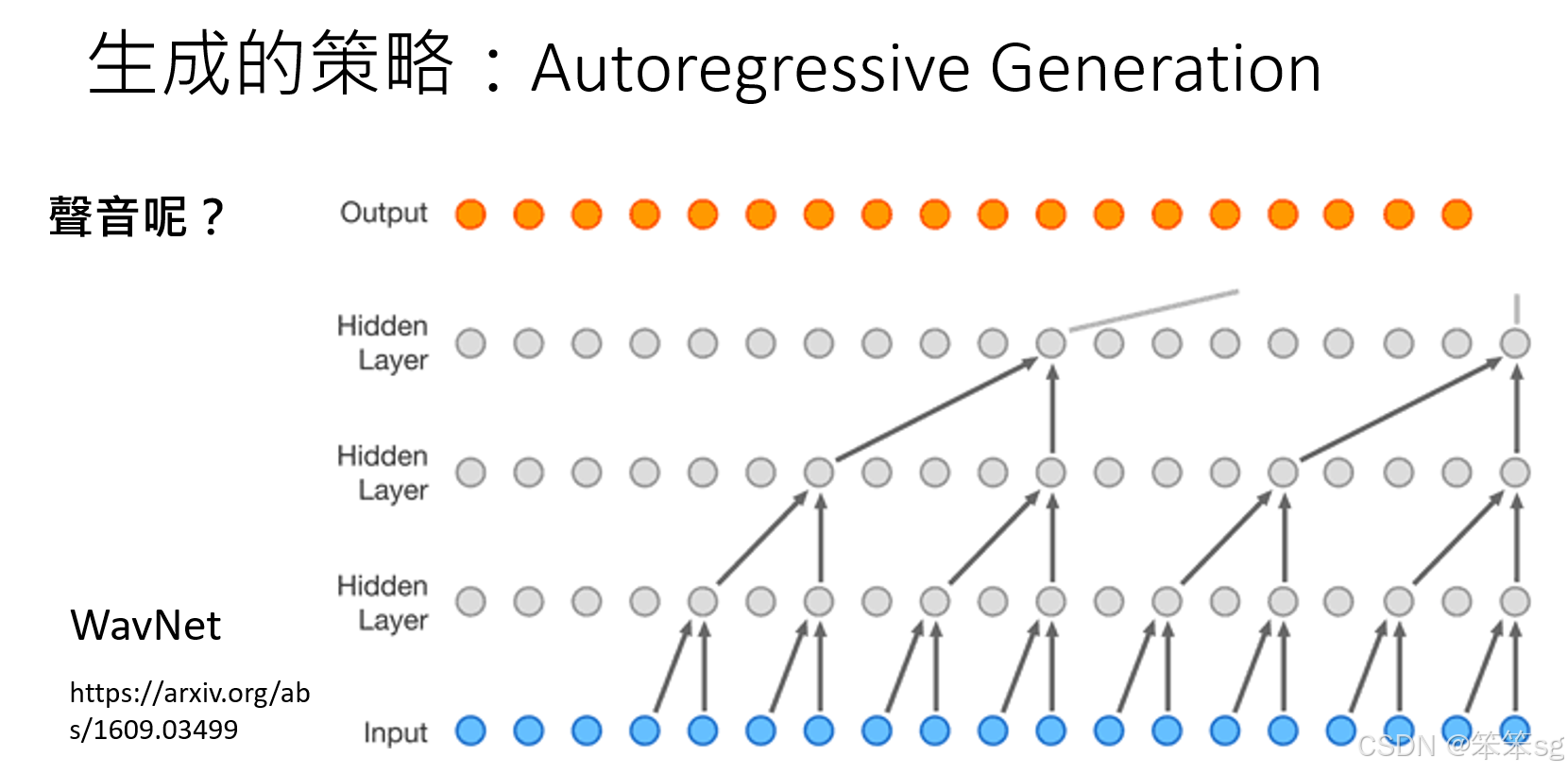
- 生成速度慢:
- 必须按顺序逐一生成,无法并行。
- 生成高分辨率图片或高采样率语音需要大量迭代,例如:
- 一张 1024×1024 图片约需 100 万次生成。
- 一分钟 22kHz 语音约需 132 万次生成。
- 时间成本高:即使计算设备性能强大,序列生成的固有顺序性无法避免。
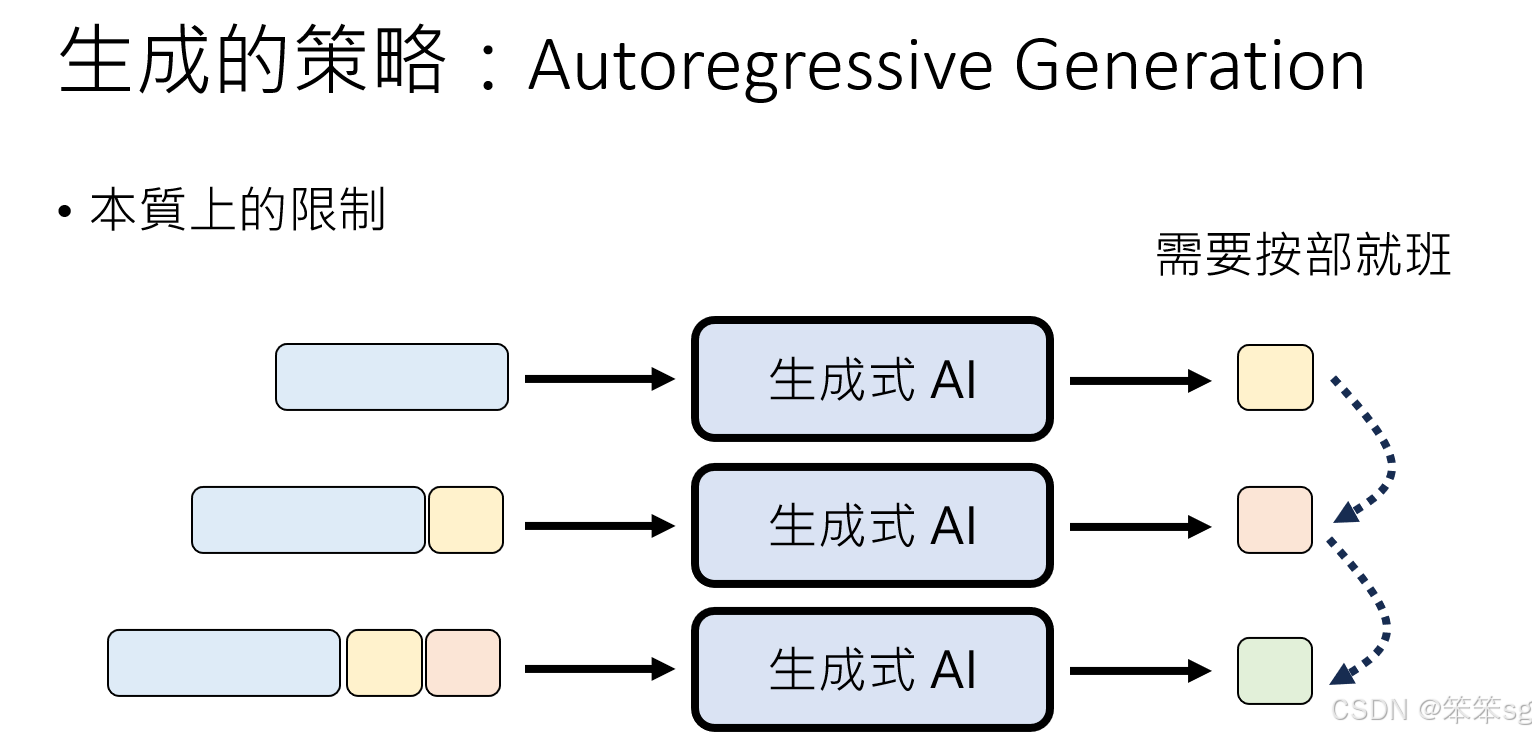
4.4 应用场景
适合对上下文依赖性强的任务,例如文本生成(如 ChatGPT)。
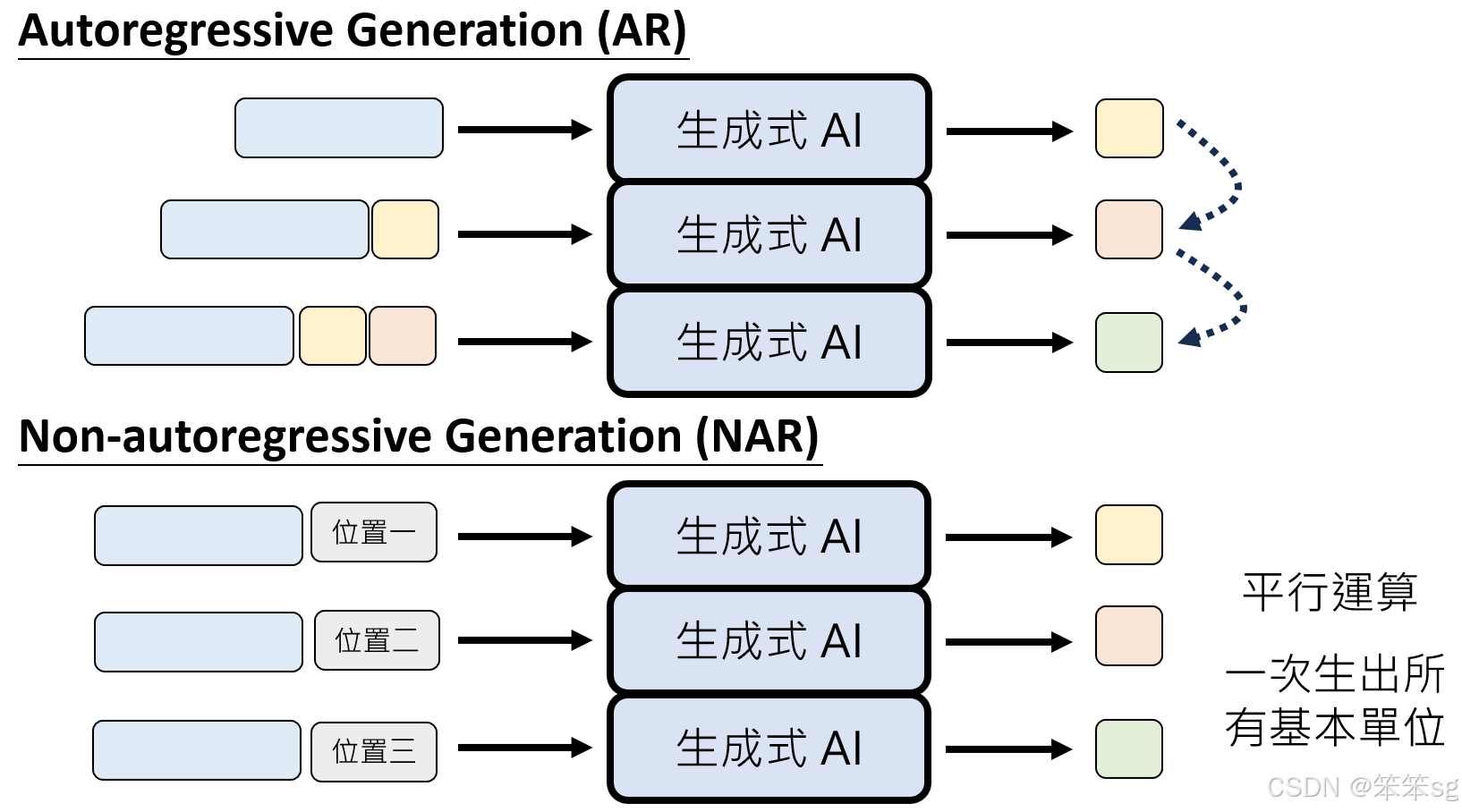
5 Non-Auto-Regressive (NAR) 生成方式
5.1 原理
- 同时生成:
- 将所有基本单位一次性并行生成。
- 不再逐步依赖前一个结果,而是基于整体条件预测所有位置的值。
5.2 优点
- 生成速度快:依赖硬件的平行运算能力,所有单位可同时生成。
- 适合高维输出:像素或 sample 数量庞大时,NAR 方法避免了逐步生成的时间瓶颈。
5.3 缺点
- 一致性可能受影响:缺乏前后依赖关系的指导,可能导致生成内容逻辑性不足,尤其在语言生成中表现明显。
5.4 应用场景
- 适合对上下文依赖性要求较低的任务,例如:
- 图像生成:像素相对独立,NAR 模型能快速生成高分辨率图片。
- 语音生成:例如 Google 的 Parallel WaveNet,直接预测所有 sample,大幅提高生成效率。
6 为什么影像和语音生成更适合 NAR 方法?
6.1 图像生成的瓶颈

- AR 模型(像素接龙):
- 一张 1024×1024 图片需要 100 万次逐步生成。
- 时间成本极高,实际应用中难以忍受。
- NAR 模型:
- 所有像素一次性并行生成,避免了逐步生成的冗长过程。
- 高效利用硬件的并行计算能力,大幅提升速度。
6.2 语音生成的瓶颈
- AR 模型(sample 接龙):
- 一分钟语音约需 132 万个 sample,逐步生成需要数小时。
- NAR 模型:
- Parallel WaveNet 等直接并行生成所有 sample,实现实时语音生成。
7 Auto-Regressive 与 Non-Auto-Regressive 的运算对比
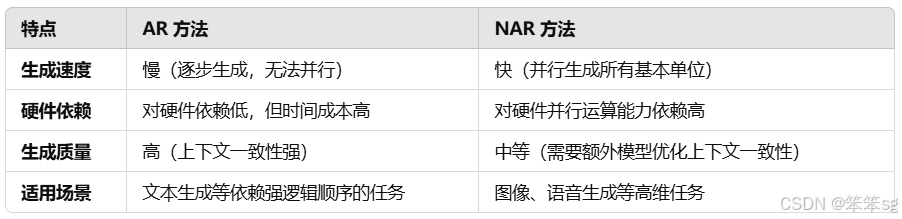
8 文字生成也可以使用NAR
NAR(Non-Auto-Regressive)生成方式不仅可以应用于图像和语音生成,也可以尝试用于文字生成,尤其是在提高生成速度方面。在现有的文字生成模型中,通常采用Auto-Regressive(AR)方法,即逐字(或逐token)生成,而你提到的NAR方法则有潜力在这个过程中加速生成。下面是将NAR应用于文字生成的思路:
8.1 预测生成的长度并并行生成
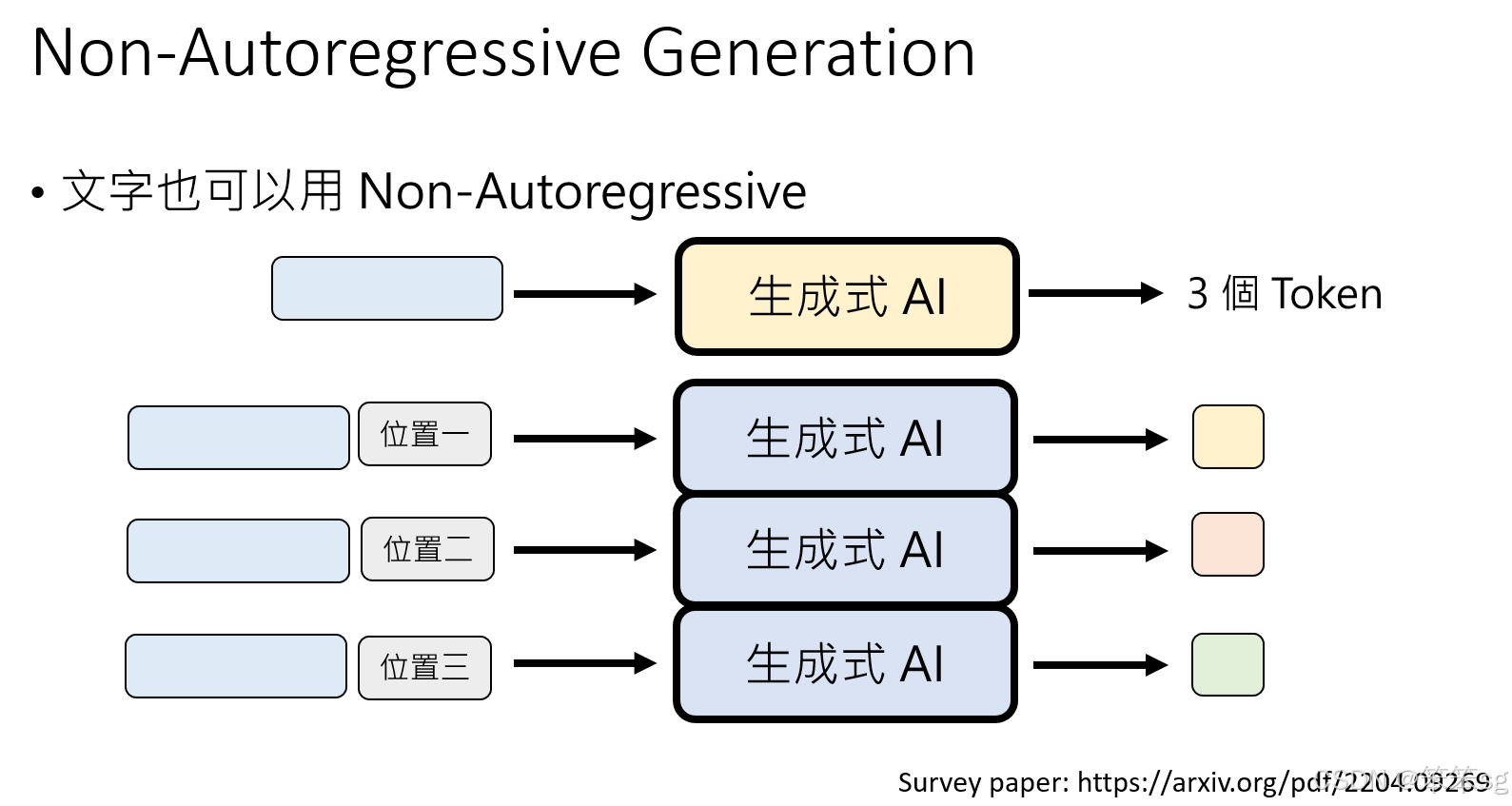
-
方法:在开始生成之前,首先让语言模型预测需要生成多少个tokens。例如,在给定输入后,模型首先预测输出的token数量(如3个token),然后再生成这3个token。这样做的好处是可以使生成过程更高效,但仍然保持了一定的顺序生成结构。
-
挑战:语言生成的上下文依赖性较强,模型需要对输出的整体结构和语义有一定的预测能力。
-
实现方式:类似于生成图像时,先固定输出的token数量,再对每个位置的token进行并行生成。在生成后,模型根据上下文情况进行适当的修正。
8.2 固定长度输出并筛选有效部分
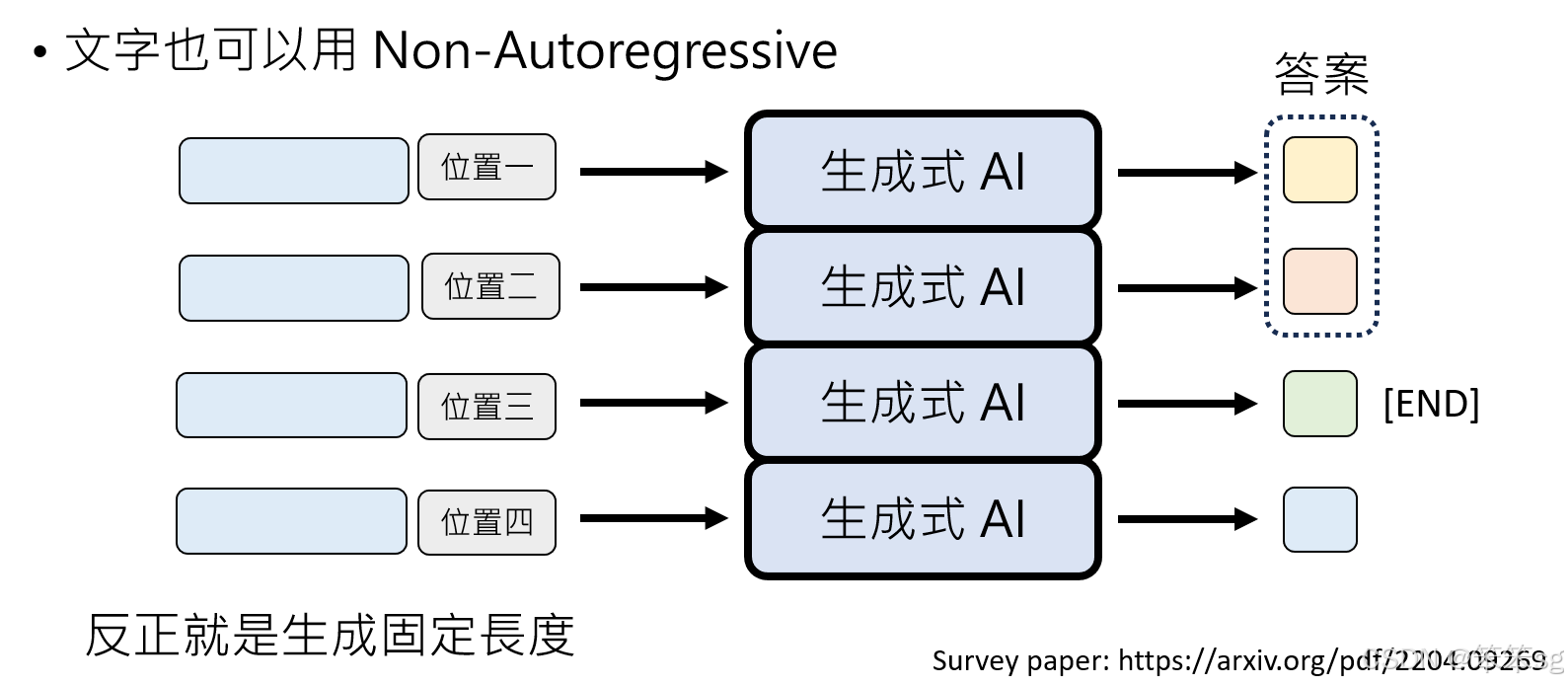
-
方法:另一种方式是,告诉语言模型生成一个固定长度的输出(如1~1024个token),无论输入是什么,模型都一次性生成该长度的文本。生成完之后,可以根据特定符号(如 "END")进行筛选,删除生成文本中多余的部分,只保留有意义的部分作为最终输出。
-
实现方式:这种方法的关键在于模型能够在固定长度内生成尽可能精确和合适的内容,然后通过符号或结构化标记(如 "END")来决定文本的截断。
9 NAR的品质问题
NAR(Non-Auto-Regressive)生成方式在图像生成中可能带来加速,但在文字生成中却面临一些挑战,主要是与生成结果的质量和一致性相关。
9.1 NAR生成方式在文字生成中的问题:
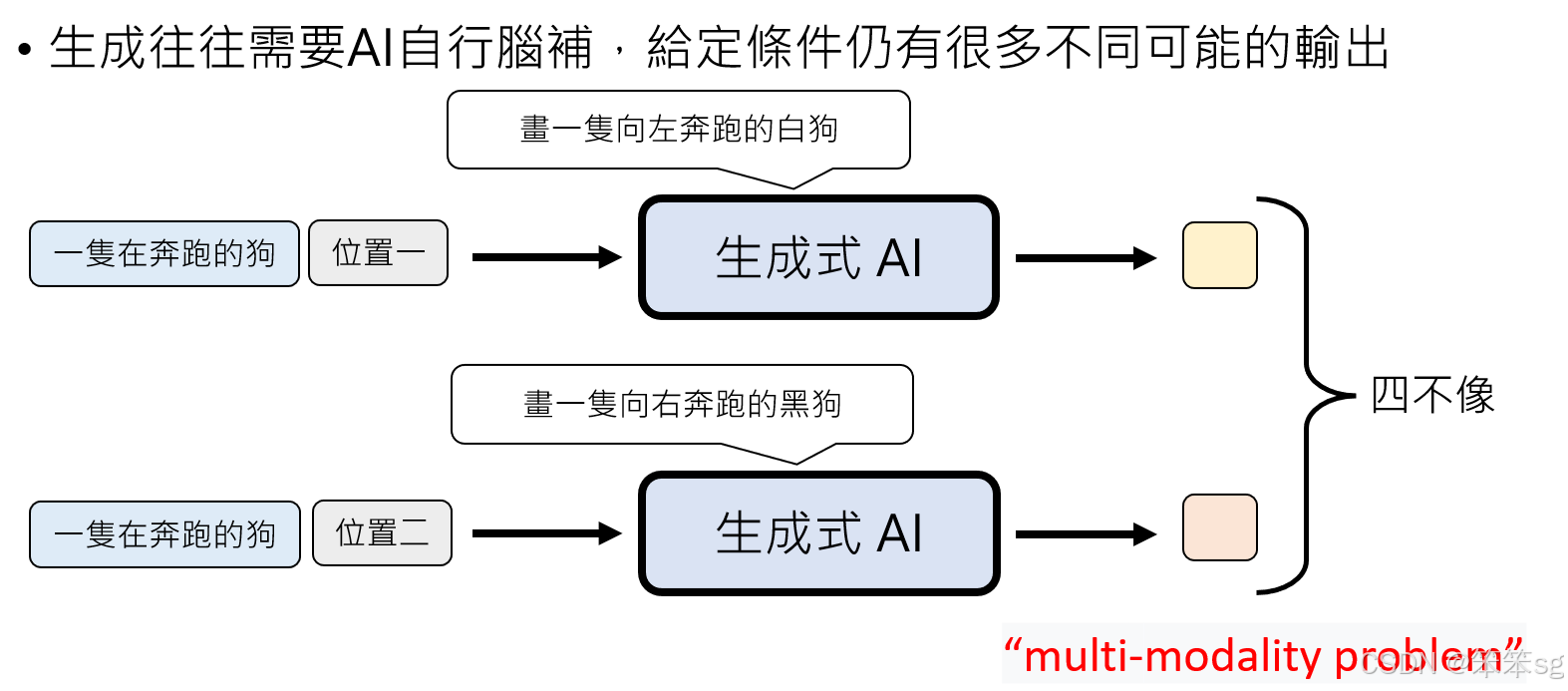
-
多样性和一致性的问题(More Time Modality): NAR生成的核心问题之一是它容易产生不一致的结果。例如,在图像生成中,如果我们并行地生成每个像素,模型可能会对同一图像的不同部分产生不同的理解,从而导致生成的图像混乱,出现不一致的情况。类似的,在文本生成中,NAR可能会在生成不同token时,模型在“脑补”时产生不同的上下文或含义,导致生成的文本缺乏逻辑连贯性和一致性。
例子:你提到的例子“李宏毅”,在NAR生成中,模型可能会在不同位置生成不一致的输出(例如,“李宏毅是演员”与“李宏毅是教授”这两种可能性)。如果在生成时没有依赖于前面的上下文,这种多样性可能会导致语句不连贯或者语义模糊。
-
缺乏上下文依赖性: NAR模型在生成时无法像Auto-Regressive(AR)模型那样依赖于已生成的token上下文。在AR模型中,生成下一个token时会考虑到之前所有的token,这有助于保持生成内容的一致性和连贯性。而在NAR模型中,每个token的生成是独立的,无法保证生成的文本保持语义的一致性,因此容易产生“四不像”的效果。
-
多样性与质量的平衡: NAR虽然能加速生成过程,但生成的质量常常较低,因为它不具备逐步纠错的能力。Auto-Regressive模型通过逐步生成和实时纠正,不断优化生成内容,而NAR则是一次性并行生成,缺少这种逐步改进的过程。即使是相同的输入,NAR生成的内容可能会偏离原始意图,导致生成的文本显得不自然或者与上下文不符。
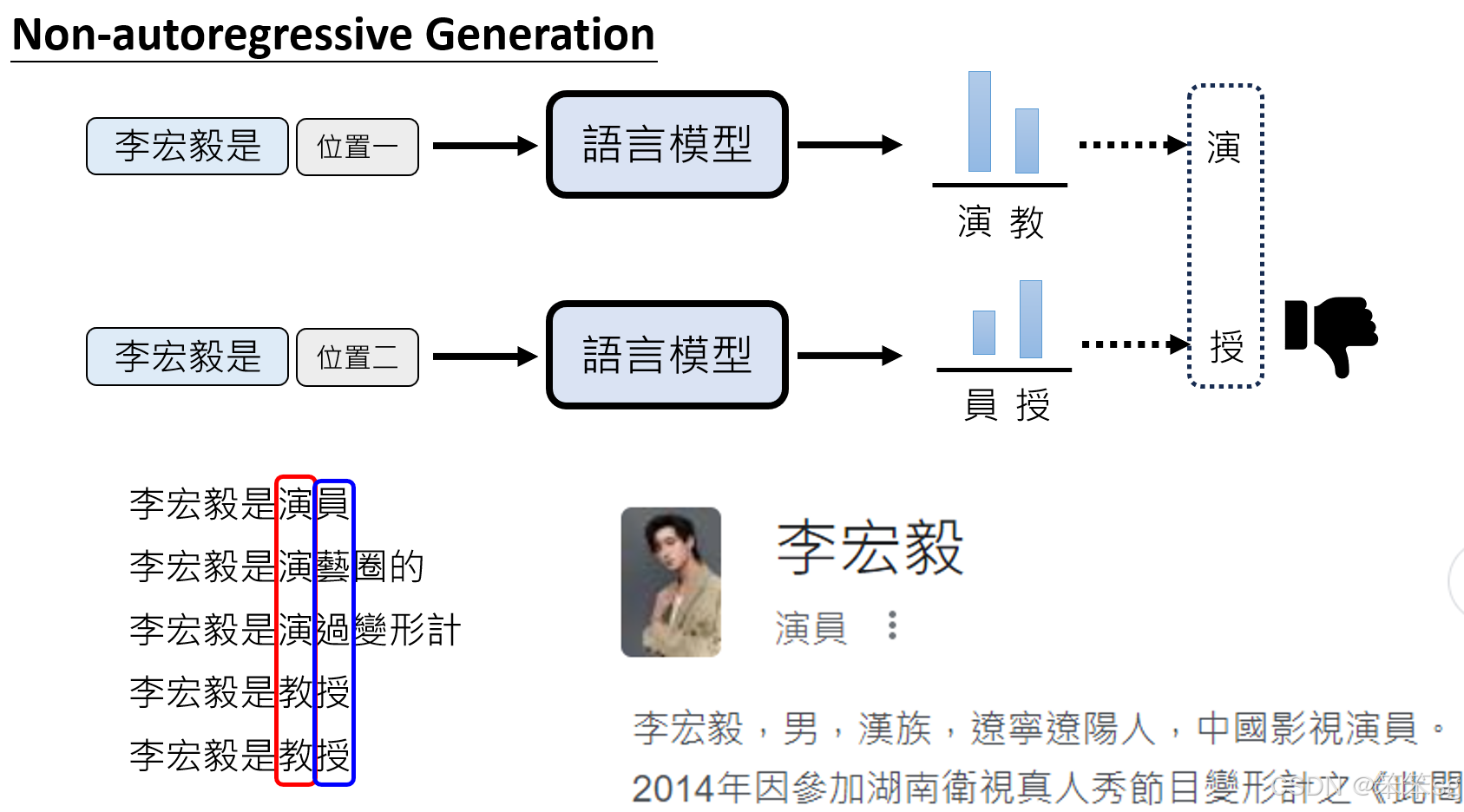
9.2 Auto-Regressive模型的优势:
-
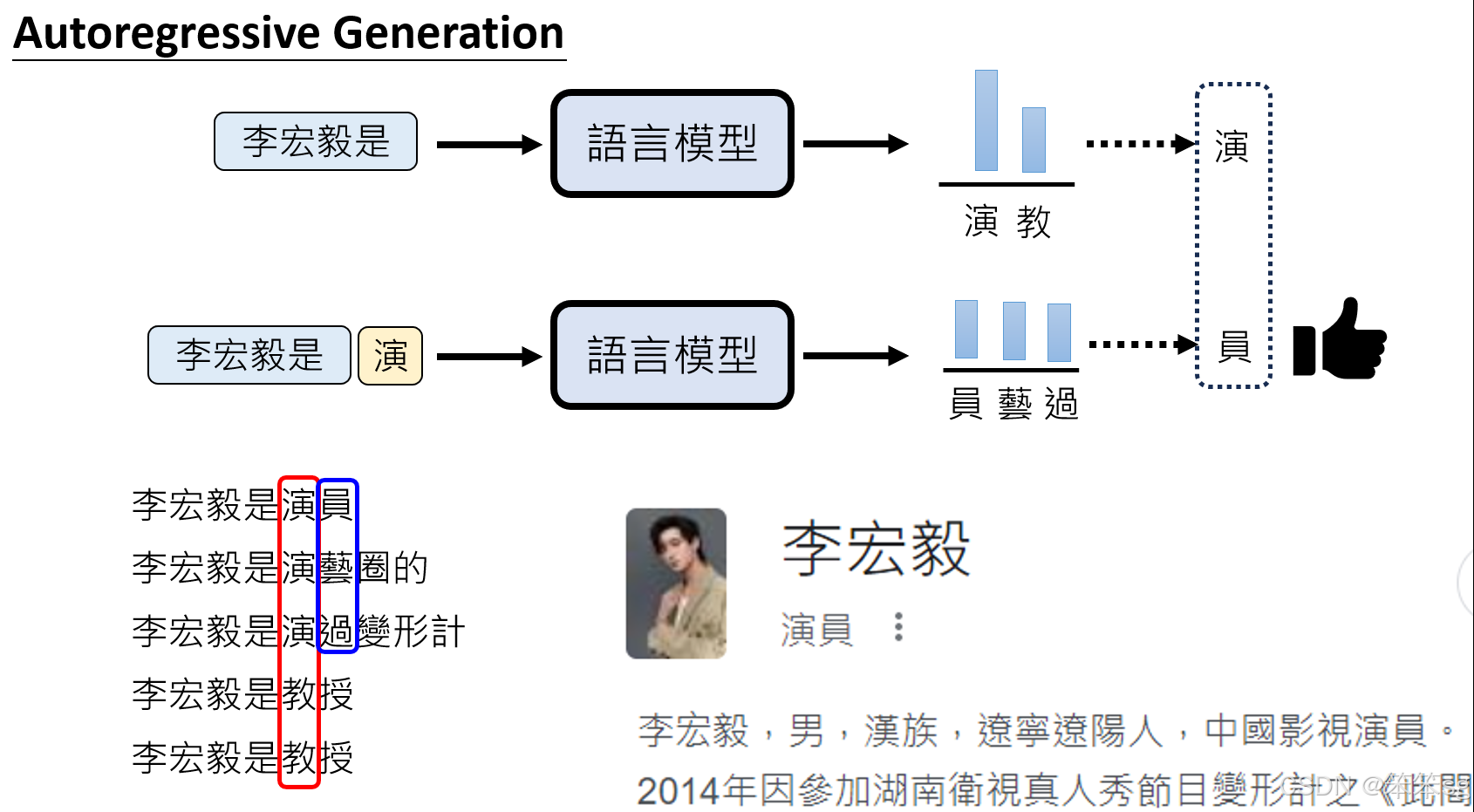
逐步生成和上下文依赖性: Auto-Regressive模型逐步生成每个token,且每个token的生成都依赖于前面已生成的内容,这使得模型能够保持生成内容的连贯性和一致性。例如,在你给出的“李宏毅”例子中,AR模型首先生成“李宏毅是演”,然后再生成后续内容,如“演员”或“教授”,确保语句的连贯性。模型根据训练数据的统计信息做出合理选择,并且每一步都考虑到前文的生成内容,从而避免了出现不连贯或不合逻辑的结果。
-
避免“多样性问题”: AR模型通过每步生成都依赖前文,不会像NAR那样在不同token生成时出现不同的“意图”。因此,AR能够在生成过程中维持一致性和高质量的输出,不会像NAR那样产生混乱的文本。
9.3 总结:
NAR生成方式虽然能加速生成过程,但在文字生成中,模型的多样性和上下文依赖性不足,导致生成结果容易出现不一致、逻辑混乱的情况。因此,尽管NAR在图像生成上有一定优势,文字生成仍然主要采用Auto-Regressive(AR)方法,以确保文本的质量和连贯性。AR通过逐步生成,每个token都基于前文的上下文,保证了生成结果的语法和语义的一致性。
10 克服NAR(Non-Auto-Regressive)生成的局限性—方法一
前面我们提到用在文字生成领域使用NAR会造成前后不一致(不连贯)的问题,但是图像和语音的生成却不得不使用NAR这种方式,那么这两个是如何克服上述问题的呢?
10.1 NAR生成问题的核心:
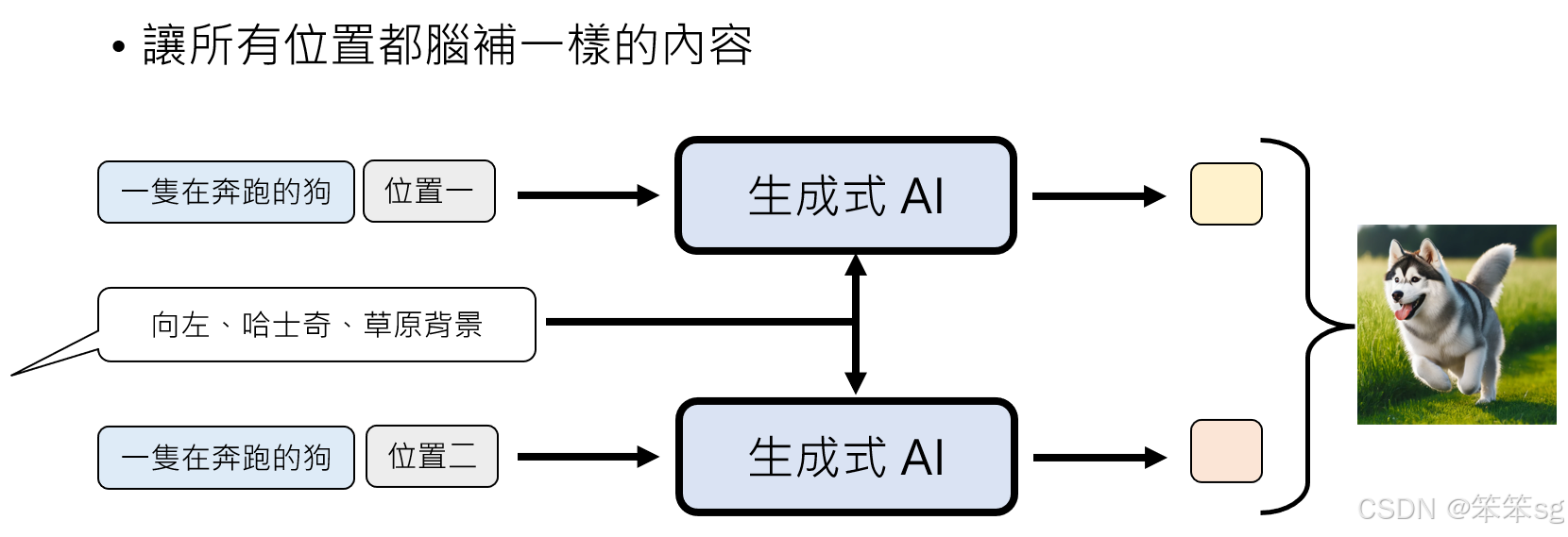
-
脑补的不一致: 在NAR生成中,模型在不同位置生成像素时,无法保持一致的脑补内容,导致图像质量不高。例如,生成图像时不同位置的像素可能反映出不同的意图,导致图像看起来混乱或不自然。
-
解决办法:提供更多的上下文: 就是在图像生成时,通过额外提供信息,让模型从一开始就知道如何生成整个图像。例如,输入不仅仅是“要画一只在奔跑的狗”,而是附加更多的描述性信息,比如这只狗是“向左奔跑的哈士奇,背景是草原”。这样,模型在生成每个像素时都有统一的脑补内容,不会出现不一致的生成。
10.2 生成模型中的新方法:随机向量
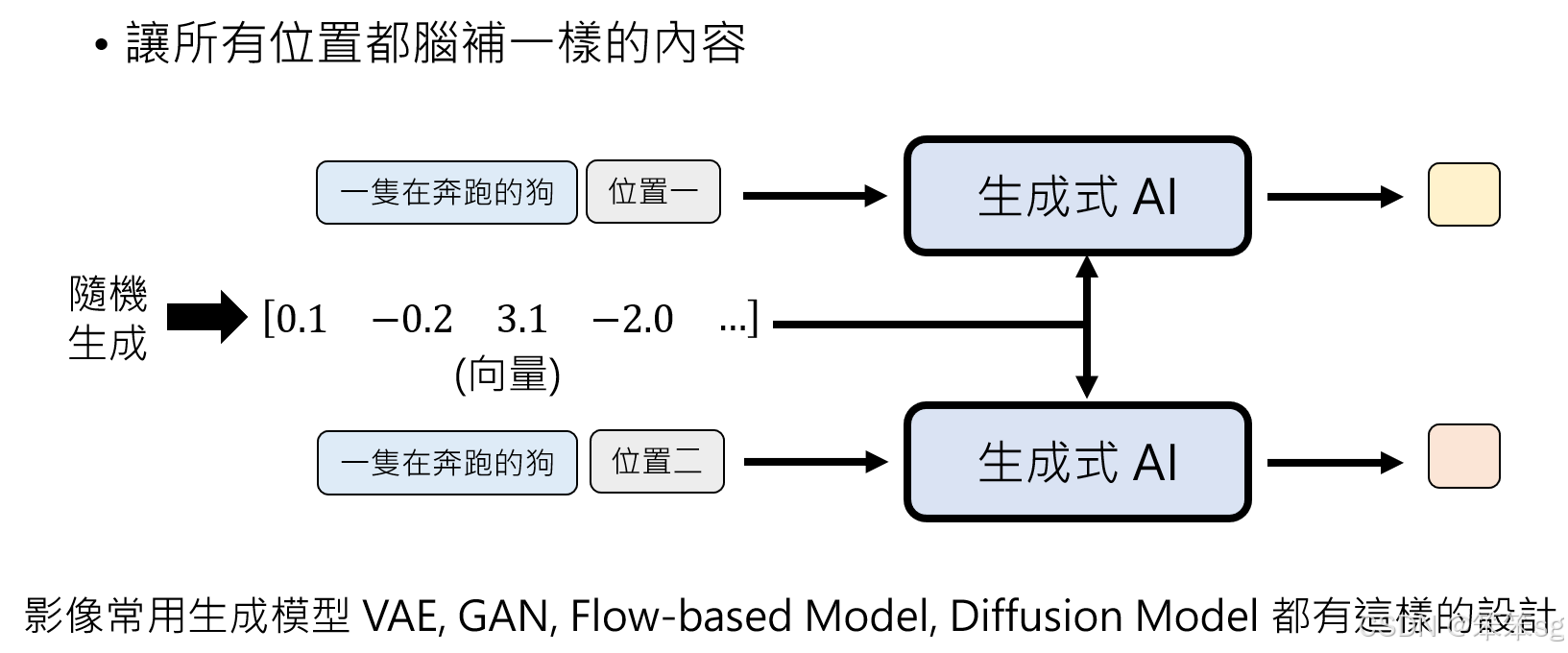
在影像生成中,尤其是像VAEs(Variational Autoencoders)、GANs(Generative Adversarial Networks)、Flow-based models和Diffusion models等模型中,确实普遍采用了一个设计:先生成一个随机向量,然后将这个向量作为输入之一,与其他条件信息(如文字描述)一起输入到生成模型中。
随机向量的作用:这个随机向量是用来给模型提供一个“随机噪声”或“潜在空间”的初始化状态。它起到了“脑补”的作用,确保无论在哪个位置生成像素时,模型都在考虑相同的背景信息,从而保证整张图片的一致性和质量。
10.3 Auto-Regressive与Non-Auto-Regressive模型结合的策略:
一句话概括:先用AR生成精简版本(相当于是写论文之前搭好一个整体的框架,例如1:引言;2:材料与方法.....),确定完框架后,然后再用NAR填充各个小节的内容,有了指导思想的帮助便可以解决前后不一致(不连贯、矛盾)的问题。
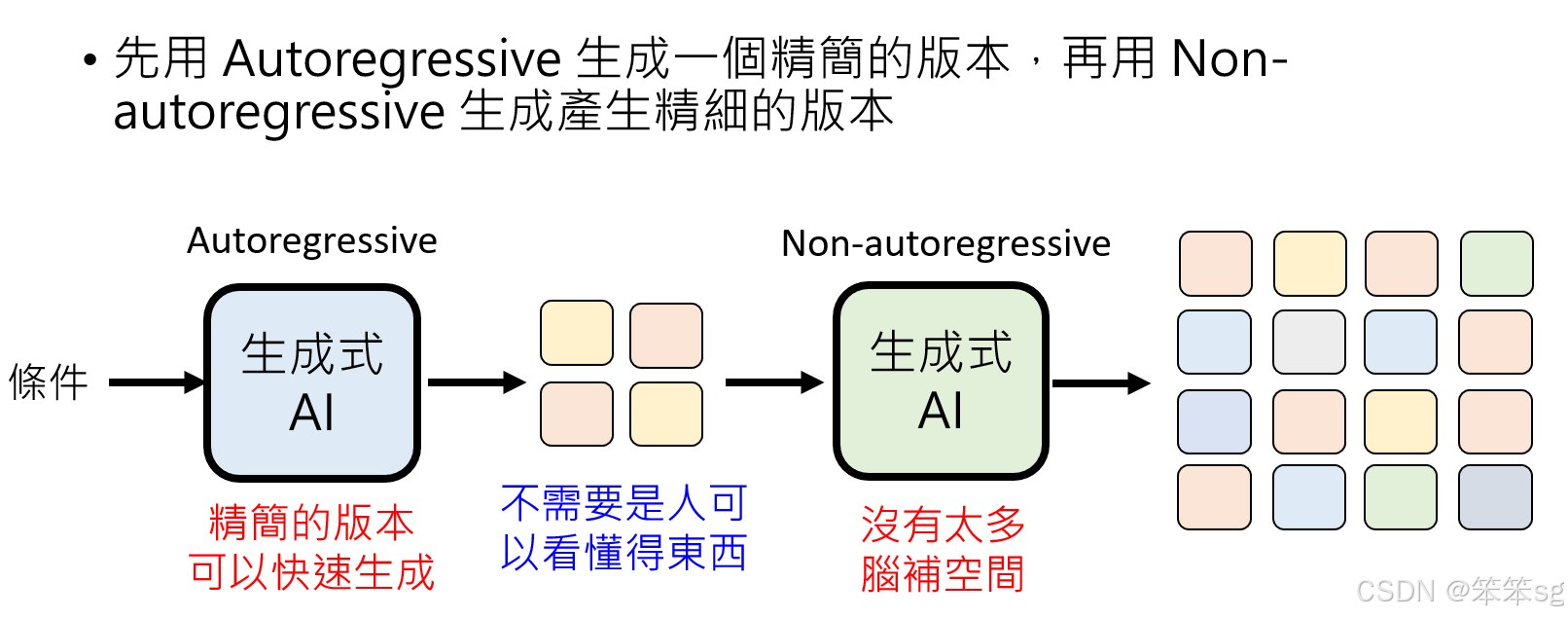
-
Auto-Regressive模型的局限性: Auto-Regressive(AR)模型擅长生成精细的内容,但生成速度较慢,尤其在处理高分辨率的图像或复杂的生成任务时。AR模型的逐步生成方式也使得生成时间变长。
-
Non-Auto-Regressive模型的局限性: Non-Auto-Regressive(NAR)模型可以并行生成,速度较快,但它存在一个问题——生成时容易脑补不一致,导致输出不符合预期。因此,NAR在精度上可能不如AR。
-
结合方法:先生成精简版本,再细化: 解决方案是将两者结合起来:首先使用Auto-Regressive模型生成一个精简版的输出,这个精简版不需要非常细致,但能提供框架和结构。接着,再使用Non-Auto-Regressive模型根据这个精简版生成更精细的版本,因为精简版本已经限制了可变性,减少了NAR模型出错的空间。
- 例如,在图像生成中,AR模型生成的是一个粗略的草图或低分辨率的版本,确定了整体框架(比如,图像的主题、色调和大体结构)。然后,NAR模型基于这个草图进行细化,生成高分辨率的最终图像。
10.4 如何生成精简版本:使用Autoencoder:
为了生成一个可供AR模型生成的“精简版本”,可以使用Autoencoder(自编码器)来压缩数据:
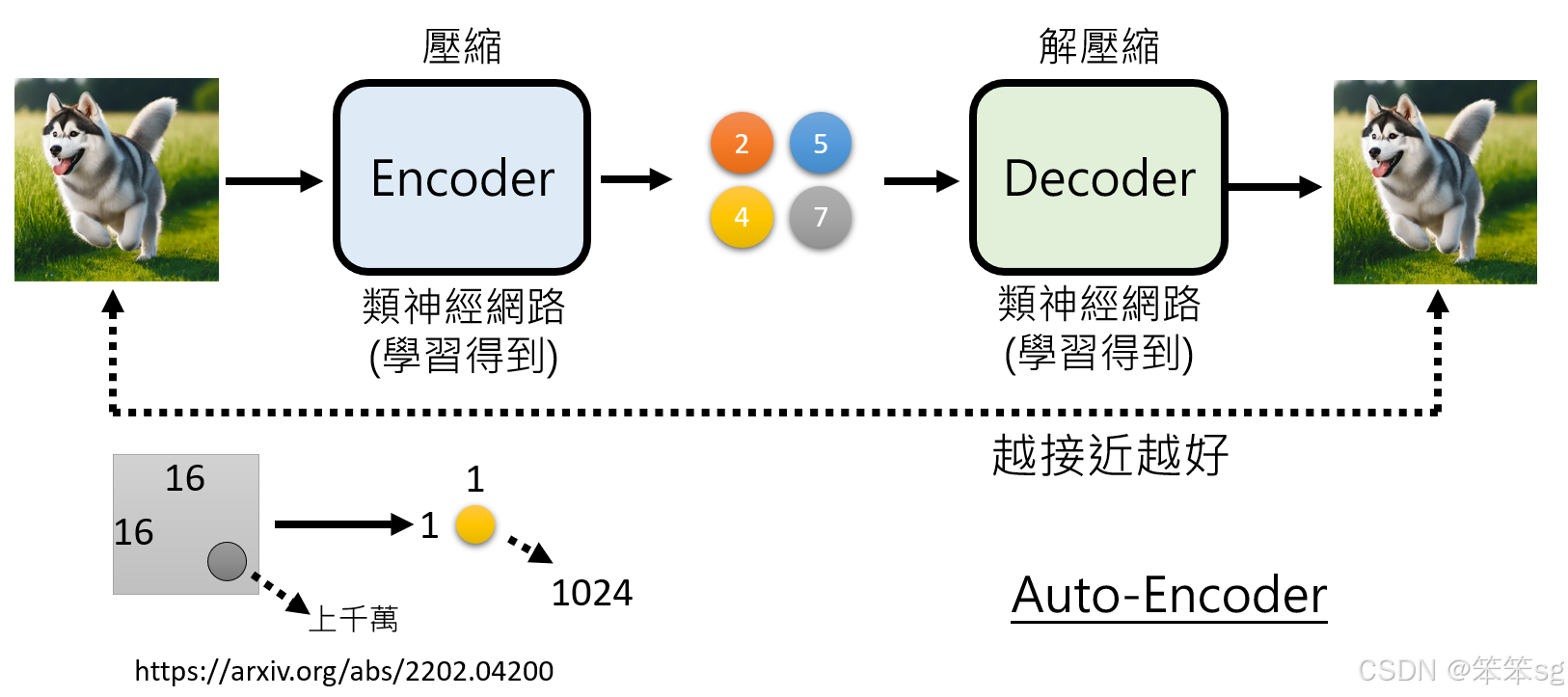
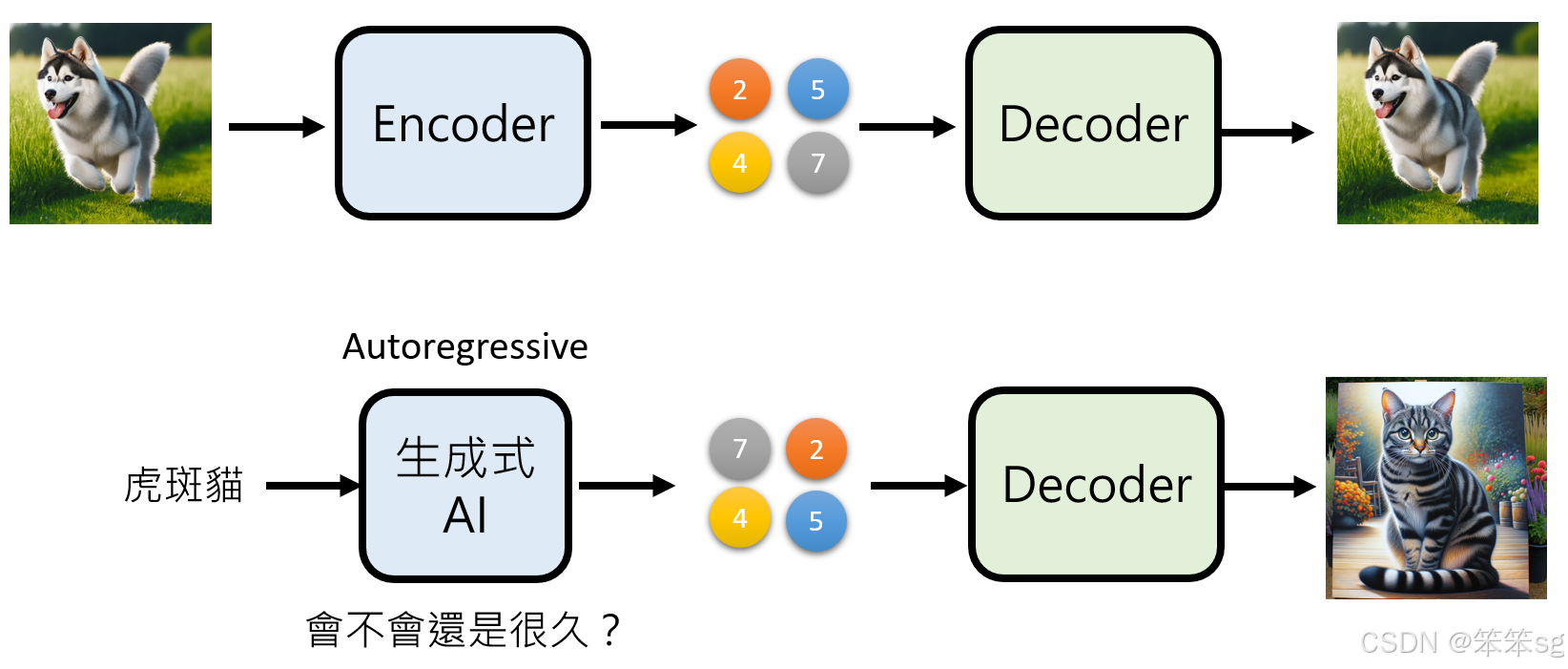
-
Autoencoder的基本原理:
- Encoder部分将图像压缩为一个低维的表示(潜在空间),这个表示对人类来说可能是不可读的,但对于模型而言,它包含了生成图像所需的关键信息。
- Decoder部分负责将这个低维表示还原为图像。在训练过程中,Autoencoder的目标是使压缩后的版本与原图尽可能相似。
-
如何利用Autoencoder生成精简版:
- 首先通过训练一个Autoencoder模型,将输入图像压缩为一个低维表示。这个低维表示包含了图像的主要结构信息,但不会包含细节。
- 然后,AR模型生成的是这个压缩后的版本,而不是原始的高维图像。
- 最后,使用NAR模型基于这个压缩版的图像生成最终的高质量图像。
10.5 在语音生成中的应用:
这种方法不仅可以应用于图像生成,还可以扩展到语音生成。比如,在语音生成中,可以使用类似的编码解码策略:
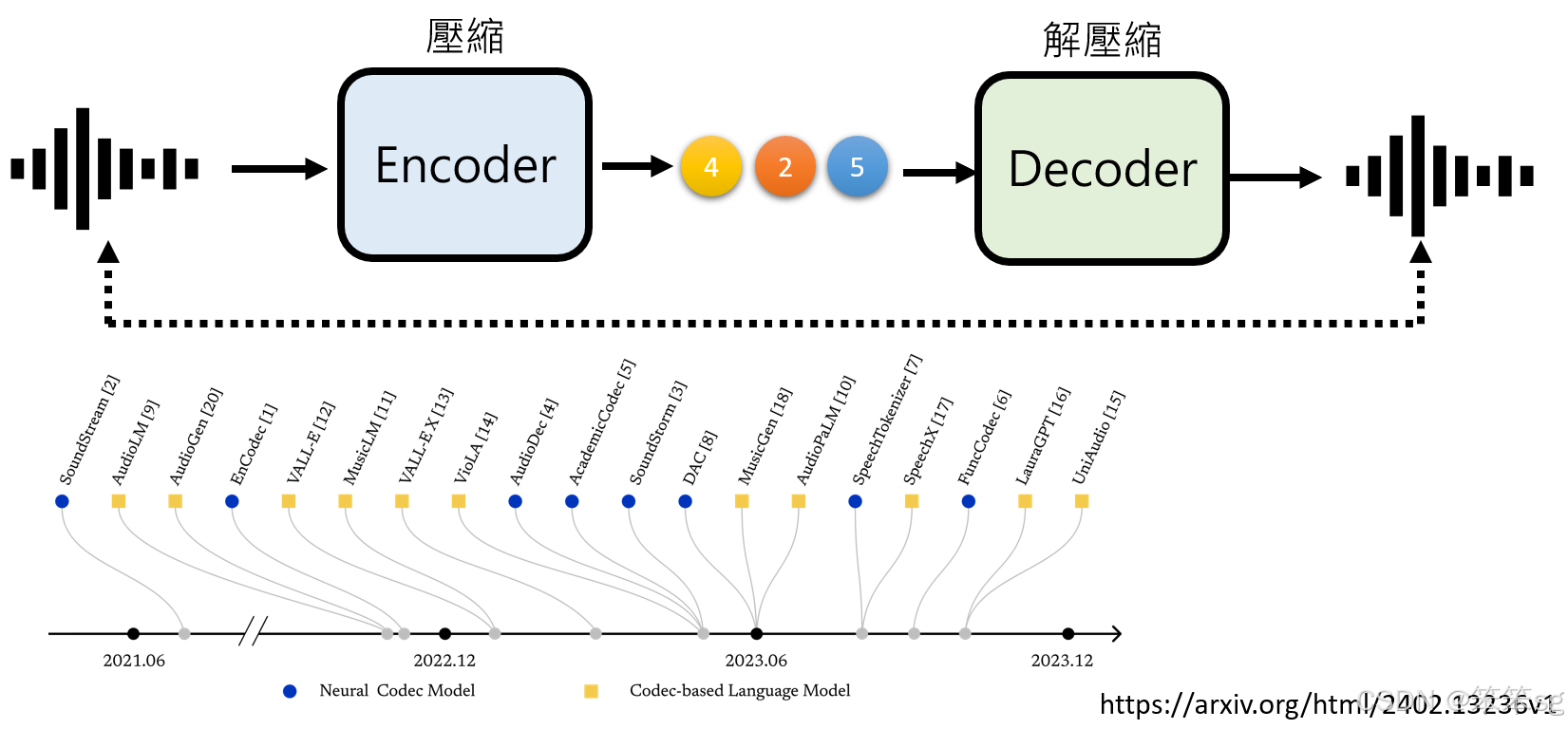
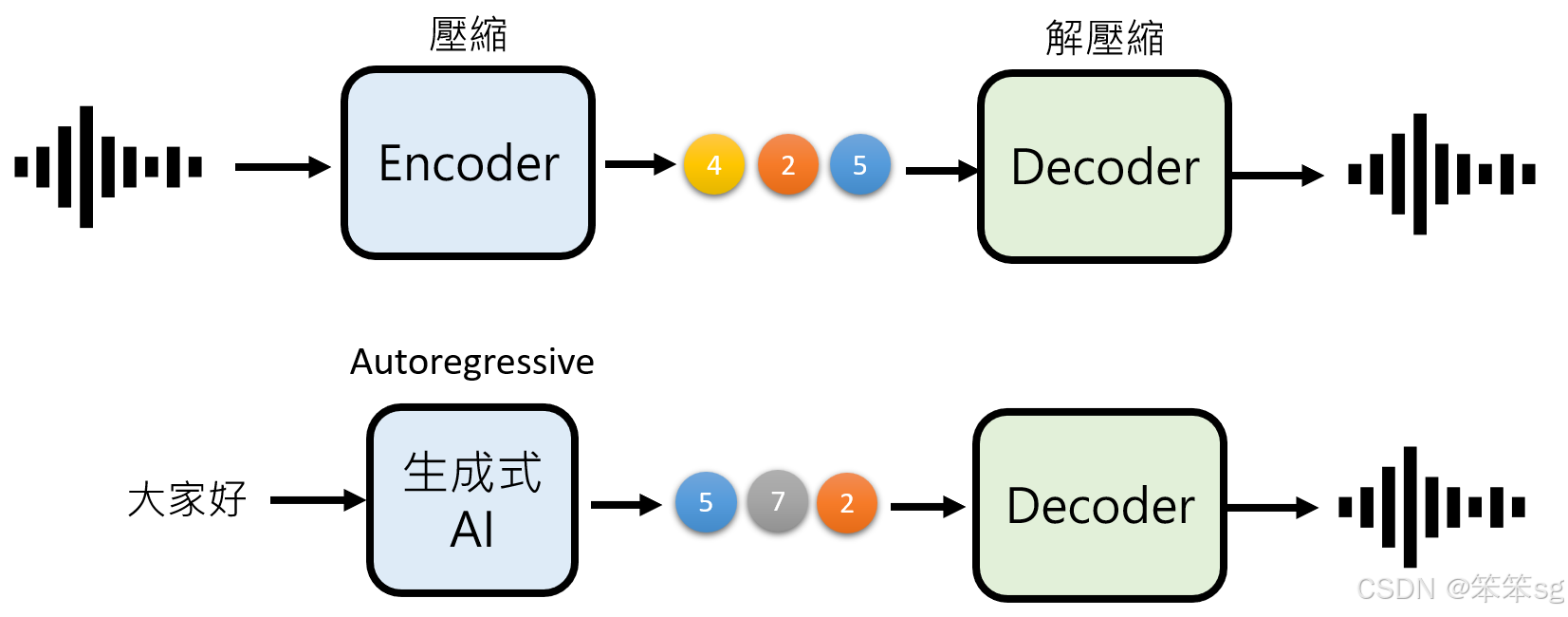
- Encoder将原始的语音信号压缩为一个简化版本,这个版本对人类来说同样是不可理解的。
- AR模型用来生成这个压缩后的语音版本,之后通过NAR模型来快速恢复出原始的复杂语音信号。
11 克服NAR(Non-Auto-Regressive)生成的局限性—方法二
要克服nauto-regressive模型的生成品质问题,还有另一种有效的方法,可以通过多次使用nauto-regressive生成来改善。以下是一些常见的策略:
11.1 分阶段生成:
这是一种通过将生成过程分解为多个阶段,每个阶段都使用nauto-regressive模型生成结果的方法。每个阶段的生成会依赖前一个阶段的结果,并且每次生成的版本之间差异较小,因此可以避免不一致的“脑补”问题。
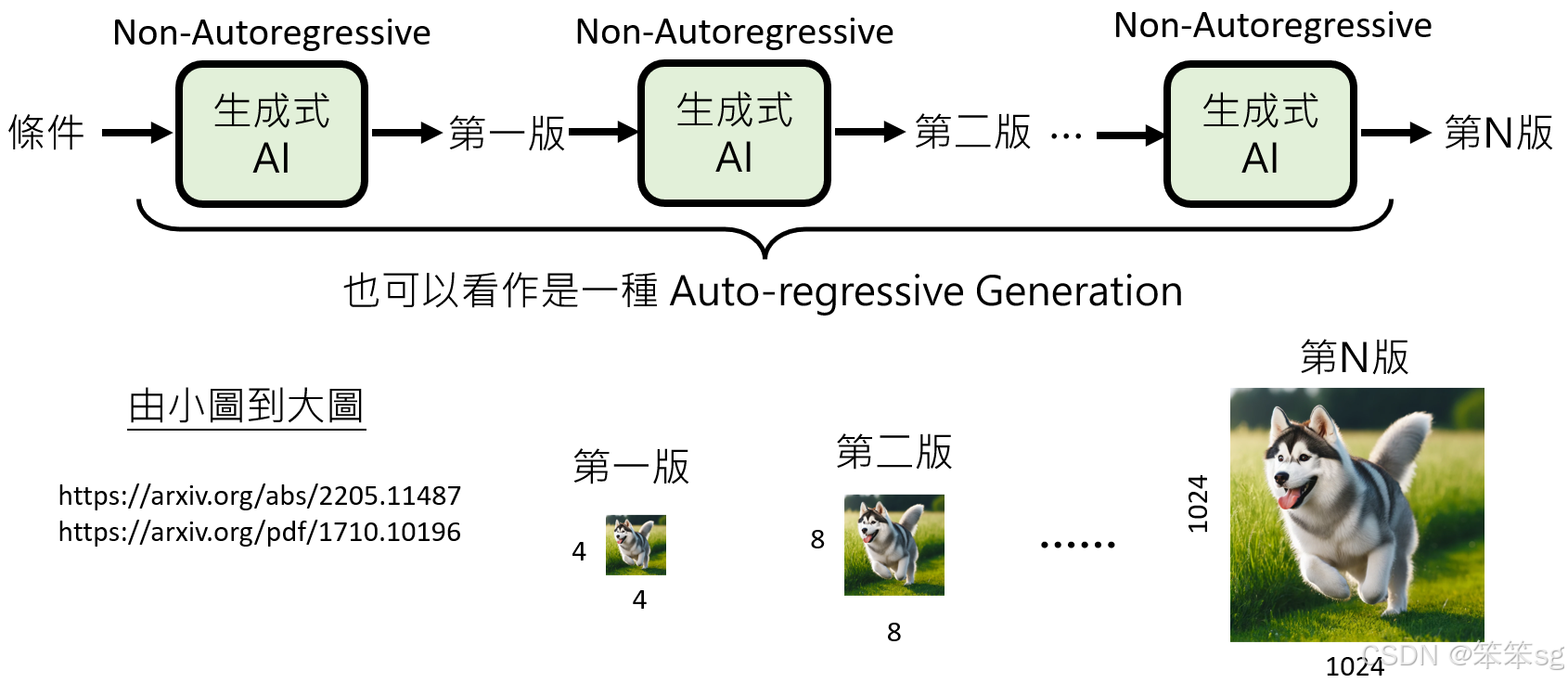
举例来说,可以从小尺寸的图像开始生成,然后逐步生成更大尺寸的图像。例如,第一个阶段生成一个4×4像素的图像,接下来生成8×8像素的图像,直到最终生成1024×1024的图像。由于每个阶段之间的差异很小,生成过程更加稳定,减少了不一致性的问题。
11.2 从有噪声到无噪声的生成:
另一种方法是从一个充满噪声的图像开始生成,然后逐步去除噪声,直到得到一个清晰的图像。这正是著名的扩散模型(Diffusion Model)的原理,它通过多个生成步骤从一个杂乱无章的图像开始,并逐渐变得更加清晰。每个步骤减少一些噪声,直到最后得到一个无噪声的图像。
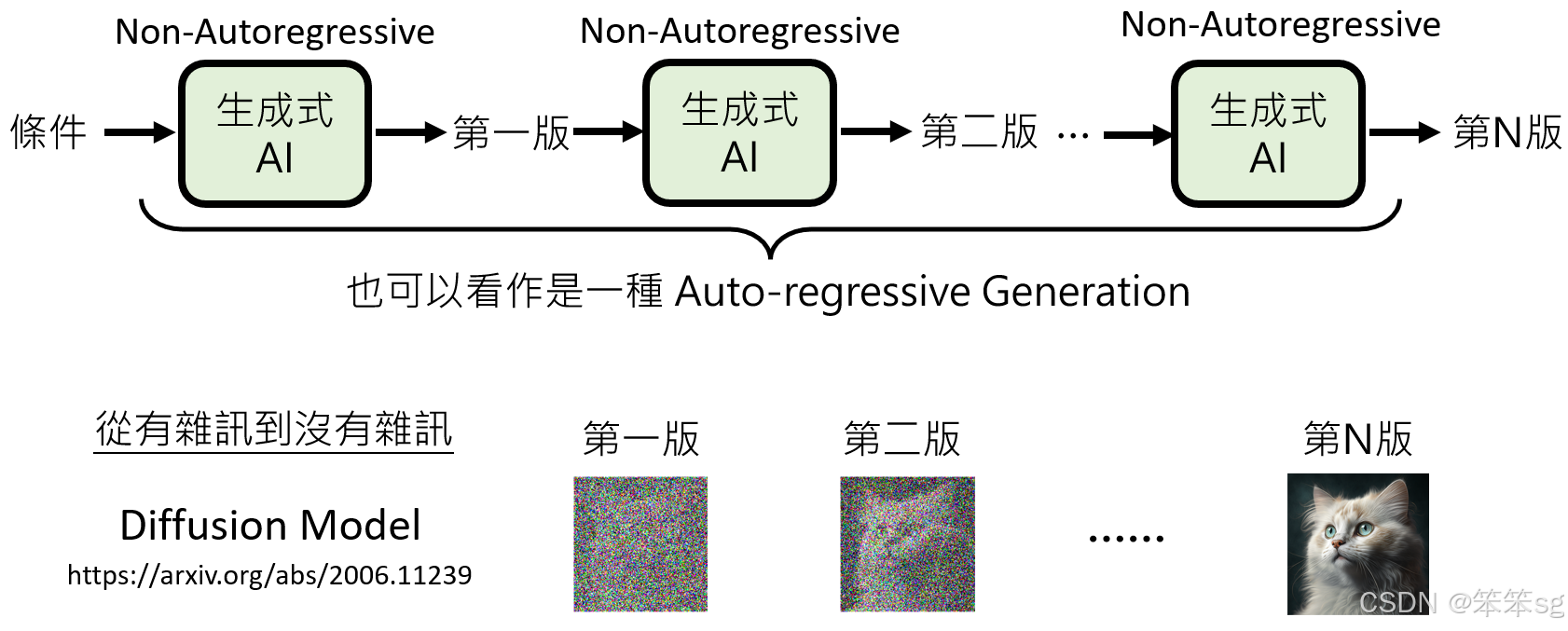
这不仅是nauto-regressive模型与auto-regressive模型的结合,还提供了一个逐渐优化的过程,使得生成的图像更加清晰和真实。
11.3 逐步修改生成的图像:
另外一种方法是生成初步版本后,逐步改进生成结果。比如,初步的生成图像可能非常粗糙,包含许多不符合预期的部分。这时,可以使用一种机制自动检测并涂去不好的部分,再根据这些已经修正的部分继续生成。这个过程就像是“修补”图像的过程,每次修正和生成的版本都比前一个更接近最终目标。
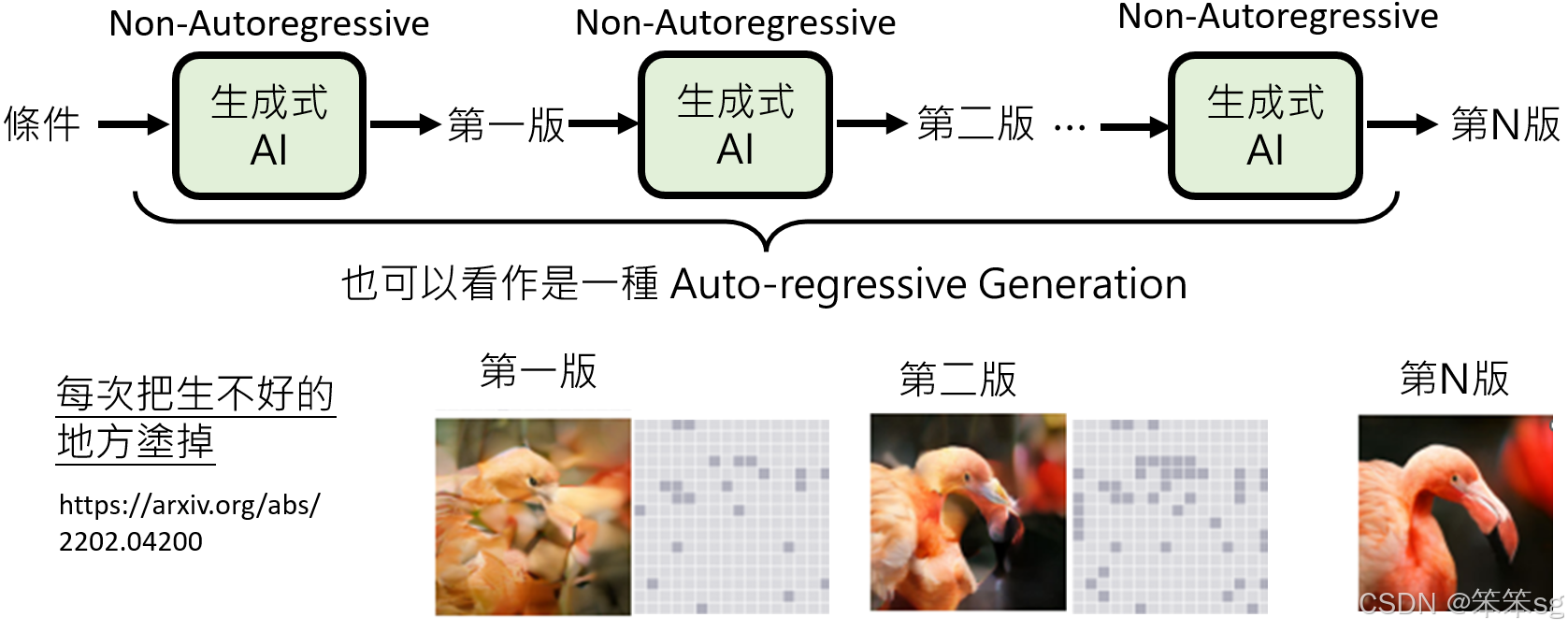
这种方法通过不断修复图像中的不好的区域,最终生成出清晰和真实的图像。
12 通过用NAR替代部分AR来减少生成时间
在结合auto-regressive和non-auto-regressive模型时,为了减少生成过程的时间,通常会采用一种方法来优化速度,尤其是在生成较大的图像时。以下是一些关键步骤:
12.1 将部分auto-regressive生成替换为non-auto-regressive生成:
在传统的auto-regressive生成中,可能需要大量的时间来生成较大的图像(如256×256)。为了加速这一过程,可以将auto-regressive的部分替换为non-auto-regressive生成(这也可以看做是一种自回归,哈哈)。non-auto-regressive模型的每个生成步骤可以大大减少所需的计算量,从而提高效率。例如,原本需要256×256次生成的过程,使用non-auto-regressive模型可能只需要十次生成步骤。
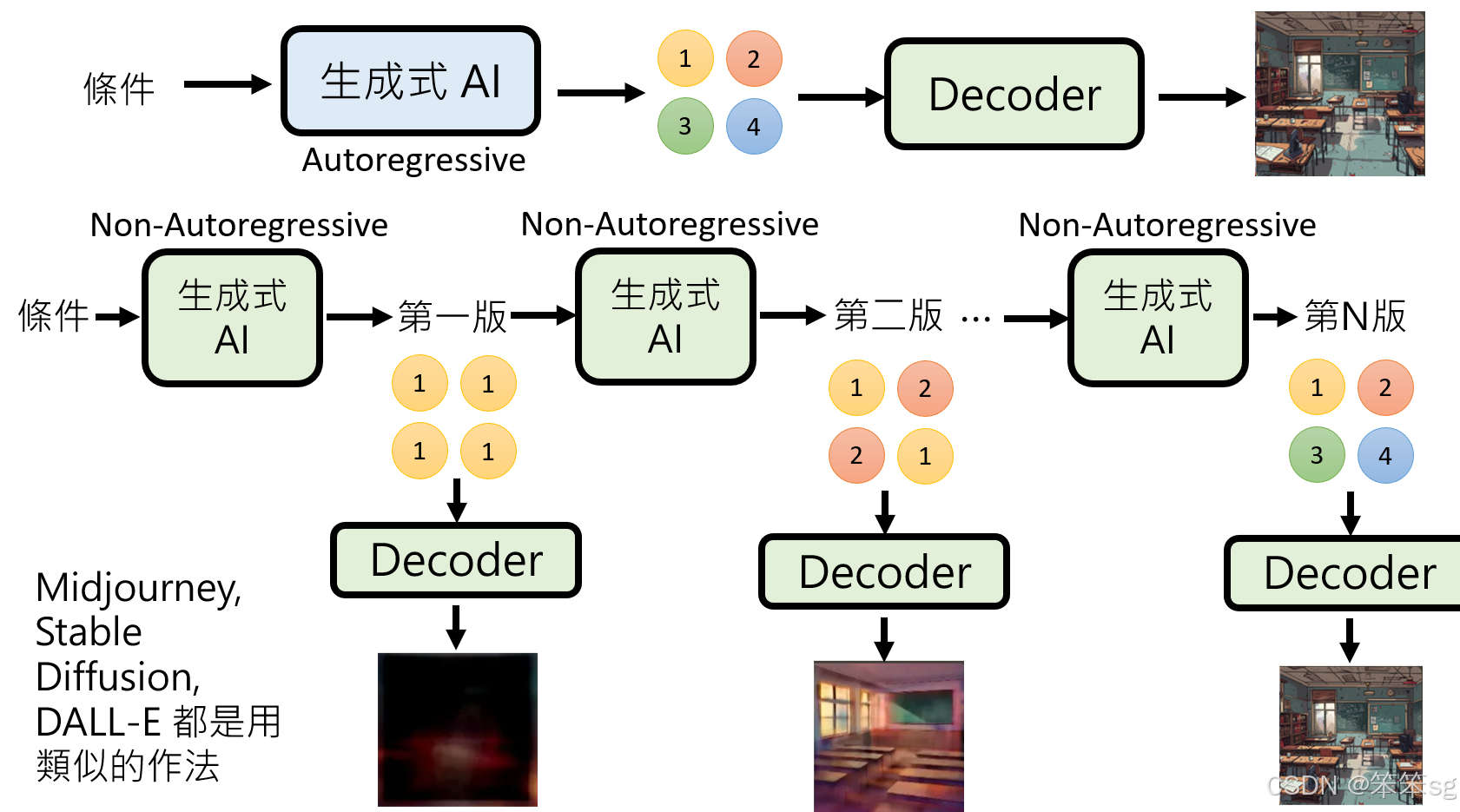
12.2 生成压缩版本的图像:
在这种优化方法中,non-auto-regressive模型生成的并不是最终的图像,而是其压缩版的表示。生成的每个压缩版本会逐渐从简单的表示开始,逐步细化,直到生成压缩的第N版。之后,这个压缩版本会被送入一个预先训练好的decoder,最终生成出高清晰度的图像。
12.3 典型的生成过程(如MidJourney、Stable Diffusion等):
在如MidJourney和Stable Diffusion等常见影像生成模型中,这一方法得到了广泛应用。例如,在MidJourney中,你输入文字描述后,模型首先生成一个非常模糊的图像,随后随着每一轮生成过程,图像逐渐变得更加清晰和细致。这一过程实际上就是通过多次使用non-auto-regressive模型生成的压缩版本,最终通过decoder将其恢复成完整的图像。
12.4 具体例子:
例如,当你在MidJourney中请求生成一个“教室”图像时,初步版本可能完全无法辨认图像内容。接下来,图像变得稍微模糊,可以看出一些教室的基本结构,最终经过若干个版本的迭代,模型会生成出一个非常精细、包含复杂元素的教室图像。这一过程中,压缩版本的生成和解码器的使用,使得每次生成既高效又准确。
13 小结
小结部分可以概括为以下几个要点:
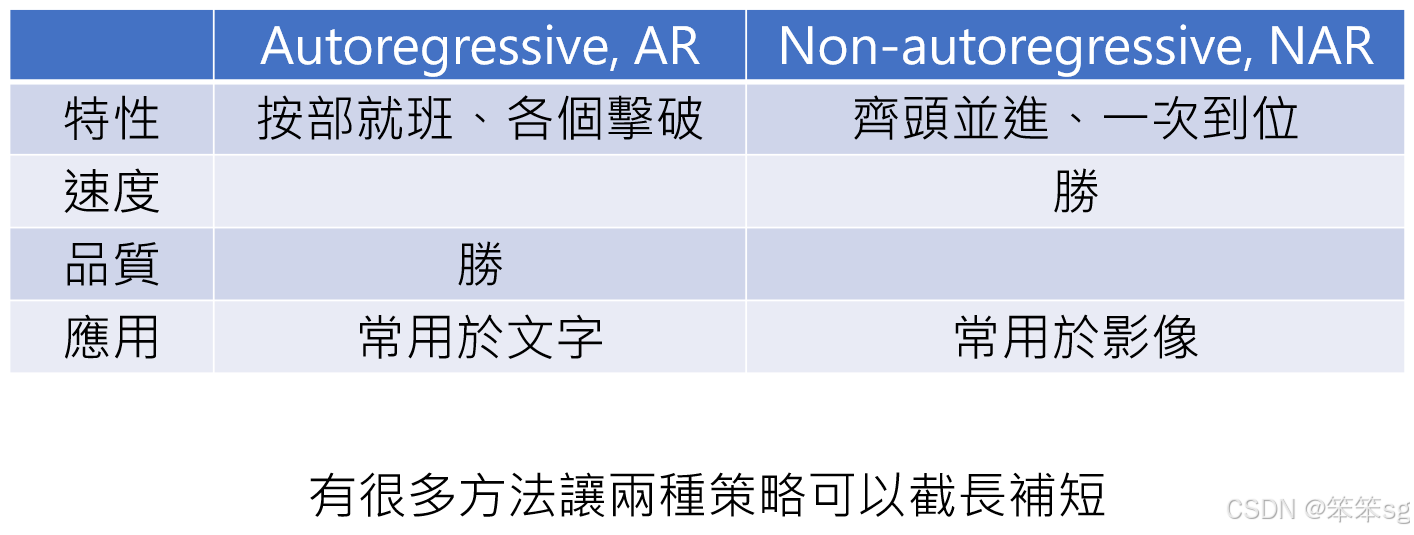
-
Auto-regressive模型:
- 特点: 按部就班地逐步生成,确保生成的质量较高。
- 优势: 生成的结果品质较好,但速度较慢,适用于对生成质量要求较高的场景。
- 应用: 通常在图像生成中,尤其是对于细节要求较高的任务。
-
Non-auto-regressive模型:
- 特点: 齐头并进,一次性生成所有内容。
- 优势: 生成速度非常快,但生成结果的质量可能较差,可能会出现一些不一致或细节缺失的问题。
- 应用: 主要用于要求较快生成速度的场景,虽然生成质量可能略逊一筹,但速度上的优势是显著的。
-
结合两者的优势:
- 综合利用: 通过结合auto-regressive和non-auto-regressive模型的优点,可以在保证生成质量的同时提高生成效率。现代的影像生成模型,像MidJourney和Stable Diffusion,就是通过这两种方法的结合,既能保持较好的生成质量,又能提升生成速度。
总结来说,auto-regressive和non-auto-regressive各有优缺点,理想的情况是将这两种方法结合起来,以实现既高效又高质量的生成效果。
评论记录:
回复评论: