
目录
1 如何利用语言模型(特别是GPT-2和GPT-4)来解释神经网络中的神经元行为
10.4 模拟器(Simulator)和解释器(Explainer)是否足够强大?
0 完整章节内容
本文为李宏毅学习笔记——2024春《GENERATIVE AI》篇——“拓展内容(第11讲)”章节的拓展部分笔记,完整内容参见:
李宏毅学习笔记——2024春《GENERATIVE AI》篇
本章节资源链接:
【生成式AI 2023】用語言模型來解釋語言模型 (上) - YouTube
之前我们在“机器学习模型的可解释性——GENERATIVE AI——拓展内容(第11讲)”已经详细介绍了关于机器学习模型的可解释性方法,今天我们来讲一下“用AI来解释AI”是如何做的。
1 如何利用语言模型(特别是GPT-2和GPT-4)来解释神经网络中的神经元行为
OpenAI近期发布的一篇论文,内容涉及如何利用语言模型(特别是GPT-2和GPT-4)来解释神经网络中的神经元行为。这是AI可解释性领域的一项探索,尤其关注如何从神经元的激活模式中推测它们的功能。

1.1 神经元的作用猜测
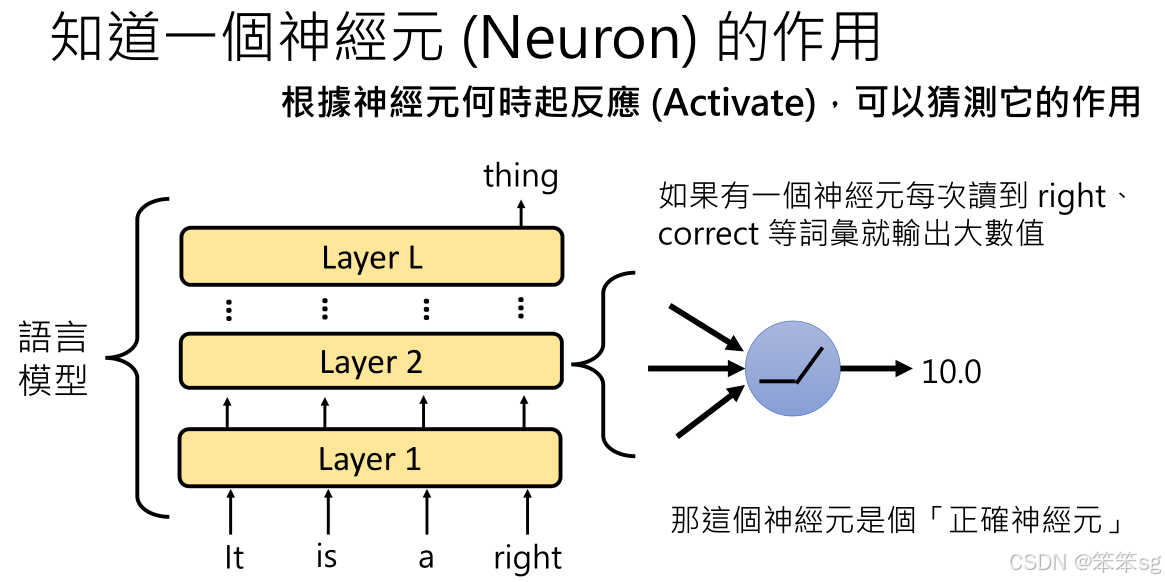
文章的核心问题是理解每个神经元的作用。通过观察神经元在读取特定词汇时的激活值,研究人员试图推测这些神经元的功能。例如,一个神经元如果在遇到“correct”或“right”时会产生较大激活值,那它很可能是在检测与“正确”相关的内容。

1.2 如何使用GPT模型进行解释

OpenAI提出了一个方法,先记录某个神经元在读取大量句子时的激活模式(即神经元输出的数值)。然后,使用GPT-4分析这些数据,推测该神经元的功能。这种方法的简单性让它成为一个有用的工具,尽管要取得准确的结果,可能需要进一步的数据处理和优化。

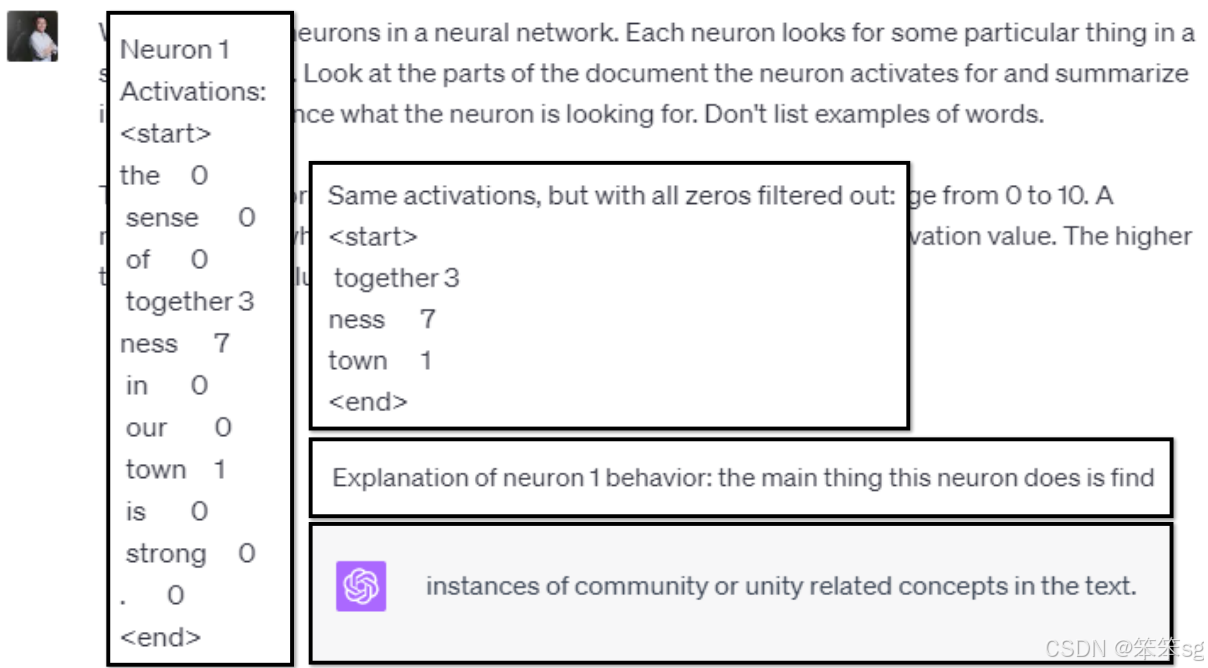
1.3 实际示例
例如,某些神经元会在看到“correct”或“right”时激活,可以推测该神经元在侦测“正确”的概念。另一个例子是,某个神经元会在读到“like tea that rides a bike”这类比喻句子时激活,推测它是在检测比喻。


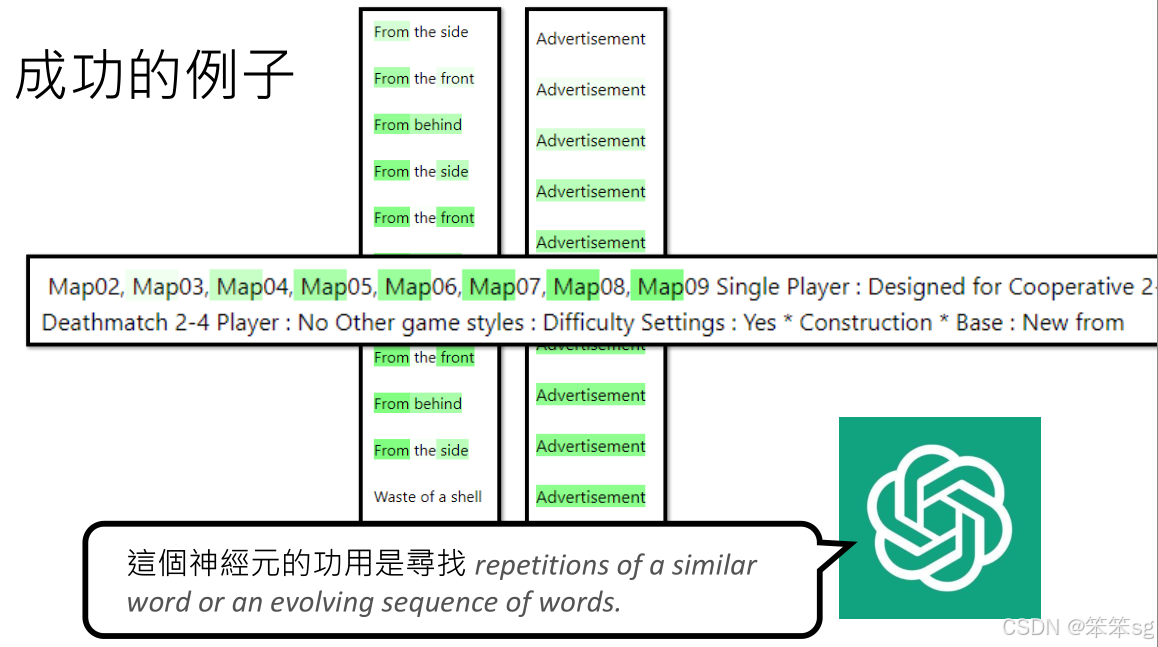
1.4 失败的例子
有些神经元的激活模式比较难以解释。比如,某些神经元在看到特定的词汇或模式时激活,但没有明显的规律性。对于这些神经元,即使GPT-4也无法准确推测其功能。


1.5 GPT模型的应用
OpenAI提出的“用语言模型解释语言模型”的方法其实非常简单,主要是通过给GPT-4提供神经元的激活模式,并请求其推测这些神经元的功能。这个过程为AI的可解释性提供了新的思路,但也揭示了AI内部复杂行为的挑战。
2 怎么知道GPT-4解释的好不好呢?
1)让GPT-4扮演神经元
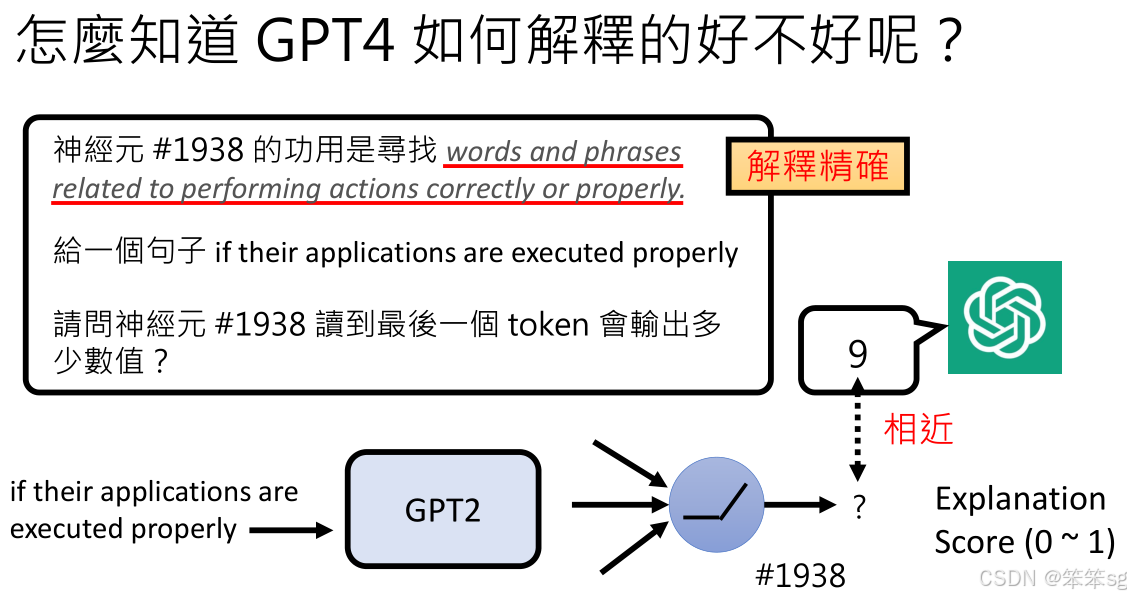
为了让GPT-4扮演一个神经元,首先要给它提供神经元的功能描述。例如,一个神经元编号(如1938)的功能是侦测“正确”的事情。然后,GPT-4根据这个功能,预测该神经元在看到一个句子时的输出数值。
2)实际神经元的输出与GPT-4的预测比对:
接下来,把同样的句子输入到GPT-2(或GPT-3的神经网络),看看神经元编号1938的真实输出是多少。然后,比较GPT-4的预测与实际输出之间的差距。如果GPT-4的预测结果接近实际输出,就证明GPT-4的解释是准确的。
3)计算解释力分数:
根据GPT-4预测的结果与真实神经元输出的相似程度,计算出一个解释力分数。这个分数的范围是0到1,1表示GPT-4的解释非常精确,0表示完全不准确。这个分数反映了GPT-4在扮演神经元时的成功程度。
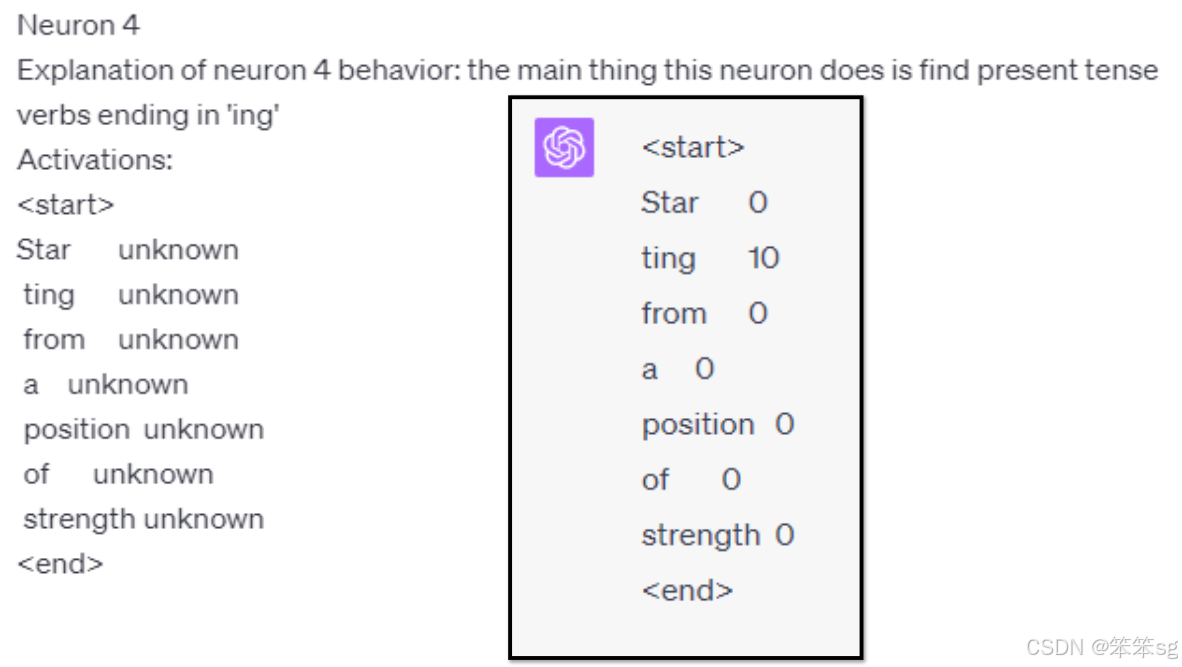
4)具体例子:

比如,假设神经元编号4的功能是侦测以“ING”结尾的动词。给GPT-4输入句子“I am running”,GPT-4根据神经元的功能会预测该神经元的输出值是10(因为“running”是以“ING”结尾的动词)。而当输入句子“I am running to”时,神经元编号4的输出值应该是0,因为句子中的最后一个token“to”并不是以“ING”结尾的动词。
3 GPT4能够成功解释神经元么?
3.1 神经元的可解释性与网络规模的关系
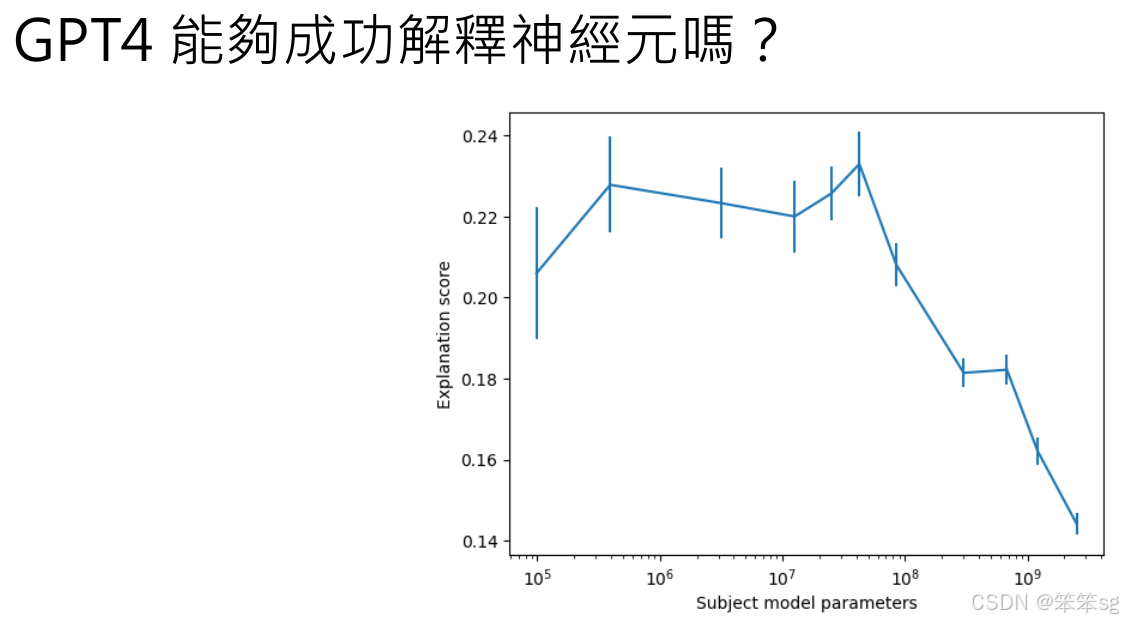
小型模型 vs. 大型模型:在小型神经网络中,每个神经元的功能通常比较明确,容易解释。而在大型模型中,神经元往往并不是单独发挥作用,多个神经元可能共同承担一个复杂任务,因此单个神经元的行为就不容易被单独解释。这是因为在大型网络中,神经元之间的关系和相互作用更加复杂和抽象。
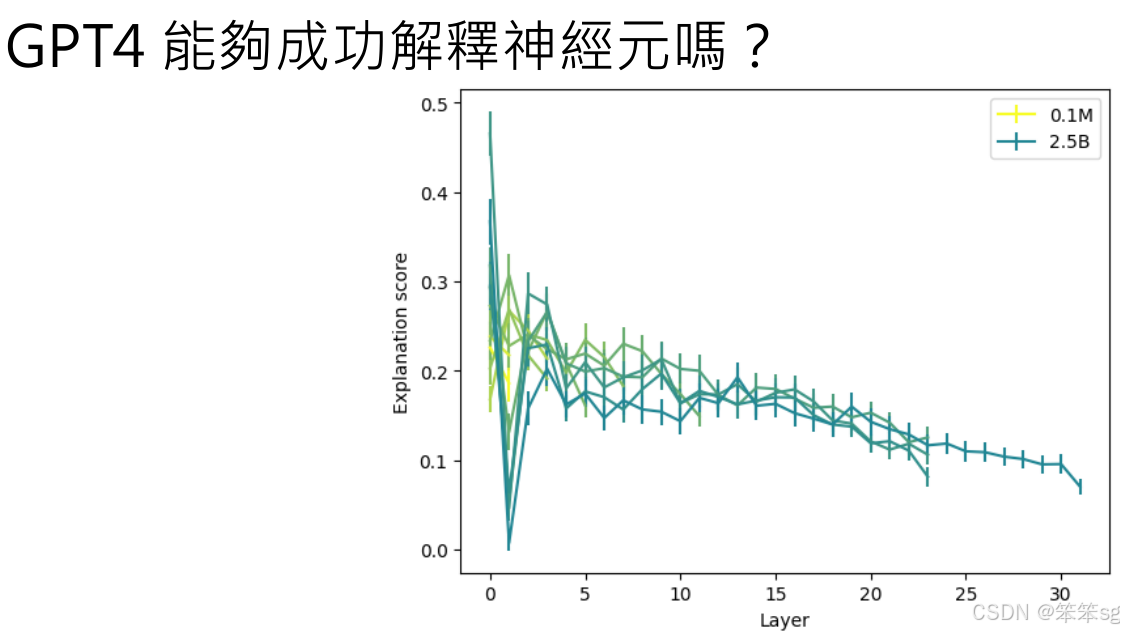
3.2 层次与可解释性的关系
低层 vs. 高层神经元:低层神经元通常负责简单的任务(例如特定词汇的识别),因此它们的行为较为单一且容易被解释。相比之下,高层神经元通常处理更加抽象的概念和模式,因此它们的行为更加难以理解。这也是为什么底层神经元的解释力评分通常较高,而高层神经元则较低。
3.3 可解释性分数的整体趋势
- 对于大多数神经元,GPT-4生成的解释力分数较低,通常在0.14到0.15之间。这意味着,尽管GPT-4能够尝试解释神经元的行为,但大多数神经元的行为并没有清晰明确的解释。
- 但有一些神经元的解释相对较好,得到了较高的解释力分数,例如“正确神经元”这一类神经元的解释分数为0.42,这表明它们的行为在一定程度上是可以理解的。

3.4 与人类解释的比较
OpenAI还进行了一个实验,邀请人类提供对神经元行为的解释,然后由GPT-4基于这些人类解释来预测神经元的输出。结果发现,尽管人类的解释有时更加直观,但人类提供的解释力分数也并没有明显高于GPT-4的解释力分数。具体来说,人类解释的平均分数为0.18,和GPT-4的平均分数0.15差别不大。
3.5 结论:神经元的行为多为不明
总体来看,大多数神经元的行为非常难以解释,这也是类神经网络的一大挑战。即使是GPT-4也很难给出合理的解释。但幸运的是,仍然有少数神经元的行为是可以理解和解释的,尤其是在低层神经元中,GPT-4能够较好地识别它们的功能。
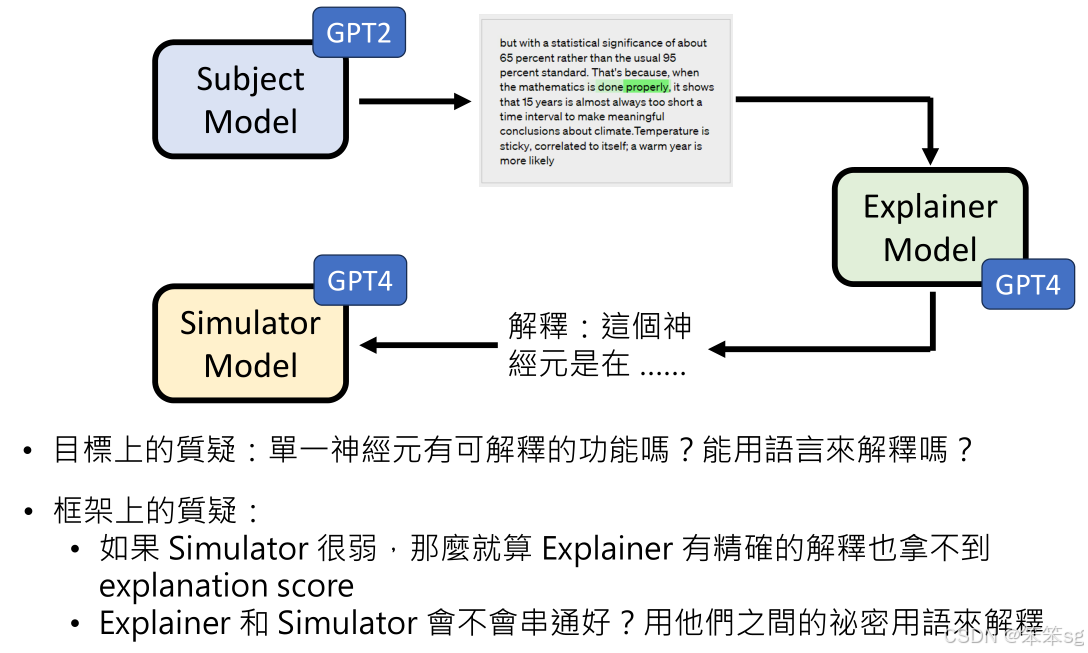
4 AI模型解释AI模型的流程
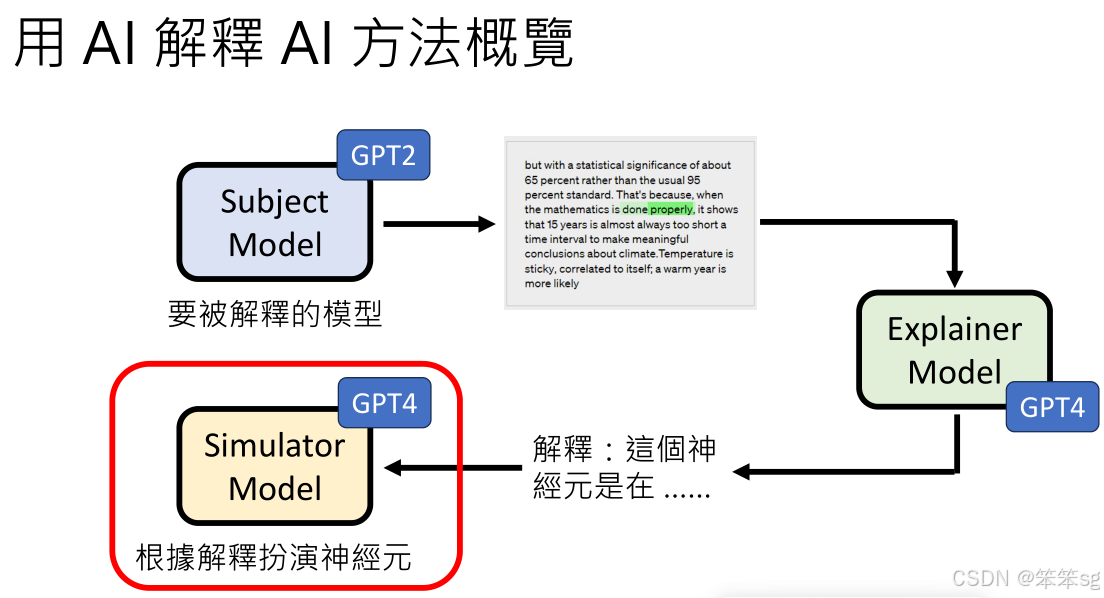
其中有三个主要组件:被解释模型、解释模型、和模拟器模型。下面是该方法的概览:
4.1 被解释的模型(Subject Model)
- 角色:被解释的模型是你希望了解其行为或决策过程的目标模型。在本例中,GPT-2就是被解释的模型。
- 任务:你会对该模型输入不同的句子,然后观察这些输入对其神经元激活的影响,尤其是它在不同的输入条件下,如何激活特定的神经元。这些激活信息将被用作输入,供解释模型进一步分析。
4.2 解释模型(Explanation Model)
- 角色:解释模型负责从被解释模型的激活数据中提取并生成解释。它会根据神经元的激活模式,提供对这些模式的描述和解释,试图揭示每个神经元或神经元组的作用和行为。
- 任务:解释模型接收到被解释模型提供的神经元激活数据后,生成关于这些激活模式的自然语言描述(例如:“这个神经元负责识别特定的动词形式”)。
4.3 模拟器模型(Simulator Model)
- 角色:模拟器模型用于验证解释的准确性。它的任务是根据解释模型生成的描述,模拟被解释模型中特定神经元的行为。(扮演这个特定的神经元,然后输入一个句子观察其激活值)
- 任务:模拟器模型尝试根据解释模型提供的说明来预测神经元的激活或输出,看看这个模拟的输出与实际的输出是否匹配。如果模拟器的预测和实际输出相符,就意味着解释是准确的。如果不匹配,说明解释有误。
4.4. 评估(Evaluation)
角色:最终,评估会通过比较模拟器的输出与被解释模型的实际输出,来判断解释模型的效果。通常,解释的质量通过一个称为**解释力评分(Explanation Score)**的量化指标来衡量。这个分数反映了模拟器的输出与实际输出的相似程度,分数越高,表示解释越准确。
4.5 可选模型
需要强调的是,虽然在这个方法中被解释的模型是GPT-2,解释模型和模拟器模型是GPT-4,但这些模型不一定非要是同一个,也不一定非要是GPT-4。理论上,任何能够理解并生成自然语言的语言模型,都可以用作解释模型或模拟器模型,只要它们能处理神经元激活数据并给出有意义的解释。
5 神经元的扮演与输出比较
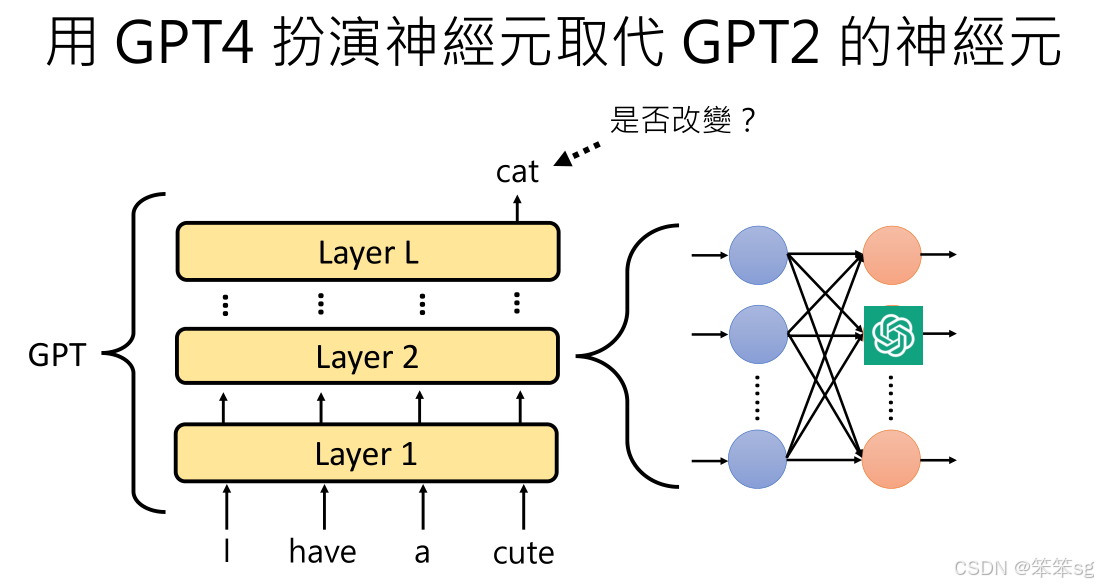
- 扮演神经元:GPT-4被用来扮演GPT-2中的某个神经元,替代原神经元在模型中的作用。这是为了评估该神经元的行为是否能够被准确模拟。通过比较GPT-4生成的神经元输出与原神经元输出之间的相似度,可以判断GPT-4是否能成功“扮演”该神经元。
- 输出的意义:单纯比较神经元的输出差异并不总能完全揭示神经元的重要性,因为某些神经元对模型的整体输出影响较大,即使其输出变化很小。反之,一些神经元可能输出大幅波动,但对模型最终结果影响有限。
6 用GPT-4替换神经元的影响
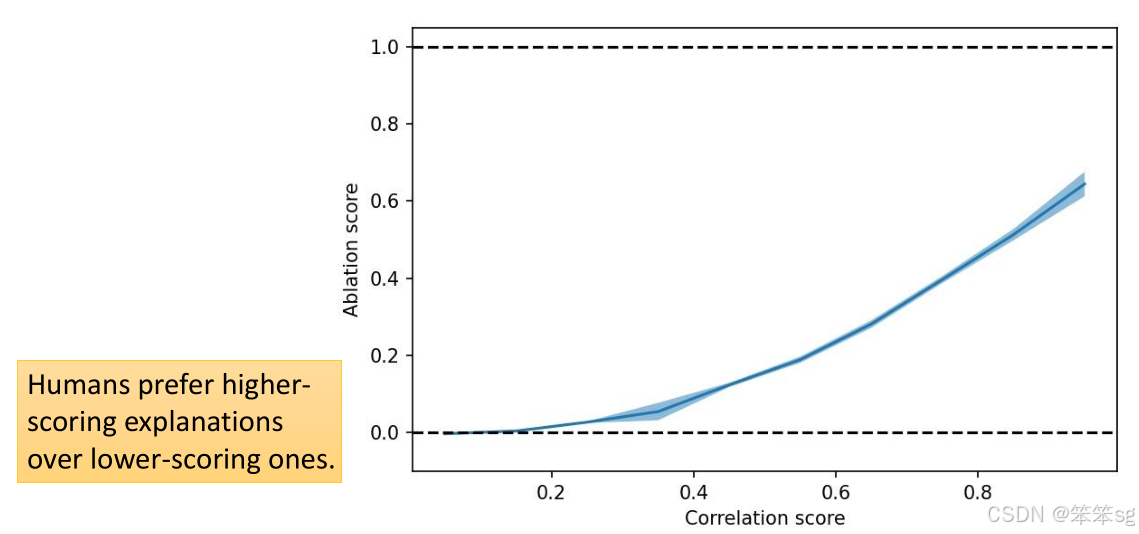
- 替换测试:通过将GPT-4生成的神经元输出替换原本的GPT-2神经元输出,观察替换后的GPT-2模型的行为变化。如果替换前后的输出差异显著,说明这个神经元可能对模型的决策有较大影响。
- 验证扮演效果:这种验证方法表明,GPT-4的输出与实际神经元输出之间的差异可以通过对比相关性分数(correlation score)和应用分数(application score)来衡量。这两者之间呈正相关,意味着可以选用其中一个分数作为最终的评价标准。
7 解释的质量与扮演的准确性
- 解释与扮演的关联:GPT-4的解释结果质量与它扮演神经元的准确性之间存在正相关关系。即,当GPT-4能准确地模拟神经元行为时,生成的解释通常会更为准确。
- 人工评价:通过人工评估,发现解释分数较高的案例,GPT-4给出的解释也通常较为准确。这意味着,GPT-4在扮演神经元时生成的解释与真实神经元行为之间的关系是有一定的实际意义的。
8 选择句子的重要性

- 挑选句子:为了获得有用的解释,需要从大量输入句子中挑选出特定神经元激活值大的句子。这样做可以更精确地捕捉到神经元的反应模式。然而,挑选句子的方法也有其局限性,可能导致错误的解释。
- 误解与修正:举例来说,如果通过初步选择的句子看某个神经元在看到某个词(如"All")时激活,可能会得出误解,认为神经元只在看到"All"时才激活。但如果生成更多关键的句子,重新验证这个神经元的激活模式,可能会发现神经元真正的作用是识别特定的上下文(如"not all"而不是单纯的"all")。这种修正通过生成新的数据,能使模型更加准确地理解神经元的实际功能。
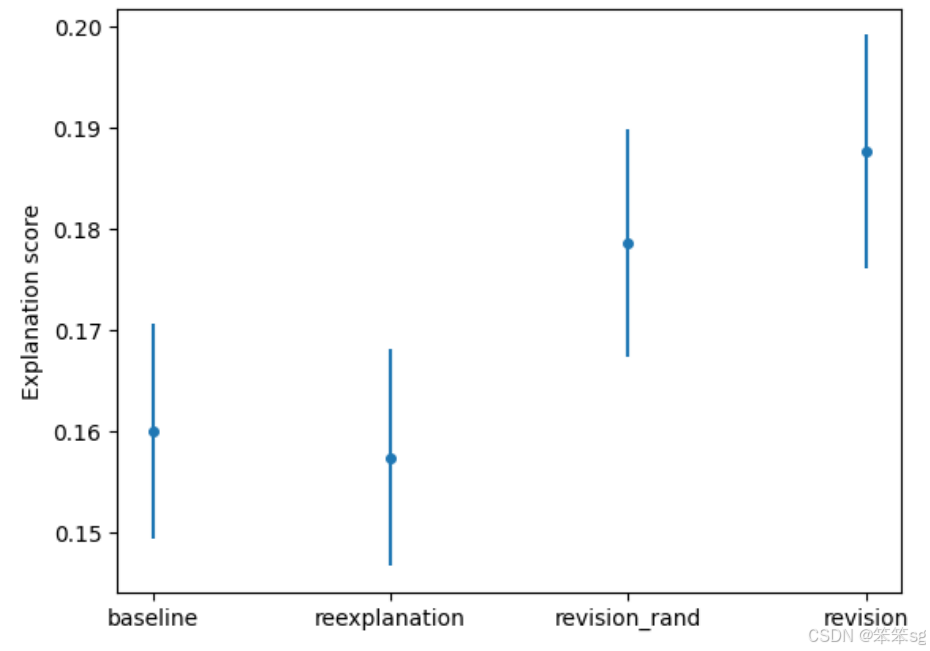
9 生成更多关键句子的优势

- GPT-4生成数据:通过让GPT-4生成更多与神经元激活相关的句子,可以帮助更好地揭示神经元的实际功能。这种方法比随机选择句子或直接挑选激活值高的句子更有效,因为GPT-4能产生带有更多关键信息的句子,有助于提高解释的准确性。
- 效果验证:通过将新生成的句子与原有的句子结合使用,可以显著提高对神经元的解释力分数,从而获得更好的模型解释。
10 “用AI来解释AI”的一些问题
10.1 AI解释AI的合理性
- 质疑:用AI来解释AI,是否就像用“我们不懂的东西解释另一个我们不懂的东西”?这种观点认为,AI作为一个复杂的黑盒,其内部机制与我们现有的理解可能完全不同,无法完全通过现有的语言或方法来解释。
- 回应:一种反驳观点是,人类的大脑本身也是一个复杂的黑盒。我们用人类的思维来解释AI模型的行为,这和用AI来解释AI其实是相似的。虽然这两者在结构和机制上有巨大差异,但如果能通过AI的输出模式来构建解释框架,这未必就是不可行的。
10.2 解释单个神经元的意义
- 质疑:文章的核心目标是解释单个神经元的作用,但单个神经元可能只是网络功能的一部分,其功能往往是与其他神经元结合后的结果。一个神经元的作用可能有限,解释单个神经元的功能是否对理解整个网络有意义?
- 回应:这种质疑是合理的。现代神经网络,尤其是深度神经网络,是通过大量神经元的协同作用完成任务的。因此,单一神经元的功能解释可能只能提供部分信息,真正的网络行为是通过神经元的组合来实现的。确实,OpenAI的研究也提到,他们有尝试让GPT-4不仅仅解释单个神经元,而是解释一组神经元的行为,这样的解释可能更有意义。
10.3 语言能否描述神经元的行为?
- 质疑:神经元的行为可能非常复杂,且不一定能用人类语言准确描述。神经元可能执行一些非常抽象的、复杂的计算,甚至是我们未曾意识到的行为,而这些行为可能无法被人类语言所捕捉。
- 回应:这是一个非常值得深思的问题。神经元的行为往往是高度抽象的,它们的功能可能并不完全符合我们常用语言的表达方式。因此,用自然语言解释神经元的行为可能存在很大的局限性。然而,尽管如此,我们可以通过近似的方式(例如使用GPT-4等模型)来表达神经元的功能,虽然这并不意味着解释一定是完美的,但至少可以为理解提供一定的启示。
10.4 模拟器(Simulator)和解释器(Explainer)是否足够强大?
- 质疑:整个方法框架是先用解释器生成解释,再通过模拟器验证这个解释。如果模拟器本身的能力较弱,那么无论解释有多好,模拟器也无法正确“扮演”神经元的行为。最终的解释力分数可能并不能反映解释的实际质量。
- 回应:这个问题确实存在,如果模拟器的能力不足,它可能无法准确地扮演神经元的功能,进而影响整个解释的有效性。因此,模拟器的性能至关重要。如果模拟器无法精确地反映神经元的行为,那么解释力分数就不能完全信赖。为了确保解释的有效性,需要对模拟器进行严格的验证和优化。
10.5 解释是否能被人类理解?
- 质疑:假设解释力分数很高,但最终得到的解释可能是“AI之间的暗语”,人类无法理解。也就是说,GPT-4给出的解释可能是有效的,但并不一定符合人类的认知方式,因此这些解释对我们来说可能没有实际意义。
- 回应:这一点是非常重要的,尤其是在AI逐渐变得更复杂时,AI解释可能变得难以为人类所理解。尽管GPT-4等模型可能能够生成非常精确的解释,但这些解释可能并不符合我们直觉上的理解方式。因此,需要进一步探索如何将这些AI生成的解释翻译为更加易于人类理解的形式。
评论记录:
回复评论: